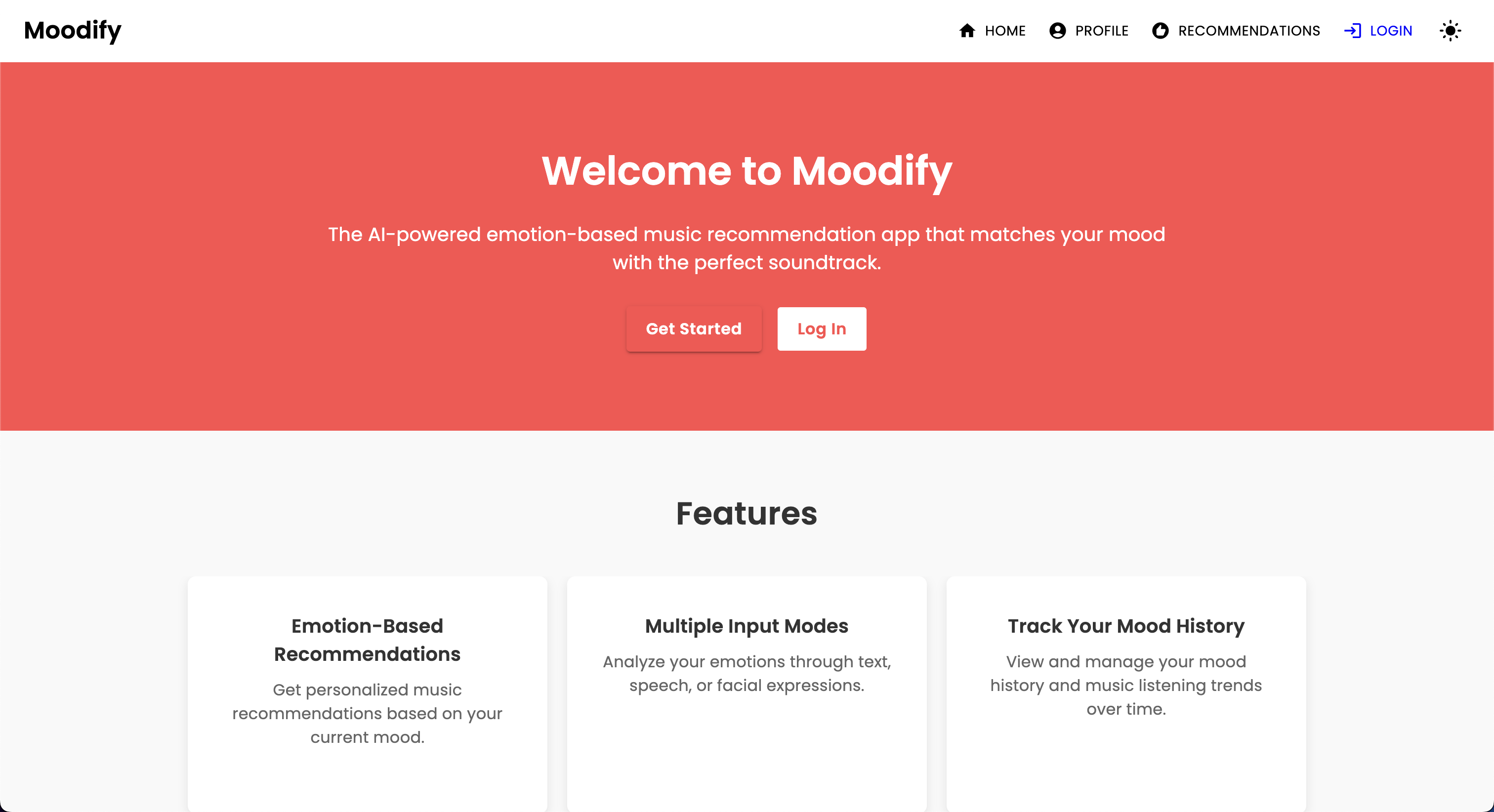
Moodify Emotion Music App
1.0.0
パーソナライズされた音楽ストリーミングサービスの台頭により、ユーザーの感情状態に基づいて音楽を推奨できるシステムに対する必要性が高まっています。このニーズを認識して、 Moodifyは2024年にSon Nguyenによって開発され、ユーザーの検出された感情に基づいてパーソナライズされた音楽の推奨事項を提供しています。
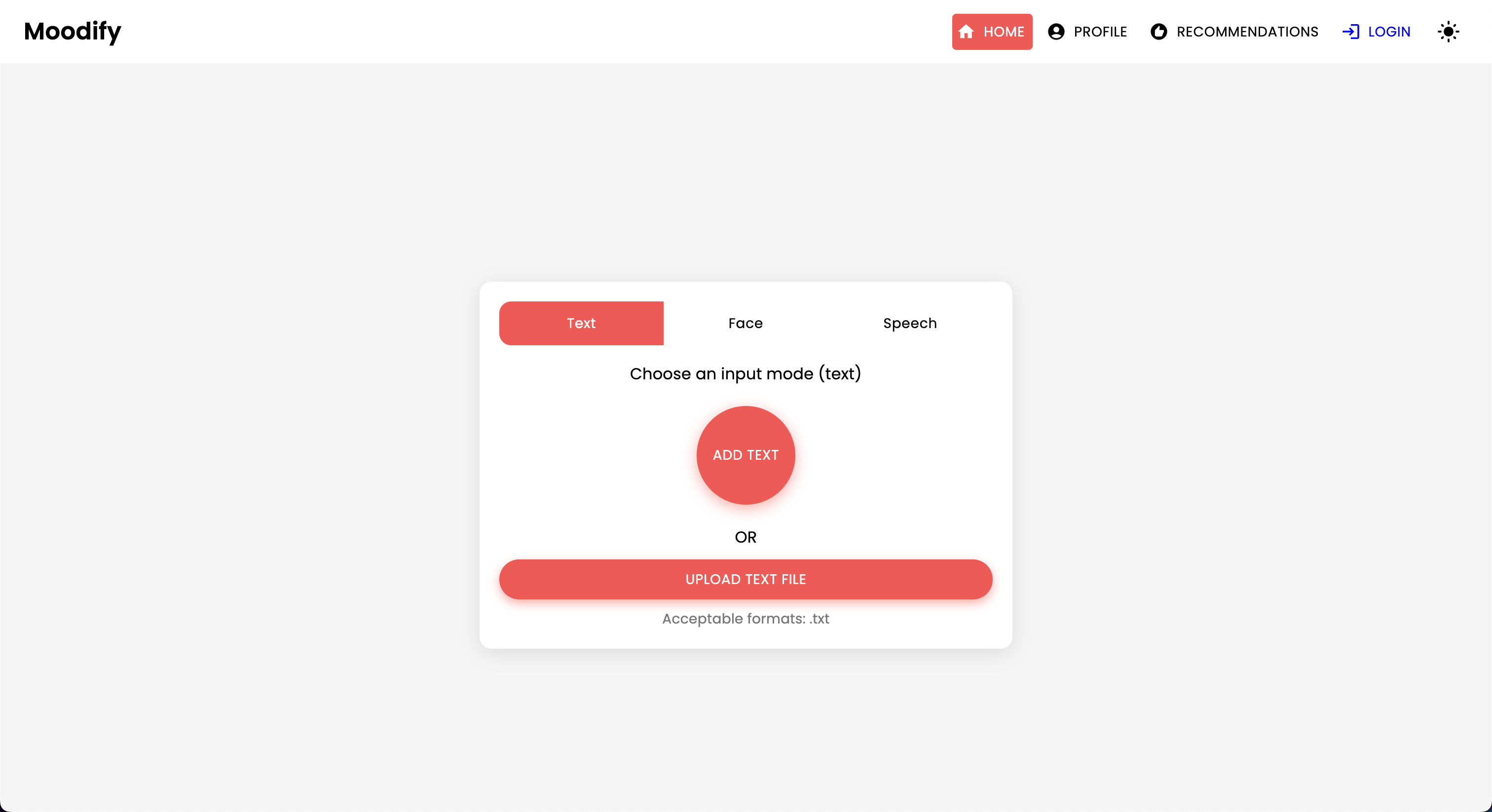
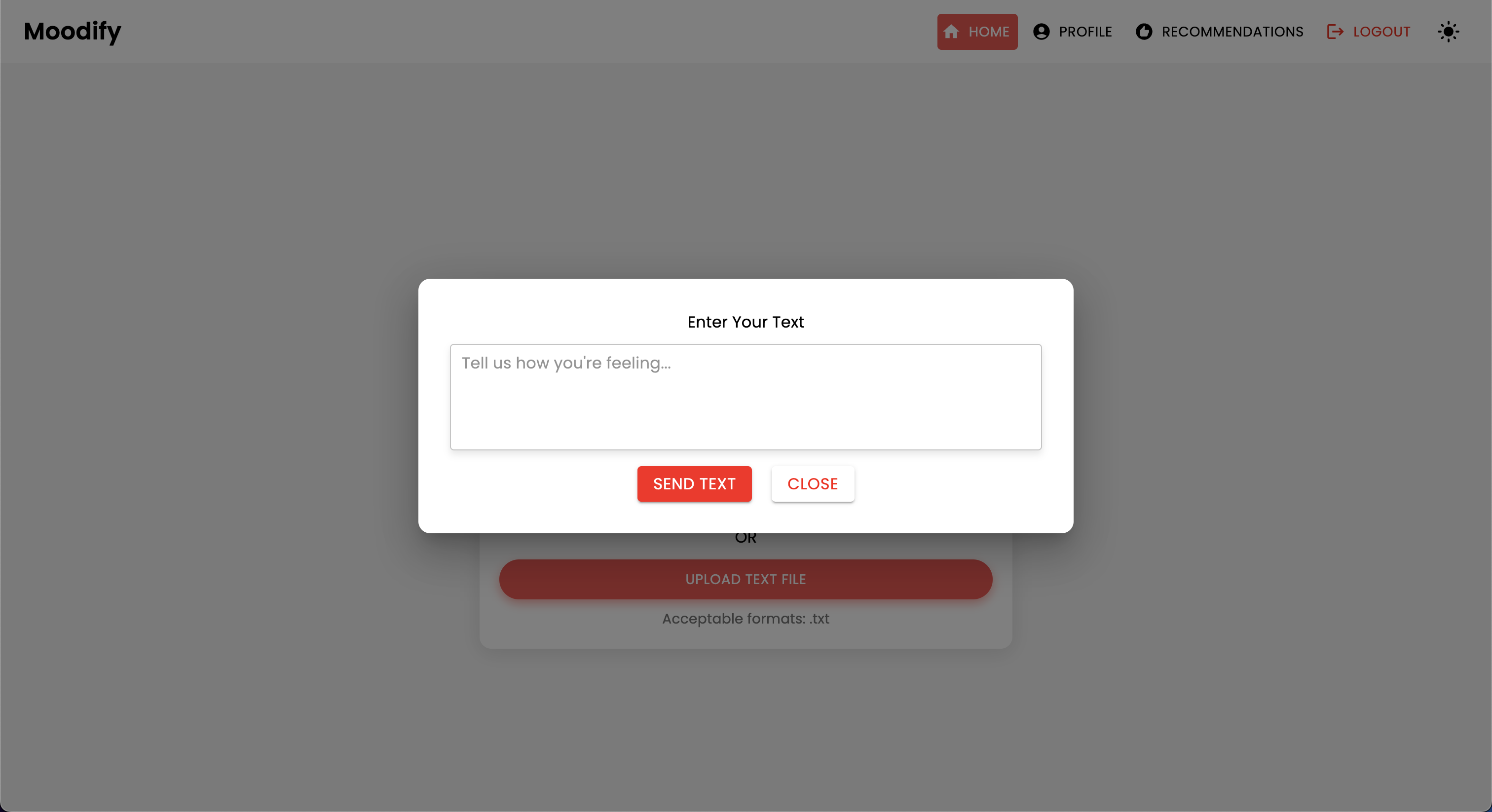
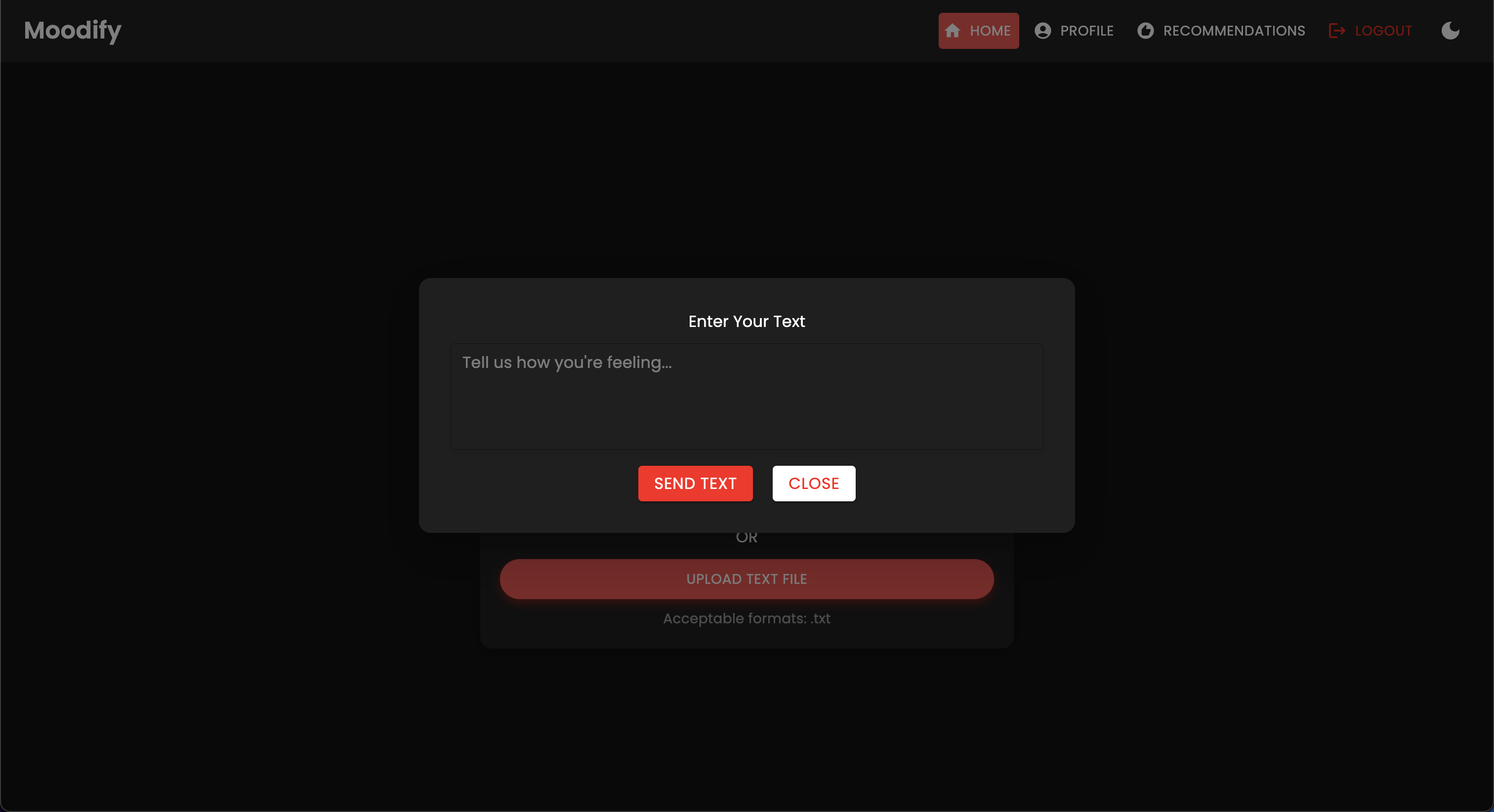
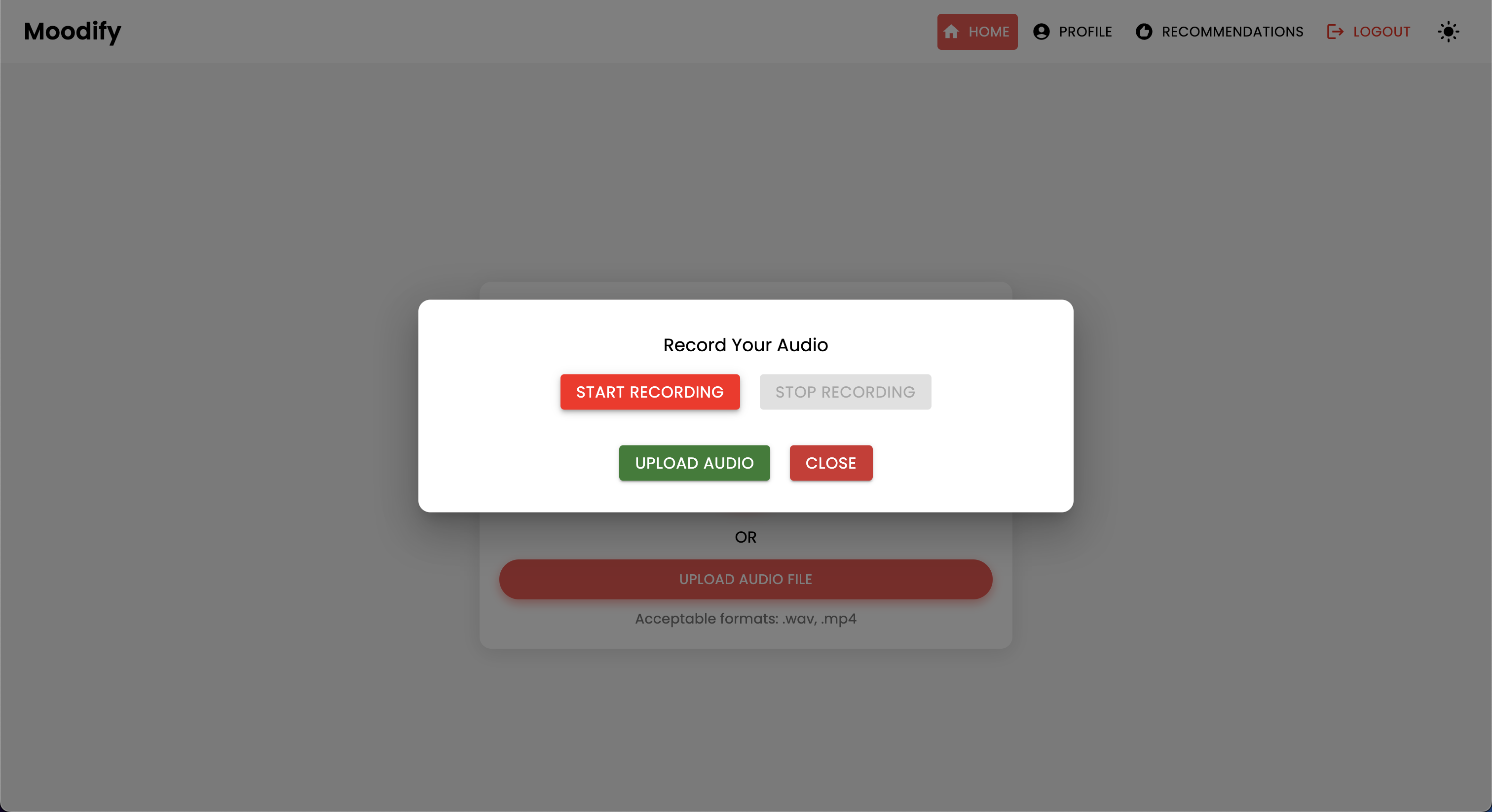
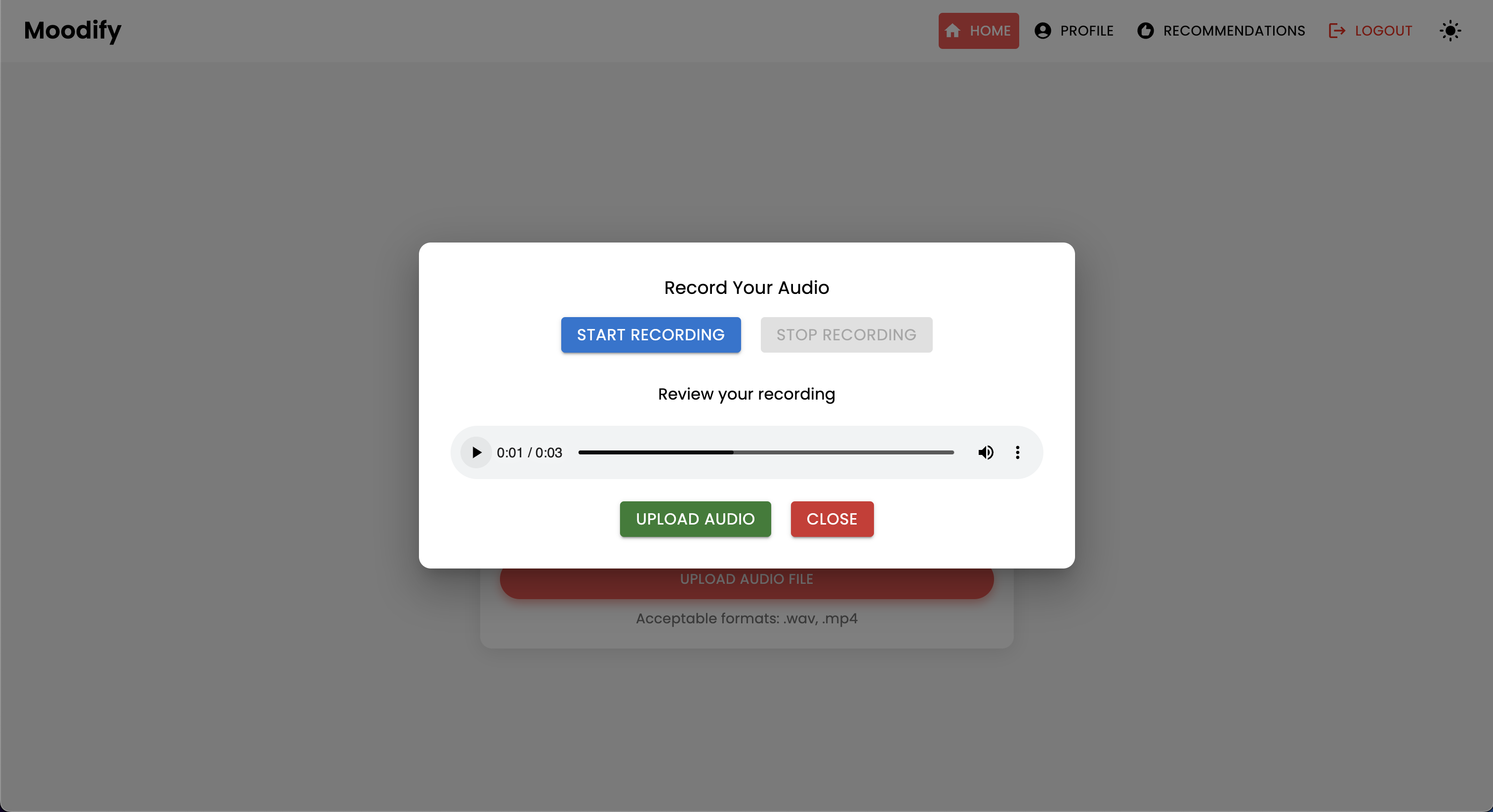
Moodifyプロジェクトは、フロントエンド、バックエンド、AI/MLモデル、およびデータ分析を組み合わせて、ユーザー感情に基づいたパーソナライズされた音楽の推奨事項を提供する統合された感情ベースの音楽推奨システムです。アプリケーションは、テキスト、スピーチ、または表情を分析し、検出された感情と一致する音楽を提案します。
デスクトッププラットフォームとモバイルプラットフォームの両方をサポートするMoodifyは、リアルタイムの感情検出と音楽の推奨事項を備えたシームレスなユーザーエクスペリエンスを提供します。プロジェクトのレバレッジは、フロントエンドに反応し、バックエンドのDjango、および感情検出のための3つの高度で自己訓練されたAI/MLモデルに反応します。データ分析スクリプトは、感情の傾向とモデルのパフォーマンスを視覚化するために使用されます。

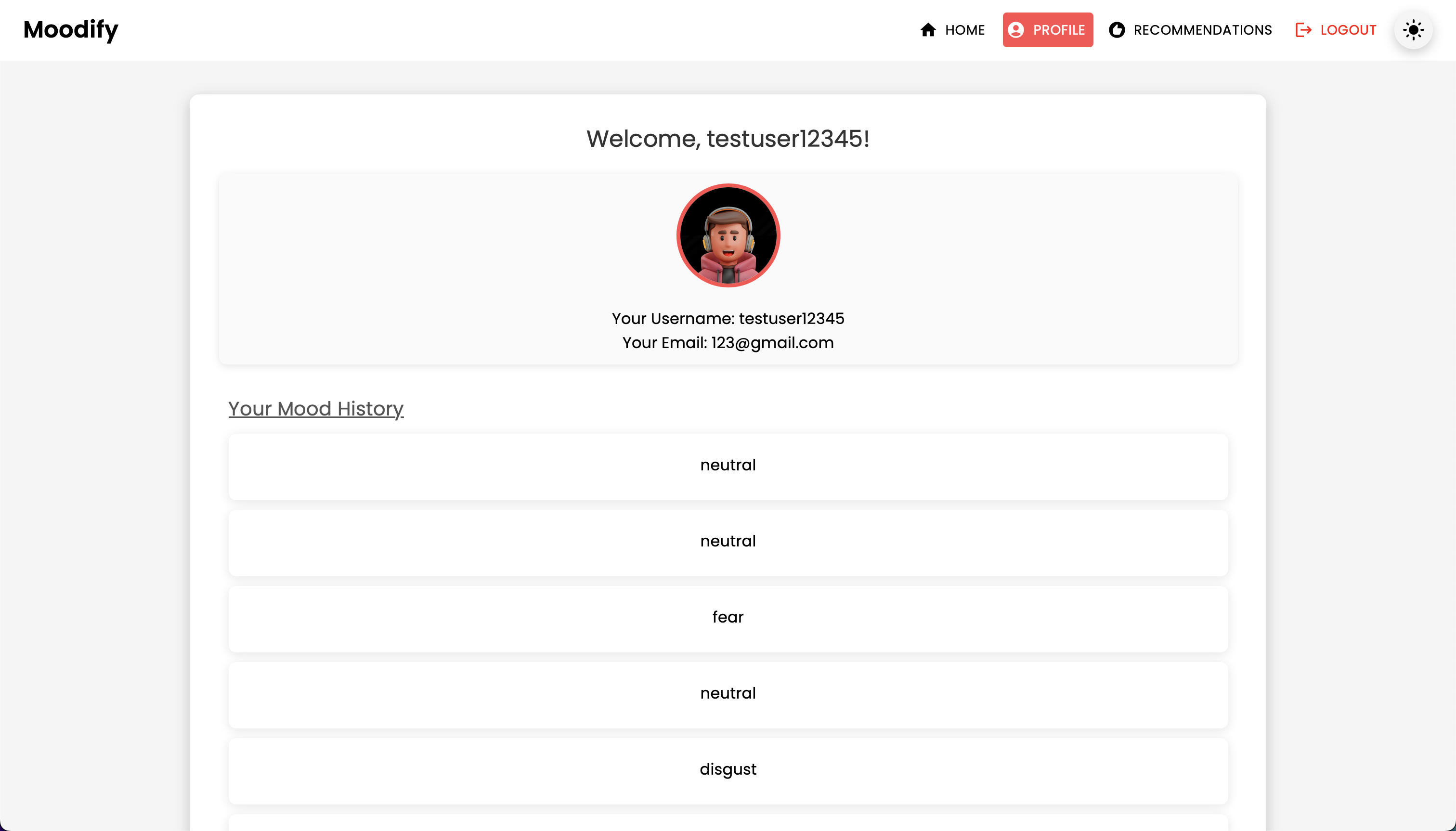
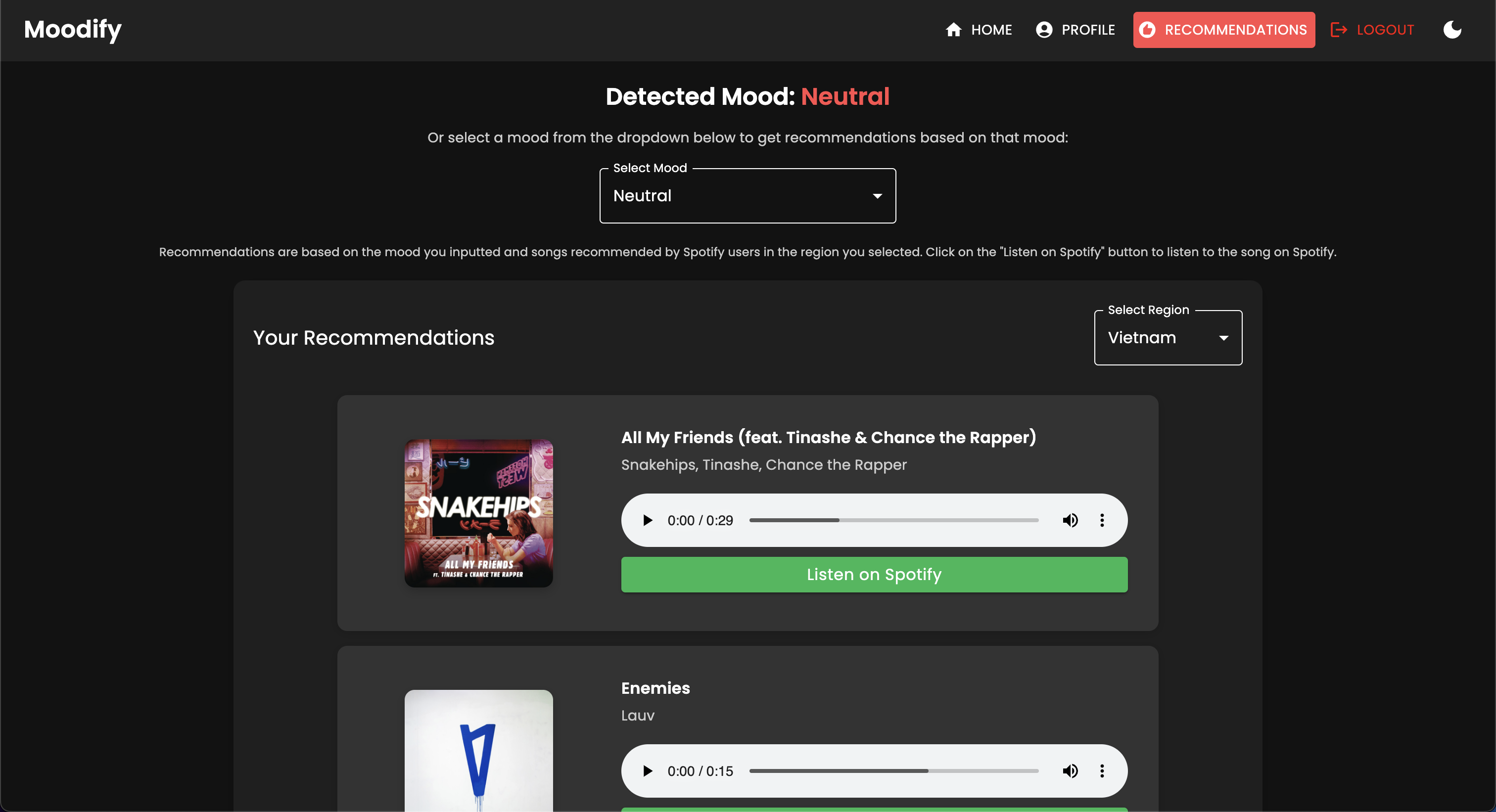
Moodifyは、テキスト、スピーチ、表情で検出されたユーザーの感情状態に基づいたパーソナライズされた音楽の推奨事項を提供します。 Djangoベースのバックエンド、感情検出のためのAI/MLモデルと相互作用し、感情の傾向とモデルのパフォーマンスに関する視覚的な洞察のためにデータ分析を利用します。
Moodifyアプリは現在ライブであり、Vercelに展開されています。次のリンクを使用して、ライブアプリにアクセスできます。Moodify。
Moodify BackEnd APIのバックエンドにもアクセスしてください。
Diclaimer: Moodifyのバックエンドは現在、レンダリングの無料ティアでホストされているため、最初にロードするには数秒かかる場合があります。さらに、非アクティブな期間や交通量の多い後にスピンダウンする可能性があるため、バックエンドが応答するのに数秒かかる場合は我慢してください。
また、レンダリングによって割り当てられるメモリの量は、 0.1 CPUで512MBのみであるため、一度にリクエストが多すぎるとバックエンドがメモリがなくなる可能性があり、サーバーが再起動する可能性があります。また、メモリの制約により、顔面および音声感情検出モデルも失敗する可能性があります。これにより、サーバーが再起動する可能性もあります。
サーバーをアップグレードするためのより多くのリソース(お金)がない限り、現在の展開での稼働時間やパフォーマンスの保証はありません。
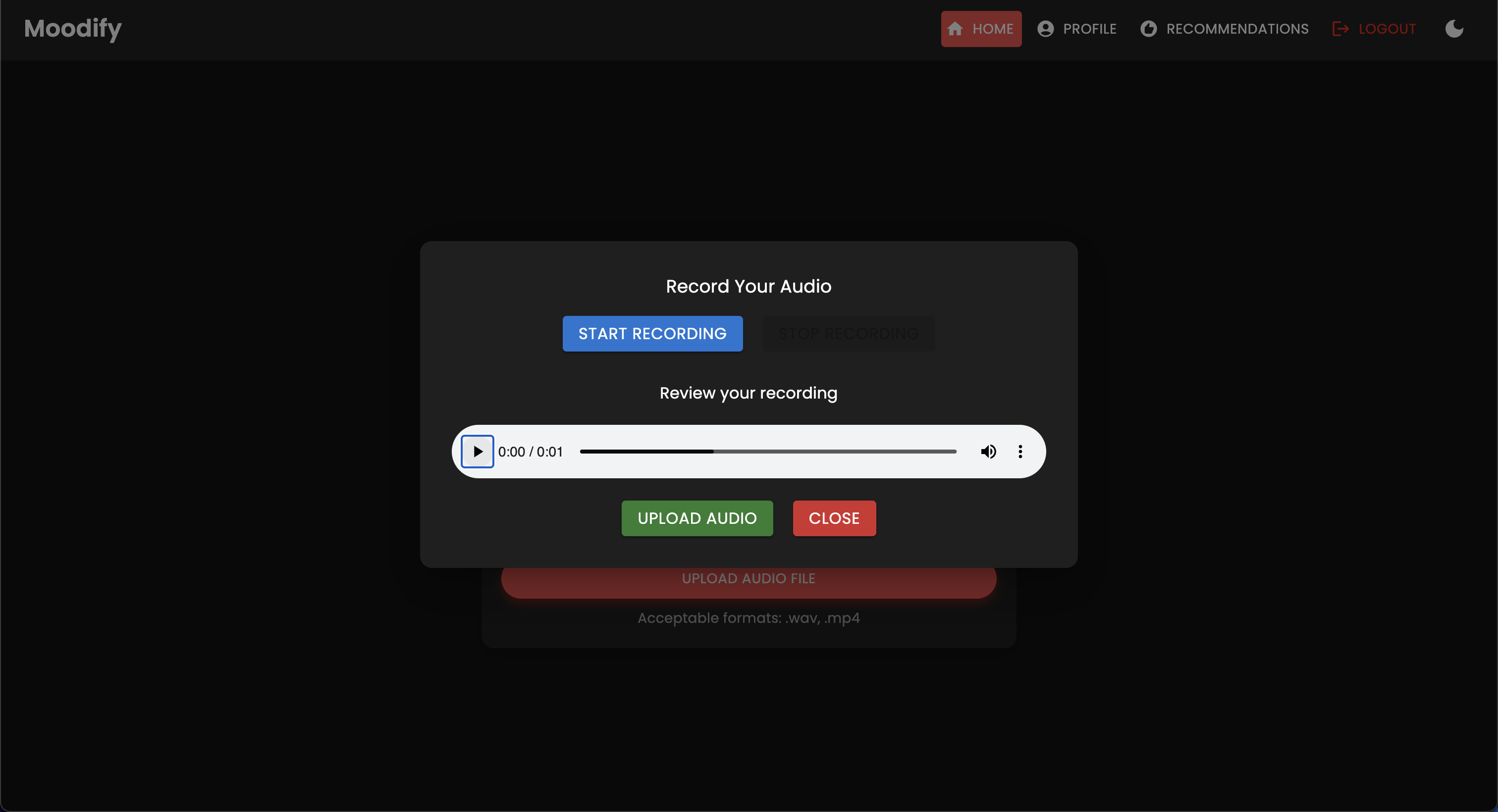
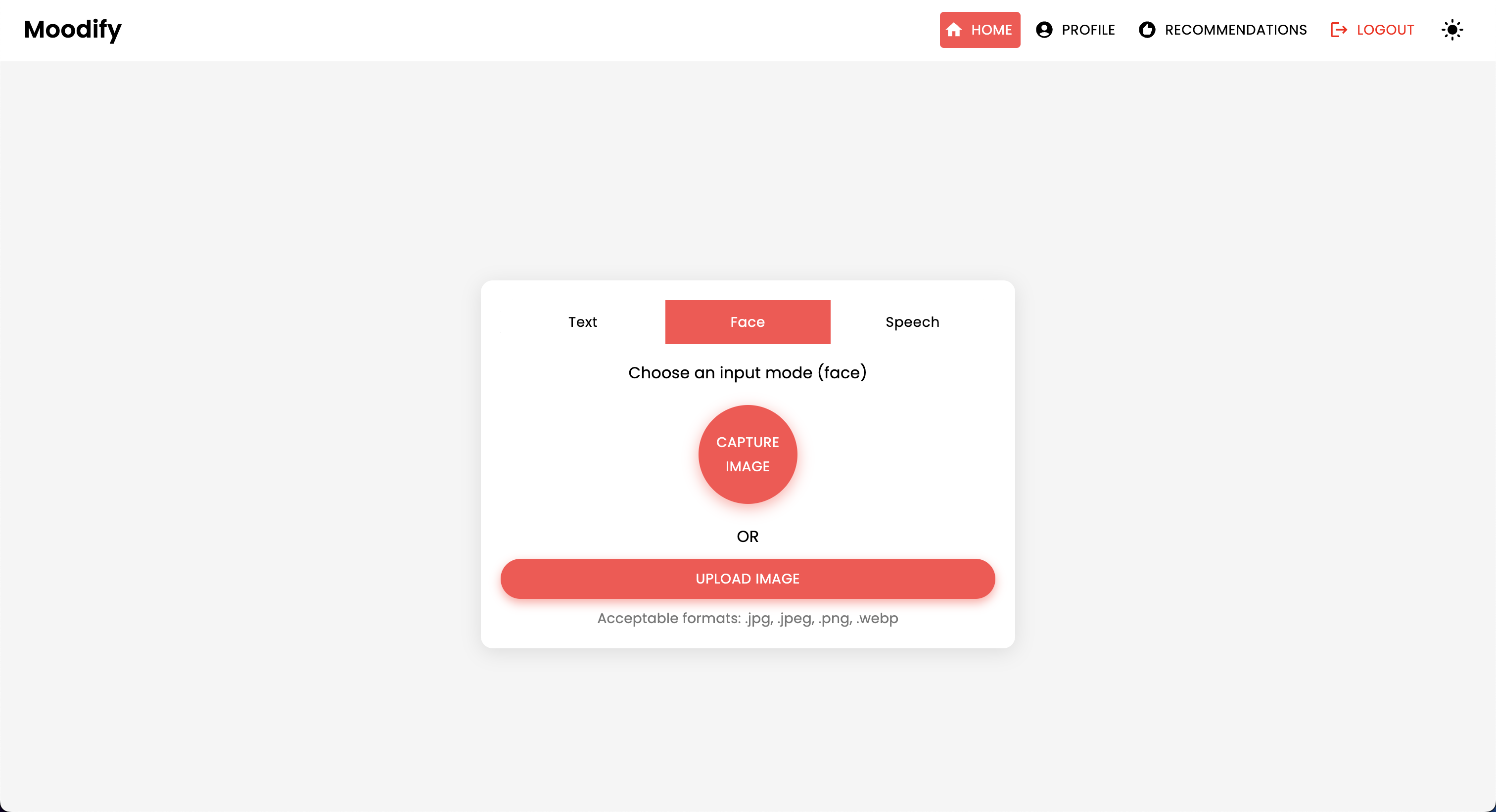
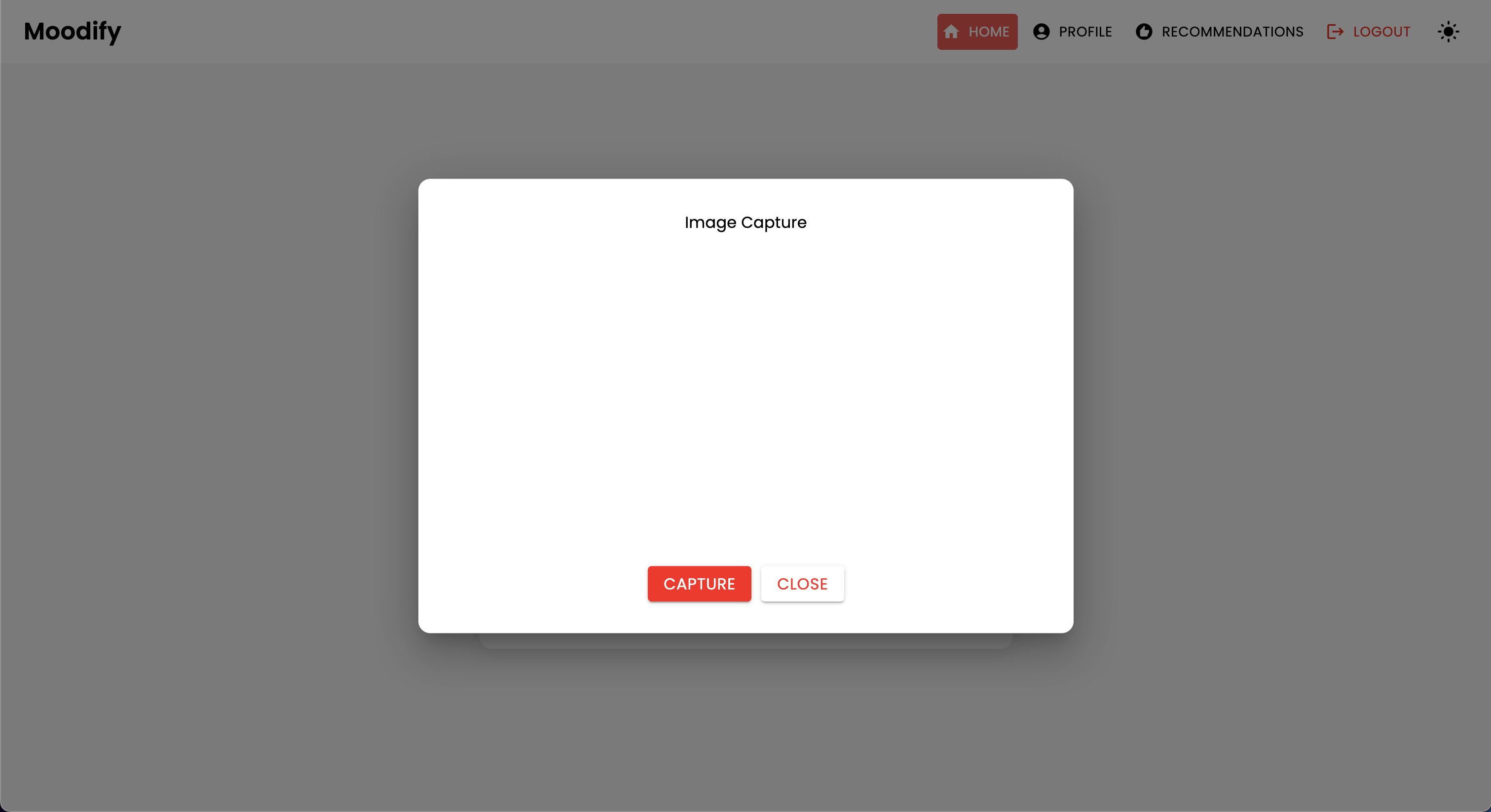
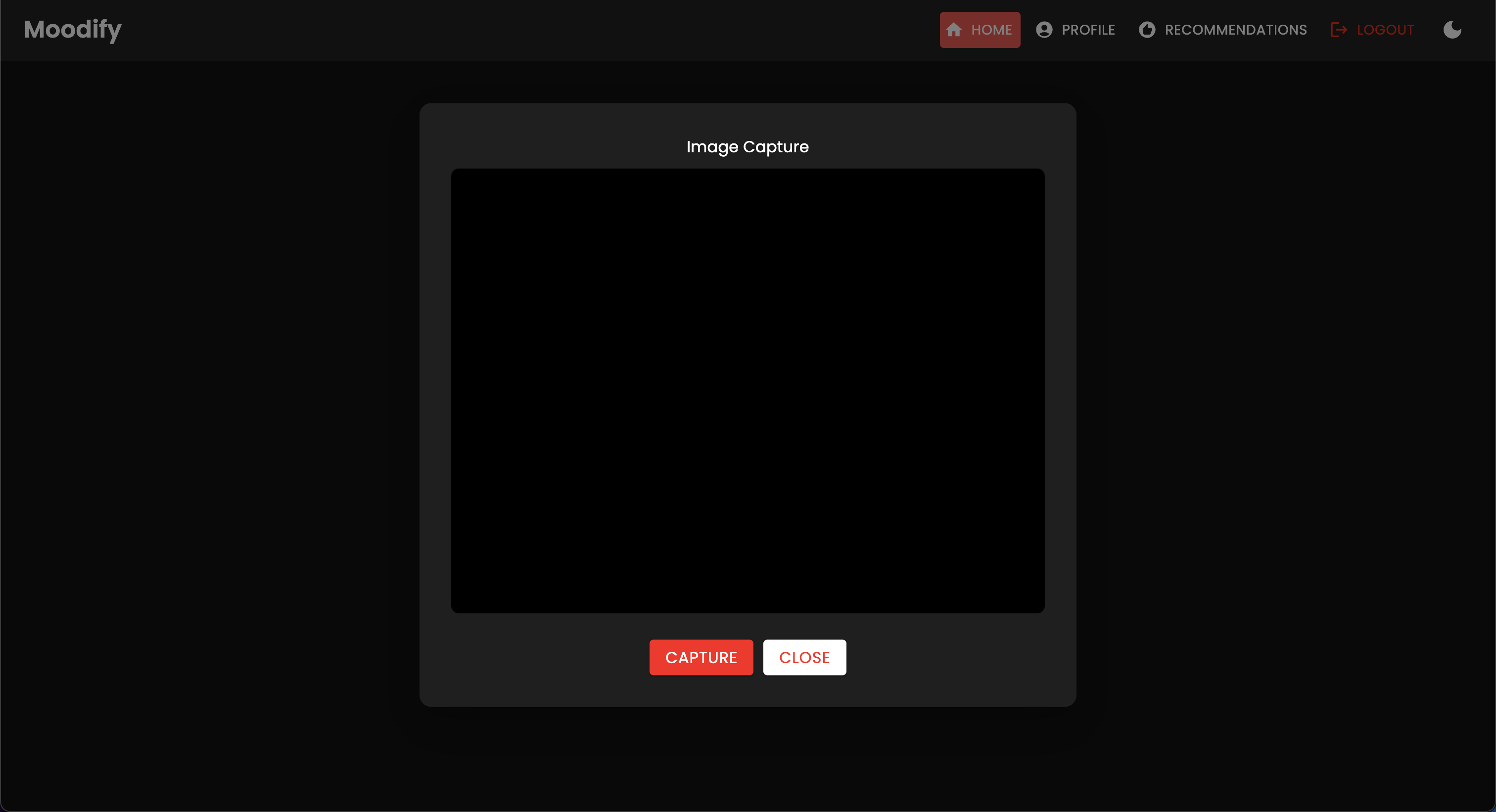

このプロジェクトには、フロントエンド、バックエンド、AI/MLモデル、およびデータ分析コンポーネントを組み合わせた包括的なファイル構造があります。
Moodify-Emotion-Music-App/
├── frontend/ # React frontend for the web application
│ ├── public/
│ │ ├── index.html # Main HTML file
│ │ ├── manifest.json # Web app manifest
│ │ └── favicon.ico # Favicon for the app
│ │
│ ├── src/
│ │ ├── components/ # Contains all React components
│ │ ├── pages/ # Contains main pages of the app
│ │ ├── styles/ # Contains global styles and themes
│ │ ├── context/ # Contains React Context API
│ │ ├── App.js # Main App component
│ │ ├── index.js # Entry point for React
│ │ └── theme.js # Material UI theme configuration
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ ├── package.json # NPM dependencies and scripts
│ └── README.md # Project documentation
│
├── backend/ # Django backend for API services and database management
│ ├── manage.py # Django's command-line utility
│ ├── requirements.txt # Backend dependencies
│ ├── backend/
│ │ ├── settings.py # Django settings for the project
│ │ ├── urls.py # URL declarations for the project
│ │ ├── users/ # User management components
│ │ └── api/ # Emotion detection and recommendation APIs
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ └── db.sqlite3 # SQLite database (if used)
│
├── ai_ml/ # AI/ML models for emotion detection
│ ├── data/ # Datasets for training and testing
│ ├── models/ # Trained models for emotion detection
│ ├── src/ # Source files for emotion detection and recommendation
│ │ ├── api/ # API scripts for running emotion detection services
│ │ ├── recommendation/ # Music recommendation logic
│ │ └── data_processing/ # Data preprocessing scripts
│ │
│ ├── Dockerfile # Dockerfile for containerization
│ └── README.md # AI/ML documentation
│
├── data_analytics/ # Data analytics scripts and visualizations
│ ├── emotion_distribution.py # Script for visualizing emotion distribution
│ ├── training_visualization.py # Script for visualizing training and validation metrics
│ ├── predictions_analysis.py # Script for analyzing model predictions
│ ├── recommendation_analysis.py # Script for visualizing music recommendations
│ ├── spark-hadoop/ # Spark and Hadoop integration scripts
│ └── visualizations/ # Generated visualizations
│
├── kubernetes/ # Kubernetes deployment files
│ ├── backend-deployment.yaml # Deployment file for the backend service
│ ├── backend-service.yaml # Deployment file for the backend service
│ ├── frontend-deployment.yaml # Deployment file for the frontend service
│ ├── frontend-service.yaml # Deployment file for the frontend service
│ └── configmap.yaml # ConfigMap for environment variables
│
├── mobile/ # React Native mobile application
│ ├── App.js # Main entry point for React Native app
│ ├── index.js # App registry for React Native
│ ├── package.json # NPM dependencies and scripts
│ ├── components/ # React Native components
│ │ ├── Footer.js # Footer component
│ │ ├── Navbar.js # Header component
│ │ ├── Auth/ # Authentication components (e.g., Login, Register)
│ │ └── Profile/ # Profile-related components
│ │
│ ├── context/ # React Context API for state management
│ │ └── DarkModeContext.js # Dark mode context provider
│ │
│ ├── pages/ # Main pages of the app
│ │ ├── HomePage.js # Home page component
│ │ ├── ProfilePage.js # Profile page component
│ │ ├── ResultsPage.js # Results page component
│ │ ├── LandingPage.js # Landing page component
│ │ └── (and more...)
│ │
│ ├── assets/ # Images, fonts, and other assets
│ ├── styles/ # Styling files (similar to CSS for web)
│ ├── .gitignore # Git ignore file
│ ├── package.json # Dependencies and scripts
│ └── README.md # Mobile app documentation
│
├── nginx/ # NGINX configuration files (for load balancing and reverse proxy)
│ ├── nginx.conf # Main NGINX configuration file
│ └── Dockerfile # Dockerfile for NGINX container
│
├── images/ # Images used in the README documentation
├── docker-compose.yml # Docker Compose file for containerization
└── README.md # Comprehensive README file for the entire project
venv ).envファイル(環境変数の場合 - ファイルの例に従って独自の資格情報を作成するか、私の場合は私に連絡してください。)AI/MLモデルのセットアップとトレーニングから始めます。バックエンドが適切に機能する必要があるためです。
または、事前に訓練されたモデルセクションで提供されているGoogleドライブリンクから事前に訓練されたモデルをダウンロードすることもできます。そうすることを選択した場合は、今のところこのセクションをスキップできます。
リポジトリをクローンします:
git clone https://github.com/hoangsonww/Moodify-Emotion-Music-App.gitAI/MLディレクトリに移動します。
cd Moodify-Emotion-Music-App/ai_ml仮想環境を作成してアクティブ化します。
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For Windows依存関係をインストールします:
pip install -r requirements.txt src/config.pyファイルの構成を編集します。
src/config.pyファイルにアクセスして、必要に応じて構成を更新します。特にSpotify APIキーとすべてのパスを構成します。src/modelsディレクトリの個々のモデルトレーニングスクリプトにアクセスし、必要に応じてデータセットと出力パスへのパスを更新します。テキスト感情モデルをトレーニングします:
python src/models/train_text_emotion.py必要に応じて他のモデルについて同様のコマンドを繰り返します(例えば、顔および音声感情モデル)。
すべての訓練されたモデルがmodelsディレクトリに配置され、次のステップに移動する前に必要なすべてのモデルをトレーニングしたことを確認してください!
必要に応じて、訓練されたAI/MLモデルをテストします。
src/models/test_emotion_models.pyスクリプトを実行して、訓練されたモデルをテストします。AI/MLモデルの準備ができたら、バックエンドのセットアップに進みます。
バックエンドディレクトリに移動します。
cd ../backend仮想環境を作成してアクティブ化します。
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For Windows依存関係をインストールします:
pip install -r requirements.txt秘密と環境を構成します:
backendディレクトリに.envファイルを作成します。.envファイルに次の環境変数を追加します。 SECRET_KEY=your_secret_key
DEBUG=True
ALLOWED_HOSTS=<your_hosts>
MONGODB_URI=<your_mongodb_uri>
backend/settings.pyにアクセスして、 SECRET_KEYを追加し、 DEBUG Trueに設定します。データベースの移行を実行します:
python manage.py migrateDjangoサーバーを開始します:
python manage.py runserverバックエンドサーバーはhttp://127.0.0.1:8000/で実行されます。
最後に、バックエンドと対話するようにフロントエンドを設定します。
フロントエンドディレクトリに移動します。
cd ../frontend糸を使用して依存関係をインストールします。
npm install開発サーバーを開始します。
npm startフロントエンドはhttp://localhost:3000で開始されます。
注:問題が発生したり、 .envファイルが必要な場合は、お気軽にお問い合わせください。
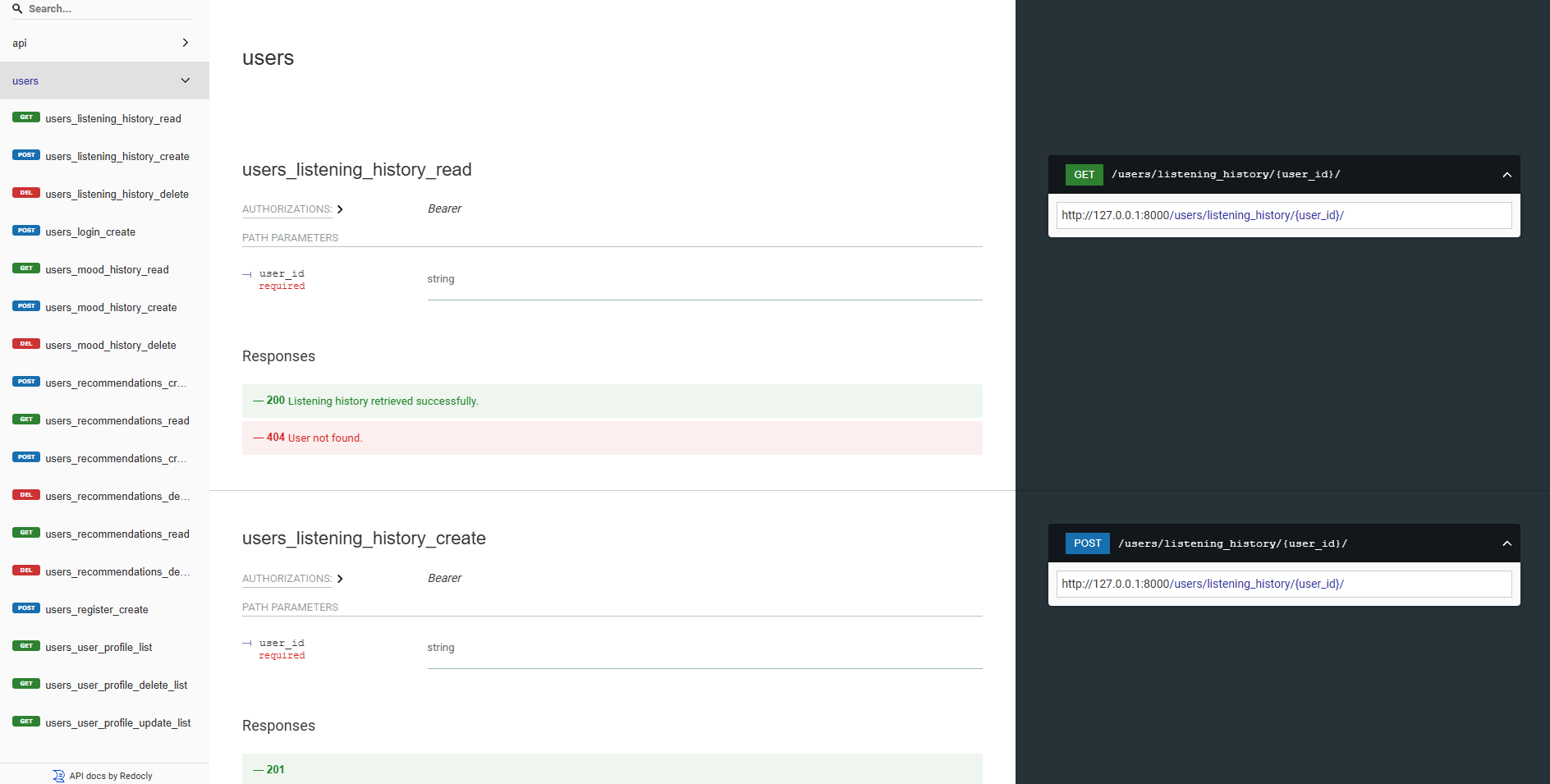
| HTTPメソッド | 終点 | 説明 |
|---|---|---|
POST | /users/register/ | 新しいユーザーを登録します |
POST | /users/login/ | ユーザーをログインして、JWTトークンを取得します |
GET | /users/user/profile/ | 認証されたユーザーのプロファイルを取得します |
PUT | /users/user/profile/update/ | 認証されたユーザーのプロファイルを更新します |
DELETE | /users/user/profile/delete/ | 認証されたユーザーのプロファイルを削除します |
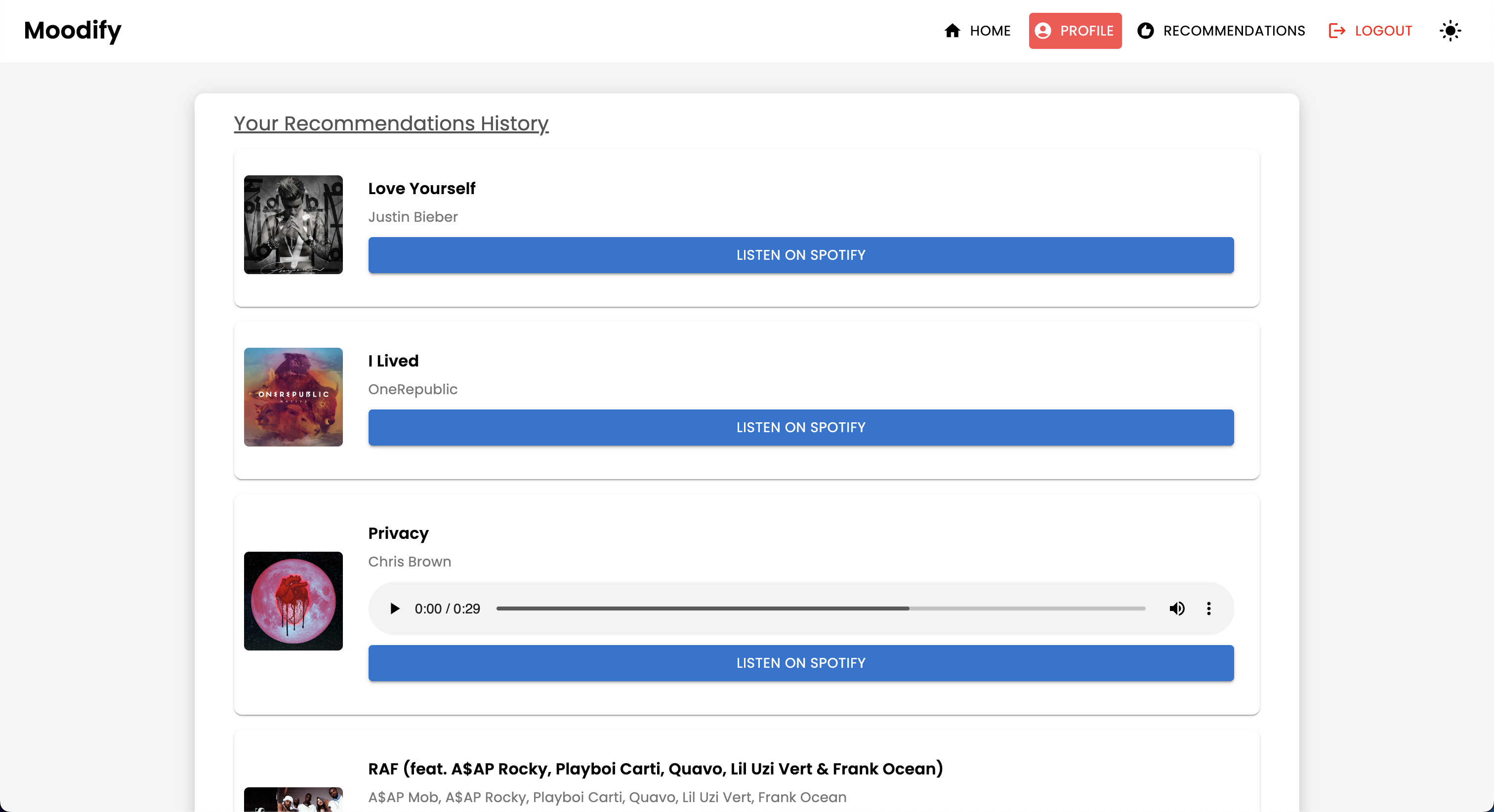
POST | /users/recommendations/ | ユーザーの推奨事項を保存します |
GET | /users/recommendations/<str:username>/ | ユーザーの推奨事項をユーザー名で取得します |
DELETE | /users/recommendations/<str:username>/<str:recommendation_id>/ | ユーザーの特定の推奨事項を削除します |
DELETE | /users/recommendations/<str:username>/ | ユーザーのすべての推奨事項を削除します |
POST | /users/mood_history/<str:user_id>/ | ユーザーの気分の歴史に気分を追加します |
GET | /users/mood_history/<str:user_id>/ | ユーザーの気分履歴を取得します |
DELETE | /users/mood_history/<str:user_id>/ | ユーザーの履歴から特定の気分を削除します |
POST | /users/listening_history/<str:user_id>/ | ユーザーのリスニング履歴にトラックを追加します |
GET | /users/listening_history/<str:user_id>/ | ユーザーのリスニング履歴を取得します |
DELETE | /users/listening_history/<str:user_id>/ | ユーザーの履歴から特定のトラックを削除します |
POST | /users/user_recommendations/<str:user_id>/ | ユーザーの推奨事項を保存します |
GET | /users/user_recommendations/<str:user_id>/ | ユーザーの推奨事項を取得します |
DELETE | /users/user_recommendations/<str:user_id>/ | ユーザーのすべての推奨事項を削除します |
POST | /users/verify-username-email/ | ユーザー名と電子メールが有効かどうかを確認します |
POST | /users/reset-password/ | ユーザーのパスワードをリセットします |
GET | /users/verify-token/ | ユーザーのトークンを確認します |
| HTTPメソッド | 終点 | 説明 |
|---|---|---|
POST | /api/text_emotion/ | 感情的な内容についてテキストを分析します |
POST | /api/speech_emotion/ | 感情的な内容のスピーチを分析します |
POST | /api/facial_emotion/ | 感情の表情を分析します |
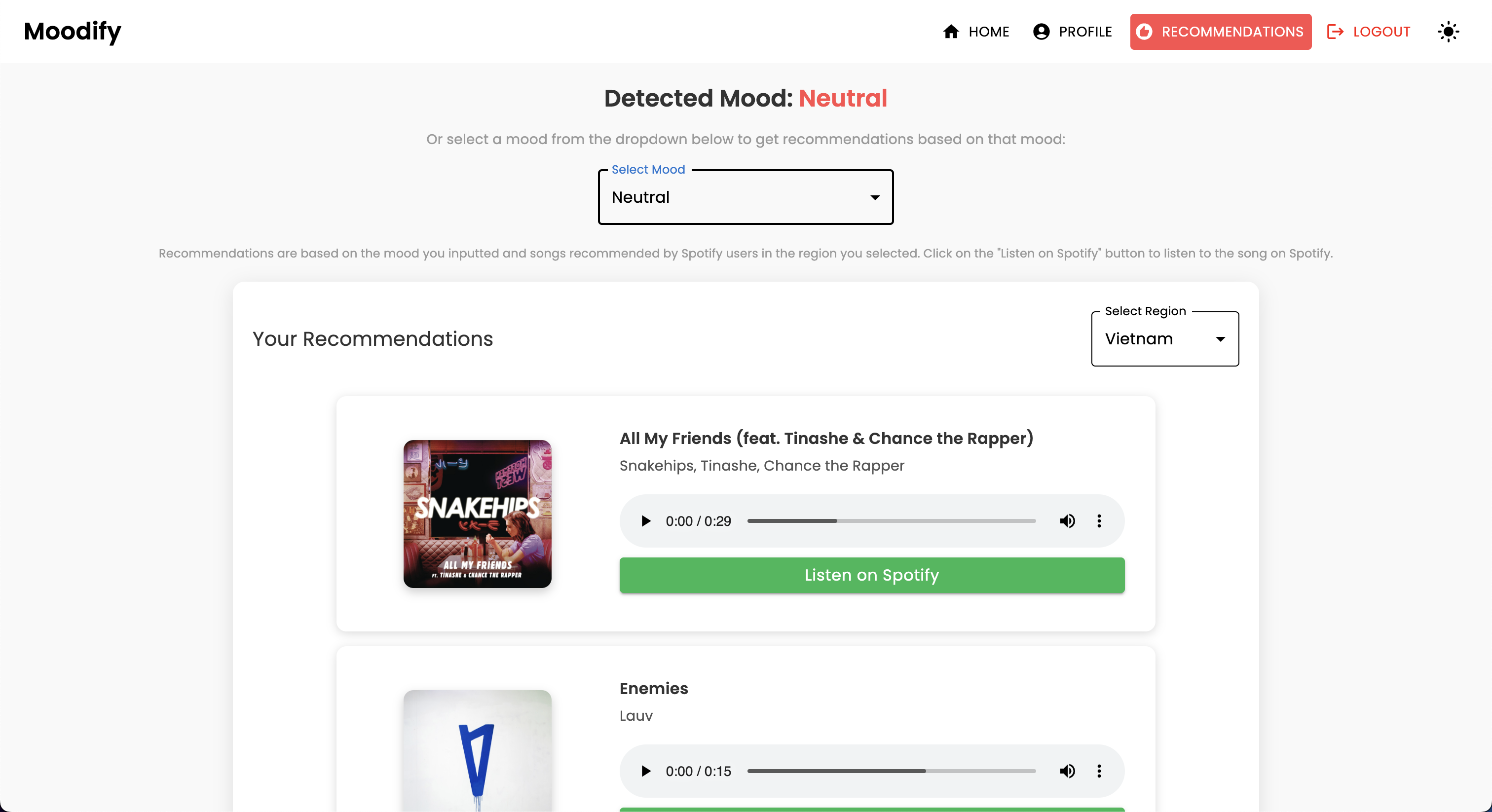
POST | /api/music_recommendation/ | 感情に基づいて音楽の推奨事項を取得します |
| HTTPメソッド | 終点 | 説明 |
|---|---|---|
GET | /admin/ | Django管理インターフェイスにアクセスします |
| HTTPメソッド | 終点 | 説明 |
|---|---|---|
GET | /swagger/ | Swagger UI APIドキュメントにアクセスします |
GET | /redoc/ | Redoc APIドキュメントにアクセスします |
GET | / | APIルートエンドポイント(SwaggerUI)にアクセスする |
スーパーユーザーを作成します:
python manage.py createsuperuser http://127.0.0.1:8000/admin/で管理パネルにアクセス
次のログインページが表示されます。
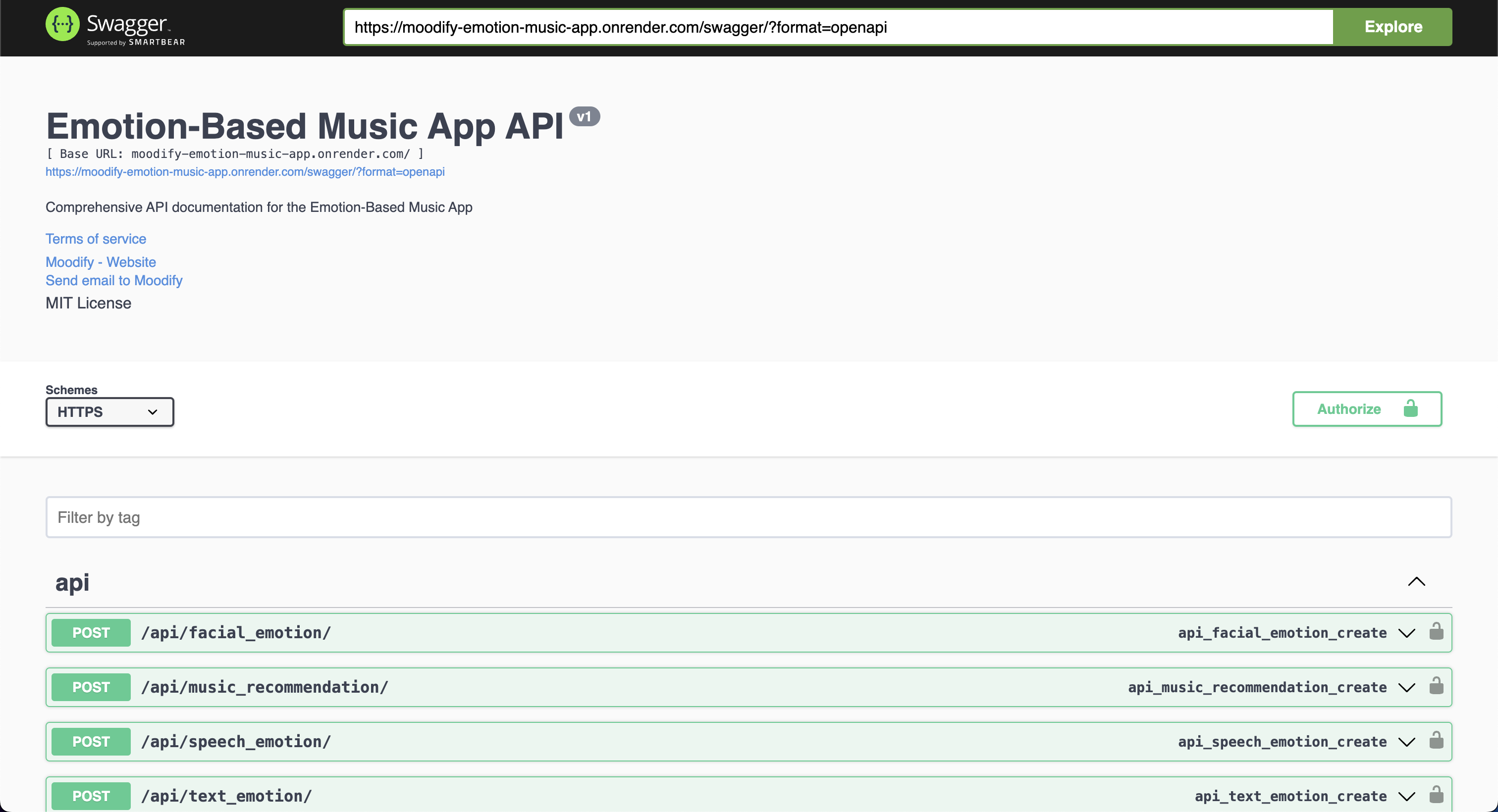
バックエンドAPIはすべて、Swagger UIとRedocを使用して十分に文書化されています。次のURLでAPIドキュメントにアクセスできます。
https://moodify-emotion-music-app.onrender.com/swagger 。https://moodify-emotion-music-app.onrender.com/redoc 。または、バックエンドサーバーをローカルで実行し、次のエンドポイントでAPIドキュメントにアクセスできます。
http://127.0.0.1:8000/swagger swagger。http://127.0.0.1:8000/redoc 8000/redoc。選択に関係なく、すべてが正しく実行されている場合は、次のAPIドキュメントを表示する必要があります。
swagger ui:
Redoc:
AI/MLモデルは、Pytorch、Tensorflow、Keras、およびHuggingfaceトランスを使用して構築されています。これらのモデルは、テキスト、音声、表情から感情を検出するために、さまざまなデータセットでトレーニングされています。
感情検出モデルは、ユーザーの入力を分析し、検出された感情に基づいてリアルタイムの音楽の推奨事項を提供するために使用されます。モデルはさまざまなデータセットでトレーニングされ、人間の感情のニュアンスをキャプチャし、正確な予測を提供します。
モデルはバックエンドAPIサービスに統合されており、ユーザーにリアルタイムの感情検出と音楽の推奨事項を提供します。
モデルは、バックエンドサービスで使用する前に最初にトレーニングする必要があります。バックエンドサーバーを実行する前に、モデルがmodelsディレクトリにトレーニングされて配置されていることを確認してください。詳細については、(#開始)[#gets-started]セクションを参照してください。
 テキスト感情モデルのトレーニングの例。
テキスト感情モデルのトレーニングの例。
モデルをトレーニングするには、提供されたスクリプトをai_ml/src/modelsディレクトリで実行できます。これらのスクリプトは、データを事前に処理し、モデルをトレーニングし、後で使用するために訓練されたモデルを保存するために使用されます。これらのスクリプトには以下が含まれます。
train_text_emotion.py :テキスト感情検出モデルをトレーニングします。train_speech_emotion.py :音声感情検出モデルをトレーニングします。train_facial_emotion.py :顔の感情検出モデルをトレーニングします。モデルをトレーニングする前に、必要な依存関係、データセット、および構成が設定されていることを確認してください。具体的には、 config.pyファイルにアクセスして、データセットと出力ディレクトリへのパスをシステムの正しいものに更新してください。
注:デフォルトでは、これらのスクリプトは、CUDAを使用してGPUを使用して(利用可能な場合)、より高速なトレーニングを優先順位を付けます。ただし、それがマシンで利用できない場合、スクリプトは自動的にトレーニングにCPUを使用することに戻ります。 GPUトレーニングに必要な依存関係があることを確認するには、次のコマンドを使用してCUDAサポートを備えたPytorchをインストールします。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118その後、 test_emotion_models.pyスクリプトを実行して訓練されたモデルをテストし、正確な予測を提供していることを確認できます。
python src/models/test_emotion_models.pyまたは、Simple Flask APIを実行して、Restful APIエンドポイントを介してモデルをテストすることもできます。
python ai_ml/src/api/emotion_api.pyエンドポイントは次のとおりです。
/text_emotion :テキスト入力から感情を検出します/speech_emotion :Speech Audioから感情を検出します/facial_emotion :画像から感情を検出します/music_recommendation :検出された感情に基づいて音楽の推奨事項を提供する重要:トレーニングとモデルの使用の詳細については、 ai_mlディレクトリのAI/MLドキュメントを参照してください。
ただし、モデルのトレーニングがリソース集中的すぎる場合は、次のGoogleドライブリンクを使用して事前に訓練されたモデルをダウンロードできます。
model.safetensors 。このmodel.safetensorsをダウンロードして、ファイルをダウンロードして、 ai_ml/models/text_emotion_modelディレクトリに配置してください。scaler.pkl 。これをダウンロードして、これをai_ml/models/speech_emotion_modelディレクトリに配置してください。trained_speech_emotion_model.pkl 。これをダウンロードして、これをai_ml/models/speech_emotion_modelディレクトリに配置してください。trained_facial_emotion_model.pt 。これをダウンロードして、これをai_ml/models/facial_emotion_modelディレクトリに配置してください。これらはお客様のためにデータセットで事前に訓練されており、バックエンドサービスで使用する準備ができているか、テスト目的でダウンロードしてmodelsディレクトリに正しく配置する準備ができています。
問題が発生した場合、またはAI/MLモデルのさらなる支援が必要な場合は、お気軽に私をコンタレクトしてください。
data_analyticsフォルダーは、感情検出モデルのパフォーマンスに関する洞察を得るために、データ分析と視覚化スクリプトを提供します。
すべての分析スクリプトを実行します:
python data_analytics/main.py visualizationsフォルダーで生成された視覚化を表示します。
視覚化の例を次に示します。
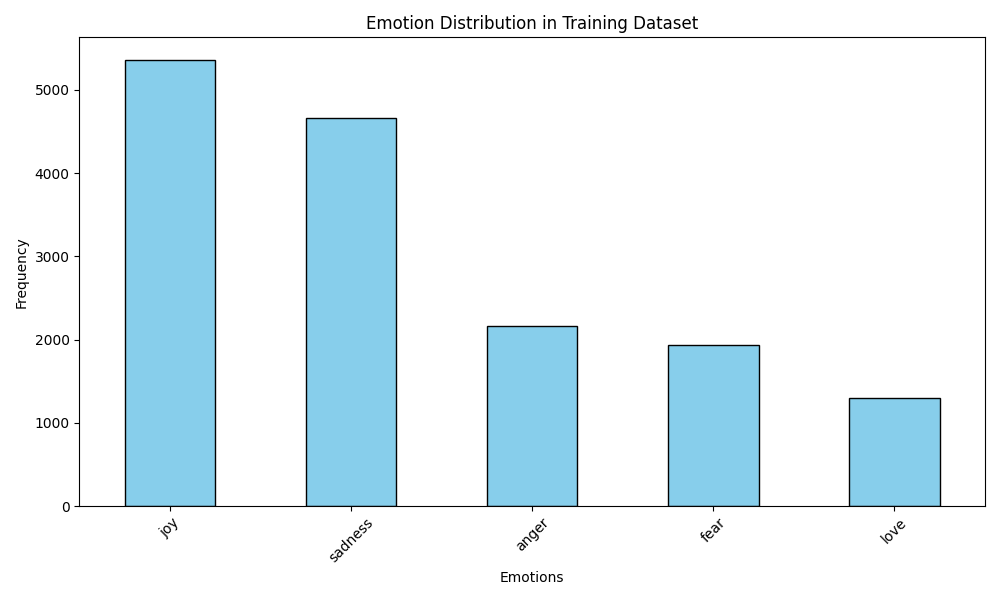 感情分布の視覚化
感情分布の視覚化
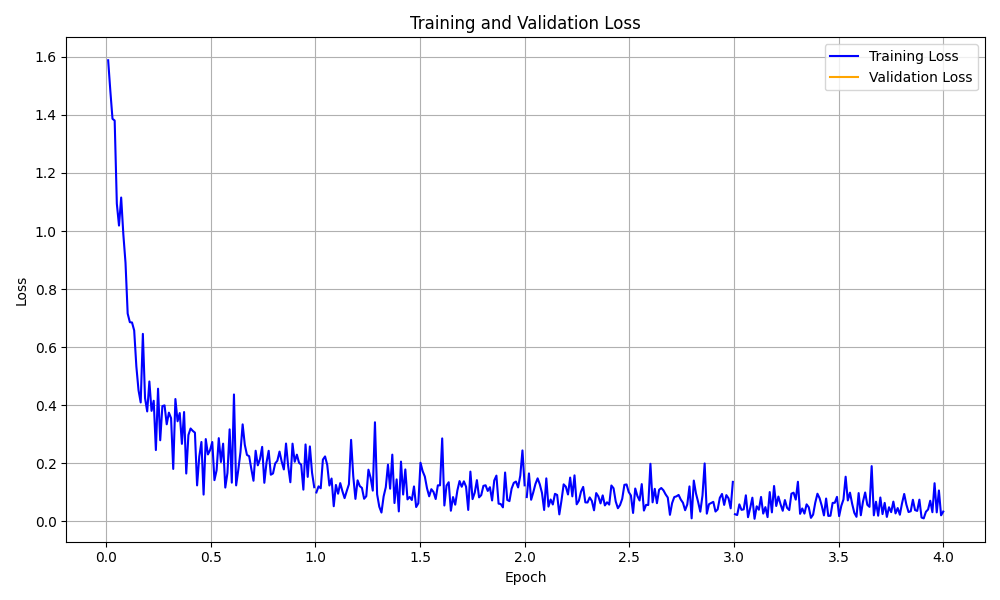 トレーニング損失曲線の視覚化
トレーニング損失曲線の視覚化
また、React Native and Expoを使用して構築されたMoodifyアプリのモバイルバージョンもあります。 mobileディレクトリでモバイルアプリを見つけることができます。
モバイルディレクトリに移動します:
cd ../mobile糸を使用して依存関係をインストールします。
yarn installExpo Development Serverを開始します。
yarn startモバイルデバイスのExpo Goアプリを使用してQRコードをスキャンして、アプリを実行します。
成功した場合は、次のホーム画面が表示されます。
モバイルアプリを自由に検討し、その機能をテストしてください!
このプロジェクトでは、DjangoバックエンドのロードバランスとサービスにNginxとGunicornを使用しています。 Nginxは逆プロキシサーバーとして機能し、GunicornはDjangoアプリケーションを提供します。
nginxをインストール:
sudo apt-get update
sudo apt-get install nginxGunicornをインストール:
pip install gunicornnginxを構成:
/nginx/nginx.conf nginx.confでnginx構成ファイル(必要に応じて)を更新します。NginxとGunicornを開始します:
sudo systemctl start nginxgunicorn backend.wsgi:application http://<server_ip>:8000/でバックエンドにアクセスします。
展開に必要に応じて、NGINX構成とグニコーン設定を自由にカスタマイズしてください。
このプロジェクトは、Dockerを使用して展開しやすく拡大するためにコンテナ化できます。フロントエンド、バックエンド、およびAI/MLモデルのDocker画像を作成できます。
Docker画像を作成します:
docker compose up --buildDocker画像は、フロントエンド、バックエンド、およびAI/MLモデル用に構築されます。以下を使用して画像を確認します。
docker imagesエラーが発生した場合は、Dockerのキャッシュが問題を引き起こす可能性があるため、キャッシュを使用せずに画像を再構築するようにしてください。
docker-compose build --no-cacheまた、バックエンドサービスとフロントエンドサービス用のKubernetes展開ファイルも追加しました。提供されたYAMLファイルを使用して、Kubernetesクラスターにサービスを展開できます。
バックエンドサービスを展開します。
kubectl apply -f kubernetes/backend-deployment.yamlフロントエンドサービスを展開します。
kubectl apply -f kubernetes/frontend-deployment.yamlサービスを公開します:
kubectl expose deployment moodify-backend --type=LoadBalancer --port=8000
kubectl expose deployment moodify-frontend --type=LoadBalancer --port=3000Loadbalancer IPを使用してサービスにアクセスします。
http://<backend_loadbalancer_ip>:8000でバックエンドサービスにアクセスできます。http://<frontend_loadbalancer_ip>:3000でフロントエンドサービスにアクセスできます。展開ファイルと構成の詳細については、 kubernetesディレクトリにアクセスしてください。
また、ビルドと展開プロセスを自動化するためのJenkins Pipelineスクリプトも含まれています。 Jenkinsを使用して、MoodifyアプリのCI/CDプロセスを自動化できます。
サーバーまたはローカルマシンにJenkinsをインストールします。
新しいジェンキンスパイプラインジョブを作成します:
jenkinsディレクトリのJenkinsfileを使用するようにパイプラインを構成します。ジェンキンスパイプラインを実行します:
JenkinsfileのJenkins Pipelineスクリプトを自由に調べて、展開プロセスに必要に応じてカスタマイズしてください。
貢献は大歓迎です!リポジトリをフォークして、プルリクエストを送信してください。
このプロジェクトは依然として積極的な開発中であり、あらゆる貢献が高く評価されていることに注意してください。
提案、機能のリクエスト、またはバグレポートがある場合は、ここで問題を公開してください。
ハッピーコーディングとバイビン! ?
2024年に息子のnguyenによって❤️で作成されました。
?トップに戻ります


