pytorch cnn visualizations
1.0.0
Этот репозиторий содержит ряд методов визуализации нейронной сети, реализованных в Pytorch.
Примечание : я удалил зависимости CV2 и переместил хранилище в сторону PIL. Несколько вещей могут быть нарушены (хотя я проверил все методы), я был бы признателен, если бы вы могли создать проблему, если что -то не сработает.
ПРИМЕЧАНИЕ . Код в этом репозитории был протестирован с версией Torch 0.4.1, и некоторые функции могут не работать, как предназначено в более поздних версиях. Хотя это не должно быть слишком большим усилием, чтобы заставить его работать, у меня сейчас нет планов, чтобы сделать код в этом хранилище совместимым с последней версией, потому что я все еще использую 0.4.1.
В зависимости от техники, в коде используется предварительно проведенный Alexnet или VGG из модельного зоопарка. Некоторые из кода также предполагают, что слои в модели разделены на два раздела; Особенности , которые содержат сверточные слои и классификатор , которые содержит полностью подключенный слой (после устранения свертков). Если вы хотите перенести этот код, чтобы использовать его в вашей модели, которая не имеет такого разделения, вам просто нужно сделать некоторое редактирование на частях, где он вызывает модель .
Каждый метод имеет свой собственный файл Python (например, gradcam.py ), который, я надеюсь, облегчит понимание. misc_functions.py содержит такие функции, как обработка изображений и отдых изображений, которые передаются реализованными методами.
Все изображения предварительно обработаны средним и STD набора данных ImageNet, прежде чем подавать в модель. Ни один из кодов не использует графический процессор, так как эти операции довольно быстры для одного изображения (за исключением глубокого сновидения из -за примера изображения, которое используется для него огромно). Вы можете использовать GPU с очень небольшими усилиями. Примеры изображений ниже включают в себя числа в скобках после описания, как мастиф (243) , это число представляет собой идентификатор класса в наборе данных ImageNet.
Я пытался прокомментировать код как можно больше, если у вас есть какие -либо проблемы, понимающие его или переносить его, не стесняйтесь отправлять электронное письмо или создать проблему.
Ниже, некоторые результаты образца для каждой операции.
| Целевой класс: King Snake (56) | Целевой класс: мастиф (243) | Целевой класс: паук (72) | |
| Исходное изображение | |||
| Цветная ванильная обратная эксплуатация | |||
| Ванильная обратная среда | |||
| Цветный управляемый обратный процесс (ГБ) | |||
| Смещаемость обратного распространения (ГБ) | |||
| Отрицательная значимость с гидом (ГБ) | |||
| Руководство с управляемым обратным распространением положительная значимость (ГБ) | |||
| Градиент-взвешенная карта активации класса (Выпускная-кам) | |||
| Градиент-взвешенная тепловая карта активации класса (Выпускная-кам) | |||
| Градиент-взвешенная тепловая карта активации класса на изображении (Выпускная-кам) | |||
| Взвешенная карта активации класса (Камеры оценки) | |||
| Взвешенная тепловая карта активации класса (Камеры оценки) | |||
| Взвешенная тепловая карта активации класса на изображении (Камеры оценки) | |||
| Раскрашенная уводная градиент-взвешенная карта активации класса (Руководство-кам) | |||
| Градиент-взвешенная классовая карта активации. (Руководство-кам) | |||
| Интегрированные градиенты (Без умножения изображения) | |||
| Уровни актуальности (LRP) - слой 7 | |||
| Уровни актуальности (LRP) - слой 1 |
LayerCam [16]-это простая модификация градуирования CAM [3], которая может генерировать надежные карты активации класса из разных слоев. Для примеров, приведенных ниже, использовался предварительно обученный VGG16 .
| Карта активации класса | Тепловая карта активации класса | Тепловая карта активации класса на изображении | |
| Layercam (Слой 9) | 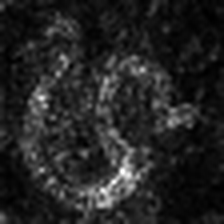 |  |  |
| Layercam (Слой 16) |  | 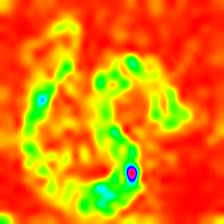 | 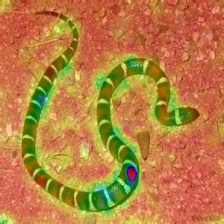 |
| Layercam (Слой 23) |  |  | 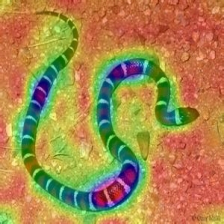 |
| Layercam (Слой 30) |  |  | 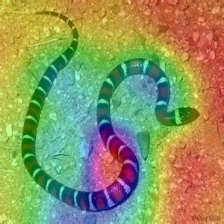 |
Еще одна техника, которая предлагается, - это просто умножение градиентов с самим изображением. Результаты, полученные с использованием нескольких методов градиента, ниже.
| Ванильный выпускник Х Изображение | |||
| Управляемый выпускник Х Изображение | |||
| Интегрированный выпускник Х Изображение |
Smooth Grad добавляет немного гауссовского шума к исходному изображению и несколько раз вычисляет градиенты и усредняет результаты [8]. Внизу есть два примера, которые используют ваниль и управляемый обратным распространением для расчета градиентов. Количество изображений ( n ) в среднем выбирается как 50. Σ показано в нижней части изображений.
| Vanilla Backprop | ||
| Руководство Backprop | ||
Фильтры CNN могут быть визуализированы, когда мы оптимизируем входное изображение в отношении вывода конкретной операции свертки. Для этого примера я использовал предварительно обученный VGG16 . Визуализация слоев начинается с основных фильтров цвета и направления на более низких уровнях. Когда мы приближаемся к окончательному слою, сложность фильтров также увеличивается. Если вы используете внешние методы, такие как размытие, градиент -отсечение и т. Д., Вы, вероятно, будут создавать лучшие изображения.
| Слой 2 (Конверт 1-2) | |||
| Слой 10 (Конвер 2-1) | |||
| Слой 17 (Конвер 3-1) | |||
| Слой 24 (Конвер 4-1) |
Другим способом визуализации слоев CNN является визуализация активаций для конкретного ввода на определенном слое и фильтре. Это было сделано в [1] Рисунок 3. Ниже пример получен из слоев/фильтров VGG16 для первого изображения с использованием управляемого обратного процесса. Код для этого Обращения находится в layer_activation_with_guided_backprop.py . Метод очень похож на управляемый обратный процесс, но вместо того, чтобы направлять сигнал из последнего уровня и определенную цель, он направляет сигнал из определенного слоя и фильтра.
| Входное изображение | Слой Vis. (Фильтр = 0) | Фильтр Vis. (Слой = 29) |
Я думаю, что этот метод является наиболее сложной техникой в этом хранилище с точки зрения понимания того, что делает код. Это в основном из -за сложной регуляризации. Если вы действительно хотите понять, как это реализовано, я предлагаю вам прочитать вторую и третью страницу статьи [5], в частности, часть регуляризации. Здесь цель состоит в том, чтобы генерировать исходное изображение после n -й слой. Чем дальше мы идем в модель, тем тяжелее она становится. Результаты в статье невероятно хорошие (см. Рисунок 6), но здесь результат быстро становится грязным, когда мы перечитываем слои. Это связано с тем, что авторы бумаги настроили параметры для каждого слоя индивидуально. Вы можете настроить параметры, как и для тех, которые приведены в статье, чтобы оптимизировать результаты для каждого слоя. Перевернутые примеры из нескольких слоев Alexnet с предыдущим изображением змеи приведены ниже.
| Слой 0: conv2d | Слой 2: maxpool2d | Слой 4: Relu |
| Слой 7: Relu | Слой 9: Relu | Слой 12: MAXPOOL2D |
Глубокая мечта технически такая же операция, что и визуализация слоя, единственная разница в том, что вы не начинаете со случайного изображения, но используете реальную картину. Приведенные ниже образцы были созданы с помощью VGG19 , полученный результат полностью подходит для фильтра, так что это своего рода удары или промаха. Более сложные модели создают функции высокого уровня в режиме. Если вы замените VGG19 на основополагающий вариант, вы получите более заметные формы, когда вы нацелитесь на более высокие убедительные слои. Например, визуализация слоя, если вы используете дополнительные методы, такие как градиент, размытие и т. Д. Вы можете получить лучшую визуализацию.
| Исходное изображение | |
| VGG19 Слой: 34 (Окончательный конвейный слой) Фильтр: 94 | |
| VGG19 Слой: 34 (Окончательный конвейный слой) Фильтр: 103 |
Эта операция создает различные выходы на основе модели и примененного метода регуляризации. Ниже, некоторые образцы, произведенные с VGG19 , включенные в гауссовую размытие всех остальных итераций ([14] для деталей). Качество сгенерированных изображений также зависит от модели, Alexnet, как правило, имеет зеленые (ISH) артефакты, но VGG производят (вроде) лучшие изображения. Обратите внимание, что эти изображения генерируются с помощью обычных CNN с оптимизацией ввода, а не с Gans .
| Целевой класс: червячная змея (52) - (VGG19) | Целевой класс: паук (72) - (VGG19) |
Приведенные ниже образцы показывают полученное изображение без регуляризации, регуляризации L1 и L2 в целевом классе: Flamingo (130), чтобы показать различия между методами регуляризации. Эти изображения генерируются с предварительным Alexnet.
| Нет регуляризации | L1 регуляризация | L2 регуляризация |
Производные образцы могут быть дополнительно оптимизированы, чтобы напоминать желаемый целевой класс, некоторые из операций, которые вы можете включить для улучшения качества, являются; размытые, градиенты обрезки, которые ниже определенного трероголда, случайные цвета на некоторых частях, случайное обрезка изображения, вынуждая сгенерированное изображение, чтобы следовать пути к непрерывности силы.
Некоторые из этих методов реализованы в Generate_regularized_class_specific_samples.py (предоставлено Alexstoken).
torch == 0.4.1
torchvision >= 0.1.9
numpy >= 1.13.0
matplotlib >= 1.5
PIL >= 1.1.7
Если вы найдете код в этом репозитории полезным для вашего исследования, рассмотрите его.
@misc{uozbulak_pytorch_vis_2022,
author = {Utku Ozbulak},
title = {PyTorch CNN Visualizations},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/utkuozbulak/pytorch-cnn-visualizations}},
commit = {b7e60adaf64c9be97b480509285718603d1e9ba4}
}
[1] JT Springenberg, A. Dosovitskiy, T. Brox и M. Riedmiller. Стремление к простоте: все сверточная сеть , https://arxiv.org/abs/1412.6806
[2] Б. Чжоу, А. Хосла, А. Лапедриза, А. Олива, А. Торралба. Обучение глубоким характеристикам для дискриминационной локализации , https://arxiv.org/abs/1512.04150
[3] RR Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh и D. Batra. Grad-Cam: Визуальные объяснения из глубоких сетей посредством локализации на основе градиентов , https://arxiv.org/abs/1610.02391
[4] К. Симонян, А. Ведальди, А. Зиссерман. Глубокие внутренние сверточные сети: визуализация моделей классификации изображений и карт значимости , https://arxiv.org/abs/1312.6034
[5] А. Махендран, А. Ведальди. Понимание глубоких представлений изображений, инвертируя их , https://arxiv.org/abs/1412.0035
[6] H. Noh, S. Hong, B. Han, сеть деконволюции обучения для семантической сегментации https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/noh_learning_deconvolution_network_iccv_2015_papers/noh_le
[7] A. Nguyen, J. Yosinski, J. Clune. Глубокие нейронные сети легко обманывают: прогнозы с высокой уверенностью для неузнаваемых изображений https://arxiv.org/abs/1412.1897
[8] Д. Смилков, Н. Торат, Н. Ким, Ф. Вийгас, М. Уоттенберг. SmoothGraduard: удаление шума, добавив шум https://arxiv.org/abs/1706.03825
[9] Д. Эрхан, Ю. Бенгио, А. Курвилл, П. Винсент. Визуализация функций с более высоким слоем глубокой сети https://www.researchgate.net/publication/265022827_visualize_higher-layer_features_of_a_deep_network
[10] A. Mordvintsev, C. Olah, M. Tyka. Начало: углубляться в нейронные сети https://research.googleblog.com/2015/06/inceptionism-going-deeper-into-neral.html
[11] IJ Goodfellow, J. Shlens, C. Szegedy. Объяснение и использование состязательных примеров https://arxiv.org/abs/1412.6572
[12] А. Шрикумар, П. Гринсайд, А. Шшербина, А. Кундадж. Не просто черный ящик: изучение важных функций посредством распространения различий в активации https://arxiv.org/abs/1605.01713
[13] М. Сундарараджан, А. Тали, К. Ян. Аксиоматическая атрибуция для глубоких сетей https://arxiv.org/abs/1703.01365
[14] J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, Hod Lipson, Понимание нейронных сетей через глубокую визуализацию https://arxiv.org/abs/1506.06579
[15] H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, X. Hu. Оценка Cam: Взвешенные визуальные объяснения для сверточных нейронных сетей https://arxiv.org/abs/1910.01279
[16] P. Jiang, C. Zhang, Q. Hou, M. Cheng, Y. Wei. Layercam: Изучение иерархических карт активации класса для локализации http://mmcheng.net/mftp/papers/21tip_layercam.pdf
[17] G. Montavon1, A. Binder, S. Lapuschkin, W. Simek и K. Muller. Распространение уровня по уровню


