pytorch cnn visualizations
1.0.0
Ce référentiel contient un certain nombre de techniques de visualisation de réseau neuronal convolutionnes implémentées dans Pytorch.
Remarque : J'ai supprimé les dépendances CV2 et déplacé le référentiel vers PIL. Quelques choses pourraient être brisées (bien que j'aie testé toutes les méthodes), j'apprécierais si vous pouviez créer un problème si quelque chose ne fonctionne pas.
Remarque : Le code de ce référentiel a été testé avec la version 0.4.1 de Torch et certaines des fonctions peuvent ne pas fonctionner comme prévu dans les versions ultérieures. Bien que cela ne devrait pas être trop d'efforts pour le faire fonctionner, je n'ai pas l'intention pour le moment de rendre le code dans ce référentiel compatible avec la dernière version car j'utilise toujours 0.4.1.
Selon la technique, le code utilise Alexnet ou VGG pré-entraîné à partir du Zoo Model. Une partie du code suppose également que les couches du modèle sont séparées en deux sections; Caractéristiques , qui contient les couches convolutionnelles et le classificateur , qui contient la couche entièrement connectée (après des convolutions de complisation). Si vous souhaitez porter ce code pour l'utiliser sur votre modèle qui n'a pas une telle séparation, il vous suffit de réaliser un montage sur les pièces où il appelle Model.Features et Model.Classifier .
Chaque technique a son propre fichier Python (par exemple gradcam.py ) qui, je l'espère, rendra les choses plus faciles à comprendre. misc_functions.py contient des fonctions telles que le traitement d'image et les loisirs d'image qui sont partagées par les techniques implémentées.
Toutes les images sont prétraitées avec la moyenne et la MST de l'ensemble de données ImageNet avant d'être alimentées au modèle. Aucun code n'utilise GPU car ces opérations sont assez rapides pour une seule image (sauf pour Deep Dream en raison de l'exemple d'image qui est utilisé pour elle est énorme). Vous pouvez utiliser le GPU avec très peu d'effort. Les exemples d'images ci-dessous incluent des nombres entre parenthèses après la description, comme Mastiff (243) , ce numéro représente l'ID de classe dans l'ensemble de données ImageNet.
J'ai essayé de commenter le code autant que possible, si vous avez des problèmes à le comprendre ou à le porter, n'hésitez pas à envoyer un e-mail ou à créer un problème.
Ci-dessous, quelques résultats d'échantillons pour chaque opération.
| Classe cible: King Snake (56) | Classe cible: Mastiff (243) | Classe cible: Spider (72) | |
| Image originale | |||
| Rétropropagation de vanille colorée | |||
| Saillance de la rétro-propagation à la vanille | |||
| Rétropropagation guidée colorée (GB) | |||
| Saillance guidée sur la rétro-propagation (GB) | |||
| Saillance négative guidée (GB) | |||
| Saillance positive guidée de rétro-propagation (GB) | |||
| Carte d'activation de la classe pondérée (Grad-cam) | |||
| Activation de la classe pondérée (Grad-cam) | |||
| Activation de la classe pondérée par gradient MAUX SUR L'IMAGE (Grad-cam) | |||
| Carte d'activation de classe pondérée en fonction du score (Score-cam) | |||
| Score Ponctionné d'activation de la classe HEATMAP (Score-cam) | |||
| Activation de la classe pondérée en fonction de la marque sur l'image (Score-cam) | |||
| Carte d'activation de la classe de gradient guidée colorée (GROD-GRAD-CAM) | |||
| Saillance de la carte d'activation de la classe pondérée par gradient guidée (GROD-GRAD-CAM) | |||
| Gradients intégrés (sans multiplication d'image) | |||
| Pertinence de couche (LRP) - Couche 7 | |||
| Pertinence de couche (LRP) - Couche 1 |
Layercam [16] est une modification simple de GRAD-CAM [3], qui peut générer des cartes d'activation de classe fiables à partir de différentes couches. Pour les exemples fournis ci-dessous, un VGG16 pré-formé a été utilisé.
| Carte d'activation de la classe | Activation de la classe | Activation de la classe MAUIE CHIEL SUR L'image | |
| LIECCAM (Couche 9) | 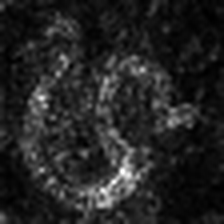 |  | 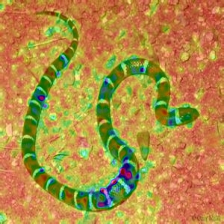 |
| LIECCAM (Couche 16) |  | 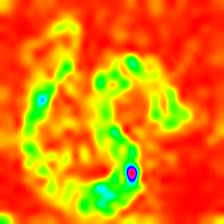 | 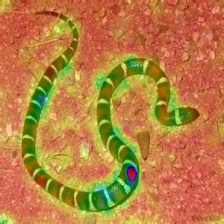 |
| LIECCAM (Couche 23) | 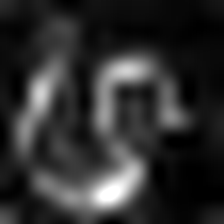 | 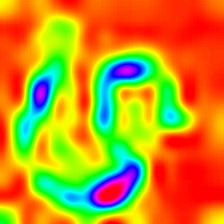 | 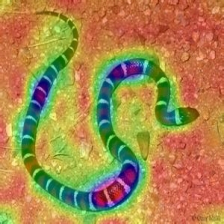 |
| LIECCAM (Couche 30) |  | 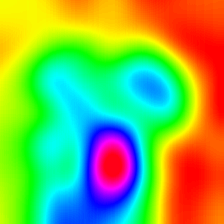 |  |
Une autre technique proposée est simplement de multiplier les gradients avec l'image elle-même. Les résultats obtenus avec l'utilisation de plusieurs techniques de gradient sont ci-dessous.
| Graduelle à la vanille X Image | |||
| Diplômé guidé X Image | |||
| Diplômé intégré X Image |
Smooth Grad ajoute un peu de bruit gaussien à l'image d'origine et calcule plusieurs fois les gradients et la moyenne des résultats [8]. Il y a deux exemples en bas qui utilisent la vanille et la rétro-propagation guidée pour calculer les gradients. Le nombre d'images ( n ) à la moyenne est sélectionné comme 50. σ est montré au bas des images.
| Backprop de vanille | ||
| Backprop guidé | ||
Les filtres CNN peuvent être visualisés lorsque nous optimisons l'image d'entrée par rapport à la sortie de l'opération de convolution spécifique. Pour cet exemple, j'ai utilisé un VGG16 pré-formé. Les visualisations des couches commencent par des filtres de base de couleur et de direction à des niveaux inférieurs. Alors que nous nous approchons de la couche finale, la complexité des filtres augmente également. Si vous utilisez des techniques externes comme le flou, l'élimination du gradient, etc. Vous producherez probablement de meilleures images.
| Couche 2 (Conv 1-2) | |||
| Couche 10 (Conv 2-1) | |||
| Couche 17 (Conv 3-1) | |||
| Couche 24 (Conv 4-1) |
Une autre façon de visualiser les couches CNN consiste à visualiser les activations pour une entrée spécifique sur une couche et un filtre spécifiques. Cela a été fait dans [1] la figure 3. L'exemple ci-dessous est obtenu à partir de couches / filtres de VGG16 pour la première image en utilisant la rétro-propagation guidée. Le code pour ces Opeations est dans couche_activation_with_guided_backprop.py . La méthode est assez similaire à la rétropropagation guidée, mais au lieu de guider le signal de la dernière couche et d'une cible spécifique, il guide le signal à partir d'une couche et d'un filtre spécifiques.
| Image d'entrée | Couche vis. (Filtre = 0) | Filtre vis. (Calque = 29) |
Je pense que cette technique est la technique la plus complexe de ce référentiel en termes de compréhension de ce que fait le code. C'est principalement à cause d'une régularisation complexe. Si vous voulez vraiment comprendre comment cela est mis en œuvre, je vous suggère de lire les deuxième et troisième page du document [5], en particulier, la partie de régularisation. Ici, l'objectif est de générer une image originale après la nième couche. Plus nous allons dans le modèle, plus il devient difficile. Les résultats dans le papier sont incroyablement bons (voir figure 6) mais ici, le résultat devient rapidement désordonné à mesure que nous itons à travers les couches. En effet, les auteurs du papier ont réglé les paramètres pour chaque couche individuellement. Vous pouvez régler les paramètres comme ceux qui sont donnés dans le papier pour optimiser les résultats pour chaque couche. Les exemples inversés de plusieurs couches d' Alexnet avec l'image de serpent précédente sont ci-dessous.
| Couche 0: conv2d | Couche 2: Maxpool2d | Couche 4: relu |
| Couche 7: relu | Couche 9: relu | Couche 12: Maxpool2d |
Deep Dream est techniquement le même opération que la visualisation de la couche. La seule différence est que vous ne commencez pas par une image aléatoire mais utilisez une vraie image. Les échantillons ci-dessous ont été créés avec VGG19 , le résultat produit est entièrement à la hauteur du filtre, il est donc en quelque sorte hit ou manque. Les modèles les plus complexes produisent des fonctionnalités de haut niveau en mode. Si vous remplacez VGG19 par une variante de création , vous obtiendrez des formes plus perceptibles lorsque vous ciblerez des couches Conv plus élevées. Comme la visualisation de la couche, si vous utilisez des techniques supplémentaires comme l'écrasement du gradient, le flou, etc., vous pourriez obtenir de meilleures visualisations.
| Image originale | |
| VGG19 Couche: 34 (Final Conv. Couche) Filtre: 94 | |
| VGG19 Couche: 34 (Final Conv. Couche) Filtre: 103 |
Cette opération produit différentes sorties en fonction du modèle et de la méthode de régularisation appliquée. Ci-dessous, quelques échantillons produits avec VGG19 incorporés avec un flou gaussien toutes les autres itération (voir [14] pour plus de détails). La qualité des images générées dépend également du modèle, Alexnet a généralement des artefacts verts (ish) mais les VGG produisent (un peu) de meilleures images. Notez que ces images sont générées avec des CNN réguliers avec l'optimisation de l'entrée et non avec des Gans .
| Classe cible: Worm Snake (52) - (VGG19) | Classe cible: Spider (72) - (VGG19) |
Les échantillons ci-dessous montrent l'image produite sans régularisation, les régularisations L1 et L2 sur la classe cible: Flamingo (130) pour montrer les différences entre les méthodes de régularisation. Ces images sont générées avec un Alexnet pré-entraîné.
| Aucune régularisation | Régularisation L1 | Régularisation L2 |
Les échantillons produits peuvent en outre être optimisés pour ressembler à la classe cible souhaitée, certaines des opérations que vous pouvez intégrer pour améliorer la qualité sont; Bluring et Clipping Gradients qui sont en dessous d'un certain échange de couleurs aléatoires de Treshold sur certaines parties, en recadrant aléatoire l'image, forçant l'image générée à suivre un chemin pour forcer la continuité.
Certaines de ces techniques sont implémentées dans generate_régulalized_class_specific_sample.py (gracieuseté d'AlexStoken).
torch == 0.4.1
torchvision >= 0.1.9
numpy >= 1.13.0
matplotlib >= 1.5
PIL >= 1.1.7
Si vous trouvez le code dans ce référentiel utile pour votre recherche, envisagez de le citer.
@misc{uozbulak_pytorch_vis_2022,
author = {Utku Ozbulak},
title = {PyTorch CNN Visualizations},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/utkuozbulak/pytorch-cnn-visualizations}},
commit = {b7e60adaf64c9be97b480509285718603d1e9ba4}
}
[1] JT Springlenberg, A. Dosovitskiy, T. Brox et M. Riedmiller. Stroiving For Simplicity: The All Convolutional Net , https://arxiv.org/abs/1412.6806
[2] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, A. Torralba. Apprentissage des caractéristiques profondes pour la localisation discriminatoire , https://arxiv.org/abs/1512.04150
[3] Rr Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh et D. Batra. Grad-CAM: Explications visuelles des réseaux profonds via la localisation basée sur le gradient , https://arxiv.org/abs/1610.02391
[4] K. Simonyan, A. Vedaldi, A. Zisserman. Networks convolutionnels profondément à l'intérieur: visualiser les modèles de classification d'images et les cartes de saillance , https://arxiv.org/abs/1312.6034
[5] A. Mahendran, A. Vedaldi. Comprendre les représentations d'images profondes en les inversant , https://arxiv.org/abs/1412.0035
[6] H. Noh, S. Hong, B. Han, Learning Deconvolution Network for Semantic segmentation https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/noh_learning_deconvolution_network_iccv_2015_paper.pdf
[7] A. Nguyen, J. Yosinski, J. Clune. Les réseaux de neurones profonds sont facilement dupés: des prédictions de confiance élevées pour les images méconnaissables https://arxiv.org/abs/1412.1897
[8] D. Smilkov, N. Thorat, N. Kim, F. Viégas, M. Wattenberg. Smoothrad: Supprimer le bruit en ajoutant du bruit https://arxiv.org/abs/1706.03825
[9] D. Erhan, Y. Bengio, A. Courville, P. Vincent. Visualiser les fonctionnalités de plus haut de couche d'un réseau profond https://www.researchgate.net/publication/265022827_visualizing_higher-ayer_features_of_a_deep_network
[10] A. Mordvintsev, C. Olah, M. Tyka. Inceptionnisme: Aller plus profondément dans les réseaux de neurones https://research.googleblog.com/2015/06/inceptionisme-pin-eeper-into-neural.html
[11] Ij Goodfellow, J. Shlens, C. Szegedy. Expliquer et exploiter des exemples contradictoires https://arxiv.org/abs/1412.6572
[12] A. Shrikumar, P. Greenside, A. Shcherbina, A. Kundaje. Pas seulement une boîte noire: l'apprentissage des fonctionnalités importantes grâce à la propagation des différences d'activation https://arxiv.org/abs/1605.01713
[13] M. Sundararajan, A. Taly, Q. Yan. Attribution axiomatique pour les réseaux profonds https://arxiv.org/abs/1703.01365
[14] J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, Hod Lipson, Comprendre les réseaux de neurones à travers une visualisation profonde https://arxiv.org/abs/1506.06579
[15] H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, X. Hu. Score-Cam: Explications visuelles pondérées en ligne des réseaux de neurones convolutionnels https://arxiv.org/abs/1910.01279
[16] P. Jiang, C. Zhang, Q. Hou, M. Cheng, Y. Wei. LIECCAM: Exploration des cartes d'activation de classe hiérarchiques pour la localisation http://mmcheng.net/mftp/papers/21tip_layercam.pdf
[17] G. Montavon1, A. Binder, S. Lapuschkin, W. Samek et K. Muller. Propagation de pertinence de la couche: un aperçu https://www.researchgate.net/publication/335708351_layer-wise_relevance_propagation_an_overview


