pytorch cnn visualizations
1.0.0
Este repositorio contiene una serie de técnicas de visualización de redes neuronales convolucionales implementadas en Pytorch.
Nota : eliminé las dependencias de CV2 y moví el repositorio hacia PIL. Algunas cosas pueden estar rotas (aunque probé todos los métodos), agradecería si pudiera crear un problema si algo no funciona.
Nota : El código en este repositorio se probó con la versión de antorcha 0.4.1 y algunas de las funciones pueden no funcionar según lo previsto en versiones posteriores. Aunque no debería ser un gran esfuerzo para que funcione, no tengo planes en este momento para que el código en este repositorio sea compatible con la última versión porque todavía estoy usando 0.4.1.
Dependiendo de la técnica, el código utiliza Alexnet o VGG previamente provocado del zoológico del modelo. Parte del código también supone que las capas en el modelo están separadas en dos secciones; Las características , que contienen las capas y clasificador convolucionales, que contienen la capa totalmente conectada (después de planear convoluciones). Si desea transferir este código para usarlo en su modelo que no tenga tal separación, solo necesita hacer algo de edición en piezas donde llama model.features y model.classifier .
Cada técnica tiene su propio archivo de Python (por ejemplo, Gradcam.py ) que espero haga que las cosas sean más fáciles de entender. misc_functions.py contiene funciones como el procesamiento de imágenes y la recreación de imágenes que comparten las técnicas implementadas.
Todas las imágenes se procesan previamente con la media y la ETS del conjunto de datos ImageNet antes de ser alimentados al modelo. Ninguno de los códigos usa GPU, ya que estas operaciones son bastante rápidas para una sola imagen (a excepción de Deep Dream debido a la imagen de ejemplo que se usa para ella es enorme). Puedes hacer uso de GPU con muy poco esfuerzo. Las imágenes de ejemplo a continuación incluyen números en los soportes después de la descripción, como Mastiff (243) , este número representa la ID de clase en el conjunto de datos de ImageNet.
Traté de comentar sobre el código tanto como sea posible, si tiene algún problema para entenderlo o portarlo, no dude en enviar un correo electrónico o crear un problema.
A continuación, hay algunos resultados de muestra para cada operación.
| Clase objetivo: King Snake (56) | Clase de destino: Mastín (243) | Clase de destino: Spider (72) | |
| Imagen original | |||
| Propropagación de vainilla de color | |||
| Varilio de retroceso de saliente | |||
| Respaldo guiado de color (GB) | |||
| Prominencia guiada de respaldo (GB) | |||
| Saliencia negativa de retroceso de retroceso guiado (GB) | |||
| Salcanza positiva de respaldo de retroceso guiado (GB) | |||
| Mapa de activación de clase ponderada por el gradiente (Graduado de graduación) | |||
| Mapa de calor de activación de clase ponderada por el gradiente (Graduado de graduación) | |||
| Mapa de calor de activación de clase ponderada por el gradiente en la imagen (Graduado de graduación) | |||
| Mapa de activación de clase ponderado en puntuación (Cam) | |||
| Mapa de calor de activación de clase ponderado por puntuación (Cam) | |||
| Mapa de calor de activación de clase ponderada en la imagen en la imagen (Cam) | |||
| Mapa de activación de clase ponderada por el gradiente guiado de color (Cam Guidy-Cam) | |||
| Guiado Mapa de activación de clases ponderado por gradiente Saliente (Cam Guidy-Cam) | |||
| Gradientes integrados (sin multiplicación de imágenes) | |||
| Relevancia de capa (LRP) - Capa 7 | |||
| Relevancia de capa (LRP) - Capa 1 |
LayerCam [16] es una modificación simple de la cámara de posgrado [3], que puede generar mapas de activación de clase confiables a partir de diferentes capas. Para los ejemplos proporcionados a continuación, se utilizó un VGG16 previamente entrenado.
| Mapa de activación de clase | Mapa de calor de activación de clases | Mapa de calor de activación de clase en la imagen | |
| Layercam (Capa 9) | 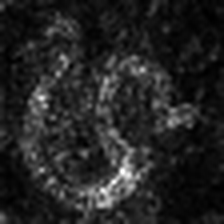 |  |  |
| Layercam (Capa 16) |  | 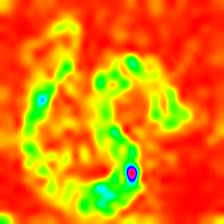 |  |
| Layercam (Capa 23) | 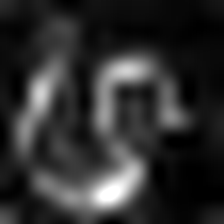 | 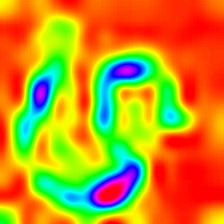 | 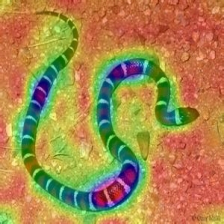 |
| Layercam (Capa 30) |  | 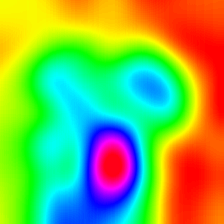 | 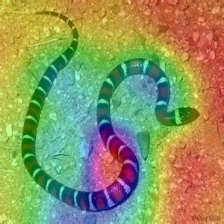 |
Otra técnica que se propone es simplemente multiplicar los gradientes con la imagen misma. Los resultados obtenidos con el uso de técnicas de gradiente múltiple están a continuación.
| Graduado de vainilla incógnita Imagen | |||
| Graduado guiado X Imagen | |||
| Graduado X Imagen |
Smooth Grad está agregando algo de ruido gaussiano a la imagen original y calculando los gradientes varias veces y promediando los resultados [8]. Hay dos ejemplos en la parte inferior que usan vainilla y backpropagación guiada para calcular los gradientes. El número de imágenes ( n ) al promedio se selecciona como 50. σ se muestra en la parte inferior de las imágenes.
| Backprop de vainilla | ||
| Backprop guiado | ||
Los filtros CNN se pueden visualizar cuando optimizamos la imagen de entrada con respecto a la salida de la operación de convolución específica. Para este ejemplo, utilicé un VGG16 previamente capacitado. Las visualizaciones de las capas comienzan con filtros básicos de color y dirección en niveles más bajos. A medida que nos acercamos a la capa final, la complejidad de los filtros también aumenta. Si emplea técnicas externas como desenfoque, recorte de gradiente, etc., probablemente producirá mejores imágenes.
| Capa 2 (Conv 1-2) | |||
| Capa 10 (Conv 2-1) | |||
| Capa 17 (Conv 3-1) | |||
| Capa 24 (Conv 4-1) |
Otra forma de visualizar las capas de CNN es visualizar las activaciones para una entrada específica en una capa y filtro específicos. Esto se realizó en [1] Figura 3. El siguiente ejemplo se obtiene de capas/filtros de VGG16 para la primera imagen utilizando backpropagation guiado. El código para estas opeations está en LACE_ACTIVATION_WITH_GUIDED_BACKPROP.PY . El método es bastante similar a la respaldo guiada, pero en lugar de guiar la señal desde la última capa y un objetivo específico, guía la señal desde una capa y filtro específicos.
| Imagen de entrada | Capa vis. (Filtro = 0) | Filtro vis. (Capa = 29) |
Creo que esta técnica es la técnica más compleja en este repositorio en términos de comprender lo que hace el código. Se debe principalmente a la regularización compleja. Si realmente desea comprender cómo se implementa esto, le sugiero que lea la segunda y tercera página del documento [5], específicamente, la parte de regularización. Aquí, el objetivo es generar una imagen original después de la enésima capa. Cuanto más avanzamos en el modelo, más difícil será. Los resultados en el documento son increíblemente buenos (ver Figura 6), pero aquí, el resultado se vuelve rápidamente desordenado a medida que iteramos a través de las capas. Esto se debe a que los autores del papel sintonizaron los parámetros para cada capa individualmente. Puede ajustar los parámetros al igual que los que se dan en el documento para optimizar los resultados para cada capa. Los ejemplos invertidos de varias capas de Alexnet con la imagen de serpiente anterior están a continuación.
| Capa 0: conv2d | Capa 2: Maxpool2d | Capa 4: Relu |
| Capa 7: Relu | Capa 9: Relu | Capa 12: Maxpool2d |
Deep Dream es técnicamente la misma operación que la visualización de la capa, la única diferencia es que no comienzas con una imagen aleatoria, sino que usas una imagen real. Las muestras a continuación se crearon con VGG19 , el resultado producido está completamente a la altura del filtro, por lo que es un poco impredecible. Los modelos más complejos producen características de alto nivel en modo. Si reemplaza VGG19 con una variante de inicio , obtendrá formas más notables cuando se dirige a capas de convivencia más altas. Al igual que la visualización de la capa, si emplea técnicas adicionales como recorte de gradiente, desenfoque, etc., puede obtener mejores visualizaciones.
| Imagen original | |
| VGG19 Capa: 34 (Capa de convención final) Filtro: 94 | |
| VGG19 Capa: 34 (Capa de convención final) Filtro: 103 |
Esta operación produce diferentes salidas basadas en el modelo y el método de regularización aplicada. A continuación, se presentan algunas muestras producidas con VGG19 incorporadas con desenfoque gaussiano cualquier otra iteración (ver [14] para más detalles). La calidad de las imágenes generadas también depende del modelo, Alexnet generalmente tiene artefactos verdes (ISH), pero los VGG producen (una especie de) mejores imágenes. Tenga en cuenta que estas imágenes se generan con CNN regulares con optimización de la entrada y no con GANS .
| Clase objetivo: Worm Snake (52) - (VGG19) | Clase de destino: Spider (72) - (VGG19) |
Las muestras a continuación muestran la imagen producida sin regularización, regularizaciones L1 y L2 en la clase objetivo: Flamingo (130) para mostrar las diferencias entre los métodos de regularización. Estas imágenes se generan con un Alexnet preventivo.
| Sin regularización | L1 Regularización | Regularización de L2 |
Las muestras producidas se pueden optimizar para parecerse a la clase objetivo deseada, algunas de las operaciones que puede incorporar para mejorar la calidad son; Gradientes de recorte y desenfoque que están por debajo de un cierto camión de camarera, cambia de color aleatorio en algunas partes, recortando la imagen al azar, lo que obliga a la imagen generada a seguir un camino para la continuidad de la fuerza.
Algunas de estas técnicas se implementan en Generate_regularized_class_Specific_Samples.py (cortesía de Alexstoken).
torch == 0.4.1
torchvision >= 0.1.9
numpy >= 1.13.0
matplotlib >= 1.5
PIL >= 1.1.7
Si encuentra el código en este repositorio útil para su investigación, considere citarlo.
@misc{uozbulak_pytorch_vis_2022,
author = {Utku Ozbulak},
title = {PyTorch CNN Visualizations},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/utkuozbulak/pytorch-cnn-visualizations}},
commit = {b7e60adaf64c9be97b480509285718603d1e9ba4}
}
[1] JT Springenberg, A. Dosovitskiy, T. Brox y M. Riedmiller. Turning por simplicidad: la red de convolucional , https://arxiv.org/abs/1412.6806
[2] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, A. Torralba. Aprender características profundas para la localización discriminativa , https://arxiv.org/abs/1512.04150
[3] Rr Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh y D. Batra. Grad-Cam: Explicaciones visuales de redes profundas a través de la localización basada en gradientes , https://arxiv.org/abs/1610.02391
[4] K. Simonyan, A. Vedaldi, A. Zisserman. Redes convolucionales profundas: Visualización de modelos de clasificación de imágenes y mapas de prominencia , https://arxiv.org/abs/1312.6034
[5] A. Mahendran, A. Vedaldi. Comprender las representaciones de imágenes profundas invirtiéndolas , https://arxiv.org/abs/1412.0035
[6] H. Noh, S. Hong, B. Han, Red de deconvolución de aprendizaje para la segmentación semántica https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/noh_learning_deconvolution_network_iccv_2015_paper.pdf
[7] A. Nguyen, J. Yosinski, J. Clune. Las redes neuronales profundas se engañan fácilmente: predicciones de alta confianza para imágenes irreconocibles https://arxiv.org/abs/1412.1897
[8] D. Smilkov, N. Thorat, N. Kim, F. Viégas, M. Wattenberg. SmoothGrad: eliminar el ruido agregando ruido https://arxiv.org/abs/1706.03825
[9] D. Erhan, Y. Bengio, A. Courville, P. Vincent. Visualizando las características de la capa superior de una red profunda https://www.researchgate.net/publication/2650222827_visualizing_highere-layer_features_of_a_deep_network
[10] A. Mordvintsev, C. Olah, M. Tyka. Inceptismo: profundizar en las redes neuronales https://research.googleblog.com/2015/06/inceptionism-iring-deeper-into-neural.html
[11] IJ Goodfellow, J. Shlens, C. Szegedy. Explicando y aprovechando ejemplos adversos https://arxiv.org/abs/1412.6572
[12] A. Shrikumar, P. Greenside, A. Shcherbina, A. Kundaje. No solo una caja negra: aprender características importantes a través de diferencias de activación propagación https://arxiv.org/abs/1605.01713
[13] M. Sundararajan, A. Taly, Q. Yan. Atribución axiomática para redes profundas https://arxiv.org/abs/1703.01365
[14] J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, Hod Lipson, Comprensión de las redes neuronales a través de una visualización profunda https://arxiv.org/abs/1506.06579
[15] H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, X. Hu. Puntaje-Cam: explicaciones visuales ponderadas en puntuación para redes neuronales convolucionales https://arxiv.org/abs/1910.01279
[16] P. Jiang, C. Zhang, Q. Hou, M. Cheng, Y. Wei. LayerCam: Explorando mapas de activación de clase jerárquica para la localización http://mmcheng.net/mftp/papers/21tip_layercam.pdf
[17] G. Montavon1, A. Binder, S. Lapuschkin, W. Samek y K. Muller. Propagación de relevancia en forma de capa: una descripción general https://www.researchgate.net/publication/335708351_layer-wise_relevance_propagation_an_overview


