Moodify Emotion Music App
1.0.0
С ростом персонализированных услуг потоковой передачи музыки растет потребность в системах, которые могут рекомендовать музыку на основе эмоциональных состояний пользователей. Понимая эту потребность, Moodify разрабатывается Son Nguyen в 2024 году для предоставления персонализированных музыкальных рекомендаций, основанных на обнаруженных эмоциях пользователей.
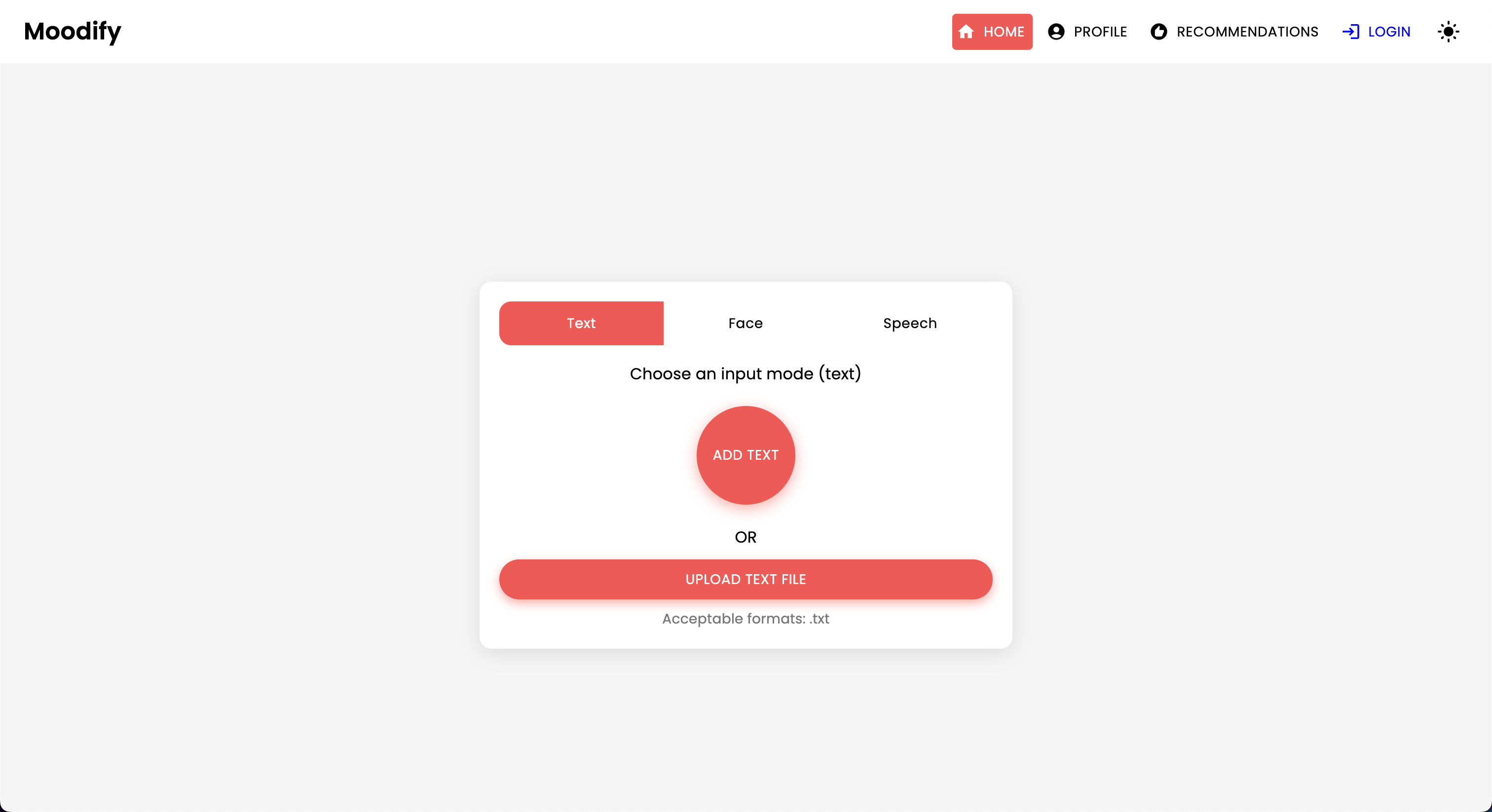
Проект Moodify -это интегрированная система музыкальной рекомендации на основе эмоций, которая объединяет модели Frontend, Backend, AI/ML и аналитику данных для предоставления персонализированных музыкальных рекомендаций на основе эмоций пользователей. Приложение анализирует текст, речь или выражения лица и предлагает музыку, которая соответствует обнаруженным эмоциям.
Поддерживая как настольные, так и мобильные платформы, Moodify предлагает беспрепятственный пользовательский опыт с рекомендациями в реальном времени и музыкальных рекомендациях. Проект использует реагирование на Frontend, Django для бэкэнда и три продвинутых, самостоятельных моделей AI/ML для обнаружения эмоций . Сценарии анализа данных используются для визуализации эмоциональных тенденций и производительности модели.

Moodify предоставляет персонализированные музыкальные рекомендации, основанные на эмоциональных состояниях пользователей, обнаруженных с помощью текста, речи и выражений лица. Он взаимодействует с бэкэнд на основе Django, моделей AI/ML для обнаружения эмоций и использует аналитику данных для визуального понимания эмоциональных тенденций и производительности модели.
Приложение Moodify в настоящее время живет и развернуто на Vercel. Вы можете получить доступ к приложению Live, используя следующую ссылку: Moodify.
Не стесняйтесь посещать бэкэнд на Moodify Backend API.
DiClaimer: Бэкэнд Moodify в настоящее время размещен с бесплатным уровнем рендеринга, поэтому для загрузки может потребоваться несколько секунд. Кроме того, он может вращаться после периода бездействия или высокого трафика, поэтому, пожалуйста, будьте терпеливы, если на ответный ответ занимает несколько секунд.
Кроме того, объем памяти, выделяемой рендерингом, составляет всего 512 МБ с 0,1 ЦП , поэтому бэкэнд может исходить из памяти, если есть слишком много запросов одновременно, что может привести к перезагрузке сервера. Кроме того, модели обнаружения эмоций и речи также могут потерпеть неудачу из -за ограничений памяти, что также может привести к перезагрузке сервера.
Нет никакой гарантии времени безотказной работы или производительности с текущим развертыванием, если у меня нет больше ресурсов (денег) для обновления сервера :( Не стесняйтесь обращаться ко мне, если вы столкнетесь с какими -либо проблемами или нуждаемся в дальнейшей помощи.
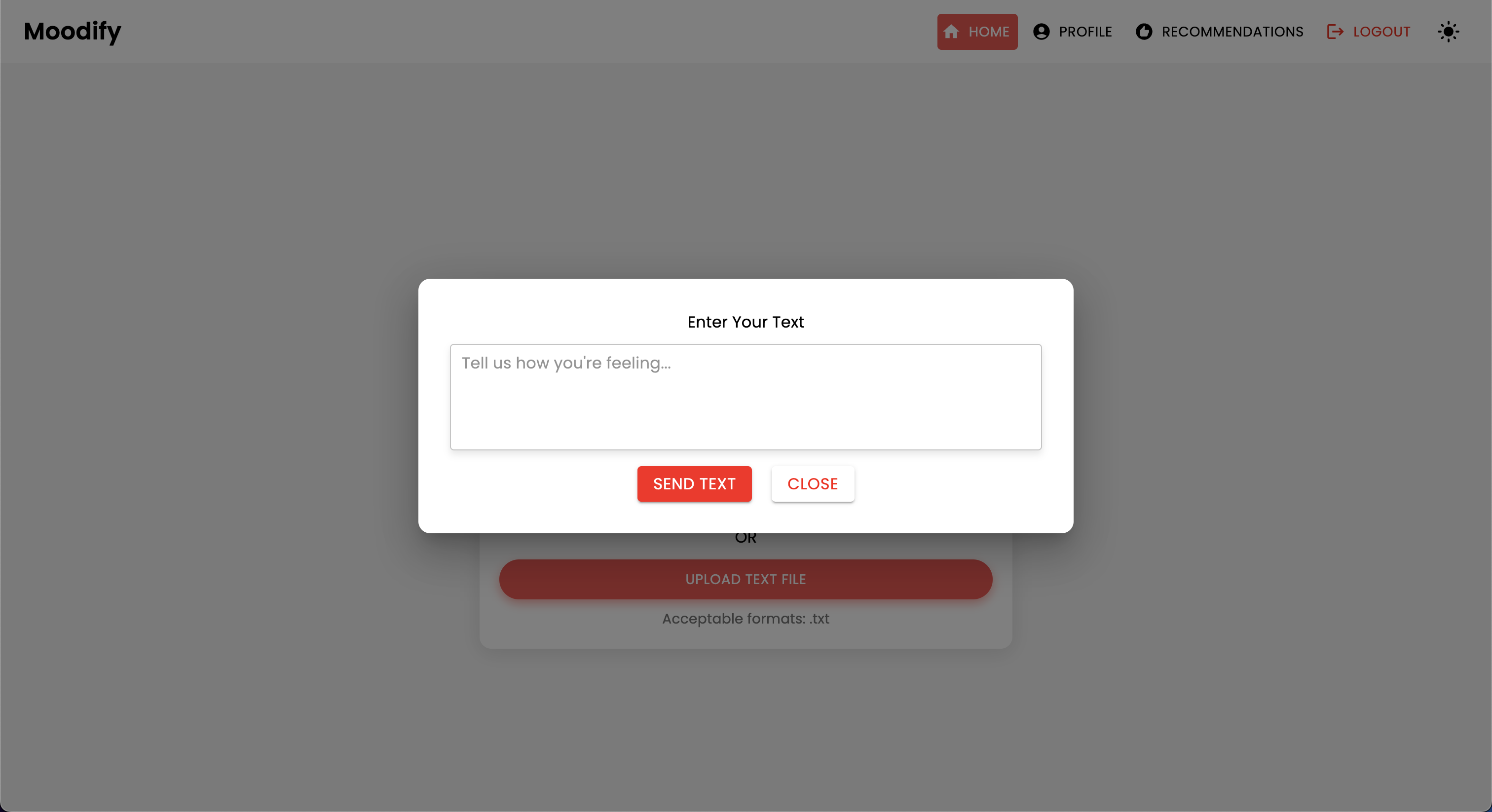
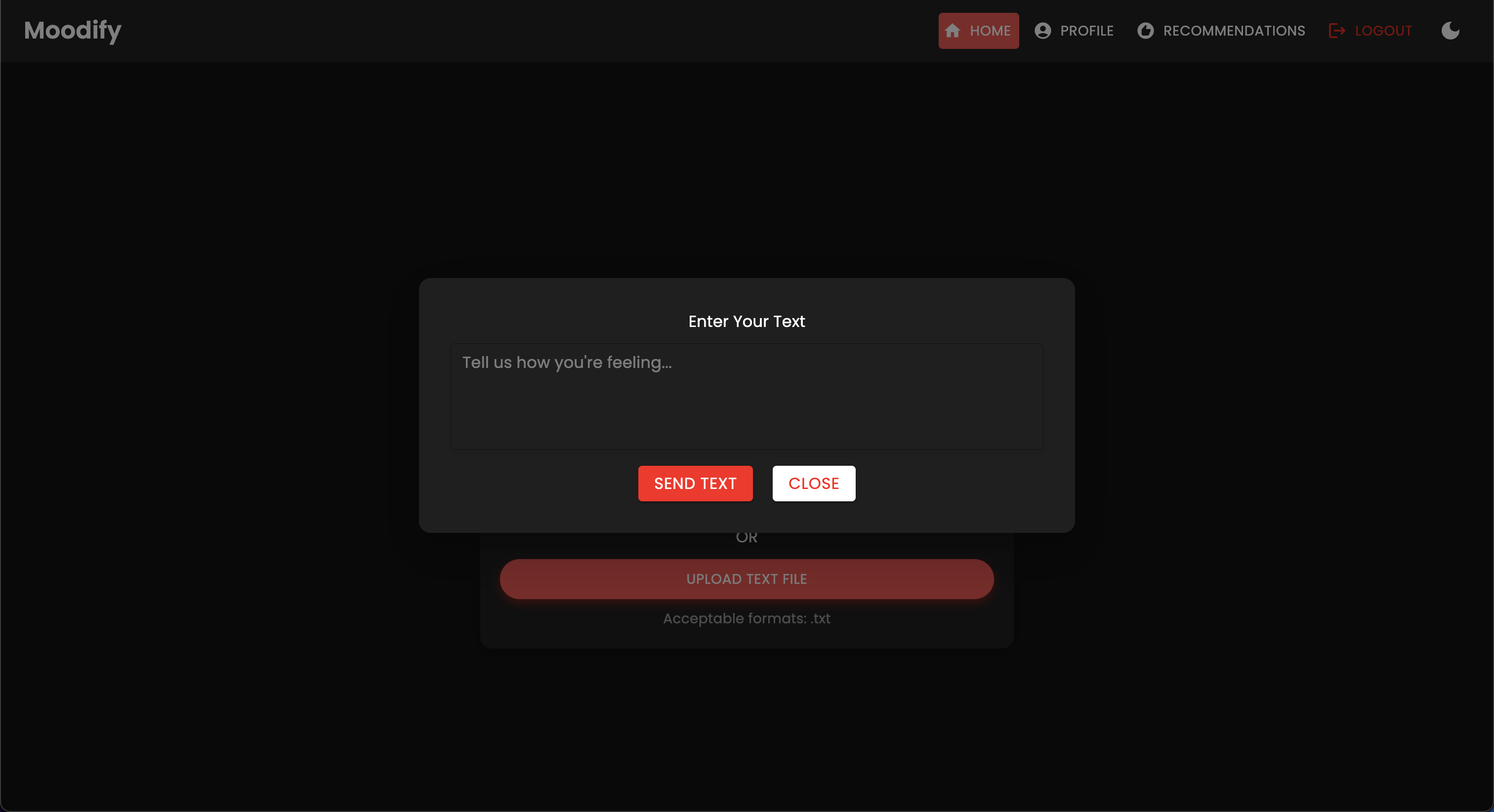
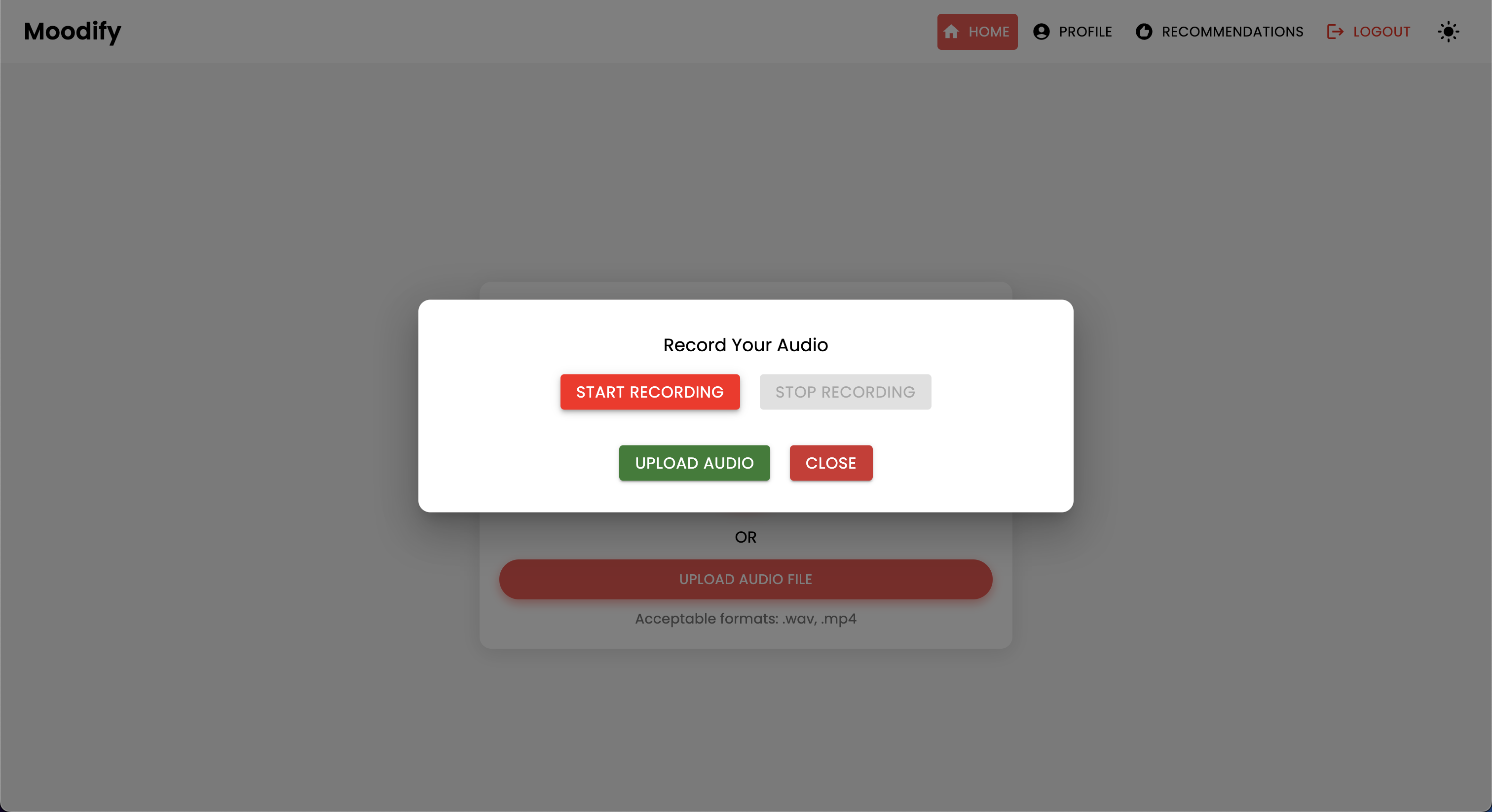
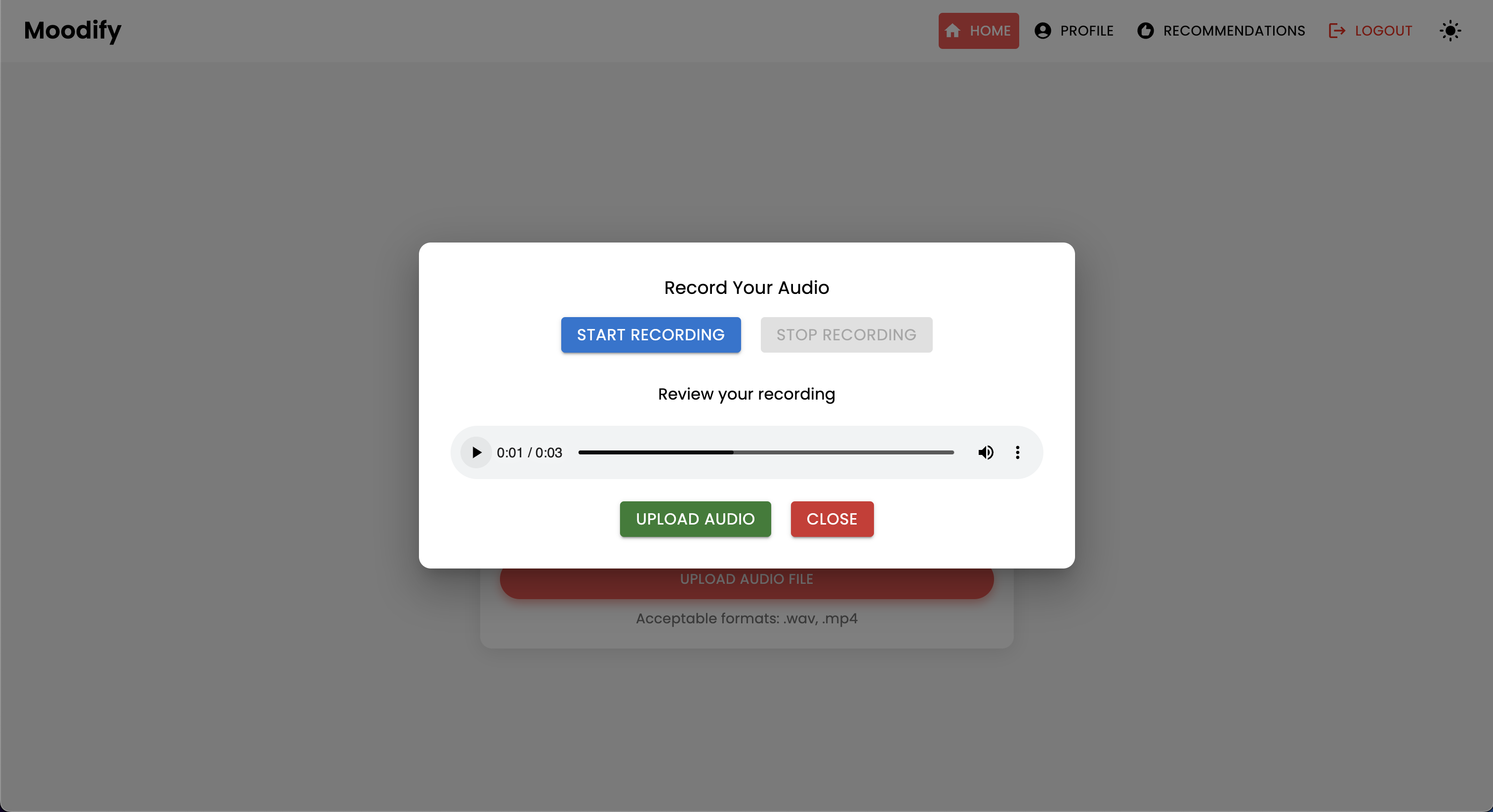
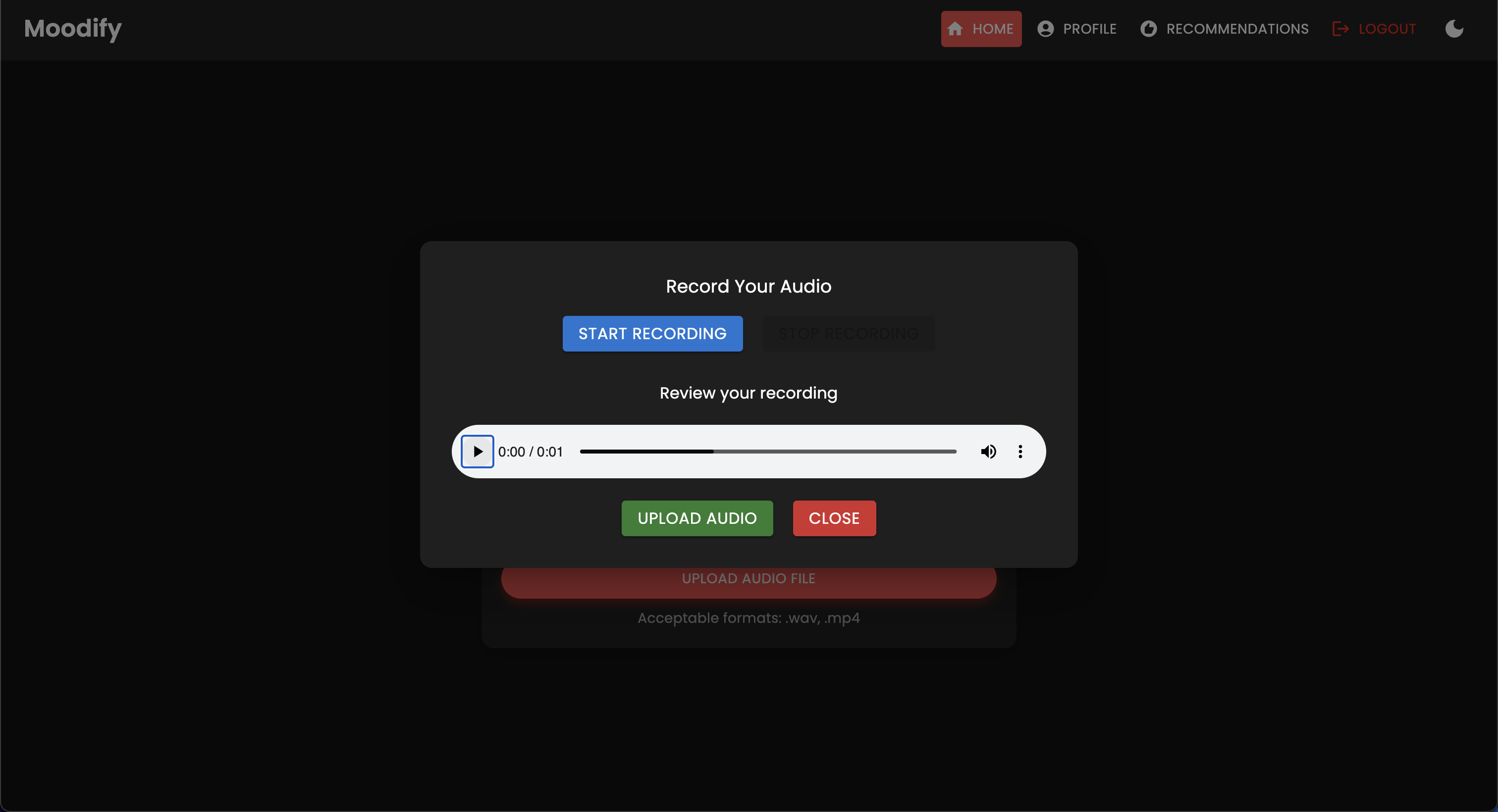
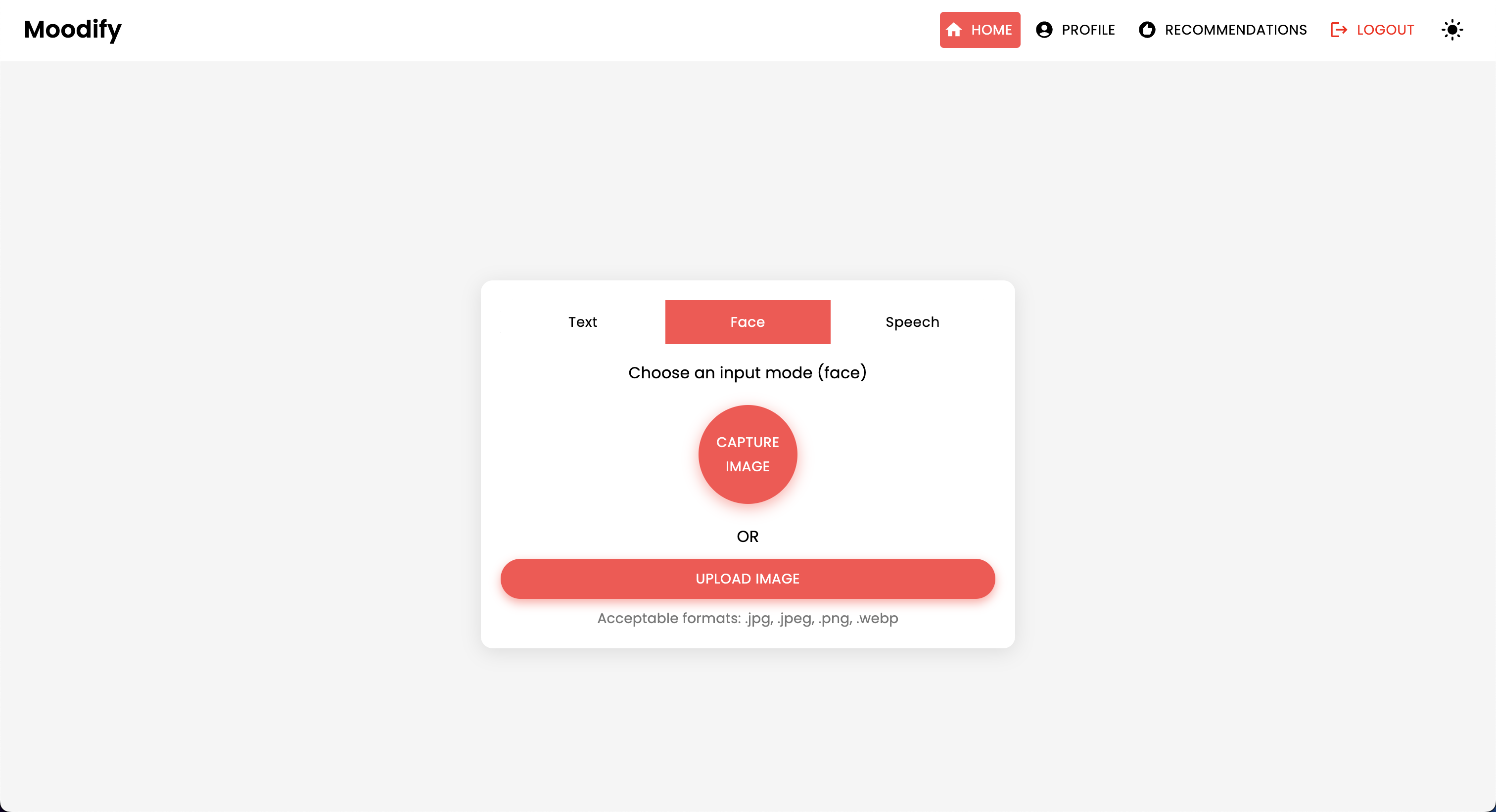

Проект имеет комплексную структуру файлов, объединяющая модели Frontend, Backend, AI/ML и компоненты анализа данных:
Moodify-Emotion-Music-App/
├── frontend/ # React frontend for the web application
│ ├── public/
│ │ ├── index.html # Main HTML file
│ │ ├── manifest.json # Web app manifest
│ │ └── favicon.ico # Favicon for the app
│ │
│ ├── src/
│ │ ├── components/ # Contains all React components
│ │ ├── pages/ # Contains main pages of the app
│ │ ├── styles/ # Contains global styles and themes
│ │ ├── context/ # Contains React Context API
│ │ ├── App.js # Main App component
│ │ ├── index.js # Entry point for React
│ │ └── theme.js # Material UI theme configuration
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ ├── package.json # NPM dependencies and scripts
│ └── README.md # Project documentation
│
├── backend/ # Django backend for API services and database management
│ ├── manage.py # Django's command-line utility
│ ├── requirements.txt # Backend dependencies
│ ├── backend/
│ │ ├── settings.py # Django settings for the project
│ │ ├── urls.py # URL declarations for the project
│ │ ├── users/ # User management components
│ │ └── api/ # Emotion detection and recommendation APIs
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ └── db.sqlite3 # SQLite database (if used)
│
├── ai_ml/ # AI/ML models for emotion detection
│ ├── data/ # Datasets for training and testing
│ ├── models/ # Trained models for emotion detection
│ ├── src/ # Source files for emotion detection and recommendation
│ │ ├── api/ # API scripts for running emotion detection services
│ │ ├── recommendation/ # Music recommendation logic
│ │ └── data_processing/ # Data preprocessing scripts
│ │
│ ├── Dockerfile # Dockerfile for containerization
│ └── README.md # AI/ML documentation
│
├── data_analytics/ # Data analytics scripts and visualizations
│ ├── emotion_distribution.py # Script for visualizing emotion distribution
│ ├── training_visualization.py # Script for visualizing training and validation metrics
│ ├── predictions_analysis.py # Script for analyzing model predictions
│ ├── recommendation_analysis.py # Script for visualizing music recommendations
│ ├── spark-hadoop/ # Spark and Hadoop integration scripts
│ └── visualizations/ # Generated visualizations
│
├── kubernetes/ # Kubernetes deployment files
│ ├── backend-deployment.yaml # Deployment file for the backend service
│ ├── backend-service.yaml # Deployment file for the backend service
│ ├── frontend-deployment.yaml # Deployment file for the frontend service
│ ├── frontend-service.yaml # Deployment file for the frontend service
│ └── configmap.yaml # ConfigMap for environment variables
│
├── mobile/ # React Native mobile application
│ ├── App.js # Main entry point for React Native app
│ ├── index.js # App registry for React Native
│ ├── package.json # NPM dependencies and scripts
│ ├── components/ # React Native components
│ │ ├── Footer.js # Footer component
│ │ ├── Navbar.js # Header component
│ │ ├── Auth/ # Authentication components (e.g., Login, Register)
│ │ └── Profile/ # Profile-related components
│ │
│ ├── context/ # React Context API for state management
│ │ └── DarkModeContext.js # Dark mode context provider
│ │
│ ├── pages/ # Main pages of the app
│ │ ├── HomePage.js # Home page component
│ │ ├── ProfilePage.js # Profile page component
│ │ ├── ResultsPage.js # Results page component
│ │ ├── LandingPage.js # Landing page component
│ │ └── (and more...)
│ │
│ ├── assets/ # Images, fonts, and other assets
│ ├── styles/ # Styling files (similar to CSS for web)
│ ├── .gitignore # Git ignore file
│ ├── package.json # Dependencies and scripts
│ └── README.md # Mobile app documentation
│
├── nginx/ # NGINX configuration files (for load balancing and reverse proxy)
│ ├── nginx.conf # Main NGINX configuration file
│ └── Dockerfile # Dockerfile for NGINX container
│
├── images/ # Images used in the README documentation
├── docker-compose.yml # Docker Compose file for containerization
└── README.md # Comprehensive README file for the entire project
venv ).env Файл (для переменных среды - вы создаете свои собственные учетные данные, следуя примеру файла или свяжитесь со мной для моего.)Начните с настройки и обучения моделей AI/ML, так как они потребуются, чтобы бэкэнд функционировал должным образом.
Или вы можете загрузить предварительно обученные модели по ссылкам Google Drive, представленным в разделе предварительно обученных моделей. Если вы решите сделать это, вы можете пропустить этот раздел.
Клонировать репозиторий:
git clone https://github.com/hoangsonww/Moodify-Emotion-Music-App.gitПерейдите в каталог AI/ML:
cd Moodify-Emotion-Music-App/ai_mlСоздать и активировать виртуальную среду:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsУстановить зависимости:
pip install -r requirements.txt Отредактируйте конфигурации в файле src/config.py :
src/config.py и обновите конфигурации по мере необходимости, особенно ваши клавиши Spotify API и настройте все пути.src/models и обновите пути для наборов данных и пути вывода по мере необходимости.Обучить текстовую модель эмоций:
python src/models/train_text_emotion.pyПовторите аналогичные команды для других моделей по мере необходимости (например, модели лицевых и речевых эмоций).
Убедитесь, что все обученные модели помещаются в каталог models , и что вы обучили все необходимые модели, прежде чем перейти к следующему шагу!
Проверьте обученные модели AI/ML по мере необходимости :
src/models/test_emotion_models.py чтобы проверить обученные модели.Как только модели AI/ML будут готовы, приступите к настройке бэкэнда.
Перейдите в справочный каталог:
cd ../backendСоздать и активировать виртуальную среду:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsУстановить зависимости:
pip install -r requirements.txtНастройте свои секреты и среду:
.env в backend ..env : SECRET_KEY=your_secret_key
DEBUG=True
ALLOWED_HOSTS=<your_hosts>
MONGODB_URI=<your_mongodb_uri>
backend/settings.py и добавьте SECRET_KEY & set DEBUG в True .Запустить миграции базы данных:
python manage.py migrateЗапустите сервер Django:
python manage.py runserver Бэкэнд -сервер будет работать по адресу http://127.0.0.1:8000/ .
Наконец, установите фронт, чтобы взаимодействовать с бэкэнд.
Перейдите к каталогу Frontend:
cd ../frontendУстановите зависимости, используя пряжу:
npm installЗапустите сервер разработки:
npm start Frontend начнется по адресу http://localhost:3000 .
Примечание. Если вы столкнетесь с какими -либо проблемами или нуждаетесь в моем файле .env , не стесняйтесь обращаться ко мне.
| HTTP Метод | Конечная точка | Описание |
|---|---|---|
POST | /users/register/ | Зарегистрируйте нового пользователя |
POST | /users/login/ | Войдите пользователя и получите токен JWT |
GET | /users/user/profile/ | Получить профиль аутентифицированного пользователя |
PUT | /users/user/profile/update/ | Обновите профиль аутентифицированного пользователя |
DELETE | /users/user/profile/delete/ | Удалить профиль аутентифицированного пользователя |
POST | /users/recommendations/ | Сохранить рекомендации для пользователя |
GET | /users/recommendations/<str:username>/ | Получить рекомендации для пользователя по имени пользователя |
DELETE | /users/recommendations/<str:username>/<str:recommendation_id>/ | Удалить конкретную рекомендацию для пользователя |
DELETE | /users/recommendations/<str:username>/ | Удалить все рекомендации для пользователя |
POST | /users/mood_history/<str:user_id>/ | Добавьте настроение в историю настроения пользователя |
GET | /users/mood_history/<str:user_id>/ | Получить историю настроения для пользователя |
DELETE | /users/mood_history/<str:user_id>/ | Удалить конкретное настроение из истории пользователя |
POST | /users/listening_history/<str:user_id>/ | Добавьте трек в историю прослушивания пользователя |
GET | /users/listening_history/<str:user_id>/ | Получить историю прослушивания для пользователя |
DELETE | /users/listening_history/<str:user_id>/ | Удалить конкретный трек из истории пользователя |
POST | /users/user_recommendations/<str:user_id>/ | Сохранить рекомендации пользователя |
GET | /users/user_recommendations/<str:user_id>/ | Получить рекомендации пользователя |
DELETE | /users/user_recommendations/<str:user_id>/ | Удалить все рекомендации для пользователя |
POST | /users/verify-username-email/ | Убедитесь, что имя пользователя и электронная почта действительны |
POST | /users/reset-password/ | Сбросить пароль пользователя |
GET | /users/verify-token/ | Проверьте токен пользователя |
| HTTP Метод | Конечная точка | Описание |
|---|---|---|
POST | /api/text_emotion/ | Проанализировать текст на эмоциональный контент |
POST | /api/speech_emotion/ | Проанализировать речь на эмоциональный содержание |
POST | /api/facial_emotion/ | Проанализировать выражения лица на эмоции |
POST | /api/music_recommendation/ | Получить музыкальные рекомендации на основе эмоций |
| HTTP Метод | Конечная точка | Описание |
|---|---|---|
GET | /admin/ | Доступ к интерфейсу администратора Django |
| HTTP Метод | Конечная точка | Описание |
|---|---|---|
GET | /swagger/ | Доступ к документации API API Swagger |
GET | /redoc/ | Доступ к документации REDOC API |
GET | / | Доступ к конечной точке API -корня (Swagger UI) |
Создайте суперпользователь:
python manage.py createsuperuser Доступ к панели администратора по адресу http://127.0.0.1:8000/admin/
Вы должны увидеть следующую страницу входа в систему:
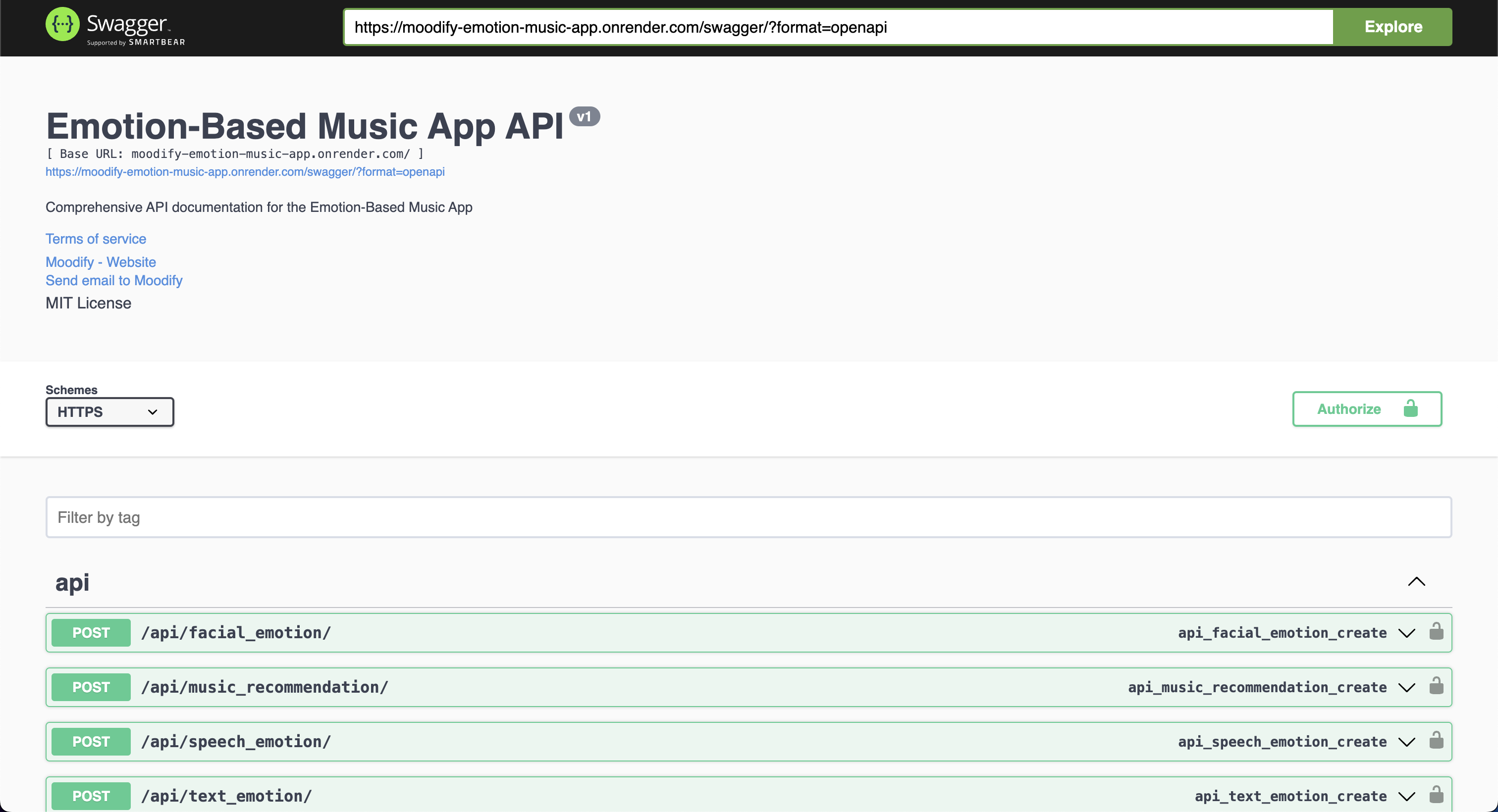
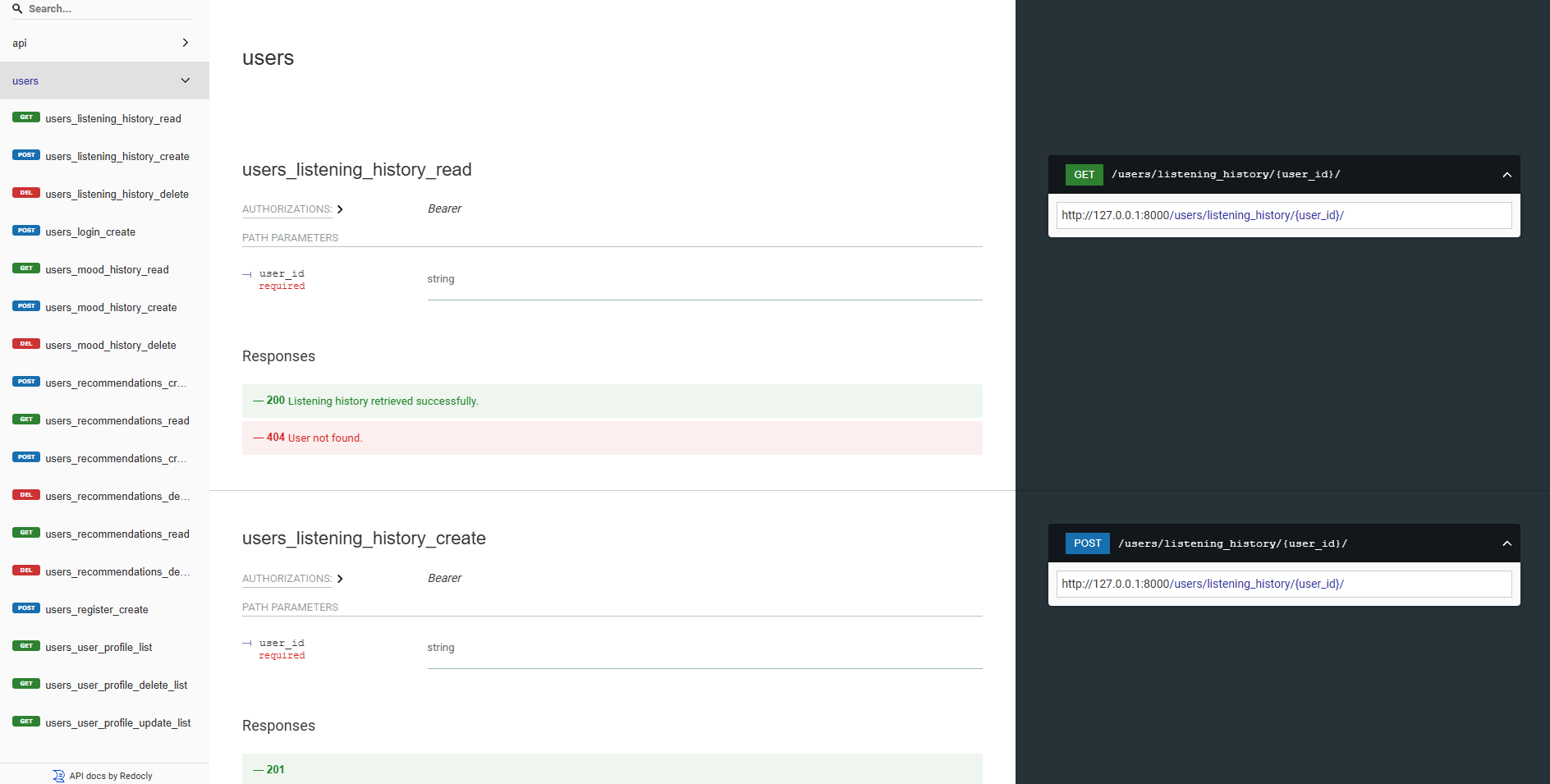
Все наши бэкэнд API хорошо документированы с использованием пользовательского интерфейса Swagger и Redoc. Вы можете получить доступ к документации API на следующих URL:
https://moodify-emotion-music-app.onrender.com/swagger .https://moodify-emotion-music-app.onrender.com/redoc .В качестве альтернативы, вы можете запустить бэкэнд -сервер локально и получить доступ к документации API в следующих конечных точках:
http://127.0.0.1:8000/swagger .http://127.0.0.1:8000/redoc .Независимо от вашего выбора, вы должны увидеть следующую документацию API, если все работает правильно:
Swagger UI:
Redoc:
Модели AI/ML построены с использованием Pytorch, Tensorflow, Keras и Trangingface Transformers. Эти модели обучаются на различных наборах данных для обнаружения эмоций из текста, речи и выражений лица.
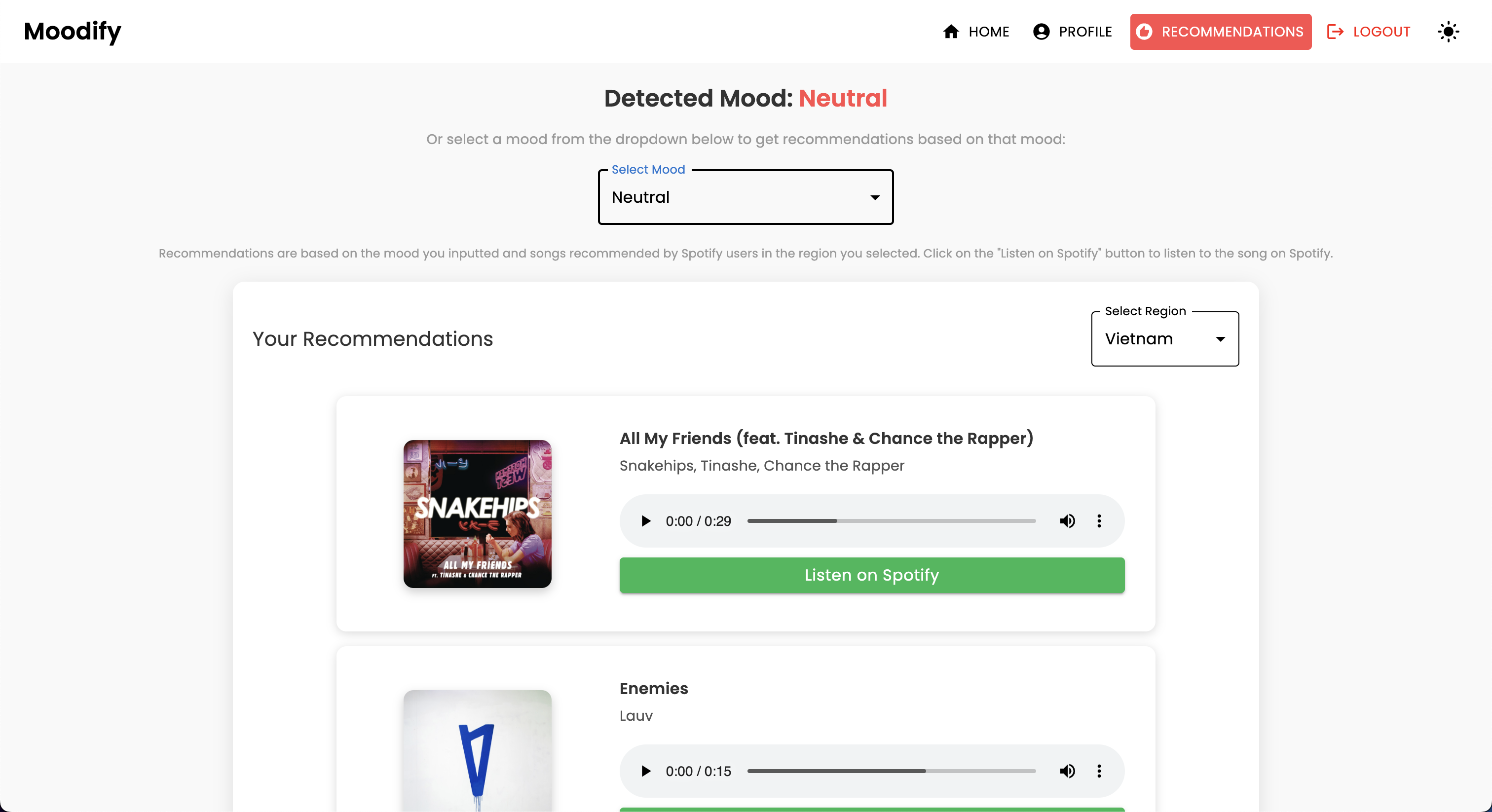
Модели обнаружения эмоций используются для анализа пользовательских входов и предоставления музыкальных рекомендаций в реальном времени на основе обнаруженных эмоций. Модели обучаются на различных наборах данных для захвата нюансов человеческих эмоций и обеспечения точных прогнозов.
Модели интегрированы в сервис API Backend для предоставления рекомендаций эмоций в реальном времени и музыкальных рекомендаций для пользователей.
Модели должны быть обучены первыми, прежде чем использовать их в бэкэнд -службах. Убедитесь, что модели обучены и размещены в каталоге models перед запуском сервера Backend. Обратитесь к разделу (начало) [#Запуск] для получения более подробной информации.
 Примеры обучения текстовой модели эмоций.
Примеры обучения текстовой модели эмоций.
Чтобы тренировать модели, вы можете запустить предоставленные сценарии в каталоге ai_ml/src/models . Эти сценарии используются для предварительной обработки данных, обучения моделей и сохранения обученных моделей для последующего использования. Эти сценарии включают:
train_text_emotion.py : Trains текстовой модели обнаружения эмоций.train_speech_emotion.py : обучение модели обнаружения эмоций речи.train_facial_emotion.py : обучение модели обнаружения эмоций лица. Убедитесь, что у вас есть необходимые зависимости, наборы данных и конфигурации, настроенные перед обучением моделей. В частности, убедитесь, что посетите файл config.py и обновите пути для наборов данных и выходных каталогов для правильных в вашей системе.
ПРИМЕЧАНИЕ. По умолчанию эти сценарии будут определять приоритеты, используя ваш графический процессор с CUDA (если доступно) для более быстрого обучения. Однако, если это недоступно на вашей машине, сценарии автоматически вернутся к использованию ЦП для обучения. Чтобы убедиться, что у вас есть необходимые зависимости для обучения графического процессора, установите Pytorch с поддержкой CUDA, используя следующую команду:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 После этого вы можете запустить сценарий test_emotion_models.py , чтобы проверить обученные модели и убедиться, что они обеспечивают точные прогнозы:
python src/models/test_emotion_models.pyВ качестве альтернативы, вы можете запустить API Simple Flask, чтобы проверить модели с помощью конечных точек API RESTFUL:
python ai_ml/src/api/emotion_api.pyКонечные точки следующие:
/text_emotion : обнаруживает эмоции от ввода текста/speech_emotion : обнаруживает эмоции от речевого звука/facial_emotion : обнаруживает эмоции из изображения/music_recommendation : предоставляет музыкальные рекомендации на основе обнаруженных эмоций Важно : для получения дополнительной информации об обучении и использовании моделей, пожалуйста, обратитесь к документации AI/ML в каталоге ai_ml .
Однако, если обучение модели слишком интенсивно для вас ресурсов, вы можете использовать следующие ссылки Google Drive для загрузки предварительно обученных моделей:
model.safetensors . Пожалуйста, загрузите этот файл model.safetensors и поместите его в каталог ai_ml/models/text_emotion_model .scaler.pkl . Пожалуйста, загрузите это и поместите это в каталог ai_ml/models/speech_emotion_model .trained_speech_emotion_model.pkl . Пожалуйста, загрузите это и поместите это в каталог ai_ml/models/speech_emotion_model .trained_facial_emotion_model.pt . Пожалуйста, загрузите это и поместите это в каталог ai_ml/models/facial_emotion_model . Они были предварительно обучены на наборах данных для вас и готовы к использованию в сервисах бэкэнд или для целей тестирования после загрузки и правильного размещения в каталоге models .
Не стесняйтесь содержать меня, если вы столкнетесь с какими -либо проблемами или нуждаетесь в дальнейшей помощи с моделями AI/ML.
Папка data_analytics предоставляет сценарии анализа данных и визуализации, чтобы получить представление о производительности модели обнаружения эмоций.
Запустите все аналитические сценарии:
python data_analytics/main.py Просмотреть сгенерированные визуализации в папке visualizations .
Вот некоторые примеры визуализации:
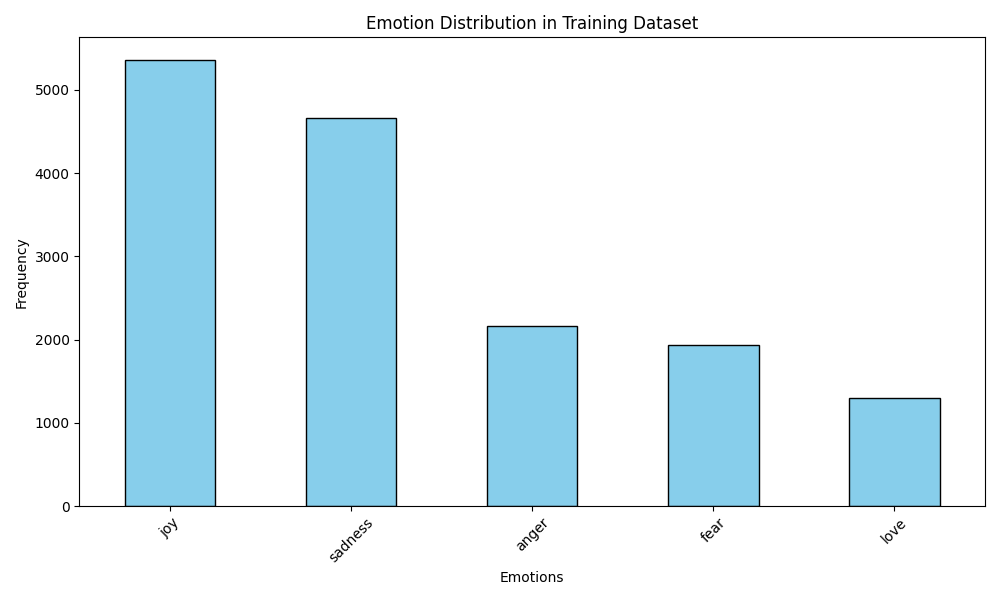 Визуализация распределения эмоций
Визуализация распределения эмоций
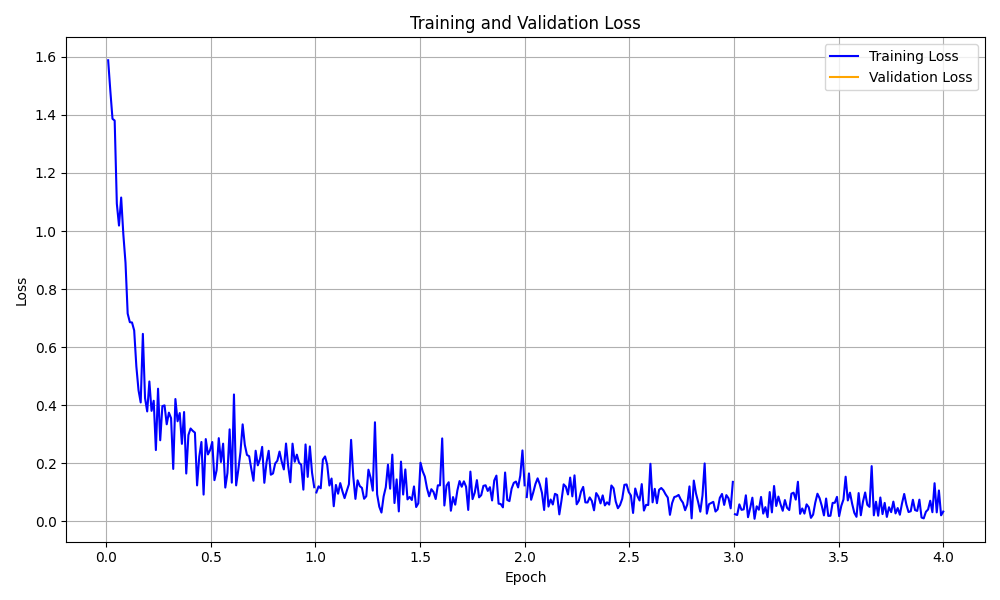 Визуализация кривой потерь обучения
Визуализация кривой потерь обучения
Существует также мобильная версия приложения Moodify, созданного с использованием REACT Native и Expo. Вы можете найти мобильное приложение в mobile каталоге.
Перейдите в мобильный каталог:
cd ../mobileУстановите зависимости, используя пряжу:
yarn installЗапустите сервер разработки Expo:
yarn startСканируйте QR -код, используя приложение Expo Go на вашем мобильном устройстве для запуска приложения.
В случае успеха вы должны увидеть следующий домашний экран:
Не стесняйтесь исследовать мобильное приложение и проверить его функции!
Проект использует NGINX и стреляющегося для балансировки нагрузки и обслуживания бэкэнда Django. Nginx выступает как обратный прокси -сервер, в то время как стрелочный зал обслуживает приложение Django.
Установите Nginx:
sudo apt-get update
sudo apt-get install nginxУстановите овиновник:
pip install gunicornНастройте Nginx:
/nginx/nginx.conf с вашей конфигурацией.Начните Nginx и стреляющегося:
sudo systemctl start nginxgunicorn backend.wsgi:application Получите доступ к бэкэнд по адресу http://<server_ip>:8000/ .
Не стесняйтесь настраивать настройки NGINX и настройки надзора по при необходимости для развертывания.
Проект может быть контейнер с использованием Docker для легкого развертывания и масштабирования. Вы можете создавать изображения Docker для моделей Frontend, Backend и AI/ML.
Создайте изображения Docker:
docker compose up --buildИзображения Docker будут построены для моделей Frontend, Backend и AI/ML. Проверьте изображения, используя:
docker imagesЕсли вы столкнетесь с какими -либо ошибками, попробуйте восстановить свое изображение без использования кэша, поскольку кэш Docker может вызвать проблемы.
docker-compose build --no-cacheМы также добавили файлы развертывания Kubernetes для сервисов Backend и Frontend. Вы можете развернуть сервисы на кластере Kubernetes, используя предоставленные файлы YAML.
Развернуть сервис бэкэнд:
kubectl apply -f kubernetes/backend-deployment.yamlРазвернуть сервис Frontend:
kubectl apply -f kubernetes/frontend-deployment.yamlРазоблачить услуги:
kubectl expose deployment moodify-backend --type=LoadBalancer --port=8000
kubectl expose deployment moodify-frontend --type=LoadBalancer --port=3000Доступ к Сервисам, используя IP LoadBalancer:
http://<backend_loadbalancer_ip>:8000 .http://<frontend_loadbalancer_ip>:3000 . Не стесняйтесь посетить каталог kubernetes для получения дополнительной информации о файлах развертывания и конфигурациях.
Мы также включили сценарий трубопровода Дженкинса для автоматизации процесса сборки и развертывания. Вы можете использовать Jenkins для автоматизации процесса CI/CD для приложения Moodify.
Установите Jenkins на ваш сервер или локальную машину.
Создайте новую работу по трубопроводу Jenkins:
Jenkinsfile в каталоге jenkins .Запустите трубопровод Jenkins:
Не стесняйтесь исследовать сценарий трубопровода Дженкинса в Jenkinsfile и настроить его по мере необходимости для процесса развертывания.
Взносы приветствуются! Не стесняйтесь раскошелиться на репозиторий и отправить запрос на привлечение.
Обратите внимание, что этот проект по -прежнему находится в активном развитии, и любые взносы ценятся.
Если у вас есть какие -либо предложения, запросы на функции или отчеты об ошибках, не стесняйтесь открывать проблему здесь.
Счастливое кодирование и вибин! ?
Создан с сыном Нгуеном в 2024 году.
? Вернуться к вершине


