Moodify Emotion Music App
1.0.0
Con el aumento de los servicios personalizados de transmisión de música, existe una creciente necesidad de sistemas que puedan recomendar música basada en los estados emocionales de los usuarios. Al darse cuenta de esta necesidad, HOOGIFY está siendo desarrollado por su hijo Nguyen en 2024 para proporcionar recomendaciones musicales personalizadas basadas en las emociones detectadas de los usuarios.
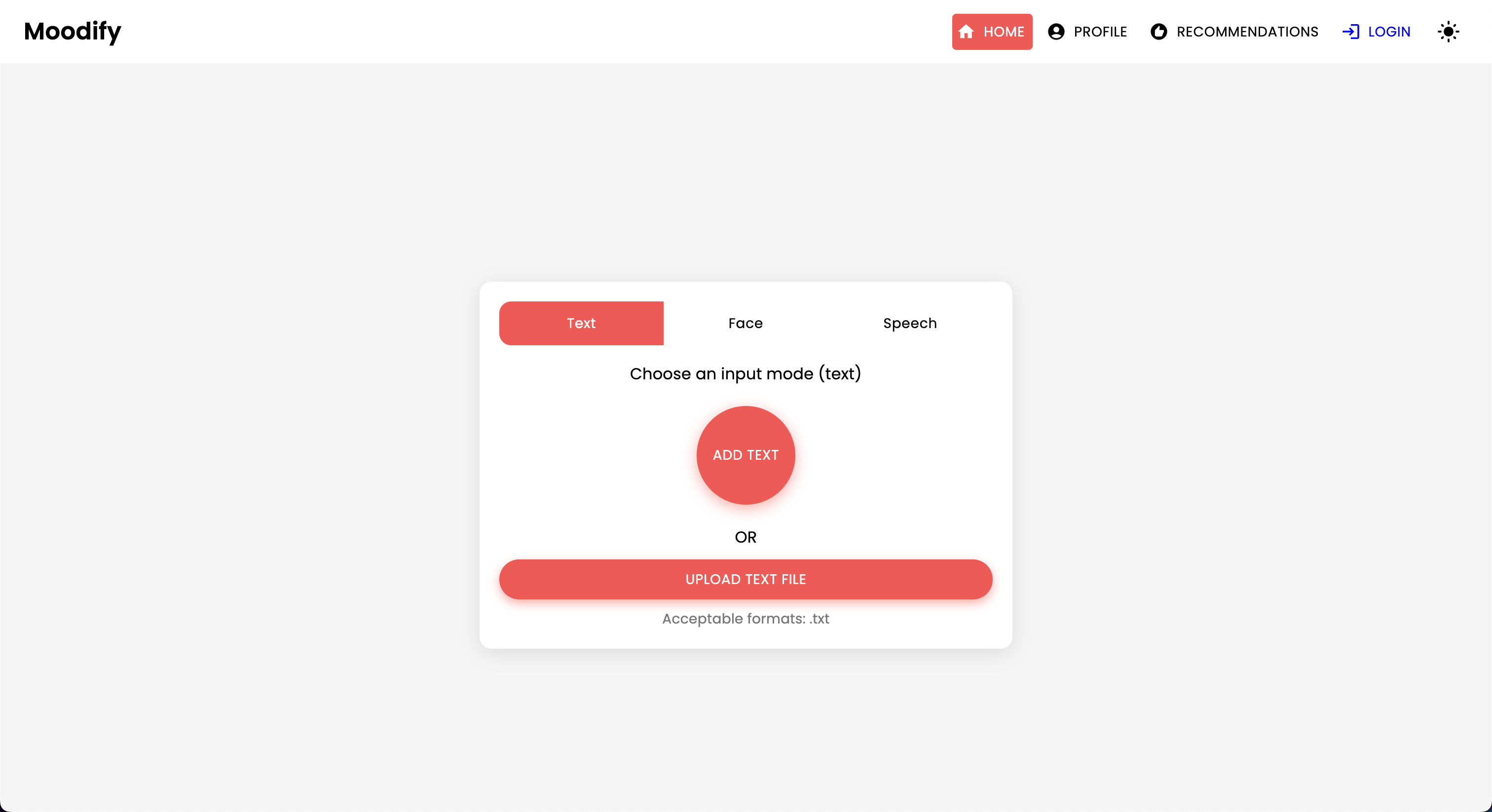
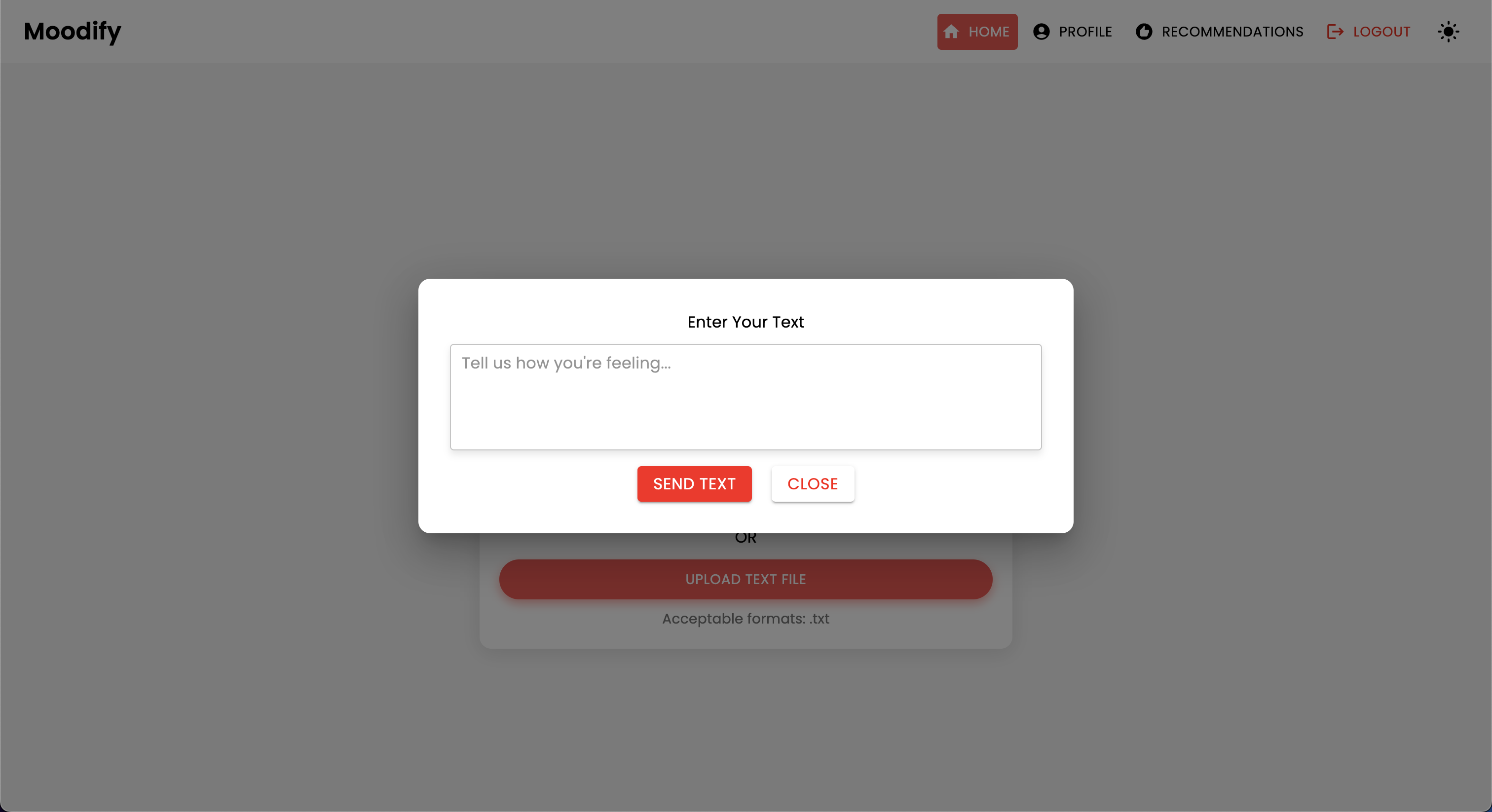
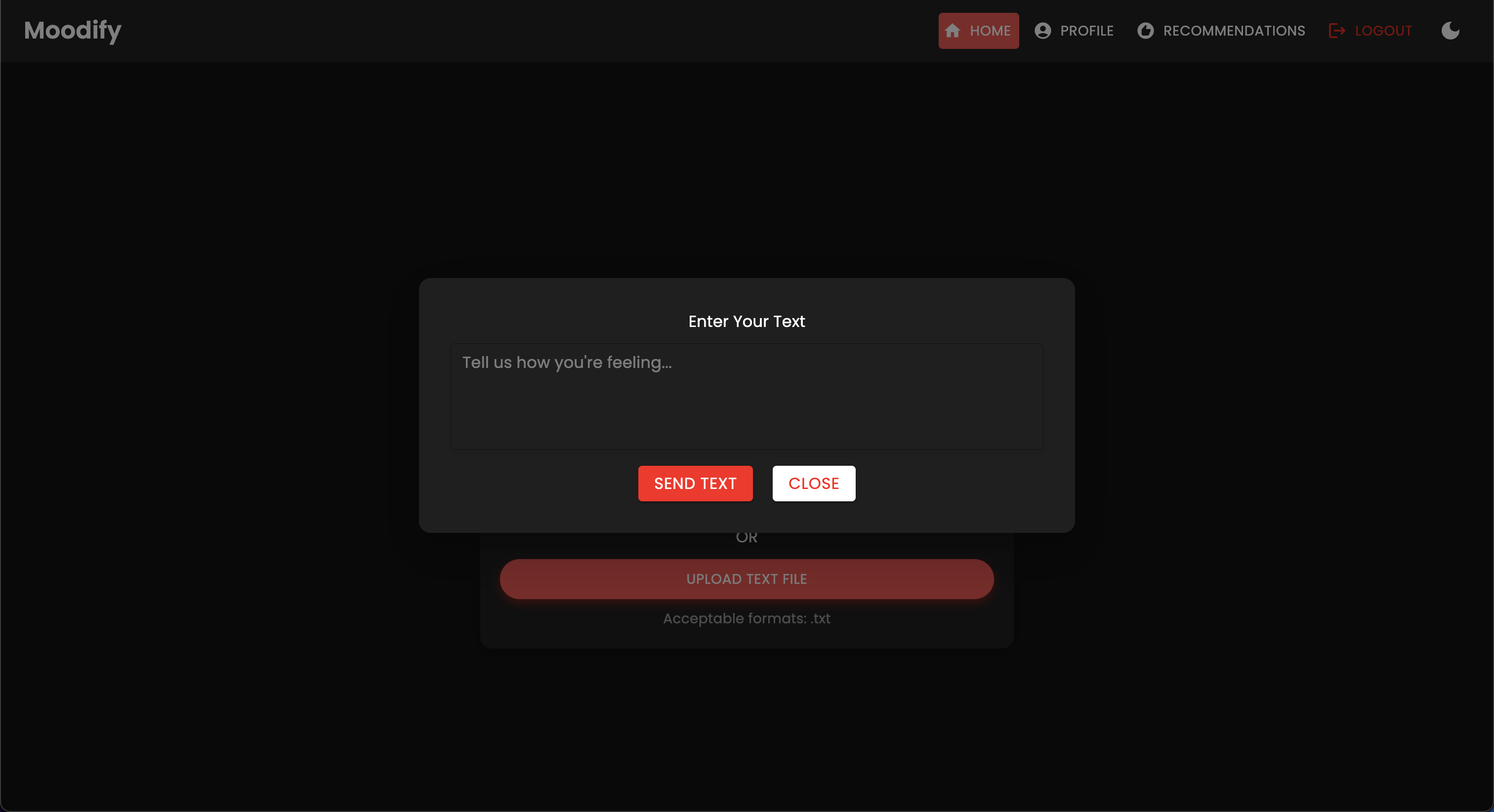
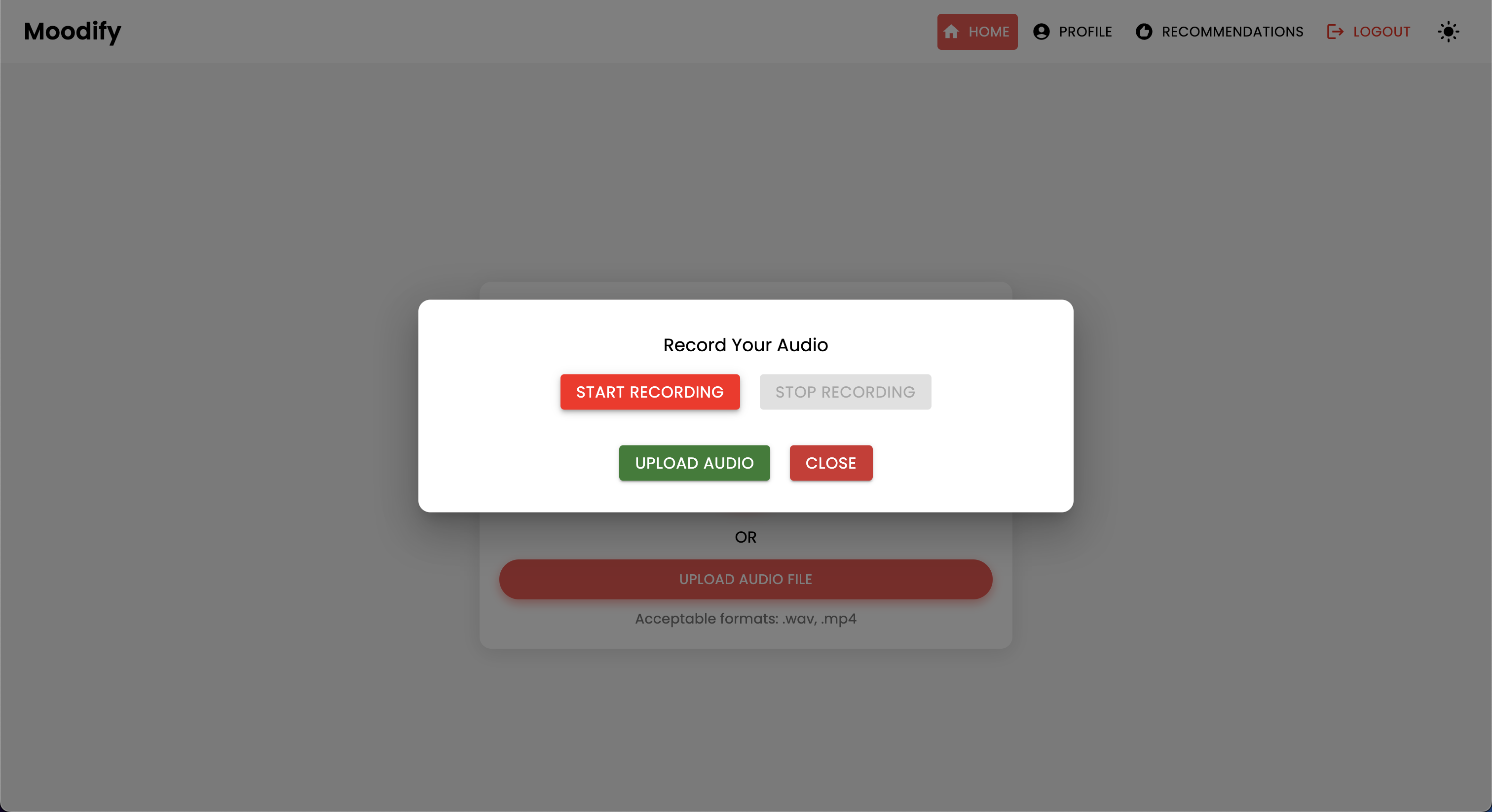
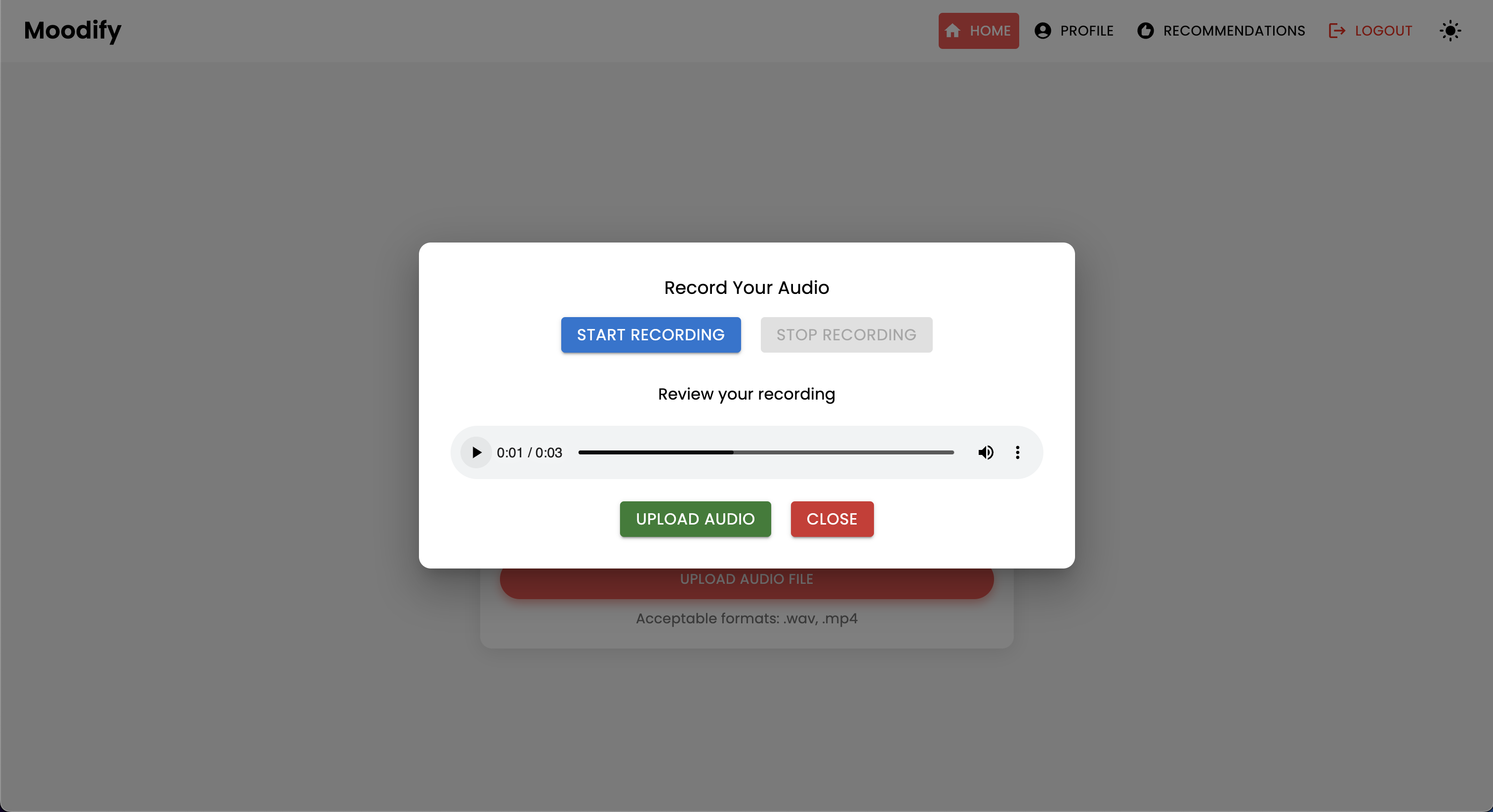
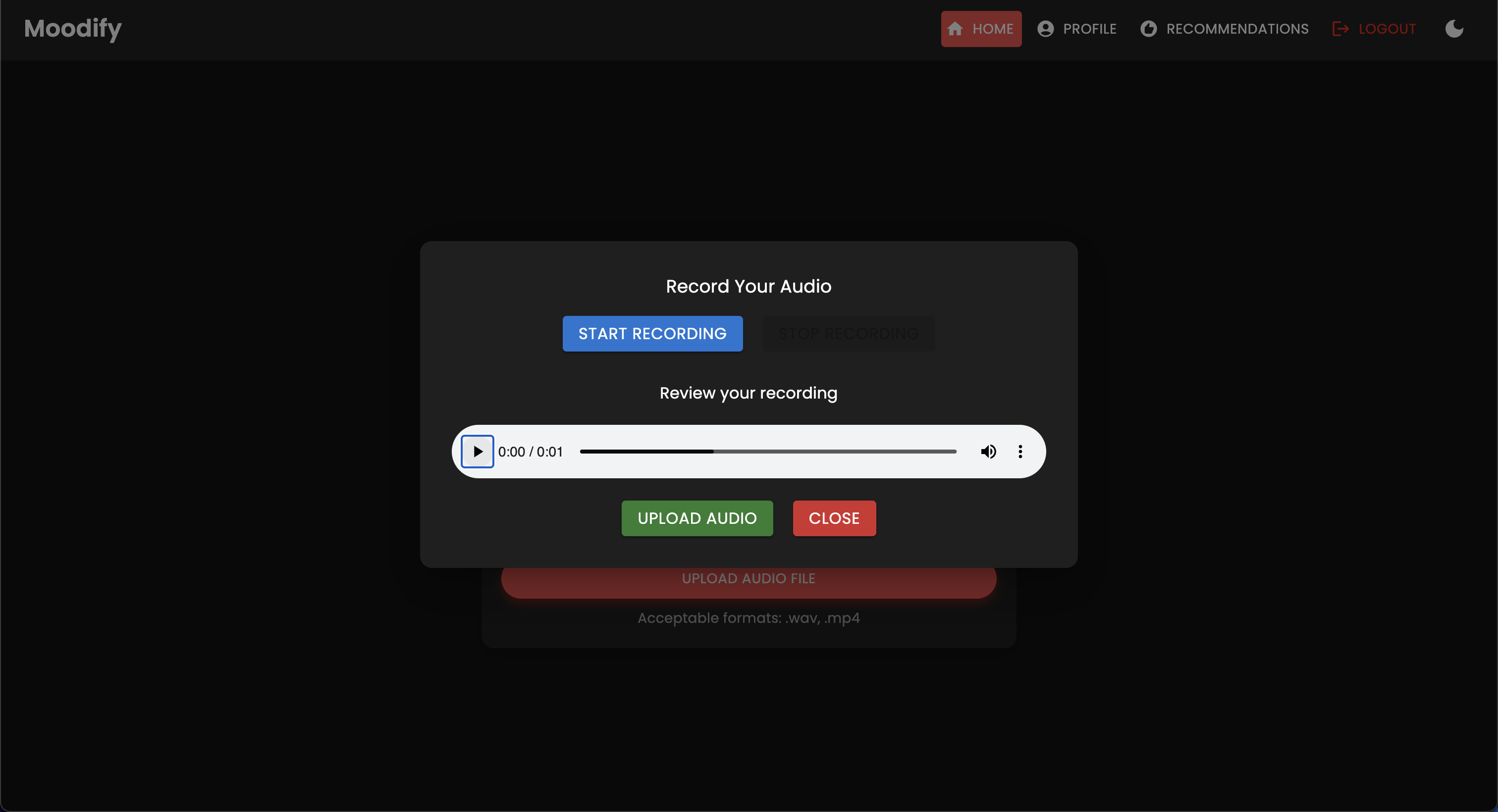
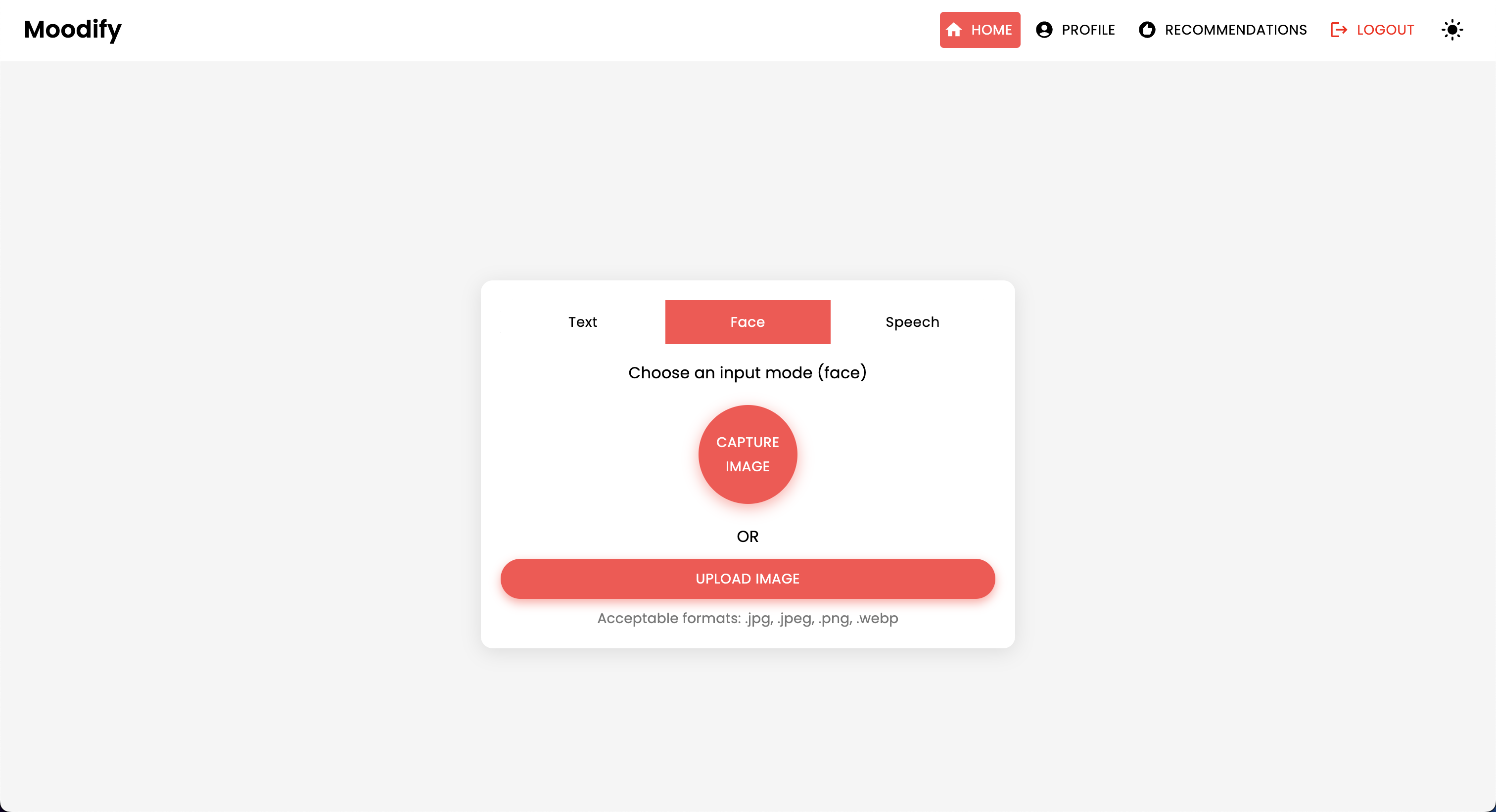
El proyecto Moodify es un sistema integrado de recomendación de música basado en la emoción que combina modelos frontend, backend, AI/ML y análisis de datos para proporcionar recomendaciones de música personalizadas basadas en las emociones de los usuarios. La aplicación analiza el texto, el habla o las expresiones faciales y sugiere música que se alinea con las emociones detectadas.
Al admitir plataformas de escritorio y móviles, Moodify ofrece una experiencia de usuario perfecta con la detección de emociones en tiempo real y las recomendaciones de música. El proyecto aprovecha el reaccionamiento de Frontend, Django para el backend y tres modelos AI/ML avanzados y autónomos para la detección de emociones . Los scripts de análisis de datos se utilizan para visualizar las tendencias de las emociones y el rendimiento del modelo.

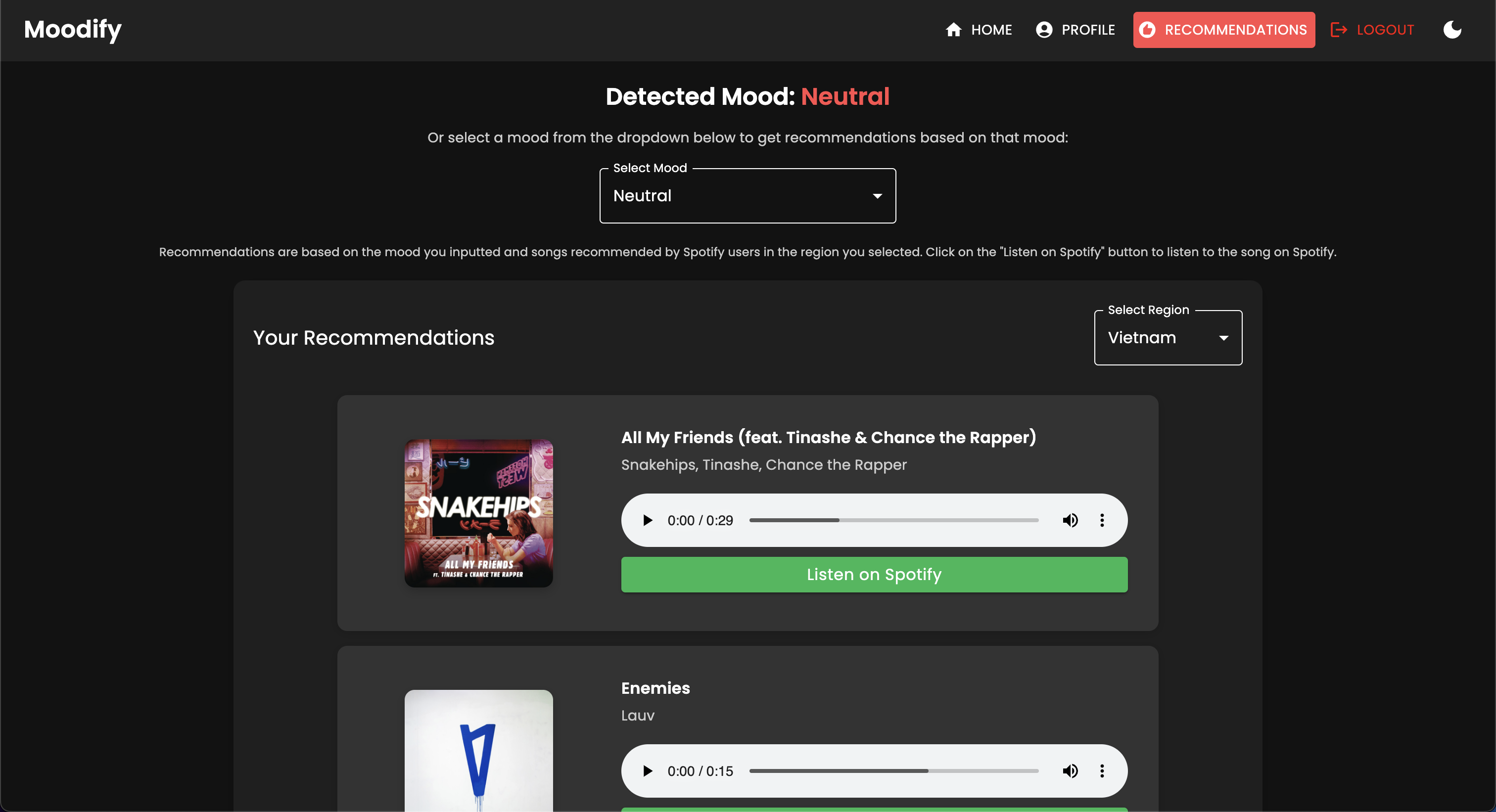
Moodify proporciona recomendaciones musicales personalizadas basadas en los estados emocionales de los usuarios detectados a través de textos, expresiones y expresiones faciales. Interactúa con un backend basado en Django, modelos AI/ML para la detección de emociones, y utiliza análisis de datos para ideas visuales sobre las tendencias emocionales y el rendimiento del modelo.
La aplicación Moodify está actualmente en vivo e implementada en VERCEL. Puede acceder a la aplicación en vivo usando el siguiente enlace: Moodify.
Siéntase libre de visitar el backend en Moodify Backend API.
DICACAMIENTO: El backend de Moodify está actualmente alojado con el nivel gratuito de Render, por lo que puede tardar unos segundos en cargarse inicialmente. Además, puede girar después de un período de inactividad o alto tráfico, por lo tanto, sea paciente si el backend tarda unos segundos en responder.
Además, la cantidad de memoria asignada por Render es solo 512 MB con 0.1 CPU , por lo que el backend puede quedarse sin memoria si hay demasiadas solicitudes a la vez, lo que puede hacer que el servidor se reinicie. Además, los modelos de detección de emociones faciales y del habla también pueden fallar debido a las limitaciones de memoria, lo que también puede hacer que el servidor se reinicie.
No hay garantía de tiempo de actividad o rendimiento con la implementación actual, a menos que tenga más recursos (dinero) para actualizar el servidor :( No dude en contactarme si se encuentra con algún problema o necesita más ayuda.

El proyecto tiene una estructura de archivos integral que combina componentes frontend, backend, AI/ML y análisis de análisis de datos:
Moodify-Emotion-Music-App/
├── frontend/ # React frontend for the web application
│ ├── public/
│ │ ├── index.html # Main HTML file
│ │ ├── manifest.json # Web app manifest
│ │ └── favicon.ico # Favicon for the app
│ │
│ ├── src/
│ │ ├── components/ # Contains all React components
│ │ ├── pages/ # Contains main pages of the app
│ │ ├── styles/ # Contains global styles and themes
│ │ ├── context/ # Contains React Context API
│ │ ├── App.js # Main App component
│ │ ├── index.js # Entry point for React
│ │ └── theme.js # Material UI theme configuration
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ ├── package.json # NPM dependencies and scripts
│ └── README.md # Project documentation
│
├── backend/ # Django backend for API services and database management
│ ├── manage.py # Django's command-line utility
│ ├── requirements.txt # Backend dependencies
│ ├── backend/
│ │ ├── settings.py # Django settings for the project
│ │ ├── urls.py # URL declarations for the project
│ │ ├── users/ # User management components
│ │ └── api/ # Emotion detection and recommendation APIs
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ └── db.sqlite3 # SQLite database (if used)
│
├── ai_ml/ # AI/ML models for emotion detection
│ ├── data/ # Datasets for training and testing
│ ├── models/ # Trained models for emotion detection
│ ├── src/ # Source files for emotion detection and recommendation
│ │ ├── api/ # API scripts for running emotion detection services
│ │ ├── recommendation/ # Music recommendation logic
│ │ └── data_processing/ # Data preprocessing scripts
│ │
│ ├── Dockerfile # Dockerfile for containerization
│ └── README.md # AI/ML documentation
│
├── data_analytics/ # Data analytics scripts and visualizations
│ ├── emotion_distribution.py # Script for visualizing emotion distribution
│ ├── training_visualization.py # Script for visualizing training and validation metrics
│ ├── predictions_analysis.py # Script for analyzing model predictions
│ ├── recommendation_analysis.py # Script for visualizing music recommendations
│ ├── spark-hadoop/ # Spark and Hadoop integration scripts
│ └── visualizations/ # Generated visualizations
│
├── kubernetes/ # Kubernetes deployment files
│ ├── backend-deployment.yaml # Deployment file for the backend service
│ ├── backend-service.yaml # Deployment file for the backend service
│ ├── frontend-deployment.yaml # Deployment file for the frontend service
│ ├── frontend-service.yaml # Deployment file for the frontend service
│ └── configmap.yaml # ConfigMap for environment variables
│
├── mobile/ # React Native mobile application
│ ├── App.js # Main entry point for React Native app
│ ├── index.js # App registry for React Native
│ ├── package.json # NPM dependencies and scripts
│ ├── components/ # React Native components
│ │ ├── Footer.js # Footer component
│ │ ├── Navbar.js # Header component
│ │ ├── Auth/ # Authentication components (e.g., Login, Register)
│ │ └── Profile/ # Profile-related components
│ │
│ ├── context/ # React Context API for state management
│ │ └── DarkModeContext.js # Dark mode context provider
│ │
│ ├── pages/ # Main pages of the app
│ │ ├── HomePage.js # Home page component
│ │ ├── ProfilePage.js # Profile page component
│ │ ├── ResultsPage.js # Results page component
│ │ ├── LandingPage.js # Landing page component
│ │ └── (and more...)
│ │
│ ├── assets/ # Images, fonts, and other assets
│ ├── styles/ # Styling files (similar to CSS for web)
│ ├── .gitignore # Git ignore file
│ ├── package.json # Dependencies and scripts
│ └── README.md # Mobile app documentation
│
├── nginx/ # NGINX configuration files (for load balancing and reverse proxy)
│ ├── nginx.conf # Main NGINX configuration file
│ └── Dockerfile # Dockerfile for NGINX container
│
├── images/ # Images used in the README documentation
├── docker-compose.yml # Docker Compose file for containerization
└── README.md # Comprehensive README file for the entire project
venv ).env archivo (para variables de entorno: crea sus propias credenciales siguiendo el archivo de ejemplo o contácteme para el mío).Comience con la configuración y la capacitación de los modelos AI/ML, ya que serán necesarios para que el backend funcione correctamente.
O bien, puede descargar los modelos previamente capacitados de los enlaces de Google Drive proporcionados en la sección de modelos previamente capacitados. Si elige hacerlo, puede omitir esta sección por ahora.
Clon el repositorio:
git clone https://github.com/hoangsonww/Moodify-Emotion-Music-App.gitNavegue al directorio AI/ML:
cd Moodify-Emotion-Music-App/ai_mlCrear y activar un entorno virtual:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsInstalar dependencias:
pip install -r requirements.txt Edite las configuraciones en el archivo src/config.py :
src/config.py y actualice las configuraciones según sea necesario, especialmente sus claves API de Spotify y configure todas las rutas.src/models y actualice las rutas a los conjuntos de datos y las rutas de salida según sea necesario.Entrena el modelo de emoción de texto:
python src/models/train_text_emotion.pyRepita comandos similares para otros modelos según sea necesario (por ejemplo, modelos de emoción facial y de voz).
¡Asegúrese de que todos los modelos capacitados se coloquen en el directorio models , y que haya capacitado todos los modelos necesarios antes de pasar al siguiente paso!
Pruebe los modelos AI/ML entrenados según sea necesario :
src/models/test_emotion_models.py para probar los modelos entrenados.Una vez que los modelos AI/ML estén listos, continúe con la configuración del backend.
Navegue al directorio de backend:
cd ../backendCrear y activar un entorno virtual:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsInstalar dependencias:
pip install -r requirements.txtConfigure sus secretos y entorno:
.env en el directorio backend ..env : SECRET_KEY=your_secret_key
DEBUG=True
ALLOWED_HOSTS=<your_hosts>
MONGODB_URI=<your_mongodb_uri>
backend/settings.py y agregue SECRET_KEY y establezca DEBUG en True .Ejecutar migraciones de bases de datos:
python manage.py migrateInicie el servidor Django:
python manage.py runserver El servidor de backend se ejecutará en http://127.0.0.1:8000/ .
Finalmente, configure el frontend para interactuar con el backend.
Navegue al directorio frontend:
cd ../frontendInstalar dependencias con hilo:
npm installInicie el servidor de desarrollo:
npm start El frontend comenzará en http://localhost:3000 .
Nota: Si encuentra algún problema o necesita mi archivo .env , no dude en ponerse en contacto conmigo.
| Método HTTP | Punto final | Descripción |
|---|---|---|
POST | /users/register/ | Registre a un nuevo usuario |
POST | /users/login/ | Iniciar sesión en un usuario y obtener un token JWT |
GET | /users/user/profile/ | Recuperar el perfil del usuario autenticado |
PUT | /users/user/profile/update/ | Actualizar el perfil del usuario autenticado |
DELETE | /users/user/profile/delete/ | Eliminar el perfil del usuario autenticado |
POST | /users/recommendations/ | Guardar recomendaciones para un usuario |
GET | /users/recommendations/<str:username>/ | Recuperar recomendaciones para un usuario por nombre de usuario |
DELETE | /users/recommendations/<str:username>/<str:recommendation_id>/ | Eliminar una recomendación específica para un usuario |
DELETE | /users/recommendations/<str:username>/ | Eliminar todas las recomendaciones para un usuario |
POST | /users/mood_history/<str:user_id>/ | Agregue un estado de ánimo al historial del estado de ánimo del usuario |
GET | /users/mood_history/<str:user_id>/ | Recuperar el historial del estado de ánimo para un usuario |
DELETE | /users/mood_history/<str:user_id>/ | Eliminar un estado de ánimo específico del historial del usuario |
POST | /users/listening_history/<str:user_id>/ | Agregue una pista al historial de escucha del usuario |
GET | /users/listening_history/<str:user_id>/ | Recuperar el historial de audición para un usuario |
DELETE | /users/listening_history/<str:user_id>/ | Eliminar una pista específica del historial del usuario |
POST | /users/user_recommendations/<str:user_id>/ | Guardar las recomendaciones de un usuario |
GET | /users/user_recommendations/<str:user_id>/ | Recuperar las recomendaciones de un usuario |
DELETE | /users/user_recommendations/<str:user_id>/ | Eliminar todas las recomendaciones para un usuario |
POST | /users/verify-username-email/ | Verifique si un nombre de usuario y un correo electrónico son válidos |
POST | /users/reset-password/ | Restablecer la contraseña de un usuario |
GET | /users/verify-token/ | Verifique el token de un usuario |
| Método HTTP | Punto final | Descripción |
|---|---|---|
POST | /api/text_emotion/ | Analizar el texto para contenido emocional |
POST | /api/speech_emotion/ | Analizar el habla para el contenido emocional |
POST | /api/facial_emotion/ | Analizar expresiones faciales para las emociones |
POST | /api/music_recommendation/ | Obtener recomendaciones musicales basadas en la emoción |
| Método HTTP | Punto final | Descripción |
|---|---|---|
GET | /admin/ | Acceda a la interfaz de administración de Django |
| Método HTTP | Punto final | Descripción |
|---|---|---|
GET | /swagger/ | Acceda a la documentación de la API de UI Swagger |
GET | /redoc/ | Acceda a la documentación de la API redoc |
GET | / | Acceda al punto final de la raíz API (UI de Swagger) |
Crea un superusador:
python manage.py createsuperuser Acceda al panel de administración en http://127.0.0.1:8000/admin/
Debería ver la siguiente página de inicio de sesión:
Nuestras API de backend están bien documentadas utilizando UI y redoc Swagger. Puede acceder a la documentación de API en las siguientes URL:
https://moodify-emotion-music-app.onrender.com/swagger .https://moodify-emotion-music-app.onrender.com/redoc .Alternativamente, puede ejecutar el servidor de backend localmente y acceder a la documentación de la API en los siguientes puntos finales:
http://127.0.0.1:8000/swagger .http://127.0.0.1:8000/redoc .Independientemente de su elección, debe ver la siguiente documentación de API si todo se ejecuta correctamente:
Swagger UI:
Redoc:
Los modelos AI/ML están construidos con transformadores Pytorch, TensorFlow, Keras y Huggingface. Estos modelos están entrenados en varios conjuntos de datos para detectar emociones de texto, expresión y expresiones faciales.
Los modelos de detección de emociones se utilizan para analizar las entradas de los usuarios y proporcionar recomendaciones de música en tiempo real basadas en las emociones detectadas. Los modelos están entrenados en varios conjuntos de datos para capturar los matices de las emociones humanas y proporcionar predicciones precisas.
Los modelos están integrados en los servicios de Backend API para proporcionar detección de emociones en tiempo real y recomendaciones de música para los usuarios.
Los modelos deben ser entrenados primero antes de usarlos en los servicios de backend. Asegúrese de que los modelos estén entrenados y colocados en el directorio models antes de ejecutar el servidor de backend. Consulte la sección (comenzando) [#Geting-starded] para obtener más detalles.
 Ejemplos de capacitación del modelo de emoción de texto.
Ejemplos de capacitación del modelo de emoción de texto.
Para entrenar los modelos, puede ejecutar los scripts proporcionados en el directorio ai_ml/src/models . Estos scripts se utilizan para preprocesar los datos, entrenar los modelos y guardar los modelos capacitados para su uso posterior. Estos scripts incluyen:
train_text_emotion.py : entrena el modelo de detección de emociones de texto.train_speech_emotion.py : entrena el modelo de detección de emociones del habla.train_facial_emotion.py : entrena el modelo de detección de emociones faciales. Asegúrese de tener las dependencias necesarias, conjuntos de datos y configuraciones configuradas antes de capacitar a los modelos. Específicamente, asegúrese de visitar el archivo config.py y actualizar las rutas a los conjuntos de datos y los directorios de salida a los correctos en su sistema.
Nota: Por defecto, estos scripts priorizarán el uso de su GPU con CUDA (si está disponible) para una capacitación más rápida. Sin embargo, si eso no está disponible en su máquina, los scripts recurrirán automáticamente al uso de la CPU para capacitación. Para asegurarse de tener las dependencias necesarias para la capacitación de GPU, instale Pytorch con soporte CUDA usando el siguiente comando:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 Después de eso, puede ejecutar el script test_emotion_models.py para probar los modelos capacitados y asegurarse de que estén proporcionando predicciones precisas:
python src/models/test_emotion_models.pyAlternativamente, puede ejecutar la API de frasco simple para probar los modelos a través de puntos finales de API RESTFUL:
python ai_ml/src/api/emotion_api.pyLos puntos finales son los siguientes:
/text_emotion : detecta la emoción de la entrada de texto/speech_emotion : detecta la emoción del audio del habla/facial_emotion : detecta la emoción de una imagen/music_recommendation : proporciona recomendaciones musicales basadas en la emoción detectada IMPORTANTE : Para obtener más información sobre la capacitación y el uso de los modelos, consulte la documentación AI/ML en el directorio ai_ml .
Sin embargo, si el entrenamiento, el modelo es demasiado intensivo para usted, puede usar los siguientes enlaces de Google Drive para descargar los modelos previamente capacitados:
model.safetensors . Descargue este archivo model.safetensors y colóquelo en el directorio ai_ml/models/text_emotion_model .scaler.pkl . Descargue esto y coloque esto en el directorio ai_ml/models/speech_emotion_model .trained_speech_emotion_model.pkl . Descargue esto y coloque esto en el directorio ai_ml/models/speech_emotion_model .trained_facial_emotion_model.pt . Descargue esto y coloque esto en el directorio ai_ml/models/facial_emotion_model . Estos han sido pre-entrenados en los conjuntos de datos para usted y están listos para usar en los servicios de backend o para fines de prueba una vez descargados y colocados correctamente en el directorio models .
No dude en contactarme si encuentra algún problema o necesita más ayuda con los modelos AI/ML.
La carpeta data_analytics proporciona scripts de análisis de datos y visualización para obtener información sobre el rendimiento del modelo de detección de emociones.
Ejecute todos los scripts de análisis:
python data_analytics/main.py Ver visualizaciones generadas en la carpeta de visualizations .
Aquí hay algunas visualizaciones de ejemplo:
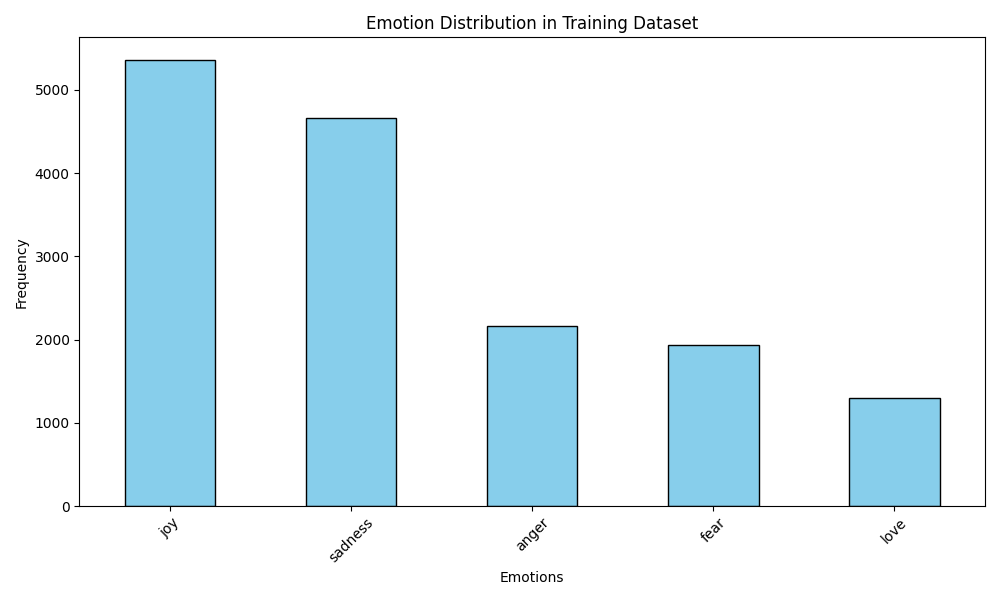 Visualización de distribución de emociones
Visualización de distribución de emociones
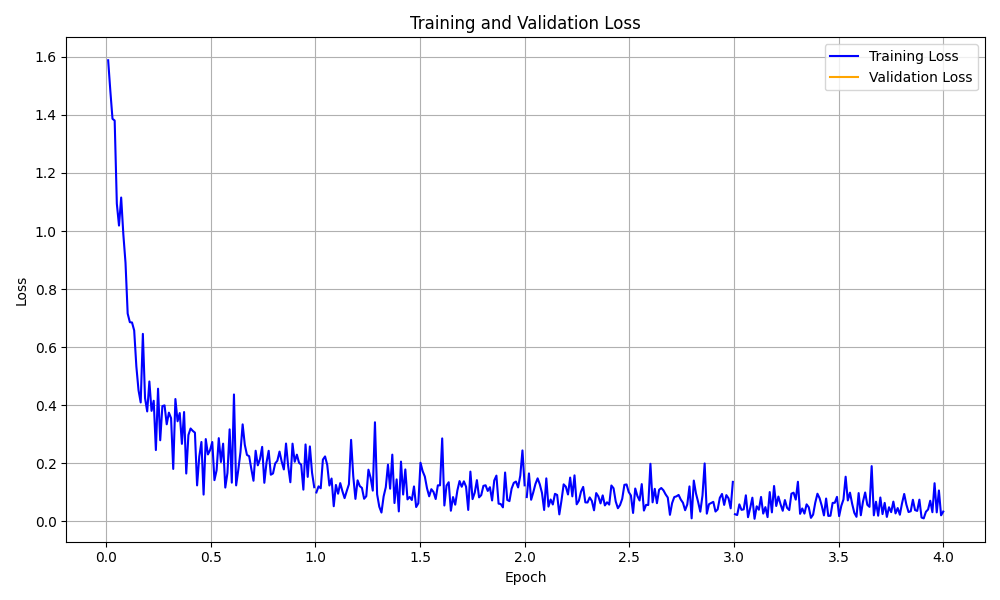 Visualización de la curva de pérdida de entrenamiento
Visualización de la curva de pérdida de entrenamiento
También hay una versión móvil de la aplicación Moodify creada con React Native y Expo. Puede encontrar la aplicación móvil en el directorio mobile .
Navegue al directorio móvil:
cd ../mobileInstalar dependencias con hilo:
yarn installInicie el servidor de desarrollo de Expo:
yarn startEscanee el código QR utilizando la aplicación Expo Go en su dispositivo móvil para ejecutar la aplicación.
Si tiene éxito, debería ver la siguiente pantalla de inicio:
¡Siéntase libre de explorar la aplicación móvil y probar sus funcionalidades!
El proyecto utiliza NGINX y Gunicorn para el equilibrio de carga y servir el backend de Django. Nginx actúa como un servidor proxy inverso, mientras que Gunicorn sirve a la aplicación Django.
Instalar nginx:
sudo apt-get update
sudo apt-get install nginxInstalar Gunicorn:
pip install gunicornConfigurar nginx:
/nginx/nginx.conf con su configuración.Inicie Nginx y Gunicorn:
sudo systemctl start nginxgunicorn backend.wsgi:application Acceda al backend en http://<server_ip>:8000/ .
No dude en personalizar la configuración de Nginx y la configuración de Gunicorn según sea necesario para su implementación.
El proyecto se puede contenedor utilizando Docker para una fácil implementación y escala. Puede crear imágenes Docker para los modelos Frontend, Backend y AI/ML.
Construye las imágenes de Docker:
docker compose up --buildLas imágenes de Docker se construirán para los modelos Frontend, Backend y AI/ML. Verifique las imágenes usando:
docker imagesSi encuentra algún error, intente reconstruir su imagen sin usar el caché ya que el caché de Docker puede causar problemas.
docker-compose build --no-cacheTambién agregamos archivos de implementación de Kubernetes para los servicios de backend y frontend. Puede implementar los servicios en un clúster Kubernetes utilizando los archivos YAML proporcionados.
Implementar el servicio de backend:
kubectl apply -f kubernetes/backend-deployment.yamlImplementar el servicio frontend:
kubectl apply -f kubernetes/frontend-deployment.yamlExponer los servicios:
kubectl expose deployment moodify-backend --type=LoadBalancer --port=8000
kubectl expose deployment moodify-frontend --type=LoadBalancer --port=3000Acceda a los servicios utilizando la IP de LoadBalancer:
http://<backend_loadbalancer_ip>:8000 .http://<frontend_loadbalancer_ip>:3000 . No dude en visitar el directorio kubernetes para obtener más información sobre los archivos y configuraciones de implementación.
También hemos incluido el script de tubería de Jenkins para automatizar el proceso de compilación e implementación. Puede usar Jenkins para automatizar el proceso CI/CD para la aplicación Moodify.
Instale Jenkins en su servidor o máquina local.
Crea un nuevo trabajo de tubería de Jenkins:
Jenkinsfile en el directorio jenkins .Ejecute la tubería de Jenkins:
Siéntase libre de explorar el script de tuberías de Jenkins en Jenkinsfile y personalizarlo según sea necesario para su proceso de implementación.
¡Las contribuciones son bienvenidas! Siéntase libre de bifurcar el repositorio y enviar una solicitud de extracción.
Tenga en cuenta que este proyecto aún está en desarrollo activo, y cualquier contribución es apreciada.
Si tiene alguna sugerencia, solicitudes de funciones o informes de errores, no dude en abrir un problema aquí.
¡Feliz codificación y vibra! ?
Creado con ❤️ por su hijo Nguyen en 2024.
? Volver arriba


