pytorch cnn visualizations
1.0.0
يحتوي هذا المستودع على عدد من تقنيات تصور الشبكة العصبية التلافيفية التي تم تنفيذها في Pytorch.
ملاحظة : أزلت تبعيات CV2 ونقلت المستودع نحو PIL. قد يتم كسر بعض الأشياء (على الرغم من أنني اختبرت جميع الطرق) ، وسأكون ممتناً إذا كان بإمكانك إنشاء مشكلة إذا لم ينجح شيء ما.
ملاحظة : تم اختبار الرمز في هذا المستودع باستخدام الإصدار الشعلة 0.4.1 وقد لا تعمل بعض الوظائف كما هو مخصص في الإصدارات اللاحقة. على الرغم من أنه لا ينبغي أن يكون هناك جهد كبير لجعله يعمل ، إلا أنه ليس لدي أي خطط في الوقت الحالي لجعل الرمز في هذا المستودع متوافقًا مع أحدث إصدار لأنني ما زلت أستخدم 0.4.1.
اعتمادًا على هذه التقنية ، يستخدم الرمز Alexnet أو VGG المسبق من حديقة الحيوان النموذجية. تفترض بعض الكود أيضًا أن الطبقات في النموذج يتم فصلها إلى قسمين ؛ الميزات ، التي تحتوي على الطبقات التلافيفية والمصنف ، التي تحتوي على الطبقة المتصلة بالكامل (بعد تسطيح الملاحظات). إذا كنت ترغب في نقل هذا الرمز لاستخدامه في النموذج الخاص بك والذي لا يحتوي على مثل هذا الفصل ، فأنت بحاجة فقط إلى إجراء بعض التحرير على الأجزاء التي يستدعيها نموذجًا .
كل تقنية لها ملف Python الخاص به (على سبيل المثال GradCam.py ) والذي آمل أن يجعل الأمور أسهل في فهمها. Misc_functions.py يحتوي على وظائف مثل معالجة الصور والترفيه الذي تتم مشاركته بواسطة التقنيات التي تم تنفيذها.
يتم تجهيز جميع الصور مسبقًا بمتوسط و std من مجموعة بيانات ImageNet قبل تغذية النموذج. لا يستخدم أي من التعليمات البرمجية GPU لأن هذه العمليات سريعة جدًا لصورة واحدة (باستثناء الحلم العميق بسبب مثال الصورة المستخدمة لها). يمكنك الاستفادة من وحدة معالجة الرسومات مع القليل من الجهد. تتضمن الصور المثال أدناه أرقامًا في الأقواس بعد الوصف ، مثل Mastiff (243) ، ويمثل هذا الرقم معرف الفئة في مجموعة بيانات ImageNet.
حاولت التعليق على الرمز قدر الإمكان ، إذا كان لديك أي مشكلات في فهمها أو تنقلها ، فلا تتردد في إرسال بريد إلكتروني أو إنشاء مشكلة.
أدناه ، بعض نتائج العينة لكل عملية.
| الفصل الهدف: King Snake (56) | فئة الهدف: Mastiff (243) | فئة الهدف: العنكبوت (72) | |
| الصورة الأصلية | |||
| ملون الفانيليا backpropagation | |||
| الفانيليا الخلفية الملاءمة | |||
| الملونة الموجه الخلفية (GB) | |||
| إرشاد ترشيد الخلفية (GB) | |||
| إرشاد الإرشاد السلبي المرشد (GB) | |||
| إرشاد الإرشاد الإرشادي الإيجابي (GB) | |||
| خريطة تنشيط الطبقة المرجحة التدرج (Grad-Cam) | |||
| خريطة تنشيط فئة مرجحة التدرج (Grad-Cam) | |||
| خريطة تنشيط فئة مرجحة على الصورة على الصورة (Grad-Cam) | |||
| خريطة تنشيط فئة مرجحة من الدرجة (كاميرا النتيجة) | |||
| خريطة تنشيط فئة مرجحة من الدرجة (كاميرا النتيجة) | |||
| تنشيط فئة مرجحة على الصورة على الصورة (كاميرا النتيجة) | |||
| خريطة تنشيط الطبقة المرشحة المرشحة الملونة (كاميرا الدرجات المرشدة) | |||
| خريطة تنشيط فئة مرجحة مرشدين. (كاميرا الدرجات المرشدة) | |||
| التدرجات المتكاملة (بدون تكاثر الصورة) | |||
| صلة الطبقة (LRP) - الطبقة 7 | |||
| صلة الطبقة (LRP) - الطبقة 1 |
Layercam [16] هو تعديل بسيط لـ Grad-Cam [3] ، والذي يمكن أن يولد خرائط تنشيط فئة موثوقة من طبقات مختلفة. بالنسبة للأمثلة الواردة أدناه ، تم استخدام VGG16 المدربة مسبقًا.
| خريطة تنشيط الفصل | تنشيط الفئة خريطة الحرارة | تنشيط الفئة خريطة الحرارة على الصورة | |
| لايركام (الطبقة 9) | 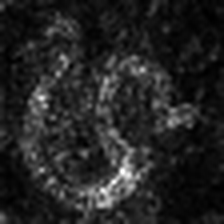 |  |  |
| لايركام (الطبقة 16) |  | 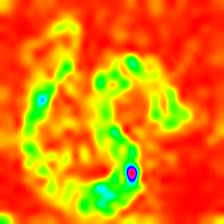 |  |
| لايركام (الطبقة 23) | 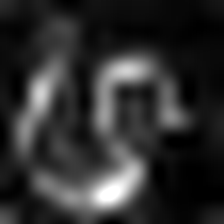 | 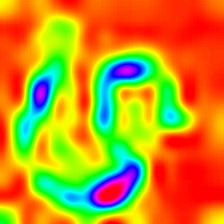 | 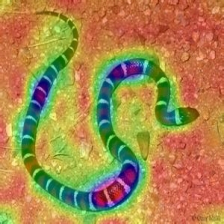 |
| لايركام (الطبقة 30) |  | 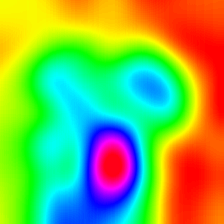 | 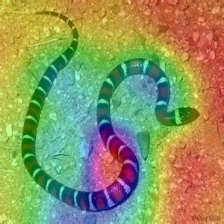 |
تقنية أخرى مقترحة هي ببساطة ضرب التدرجات مع الصورة نفسها. النتائج التي تم الحصول عليها مع استخدام تقنيات التدرج المتعددة أدناه.
| فانيليا غراد x صورة | |||
| جراد موجه x صورة | |||
| خريج متكامل x صورة |
يقوم Grad السلس بإضافة بعض الضوضاء الغوسية إلى الصورة الأصلية وحساب التدرجات عدة مرات ومتوسط النتائج [8]. هناك مثالان في الجزء السفلي يستخدمان الفانيليا وترشيدات الخلفية الموجه لحساب التدرجات. يتم تحديد عدد الصور ( n ) إلى المتوسط أكثر من 50. σ يظهر في أسفل الصور.
| الفانيليا Backprop | ||
| Backprop الموجه | ||
يمكن تصور مرشحات CNN عندما نحسن صورة الإدخال فيما يتعلق بإخراج عملية التوافق المحددة. في هذا المثال ، استخدمت VGG16 المدربة مسبقًا. تبدأ تصورات الطبقات مع مرشحات اللون والاتجاه الأساسية في مستويات أقل. مع اقترابنا من الطبقة النهائية ، يزداد تعقيد المرشحات أيضًا. إذا كنت تستخدم تقنيات خارجية مثل عدم وضوح ، فإن القطع التدرج وما إلى ذلك ، فمن المحتمل أن تنتج صورًا أفضل.
| الطبقة 2 (مقنع 1-2) | |||
| الطبقة 10 (مقنع 2-1) | |||
| الطبقة 17 (مقنع 3-1) | |||
| الطبقة 24 (مقنع 4-1) |
هناك طريقة أخرى لتصور طبقات CNN وهي تصور عمليات التنشيط لإدخال محدد على طبقة ومرشح معين. وقد تم ذلك في [1] الشكل 3. تم الحصول على مثال أدناه من طبقات/مرشحات VGG16 للصورة الأولى باستخدام backpropagation الموجهة. رمز هذا opeations في layer_activation_with_guided_backprop.py . تتشابه هذه الطريقة تمامًا مع تربية الخلفية الموجه ، ولكن بدلاً من توجيه الإشارة من الطبقة الأخيرة وهدف معين ، فإنه يوجه الإشارة من طبقة ومرشح محددة.
| إدخال صورة | طبقة فيس. (مرشح = 0) | تصفية فيس. (الطبقة = 29) |
أعتقد أن هذه التقنية هي التقنية الأكثر تعقيدًا في هذا المستودع من حيث فهم ما يفعله الرمز. ويرجع ذلك أساسا إلى التنظيم المعقد. إذا كنت تريد حقًا أن تفهم كيف يتم تنفيذ ذلك ، أقترح عليك قراءة الصفحة الثانية والثالثة من الورقة [5] ، على وجه التحديد ، جزء التنظيم. هنا ، الهدف هو إنشاء صورة أصلية بعد الطبقة التاسعة. كلما ذهبنا إلى النموذج ، كلما أصبح الأمر أكثر صعوبة. النتائج في الورقة جيدة بشكل لا يصدق (انظر الشكل 6) ولكن هنا ، تصبح النتيجة بسرعة فوضوية ونحن نتكرر من خلال الطبقات. وذلك لأن مؤلفي الورق قاموا بضبط المعلمات لكل طبقة بشكل فردي. يمكنك ضبط المعلمات تمامًا مثل تلك التي يتم تقديمها في الورقة لتحسين النتائج لكل طبقة. توجد أمثلة مقلوبة من عدة طبقات من Alexnet مع صورة الأفعى السابقة أدناه.
| الطبقة 0: Conv2d | الطبقة 2: maxpool2d | الطبقة 4: RELU |
| الطبقة 7: RELU | الطبقة 9: RELU | الطبقة 12: maxpool2d |
الحلم العميق هو من الناحية الفنية نفس العملية مثل التصور للطبقة ، والفرق الوحيد هو أنك لا تبدأ بصورة عشوائية ولكن استخدم صورة حقيقية. تم إنشاء العينات أدناه باستخدام VGG19 ، والنتيجة المنتجة تصل تمامًا إلى المرشح بحيث يكون نوعًا من الضرب أو التفويت. تنتج النماذج الأكثر تعقيدًا ميزات عالية المستوى. إذا قمت باستبدال VGG19 بمتغير بدء ، فستحصل على أشكال أكثر وضوحًا عند استهداف طبقات مقنعة أعلى. مثل تصور الطبقة ، إذا كنت تستخدم تقنيات إضافية مثل القطع التدرج ، واضطراب ، إلخ. قد تحصل على تصورات أفضل.
| الصورة الأصلية | |
| VGG19 الطبقة: 34 (مقنع النهائي طبقة) مرشح: 94 | |
| VGG19 الطبقة: 34 (مقنع النهائي طبقة) مرشح: 103 |
تنتج هذه العملية مخرجات مختلفة بناءً على النموذج وطريقة التنظيم المطبقة. فيما يلي بعض العينات التي تم إنتاجها مع VGG19 مدمجة مع طمس غاوسي كل تكرار آخر (انظر [14] للحصول على التفاصيل). تعتمد جودة الصور التي تم إنشاؤها أيضًا على النموذج ، حيث تحتوي Alexnet عمومًا على قطع أثرية خضراء (ISH) ولكن VGGs تنتج (نوع) صور أفضل. لاحظ أن هذه الصور يتم إنشاؤها باستخدام CNNs العادية مع تحسين الإدخال وليس مع Gans .
| فئة الهدف: ثعبان الدودة (52) - (VGG19) | فئة الهدف: Spider (72) - (VGG19) |
تُظهر العينات أدناه الصورة المنتجة بدون تنظيم ، تنظيم L1 و L2 على الفئة المستهدفة: Flamingo (130) لإظهار الاختلافات بين طرق التنظيم. يتم إنشاء هذه الصور مع أليكسنيت مسبق.
| لا التنظيم | تنظيم L1 | L2 تنظيم |
يمكن تحسين العينات المنتجة لتشبه الفئة المستهدفة المطلوبة ، بعض العمليات التي يمكنك دمجها لتحسين الجودة ؛ غير واضحة ، تقطيع التدرجات التي تقل عن مشكلات ألوان عشوائية معينة ، على بعض الأجزاء ، اقتصاص الصورة العشوائية ، مما يفرض صورة تم إنشاؤها على اتباع مسار لقوة الاستمرارية.
يتم تنفيذ بعض هذه التقنيات في cenert_regularized_class_specific_samples.py (من باب المجاملة AlexStoken).
torch == 0.4.1
torchvision >= 0.1.9
numpy >= 1.13.0
matplotlib >= 1.5
PIL >= 1.1.7
إذا وجدت الرمز في هذا المستودع مفيدًا لبحثك ، ففكر في الإشارة إليه.
@misc{uozbulak_pytorch_vis_2022,
author = {Utku Ozbulak},
title = {PyTorch CNN Visualizations},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/utkuozbulak/pytorch-cnn-visualizations}},
commit = {b7e60adaf64c9be97b480509285718603d1e9ba4}
}
[1] JT Springenberg ، A. Dosovitskiy ، T. Brox ، and M. Riedmiller. السعي لتحقيق البساطة: الشبكة التلافيفية ، https://arxiv.org/abs/1412.6806
[2] B. Zhou ، A. Khosla ، A. Lapedriza ، A. Oliva ، A. Torralba. تعلم ميزات عميقة للتوطين التمييزي ، https://arxiv.org/abs/1512.04150
[3] RR Selvaraju ، A. Das ، R. Vedantam ، M. Cogswell ، D. Parikh ، and D. Batra. Grad-Cam: تفسيرات مرئية من الشبكات العميقة عبر التعريب القائم على التدرج ، https://arxiv.org/abs/1610.02391
[4] K. Simonyan ، A. Vedaldi ، A. Zisserman. الشبكات التلافيفية العميقة: تصور نماذج تصنيف الصور وخرائط الملاءمة ، https://arxiv.org/abs/1312.6034
[5] أ. ماهيندران ، أ. فيدالدي. فهم تمثيلات الصور العميقة عن طريق قلبها ، https://arxiv.org/abs/1412.0035
[6] H. Noh ، S. Hong ، B. Han ، شبكة التعلم الشبكة للتجزئة الدلالية https://www.cv-
[7] A. Nguyen ، J. Yosinski ، J. Clune. يتم خداع الشبكات العصبية العميقة بسهولة: تنبؤات عالية الثقة للصور التي لا يمكن التعرف عليها https://arxiv.org/abs/1412.1897
[8] D. Smilkov ، N. Thorat ، N. Kim ، F. Viégas ، M. Wattenberg. SmoothGrad: إزالة الضوضاء عن طريق إضافة الضوضاء https://arxiv.org/abs/1706.03825
[9] D. Erhan ، Y. Bengio ، A. Courville ، P. Vincent. تصور الميزات ذات الطبقة العليا للشبكة العميقة https://www.researchgate.net/publication/265022827_visualizing_higher-layer_features_of_a_deep_network
[10] A. Mordvintsev ، C. Olah ، M. Tyka. التأسيس: الانتقال إلى الشبكات العصبية https://research.googleblog.com/2015/06/inceptionism-deeper-into-neural.html
[11] IJ Goodfellow ، J. Shlens ، C. Szegedy. شرح وتسخير أمثلة الخصومة https://arxiv.org/abs/1412.6572
[12] A. Shrikumar ، P. Greenside ، A. Shcherbina ، A. Kundaje. ليس مجرد مربع أسود: تعلم ميزات مهمة من خلال نشر الاختلافات التنشيط https://arxiv.org/abs/1605.01713
[13] M. Sundararajan ، A. Taly ، Q. Yan. الإسناد البديهي للشبكات العميقة https://arxiv.org/abs/1703.01365
[14] J. Yosinski ، J. Clune ، A. Nguyen ، T. Fuchs ، Hod Lipson ، فهم الشبكات العصبية من خلال التصور العميق https://arxiv.org/abs/1506.06579
[15] H. Wang ، Z. Wang ، M. Du ، F. Yang ، Z. Zhang ، S. Ding ، P. Mardziel ، X. Hu. نقاط النتيجة: تفسيرات بصرية مرتفعة للشبكات العصبية التلافيفية https://arxiv.org/abs/1910.01279
[16] P. Jiang ، C. Zhang ، Q. Hou ، M. Cheng ، Y. Wei. Layercam: استكشاف خرائط تنشيط الفئة الهرمية للتوطين http://mmcheng.net/mftp/papers/21tip_layercam.pdf
[17] G. Montavon1 ، A. Binder ، S. Lapuschkin ، W. Samek ، and K. Muller. انتشار صلة الطبقة: نظرة عامة https://www.researchgate.net/publication/335708351_layer-wise_relevance_propagation_an_overview


