Moodify Emotion Music App
1.0.0
Com o surgimento de serviços personalizados de streaming de música, há uma necessidade crescente de sistemas que podem recomendar música com base nos estados emocionais dos usuários. Percebendo essa necessidade, o Moodify está sendo desenvolvido pelo Son Nguyen em 2024 para fornecer recomendações musicais personalizadas com base nas emoções detectadas dos usuários.
O Moodify Project é um sistema de recomendação musical baseado em emoções integrado que combina modelos de front-end, back-end, IA/ML e análise de dados para fornecer recomendações de música personalizadas com base em emoções do usuário. O aplicativo analisa expressões de texto, fala ou facial e sugere músicas que se alinham às emoções detectadas.
Suportando plataformas de mesa e móveis, o Moodify oferece uma experiência perfeita para o usuário com detecção de emoções em tempo real e recomendações musicais. O projeto aproveita reaja para o front-end, Django para o back-end e três modelos avançados de IA/ML auto-teriados para detecção de emoções . Os scripts de análise de dados são usados para visualizar tendências emocionais e desempenho do modelo.

O Moodify fornece recomendações musicais personalizadas com base nos estados emocionais dos usuários detectados por texto, fala e expressões faciais. Ele interage com um back-end baseado em Django, modelos de AI/ML para detecção de emoções e utiliza análise de dados para insights visuais sobre tendências emocionais e desempenho do modelo.
O aplicativo Moodify está atualmente ao vivo e implantado no Vercel. Você pode acessar o aplicativo ao vivo usando o seguinte link: Moodify.
Sinta -se à vontade para também visitar o back -end na API de back -end do Moodify.
Diclaimer: O back -end do Moodify está atualmente hospedado com o nível gratuito de renderização, por isso pode levar alguns segundos para carregar inicialmente. Além disso, pode girar após um período de inatividade ou tráfego alto, portanto, seja paciente se o back -end levar alguns segundos para responder.
Além disso, a quantidade de memória alocada pela renderização é de apenas 512 MB com 0,1 CPU ; portanto, o back -end pode ficar sem memória se houver muitas solicitações de uma só vez, o que pode fazer com que o servidor seja reiniciado. Além disso, os modelos de detecção de emoção facial e de fala também podem falhar devido a restrições de memória - o que também pode fazer com que o servidor seja reiniciado.
Não há garantia de tempo de atividade ou desempenho com a implantação atual, a menos que eu tenha mais recursos (dinheiro) para atualizar o servidor :( Fique à vontade para entrar em contato comigo se encontrar algum problema ou precisar de mais assistência.
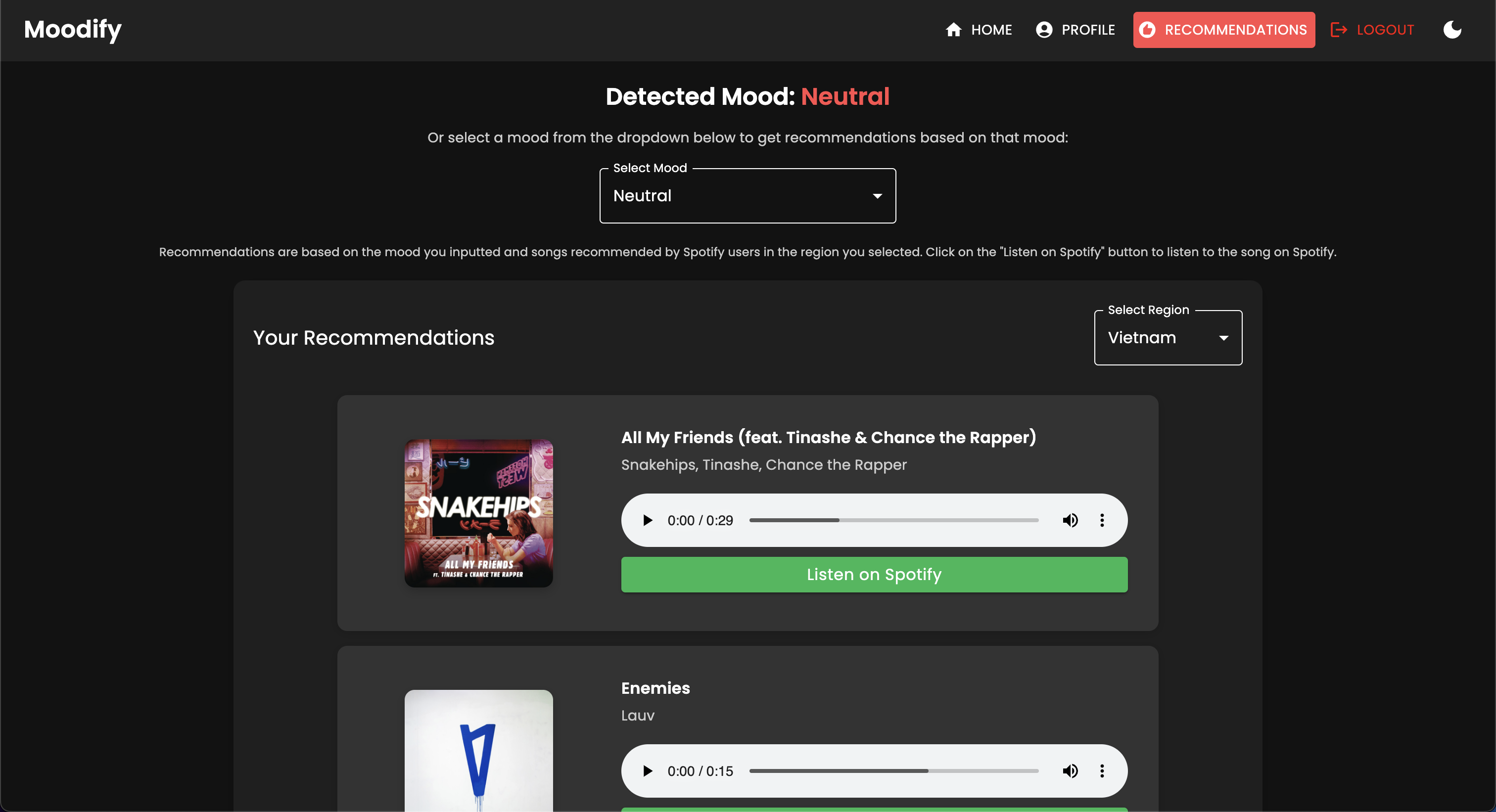

O projeto possui uma estrutura de arquivos abrangente que combina componentes de front -end, back -end, AI/ML e componentes de análise de dados:
Moodify-Emotion-Music-App/
├── frontend/ # React frontend for the web application
│ ├── public/
│ │ ├── index.html # Main HTML file
│ │ ├── manifest.json # Web app manifest
│ │ └── favicon.ico # Favicon for the app
│ │
│ ├── src/
│ │ ├── components/ # Contains all React components
│ │ ├── pages/ # Contains main pages of the app
│ │ ├── styles/ # Contains global styles and themes
│ │ ├── context/ # Contains React Context API
│ │ ├── App.js # Main App component
│ │ ├── index.js # Entry point for React
│ │ └── theme.js # Material UI theme configuration
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ ├── package.json # NPM dependencies and scripts
│ └── README.md # Project documentation
│
├── backend/ # Django backend for API services and database management
│ ├── manage.py # Django's command-line utility
│ ├── requirements.txt # Backend dependencies
│ ├── backend/
│ │ ├── settings.py # Django settings for the project
│ │ ├── urls.py # URL declarations for the project
│ │ ├── users/ # User management components
│ │ └── api/ # Emotion detection and recommendation APIs
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ └── db.sqlite3 # SQLite database (if used)
│
├── ai_ml/ # AI/ML models for emotion detection
│ ├── data/ # Datasets for training and testing
│ ├── models/ # Trained models for emotion detection
│ ├── src/ # Source files for emotion detection and recommendation
│ │ ├── api/ # API scripts for running emotion detection services
│ │ ├── recommendation/ # Music recommendation logic
│ │ └── data_processing/ # Data preprocessing scripts
│ │
│ ├── Dockerfile # Dockerfile for containerization
│ └── README.md # AI/ML documentation
│
├── data_analytics/ # Data analytics scripts and visualizations
│ ├── emotion_distribution.py # Script for visualizing emotion distribution
│ ├── training_visualization.py # Script for visualizing training and validation metrics
│ ├── predictions_analysis.py # Script for analyzing model predictions
│ ├── recommendation_analysis.py # Script for visualizing music recommendations
│ ├── spark-hadoop/ # Spark and Hadoop integration scripts
│ └── visualizations/ # Generated visualizations
│
├── kubernetes/ # Kubernetes deployment files
│ ├── backend-deployment.yaml # Deployment file for the backend service
│ ├── backend-service.yaml # Deployment file for the backend service
│ ├── frontend-deployment.yaml # Deployment file for the frontend service
│ ├── frontend-service.yaml # Deployment file for the frontend service
│ └── configmap.yaml # ConfigMap for environment variables
│
├── mobile/ # React Native mobile application
│ ├── App.js # Main entry point for React Native app
│ ├── index.js # App registry for React Native
│ ├── package.json # NPM dependencies and scripts
│ ├── components/ # React Native components
│ │ ├── Footer.js # Footer component
│ │ ├── Navbar.js # Header component
│ │ ├── Auth/ # Authentication components (e.g., Login, Register)
│ │ └── Profile/ # Profile-related components
│ │
│ ├── context/ # React Context API for state management
│ │ └── DarkModeContext.js # Dark mode context provider
│ │
│ ├── pages/ # Main pages of the app
│ │ ├── HomePage.js # Home page component
│ │ ├── ProfilePage.js # Profile page component
│ │ ├── ResultsPage.js # Results page component
│ │ ├── LandingPage.js # Landing page component
│ │ └── (and more...)
│ │
│ ├── assets/ # Images, fonts, and other assets
│ ├── styles/ # Styling files (similar to CSS for web)
│ ├── .gitignore # Git ignore file
│ ├── package.json # Dependencies and scripts
│ └── README.md # Mobile app documentation
│
├── nginx/ # NGINX configuration files (for load balancing and reverse proxy)
│ ├── nginx.conf # Main NGINX configuration file
│ └── Dockerfile # Dockerfile for NGINX container
│
├── images/ # Images used in the README documentation
├── docker-compose.yml # Docker Compose file for containerization
└── README.md # Comprehensive README file for the entire project
venv ).env arquivo (para variáveis de ambiente - você cria suas próprias credenciais seguindo o arquivo de exemplo ou entre em contato comigo para o meu.)Comece com a configuração e o treinamento dos modelos de IA/ML, pois eles serão necessários para que o back -end funcione corretamente.
Ou você pode baixar os modelos pré-treinados nos links do Google Drive fornecidos na seção Modelos pré-treinados. Se você optar por fazer isso, poderá pular esta seção por enquanto.
Clone o repositório:
git clone https://github.com/hoangsonww/Moodify-Emotion-Music-App.gitNavegue até o diretório AI/ML:
cd Moodify-Emotion-Music-App/ai_mlCrie e ativar um ambiente virtual:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsInstale dependências:
pip install -r requirements.txt Edite as configurações no arquivo src/config.py :
src/config.py e atualize as configurações conforme necessário, especialmente as suas teclas da API do Spotify e configure todos os caminhos.src/models e atualize os caminhos para os conjuntos de dados e caminhos de saída, conforme necessário.Treine o modelo de emoção de texto:
python src/models/train_text_emotion.pyRepita comandos semelhantes para outros modelos, conforme necessário (por exemplo, modelos de emoções faciais e de fala).
Verifique se todos os modelos treinados são colocados no diretório models e que você treinou todos os modelos necessários antes de passar para a próxima etapa!
Teste os modelos treinados de IA/ML conforme necessário :
src/models/test_emotion_models.py para testar os modelos treinados.Depois que os modelos AI/ML estiverem prontos, prossiga com a configuração do back -end.
Navegue até o diretório de back -end:
cd ../backendCrie e ativar um ambiente virtual:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsInstale dependências:
pip install -r requirements.txtConfigure seus segredos e ambiente:
.env no diretório backend ..env : SECRET_KEY=your_secret_key
DEBUG=True
ALLOWED_HOSTS=<your_hosts>
MONGODB_URI=<your_mongodb_uri>
backend/settings.py e adicione SECRET_KEY e defina DEBUG como True .Executar migrações de banco de dados:
python manage.py migrateInicie o servidor Django:
python manage.py runserver O servidor de backend estará em execução em http://127.0.0.1:8000/ .
Finalmente, configure o front -end para interagir com o back -end.
Navegue até o diretório de front -end:
cd ../frontendInstale dependências usando o YAR:
npm installInicie o servidor de desenvolvimento:
npm start O front -end começará em http://localhost:3000 .
NOTA: Se você encontrar algum problema ou precisar do meu arquivo .env , sinta -se à vontade para entrar em contato comigo.
| Método HTTP | Endpoint | Descrição |
|---|---|---|
POST | /users/register/ | Registre um novo usuário |
POST | /users/login/ | Login um usuário e obtenha um token JWT |
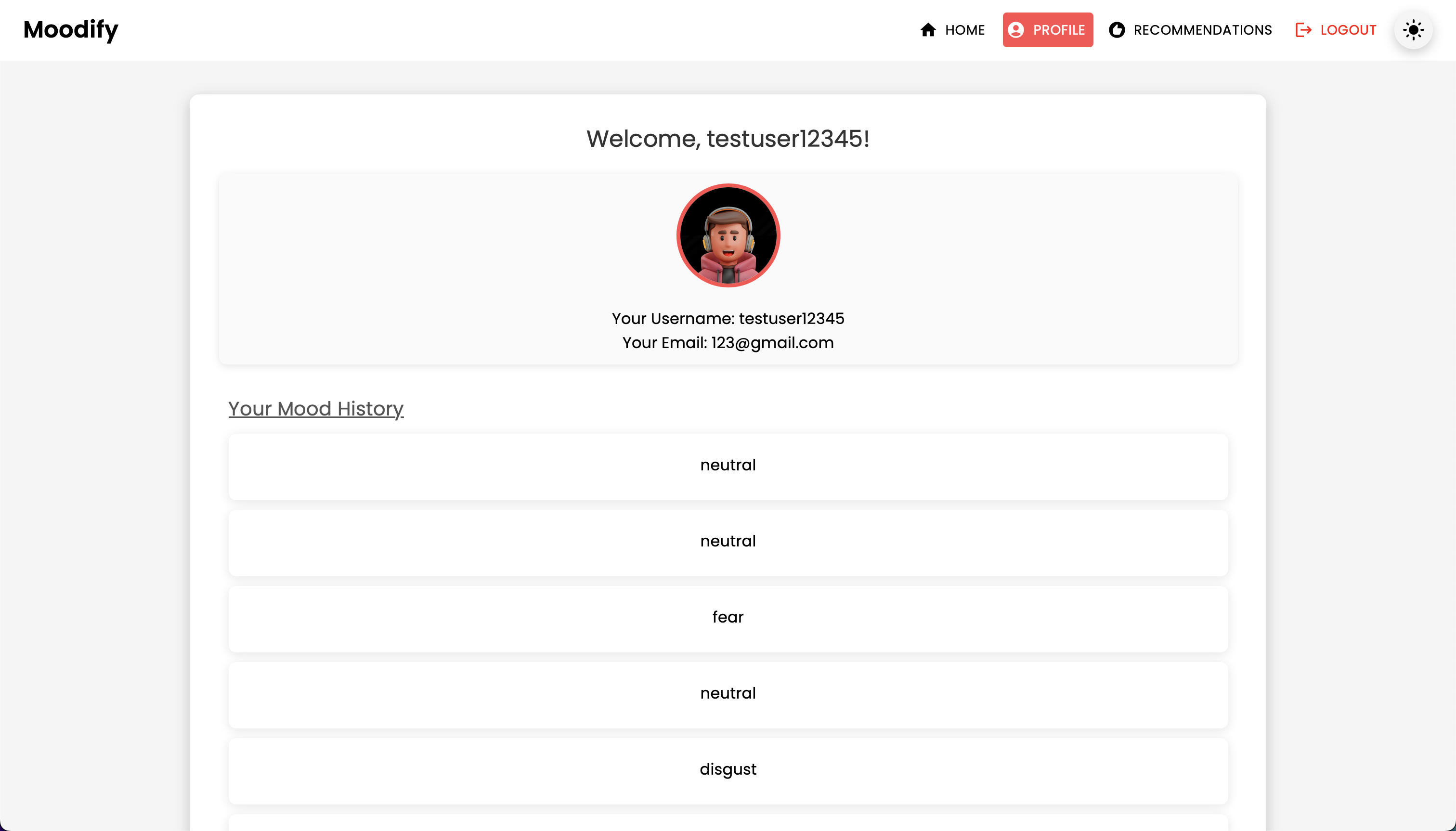
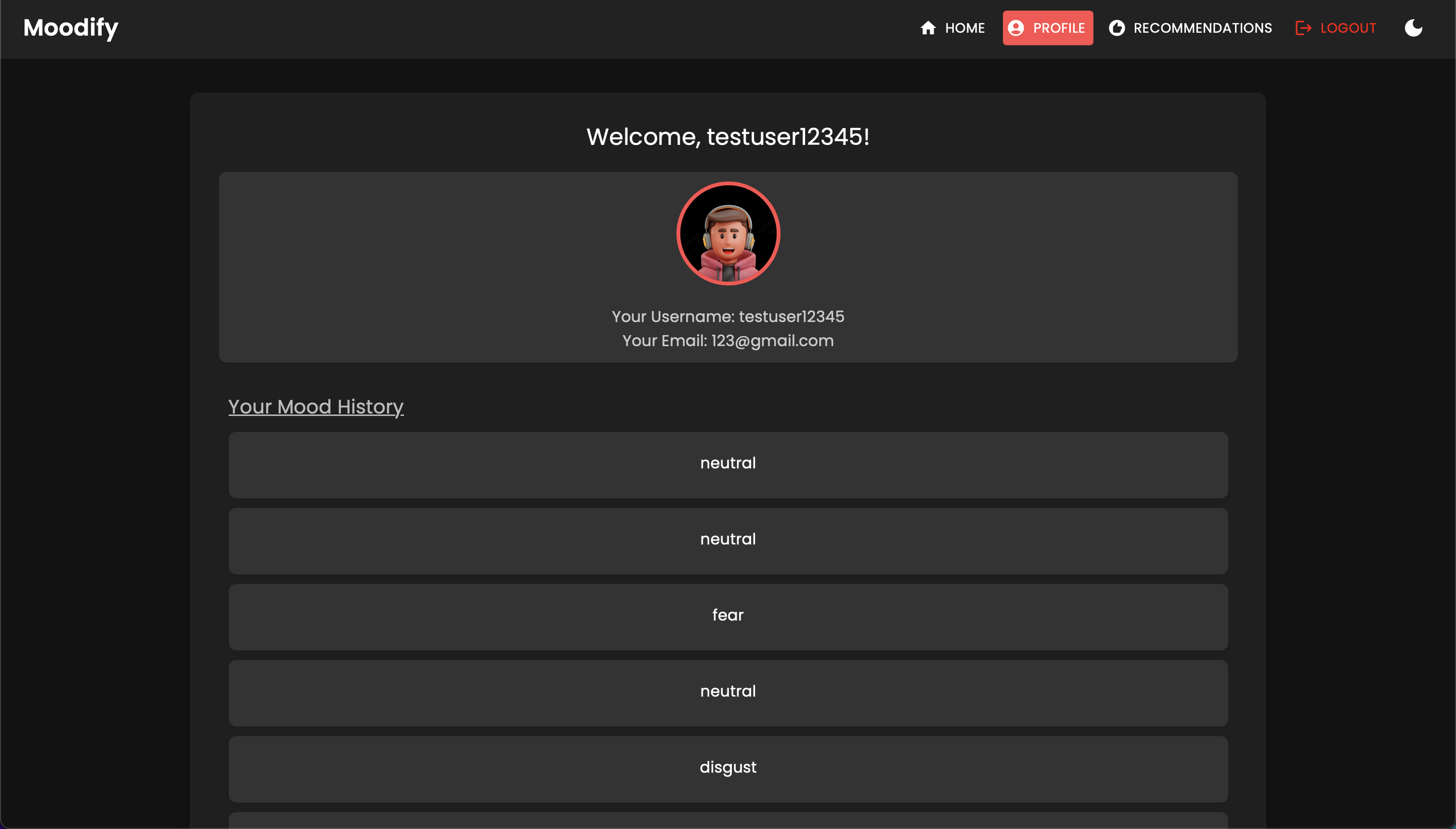
GET | /users/user/profile/ | Recuperar o perfil do usuário autenticado |
PUT | /users/user/profile/update/ | Atualize o perfil do usuário autenticado |
DELETE | /users/user/profile/delete/ | Exclua o perfil do usuário autenticado |
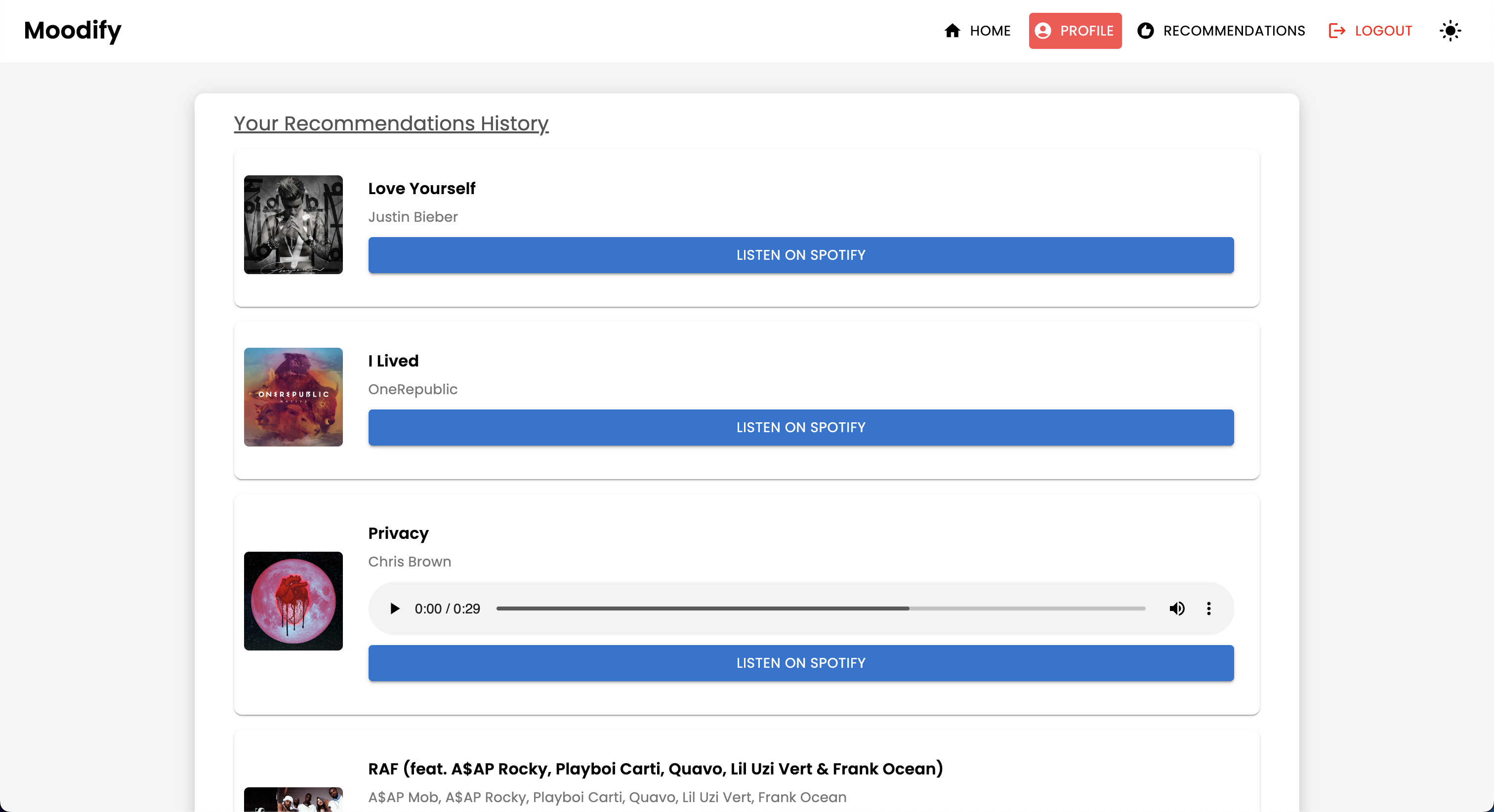
POST | /users/recommendations/ | Salvar recomendações para um usuário |
GET | /users/recommendations/<str:username>/ | Recuperar recomendações para um usuário por nome de usuário |
DELETE | /users/recommendations/<str:username>/<str:recommendation_id>/ | Exclua uma recomendação específica para um usuário |
DELETE | /users/recommendations/<str:username>/ | Exclua todas as recomendações para um usuário |
POST | /users/mood_history/<str:user_id>/ | Adicione um humor ao histórico de humor do usuário |
GET | /users/mood_history/<str:user_id>/ | Recuperar o histórico de humor para um usuário |
DELETE | /users/mood_history/<str:user_id>/ | Exclua um humor específico do histórico do usuário |
POST | /users/listening_history/<str:user_id>/ | Adicione uma faixa ao histórico de escuta do usuário |
GET | /users/listening_history/<str:user_id>/ | Recuperar o histórico de escuta para um usuário |
DELETE | /users/listening_history/<str:user_id>/ | Exclua uma faixa específica do histórico do usuário |
POST | /users/user_recommendations/<str:user_id>/ | Salve as recomendações de um usuário |
GET | /users/user_recommendations/<str:user_id>/ | Recuperar as recomendações de um usuário |
DELETE | /users/user_recommendations/<str:user_id>/ | Exclua todas as recomendações para um usuário |
POST | /users/verify-username-email/ | Verifique se um nome de usuário e e -mail são válidos |
POST | /users/reset-password/ | Redefina a senha de um usuário |
GET | /users/verify-token/ | Verifique o token de um usuário |
| Método HTTP | Endpoint | Descrição |
|---|---|---|
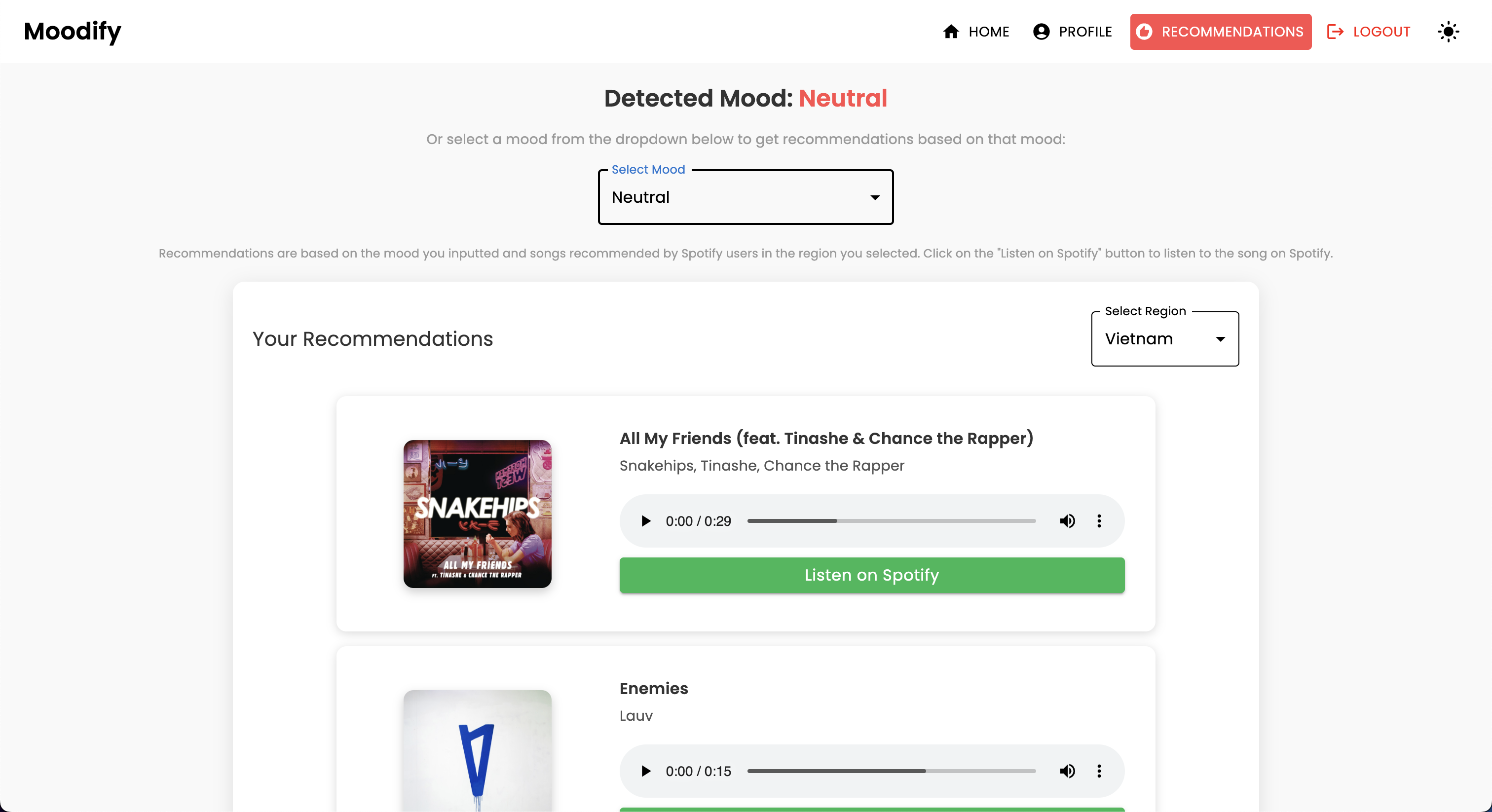
POST | /api/text_emotion/ | Analise o texto para conteúdo emocional |
POST | /api/speech_emotion/ | Analise o discurso para conteúdo emocional |
POST | /api/facial_emotion/ | Analisar expressões faciais para emoções |
POST | /api/music_recommendation/ | Obtenha recomendações musicais baseadas em emoção |
| Método HTTP | Endpoint | Descrição |
|---|---|---|
GET | /admin/ | Acesse a interface administrador do Django |
| Método HTTP | Endpoint | Descrição |
|---|---|---|
GET | /swagger/ | Acesse a documentação da API da UI da Swagger |
GET | /redoc/ | Acesse a documentação da API Redoc |
GET | / | Acesse o terminal da raiz da API (interface do usuário da Swagger) |
Crie um superusuário:
python manage.py createsuperuser Acesse o painel de administração em http://127.0.0.1:8000/admin/
Você deve ver a seguinte página de login:
Nossas APIs de back-end são todas bem documentadas usando UI Swagger e Redoc. Você pode acessar a documentação da API nos seguintes URLs:
https://moodify-emotion-music-app.onrender.com/swagger .https://moodify-emotion-music-app.onrender.com/redoc .Como alternativa, você pode executar o servidor de back -end localmente e acessar a documentação da API nos seguintes terminais:
http://127.0.0.1:8000/swagger .http://127.0.0.1:8000/redoc .Independentemente de sua escolha, você deve ver a seguinte documentação da API se tudo estiver funcionando corretamente:
Swagger Ui:
Redoc:
Os modelos AI/ML são construídos usando transformadores Pytorch, Tensorflow, Keras e Hugging Space. Esses modelos são treinados em vários conjuntos de dados para detectar emoções de texto, fala e expressões faciais.
Os modelos de detecção de emoções são usados para analisar as entradas do usuário e fornecer recomendações musicais em tempo real com base nas emoções detectadas. Os modelos são treinados em vários conjuntos de dados para capturar as nuances das emoções humanas e fornecer previsões precisas.
Os modelos são integrados aos serviços de API de back-end para fornecer detecção de emoções em tempo real e recomendações musicais para os usuários.
Os modelos devem ser treinados primeiro antes de usá -los nos serviços de back -end. Verifique se os modelos são treinados e colocados no diretório models antes de executar o servidor de back -end. Consulte a seção (Introdução) [#Gettinged] para obter mais detalhes.
 Exemplos de treinamento do modelo de emoção de texto.
Exemplos de treinamento do modelo de emoção de texto.
Para treinar os modelos, você pode executar os scripts fornecidos no diretório ai_ml/src/models . Esses scripts são usados para pré -processar os dados, treinar os modelos e salvar os modelos treinados para uso posterior. Esses scripts incluem:
train_text_emotion.py : treina o modelo de detecção de emoção de texto.train_speech_emotion.py : treina o modelo de detecção de emoção de fala.train_facial_emotion.py : Treina o modelo de detecção de emoção facial. Certifique -se de ter as dependências, conjuntos de dados e configurações necessários configurados antes de treinar os modelos. Especificamente, visite o arquivo config.py e atualize os caminhos para os conjuntos de dados e diretórios de saída para os corretos do seu sistema.
Nota: Por padrão, esses scripts priorizarão o uso da sua GPU com CUDA (se disponível) para treinamento mais rápido. No entanto, se isso não estiver disponível em sua máquina, os scripts voltarão automaticamente a usar a CPU para treinamento. Para garantir que você tenha as dependências necessárias para o treinamento da GPU, instale o Pytorch com suporte CUDA usando o seguinte comando:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 Depois disso, você pode executar o script test_emotion_models.py para testar os modelos treinados e garantir que eles estejam fornecendo previsões precisas:
python src/models/test_emotion_models.pyComo alternativa, você pode executar a API simples de frasco para testar os modelos por meio de pontos de extremidade da API RESTful:
python ai_ml/src/api/emotion_api.pyOs pontos de extremidade são os seguintes:
/text_emotion : detecta emoção da entrada de texto/speech_emotion : detecta emoção do áudio de fala/facial_emotion : detecta emoção de uma imagem/music_recommendation : fornece recomendações musicais com base na emoção detectada IMPORTANTE : Para obter mais informações sobre treinamento e uso dos modelos, consulte a documentação da IA/ML no diretório ai_ml .
No entanto, se o treinamento do modelo for muito intensivo para você, você poderá usar os seguintes links do Google Drive para baixar os modelos pré-treinados:
model.safetensors . Faça o download deste arquivo model.safetensors e coloque -o no diretório ai_ml/models/text_emotion_model .scaler.pkl . Faça o download disso e coloque isso no diretório ai_ml/models/speech_emotion_model .trained_speech_emotion_model.pkl . Faça o download disso e coloque isso no diretório ai_ml/models/speech_emotion_model .trained_facial_emotion_model.pt . Faça o download disso e coloque isso no diretório ai_ml/models/facial_emotion_model . Estes foram pré-treinados nos conjuntos de dados para você e estão prontos para uso nos serviços de back-end ou para fins de teste, uma vez baixados e colocados corretamente no diretório models .
Sinta -se à vontade para me conter se encontrar algum problema ou precisar de mais assistência com os modelos AI/ML.
A pasta data_analytics fornece scripts de análise e visualização de dados para obter informações sobre o desempenho do modelo de detecção de emoção.
Execute todos os scripts de análise:
python data_analytics/main.py Visualizar visualizações geradas na pasta visualizations .
Aqui estão algumas visualizações de exemplo:
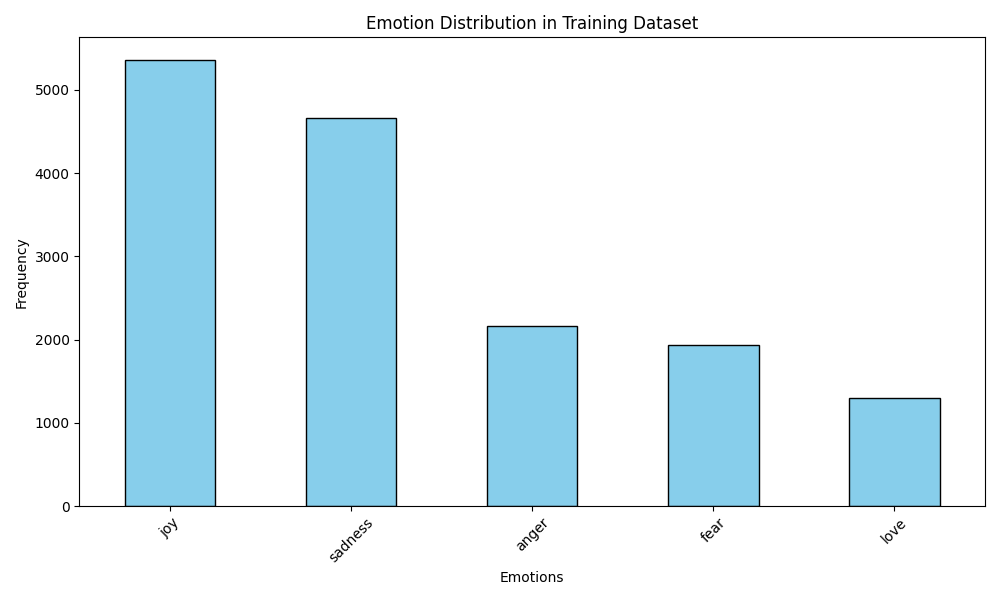 Visualização de distribuição de emoções
Visualização de distribuição de emoções
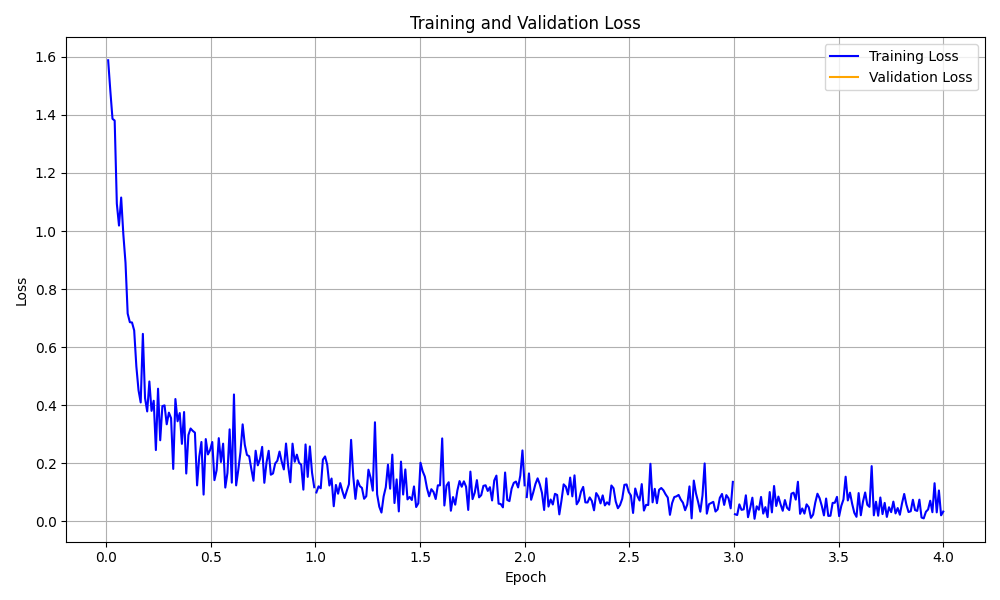 Visualização da curva de perda de treinamento
Visualização da curva de perda de treinamento
Há também uma versão móvel do aplicativo Moodify criado usando o React Native and Expo. Você pode encontrar o aplicativo móvel no diretório mobile .
Navegue até o diretório móvel:
cd ../mobileInstale dependências usando o YAR:
yarn installInicie o servidor de desenvolvimento da Expo:
yarn startDigitalize o código QR usando o aplicativo Expo Go no seu dispositivo móvel para executar o aplicativo.
Se for bem -sucedido, você deve ver a seguinte tela inicial:
Sinta -se à vontade para explorar o aplicativo móvel e testar suas funcionalidades!
O projeto usa Nginx e Gunicorn para balanceamento de carga e servir o back -end do Django. O NGINX atua como um servidor proxy reverso, enquanto o Gunicorn serve o aplicativo Django.
Instale o nginx:
sudo apt-get update
sudo apt-get install nginxInstale o Gunicorn:
pip install gunicornConfigure nginx:
/nginx/nginx.conf com sua configuração.Comece Nginx e Gunicorn:
sudo systemctl start nginxgunicorn backend.wsgi:application Acesse o back -end em http://<server_ip>:8000/ .
Sinta -se à vontade para personalizar as configurações do NGINX e as configurações de arma de arma, conforme necessário para sua implantação.
O projeto pode ser contêineido usando o Docker para facilitar a implantação e a escala. Você pode criar imagens do Docker para os modelos de front -end, back -end e AI/ML.
Construa as imagens do Docker:
docker compose up --buildAs imagens do Docker serão construídas para os modelos de front -end, back -end e AI/ML. Verifique as imagens usando:
docker imagesSe você encontrar algum erro, tente reconstruir sua imagem sem usar o cache, pois o cache do Docker pode causar problemas.
docker-compose build --no-cacheTambém adicionamos arquivos de implantação da Kubernetes para os serviços de back -end e front -end. Você pode implantar os serviços em um cluster Kubernetes usando os arquivos YAML fornecidos.
Implante o serviço de back -end:
kubectl apply -f kubernetes/backend-deployment.yamlImplante o serviço de front -end:
kubectl apply -f kubernetes/frontend-deployment.yamlExponha os Serviços:
kubectl expose deployment moodify-backend --type=LoadBalancer --port=8000
kubectl expose deployment moodify-frontend --type=LoadBalancer --port=3000Acesse os Serviços usando o IP do LoadBalancer:
http://<backend_loadbalancer_ip>:8000 .http://<frontend_loadbalancer_ip>:3000 . Sinta -se à vontade para visitar o diretório kubernetes para obter mais informações sobre os arquivos e configurações de implantação.
Também incluímos o Jenkins Pipeline Script para automatizar o processo de compilação e implantação. Você pode usar o Jenkins para automatizar o processo CI/CD para o aplicativo Moodify.
Instale Jenkins em seu servidor ou máquina local.
Crie um novo trabalho de pipeline de Jenkins:
Jenkinsfile no diretório jenkins .Execute o pipeline Jenkins:
Sinta -se à vontade para explorar o script Jenkins Pipeline no Jenkinsfile e personalizá -lo conforme necessário para o seu processo de implantação.
As contribuições são bem -vindas! Sinta -se à vontade para bifurcar o repositório e enviar uma solicitação de tração.
Observe que este projeto ainda está em desenvolvimento ativo e quaisquer contribuições são apreciadas.
Se você tiver alguma sugestão, solicitações de recursos ou relatórios de bugs, sinta -se à vontade para abrir um problema aqui.
Feliz codificação e vibin '! ?
Criado com ❤️ pelo filho Nguyen em 2024.
? De volta ao topo


