Prototypical Networks for Few shot Learning PyTorch
1.0.0
Implementação alternativa simples de redes prototípicas para poucos aprendizado de tiro (papel, código) em Pytorch.
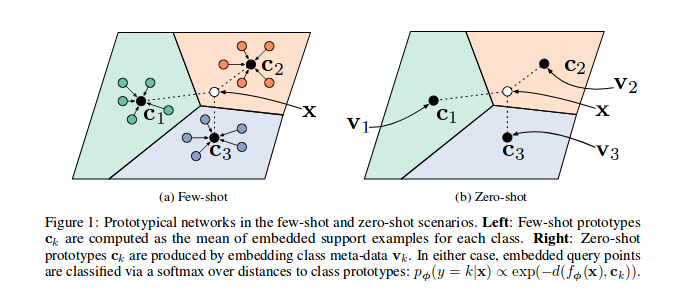
Como mostrado nas redes prototípicas de papel de referência, são treinados para incorporar os recursos de amostras em um espaço vetorial, em particular, em cada episódio ( n_support ), várias amostras para um subconjunto de classes são selecionadas e enviadas através do modelo, para cada subconjunto de sua classe c As amostras n_query restantes e sua classe baricentre podem ser minimizadas.
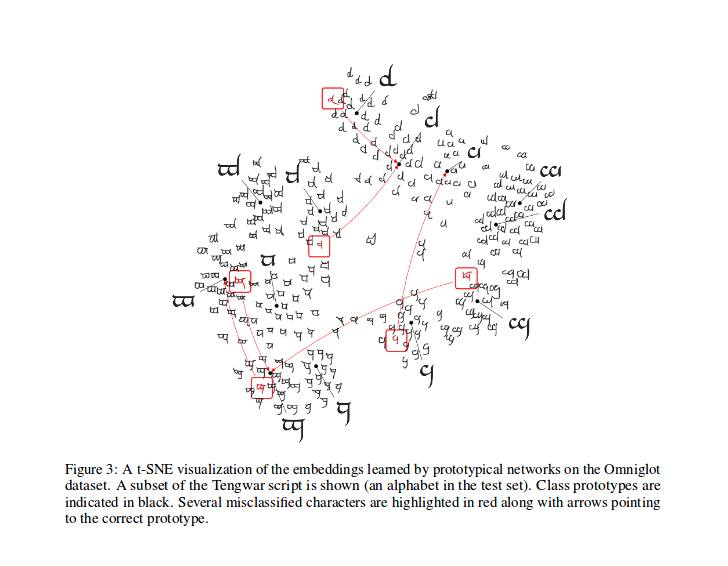
Após o treinamento, você pode calcular o T-SNE para os recursos gerados pelo modelo (não feito neste repositório, mais Infos sobre T-Sne aqui), esta é uma amostra como mostrado no papel.
Parabéns a @ludc por sua contribuição: Pytorch/Vision#46. Usaremos o conjunto de dados oficial quando for adicionado à TorchVision se não implicar grandes alterações no código.
Implementamos o método de divisão de Vynials como em [Redes de correspondência para o aprendizado de um tiro]. Esse deveria ser o mesmo método usado no artigo (na verdade, eu baixei os arquivos divididos do repositório "offical"). Em seguida, aplicamos as mesmas rotações descritas. Dessa forma, devemos ser capazes de comparar os resultados obtidos executando esse código com os resultados descritos no documento de referência.
Conforme descrito em seu Pydoc, esta classe é usada para gerar os índices de cada lote para um algoritmo de treinamento prototípico.
Em particular, o objeto é instanciado passando a lista dos rótulos para o conjunto de dados, o amostrador infere o número total de classes e cria um conjunto de índices para cada classe ni o conjunto de dados. Em cada episódio, o amostrador seleciona n_classes classes aleatórias e retorna um número ( n_support + n_query ) dos índices de amostras para cada uma das classes selecionadas.
Calcule a perda como no artigo citado, principalmente inspirado por este código por um de seus autores.
Na função prototypical_loss.py , a função de perda e a classe de perda à la pytorch são implementadas.
A função obtém a entrada da entrada em lote do modelo, as verdades de amostras e o número n_suppport de amostras a serem usadas como amostras de suporte. As classes de episódios são inferidas da lista de destino, as amostras n_support são extraídas aleatoriamente para cada classe, os baricientos de classe são calculados, bem como as distâncias da incorporação de cada amostras restantes de cada barycentre e a probabilidade de cada amostra de pertencer a cada classe de episódios são calculadas finmally; Em seguida, a perda é calculada a partir das probabilidades de previsões erradas (para as amostras de consulta) como de costume nos problemas de classificação.
Observe que o código de treinamento está aqui apenas para fins de demonstração.
Para treinar o protone nesta tarefa, CD na pasta raiz src deste repo e execute:
$ python train.py
O script pega as seguintes opções de linha de comando:
dataset_root '../dataset'
nepochs : número de épocas para treinar, padrão para 100
learning_rate : Taxa de aprendizado para o modelo, padrão para 0.001
lr_scheduler_step : Etapa do agendador da taxa de aprendizagem steplr, padrão para 20
lr_scheduler_gamma : Agendador de Taxa de Aprendizagem de Steplr Gamma, Padrão para 0.5
iterations : número de episódios por época. padrão para 100
classes_per_it_tr : Número de classes aleatórias por episódio para treinamento. padrão para 60
num_support_tr : Número de amostras por classe para usar como suporte para treinamento. padrão para 5
num_query_tr : NNUMPER DE Amostras por classe para usar como consulta para treinamento. padrão para 5
classes_per_it_val : Número de classes aleatórias por episódio para validação. padrão para 5
num_support_val : Número de amostras por classe para usar como suporte para validação. padrão para 5
num_query_val : Número de amostras por classe para usar como consulta para validação. padrão para 15
manual_seed : entrada para as inicializações manuais de sementes, padrão para 7
cuda : Ativa o CUDA (armazene True )
A execução do comando sem argumentos treinará os modelos com os valores padrão do HyperParparMters (produzindo resultados mostrados acima).
Estamos tentando reproduzir o papel de referência Performaces, atualizaremos aqui nossos melhores resultados.
| Modelo | 1-shot (Acc. | 5-tiros (Acc. 5 vias) | 1 -Shot (acc. | 5-shot (acc. |
|---|---|---|---|---|
| Papel de referência | 98,8% | 99,7% | 96,0% | 98,9% |
| Este repo | 98,5%** | 99,6%* | 95,1%° | 98,6%° |
* alcançado usando parâmetros padrão (usando --cuda Option)
** alcançado em execução python train.py --cuda -nsTr 1 -nsVa 1
° alcançado em execução python train.py --cuda -nsTr 1 -nsVa 1 -cVa 20
° python train.py --cuda -nsTr 5 -nsVa 5 -cVa 20
cite o papel da seguinte forma (copiou-o de Arxiv para você):
@article{DBLP:journals/corr/SnellSZ17,
author = {Jake Snell and
Kevin Swersky and
Richard S. Zemel},
title = {Prototypical Networks for Few-shot Learning},
journal = {CoRR},
volume = {abs/1703.05175},
year = {2017},
url = {http://arxiv.org/abs/1703.05175},
archivePrefix = {arXiv},
eprint = {1703.05175},
timestamp = {Wed, 07 Jun 2017 14:41:38 +0200},
biburl = {http://dblp.org/rec/bib/journals/corr/SnellSZ17},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Este projeto está licenciado sob a licença do MIT
Copyright (c) 2018 Daniele E. Ciriello, Orobix SRL (www.orobix.com).


