pytorch cnn visualizations
1.0.0
Dieses Repository enthält eine Reihe von in Pytorch implementierten Faltungs -Visualisierungstechniken für neuronale Netzwerke.
HINWEIS : Ich habe CV2 -Abhängigkeiten entfernt und das Repository nach PIL bewegt. Ein paar Dinge könnten gebrochen werden (obwohl ich alle Methoden getestet habe), würde ich mich freuen, wenn Sie ein Problem erstellen könnten, wenn etwas nicht funktioniert.
Hinweis : Der Code in diesem Repository wurde mit Torch Version 0.4.1 getestet, und einige der Funktionen funktionieren möglicherweise nicht wie in späteren Versionen beabsichtigt. Obwohl es sich nicht allzu bemühen sollte, es zum Laufen zu bringen, habe ich momentan keine Pläne, den Code in diesem Repository -kompatibel mit der neuesten Version zu erstellen, da ich noch 0.4.1 verwende.
Abhängig von der Technik verwendet der Code ein vorgefertigter Alexnet oder VGG aus dem Modellzoo. Ein Teil des Codes geht auch davon aus, dass die Schichten im Modell in zwei Abschnitte unterteilt sind. Merkmale , die die Faltungsschichten und den Klassifizierer enthält, die die vollständig verbundene Schicht enthält (nach dem Ausflachen von Konvolutionen). Wenn Sie diesen Code portieren möchten, um ihn für Ihr Modell zu verwenden, das keine solche Trennung hat, müssen Sie nur einige Bearbeitungen für Teile durchführen, in denen es modell nennt .
Jede Technik hat eine eigene Python -Datei (z. B. Gradcam.py ), von der ich hoffe, dass sie die Dinge erleichtert. misc_functions.py enthält Funktionen wie Bildverarbeitung und Bilderholung, die von den implementierten Techniken gemeinsam genutzt werden.
Alle Bilder sind mit dem Mittelwert und dem STD des ImageNet-Datensatzes verarbeitet, bevor sie dem Modell zugeführt werden. Keiner der Code verwendet GPU, da diese Operationen für ein einzelnes Bild ziemlich schnell sind (mit Ausnahme von Deep Dream aufgrund des Beispielbildes, das dafür verwendet wird, ist riesig). Sie können GPU mit sehr wenig Aufwand nutzen. Die folgenden Beispielbilder enthalten Zahlen in den Klammern nach der Beschreibung, wie Mastiff (243) , diese Nummer repräsentiert die Klassen -ID im ImageNet -Datensatz.
Ich habe versucht, den Code so weit wie möglich zu kommentieren, wenn Sie Probleme haben, ihn zu verstehen oder zu portieren, zögern Sie nicht, eine E -Mail zu senden oder ein Problem zu erstellen.
Im Folgenden finden Sie einige Beispielergebnisse für jeden Vorgang.
| Zielklasse: King Snake (56) | Zielklasse: Mastiff (243) | Zielklasse: Spinnen (72) | |
| Originalbild | |||
| Farbige Vanille -Backpropagation | |||
| Vanille -Backpropagationsmals | |||
| Farbige geführte Backpropagation (GB) | |||
| Führungsspezifische Backpropagations -Austragungsantrieb (GB) | |||
| Führung negativer Hindernis für Backpropagation (GB) | |||
| Geführte Backpropagation positive Ärmlichkeit (GB) | |||
| Gradientengewichtete Klassenaktivierungskarte (Grad-Cam) | |||
| Die Aktivierungs-Aktivierung von Gradientengewichteter heatmap (Grad-Cam) | |||
| Die Aktivierung von Gradienten-Gewichtsklassen Heatmap auf dem Bild (Grad-Cam) | |||
| Score-Gewicht-Klassenaktivierungskarte (Score-CAM) | |||
| Score-Wights-Klassenaktivierung Heatmap (Score-CAM) | |||
| Score-Wighted-Class-Aktivierung Heatmap auf dem Bild (Score-CAM) | |||
| Farbig geführte Gradienten-gewichtete Klassenaktivierungskarte (Guided-Grad-Cam) | |||
| Guided Gradient-gewichtete Klassenaktivierungskartendualität (Guided-Grad-Cam) | |||
| Integrierte Gradienten (ohne Bildmultiplikation) | |||
| Layerwise Relevanz (Lrp) - Schicht 7 | |||
| Layerwise Relevanz (Lrp) - Schicht 1 |
Layercam [16] ist eine einfache Modifikation von Grad-CAM [3], die zuverlässige Klassenaktivierungskarten aus verschiedenen Schichten erzeugen kann. Für die nachstehenden Beispiele wurde ein vorgebildeter VGG16 verwendet.
| Klassenaktivierungskarte | Klassenaktivierung HEATMAP | Klassenaktivierung Wärmemap auf dem Bild | |
| Layercam (Schicht 9) | 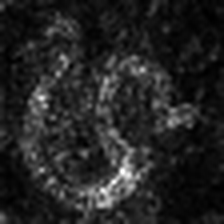 |  | 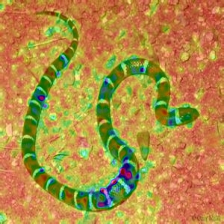 |
| Layercam (Schicht 16) |  | 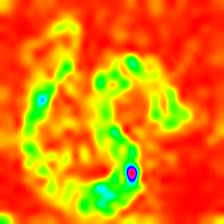 | 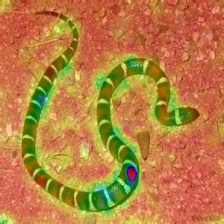 |
| Layercam (Schicht 23) | 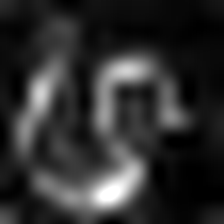 | 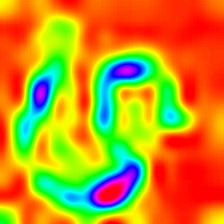 | 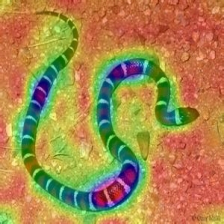 |
| Layercam (Schicht 30) |  | 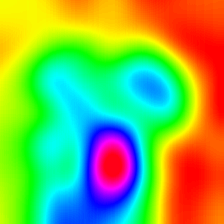 |  |
Eine andere Technik, die vorgeschlagen wird, ist einfach, die Gradienten mit dem Bild selbst zu multiplizieren. Die mit der Verwendung mehrerer Gradiententechniken erzielten Ergebnisse finden Sie unten.
| Vanilla Grad X Bild | |||
| Guided Grad X Bild | |||
| Integrierter Grad X Bild |
Smooth Grad fügt dem Originalbild ein gewisses Gaußsche Rauschen hinzu und berechnet mehrmals Gradienten und durchschnittlich die Ergebnisse [8]. Am Boden befinden sich zwei Beispiele, die Vanille und geführte Backpropagation verwenden, um die Gradienten zu berechnen. Die Anzahl der Bilder ( n ) bis durchschnittlich wird als 50 ausgewählt. Σ ist am unteren Rand der Bilder angezeigt.
| Vanille -Backprop | ||
| Backprop geführt | ||
CNN -Filter können visualisiert werden, wenn wir das Eingangsbild in Bezug auf die Ausgabe des spezifischen Faltungsvorgangs optimieren. In diesem Beispiel habe ich einen vorgebildeten VGG16 verwendet. Die Visualisierungen von Schichten beginnen mit grundlegenden Farb- und Richtfiltern in niedrigeren Ebenen. Wenn wir uns der endgültigen Schicht nähern, nimmt auch die Komplexität der Filter zu. Wenn Sie externe Techniken wie Unschärfe, Gradientenausschnitten usw. anwenden usw. Sie werden wahrscheinlich bessere Bilder produzieren.
| Schicht 2 (Conv 1-2) | |||
| Schicht 10 (Überzeugen) | |||
| Schicht 17 (Überzeugen) | |||
| Schicht 24 (Überzeugen Sie 4-1) |
Eine andere Möglichkeit, CNN -Schichten zu visualisieren, besteht darin, Aktivierungen für eine bestimmte Eingabe für eine bestimmte Ebene und einen bestimmten Filter zu visualisieren. Dies geschah in [1]. Abbildung 3. Nachfolgend wird das Beispiel aus Schichten/Filtern von VGG16 für das erste Bild unter Verwendung einer geführten Backpropagation erhalten. Der Code für diese Opeaions ist in layer_activation_with_guided_backprop.py . Die Methode ist der geführten Backpropagation ziemlich ähnlich, aber anstatt das Signal von der letzten Schicht und einem bestimmten Ziel zu leiten, führt es das Signal von einer bestimmten Schicht und einem bestimmten Filter.
| Eingabebild | Schicht vis. (Filter = 0) | Filter vis. (Schicht = 29) |
Ich denke, diese Technik ist die komplexeste Technik in diesem Repository, um zu verstehen, was der Code tut. Es liegt hauptsächlich an der komplexen Regularisierung. Wenn Sie wirklich verstehen möchten, wie dies implementiert wird, schlage ich vor, dass Sie die zweite und dritte Seite des Papiers [5] lesen, insbesondere den Regularisierungsteil. Hier ist das Ziel, nach der n -ten Schicht ein Originalbild zu generieren. Je weiter wir in das Modell gehen, desto schwieriger wird es. Die Ergebnisse im Papier sind unglaublich gut (siehe Abbildung 6), aber hier wird das Ergebnis schnell unordentlich, wenn wir durch die Schichten iterieren. Dies liegt daran, dass die Autoren des Papiers die Parameter für jede Schicht einzeln abgestimmt haben. Sie können die Parameter genauso wie die in das Papier angegebene Parameter einstellen, um die Ergebnisse für jede Schicht zu optimieren. Die umgekehrten Beispiele aus mehreren Alexnet -Schichten mit dem vorherigen Schlangenbild finden Sie unten.
| Schicht 0: conv2d | Schicht 2: maxpool2d | Schicht 4: Relu |
| Schicht 7: Relu | Schicht 9: Relu | Schicht 12: maxpool2d |
Deep Dream ist technisch die gleiche Operation wie Schichtvisualisierung Der einzige Unterschied besteht darin, dass Sie nicht mit einem zufälligen Bild beginnen, sondern ein echtes Bild verwenden. Die unten stehenden Proben wurden mit VGG19 erstellt, das erzeugte Ergebnis ist vollständig bis zum Filter, sodass es eine Art Treffer oder Miss ist. Die komplexeren Modelle erzeugen Modus -Merkmale auf hoher Ebene. Wenn Sie VGG19 durch eine Inception -Variante ersetzen, erhalten Sie eine bemerkenswerte Formen, wenn Sie höhere Konvoke -Ebenen ansprechen. Wenn Sie wie Layer -Visualisierung zusätzliche Techniken wie Gradientenausschnitten, Unschärfe usw. einsetzen, erhalten Sie möglicherweise bessere Visualisierungen.
| Originalbild | |
| VGG19 Schicht: 34 (Letzte Konv. Layer) Filter: 94 | |
| VGG19 Schicht: 34 (Letzte Konv. Layer) Filter: 103 |
Dieser Vorgang erzeugt unterschiedliche Ausgänge basierend auf dem Modell und der angewandten Regularisierungsmethode. Im Folgenden finden Sie einige Proben, die mit VGG19 produziert werden, die mit Gaußschen Unschärfe bei jeder anderen Iteration integriert sind (siehe [14] für Einzelheiten). Die Qualität der generierten Bilder hängt auch vom Modell ab, Alexnet verfügt im Allgemeinen über grüne Artefakte (ISH), aber VGGs produzieren (Art von) besseren Bildern. Beachten Sie, dass diese Bilder mit regulären CNNs mit Optimierung des Eingangs und nicht mit Gans erzeugt werden.
| Zielklasse: Wurmschlange (52) - (VGG19) | Zielklasse: Spinnen (72) - (VGG19) |
Die folgenden Proben zeigen das produzierte Bild ohne Regularisierung, L1- und L2 -Regularisierungen in der Zielklasse: Flamingo (130), um die Unterschiede zwischen Regularisierungsmethoden zu zeigen. Diese Bilder werden mit einem vorbereiteten Alexnet erzeugt.
| Keine Regularisierung | L1 -Regularisierung | L2 Regularisierung |
Produzierte Proben können weiter optimiert werden, um der gewünschten Zielklasse zu ähneln. Einige der Vorgänge, die Sie zur Verbesserung der Qualität einbeziehen können, sind. Unschärfe, Schnittgradienten, die unter einem bestimmten Schrärchen liegen, zufällige Farbwaps in einigen Teilen, zufällige Beschneidung des Bildes und das erzeugte Bild, um einem Pfad zu folgen, um die Kontinuität zu erzwingen.
Einige dieser Techniken sind in generate_regularisierte_class_specific_samples.py (mit freundlicher Genehmigung von Alexstoken) implementiert.
torch == 0.4.1
torchvision >= 0.1.9
numpy >= 1.13.0
matplotlib >= 1.5
PIL >= 1.1.7
Wenn Sie den Code in diesem Repository für Ihre Forschung nützlich finden, sollten Sie ihn zitieren.
@misc{uozbulak_pytorch_vis_2022,
author = {Utku Ozbulak},
title = {PyTorch CNN Visualizations},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/utkuozbulak/pytorch-cnn-visualizations}},
commit = {b7e60adaf64c9be97b480509285718603d1e9ba4}
}
[1] JT Spartenberg, A. Dosovitskiy, T. Brox und M. Riedmiller. Einfachheitestests
[2] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, A. Torralba. Tiefe Merkmale für diskriminative Lokalisierung lernen , https://arxiv.org/abs/1512.04150
[3] RR Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh und D. Batra. Grad-cam: Visuelle Erklärungen aus tiefen Netzwerken über die Gradienten-basierte Lokalisierung , https://arxiv.org/abs/1610.02391
[4] K. Simonyan, A. Vedaldi, A. Zisserman. Tief in Faltungsnetzwerken: Visualisierung von Bildklassifizierungsmodellen und Salcy -Karten , https://arxiv.org/abs/1312.6034
[5] A. Mahendran, A. Vedaldi. Verständnis von Deep -Image -Darstellungen, indem Sie sie invertieren , https://arxiv.org/abs/1412.0035
[6] H. Noh, S. Hong, B. Han, Learning Deconvolution Network für semantische Segmentierung https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/noh_learning_deconvolution_network_iccv_2015_paper.pdf
[7] A. Nguyen, J. Yosinski, J. Clune. Tiefe neuronale Netzwerke sind leicht täuschen: hohe Vertrauensvorhersagen für nicht wiederzuerkennene Bilder https://arxiv.org/abs/1412.1897
[8] D. Smilkov, N. Thorat, N. Kim, F. Viégas, M. Watttenberg. SmoothGrad: Entfernen von Rauschen durch Hinzufügen von Rauschen https://arxiv.org/abs/1706.03825
[9] D. Erhan, Y. Bengio, A. Courville, P. Vincent. Visualisieren von höheren Layer-Funktionen eines tiefen Netzwerks https://www.researchgate.net/publication/2650222827_visualizing_higher-Layer_Features_of_a_deep_network
[10] A. Mordvintsev, C. Olah, M. Tyka. Inceptionismus: Tiefer in neuronale Netzwerke https://research.googleblog.com/2015/06/inceptionism-inggoing-leeper-into-neural.html
[11] IJ Goodfellow, J. Shlens, C. Szegedy. Erklären und Nutzung von kontroversen Beispielen https://arxiv.org/abs/1412.6572
[12] A. Shrikumar, P. Greenside, A. Shcherbina, A. Kundaje. Nicht nur eine schwarze Box: Lernen wichtige Merkmale durch verbreitete Aktivierungsunterschiede https://arxiv.org/abs/1605.01713
[13] M. Sundararajan, A. Taly, Q. Yan. Axiomatische Zuschreibung für tiefe Netzwerke https://arxiv.org/abs/1703.01365
[14] J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, Hod Lipson, Verständnis der neuronalen Netze durch die tiefe Visualisierung https://arxiv.org/abs/1506.06579
[15] H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, X. Hu. Score-Cam: Score-Wights Visual Erklärungen für Faltungsfaltungsnetze https://arxiv.org/abs/1910.01279
[16] P. Jiang, C. Zhang, Q. Hou, M. Cheng, Y. Wei. Layercam: Erforschung hierarchischer Klassenaktivierungskarten für die Lokalisierung http://mmcheng.net/mftp/papers/21tip_layercam.pdf
[17] G. Montavon1, A. Binder, S. Lapuschkin, W. Samek und K. Müller. Schichtwise Relevanz-Ausbreitung: Eine Übersicht https://www.researchgate.net/publication/335708351_Layer-wise_relevance_propagation_an_overview


