Prototypical Networks for Few shot Learning PyTorch
1.0.0
Pytorch의 소수의 샷 학습 (종이, 코드)을위한 프로토 타입 네트워크의 간단한 대체 구현.
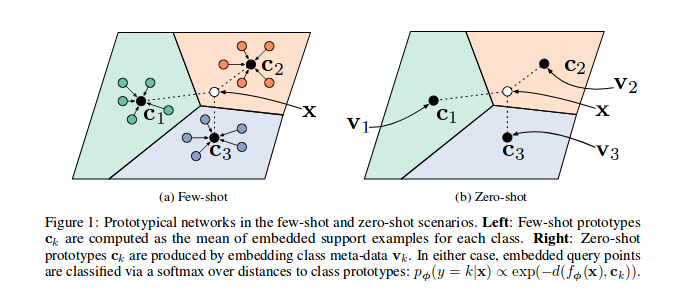
참조 용지 프로토 타입 네트워크는 벡터 공간, 특히 각 에피소드 (반복)에 벡터 공간에 샘플 특징을 포함하도록 훈련 된 바와 같이, 클래스의 서브 세트에 대한 다수의 샘플이 모델을 통해 선택되고 전송되며, 클래스 c 의 각 하위 집합에 대해 여러 샘플의 특징 ( n_support )에 사용된다. n_query 샘플과 클래스 바리 센터를 최소화 할 수 있습니다.
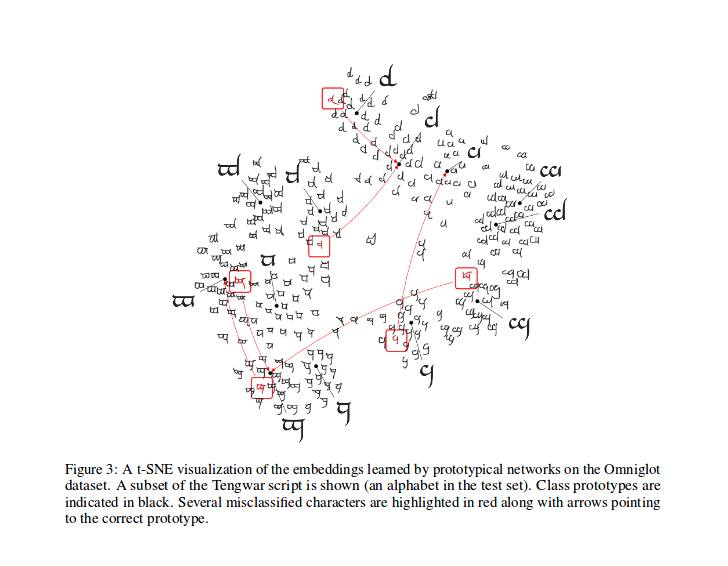
훈련 후, 모델에서 생성 된 기능에 대해 t-sne을 계산할 수 있습니다 (이 repo에서 수행되지 않고 T-SNE에 대한 더 많은 정보)은 논문에 표시된 샘플입니다.
그의 기여를 위해 @ludc에 대한 Kudos : Pytorch/Vision#46. 공식 데이터 세트가 코드의 큰 변경을 의미하지 않으면 TorchVision에 추가 될 때 공식 데이터 세트를 사용합니다.
우리는 [One Shot Learning을위한 네트워크 일치]에서와 같이 Vynials 분할 방법을 구현했습니다. 그것은 종이에 사용 된 것과 동일해야합니다 (실제로 "Offical"Repo에서 분할 파일을 다운로드). 그런 다음 설명 된 동일한 회전을 적용합니다. 이런 식 으로이 코드를 실행하여 얻은 결과를 참조 용지에 설명 된 결과와 비교할 수 있어야합니다.
PYDOC에 설명 된 바와 같이,이 클래스는 프로토 타입 교육 알고리즘에 대한 각 배치의 인덱스를 생성하는 데 사용됩니다.
특히, 샘플은 데이터 세트의 레이블 목록을 전달하여 샘플러가 총 클래스 수를 유도하고 데이터 세트의 각 클래스에 대한 인덱스 세트를 만듭니다. 각 에피소드에서 샘플러는 n_classes 랜덤 클래스를 선택하고 선택한 각 클래스 각각에 대해 샘플 인덱스의 숫자 ( n_support + n_query )를 반환합니다.
인용 된 논문에서와 같이 손실을 계산하는데, 주로 저자 중 한 사람 이이 코드에서 영감을 얻은다.
prototypical_loss.py 에서 손실 함수와 손실 클래스 à la pytorch가 모두 구현됩니다.
이 기능은 모델, 샘플의 지상 진실 및지지 샘플로 사용될 샘플의 n_suppport 에서 배치 입력을 입력합니다. 에피소드 클래스는 대상 목록에서 추론되고, n_support 샘플은 각 클래스에 대해 무작위로 추출되고, 해당 클래스 바리 센트는 계산되고, 각 클래스 바리 센터에서 나머지 샘플의 삽입의 거리와 각 에피소드 클래스에 속하는 각 샘플의 확률은 지느러미에 계산됩니다. 그런 다음 분류 문제에서 평소와 같이 잘못된 예측 확률 (쿼리 샘플의 경우)에서 손실을 계산합니다.
교육 코드는 시연 목적으로 만 있습니다.
이 작업에 대한 Protonet을 훈련시키기 위해 CD는이 Repo의 src 루트 폴더에 들어가서 실행합니다.
$ python train.py
스크립트는 다음 명령 줄 옵션을 취합니다.
dataset_root : THA 데이터 세트가 저장되는 루트 디렉토리, 기본값 '../dataset'
nepochs : 훈련 할 에포크 수, 기본값 100
learning_rate : 모델의 학습 속도, 기본값 0.001
lr_scheduler_step : Steplr 학습 속도 스케줄러 단계, 기본값으로 20
lr_scheduler_gamma : Steplr 학습 속도 스케줄러 감마, 기본값 0.5
iterations : 에포크 당 에피소드 수. 기본값은 100 입니다
classes_per_it_tr : 훈련을위한 에피소드 당 랜덤 클래스 수. 기본값은 60 입니다
num_support_tr : 교육 지원으로 사용할 수업 당 샘플 수. 기본값 5
num_query_tr : 교육을위한 쿼리로 사용할 클래스 당 샘플이 있습니다. 기본값 5
classes_per_it_val : 유효성 검사를위한 에피소드 당 랜덤 클래스 수. 기본값 5
num_support_val : 유효성 검사 지원으로 사용할 클래스 당 샘플 수. 기본값 5
num_query_val : 유효성 검사를위한 쿼리로 사용할 클래스 당 샘플 수. 기본값은 15 입니다
manual_seed : 수동 시드 초기화 입력, 기본값은 7
cuda : CUDA 활성화 ( True 상점)
인수없이 명령을 실행하면 기본 하이퍼 파 램터 값 (위의 결과를 생성)으로 모델을 훈련시킵니다.
우리는 참조 용지 공연을 재현하려고 노력하고 있으며 여기에서 최상의 결과를 업데이트 할 것입니다.
| 모델 | 1- 샷 (5 웨이 ACC.) | 5 샷 (5 방향 Acc.) | 1- 샷 (20 웨이 ACC.) | 5- 샷 (20 방 Acc.) |
|---|---|---|---|---|
| 참조 용지 | 98.8% | 99.7% | 96.0% | 98.9% |
| 이 repo | 98.5%** | 99.6%* | 95.1%° | 98.6%° |
* 기본 매개 변수를 사용하여 달성했습니다 ( --cuda 옵션 사용)
** 달리기 python train.py --cuda -nsTr 1 -nsVa 1
° 실행 python train.py --cuda -nsTr 1 -nsVa 1 -cVa 20
°있어 python train.py --cuda -nsTr 5 -nsVa 5 -cVa 20 달성
다음과 같이 논문을 인용하십시오 (Arxiv에서 복사했습니다) :
@article{DBLP:journals/corr/SnellSZ17,
author = {Jake Snell and
Kevin Swersky and
Richard S. Zemel},
title = {Prototypical Networks for Few-shot Learning},
journal = {CoRR},
volume = {abs/1703.05175},
year = {2017},
url = {http://arxiv.org/abs/1703.05175},
archivePrefix = {arXiv},
eprint = {1703.05175},
timestamp = {Wed, 07 Jun 2017 14:41:38 +0200},
biburl = {http://dblp.org/rec/bib/journals/corr/SnellSZ17},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
이 프로젝트는 MIT 라이센스에 따라 라이센스가 부여됩니다
저작권 (C) 2018 Daniele E. Ciriello, Orobix SRL (www.orobix.com).


