pytorch cnn visualizations
1.0.0
このリポジトリには、Pytorchで実装されている多くの畳み込みニューラルネットワーク視覚化技術が含まれています。
注:CV2依存関係を削除し、リポジトリをPILに移動しました。いくつかのことが壊れている可能性があります(すべての方法をテストしましたが)、何かが機能しない場合に問題を作成できれば感謝します。
注:このリポジトリのコードは、Torchバージョン0.4.1でテストされ、一部の関数は後のバージョンで意図したように機能しない場合があります。それを機能させるための努力はそれほど多くないはずですが、現在0.4.1を使用しているため、このリポジトリのコードを最新バージョンと互換性のあるコードにする計画はありません。
この手法に応じて、コードはモデル動物園の前提条件のAlexNetまたはVGGを使用します。コードの一部は、モデル内のレイヤーが2つのセクションに分離されていることも想定しています。畳み込み層と分類器を含む機能には、完全に接続された層が含まれています(畳み込みをフラットアウトした後)。このような分離がないモデルで使用するためにこのコードを移植する場合は、 model.features and model.classifierを呼び出すパーツで編集を行う必要があります。
すべての手法には、独自のPythonファイル( Gradcam.pyなど)があり、物事が理解しやすくなることを願っています。 MISC_FUNCTIONS.PYには、実装された手法で共有される画像処理や画像レクリエーションなどの関数が含まれています。
すべての画像は、モデルに供給される前に、Imagenetデータセットの平均とSTDで前処理されます。これらの操作は単一の画像では非常に高速であるため、コードはGPUを使用していません(使用される画像の例が大きいため、Deep Dreamを除く)。 GPUをごくわずかに努力できます。以下の写真の例には、 Mastiff(243)のような説明の後の括弧内の数字が含まれています。この番号は、ImagenetデータセットのクラスIDを表します。
コードについてできる限りコメントしようとしました。あなたがそれを理解したり移植したりする問題がある場合は、メールを送信したり、問題を作成したりすることをheしないでください。
以下に、各操作のサンプル結果をいくつか示します。
| ターゲットクラス:キングスネーク(56) | ターゲットクラス:マスティフ(243) | ターゲットクラス:スパイダー(72) | |
| 元の画像 | |||
| 色付きのバニラバックプロパゲーション | |||
| バニラバックプロパゲーションの顕著性 | |||
| 色付きのガイド付きバックプロパゲーション (GB) | |||
| ガイド付きバックプロパゲーションの顕著性 (GB) | |||
| ガイド付きバックプロパゲーション否定的顕著性 (GB) | |||
| ガイド付きバックプロパゲーションポジティブな顕著性 (GB) | |||
| 勾配加重クラスアクティベーションマップ (Grad-Cam) | |||
| 勾配加重クラス活性化ヒートマップ (Grad-Cam) | |||
| 画像上の勾配加重クラスの活性化ヒートマップ (Grad-Cam) | |||
| スコア加重クラスアクティベーションマップ (スコアカム) | |||
| スコア加重クラスアクティベーションヒートマップ (スコアカム) | |||
| 画像上のスコア加重クラスアクティベーションヒートマップ (スコアカム) | |||
| 色付きの勾配勾配加重クラスアクティベーションマップ (ガイド付きグラードカム) | |||
| ガイド付きグラデーション加重クラスアクティベーションマップの顕著性 (ガイド付きグラードカム) | |||
| 統合された勾配 (画像の乗算なし) | |||
| 層状の関連性 (LRP) - レイヤー7 | |||
| 層状の関連性 (LRP) - レイヤー1 |
LayerCam [16]は、グラッカム[3]の単純な変更であり、異なるレイヤーから信頼できるクラスアクティベーションマップを生成できます。以下に示す例では、事前に訓練されたVGG16が使用されました。
| クラスアクティベーションマップ | クラスアクティベーションヒートマップ | 画像上のクラスアクティベーションヒートマップ | |
| layercam (レイヤー9) | 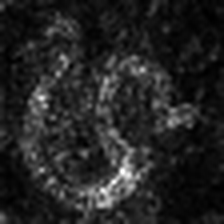 |  |  |
| layercam (レイヤー16) |  | 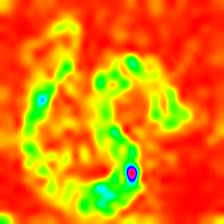 |  |
| layercam (レイヤー23) |  | 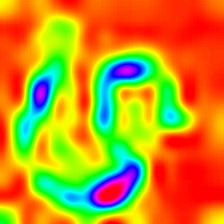 | 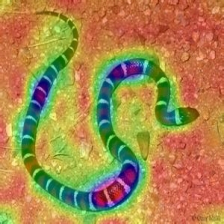 |
| layercam (レイヤー30) |  |  | 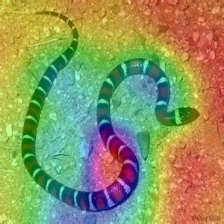 |
提案されているもう1つの手法は、勾配に画像自体を掛けるだけです。複数の勾配技術の使用で得られた結果は以下にあります。
| バニラ卒業生 x 画像 | |||
| ガイド付き卒業生 x 画像 | |||
| 統合卒業生 x 画像 |
滑らかなグレードは、元の画像にガウスノイズを追加し、勾配を複数回計算し、結果を平均化しています[8]。下部には、勾配を計算するためにバニラとガイド付きバックプロパゲーションを使用する2つの例があります。画像の数( n )から平均オーバーが選択されます。50。σは画像の下部に表示されます。
| バニラバックプロップ | ||
| ガイド付きバックプロップ | ||
CNNフィルターは、特定の畳み込み操作の出力に関して入力画像を最適化するときに視覚化できます。この例では、事前に訓練されたVGG16を使用しました。層の視覚化は、より低いレベルの基本的な色と方向フィルターから始まります。最終層に向かって近づくと、フィルターの複雑さも増加します。ぼかし、グラデーションのクリッピングなどの外部技術を使用すると、おそらくより良い画像を作成するでしょう。
| レイヤー2 (Conv 1-2) | |||
| レイヤー10 (Conv 2-1) | |||
| レイヤー17 (CONP3-1) | |||
| レイヤー24 (CONP4-1) |
CNN層を視覚化する別の方法は、特定のレイヤーとフィルターの特定の入力のアクティベーションを視覚化することです。これは[1]図3で行われました。以下の例は、ガイド付きバックプロパゲーションを使用して最初の画像のVGG16のレイヤー/フィルターから取得されます。この視聴のコードは、 layer_activation_with_guided_backprop.pyにあります。この方法は、ガイド付きバックプロパゲーションに非常に似ていますが、最後のレイヤーと特定のターゲットから信号をガイドする代わりに、特定のレイヤーとフィルターから信号をガイドします。
| 入力画像 | レイヤーVIS。 (フィルター= 0) | フィルターVIS。 (layer = 29) |
この手法は、コードが何をするかを理解するという点で、このリポジトリで最も複雑な手法だと思います。これは主に複雑な正則化が原因です。これがどのように実装されているかを本当に理解したい場合は、論文[5]の2番目と3番目のページ、具体的には正規化部分を読むことをお勧めします。ここで、目的は、NTH層の後に元の画像を生成することです。さらにモデルに入るほど、難しくなります。論文の結果は非常に優れています(図6を参照)が、ここでは、レイヤーを繰り返すと結果がすぐに乱雑になります。これは、論文の著者が各レイヤーのパラメーターを個別に調整したためです。各レイヤーの結果を最適化するために、ペーパーに記載されているものと同じようにパラメーターを調整できます。前のヘビの写真を備えたアレックスネットのいくつかの層からの逆の例は以下にあります。
| レイヤー0: CONV2D | レイヤー2: maxpool2d | レイヤー4: relu |
| レイヤー7: relu | レイヤー9: Relu | レイヤー12: maxpool2d |
Deep Dreamは技術的にはレイヤーの視覚化と同じ操作です唯一の違いは、ランダムな画像から始めず、実際の画像を使用することです。以下のサンプルはVGG19で作成され、生成された結果は完全にフィルター次第であるため、一種のヒットまたはミスです。より複雑なモデルは、モードの高レベルの機能を生成します。 VGG19をInceptionバリアントに置き換えると、より高いCONVレイヤーをターゲットにすると、より顕著な形状が得られます。レイヤーの視覚化と同様に、グラデーションクリッピング、ぼやけなどの追加手法を使用すると、より良い視覚化が得られる可能性があります。
| 元の画像 | |
| VGG19 レイヤー:34 (FinalConv。Layer)フィルター:94 | |
| VGG19 レイヤー:34 (FinalConv。Layer)フィルター:103 |
この操作は、モデルと適用された正規化方法に基づいて異なる出力を生成します。以下は、他のすべての反復をガウスブルールに組み込んだVGG19で生成されたいくつかのサンプルです(詳細については[14]を参照)。生成された画像の品質はモデルにも依存し、 Alexnetには一般に緑(ISH)アーティファクトがありますが、VGGはより良い画像を生成します。これらの画像は、GANではなく入力を最適化する通常のCNNで生成されることに注意してください。
| ターゲットクラス:ワームヘビ(52) - (VGG19) | ターゲットクラス:スパイダー(72) - (VGG19) |
以下のサンプルは、正規化なしの生成された画像、ターゲットクラスのL1およびL2の正則化を示しています: Flamingo (130)は、正規化方法の違いを示しています。これらの画像は、前提条件のAlexNetで生成されます。
| 正則化はありません | L1正規化 | L2正規化 |
生産されたサンプルは、より品質を改善するために組み込まれる操作の一部に似ているために、より最適化できます。特定のトレションドの下にあるぼやけ、クリッピンググラデーション、一部の部分でのランダムな色スワップ、画像のランダムなカラースワップ、生成された画像に強制的な連続性を強制するように強制します。
これらの手法のいくつかは、 Generate_ returized_class_specific_samples.py (Alexstokenの厚意により)で実装されています。
torch == 0.4.1
torchvision >= 0.1.9
numpy >= 1.13.0
matplotlib >= 1.5
PIL >= 1.1.7
このリポジトリのコードがあなたの研究に役立つと思う場合は、それを引用することを検討してください。
@misc{uozbulak_pytorch_vis_2022,
author = {Utku Ozbulak},
title = {PyTorch CNN Visualizations},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/utkuozbulak/pytorch-cnn-visualizations}},
commit = {b7e60adaf64c9be97b480509285718603d1e9ba4}
}
[1] JT Springenberg、A。Dosovitskiy、T。Brox、およびM. Riedmiller。シンプルさを求めて努力:すべての畳み込みネット、https://arxiv.org/abs/1412.6806
[2] B. Zhou、A。Khosla、A。Lapedriza、A。Oliva、A。Torralba。識別ローカリゼーションのための深い機能の学習、https://arxiv.org/abs/1512.04150
[3] Rr Selvaraju、A。Das、R。Vedantam、M。Cogswell、D。Parikh、およびD. Batra。 Grad-Cam:グラデーションベースのローカリゼーションを介したディープネットワークからの視覚的説明、https://arxiv.org/abs/1610.02391
[4] K. Simonyan、A。Vedaldi、A。Zisserman。内側の畳み込みネットワークの奥深く:画像分類モデルと顕著性マップを視覚化する、https://arxiv.org/abs/1312.6034
[5] A.マヘンドラン、A。ヴェダルディ。 https://arxiv.org/abs/1412.0035を反転させることにより、深い画像表現を理解します
[6] H. Noh、S。Hong、B。Han、セマンティックセグメンテーションのためのデコンボリューションネットワークの学習https://www.cv-foundation.org/papers/noh_learning_deconvolution_netwark_iccv_2015_paper.pdf.pdf.pdf.pdf
[7] A. Nguyen、J。Yosinski、J。Clune。深いニューラルネットワークは簡単にだまされます:認識できない画像の高い自信の予測https://arxiv.org/abs/1412.1897
[8] D. Smilkov、N。Thorat、N。Kim、F。Viégas、M。Wattenberg。スムーズグラード:ノイズhttps://arxiv.org/abs/1706.03825を追加してノイズを削除します
[9] D. Erhan、Y。Bengio、A。Courville、P。Vincent 。ディープネットワークの高層機能の視覚化https://www.researchgate.net/publication/265022827_visualizing_higher-layer_features_of_a_deep_network
[10] A. Mordvintsev、C。Olah、M。Tyka。 Inceptionism:Neural Networks https://research.googleblog.com/2015/06/inceptionism-deeper-into-neural.html
[11] IJ Goodfellow、J。Shlens、C。Szegedy。敵対例の説明と活用https://arxiv.org/abs/1412.6572
[12] A. Shrikumar、P。Greenside、A。Shcherbina、A。Kundaje。ブラックボックスだけでなく:アクティベーションの違いを伝播することで重要な機能を学ぶhttps://arxiv.org/abs/1605.01713
[13] M. Sundararajan、A。Taly、Q。Yan。ディープネットワークの公理的帰属https://arxiv.org/abs/1703.01365
[14] J. Yosinski、J。Clune、A。Nguyen、T。Fuchs、Hod Lipson、深い視覚化によるニューラルネットワークの理解https://arxiv.org/abs/1506.06579
[15] H. Wang、Z。Wang、M。Du、F。Yang、Z。Zhang、S。Ding、P。Mardziel、X。Hu。スコアカム:畳み込み神経ネットワークhttps://arxiv.org/abs/1910.01279のスコア加重視覚的説明
[16] P. Jiang、C。Zhang、Q。Hou、M。Cheng、Y。Wei。 layercam:ローカリゼーションの階層クラスのアクティベーションマップの探索http://mmcheng.net/mftp/papers/21tip_layercam.pdf
[17] G. Montavon1、A。Binder、S。Lapuschkin、W。Samek、およびK. Muller。レイヤーワイズ関連の伝播:概要https://www.researchgate.net/publication/335708351_layer-wise_relevance_propagation_an_overview


