Moodify Emotion Music App
1.0.0
ด้วยการเพิ่มขึ้นของบริการสตรีมมิ่งเพลงส่วนบุคคลมีความต้องการที่เพิ่มขึ้นสำหรับระบบที่สามารถแนะนำเพลงตามสถานะทางอารมณ์ของผู้ใช้ เมื่อตระหนักถึงความต้องการนี้ Moodify ได้รับการพัฒนาโดย Son Nguyen ในปี 2024 เพื่อให้คำแนะนำเพลงส่วนบุคคลตามอารมณ์ที่ตรวจพบของผู้ใช้
โครงการ Moodify เป็นระบบแนะนำเพลงที่ใช้อารมณ์แบบบูรณาการซึ่งรวมส่วนหน้า, แบ็กเอนด์, โมเดล AI/ML และการวิเคราะห์ข้อมูลเพื่อให้คำแนะนำเพลงส่วนบุคคลตามอารมณ์ของผู้ใช้ แอปพลิเคชันวิเคราะห์ข้อความการพูดหรือการแสดงออกทางสีหน้าและแนะนำเพลงที่สอดคล้องกับอารมณ์ที่ตรวจพบ
สนับสนุนทั้งเดสก์ท็อปและแพลตฟอร์มมือถือ Moodify มอบประสบการณ์การใช้งานที่ไร้รอยต่อด้วยการตรวจจับอารมณ์แบบเรียลไทม์และคำแนะนำเพลง โครงการใช้ประโยชน์จาก การตอบสนองสำหรับส่วนหน้า Django สำหรับแบ็กเอนด์และโมเดล AI/ML ที่ได้รับการฝึกอบรมขั้นสูงสามแบบสำหรับการตรวจจับอารมณ์ สคริปต์การวิเคราะห์ข้อมูลใช้เพื่อแสดงภาพแนวโน้มอารมณ์และประสิทธิภาพของโมเดล

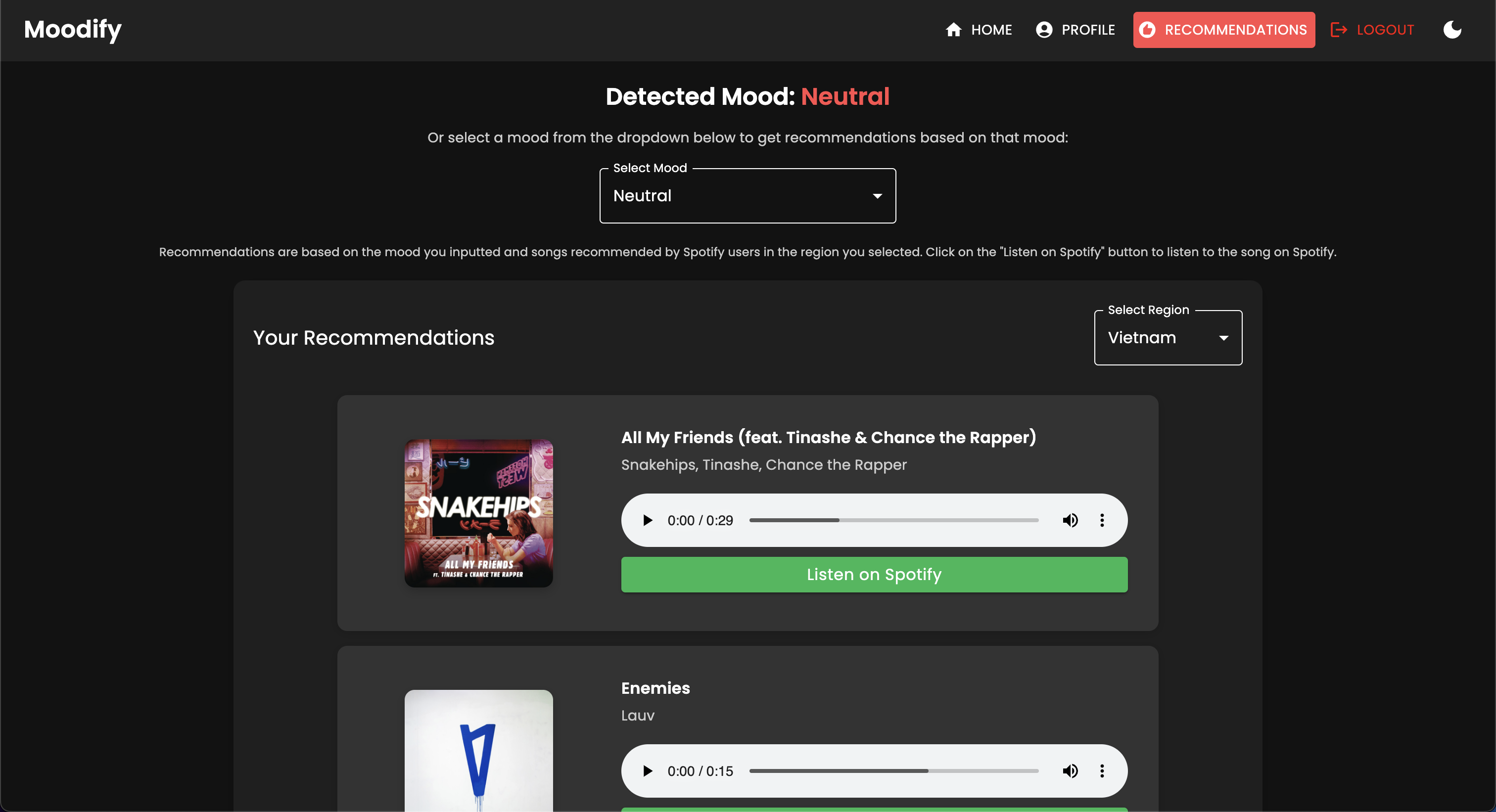
Moodify ให้คำแนะนำทางดนตรีส่วนบุคคลตามสถานะทางอารมณ์ของผู้ใช้ที่ตรวจพบผ่านข้อความการพูดและการแสดงออกทางสีหน้า มันโต้ตอบกับแบ็กเอนด์ที่ใช้ Django, โมเดล AI/ML สำหรับการตรวจจับอารมณ์และใช้การวิเคราะห์ข้อมูลสำหรับข้อมูลเชิงลึกด้านภาพเกี่ยวกับแนวโน้มอารมณ์และประสิทธิภาพของโมเดล
แอพ Moodify กำลังใช้งานอยู่และนำไปใช้กับ Vercel คุณสามารถเข้าถึงแอพสดโดยใช้ลิงค์ต่อไปนี้: Moodify
อย่าลังเลที่จะเยี่ยมชมแบ็กเอนด์ที่ Moodify Backend API
DiClaener: แบ็กเอนด์ของ Moodify ปัจจุบันโฮสต์ด้วย ระดับฟรี ของการเรนเดอร์ดังนั้นอาจใช้เวลาสองสามวินาทีในการโหลดในตอนแรก นอกจากนี้มันอาจหมุนลงหลังจากระยะเวลาที่ไม่มีการใช้งานหรือการจราจรสูงดังนั้นโปรดอดทนหากแบ็กเอนด์ใช้เวลาสองสามวินาทีในการตอบสนอง
นอกจากนี้จำนวนหน่วยความจำที่จัดสรรโดย Render เพียง 512MB ที่มี 0.1 CPU ดังนั้นแบ็กเอนด์อาจหมดหน่วยความจำหากมีคำขอมากเกินไปในครั้งเดียวซึ่งอาจทำให้เซิร์ฟเวอร์รีสตาร์ท นอกจากนี้รูปแบบการตรวจจับอารมณ์ใบหน้าและการพูดอาจล้มเหลวเนื่องจากข้อ จำกัด ของหน่วยความจำ - ซึ่งสามารถทำให้เซิร์ฟเวอร์รีสตาร์ท
ไม่มีการรับประกันการใช้งานหรือประสิทธิภาพด้วยการปรับใช้ปัจจุบันเว้นแต่ว่าฉันมีทรัพยากรเพิ่มเติม (เงิน) เพื่ออัพเกรดเซิร์ฟเวอร์ :( อย่าลังเลที่จะติดต่อฉันหากคุณพบปัญหาใด ๆ หรือต้องการความช่วยเหลือเพิ่มเติม

โครงการมีโครงสร้างไฟล์ที่ครอบคลุมรวมส่วนหน้า, แบ็กเอนด์, โมเดล AI/ML และส่วนประกอบการวิเคราะห์ข้อมูล:
Moodify-Emotion-Music-App/
├── frontend/ # React frontend for the web application
│ ├── public/
│ │ ├── index.html # Main HTML file
│ │ ├── manifest.json # Web app manifest
│ │ └── favicon.ico # Favicon for the app
│ │
│ ├── src/
│ │ ├── components/ # Contains all React components
│ │ ├── pages/ # Contains main pages of the app
│ │ ├── styles/ # Contains global styles and themes
│ │ ├── context/ # Contains React Context API
│ │ ├── App.js # Main App component
│ │ ├── index.js # Entry point for React
│ │ └── theme.js # Material UI theme configuration
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ ├── package.json # NPM dependencies and scripts
│ └── README.md # Project documentation
│
├── backend/ # Django backend for API services and database management
│ ├── manage.py # Django's command-line utility
│ ├── requirements.txt # Backend dependencies
│ ├── backend/
│ │ ├── settings.py # Django settings for the project
│ │ ├── urls.py # URL declarations for the project
│ │ ├── users/ # User management components
│ │ └── api/ # Emotion detection and recommendation APIs
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ └── db.sqlite3 # SQLite database (if used)
│
├── ai_ml/ # AI/ML models for emotion detection
│ ├── data/ # Datasets for training and testing
│ ├── models/ # Trained models for emotion detection
│ ├── src/ # Source files for emotion detection and recommendation
│ │ ├── api/ # API scripts for running emotion detection services
│ │ ├── recommendation/ # Music recommendation logic
│ │ └── data_processing/ # Data preprocessing scripts
│ │
│ ├── Dockerfile # Dockerfile for containerization
│ └── README.md # AI/ML documentation
│
├── data_analytics/ # Data analytics scripts and visualizations
│ ├── emotion_distribution.py # Script for visualizing emotion distribution
│ ├── training_visualization.py # Script for visualizing training and validation metrics
│ ├── predictions_analysis.py # Script for analyzing model predictions
│ ├── recommendation_analysis.py # Script for visualizing music recommendations
│ ├── spark-hadoop/ # Spark and Hadoop integration scripts
│ └── visualizations/ # Generated visualizations
│
├── kubernetes/ # Kubernetes deployment files
│ ├── backend-deployment.yaml # Deployment file for the backend service
│ ├── backend-service.yaml # Deployment file for the backend service
│ ├── frontend-deployment.yaml # Deployment file for the frontend service
│ ├── frontend-service.yaml # Deployment file for the frontend service
│ └── configmap.yaml # ConfigMap for environment variables
│
├── mobile/ # React Native mobile application
│ ├── App.js # Main entry point for React Native app
│ ├── index.js # App registry for React Native
│ ├── package.json # NPM dependencies and scripts
│ ├── components/ # React Native components
│ │ ├── Footer.js # Footer component
│ │ ├── Navbar.js # Header component
│ │ ├── Auth/ # Authentication components (e.g., Login, Register)
│ │ └── Profile/ # Profile-related components
│ │
│ ├── context/ # React Context API for state management
│ │ └── DarkModeContext.js # Dark mode context provider
│ │
│ ├── pages/ # Main pages of the app
│ │ ├── HomePage.js # Home page component
│ │ ├── ProfilePage.js # Profile page component
│ │ ├── ResultsPage.js # Results page component
│ │ ├── LandingPage.js # Landing page component
│ │ └── (and more...)
│ │
│ ├── assets/ # Images, fonts, and other assets
│ ├── styles/ # Styling files (similar to CSS for web)
│ ├── .gitignore # Git ignore file
│ ├── package.json # Dependencies and scripts
│ └── README.md # Mobile app documentation
│
├── nginx/ # NGINX configuration files (for load balancing and reverse proxy)
│ ├── nginx.conf # Main NGINX configuration file
│ └── Dockerfile # Dockerfile for NGINX container
│
├── images/ # Images used in the README documentation
├── docker-compose.yml # Docker Compose file for containerization
└── README.md # Comprehensive README file for the entire project
venv ).env (สำหรับตัวแปรสภาพแวดล้อม - คุณสร้างข้อมูลรับรองของคุณเองตามไฟล์ตัวอย่างหรือติดต่อฉันเพื่อหาของฉัน)เริ่มต้นด้วยการตั้งค่าและฝึกอบรมโมเดล AI/ML เนื่องจากจะต้องใช้สำหรับแบ็กเอนด์เพื่อให้ทำงานได้อย่างถูกต้อง
หรือคุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมมาก่อนได้จากลิงก์ Google Drive ที่มีให้ในส่วนโมเดลที่ผ่านการฝึกอบรมมาก่อน หากคุณเลือกที่จะทำเช่นนั้นคุณสามารถข้ามส่วนนี้ได้ในตอนนี้
โคลนที่เก็บ:
git clone https://github.com/hoangsonww/Moodify-Emotion-Music-App.gitนำทางไปยังไดเรกทอรี AI/ML:
cd Moodify-Emotion-Music-App/ai_mlสร้างและเปิดใช้งานสภาพแวดล้อมเสมือนจริง:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For Windowsติดตั้งการพึ่งพา:
pip install -r requirements.txt แก้ไขการกำหนดค่าในไฟล์ src/config.py :
src/config.py และอัปเดตการกำหนดค่าตามต้องการโดยเฉพาะอย่างยิ่งคีย์ Spotify API ของคุณและกำหนดค่าเส้นทางทั้งหมดsrc/models และอัปเดตเส้นทางไปยังชุดข้อมูลและเส้นทางเอาต์พุตตามต้องการฝึกอบรมโมเดลอารมณ์ความรู้สึก:
python src/models/train_text_emotion.pyทำซ้ำคำสั่งที่คล้ายกันสำหรับโมเดลอื่น ๆ ตามต้องการ (เช่นโมเดลอารมณ์ใบหน้าและเสียงพูด)
ตรวจสอบให้แน่ใจว่ารุ่นที่ผ่านการฝึกอบรมทั้งหมดจะถูกวางไว้ในไดเรกทอรี models และคุณได้ฝึกอบรมโมเดลที่จำเป็นทั้งหมดก่อนที่จะย้ายไปยังขั้นตอนต่อไป!
ทดสอบโมเดล AI/ML ที่ผ่านการฝึกอบรมตามต้องการ :
src/models/test_emotion_models.py เพื่อทดสอบโมเดลที่ผ่านการฝึกอบรมเมื่อโมเดล AI/ML พร้อมให้ดำเนินการตั้งค่าแบ็กเอนด์
นำทางไปยังไดเรกทอรีแบ็กเอนด์:
cd ../backendสร้างและเปิดใช้งานสภาพแวดล้อมเสมือนจริง:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For Windowsติดตั้งการพึ่งพา:
pip install -r requirements.txtกำหนดค่าความลับและสภาพแวดล้อมของคุณ:
.env ในไดเรกทอรี backend.env : SECRET_KEY=your_secret_key
DEBUG=True
ALLOWED_HOSTS=<your_hosts>
MONGODB_URI=<your_mongodb_uri>
backend/settings.py และเพิ่ม SECRET_KEY & Set DEBUG เป็น Trueเรียกใช้การย้ายฐานข้อมูล:
python manage.py migrateเริ่มเซิร์ฟเวอร์ Django:
python manage.py runserver เซิร์ฟเวอร์แบ็กเอนด์จะทำงานที่ http://127.0.0.1:8000/
ในที่สุดตั้งค่าส่วนหน้าเพื่อโต้ตอบกับแบ็กเอนด์
นำทางไปยังไดเรกทอรีส่วนหน้า:
cd ../frontendติดตั้งการพึ่งพาโดยใช้เส้นด้าย:
npm installเริ่มต้นเซิร์ฟเวอร์การพัฒนา:
npm start ส่วนหน้าจะเริ่มต้นที่ http://localhost:3000
หมายเหตุ: หากคุณพบปัญหาใด ๆ หรือต้องการไฟล์ .env ของฉันอย่าลังเลที่จะติดต่อฉัน
| วิธี http | จุดสิ้นสุด | คำอธิบาย |
|---|---|---|
POST | /users/register/ | ลงทะเบียนผู้ใช้ใหม่ |
POST | /users/login/ | เข้าสู่ระบบผู้ใช้และรับโทเค็น JWT |
GET | /users/user/profile/ | ดึงโปรไฟล์ของผู้ใช้ที่ได้รับการรับรองความถูกต้อง |
PUT | /users/user/profile/update/ | อัปเดตโปรไฟล์ของผู้ใช้ที่ได้รับการรับรองความถูกต้อง |
DELETE | /users/user/profile/delete/ | ลบโปรไฟล์ของผู้ใช้ที่ได้รับการรับรองความถูกต้อง |
POST | /users/recommendations/ | บันทึกคำแนะนำสำหรับผู้ใช้ |
GET | /users/recommendations/<str:username>/ | ดึงคำแนะนำสำหรับผู้ใช้ตามชื่อผู้ใช้ |
DELETE | /users/recommendations/<str:username>/<str:recommendation_id>/ | ลบคำแนะนำเฉพาะสำหรับผู้ใช้ |
DELETE | /users/recommendations/<str:username>/ | ลบคำแนะนำทั้งหมดสำหรับผู้ใช้ |
POST | /users/mood_history/<str:user_id>/ | เพิ่มอารมณ์ให้กับประวัติอารมณ์ของผู้ใช้ |
GET | /users/mood_history/<str:user_id>/ | ดึงประวัติอารมณ์สำหรับผู้ใช้ |
DELETE | /users/mood_history/<str:user_id>/ | ลบอารมณ์ที่เฉพาะเจาะจงจากประวัติของผู้ใช้ |
POST | /users/listening_history/<str:user_id>/ | เพิ่มแทร็กในประวัติการฟังของผู้ใช้ |
GET | /users/listening_history/<str:user_id>/ | ดึงประวัติการฟังสำหรับผู้ใช้ |
DELETE | /users/listening_history/<str:user_id>/ | ลบแทร็กเฉพาะจากประวัติของผู้ใช้ |
POST | /users/user_recommendations/<str:user_id>/ | บันทึกคำแนะนำของผู้ใช้ |
GET | /users/user_recommendations/<str:user_id>/ | ดึงคำแนะนำของผู้ใช้ |
DELETE | /users/user_recommendations/<str:user_id>/ | ลบคำแนะนำทั้งหมดสำหรับผู้ใช้ |
POST | /users/verify-username-email/ | ตรวจสอบว่าชื่อผู้ใช้และอีเมลถูกต้องหรือไม่ |
POST | /users/reset-password/ | รีเซ็ตรหัสผ่านของผู้ใช้ |
GET | /users/verify-token/ | ตรวจสอบโทเค็นของผู้ใช้ |
| วิธี http | จุดสิ้นสุด | คำอธิบาย |
|---|---|---|
POST | /api/text_emotion/ | วิเคราะห์ข้อความสำหรับเนื้อหาทางอารมณ์ |
POST | /api/speech_emotion/ | วิเคราะห์คำพูดสำหรับเนื้อหาทางอารมณ์ |
POST | /api/facial_emotion/ | วิเคราะห์การแสดงออกทางสีหน้าเพื่ออารมณ์ |
POST | /api/music_recommendation/ | รับคำแนะนำทางดนตรีตามอารมณ์ |
| วิธี http | จุดสิ้นสุด | คำอธิบาย |
|---|---|---|
GET | /admin/ | เข้าถึงอินเทอร์เฟซผู้ดูแลระบบ Django |
| วิธี http | จุดสิ้นสุด | คำอธิบาย |
|---|---|---|
GET | /swagger/ | เข้าถึงเอกสาร Swagger UI API |
GET | /redoc/ | เข้าถึงเอกสาร API REDOC API |
GET | / | เข้าถึงจุดสิ้นสุดราก API (Swagger UI) |
สร้าง superuser:
python manage.py createsuperuser เข้าถึงแผงผู้ดูแลระบบได้ที่ http://127.0.0.1:8000/admin/
คุณควรดูหน้าเข้าสู่ระบบต่อไปนี้:
API แบ็กเอนด์ของเราล้วนมีเอกสารที่ดีโดยใช้ Swagger UI และ REDOC คุณสามารถเข้าถึงเอกสาร API ได้ที่ URL ต่อไปนี้:
https://moodify-emotion-music-app.onrender.com/swaggerhttps://moodify-emotion-music-app.onrender.com/redocหรือคุณสามารถเรียกใช้เซิร์ฟเวอร์แบ็กเอนด์ในเครื่องและเข้าถึงเอกสาร API ได้ที่จุดสิ้นสุดต่อไปนี้:
http://127.0.0.1:8000/swaggerhttp://127.0.0.1:8000/redocคุณควรเห็นเอกสาร API ต่อไปนี้หากทุกอย่างทำงานอย่างถูกต้อง:
Swagger UI:
redoc:
โมเดล AI/ML ถูกสร้างขึ้นโดยใช้ Pytorch, Tensorflow, Keras และ HuggingFace Transformers แบบจำลองเหล่านี้ได้รับการฝึกฝนในชุดข้อมูลต่าง ๆ เพื่อตรวจจับอารมณ์จากข้อความการพูดและการแสดงออกทางสีหน้า
แบบจำลองการตรวจจับอารมณ์ใช้เพื่อวิเคราะห์อินพุตของผู้ใช้และให้คำแนะนำเพลงแบบเรียลไทม์ตามอารมณ์ที่ตรวจพบ แบบจำลองได้รับการฝึกฝนในชุดข้อมูลต่าง ๆ เพื่อจับภาพความแตกต่างของอารมณ์ของมนุษย์และให้การคาดการณ์ที่แม่นยำ
โมเดลถูกรวมเข้ากับบริการแบ็กเอนด์ API เพื่อให้การตรวจจับอารมณ์แบบเรียลไทม์และคำแนะนำเพลงสำหรับผู้ใช้
แบบจำลองจะต้องได้รับการฝึกอบรมก่อนที่จะใช้ในบริการแบ็กเอนด์ ตรวจสอบให้แน่ใจว่าโมเดลได้รับการฝึกฝนและวางไว้ในไดเรกทอรี models ก่อนที่จะเรียกใช้เซิร์ฟเวอร์แบ็กเอนด์ อ้างถึงส่วน (เริ่มต้น) [#เริ่มต้น] สำหรับรายละเอียดเพิ่มเติม
 ตัวอย่างของการฝึกอบรมแบบจำลองอารมณ์ความรู้สึก
ตัวอย่างของการฝึกอบรมแบบจำลองอารมณ์ความรู้สึก
ในการฝึกอบรมโมเดลคุณสามารถเรียกใช้สคริปต์ที่ให้ไว้ในไดเรกทอรี ai_ml/src/models สคริปต์เหล่านี้ใช้ในการประมวลผลข้อมูลล่วงหน้าฝึกอบรมโมเดลและบันทึกโมเดลที่ผ่านการฝึกอบรมมาใช้ในภายหลัง สคริปต์เหล่านี้รวมถึง:
train_text_emotion.py : ฝึกฝนรูปแบบการตรวจจับอารมณ์ความรู้สึกtrain_speech_emotion.py : ฝึกฝนรูปแบบการตรวจจับอารมณ์ความรู้สึกtrain_facial_emotion.py : ฝึกอบรมรูปแบบการตรวจจับอารมณ์ใบหน้า ตรวจสอบให้แน่ใจว่าคุณมีการพึ่งพาชุดข้อมูลและการกำหนดค่าที่จำเป็นก่อนการฝึกอบรมแบบจำลอง โดยเฉพาะตรวจสอบให้แน่ใจว่าได้เยี่ยมชมไฟล์ config.py และอัปเดตพา ธ ไปยังชุดข้อมูลและไดเรกทอรีเอาต์พุตไปยังไฟล์ที่ถูกต้องในระบบของคุณ
หมายเหตุ: โดยค่าเริ่มต้นสคริปต์เหล่านี้จะจัดลำดับความสำคัญโดยใช้ GPU ของคุณด้วย CUDA (ถ้ามี) สำหรับการฝึกอบรมที่เร็วขึ้น อย่างไรก็ตามหากไม่สามารถใช้งานได้ในเครื่องของคุณสคริปต์จะถอยกลับไปใช้ CPU โดยอัตโนมัติสำหรับการฝึกอบรม เพื่อให้แน่ใจว่าคุณมีการพึ่งพาที่จำเป็นสำหรับการฝึกอบรม GPU ให้ติดตั้ง pytorch ด้วยการสนับสนุน CUDA โดยใช้คำสั่งต่อไปนี้:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 หลังจากนั้นคุณสามารถเรียกใช้สคริปต์ test_emotion_models.py เพื่อทดสอบโมเดลที่ผ่านการฝึกอบรมและตรวจสอบให้แน่ใจว่าพวกเขาให้การคาดการณ์ที่ถูกต้อง:
python src/models/test_emotion_models.pyอีกทางเลือกหนึ่งคุณสามารถเรียกใช้ Flask API แบบง่ายเพื่อทดสอบโมเดลผ่านจุดสิ้นสุดของ RESTFUL API:
python ai_ml/src/api/emotion_api.pyจุดสิ้นสุดมีดังนี้:
/text_emotion : ตรวจจับอารมณ์จากอินพุตข้อความ/speech_emotion : ตรวจจับอารมณ์จากเสียงพูด/facial_emotion : ตรวจจับอารมณ์จากภาพ/music_recommendation : ให้คำแนะนำทางดนตรีตามอารมณ์ที่ตรวจพบ สำคัญ : สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการฝึกอบรมและการใช้แบบจำลองโปรดดูเอกสาร AI/ML ในไดเรกทอรี ai_ml
อย่างไรก็ตามหากการฝึกอบรมโมเดลนั้นใช้ทรัพยากรมากเกินไปคุณสามารถใช้ลิงก์ Google ไดรฟ์ต่อไปนี้เพื่อดาวน์โหลดรุ่นที่ผ่านการฝึกอบรมมาก่อน:
model.safetensors โปรดดาวน์โหลดไฟล์ model.safetensors และวางลงในไดเรกทอรี ai_ml/models/text_emotion_modelscaler.pkl โปรดดาวน์โหลดสิ่งนี้และวางสิ่งนี้ลงในไดเรกทอรี ai_ml/models/speech_emotion_modeltrained_speech_emotion_model.pkl โปรดดาวน์โหลดสิ่งนี้และวางสิ่งนี้ลงในไดเรกทอรี ai_ml/models/speech_emotion_modeltrained_facial_emotion_model.pt โปรดดาวน์โหลดสิ่งนี้และวางสิ่งนี้ลงในไดเรกทอรี ai_ml/models/facial_emotion_model สิ่งเหล่านี้ได้รับการฝึกอบรมล่วงหน้าในชุดข้อมูลสำหรับคุณและพร้อมที่จะใช้ในบริการแบ็กเอนด์หรือเพื่อการทดสอบเมื่อดาวน์โหลดและวางไว้อย่างถูกต้องในไดเรกทอรี models
อย่าลังเลที่จะติดต่อฉันหากคุณพบปัญหาใด ๆ หรือต้องการความช่วยเหลือเพิ่มเติมกับโมเดล AI/ML
โฟลเดอร์ data_analytics ให้การวิเคราะห์ข้อมูลและสคริปต์การสร้างภาพเพื่อรับข้อมูลเชิงลึกเกี่ยวกับประสิทธิภาพของโมเดลการตรวจจับอารมณ์
เรียกใช้สคริปต์การวิเคราะห์ทั้งหมด:
python data_analytics/main.py ดูการสร้างภาพข้อมูลที่สร้างขึ้นในโฟลเดอร์ visualizations
นี่คือตัวอย่างการสร้างภาพข้อมูล:
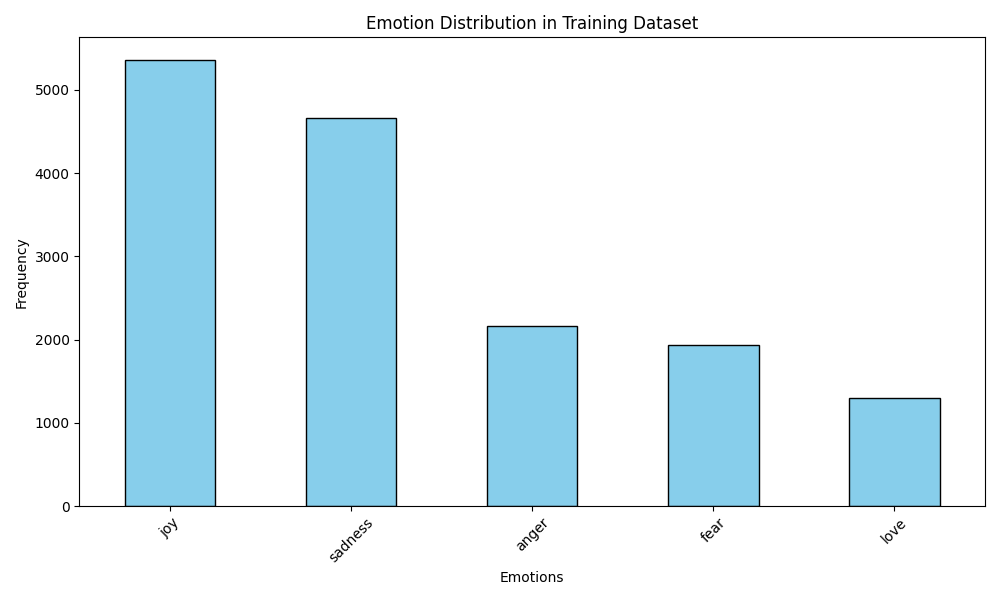 การสร้างภาพการกระจายอารมณ์
การสร้างภาพการกระจายอารมณ์
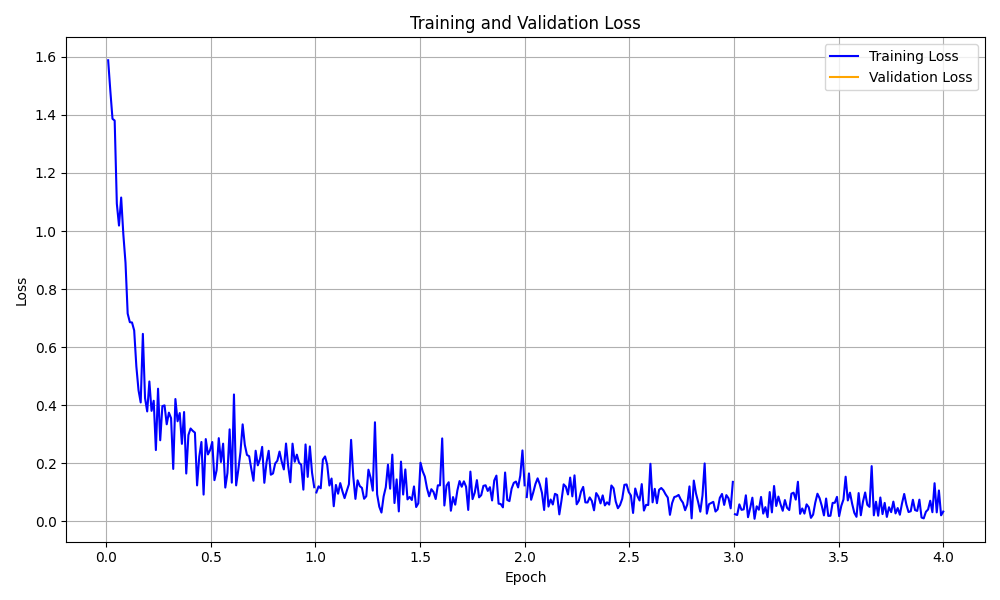 การสร้างภาพโค้งการสูญเสียการฝึกอบรม
การสร้างภาพโค้งการสูญเสียการฝึกอบรม
นอกจากนี้ยังมีแอพ Moodify รุ่นมือถือที่สร้างขึ้นโดยใช้ React Native และ Expo คุณสามารถค้นหาแอพมือถือในไดเรกทอรี mobile
นำทางไปยังไดเรกทอรีมือถือ:
cd ../mobileติดตั้งการพึ่งพาโดยใช้เส้นด้าย:
yarn installเริ่มต้นเซิร์ฟเวอร์การพัฒนางานแสดงสินค้า:
yarn startสแกนรหัส QR โดยใช้แอพ Expo Go บนอุปกรณ์มือถือของคุณเพื่อเรียกใช้แอพ
หากประสบความสำเร็จคุณควรเห็นหน้าจอหลักต่อไปนี้:
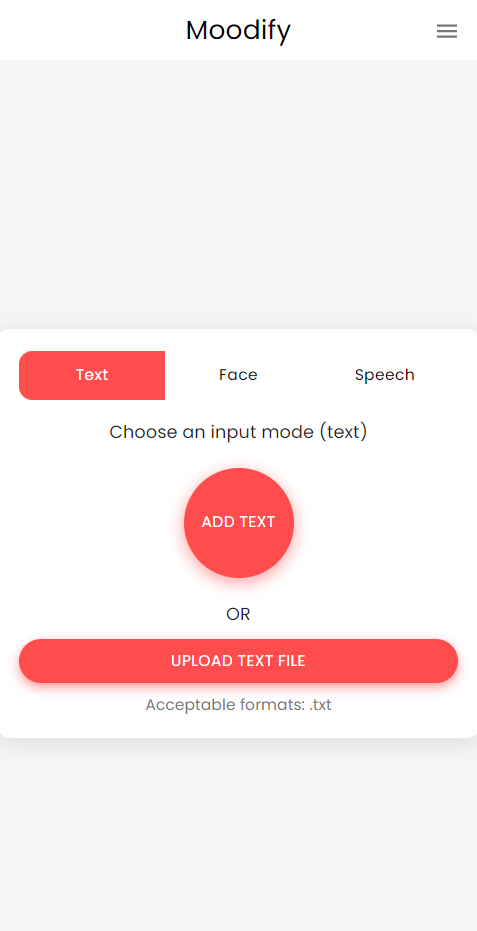
อย่าลังเลที่จะสำรวจแอพมือถือและทดสอบฟังก์ชันการทำงาน!
โครงการใช้ Nginx และ Gunicorn สำหรับการโหลดบาลานซ์และให้บริการแบ็กเอนด์ Django Nginx ทำหน้าที่เป็นพร็อกซีเซิร์ฟเวอร์ย้อนกลับในขณะที่ Gunicorn ให้บริการแอปพลิเคชัน Django
ติดตั้ง nginx:
sudo apt-get update
sudo apt-get install nginxติดตั้ง Gunicorn:
pip install gunicornกำหนดค่า nginx:
/nginx/nginx.conf พร้อมการกำหนดค่าของคุณเริ่ม Nginx และ Gunicorn:
sudo systemctl start nginxgunicorn backend.wsgi:application เข้าถึงแบ็กเอนด์ที่ http://<server_ip>:8000/
อย่าลังเลที่จะปรับแต่งการกำหนดค่า NGINX และการตั้งค่า gunicorn ตามต้องการสำหรับการปรับใช้ของคุณ
โครงการสามารถบรรจุได้โดยใช้ Docker เพื่อการปรับใช้และปรับขนาดได้ง่าย คุณสามารถสร้างภาพ Docker สำหรับรุ่น Frontend, Backend และ AI/ML
สร้างภาพนักเทียบท่า:
docker compose up --buildภาพนักเทียบท่าจะถูกสร้างขึ้นสำหรับรุ่นส่วนหน้าแบ็กเอนด์และ AI/ML ตรวจสอบภาพโดยใช้:
docker imagesหากคุณพบข้อผิดพลาดใด ๆ ลองสร้างภาพของคุณใหม่โดยไม่ต้องใช้แคชเนื่องจากแคชของ Docker อาจทำให้เกิดปัญหา
docker-compose build --no-cacheนอกจากนี้เรายังเพิ่มไฟล์การปรับใช้ Kubernetes สำหรับบริการแบ็กเอนด์และส่วนหน้า คุณสามารถปรับใช้บริการบนคลัสเตอร์ Kubernetes โดยใช้ไฟล์ YAML ที่ให้ไว้
ปรับใช้บริการแบ็กเอนด์:
kubectl apply -f kubernetes/backend-deployment.yamlปรับใช้บริการส่วนหน้า:
kubectl apply -f kubernetes/frontend-deployment.yamlเปิดเผยบริการ:
kubectl expose deployment moodify-backend --type=LoadBalancer --port=8000
kubectl expose deployment moodify-frontend --type=LoadBalancer --port=3000เข้าถึงบริการโดยใช้ LoadBalancer IP:
http://<backend_loadbalancer_ip>:8000http://<frontend_loadbalancer_ip>:3000 อย่าลังเลที่จะเยี่ยมชมไดเรกทอรี kubernetes สำหรับข้อมูลเพิ่มเติมเกี่ยวกับไฟล์การปรับใช้และการกำหนดค่า
นอกจากนี้เรายังได้รวมสคริปต์ไปป์ไลน์ของเจนกินส์สำหรับการสร้างกระบวนการสร้างและการปรับใช้โดยอัตโนมัติ คุณสามารถใช้เจนกินส์เพื่อทำให้กระบวนการ CI/CD เป็นไปโดยอัตโนมัติสำหรับแอพ Moodify
ติดตั้งเจนกินส์บนเซิร์ฟเวอร์หรือเครื่องในท้องถิ่นของคุณ
สร้างงานท่อส่งเจนกินส์ใหม่:
Jenkinsfile ในไดเรกทอรี jenkinsเรียกใช้ท่อเจนกินส์:
อย่าลังเลที่จะสำรวจสคริปต์ท่อเจนกินส์ใน Jenkinsfile และปรับแต่งตามที่จำเป็นสำหรับกระบวนการปรับใช้ของคุณ
ยินดีต้อนรับ! อย่าลังเลที่จะแยกที่เก็บและส่งคำขอดึง
โปรดทราบว่าโครงการนี้ยังอยู่ระหว่างการพัฒนาที่ใช้งานอยู่และการมีส่วนร่วมใด ๆ ที่ได้รับการชื่นชม
หากคุณมีข้อเสนอแนะใด ๆ คำขอคุณสมบัติหรือรายงานข้อผิดพลาดอย่าลังเลที่จะเปิดปัญหาที่นี่
การเขียนโค้ดที่มีความสุขและ Vibin '! -
สร้างขึ้นด้วย❤โดยลูกชายเหงียนในปี 2567
- กลับไปด้านบน


