pytorch cnn visualizations
1.0.0
This repository contains a number of convolutional neural network visualization techniques implemented in PyTorch.
Note : I removed cv2 dependencies and moved the repository towards PIL. A few things might be broken (although I tested all methods), I would appreciate if you could create an issue if something does not work.
Note : The code in this repository was tested with torch version 0.4.1 and some of the functions may not work as intended in later versions. Embora não deva ser um grande esforço para fazê -lo funcionar, não tenho planos no momento para tornar o código neste repositório compatível com a versão mais recente, porque ainda estou usando 0.4.1.
Depending on the technique, the code uses pretrained AlexNet or VGG from the model zoo. Some of the code also assumes that the layers in the model are separated into two sections; features , which contains the convolutional layers and classifier , that contains the fully connected layer (after flatting out convolutions). If you want to port this code to use it on your model that does not have such separation, you just need to do some editing on parts where it calls model.features and model.classifier .
Every technique has its own python file (eg gradcam.py ) which I hope will make things easier to understand. misc_functions.py contains functions like image processing and image recreation which is shared by the implemented techniques.
All images are pre-processed with mean and std of the ImageNet dataset before being fed to the model. Nenhum dos código usa a GPU, pois essas operações são bastante rápidas para uma única imagem (exceto para o Deep Dream, devido à imagem de exemplo que é usada para ela é enorme). You can make use of gpu with very little effort. As imagens de exemplo abaixo incluem números entre colchetes após a descrição, como mastiff (243) , esse número representa o ID da classe no conjunto de dados ImageNet.
Tentei comentar o código o máximo possível, se você tiver algum problema para entendê -lo ou portá -lo, não hesite em enviar um email ou criar um problema.
Below, are some sample results for each operation.
| Target class: King Snake (56) | Target class: Mastiff (243) | Target class: Spider (72) | |
| Original Image | |||
| Colored Vanilla Backpropagation | |||
| Vanilla Backpropagation Saliency | |||
| Colored Guided Backpropagation (GB) | |||
| Guided Backpropagation Saliency (GB) | |||
| Guided Backpropagation Negative Saliency (GB) | |||
| Guided Backpropagation Positive Saliency (GB) | |||
| Gradient-weighted Class Activation Map (Grad-CAM) | |||
| Gradient-weighted Class Activation Heatmap (Grad-CAM) | |||
| Gradient-weighted Class Activation Heatmap on Image (Grad-CAM) | |||
| Score-weighted Class Activation Map (Score-CAM) | |||
| Score-weighted Class Activation Heatmap (Score-CAM) | |||
| Score-weighted Class Activation Heatmap on Image (Score-CAM) | |||
| Colored Guided Gradient-weighted Class Activation Map (Guided-Grad-CAM) | |||
| Guided Gradient-weighted Class Activation Map Saliency (Guided-Grad-CAM) | |||
| Integrated Gradients (without image multiplication) | |||
| Layerwise Relevance (LRP) - Layer 7 | |||
| Layerwise Relevance (LRP) - Layer 1 |
LayerCAM [16] is a simple modification of Grad-CAM [3], which can generate reliable class activation maps from different layers. For the examples provided below, a pre-trained VGG16 was used.
| Class Activation Map | Class Activation HeatMap | Class Activation HeatMap on Image | |
| LayerCAM (Layer 9) | 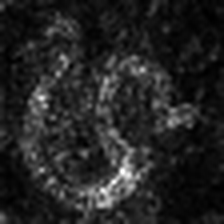 |  | 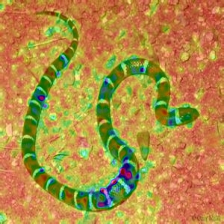 |
| LayerCAM (Layer 16) |  | 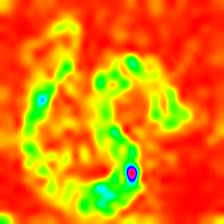 | 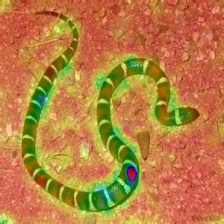 |
| LayerCAM (Layer 23) | 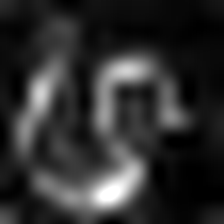 | 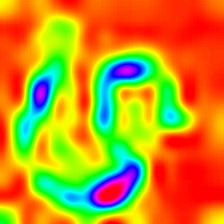 | 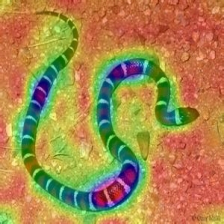 |
| LayerCAM (Layer 30) |  | 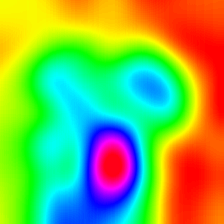 | 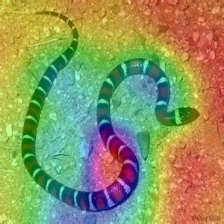 |
Another technique that is proposed is simply multiplying the gradients with the image itself. Results obtained with the usage of multiple gradient techniques are below.
| Vanilla Grad X Imagem | |||
| Guided Grad X Imagem | |||
| Integrated Grad X Imagem |
Smooth grad is adding some Gaussian noise to the original image and calculating gradients multiple times and averaging the results [8]. There are two examples at the bottom which use vanilla and guided backpropagation to calculate the gradients. Number of images ( n ) to average over is selected as 50. σ is shown at the bottom of the images.
| Vanilla Backprop | ||
| Guided Backprop | ||
CNN filters can be visualized when we optimize the input image with respect to output of the specific convolution operation. For this example I used a pre-trained VGG16 . Visualizations of layers start with basic color and direction filters at lower levels. As we approach towards the final layer the complexity of the filters also increase. If you employ external techniques like blurring, gradient clipping etc. you will probably produce better images.
| Layer 2 (Conv 1-2) | |||
| Layer 10 (Conv 2-1) | |||
| Layer 17 (Conv 3-1) | |||
| Layer 24 (Conv 4-1) |
Another way to visualize CNN layers is to to visualize activations for a specific input on a specific layer and filter. This was done in [1] Figure 3. Below example is obtained from layers/filters of VGG16 for the first image using guided backpropagation. The code for this opeations is in layer_activation_with_guided_backprop.py . O método é bastante semelhante à retropropagação guiada, mas, em vez de orientar o sinal da última camada e um alvo específico, ele guia o sinal de uma camada e filtro específicos.
| Input Image | Layer Vis. (Filter=0) | Filter Vis. (Layer=29) |
I think this technique is the most complex technique in this repository in terms of understanding what the code does. It is mainly because of complex regularization. Se você realmente deseja entender como isso é implementado, sugiro que você leia a segunda e a terceira página do artigo [5], especificamente, a parte da regularização. Here, the aim is to generate original image after nth layer. The further we go into the model, the harder it becomes. The results in the paper are incredibly good (see Figure 6) but here, the result quickly becomes messy as we iterate through the layers. This is because the authors of the paper tuned the parameters for each layer individually. You can tune the parameters just like the to ones that are given in the paper to optimize results for each layer. The inverted examples from several layers of AlexNet with the previous Snake picture are below.
| Layer 0: Conv2d | Layer 2: MaxPool2d | Layer 4: ReLU |
| Layer 7: ReLU | Layer 9: ReLU | Layer 12: MaxPool2d |
O Deep Dream é tecnicamente a mesma operação que a visualização da camada, a única diferença é que você não começa com uma imagem aleatória, mas usa uma imagem real. The samples below were created with VGG19 , the produced result is entirely up to the filter so it is kind of hit or miss. The more complex models produce mode high level features. If you replace VGG19 with an Inception variant you will get more noticable shapes when you target higher conv layers. Like layer visualization, if you employ additional techniques like gradient clipping, blurring etc. you might get better visualizations.
| Original Image | |
| VGG19 Layer: 34 (Final Conv. Layer) Filter: 94 | |
| VGG19 Layer: 34 (Final Conv. Layer) Filter: 103 |
This operation produces different outputs based on the model and the applied regularization method. Below, are some samples produced with VGG19 incorporated with Gaussian blur every other iteration (see [14] for details). The quality of generated images also depend on the model, AlexNet generally has green(ish) artifacts but VGGs produce (kind of) better images. Note that these images are generated with regular CNNs with optimizing the input and not with GANs .
| Target class: Worm Snake (52) - (VGG19) | Target class: Spider (72) - (VGG19) |
As amostras abaixo mostram a imagem produzida sem regularização, regularizações de L1 e L2 na classe Target: Flamingo (130) para mostrar as diferenças entre os métodos de regularização. These images are generated with a pretrained AlexNet.
| No Regularization | L1 Regularization | L2 Regularization |
As amostras produzidas podem ser ainda otimizadas para se parecer com a classe de destino desejada, algumas das operações que você pode incorporar para melhorar a qualidade são; gradientes de recorte e alimentos abaixo de um certo trreshold e swaps de cores aleatórias em algumas partes, corte aleatório da imagem, forçando a imagem gerada a seguir um caminho para forçar a continuidade.
Some of these techniques are implemented in generate_regularized_class_specific_samples.py (courtesy of alexstoken).
torch == 0.4.1
torchvision >= 0.1.9
numpy >= 1.13.0
matplotlib >= 1.5
PIL >= 1.1.7
If you find the code in this repository useful for your research consider citing it.
@misc{uozbulak_pytorch_vis_2022,
author = {Utku Ozbulak},
title = {PyTorch CNN Visualizations},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/utkuozbulak/pytorch-cnn-visualizations}},
commit = {b7e60adaf64c9be97b480509285718603d1e9ba4}
}
[1] JT Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller. Striving for Simplicity: The All Convolutional Net , https://arxiv.org/abs/1412.6806
[2] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, A. Torralba. Learning Deep Features for Discriminative Localization , https://arxiv.org/abs/1512.04150
[3] RR Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh, and D. Batra. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization , https://arxiv.org/abs/1610.02391
[4] K. Simonyan, A. Vedaldi, A. Zisserman. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps , https://arxiv.org/abs/1312.6034
[5] A. Mahendran, A. Vedaldi. Understanding Deep Image Representations by Inverting Them , https://arxiv.org/abs/1412.0035
[6] H. Noh, S. Hong, B. Han, Learning Deconvolution Network for Semantic Segmentation https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Noh_Learning_Deconvolution_Network_ICCV_2015_paper.pdf
[7] A. Nguyen, J. Yosinski, J. Clune. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images https://arxiv.org/abs/1412.1897
[8] D. Smilkov, N. Thorat, N. Kim, F. Viégas, M. Wattenberg. SmoothGrad: removing noise by adding noise https://arxiv.org/abs/1706.03825
[9] D. Erhan, Y. Bengio, A. Courville, P. Vincent. Visualizando recursos de camada superior de uma rede profunda https://www.researchgate.net/publication/265022827_visualizando_higher-layer_features_of_a_deep_network
[10] A. Mordvintsev, C. Olah, M. Tyka. Inceptionism: Going Deeper into Neural Networks https://research.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html
[11] IJ Goodfellow, J. Shlens, C. Szegedy. Explaining and Harnessing Adversarial Examples https://arxiv.org/abs/1412.6572
[12] A. Shrikumar, P. Greenside, A. Shcherbina, A. Kundaje. Not Just a Black Box: Learning Important Features Through Propagating Activation Differences https://arxiv.org/abs/1605.01713
[13] M. Sundararajan, A. Taly, Q. Yan. Axiomatic Attribution for Deep Networks https://arxiv.org/abs/1703.01365
[14] J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, Hod Lipson, Entendendo as redes neurais através da visualização profunda https://arxiv.org/abs/1506.06579
[15] H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, X. Hu. Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks https://arxiv.org/abs/1910.01279
[16] P. Jiang, C. Zhang, Q. Hou, M. Cheng, Y. Wei. LayerCAM: Exploring Hierarchical Class Activation Maps for Localization http://mmcheng.net/mftp/Papers/21TIP_LayerCAM.pdf
[17] G. Montavon1, A. Binder, S. Lapuschkin, W. Samek, and K. Muller. Layer-Wise Relevance Propagation: An Overview https://www.researchgate.net/publication/335708351_Layer-Wise_Relevance_Propagation_An_Overview


