pytorch cnn visualizations
1.0.0
พื้นที่เก็บข้อมูลนี้มีเทคนิคการสร้างภาพเครือข่ายประสาทแบบ convolutional จำนวนหนึ่งที่นำมาใช้ใน Pytorch
หมายเหตุ : ฉันลบการพึ่งพา CV2 และย้ายที่เก็บไปยัง PIL บางสิ่งอาจเสีย (แม้ว่าฉันจะทดสอบวิธีการทั้งหมด) แต่ฉันจะขอบคุณถ้าคุณสามารถสร้างปัญหาได้หากสิ่งที่ไม่ได้ผล
หมายเหตุ : รหัสในที่เก็บนี้ได้รับการทดสอบด้วยคบเพลิงเวอร์ชัน 0.4.1 และฟังก์ชั่นบางอย่างอาจไม่ทำงานตามที่ตั้งใจไว้ในรุ่นต่อมา แม้ว่ามันจะไม่ควรใช้ความพยายามมากนัก แต่ฉันก็ไม่มีแผนในขณะนี้ที่จะสร้างรหัสในที่เก็บนี้เข้ากันได้กับเวอร์ชันล่าสุดเพราะฉันยังคงใช้ 0.4.1
ขึ้นอยู่กับเทคนิครหัสใช้ Alexnet หรือ VGG จาก Model Zoo ทั้งนี้ขึ้นอยู่กับเทคนิค รหัสบางส่วนยังถือว่าเลเยอร์ในแบบจำลองถูกแยกออกเป็นสองส่วน คุณสมบัติ ซึ่งมีเลเยอร์และ ตัวจําแนก convolutional ซึ่งมีเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ (หลังจากการโน้มน้าวใจออก) หากคุณต้องการพอร์ตรหัสนี้เพื่อใช้กับโมเดลของคุณที่ไม่มีการแยกดังกล่าวคุณเพียงแค่ต้องทำการแก้ไขบางส่วนที่เรียกว่า model.features และ model.classifier
ทุกเทคนิคมีไฟล์ Python ของตัวเอง (เช่น gradcam.py ) ซึ่งฉันหวังว่าจะทำให้สิ่งต่าง ๆ เข้าใจง่ายขึ้น MISC_FUNCTIONS.PY มีฟังก์ชั่นเช่นการประมวลผลภาพและการพักผ่อนหย่อนใจซึ่งใช้ร่วมกันโดยเทคนิคที่ใช้งาน
ภาพทั้งหมดถูกประมวลผลล่วงหน้าด้วยค่าเฉลี่ยและ std ของชุดข้อมูล Imagenet ก่อนที่จะถูกป้อนเข้ากับโมเดล ไม่มีรหัสใดที่ใช้ GPU เนื่องจากการดำเนินการเหล่านี้ค่อนข้างเร็วสำหรับภาพเดียว (ยกเว้นความฝันที่ลึกล้ำเนื่องจากภาพตัวอย่างที่ใช้สำหรับมันมีขนาดใหญ่) คุณสามารถใช้ประโยชน์จาก GPU ได้น้อยมาก ภาพตัวอย่างด้านล่างรวมตัวเลขในวงเล็บหลังจากคำอธิบายเช่น Mastiff (243) หมายเลขนี้แสดงถึง ID คลาสในชุดข้อมูล Imagenet
ฉันพยายามแสดงความคิดเห็นเกี่ยวกับรหัสให้มากที่สุดหากคุณมีปัญหาใด ๆ ที่เข้าใจหรือพอร์ตมันอย่าลังเลที่จะส่งอีเมลหรือสร้างปัญหา
ด้านล่างนี้เป็นตัวอย่างตัวอย่างสำหรับการดำเนินการแต่ละครั้ง
| Target Class: King Snake (56) | Target Class: Mastiff (243) | คลาสเป้าหมาย: แมงมุม (72) | |
| ภาพต้นฉบับ | |||
| backpropagation วานิลลาสี | |||
| วานิลลา backpropagation saliency | |||
| backpropagation สีนำทาง (GB) | |||
| มีการแนะนำ backpropagation (GB) | |||
| มีการแนะนำ backpropagation เชิงลบ (GB) | |||
| มีการแนะนำ backpropagation เชิงบวก (GB) | |||
| แผนที่การเปิดใช้งานระดับน้ำหนักการไล่ระดับสี (ผู้สำเร็จการศึกษา) | |||
| การเปิดใช้งานระดับความร้อนระดับความร้อน (ผู้สำเร็จการศึกษา) | |||
| การเปิดใช้งานระดับความร้อนระดับความร้อนบนภาพ (ผู้สำเร็จการศึกษา) | |||
| แผนที่การเปิดใช้งานระดับน้ำหนักถ่วงน้ำหนัก (คะแนน -CAM) | |||
| การเปิดใช้งานระดับความร้อนระดับน้ำหนัก (คะแนน -CAM) | |||
| การเปิดใช้งานระดับความร้อนระดับความร้อนบนภาพ (คะแนน -CAM) | |||
| แผนที่เปิดใช้งานระดับการไล่ระดับสี (Guided-grad-cam) | |||
| แผนที่การเปิดใช้งานระดับการไล่ระดับสีระดับไกด์ (Guided-grad-cam) | |||
| การไล่ระดับสีแบบบูรณาการ (โดยไม่ต้องคูณภาพ) | |||
| ความเกี่ยวข้องของเลเยอร์ (LRP) - เลเยอร์ 7 | |||
| ความเกี่ยวข้องของเลเยอร์ (LRP) - เลเยอร์ 1 |
Layercam [16] เป็นการปรับเปลี่ยนอย่างง่ายของ Grad-Cam [3] ซึ่งสามารถสร้างแผนที่การเปิดใช้งานคลาสที่เชื่อถือได้จากเลเยอร์ที่แตกต่างกัน สำหรับตัวอย่างที่ให้ไว้ด้านล่างใช้ VGG16 ที่ผ่านการฝึกอบรมมาแล้ว
| แผนที่เปิดใช้งานคลาส | การเปิดใช้งานระดับความร้อน | การเปิดใช้งานระดับความร้อนบนภาพ | |
| การวางตัว (เลเยอร์ 9) | 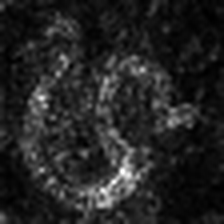 |  | 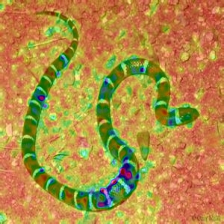 |
| การวางตัว (เลเยอร์ 16) |  | 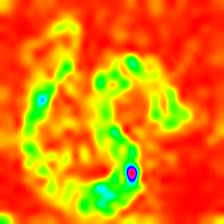 | 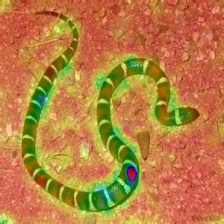 |
| การวางตัว (เลเยอร์ 23) | 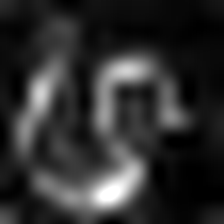 | 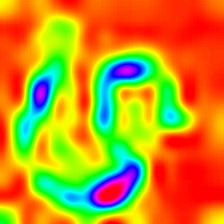 | 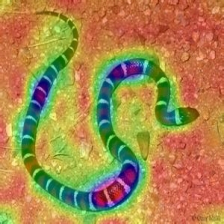 |
| การวางตัว (เลเยอร์ 30) |  | 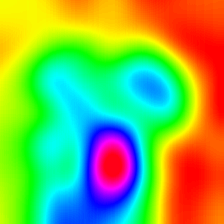 | 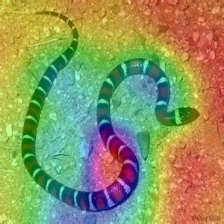 |
อีกเทคนิคหนึ่งที่เสนอคือการคูณการไล่ระดับสีด้วยตัวเอง ผลลัพธ์ที่ได้จากการใช้เทคนิคการไล่ระดับสีหลายอย่างด้านล่าง
| Vanilla Grad x ภาพ | |||
| ผู้สำเร็จการศึกษา x ภาพ | |||
| ผู้สำเร็จการศึกษาแบบบูรณาการ x ภาพ |
Smooth Grad กำลังเพิ่มเสียงรบกวนแบบเกาส์ลงในภาพต้นฉบับและการคำนวณการไล่ระดับสีหลายครั้งและเฉลี่ยผลลัพธ์ [8] มีสองตัวอย่างที่ด้านล่างซึ่งใช้ วานิลลา และ backpropagation ชี้นำ เพื่อคำนวณการไล่ระดับสี จำนวนภาพ ( n ) ถึงค่าเฉลี่ยมากกว่าจะถูกเลือกเป็น 50. σ แสดงที่ด้านล่างของภาพ
| วานิลลา backprop | ||
| backprop ชี้นำ | ||
ตัวกรอง CNN สามารถมองเห็นได้เมื่อเราปรับภาพอินพุตให้เหมาะสมกับเอาต์พุตของการดำเนินการ convolution เฉพาะ สำหรับตัวอย่างนี้ฉันใช้ VGG16 ที่ผ่านการฝึกอบรมมาก่อน การสร้างภาพของเลเยอร์เริ่มต้นด้วยตัวกรองสีและทิศทางพื้นฐานในระดับที่ต่ำกว่า ในขณะที่เราเข้าหาเลเยอร์สุดท้ายความซับซ้อนของตัวกรองก็เพิ่มขึ้นเช่นกัน หากคุณใช้เทคนิคภายนอกเช่นเบลอการตัดไล่ระดับสี ฯลฯ คุณอาจจะสร้างภาพที่ดีขึ้น
| เลเยอร์ 2 (Conv 1-2) | |||
| เลเยอร์ 10 (Conv 2-1) | |||
| เลเยอร์ 17 (Conv 3-1) | |||
| เลเยอร์ 24 (Conv 4-1) |
อีกวิธีหนึ่งในการแสดงภาพเลเยอร์ CNN คือการแสดงภาพการเปิดใช้งานสำหรับอินพุตเฉพาะในเลเยอร์และตัวกรองเฉพาะ สิ่งนี้ทำใน [1] รูปที่ 3 ตัวอย่างด้านล่างได้มาจากเลเยอร์/ตัวกรองของ VGG16 สำหรับภาพแรกโดยใช้ backpropagation แบบชี้นำ รหัสสำหรับการเปิดใช้งานนี้อยู่ใน layer_activation_with_guided_backprop.py วิธีนี้ค่อนข้างคล้ายกับ backpropagation ที่เป็นแนวทาง แต่แทนที่จะนำสัญญาณจากเลเยอร์สุดท้ายและเป้าหมายเฉพาะมันจะนำสัญญาณจากเลเยอร์และตัวกรองที่เฉพาะเจาะจง
| รูปภาพอินพุต | เลเยอร์ VIS (ตัวกรอง = 0) | ตัวกรอง VIS (เลเยอร์ = 29) |
ฉันคิดว่าเทคนิคนี้เป็นเทคนิคที่ซับซ้อนที่สุดในที่เก็บนี้ในแง่ของการทำความเข้าใจว่ารหัสทำอะไร ส่วนใหญ่เป็นเพราะการทำให้เป็นมาตรฐานที่ซับซ้อน หากคุณต้องการเข้าใจอย่างแท้จริงว่าสิ่งนี้ถูกนำไปใช้อย่างไรฉันขอแนะนำให้คุณอ่านหน้าที่สองและสามของกระดาษ [5] โดยเฉพาะส่วนการทำให้เป็นมาตรฐาน ที่นี่เป้าหมายคือการสร้างภาพต้นฉบับหลังจากเลเยอร์ n ยิ่งเราเข้าสู่โมเดลมากเท่าไหร่มันก็ยิ่งยากขึ้นเท่านั้น ผลลัพธ์ในกระดาษนั้นดีอย่างไม่น่าเชื่อ (ดูรูปที่ 6) แต่ที่นี่ผลลัพธ์จะกลายเป็นเรื่องยุ่ง ๆ เมื่อเราวนซ้ำผ่านเลเยอร์ นี่เป็นเพราะผู้เขียนกระดาษปรับพารามิเตอร์สำหรับแต่ละชั้นแต่ละชั้น คุณสามารถปรับพารามิเตอร์เช่นเดียวกับที่ได้รับในกระดาษเพื่อเพิ่มประสิทธิภาพผลลัพธ์สำหรับแต่ละเลเยอร์ ตัวอย่างคว่ำจาก Alexnet หลายชั้นพร้อมรูปภาพ งู ก่อนหน้านี้อยู่ด้านล่าง
| เลเยอร์ 0: conv2d | เลเยอร์ 2: MaxPool2D | เลเยอร์ 4: Relu |
| เลเยอร์ 7: Relu | เลเยอร์ 9: Relu | เลเยอร์ 12: MaxPool2D |
Deep Dream เป็นเทคนิคการดำเนินการเดียวกันกับการสร้างภาพเลเยอร์ความแตกต่างเพียงอย่างเดียวคือคุณไม่ได้เริ่มต้นด้วยภาพสุ่ม แต่ใช้ภาพจริง ตัวอย่างด้านล่างถูกสร้างขึ้นด้วย VGG19 ผลลัพธ์ที่ผลิตขึ้นอยู่กับตัวกรองทั้งหมดดังนั้นจึงเป็นเพลงฮิตหรือพลาด รุ่นที่ซับซ้อนมากขึ้นสร้างคุณสมบัติระดับสูงของโหมด หากคุณแทนที่ VGG19 ด้วยตัวแปร Inception คุณจะได้รับรูปร่างที่เห็นได้ชัดเจนมากขึ้นเมื่อคุณกำหนดเป้าหมายเลเยอร์ความสัมพันธ์ที่สูงขึ้น เช่นการสร้างภาพเลเยอร์หากคุณใช้เทคนิคเพิ่มเติมเช่นการตัดไล่ระดับสีการเบลอ ฯลฯ คุณอาจได้รับการสร้างภาพที่ดีขึ้น
| ภาพต้นฉบับ | |
| VGG19 เลเยอร์: 34 (เลเยอร์ความเชื่อมั่นสุดท้าย) ตัวกรอง: 94 | |
| VGG19 เลเยอร์: 34 ตัวกรอง (Final Conv. Layer): 103 |
การดำเนินการนี้สร้างผลลัพธ์ที่แตกต่างกันตามโมเดลและวิธีการทำให้เป็นมาตรฐานที่ใช้ ด้านล่างนี้มีตัวอย่างบางส่วนที่ผลิตด้วย VGG19 ที่รวมอยู่ด้วย Gaussian Blur ทุกครั้ง (ดู [14] สำหรับรายละเอียด) คุณภาพของภาพที่สร้างขึ้นนั้นขึ้นอยู่กับแบบจำลองโดยทั่วไป Alexnet มีสิ่งประดิษฐ์สีเขียว (ish) แต่ VGGs ผลิตภาพที่ดีกว่า (ชนิด) โปรดทราบว่าภาพเหล่านี้ถูกสร้างขึ้นด้วย CNN ปกติด้วยการเพิ่มประสิทธิภาพอินพุตและ ไม่ได้อยู่กับ GANS
| Target Class: Worm Snake (52) - (VGG19) | คลาสเป้าหมาย: แมงมุม (72) - (VGG19) |
ตัวอย่างด้านล่างแสดงภาพที่ผลิตโดยไม่มีการทำให้เป็นมาตรฐาน L1 และ L2 เป็นมาตรฐานในคลาสเป้าหมาย: ฟลามิงโก (130) เพื่อแสดงความแตกต่างระหว่างวิธีการทำให้เป็นปกติ ภาพเหล่านี้ถูกสร้างขึ้นด้วย Alexnet ที่ได้รับการฝึกฝน
| ไม่มีการทำให้เป็นมาตรฐาน | การทำให้เป็นมาตรฐาน L1 | การทำให้เป็นมาตรฐาน L2 |
ตัวอย่างที่ผลิตสามารถปรับให้เหมาะสมต่อไปเพื่อให้คล้ายกับคลาสเป้าหมายที่ต้องการการดำเนินการบางอย่างที่คุณสามารถรวมเพื่อปรับปรุงคุณภาพคือ; เบลอการไล่ระดับสีที่ต่ำกว่าการแลกเปลี่ยนสีแบบสุ่มบางส่วนในบางส่วนการปลูกถ่ายภาพแบบสุ่มบังคับให้ภาพที่สร้างขึ้นเพื่อติดตามเส้นทางเพื่อบังคับความต่อเนื่อง
เทคนิคเหล่านี้บางส่วนถูกนำไปใช้ใน generate_regularized_class_specific_samples.py (ความอนุเคราะห์จาก Alexstoken)
torch == 0.4.1
torchvision >= 0.1.9
numpy >= 1.13.0
matplotlib >= 1.5
PIL >= 1.1.7
หากคุณพบรหัสในที่เก็บนี้มีประโยชน์สำหรับการวิจัยของคุณให้พิจารณาอ้างถึง
@misc{uozbulak_pytorch_vis_2022,
author = {Utku Ozbulak},
title = {PyTorch CNN Visualizations},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/utkuozbulak/pytorch-cnn-visualizations}},
commit = {b7e60adaf64c9be97b480509285718603d1e9ba4}
}
[1] JT Springenberg, A. Dosovitskiy, T. Brox และ M. Riedmiller การดิ้นรนเพื่อความเรียบง่าย: NET ทั้งหมด , https://arxiv.org/abs/1412.6806
[2] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, A. Torralba การเรียนรู้คุณสมบัติที่ลึกซึ้งสำหรับการเลือกปฏิบัติ https://arxiv.org/abs/1512.04150
[3] RR Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh และ D. Batra Grad-CAM: คำอธิบายภาพจากเครือข่ายลึกผ่านการแปลตามการไล่ระดับสี https://arxiv.org/abs/1610.02391
[4] K. Simonyan, A. Vedaldi, A. Zisserman ลึกลงไปในเครือข่าย convolutional: การแสดงภาพโมเดลการจำแนกภาพและแผนที่ความสามารถพิเศษ , https://arxiv.org/abs/1312.6034
[5] A. Mahendran, A. Vedaldi ทำความเข้าใจกับการเป็นตัวแทนภาพลึกโดยการคว่ำพวกเขา https://arxiv.org/abs/1412.0035
[6] H. Noh, S. Hong, B. Han, การเรียนรู้ Deconvolution Network สำหรับการแบ่งส่วนความหมาย
[7] A. Nguyen, J. Yosinski, J. Clune เครือข่ายประสาทลึกถูกหลอกได้ง่าย: การทำนายความมั่นใจสูงสำหรับภาพที่ไม่สามารถจดจำได้ https://arxiv.org/abs/1412.1897
[8] D. Smilkov, N. Thorat, N. Kim, F. Viégas, M. Wattenberg SmoothGrad: ลบเสียงรบกวนโดยการเพิ่มเสียงรบกวน https://arxiv.org/abs/1706.03825
[9] D. Erhan, Y. Bengio, A. Courville, P. Vincent การแสดงคุณสมบัติชั้นสูงของเลเยอร์ของเครือข่ายลึก https://www.researchgate.net/publication/265022827_visualizing_higher-layer_features_of_a_deep_network
[10] A. Mordvintsev, C. Olah, M. Tyka Inceptionism: ลึกลงไปในเครือข่ายประสาท
[11] IJ Goodfellow, J. Shlens, C. Szegedy การอธิบายและควบคุมตัวอย่างที่เป็นปฏิปักษ์ https://arxiv.org/abs/1412.6572
[12] A. Shrikumar, P. Greenside, A. Shcherbina, A. Kundaje ไม่ใช่แค่กล่องดำ: การเรียนรู้คุณสมบัติที่สำคัญผ่านการเผยแพร่ความแตกต่างการเปิดใช้งาน https://arxiv.org/abs/1605.01713
[13] M. Sundararajan, A. Taly, Q. Yan การระบุแหล่งที่มาของ Axiomatic สำหรับเครือข่ายลึก https://arxiv.org/abs/1703.01365
[14] J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, Hod Lipson, การทำความเข้าใจเครือข่ายประสาทผ่านการสร้างภาพข้อมูลลึก https://arxiv.org/abs/1506.06579
[15] H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, X. Hu คะแนน -CAM: คำอธิบายภาพที่มีน้ำหนักมากสำหรับเครือข่ายประสาทสัมผัส https://arxiv.org/abs/1910.01279
[16] P. Jiang, C. Zhang, Q. Hou, M. Cheng, Y. Wei layercam: การสำรวจแผนที่การเปิดใช้งานระดับลำดับชั้นสำหรับการแปล http://mmcheng.net/mftp/papers/21tip_layercam.pdf
[17] G. Montavon1, A. Binder, S. Lapuschkin, W. Samek และ K. Muller การแพร่กระจายความเกี่ยวข้องของเลเยอร์: ภาพรวม https://www.researchgate.net/publication/335708351_layer-vise_relevance_propagation_an_overview


