Moodify Emotion Music App
1.0.0
Avec la montée en puissance des services de streaming de musique personnalisés, il existe un besoin croissant de systèmes qui peuvent recommander de la musique basée sur les états émotionnels des utilisateurs. Réalisant ce besoin, MoodIfy est développé par Son Nguyen en 2024 pour fournir des recommandations musicales personnalisées basées sur les émotions détectées par les utilisateurs.
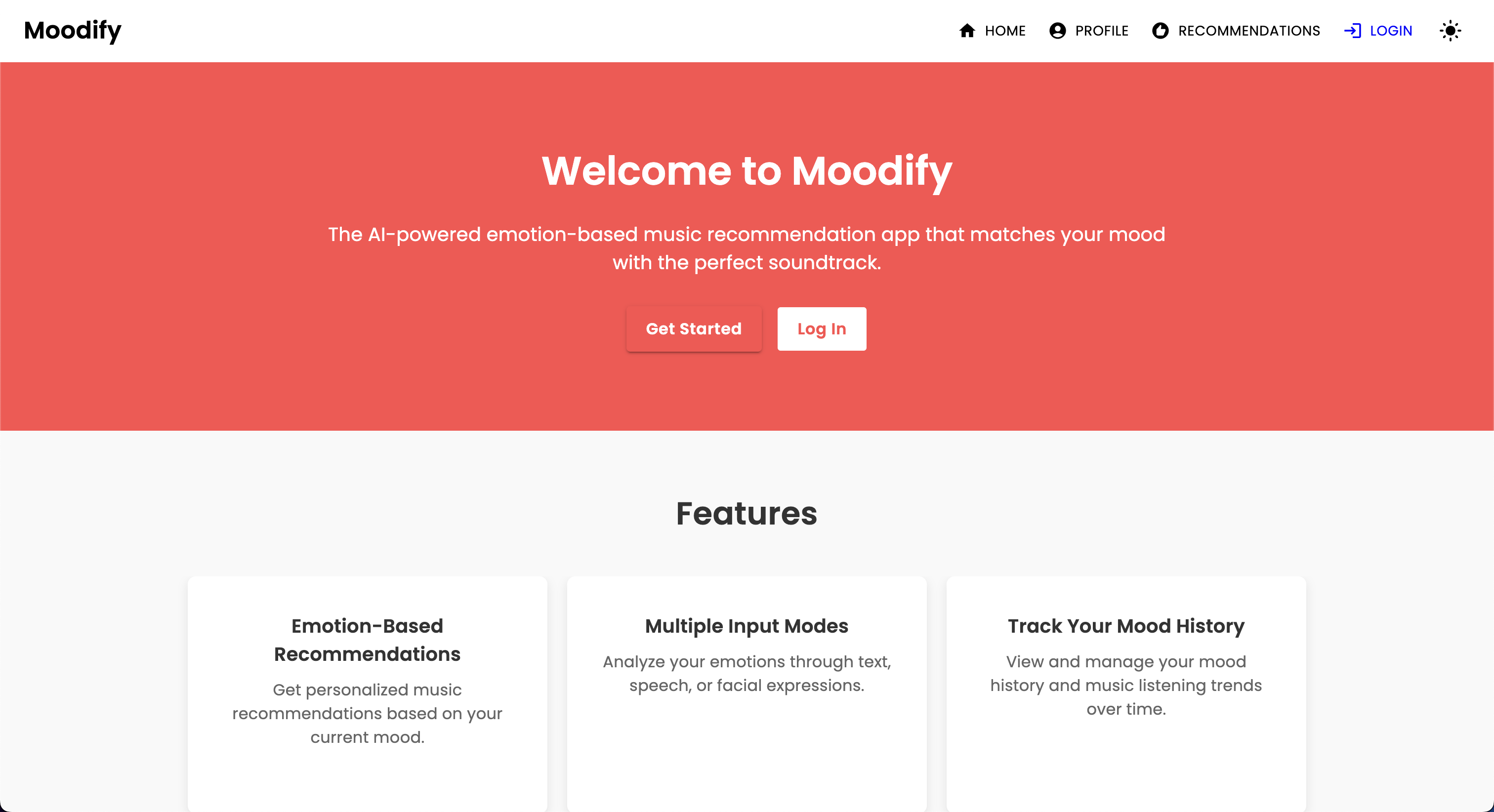
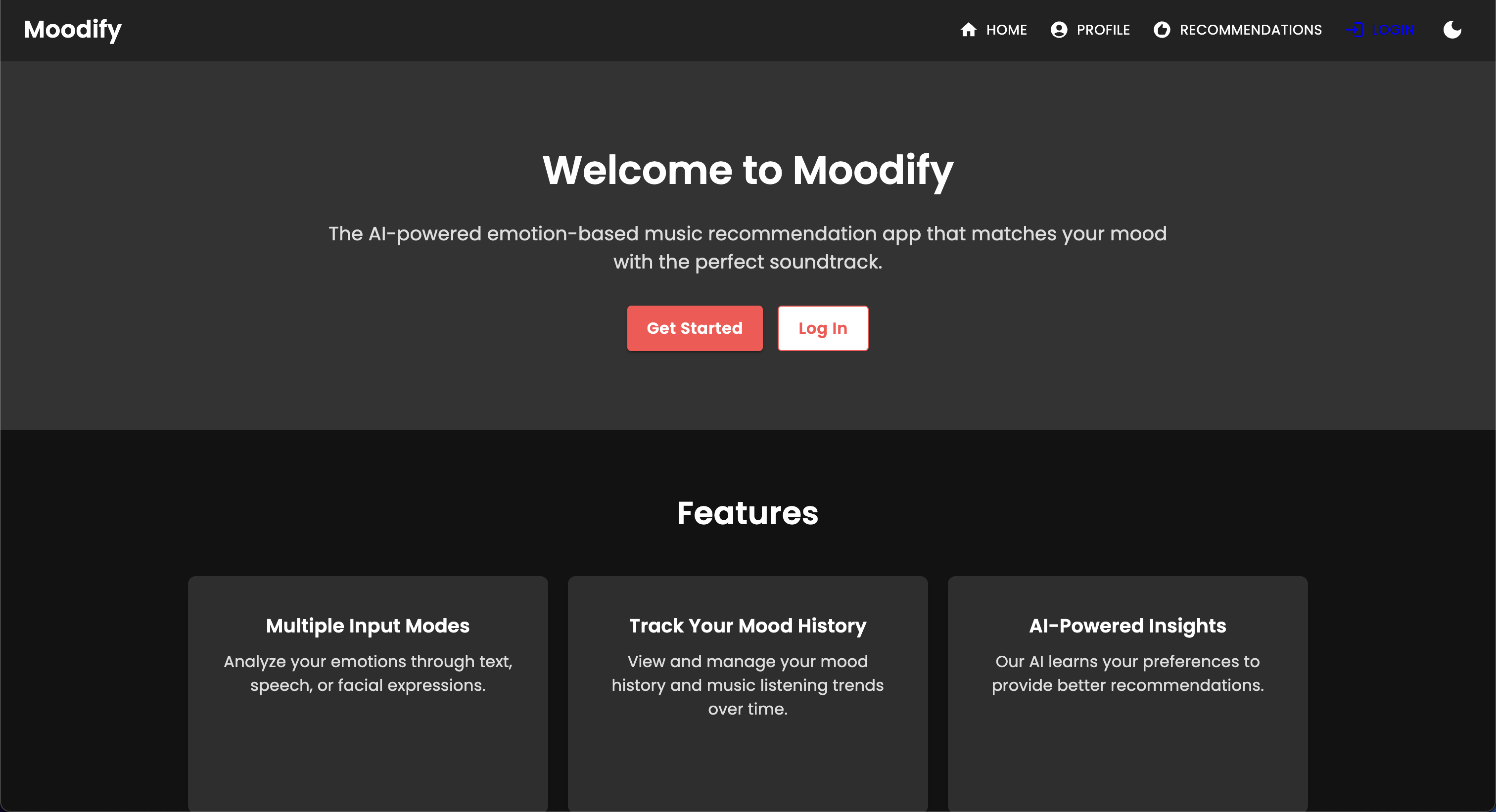
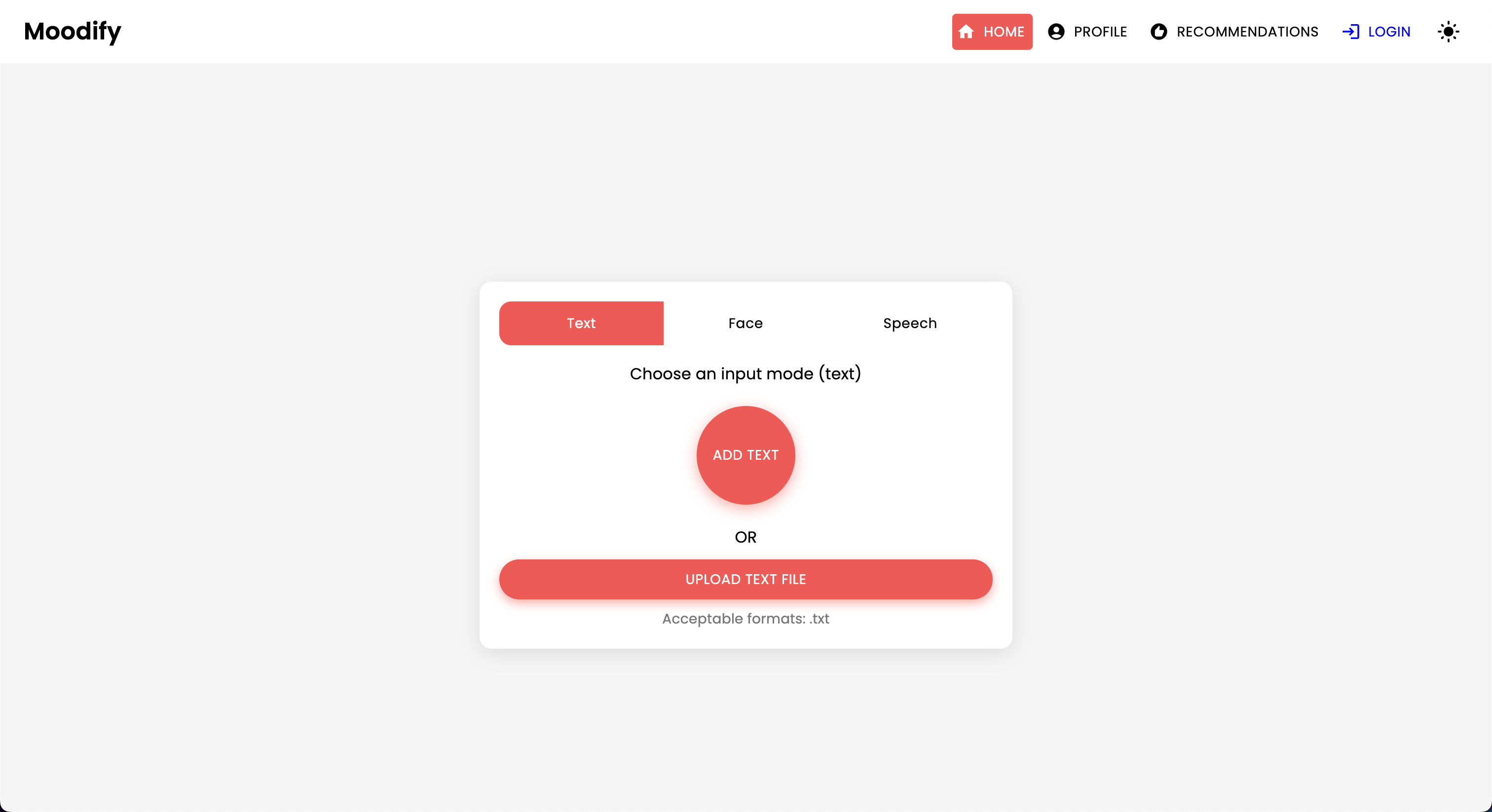
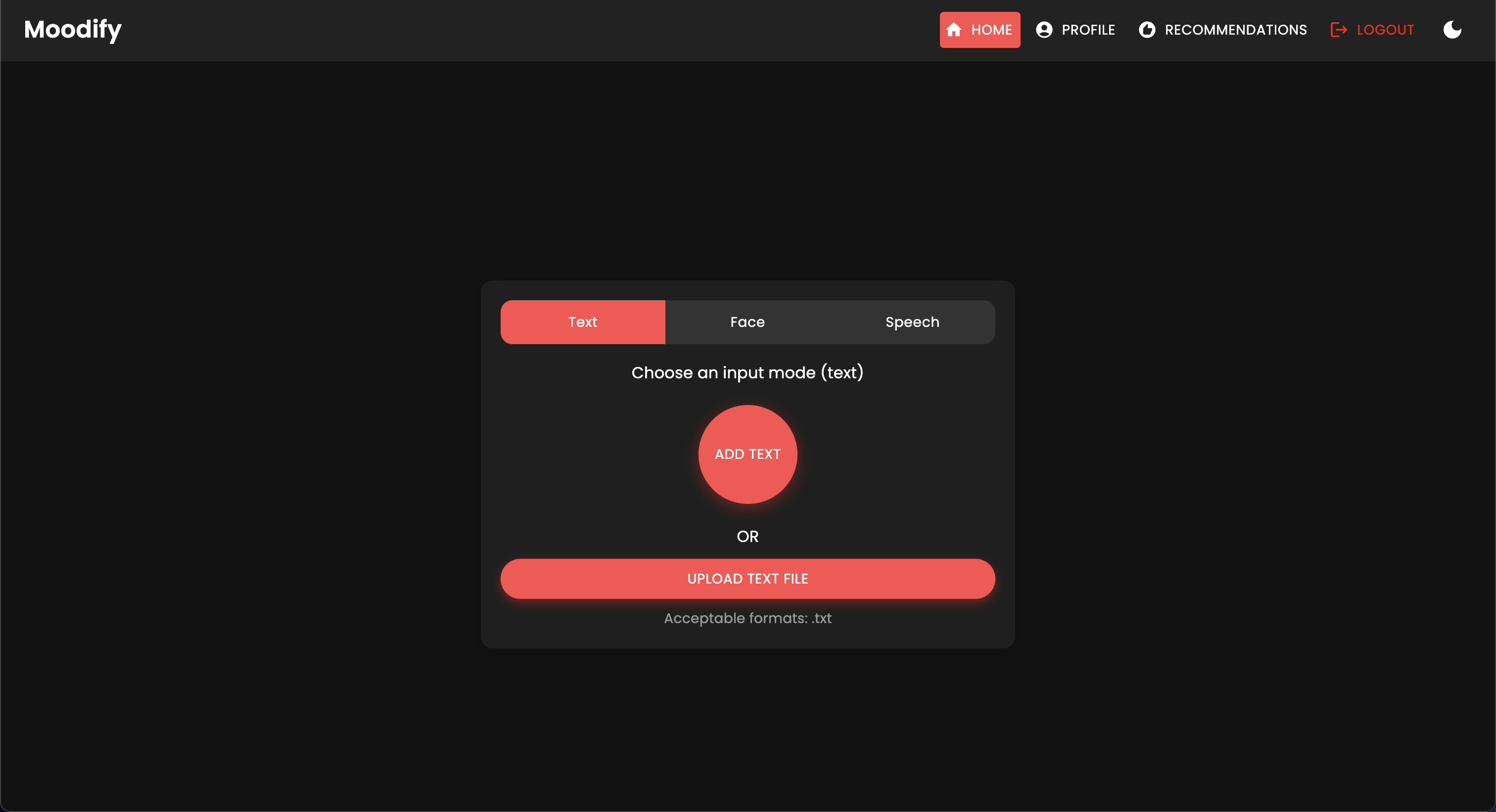
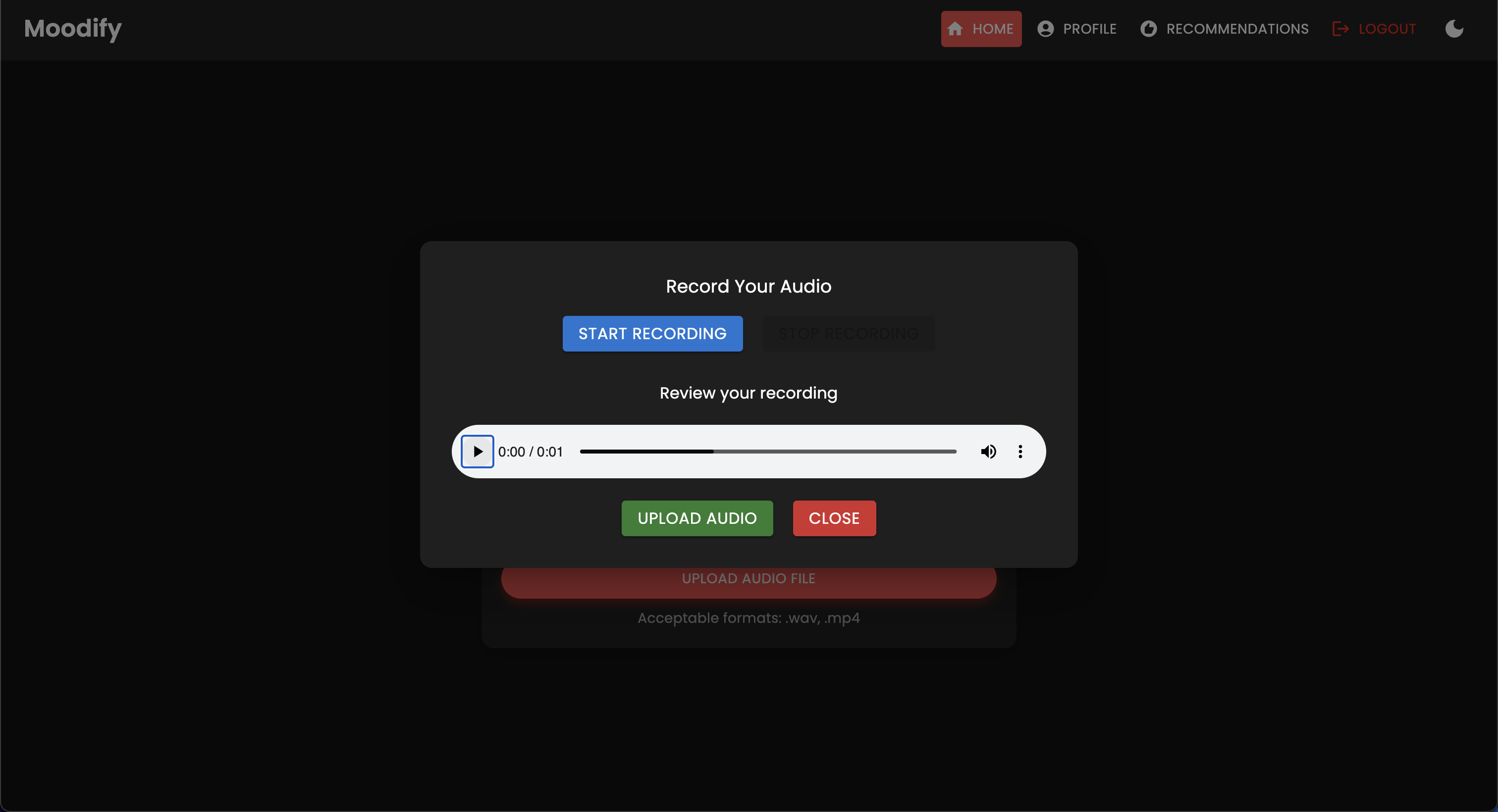
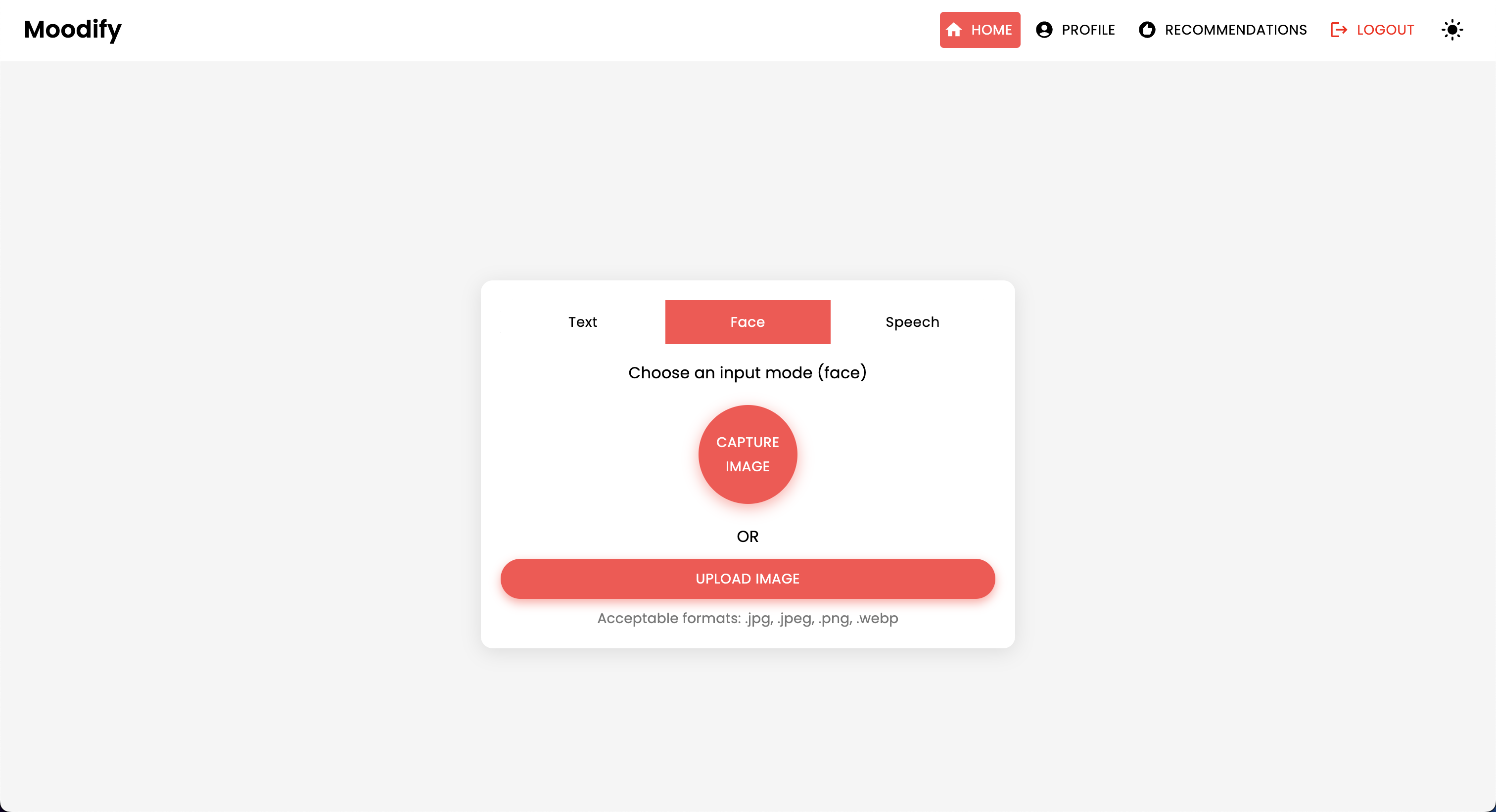
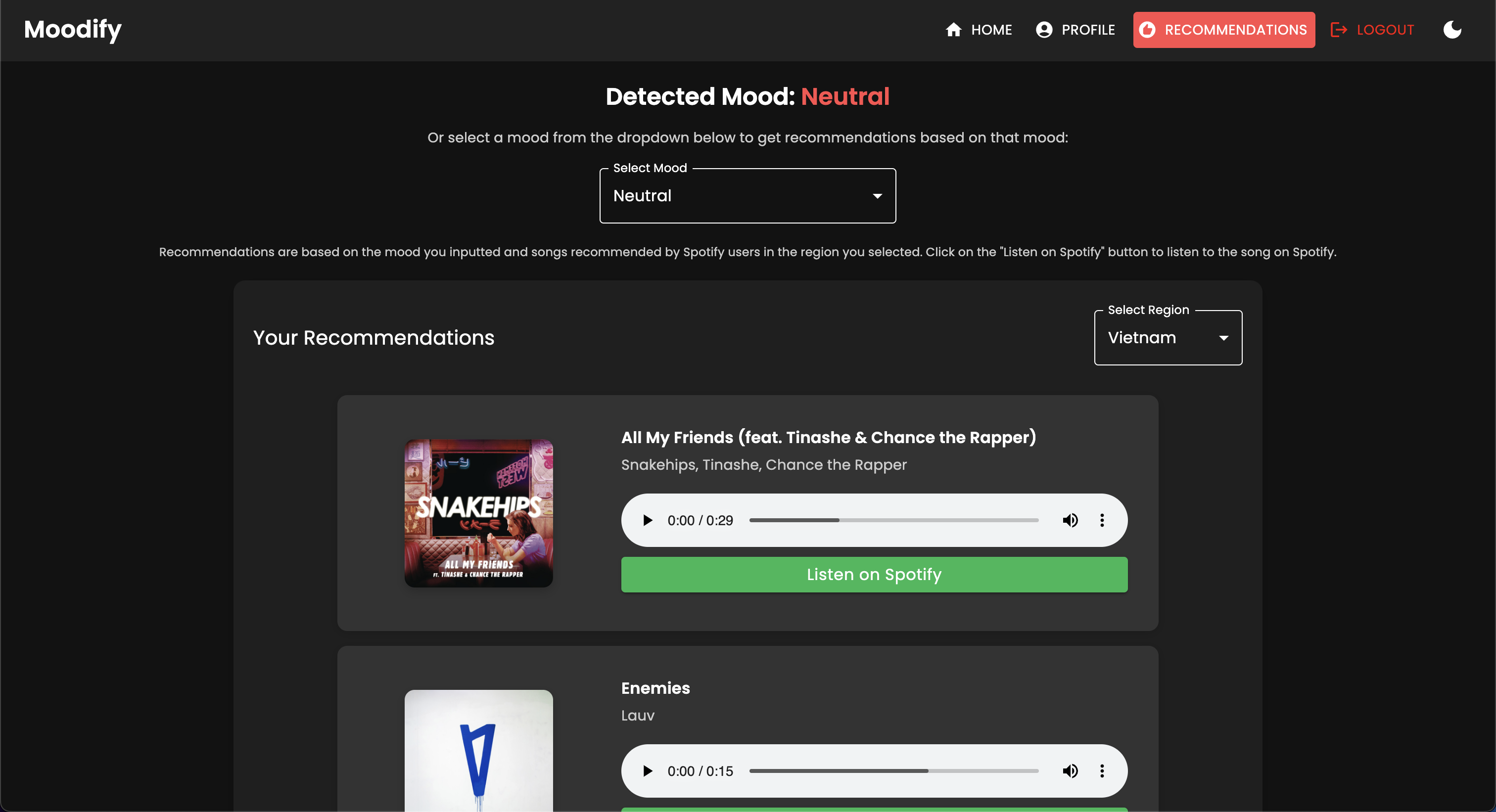
Le projet MoodIfy est un système de recommandation de musique intégré basé sur des émotions qui combine des modèles frontal, backend, AI / ML et analyse de données pour fournir des recommandations musicales personnalisées basées sur les émotions des utilisateurs. L'application analyse le texte, la parole ou les expressions faciales et suggère de la musique qui s'aligne sur les émotions détectées.
Soutenant les plates-formes de bureau et mobiles, MoodIfy offre une expérience utilisateur transparente avec des recommandations de détection d'émotions en temps réel et de musique. Les mots de mise à profit du projet réagissent pour le frontend, Django pour le backend et trois modèles AI / ML avancés et auto-formés pour la détection des émotions . Les scripts d'analyse de données sont utilisés pour visualiser les tendances des émotions et le modèle des performances.

MoodIfy fournit des recommandations musicales personnalisées basées sur les états émotionnels des utilisateurs détectés par le texte, la parole et les expressions faciales. Il interagit avec un backend basé sur Django, des modèles AI / ML pour la détection des émotions, et utilise l'analyse des données pour les informations visuelles sur les tendances des émotions et les performances du modèle.
L'application MoodIfy est actuellement en direct et déployée sur Vercel. Vous pouvez accéder à l'application en direct en utilisant le lien suivant: MoodIFIE.
N'hésitez pas à visiter également l'API Backend à MoodIfy Backend.
DiClaimer: Le backend de MoodIfy est actuellement hébergé avec le niveau gratuit de rendu, il peut donc prendre quelques secondes pour se charger initialement. De plus, il peut tourner après une période d'inactivité ou de trafic élevé, alors soyez patient si le backend prend quelques secondes pour répondre.
De plus, la quantité de mémoire allouée par rendu n'est que de 512 Mo avec 0,1 CPU , donc le backend peut manquer de mémoire s'il y a trop de demandes à la fois, ce qui peut entraîner le redémarrage du serveur. En outre, les modèles de détection des émotions faciales et de parole peuvent également échouer en raison de contraintes de mémoire - ce qui peut également entraîner le redémarrage du serveur.
Il n'y a aucune garantie de disponibilité ou de performance avec le déploiement actuel, sauf si j'ai plus de ressources (argent) pour mettre à niveau le serveur :( N'hésitez pas à me contacter si vous rencontrez des problèmes ou si vous avez besoin d'aide.
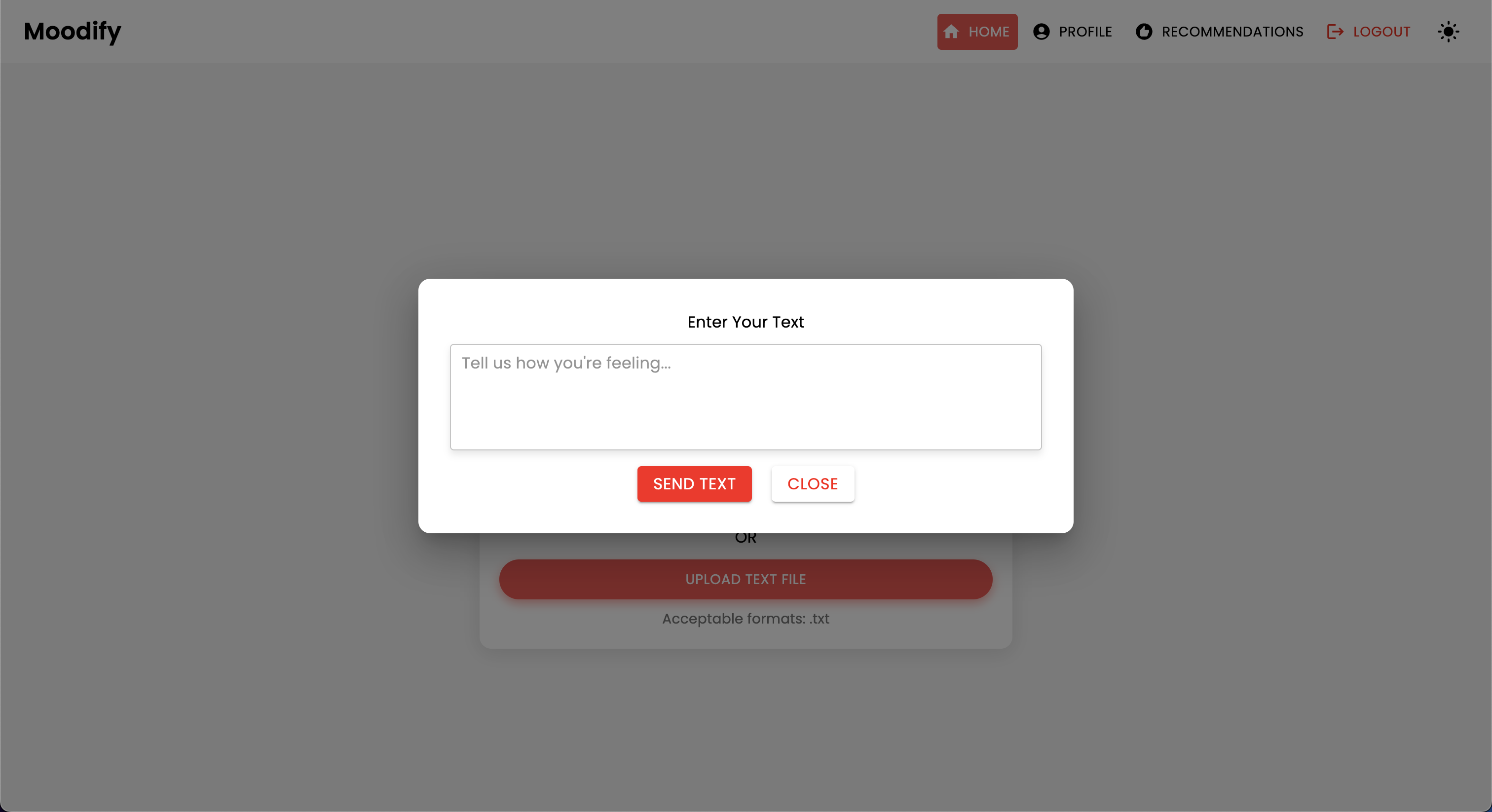
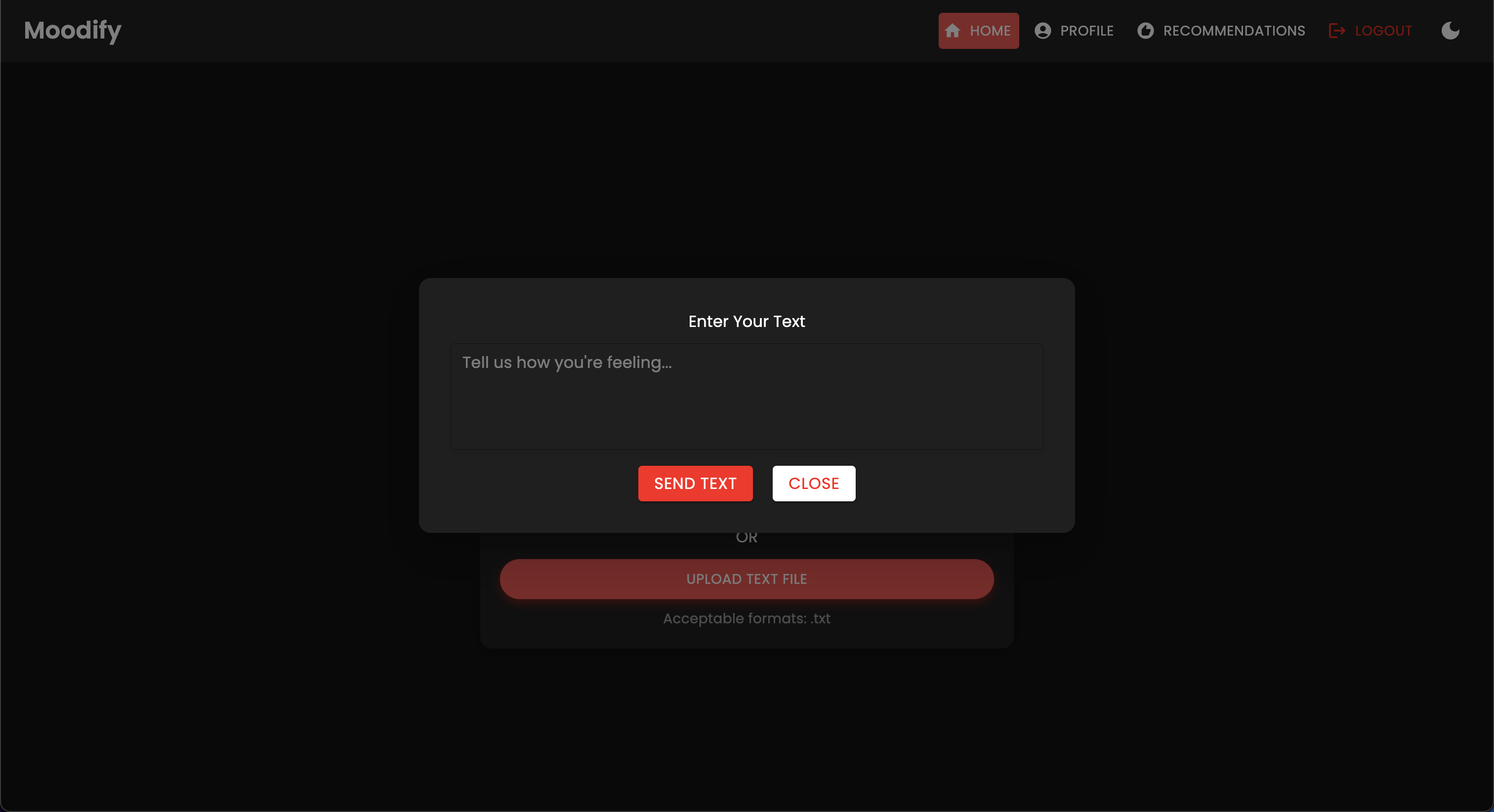
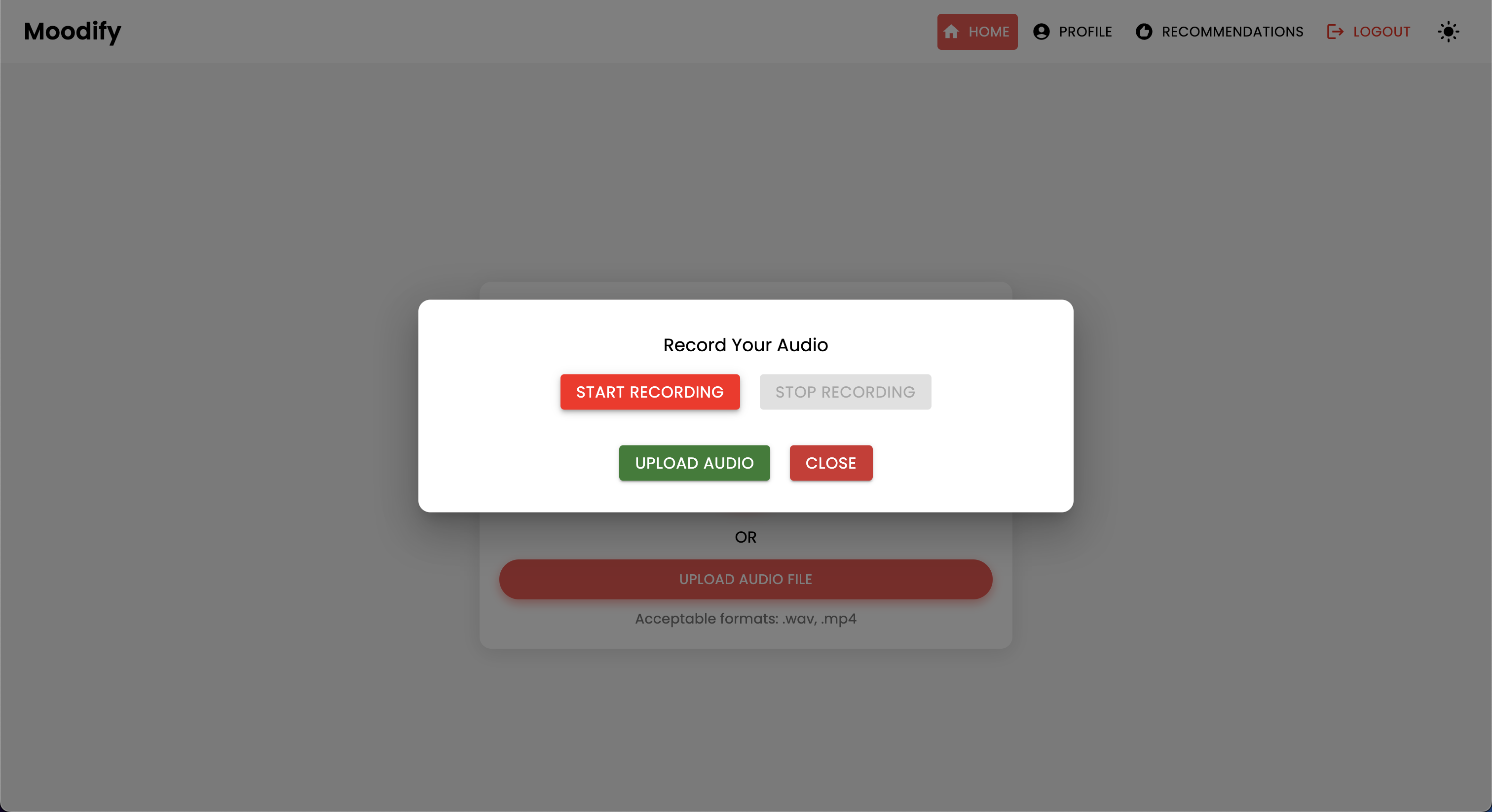
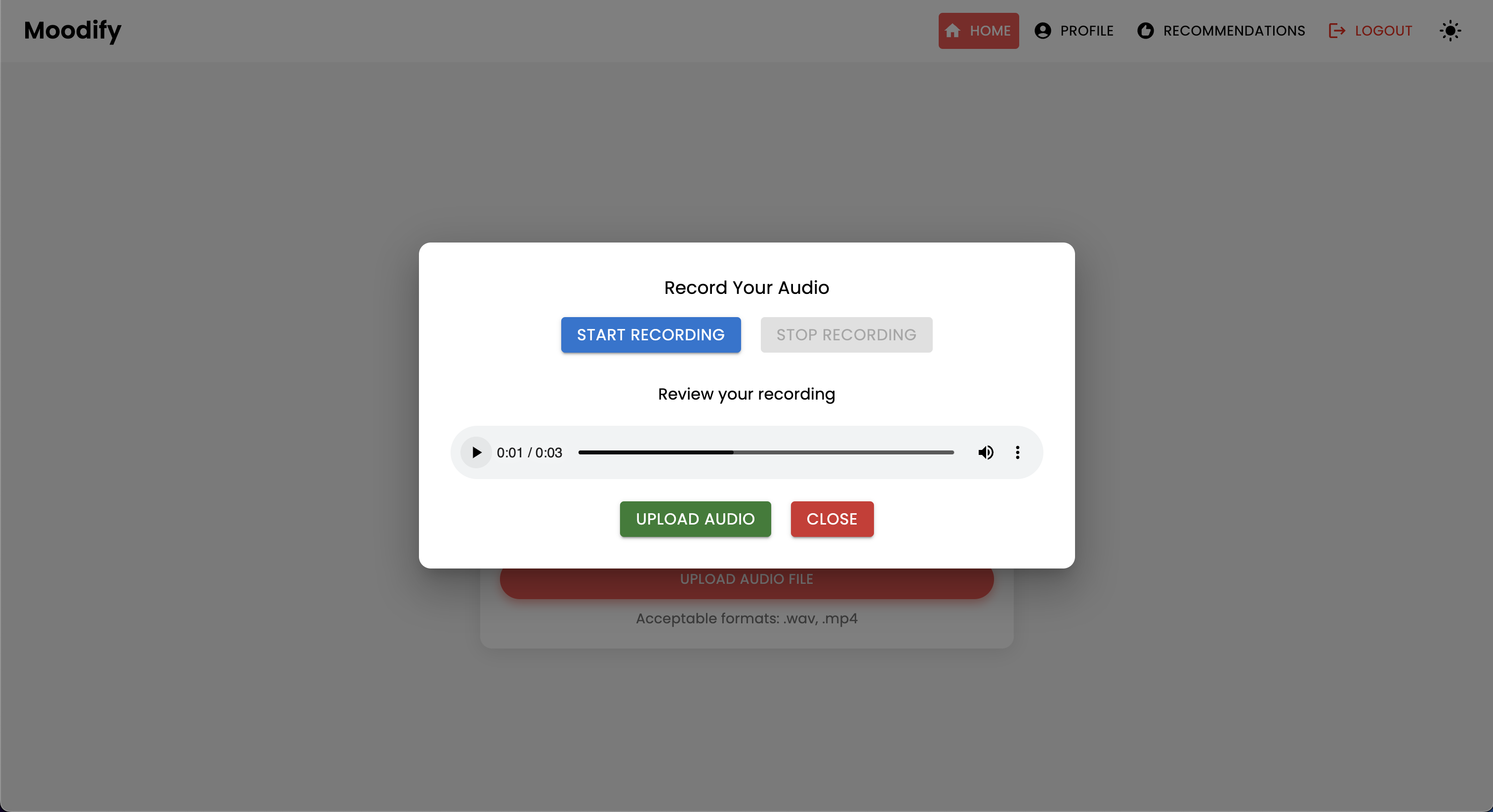

Le projet dispose d'une structure de fichiers complète combinant les modèles frontaux, backend, AI / ML et composants d'analyse de données:
Moodify-Emotion-Music-App/
├── frontend/ # React frontend for the web application
│ ├── public/
│ │ ├── index.html # Main HTML file
│ │ ├── manifest.json # Web app manifest
│ │ └── favicon.ico # Favicon for the app
│ │
│ ├── src/
│ │ ├── components/ # Contains all React components
│ │ ├── pages/ # Contains main pages of the app
│ │ ├── styles/ # Contains global styles and themes
│ │ ├── context/ # Contains React Context API
│ │ ├── App.js # Main App component
│ │ ├── index.js # Entry point for React
│ │ └── theme.js # Material UI theme configuration
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ ├── package.json # NPM dependencies and scripts
│ └── README.md # Project documentation
│
├── backend/ # Django backend for API services and database management
│ ├── manage.py # Django's command-line utility
│ ├── requirements.txt # Backend dependencies
│ ├── backend/
│ │ ├── settings.py # Django settings for the project
│ │ ├── urls.py # URL declarations for the project
│ │ ├── users/ # User management components
│ │ └── api/ # Emotion detection and recommendation APIs
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ └── db.sqlite3 # SQLite database (if used)
│
├── ai_ml/ # AI/ML models for emotion detection
│ ├── data/ # Datasets for training and testing
│ ├── models/ # Trained models for emotion detection
│ ├── src/ # Source files for emotion detection and recommendation
│ │ ├── api/ # API scripts for running emotion detection services
│ │ ├── recommendation/ # Music recommendation logic
│ │ └── data_processing/ # Data preprocessing scripts
│ │
│ ├── Dockerfile # Dockerfile for containerization
│ └── README.md # AI/ML documentation
│
├── data_analytics/ # Data analytics scripts and visualizations
│ ├── emotion_distribution.py # Script for visualizing emotion distribution
│ ├── training_visualization.py # Script for visualizing training and validation metrics
│ ├── predictions_analysis.py # Script for analyzing model predictions
│ ├── recommendation_analysis.py # Script for visualizing music recommendations
│ ├── spark-hadoop/ # Spark and Hadoop integration scripts
│ └── visualizations/ # Generated visualizations
│
├── kubernetes/ # Kubernetes deployment files
│ ├── backend-deployment.yaml # Deployment file for the backend service
│ ├── backend-service.yaml # Deployment file for the backend service
│ ├── frontend-deployment.yaml # Deployment file for the frontend service
│ ├── frontend-service.yaml # Deployment file for the frontend service
│ └── configmap.yaml # ConfigMap for environment variables
│
├── mobile/ # React Native mobile application
│ ├── App.js # Main entry point for React Native app
│ ├── index.js # App registry for React Native
│ ├── package.json # NPM dependencies and scripts
│ ├── components/ # React Native components
│ │ ├── Footer.js # Footer component
│ │ ├── Navbar.js # Header component
│ │ ├── Auth/ # Authentication components (e.g., Login, Register)
│ │ └── Profile/ # Profile-related components
│ │
│ ├── context/ # React Context API for state management
│ │ └── DarkModeContext.js # Dark mode context provider
│ │
│ ├── pages/ # Main pages of the app
│ │ ├── HomePage.js # Home page component
│ │ ├── ProfilePage.js # Profile page component
│ │ ├── ResultsPage.js # Results page component
│ │ ├── LandingPage.js # Landing page component
│ │ └── (and more...)
│ │
│ ├── assets/ # Images, fonts, and other assets
│ ├── styles/ # Styling files (similar to CSS for web)
│ ├── .gitignore # Git ignore file
│ ├── package.json # Dependencies and scripts
│ └── README.md # Mobile app documentation
│
├── nginx/ # NGINX configuration files (for load balancing and reverse proxy)
│ ├── nginx.conf # Main NGINX configuration file
│ └── Dockerfile # Dockerfile for NGINX container
│
├── images/ # Images used in the README documentation
├── docker-compose.yml # Docker Compose file for containerization
└── README.md # Comprehensive README file for the entire project
venv ).env Fichier (pour les variables d'environnement - vous créez vos propres informations d'identification en suivant l'exemple de fichier ou contactez-moi pour le mien.)Commencez par la configuration et la formation des modèles AI / ML, car ils seront nécessaires pour que le backend fonctionne correctement.
Ou, vous pouvez télécharger les modèles pré-formés à partir des liens Google Drive fournis dans la section des modèles pré-formés. Si vous choisissez de le faire, vous pouvez ignorer cette section pour l'instant.
Clone le référentiel:
git clone https://github.com/hoangsonww/Moodify-Emotion-Music-App.gitAccédez au répertoire AI / ML:
cd Moodify-Emotion-Music-App/ai_mlCréer et activer un environnement virtuel:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsInstallez les dépendances:
pip install -r requirements.txt Modifiez les configurations dans le fichier src/config.py :
src/config.py et mettez à jour les configurations au besoin, en particulier vos touches API Spotify et configurez tous les chemins.src/models et mettez à jour les chemins des ensembles de données et des chemins de sortie selon les besoins.Former le modèle d'émotion du texte:
python src/models/train_text_emotion.pyRépétez les commandes similaires pour d'autres modèles au besoin (par exemple, les modèles d'émotion faciale et de parole).
Assurez-vous que tous les modèles qualifiés sont placés dans le répertoire models et que vous avez formé tous les modèles nécessaires avant de passer à l'étape suivante!
Testez les modèles AI / ML formés au besoin :
src/models/test_emotion_models.py pour tester les modèles formés.Une fois les modèles AI / ML prêts, procédez par configuration du backend.
Accédez au répertoire backend:
cd ../backendCréer et activer un environnement virtuel:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsInstallez les dépendances:
pip install -r requirements.txtConfigurez vos secrets et votre environnement:
.env dans le répertoire backend ..env : SECRET_KEY=your_secret_key
DEBUG=True
ALLOWED_HOSTS=<your_hosts>
MONGODB_URI=<your_mongodb_uri>
backend/settings.py et ajoutez SECRET_KEY & Set DEBUG sur True .Exécutez les migrations de la base de données:
python manage.py migrateDémarrez le serveur Django:
python manage.py runserver Le serveur backend s'exécutera sur http://127.0.0.1:8000/ .
Enfin, configurez le frontend pour interagir avec le backend.
Accédez au répertoire Frontend:
cd ../frontendInstallez les dépendances à l'aide du fil:
npm installDémarrer le serveur de développement:
npm start Le frontend commencera sur http://localhost:3000 .
Remarque: Si vous rencontrez des problèmes ou avez besoin de mon fichier .env , n'hésitez pas à me contacter.
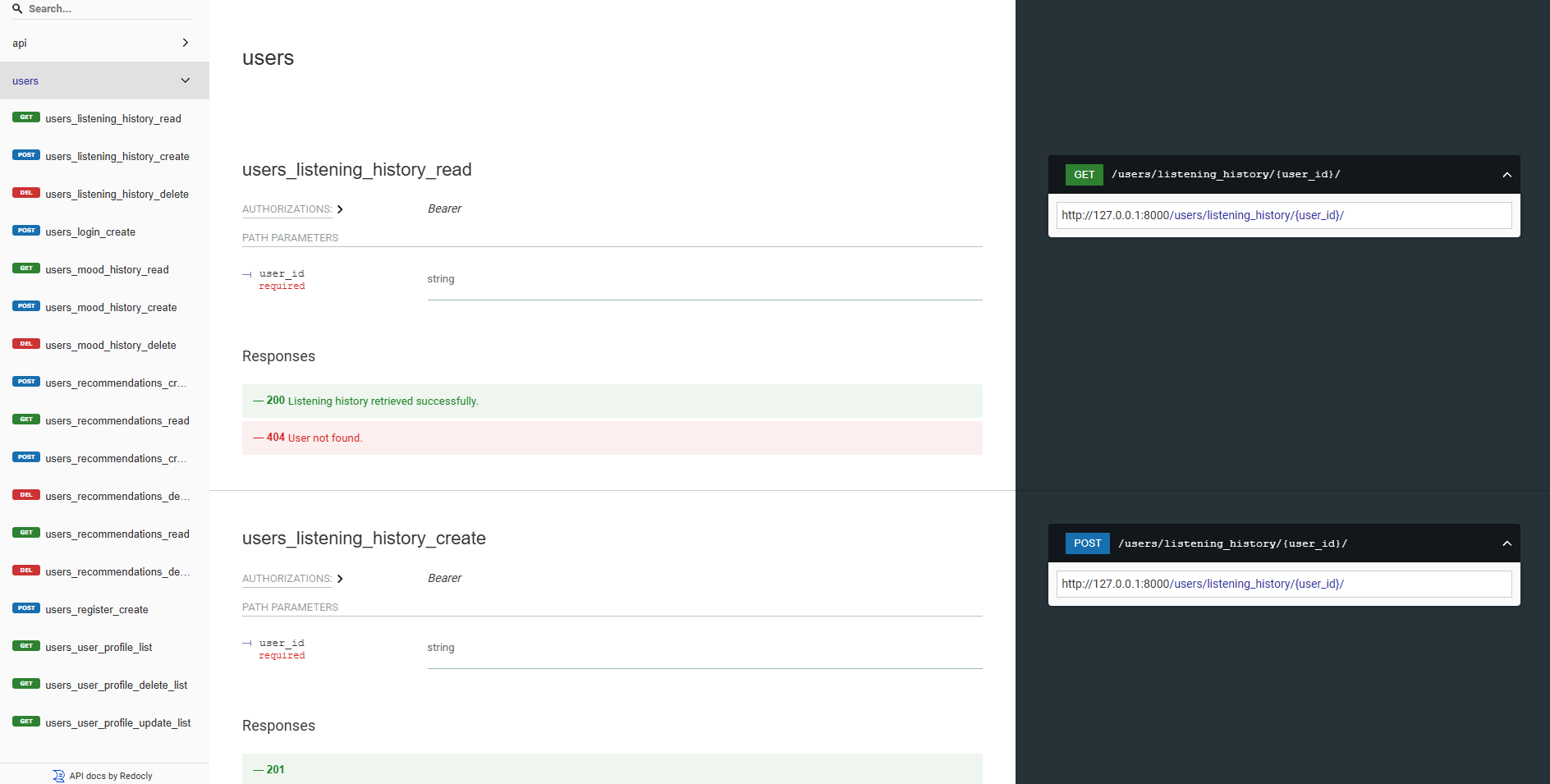
| Méthode HTTP | Point final | Description |
|---|---|---|
POST | /users/register/ | Enregistrer un nouvel utilisateur |
POST | /users/login/ | Connectez-vous un utilisateur et obtenez un jeton JWT |
GET | /users/user/profile/ | Récupérer le profil de l'utilisateur authentifié |
PUT | /users/user/profile/update/ | Mettre à jour le profil de l'utilisateur authentifié |
DELETE | /users/user/profile/delete/ | Supprimer le profil de l'utilisateur authentifié |
POST | /users/recommendations/ | Enregistrer les recommandations pour un utilisateur |
GET | /users/recommendations/<str:username>/ | Récupérer les recommandations pour un utilisateur par nom d'utilisateur |
DELETE | /users/recommendations/<str:username>/<str:recommendation_id>/ | Supprimer une recommandation spécifique pour un utilisateur |
DELETE | /users/recommendations/<str:username>/ | Supprimer toutes les recommandations pour un utilisateur |
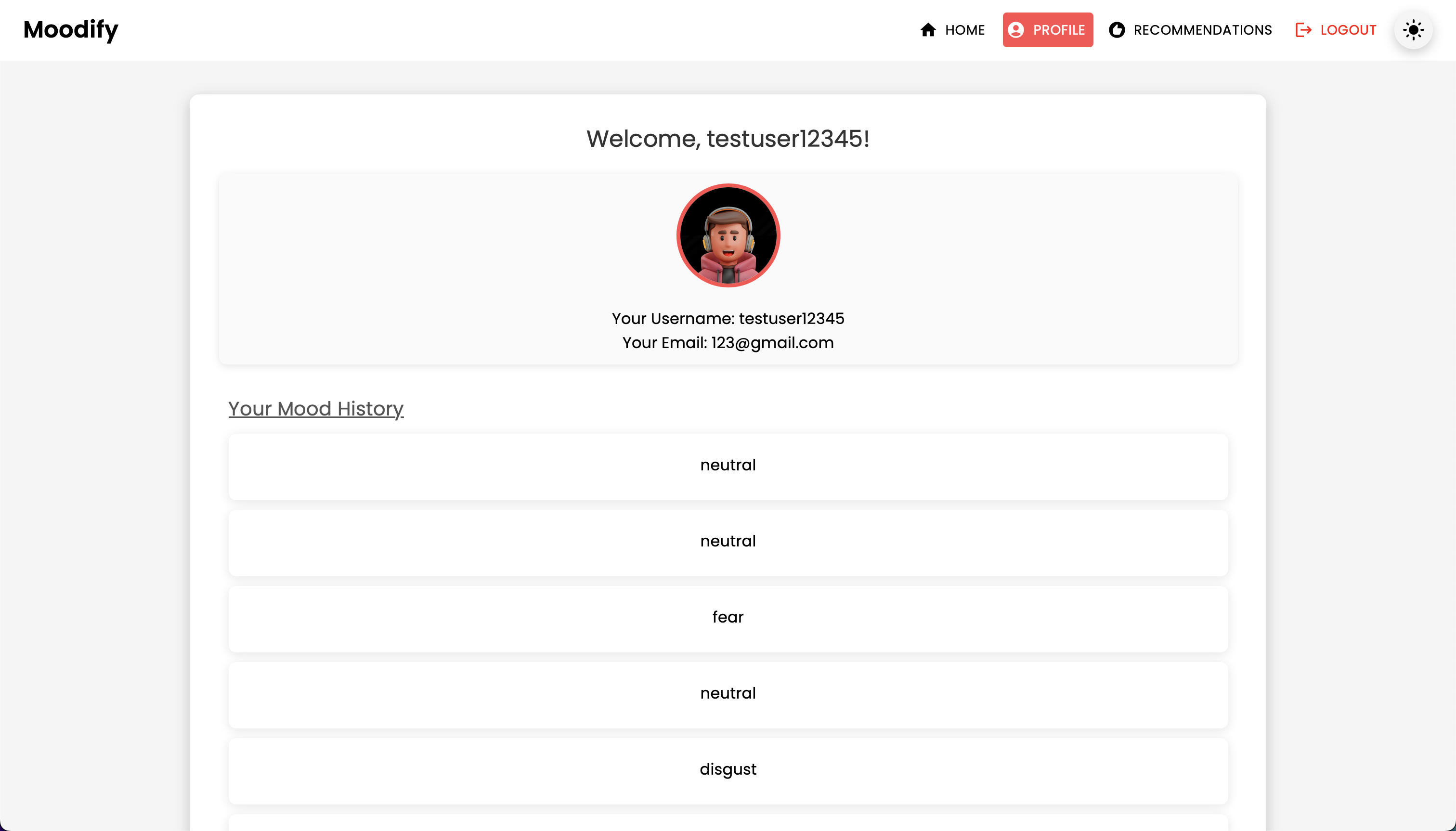
POST | /users/mood_history/<str:user_id>/ | Ajoutez une humeur à l'historique de l'humeur de l'utilisateur |
GET | /users/mood_history/<str:user_id>/ | Récupérer l'historique de l'humeur pour un utilisateur |
DELETE | /users/mood_history/<str:user_id>/ | Supprimer une humeur spécifique de l'historique de l'utilisateur |
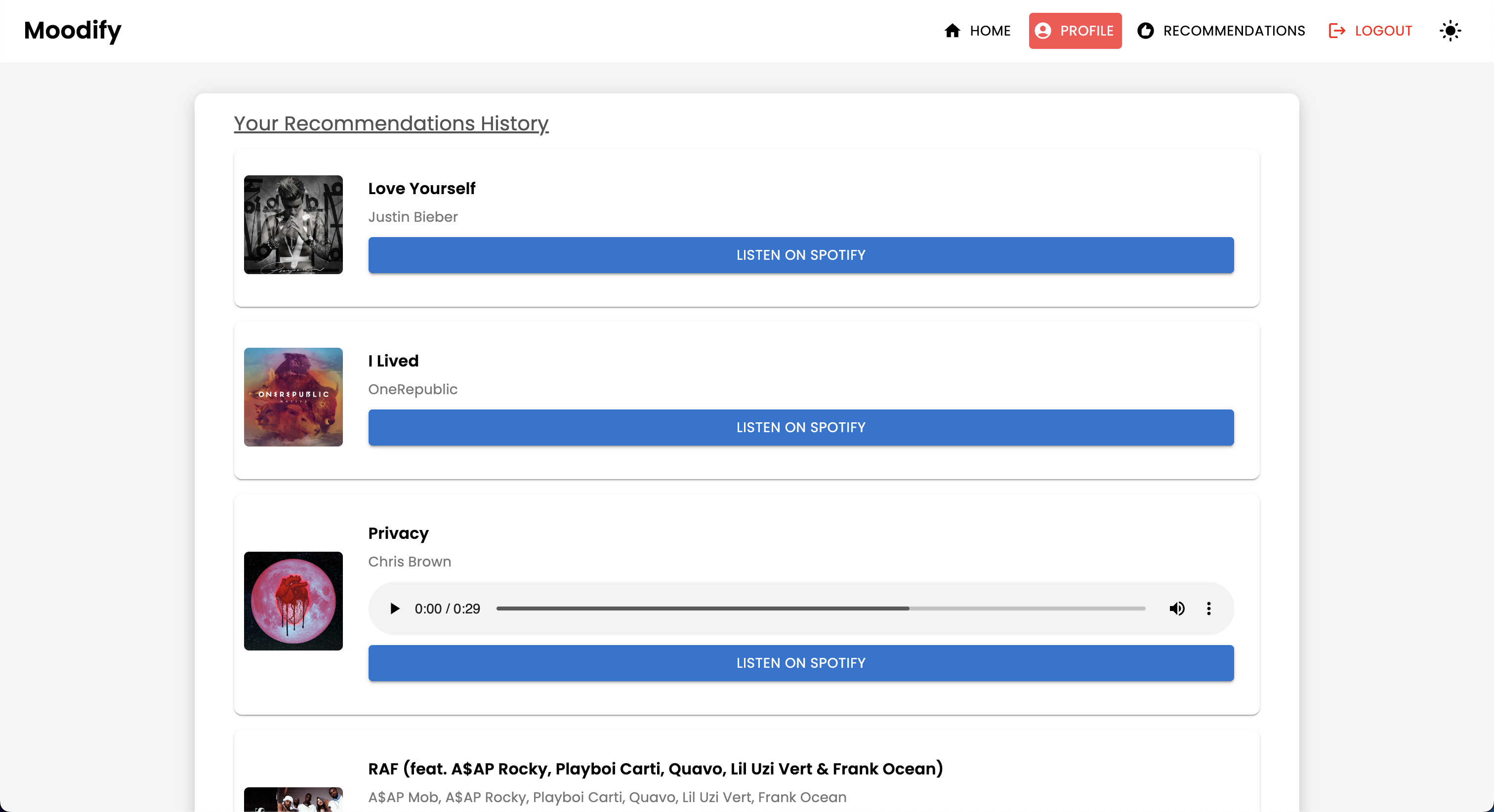
POST | /users/listening_history/<str:user_id>/ | Ajoutez une piste à l'historique d'écoute de l'utilisateur |
GET | /users/listening_history/<str:user_id>/ | Récupérer l'historique d'écoute pour un utilisateur |
DELETE | /users/listening_history/<str:user_id>/ | Supprimer une piste spécifique de l'historique de l'utilisateur |
POST | /users/user_recommendations/<str:user_id>/ | Enregistrer les recommandations d'un utilisateur |
GET | /users/user_recommendations/<str:user_id>/ | Récupérer les recommandations d'un utilisateur |
DELETE | /users/user_recommendations/<str:user_id>/ | Supprimer toutes les recommandations pour un utilisateur |
POST | /users/verify-username-email/ | Vérifiez si un nom d'utilisateur et un e-mail sont valides |
POST | /users/reset-password/ | Réinitialiser le mot de passe d'un utilisateur |
GET | /users/verify-token/ | Vérifiez le jeton d'un utilisateur |
| Méthode HTTP | Point final | Description |
|---|---|---|
POST | /api/text_emotion/ | Analyser le texte pour le contenu émotionnel |
POST | /api/speech_emotion/ | Analyser la parole pour un contenu émotionnel |
POST | /api/facial_emotion/ | Analyser les expressions faciales pour les émotions |
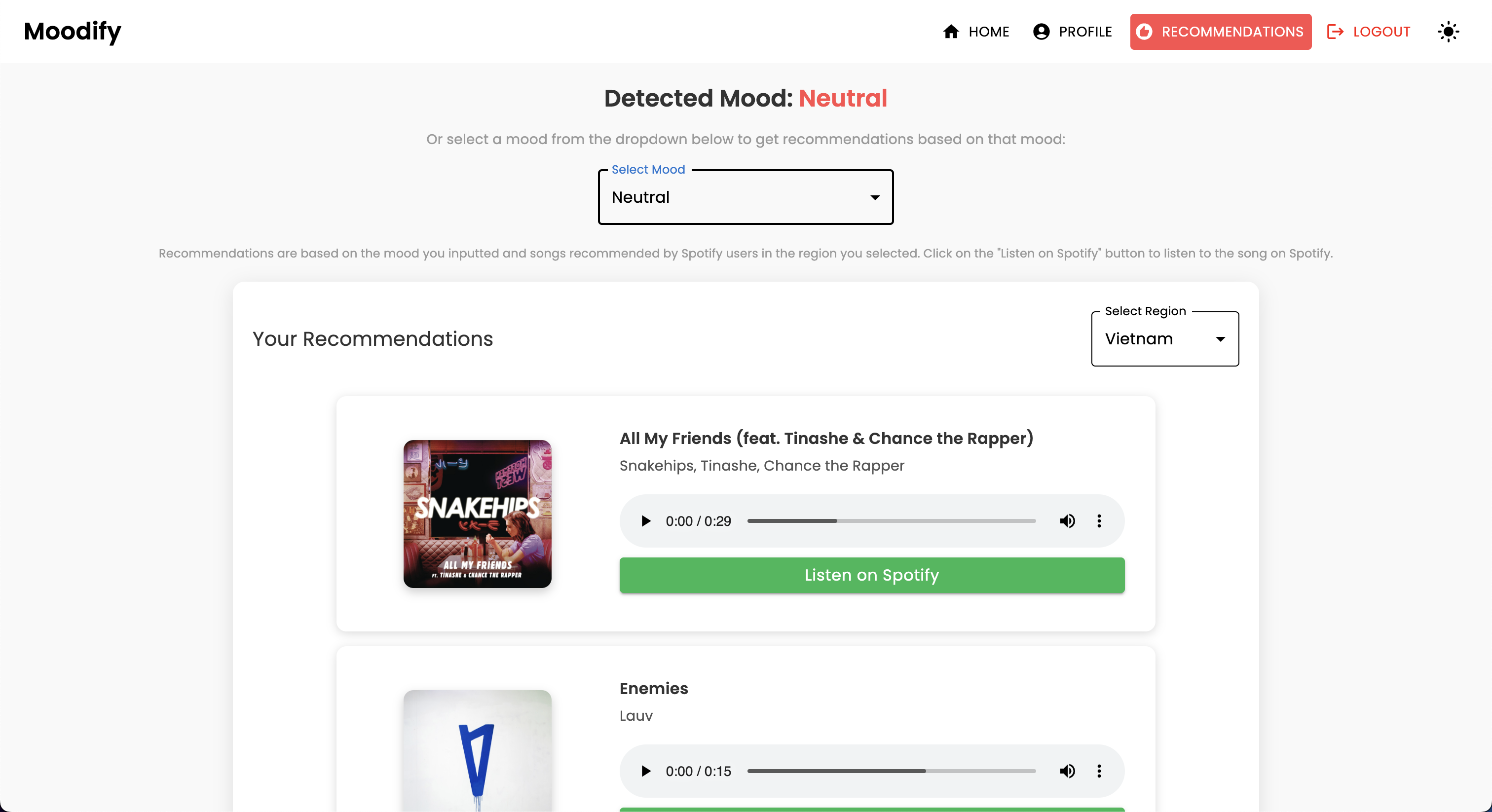
POST | /api/music_recommendation/ | Obtenez des recommandations musicales en fonction de l'émotion |
| Méthode HTTP | Point final | Description |
|---|---|---|
GET | /admin/ | Accéder à l'interface d'administration Django |
| Méthode HTTP | Point final | Description |
|---|---|---|
GET | /swagger/ | Accéder à la documentation de l'API UI Swagger |
GET | /redoc/ | Accéder à la documentation de l'API Redoc |
GET | / | Accéder au point de terminaison de la racine de l'API (interface utilisateur Swagger) |
Créez un superutilisateur:
python manage.py createsuperuser Accédez au panneau d'administration à http://127.0.0.1:8000/admin/
Vous devriez voir la page de connexion suivante:
Nos API backend sont toutes bien documentées à l'aide de Swagger UI et Redoc. Vous pouvez accéder à la documentation de l'API aux URL suivantes:
https://moodify-emotion-music-app.onrender.com/swagger .https://moodify-emotion-music-app.onrender.com/redoc .Alternativement, vous pouvez exécuter le serveur backend localement et accéder à la documentation de l'API aux points de terminaison suivants:
http://127.0.0.1:8000/swagger .http://127.0.0.1:8000/redoc .Quel que soit votre choix, vous devriez voir la documentation API suivante si tout fonctionne correctement:
Swagger ui:
Redoc:
Les modèles AI / ML sont construits à l'aide de Transformers Pytorch, TensorFlow, Keras et Hugging Face. Ces modèles sont formés sur divers ensembles de données pour détecter les émotions à partir de texte, de parole et d'expressions faciales.
Les modèles de détection d'émotion sont utilisés pour analyser les entrées des utilisateurs et fournir des recommandations musicales en temps réel en fonction des émotions détectées. Les modèles sont formés sur divers ensembles de données pour capturer les nuances des émotions humaines et fournir des prédictions précises.
Les modèles sont intégrés dans les services d'API backend pour fournir des recommandations de détection d'émotions en temps réel et de musique pour les utilisateurs.
Les modèles doivent être formés en premier avant de les utiliser dans les services backend. Assurez-vous que les modèles sont formés et placés dans le répertoire models avant d'exécuter le serveur backend. Reportez-vous à la section (Débutage) [# Get-Started] pour plus de détails.
 Exemples de formation du modèle d'émotion de texte.
Exemples de formation du modèle d'émotion de texte.
Pour former les modèles, vous pouvez exécuter les scripts fournis dans le répertoire ai_ml/src/models . Ces scripts sont utilisés pour prétraiter les données, former les modèles et enregistrer les modèles formés pour une utilisation ultérieure. Ces scripts incluent:
train_text_emotion.py : entraîne le modèle de détection d'émotion du texte.train_speech_emotion.py : forme le modèle de détection des émotions de la parole.train_facial_emotion.py : entraîne le modèle de détection des émotions faciales. Assurez-vous que vous avez configuré les dépendances, les ensembles de données et les configurations nécessaires avant de former les modèles. Plus précisément, assurez-vous de visiter le fichier config.py et mettez à jour les chemins de temps vers les ensembles de données et les répertoires de sortie vers les bons de votre système.
Remarque: Par défaut, ces scripts priorisent l'utilisation de votre GPU avec CUDA (si disponible) pour une formation plus rapide. Cependant, si cela n'est pas disponible sur votre machine, les scripts se replieront automatiquement à l'utilisation du CPU pour la formation. Pour vous assurer que vous avez les dépendances nécessaires pour la formation GPU, installez Pytorch avec le support CUDA en utilisant la commande suivante:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 Après cela, vous pouvez exécuter le script test_emotion_models.py pour tester les modèles formés et vous assurer qu'ils fournissent des prédictions précises:
python src/models/test_emotion_models.pyAlternativement, vous pouvez exécuter l'API Simple Flask pour tester les modèles via des points de terminaison API RESTFul:
python ai_ml/src/api/emotion_api.pyLes points de terminaison sont les suivants:
/text_emotion : détecte l'émotion à partir de l'entrée de texte/speech_emotion : détecte l'émotion de l'audio de la parole/facial_emotion : détecte l'émotion d'une image/music_recommendation : fournit des recommandations musicales basées sur l'émotion détectée IMPORTANT : Pour plus d'informations sur la formation et l'utilisation des modèles, veuillez vous référer à la documentation AI / ML dans le répertoire ai_ml .
Cependant, si la formation du modèle est trop à forte intensité de ressources pour vous, vous pouvez utiliser les liens Google Drive suivants pour télécharger les modèles pré-formés:
model.safetensors . Veuillez télécharger ce fichier model.safetensors et le placer dans le répertoire ai_ml/models/text_emotion_model .scaler.pkl . Veuillez télécharger ceci et placer ceci dans le répertoire ai_ml/models/speech_emotion_model .trained_speech_emotion_model.pkl . Veuillez télécharger ceci et placer ceci dans le répertoire ai_ml/models/speech_emotion_model .trained_facial_emotion_model.pt . Veuillez télécharger ceci et placer ceci dans le répertoire ai_ml/models/facial_emotion_model . Ceux-ci ont été formés sur les ensembles de données pour vous et sont prêts à être utilisés dans les services backend ou à des fins de test une fois téléchargées et correctement placées dans le répertoire models .
N'hésitez pas à me contacter si vous rencontrez des problèmes ou si vous avez besoin d'aide supplémentaire avec les modèles AI / ML.
Le dossier data_analytics fournit des scripts d'analyse et de visualisation des données pour mieux comprendre les performances du modèle de détection des émotions.
Exécutez tous les scripts d'analyse:
python data_analytics/main.py Voir les visualisations générées dans le dossier visualizations .
Voici quelques exemples de visualisations:
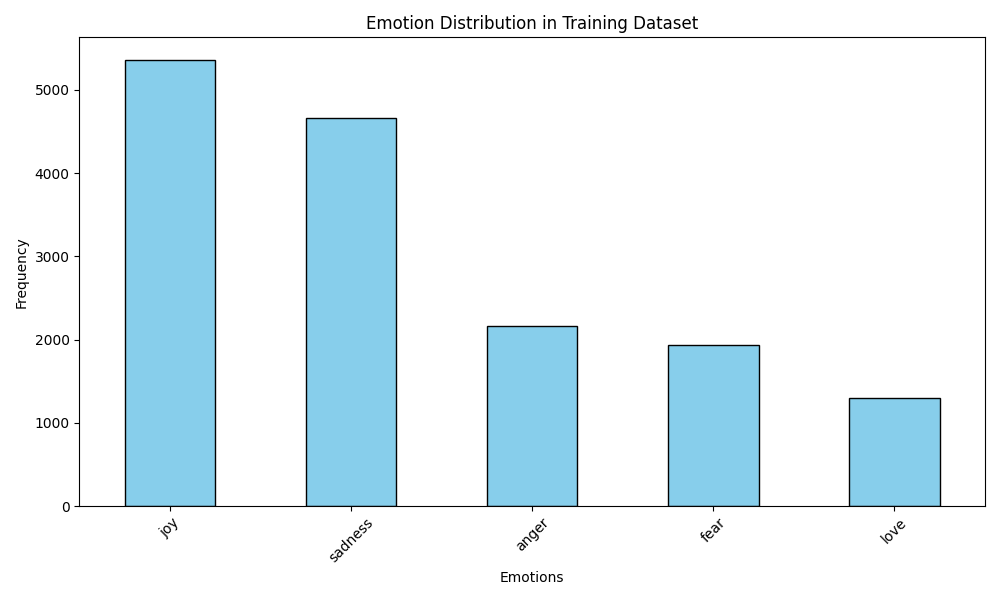 Visualisation de la distribution des émotions
Visualisation de la distribution des émotions
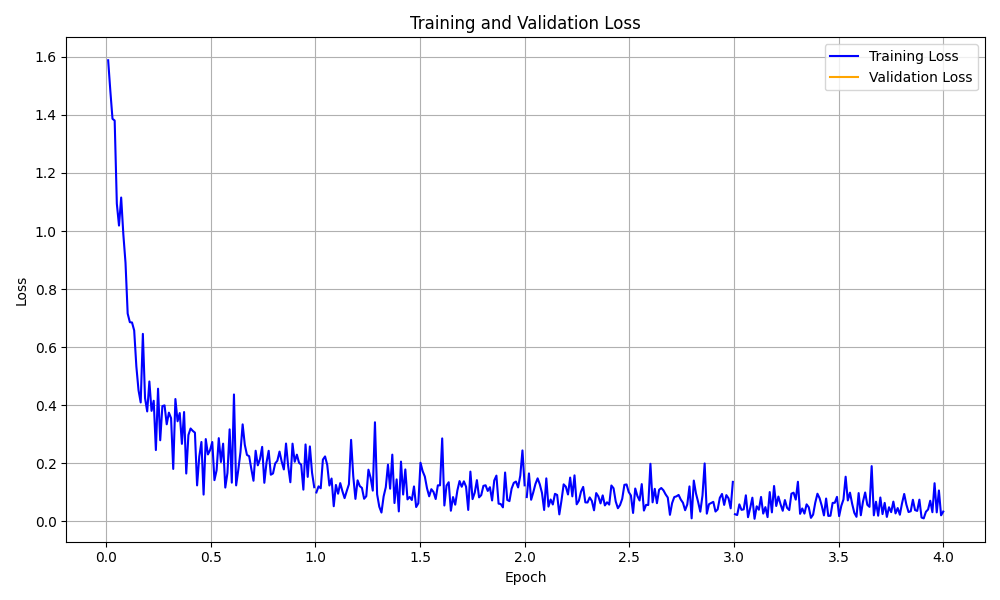 Visualisation de la courbe de perte de formation
Visualisation de la courbe de perte de formation
Il existe également une version mobile de l'application MoodIfy construite à l'aide de React Native et Expo. Vous pouvez trouver l'application mobile dans le répertoire mobile .
Accédez au répertoire mobile:
cd ../mobileInstallez les dépendances à l'aide du fil:
yarn installDémarrez le serveur de développement Expo:
yarn startAnalysez le code QR à l'aide de l'application Expo Go sur votre appareil mobile pour exécuter l'application.
En cas de succès, vous devriez voir l'écran d'accueil suivant:
N'hésitez pas à explorer l'application mobile et à tester ses fonctionnalités!
Le projet utilise Nginx et Gunicorn pour l'équilibrage de la charge et le service du backend Django. Nginx agit comme un serveur proxy inversé, tandis que Gunicorn sert l'application Django.
Installer nginx:
sudo apt-get update
sudo apt-get install nginxInstallez Gunicorn:
pip install gunicornConfigurer nginx:
/nginx/nginx.conf avec votre configuration.Démarrez Nginx et Gunicorn:
sudo systemctl start nginxgunicorn backend.wsgi:application Accédez au backend sur http://<server_ip>:8000/ .
N'hésitez pas à personnaliser la configuration Nginx et les paramètres de Gunicorn selon les besoins de votre déploiement.
Le projet peut être conteneurisé à l'aide de Docker pour un déploiement et une échelle faciles. Vous pouvez créer des images Docker pour les modèles Frontend, Backend et AI / ML.
Construisez les images Docker:
docker compose up --buildLes images Docker seront construites pour les modèles Frontend, Backend et AI / ML. Vérifiez les images en utilisant:
docker imagesSi vous rencontrez des erreurs, essayez de reconstruire votre image sans utiliser le cache, car le cache de Docker peut causer des problèmes.
docker-compose build --no-cacheNous avons également ajouté des fichiers de déploiement de Kubernetes pour les services backend et frontend. Vous pouvez déployer les services sur un cluster Kubernetes à l'aide des fichiers YAML fournis.
Déployer le service backend:
kubectl apply -f kubernetes/backend-deployment.yamlDéployer le service Frontend:
kubectl apply -f kubernetes/frontend-deployment.yamlExposez les services:
kubectl expose deployment moodify-backend --type=LoadBalancer --port=8000
kubectl expose deployment moodify-frontend --type=LoadBalancer --port=3000Accédez aux services à l'aide de la IP LoadBalancer:
http://<backend_loadbalancer_ip>:8000 .http://<frontend_loadbalancer_ip>:3000 . N'hésitez pas à visiter le répertoire kubernetes pour plus d'informations sur les fichiers et configurations de déploiement.
Nous avons également inclus le script de pipeline Jenkins pour automatiser le processus de construction et de déploiement. Vous pouvez utiliser Jenkins pour automatiser le processus CI / CD pour l'application MoodIfy.
Installez Jenkins sur votre serveur ou votre machine locale.
Créez un nouveau travail de pipeline Jenkins:
Jenkinsfile dans le répertoire jenkins .Exécutez le pipeline Jenkins:
N'hésitez pas à explorer le script de pipeline Jenkins dans le Jenkinsfile et à le personnaliser au besoin pour votre processus de déploiement.
Les contributions sont les bienvenues! N'hésitez pas à alimenter le référentiel et à soumettre une demande de traction.
Notez que ce projet est toujours en cours de développement actif et que toute contribution est appréciée.
Si vous avez des suggestions, des demandes de fonctionnalités ou des rapports de bogues, n'hésitez pas à ouvrir un problème ici.
Bonne codage et vibin '! ?
Créé avec ❤️ par Son Nguyen en 2024.
? Retour en haut


