Moodify Emotion Music App
1.0.0
Mit dem Aufkommen personalisierter Musik -Streaming -Dienste besteht ein wachsender Bedarf an Systemen, die Musik auf der Grundlage der emotionalen Zustände der Benutzer empfehlen können. Moodify realisiert dieses Bedürfnis und wird von Son Nguyen im Jahr 2024 entwickelt, um personalisierte Musikempfehlungen auf der Grundlage der erkannten Emotionen der Benutzer zu liefern.
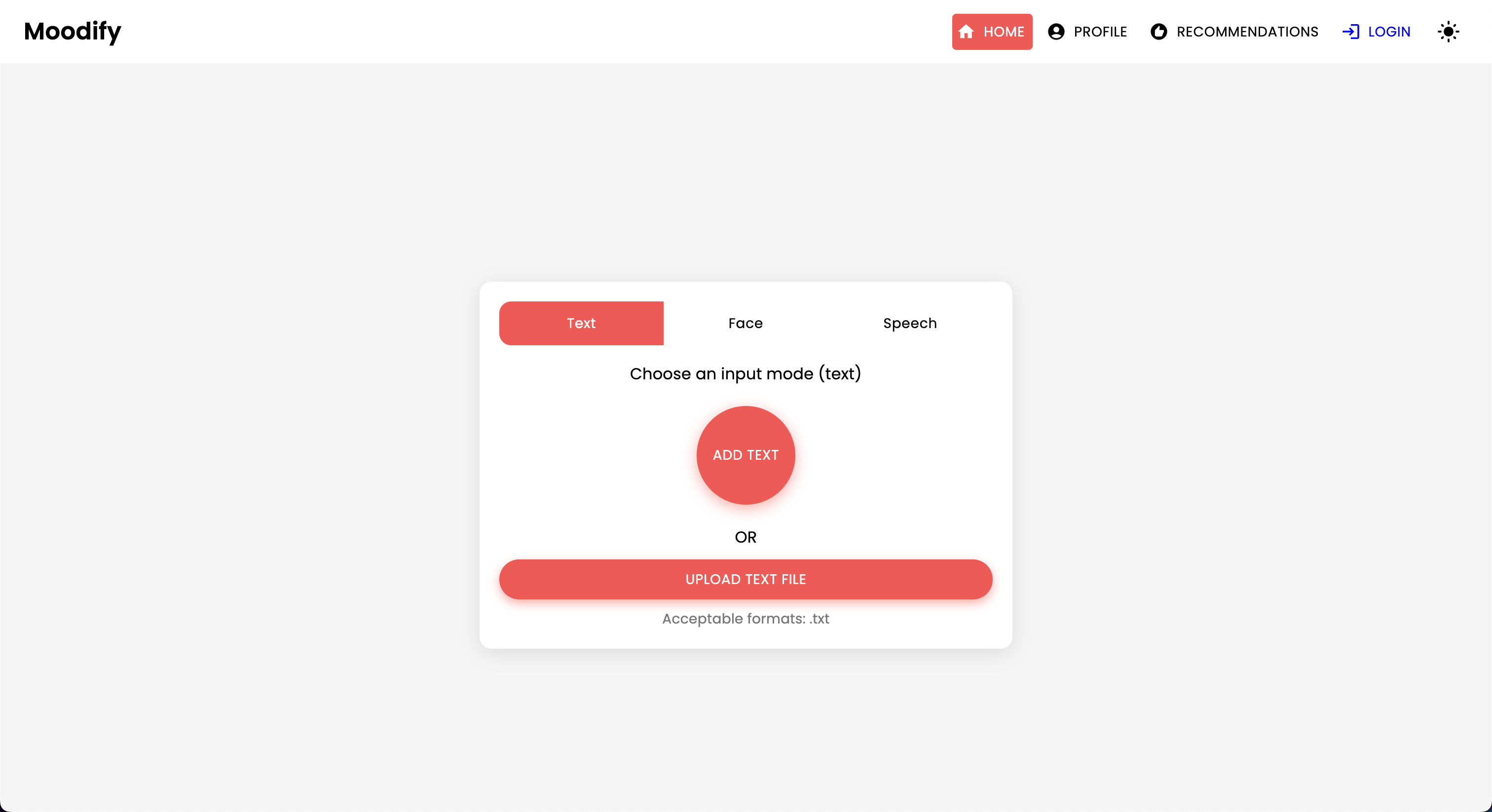
Das Moodify -Projekt ist ein integriertes, emotionales Musikempfehlungssystem, das Frontend-, Backend-, KI/ML-Modelle und Datenanalysen kombiniert, um personalisierte Musikempfehlungen basierend auf Benutzeremotionen zu liefern. Die Anwendung analysiert Text, Sprache oder Gesichtsausdrücke und schlägt Musik vor, die mit den erkannten Emotionen übereinstimmt.
Moodify unterstützt sowohl Desktop- als auch mobile Plattformen und bietet ein nahtloses Benutzererlebnis mit Echtzeit-Emotionserkennung und Musikempfehlungen. Das Projekt nutzt den Frontend, Django für das Backend, und drei fortschrittliche, selbst ausgebildete KI/ML-Modelle zur Emotionserkennung . Datenanalyse -Skripte werden verwendet, um Emotionstrends und Modellleistung zu visualisieren.

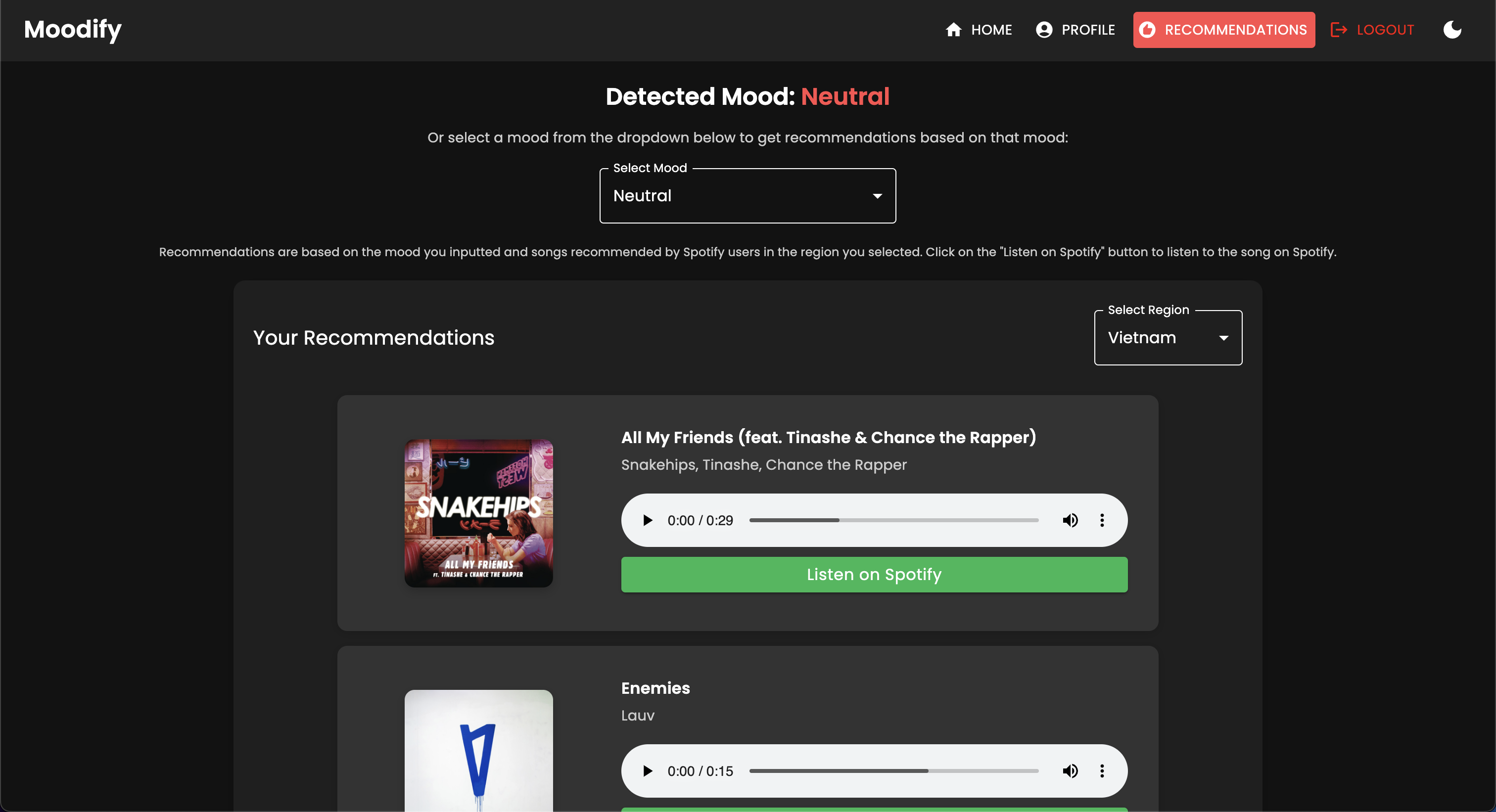
Moodify bietet personalisierte Musikempfehlungen basierend auf den emotionalen Zuständen der Benutzer, die durch Text, Sprache und Gesichtsausdrücke erkannt wurden. Es interagiert mit einem Django-basierten Backend, KI/ML-Modellen für die Emotionserkennung und verwendet Datenanalysen für visuelle Einblicke in die Emotionstrends und die Modellleistung.
Die Moodify -App ist derzeit live und wird auf Vercel bereitgestellt. Sie können mit dem folgenden Link: Moodify auf die Live -App zugreifen.
Besuchen Sie auch das Backend bei Moodify Backend API.
DICLAIMER: Der Backend von Moodify wird derzeit mit der kostenlosen Stufe des Renders gehostet, daher kann es einige Sekunden dauern, bis sie zunächst geladen werden kann. Darüber hinaus kann es sich nach einer Zeit der Inaktivität oder eines hohen Verkehrs nach unten drehen. Seien Sie also geduldig, wenn das Backend einige Sekunden dauert, bis sie reagiert.
Außerdem beträgt die vom Rendern zugewiesene Speicherspeicher nur 512 MB mit 0,1 CPU . Daher kann dem Backend keinen Speicher mehr haben, wenn zu viele Anforderungen gleichzeitig vorliegen, was dazu führen kann, dass der Server neu gestartet wird. Außerdem können die Modelle zur Erkennung von Gesichts- und Sprachemotionen aufgrund von Speicherbeschränkungen fehlschlagen - was auch dazu führen kann, dass der Server neu gestartet wird.
Mit der aktuellen Bereitstellung gibt es keine Garantie für Betriebszeit oder Leistung, es sei denn, ich habe mehr Ressourcen (Geld), um den Server zu aktualisieren :( Fühlen Sie sich frei, mich zu kontaktieren, wenn Sie auf Probleme stoßen oder weitere Unterstützung benötigen.
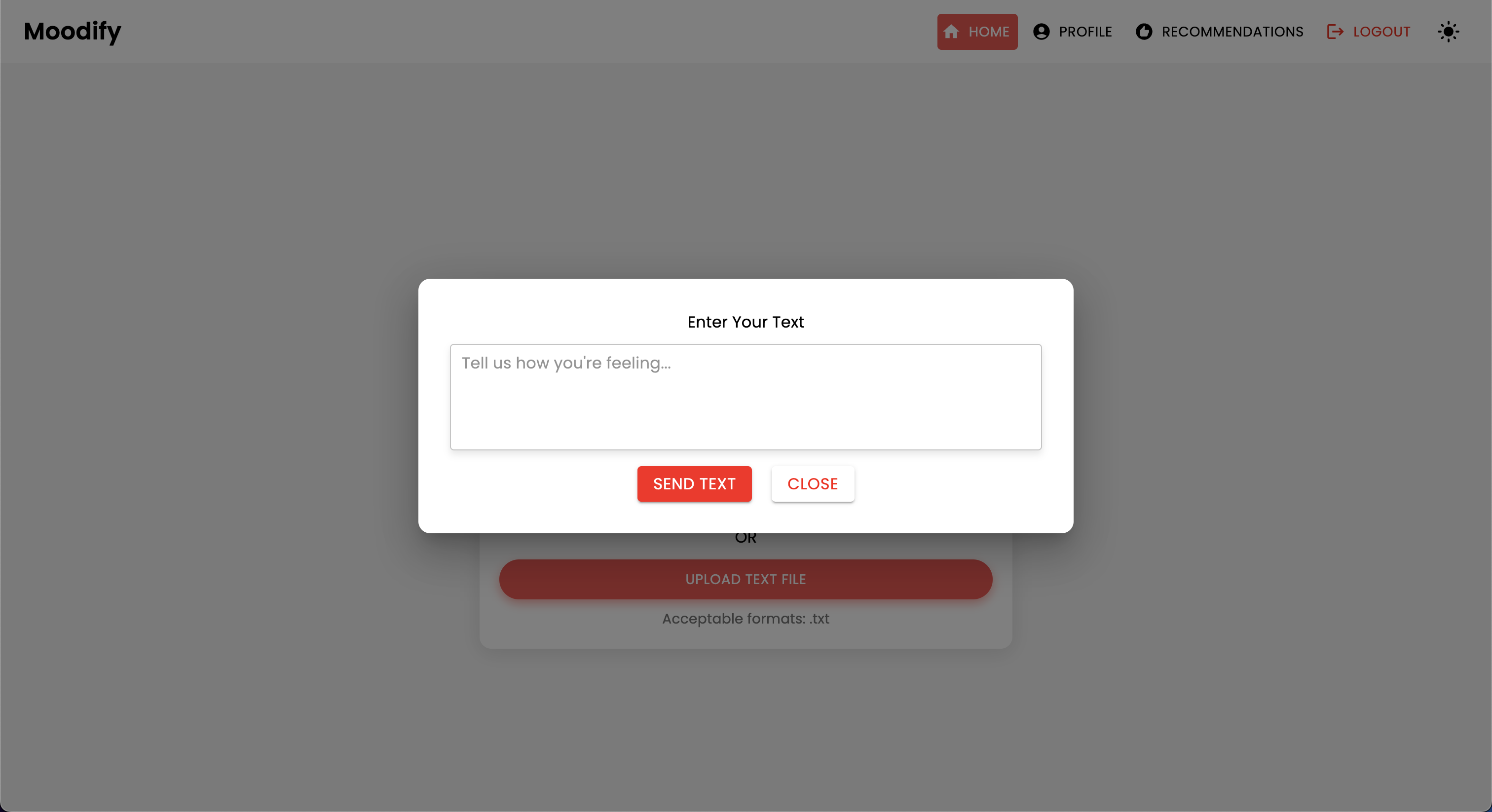
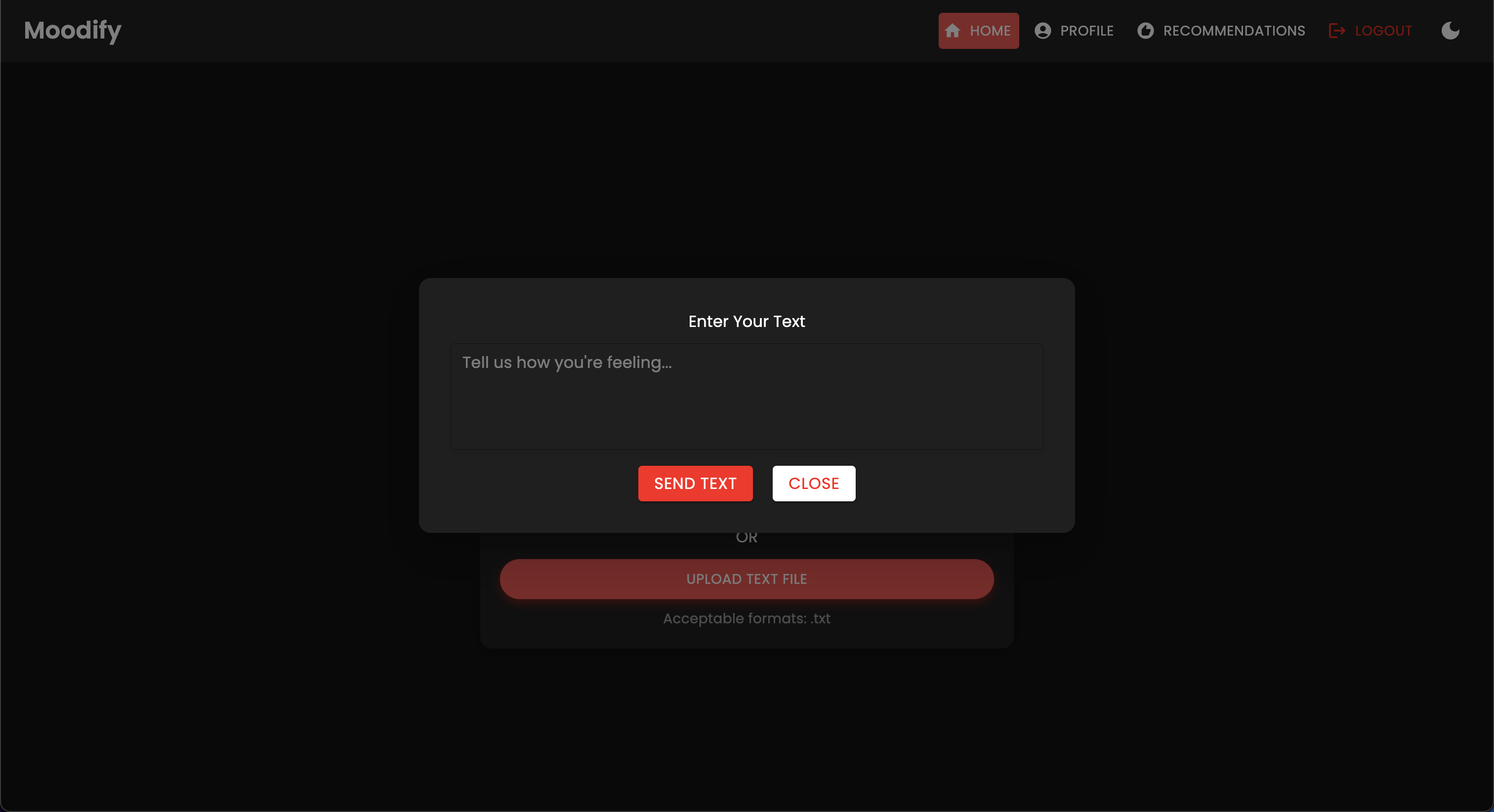
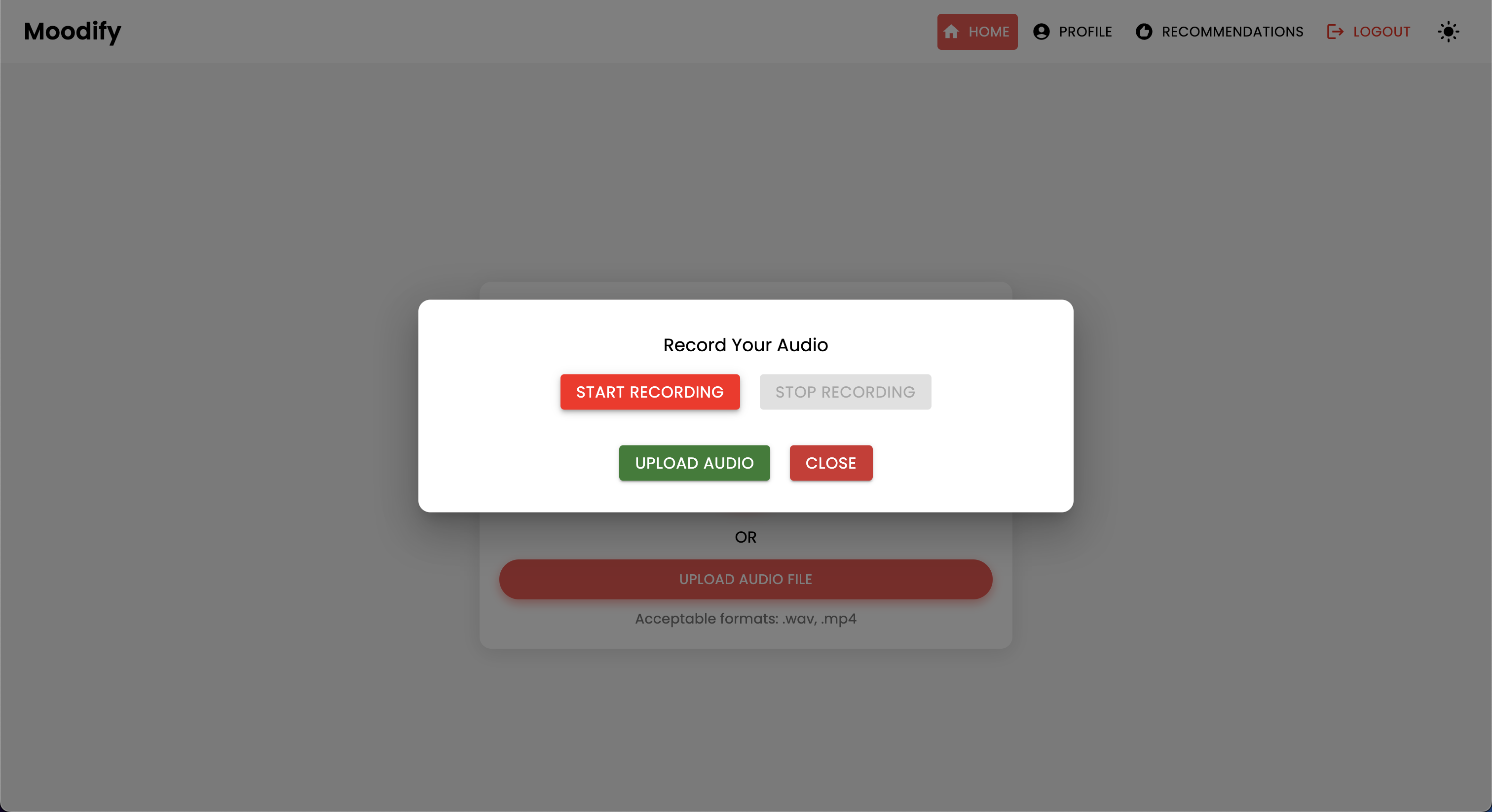
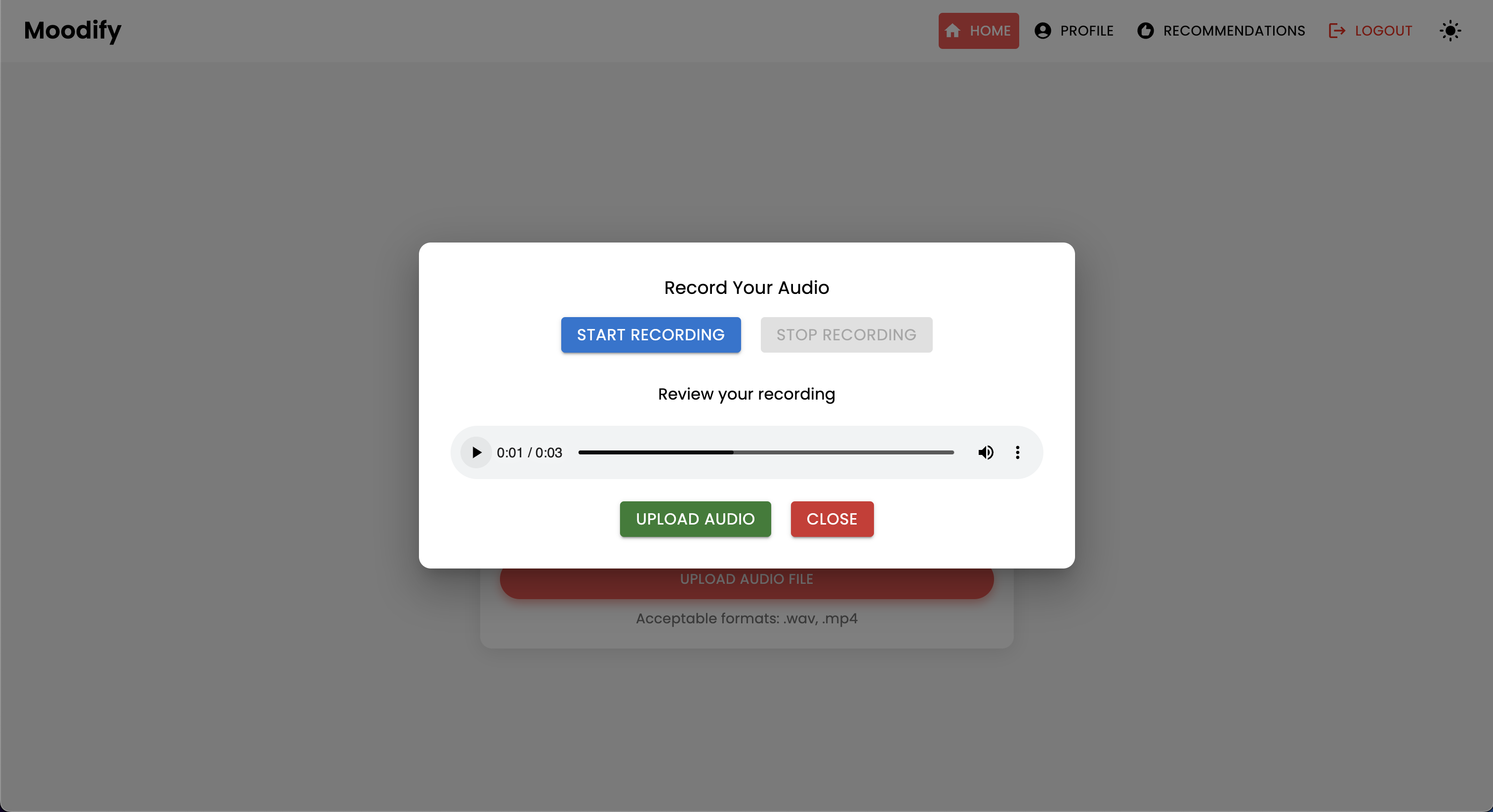
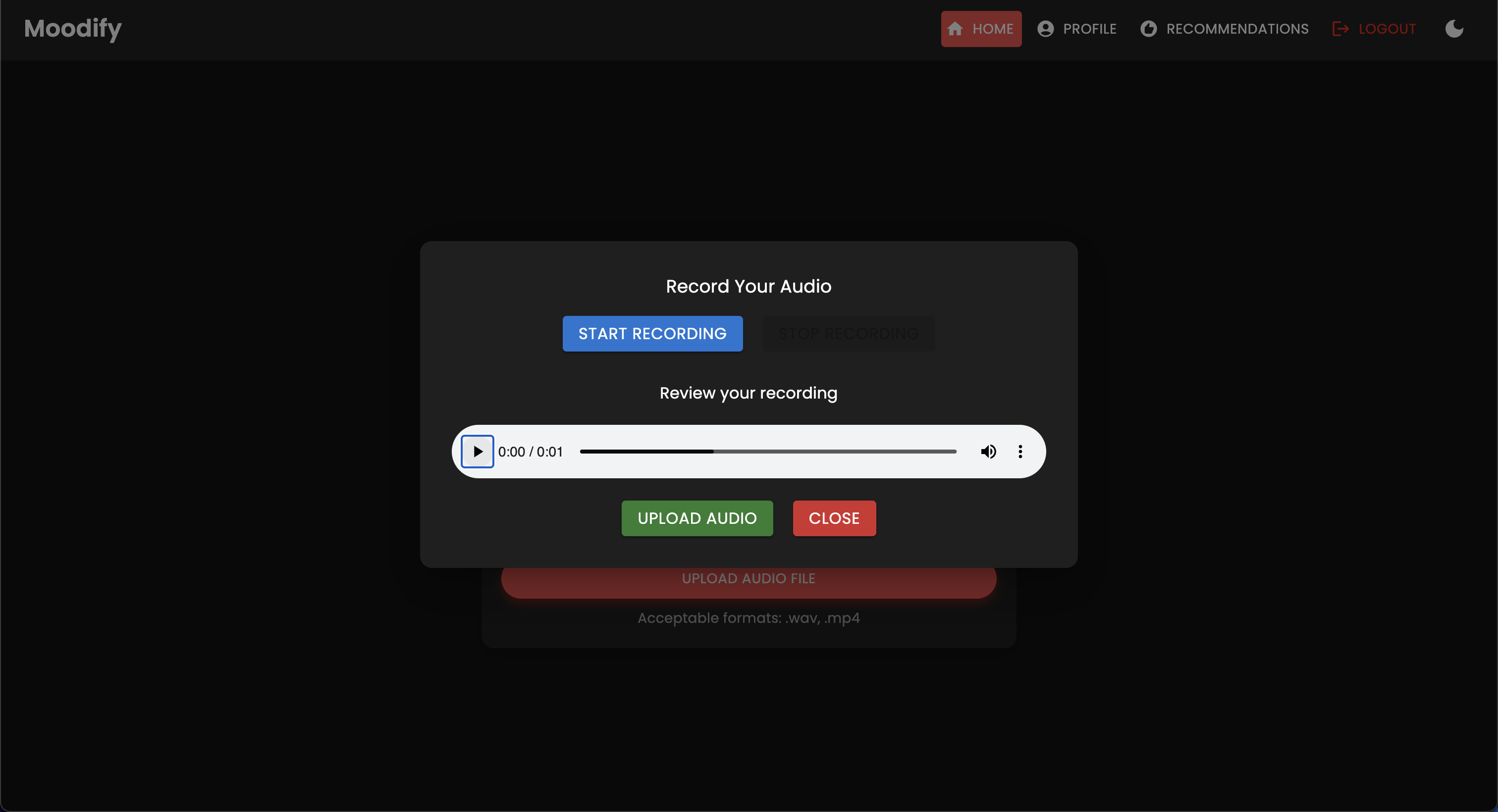
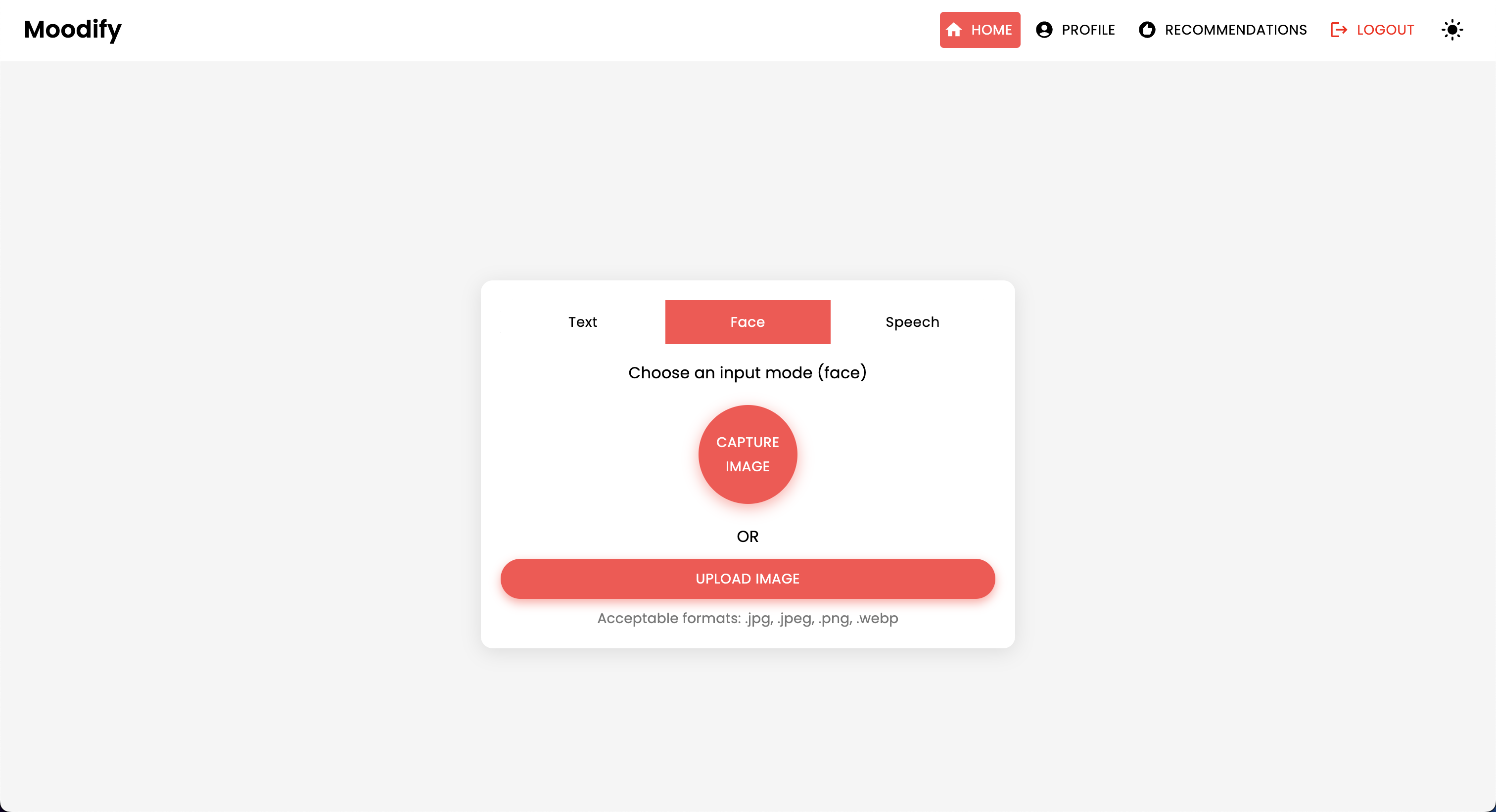

Das Projekt verfügt über eine umfassende Dateistruktur, die Frontend-, Backend-, KI/ML -Modelle und Datenanalysekomponenten kombiniert:
Moodify-Emotion-Music-App/
├── frontend/ # React frontend for the web application
│ ├── public/
│ │ ├── index.html # Main HTML file
│ │ ├── manifest.json # Web app manifest
│ │ └── favicon.ico # Favicon for the app
│ │
│ ├── src/
│ │ ├── components/ # Contains all React components
│ │ ├── pages/ # Contains main pages of the app
│ │ ├── styles/ # Contains global styles and themes
│ │ ├── context/ # Contains React Context API
│ │ ├── App.js # Main App component
│ │ ├── index.js # Entry point for React
│ │ └── theme.js # Material UI theme configuration
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ ├── package.json # NPM dependencies and scripts
│ └── README.md # Project documentation
│
├── backend/ # Django backend for API services and database management
│ ├── manage.py # Django's command-line utility
│ ├── requirements.txt # Backend dependencies
│ ├── backend/
│ │ ├── settings.py # Django settings for the project
│ │ ├── urls.py # URL declarations for the project
│ │ ├── users/ # User management components
│ │ └── api/ # Emotion detection and recommendation APIs
│ │
│ ├── .gitignore # Git ignore file
│ ├── Dockerfile # Dockerfile for containerization
│ └── db.sqlite3 # SQLite database (if used)
│
├── ai_ml/ # AI/ML models for emotion detection
│ ├── data/ # Datasets for training and testing
│ ├── models/ # Trained models for emotion detection
│ ├── src/ # Source files for emotion detection and recommendation
│ │ ├── api/ # API scripts for running emotion detection services
│ │ ├── recommendation/ # Music recommendation logic
│ │ └── data_processing/ # Data preprocessing scripts
│ │
│ ├── Dockerfile # Dockerfile for containerization
│ └── README.md # AI/ML documentation
│
├── data_analytics/ # Data analytics scripts and visualizations
│ ├── emotion_distribution.py # Script for visualizing emotion distribution
│ ├── training_visualization.py # Script for visualizing training and validation metrics
│ ├── predictions_analysis.py # Script for analyzing model predictions
│ ├── recommendation_analysis.py # Script for visualizing music recommendations
│ ├── spark-hadoop/ # Spark and Hadoop integration scripts
│ └── visualizations/ # Generated visualizations
│
├── kubernetes/ # Kubernetes deployment files
│ ├── backend-deployment.yaml # Deployment file for the backend service
│ ├── backend-service.yaml # Deployment file for the backend service
│ ├── frontend-deployment.yaml # Deployment file for the frontend service
│ ├── frontend-service.yaml # Deployment file for the frontend service
│ └── configmap.yaml # ConfigMap for environment variables
│
├── mobile/ # React Native mobile application
│ ├── App.js # Main entry point for React Native app
│ ├── index.js # App registry for React Native
│ ├── package.json # NPM dependencies and scripts
│ ├── components/ # React Native components
│ │ ├── Footer.js # Footer component
│ │ ├── Navbar.js # Header component
│ │ ├── Auth/ # Authentication components (e.g., Login, Register)
│ │ └── Profile/ # Profile-related components
│ │
│ ├── context/ # React Context API for state management
│ │ └── DarkModeContext.js # Dark mode context provider
│ │
│ ├── pages/ # Main pages of the app
│ │ ├── HomePage.js # Home page component
│ │ ├── ProfilePage.js # Profile page component
│ │ ├── ResultsPage.js # Results page component
│ │ ├── LandingPage.js # Landing page component
│ │ └── (and more...)
│ │
│ ├── assets/ # Images, fonts, and other assets
│ ├── styles/ # Styling files (similar to CSS for web)
│ ├── .gitignore # Git ignore file
│ ├── package.json # Dependencies and scripts
│ └── README.md # Mobile app documentation
│
├── nginx/ # NGINX configuration files (for load balancing and reverse proxy)
│ ├── nginx.conf # Main NGINX configuration file
│ └── Dockerfile # Dockerfile for NGINX container
│
├── images/ # Images used in the README documentation
├── docker-compose.yml # Docker Compose file for containerization
└── README.md # Comprehensive README file for the entire project
venv ).env -Datei (für Umgebungsvariablen - Sie erstellen Ihre eigenen Anmeldeinformationen, die der Beispieldatei folgen, oder kontaktieren mich für meine.)Beginnen Sie mit der Einrichtung und Schulung der KI/ML -Modelle, da sie erforderlich sind, damit das Backend ordnungsgemäß funktioniert.
Sie können die vorgebildeten Modelle aus den im Abschnitt "Vorausgebildeten Modelle" bereitgestellten Modelle von Google Drive herunterladen. Wenn Sie sich dafür entscheiden, können Sie diesen Abschnitt vorerst überspringen.
Klonen Sie das Repository:
git clone https://github.com/hoangsonww/Moodify-Emotion-Music-App.gitNavigieren Sie zum AI/ML -Verzeichnis:
cd Moodify-Emotion-Music-App/ai_mlErstellen und aktivieren Sie eine virtuelle Umgebung:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsAbhängigkeiten installieren:
pip install -r requirements.txt Bearbeiten Sie die Konfigurationen in der Datei src/config.py :
src/config.py und aktualisieren Sie die Konfigurationen nach Bedarf, insbesondere Ihre Spotify -API -Schlüssel und konfigurieren Sie alle Pfade.src/models und aktualisieren Sie die Pfade nach Bedarf auf die Datensätze und Ausgabepfade.Trainieren Sie das Text -Emotionsmodell:
python src/models/train_text_emotion.pyWiederholen Sie ähnliche Befehle für andere Modelle nach Bedarf (z. B. Modelle mit Gesichts- und Sprachemotion).
Stellen Sie sicher, dass alle geschulten Modelle in das models aufgenommen werden und dass Sie alle notwendigen Modelle geschult haben, bevor Sie zum nächsten Schritt wechseln!
Testen Sie die ausgebildeten KI/ML -Modelle nach Bedarf :
src/models/test_emotion_models.py aus, um die geschulten Modelle zu testen.Sobald die KI/ML -Modelle fertig sind, setzen Sie das Backend fort.
Navigieren Sie zum Backend -Verzeichnis:
cd ../backendErstellen und aktivieren Sie eine virtuelle Umgebung:
python -m venv venv
source venv/bin/activate # For macOS/Linux
. v env S cripts a ctivate # For WindowsAbhängigkeiten installieren:
pip install -r requirements.txtKonfigurieren Sie Ihre Geheimnisse und Ihre Umgebung:
.env -Datei im backend -Verzeichnis..env -Datei die folgenden Umgebungsvariablen hinzu: SECRET_KEY=your_secret_key
DEBUG=True
ALLOWED_HOSTS=<your_hosts>
MONGODB_URI=<your_mongodb_uri>
backend/settings.py und fügen Sie SECRET_KEY hinzu und setzen Sie DEBUG zu True .Datenbankmigrationen ausführen:
python manage.py migrateStarten Sie den Django -Server:
python manage.py runserver Der Backend -Server wird unter http://127.0.0.1:8000/ ausgeführt.
Richten Sie schließlich die Frontend ein, um mit dem Backend zu interagieren.
Navigieren Sie zum Frontend -Verzeichnis:
cd ../frontendInstallieren Sie Abhängigkeiten mit Garn:
npm installStarten Sie den Entwicklungsserver:
npm start Der Frontend beginnt bei http://localhost:3000 .
Hinweis: Wenn Sie auf Probleme stoßen oder meine .env -Datei benötigen, können Sie mich gerne kontaktieren.
| HTTP -Methode | Endpunkt | Beschreibung |
|---|---|---|
POST | /users/register/ | Registrieren Sie einen neuen Benutzer |
POST | /users/login/ | Melden Sie sich einen Benutzer an und erhalten Sie ein JWT -Token |
GET | /users/user/profile/ | Abrufen Sie das Profil des authentifizierten Benutzers ab |
PUT | /users/user/profile/update/ | Aktualisieren Sie das Profil des authentifizierten Benutzers |
DELETE | /users/user/profile/delete/ | Löschen Sie das Profil des authentifizierten Benutzers |
POST | /users/recommendations/ | Sparen Sie Empfehlungen für einen Benutzer |
GET | /users/recommendations/<str:username>/ | Rufen Sie Empfehlungen für einen Benutzer per Benutzername ab |
DELETE | /users/recommendations/<str:username>/<str:recommendation_id>/ | Löschen Sie eine bestimmte Empfehlung für einen Benutzer |
DELETE | /users/recommendations/<str:username>/ | Löschen Sie alle Empfehlungen für einen Benutzer |
POST | /users/mood_history/<str:user_id>/ | Fügen Sie der Stimmungsgeschichte des Benutzers eine Stimmung hinzu |
GET | /users/mood_history/<str:user_id>/ | Stimmungsverlauf für einen Benutzer abrufen |
DELETE | /users/mood_history/<str:user_id>/ | Löschen Sie eine bestimmte Stimmung aus dem Verlauf des Benutzers |
POST | /users/listening_history/<str:user_id>/ | Fügen Sie dem Hörverlauf des Benutzers einen Track hinzu |
GET | /users/listening_history/<str:user_id>/ | Hörhistorie für einen Benutzer abrufen |
DELETE | /users/listening_history/<str:user_id>/ | Löschen Sie einen bestimmten Track aus dem Verlauf des Benutzers |
POST | /users/user_recommendations/<str:user_id>/ | Speichern Sie die Empfehlungen eines Benutzers |
GET | /users/user_recommendations/<str:user_id>/ | Rufen Sie die Empfehlungen eines Benutzers ab |
DELETE | /users/user_recommendations/<str:user_id>/ | Löschen Sie alle Empfehlungen für einen Benutzer |
POST | /users/verify-username-email/ | Überprüfen Sie, ob ein Benutzername und eine E -Mail gültig sind |
POST | /users/reset-password/ | Setzen Sie das Passwort eines Benutzers zurück |
GET | /users/verify-token/ | Überprüfen Sie das Token eines Benutzers |
| HTTP -Methode | Endpunkt | Beschreibung |
|---|---|---|
POST | /api/text_emotion/ | Analysieren Sie den Text auf emotionale Inhalte |
POST | /api/speech_emotion/ | Analysieren Sie die Sprache auf emotionale Inhalte |
POST | /api/facial_emotion/ | Analyse der Gesichtsausdrücke auf Emotionen |
POST | /api/music_recommendation/ | Holen Sie sich Musikempfehlungen, die auf Emotionen basieren |
| HTTP -Methode | Endpunkt | Beschreibung |
|---|---|---|
GET | /admin/ | Greifen Sie auf die Django Admin -Schnittstelle zu |
| HTTP -Methode | Endpunkt | Beschreibung |
|---|---|---|
GET | /swagger/ | Greifen Sie auf die Dokumentation der Swagger UI API zu |
GET | /redoc/ | Greifen Sie auf die Dokumentation zur Redoc -API zu |
GET | / | Greifen Sie auf den API Root Endpoint (Swagger UI) zu |
Erstellen Sie einen Superuser:
python manage.py createsuperuser Greifen Sie auf das Administratorfeld unter http://127.0.0.1:8000/admin/ zu
Sie sollten die folgende Anmeldeseite sehen:
Unsere Backend-APIs sind alle mit der Swagger UI und Redoc gut dokumentiert. Sie können bei den folgenden URLs auf die API -Dokumentation zugreifen:
https://moodify-emotion-music-app.onrender.com/swagger .https://moodify-emotion-music-app.onrender.com/redoc .Alternativ können Sie den Backend -Server lokal ausführen und an folgenden Endpunkten auf die API -Dokumentation zugreifen:
http://127.0.0.1:8000/swagger .http://127.0.0.1:8000/redoc .Unabhängig von Ihrer Wahl sollten Sie die folgende API -Dokumentation sehen, wenn alles korrekt ausgeführt wird:
Swagger UI:
Redoc:
Die KI/ML -Modelle werden unter Verwendung von Pytorch, Tensorflow, Keras und Harmgingface -Transformatoren erstellt. Diese Modelle werden auf verschiedenen Datensätzen geschult, um Emotionen aus Text-, Sprach- und Mimik -Ausdrücken zu erkennen.
Mit den Emotionserkennungsmodellen werden Benutzereingaben analysiert und Musikempfehlungen in Echtzeit basierend auf den erkannten Emotionen bereitstellen. Die Modelle werden auf verschiedenen Datensätzen geschult, um die Nuancen menschlicher Emotionen zu erfassen und genaue Vorhersagen zu liefern.
Die Modelle sind in die Backend-API-Dienste integriert, um den Benutzern Echtzeit-Emotionserkennung und Musikempfehlungen zu erteilen.
Die Modelle müssen zuerst geschult werden, bevor sie in den Backend -Diensten verwendet werden. Stellen Sie sicher, dass die Modelle vor dem Ausführen des Backend -Servers im Verzeichnis models geschult und in das Models -Verzeichnis platziert werden. Weitere Informationen finden Sie im Abschnitt (Erste Schritte) [#Starting].
 Beispiele für das Training des Text -Emotionsmodells.
Beispiele für das Training des Text -Emotionsmodells.
Um die Modelle zu trainieren, können Sie die bereitgestellten Skripte im Verzeichnis ai_ml/src/models ausführen. Diese Skripte werden verwendet, um die Daten vorzubereiten, die Modelle zu trainieren und die geschulten Modelle für die spätere Verwendung zu speichern. Diese Skripte enthalten:
train_text_emotion.py : trainiert das Text -Emotionserkennungsmodell.train_speech_emotion.py : trainiert das Speech -Emotionserkennungsmodell.train_facial_emotion.py : trainiert das Modell des Gesichtsemotionserkennungsmodells. Stellen Sie sicher, dass Sie über die erforderlichen Abhängigkeiten, Datensätze und Konfigurationen verfügen, bevor Sie die Modelle trainieren. Besuchen Sie insbesondere die config.py .
Hinweis: Standardmäßig priorisieren diese Skripte mit Ihrer GPU mit CUDA (falls verfügbar) für schnelleres Training. Wenn dies jedoch nicht auf Ihrem Computer verfügbar ist, fallen die Skripte automatisch in die CPU zum Training zurück. Um sicherzustellen, dass Sie über die erforderlichen Abhängigkeiten für das GPU -Training verfügen, installieren Sie Pytorch mit CUDA -Unterstützung mit dem folgenden Befehl:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 Danach können Sie das Skript test_emotion_models.py ausführen, um die geschulten Modelle zu testen und sicherzustellen, dass sie genaue Vorhersagen liefern:
python src/models/test_emotion_models.pyAlternativ können Sie die einfache Flask -API ausführen, um die Modelle über erholsame API -Endpunkte zu testen:
python ai_ml/src/api/emotion_api.pyDie Endpunkte sind wie folgt:
/text_emotion : Erkennt Emotionen aus der Texteingabe/speech_emotion : Erkennt Emotionen aus Sprachungs Audio/facial_emotion : Erkennt Emotionen aus einem Bild/music_recommendation : Bietet Musikempfehlungen auf der Grundlage der erkannten Emotionen Wichtig : Weitere Informationen zum Training und die Verwendung der Modelle finden Sie in der KI/ML -Dokumentation im Verzeichnis ai_ml .
Wenn das Training das Modell jedoch zu ressourcenintensiv ist, können Sie die folgenden Google Drive-Links verwenden, um die vorgebauten Modelle herunterzuladen:
model.safetensors . Bitte laden Sie dieses model.safetensors herunter ai_ml/models/text_emotion_modelscaler.pkl . Bitte laden Sie dies herunter und legen Sie dies in das Verzeichnis ai_ml/models/speech_emotion_model .trained_speech_emotion_model.pkl . Bitte laden Sie dies herunter und legen Sie dies in das Verzeichnis ai_ml/models/speech_emotion_model .trained_facial_emotion_model.pt . Bitte laden Sie dies herunter und legen Sie dies in das Verzeichnis ai_ml/models/facial_emotion_model . Diese wurden für Sie auf den Datensätzen vorgeschrieben und sind bereit, in den Backend-Diensten oder zu Testzwecken nach dem Herunterladen und korrekt in das models platziert zu verwenden.
Fühlen Sie sich frei, mich zu bestehen, wenn Sie auf Probleme stoßen oder weitere Unterstützung bei den KI/ML -Modellen benötigen.
Der Ordner data_analytics bietet Datenanalyse- und Visualisierungsskripte, um Einblicke in die Leistung des Emotionserkennungsmodells zu erhalten.
Führen Sie alle Analytics -Skripte aus:
python data_analytics/main.py Zeigen Sie generierte Visualisierungen im Ordner visualizations an.
Hier sind einige Beispielvisualisierungen:
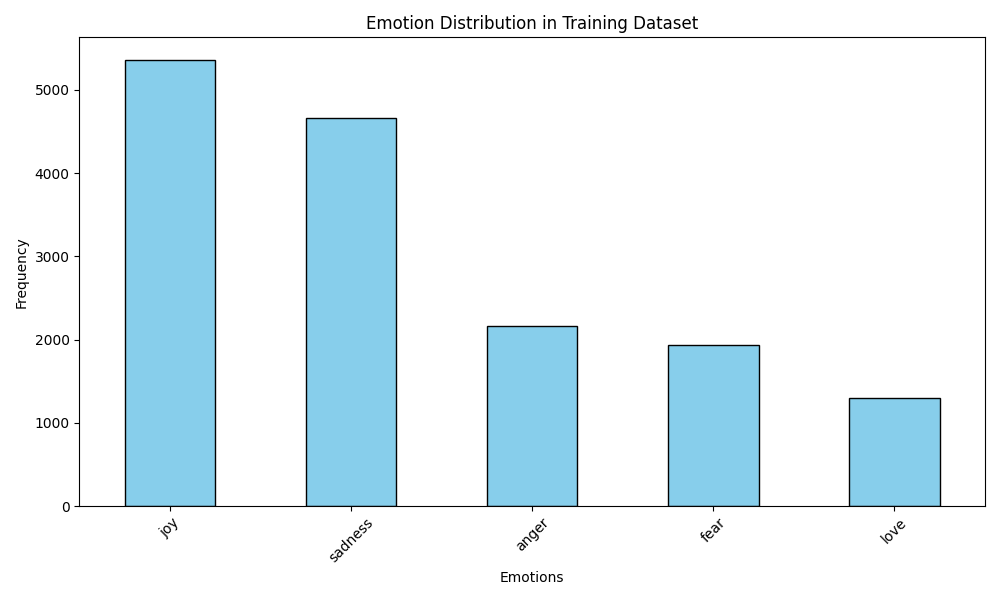 Emotionsverteilung Visualisierung
Emotionsverteilung Visualisierung
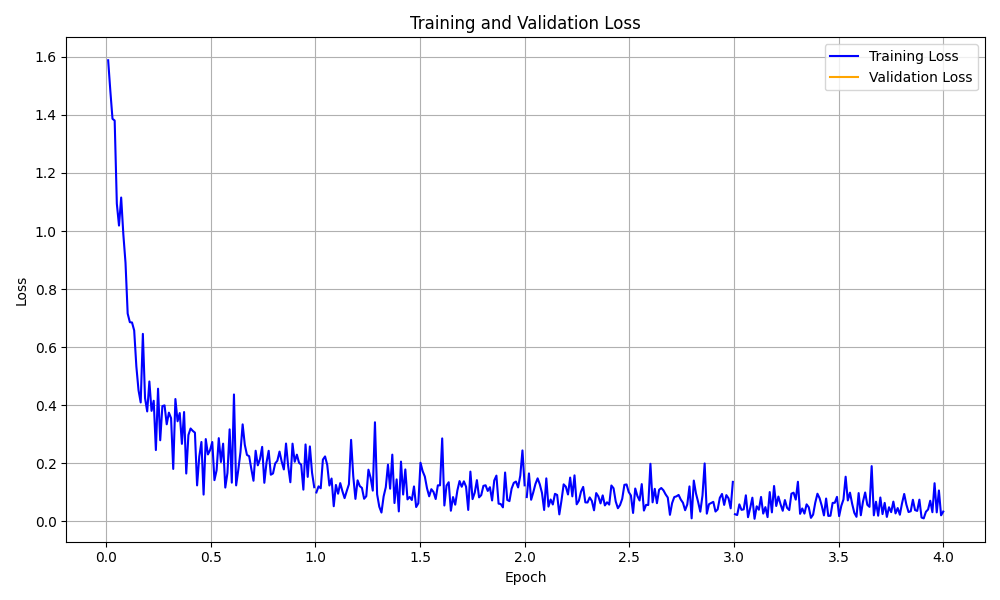 Trainingsverlustkurvenvisualisierung
Trainingsverlustkurvenvisualisierung
Es gibt auch eine mobile Version der Moodify -App, die mit React Native und Expo erstellt wurde. Sie finden die mobile App im mobile Verzeichnis.
Navigieren Sie zum mobilen Verzeichnis:
cd ../mobileInstallieren Sie Abhängigkeiten mit Garn:
yarn installStarten Sie den Expo Development Server:
yarn startScannen Sie den QR -Code mit der Expo -Go -App auf Ihrem Mobilgerät, um die App auszuführen.
Wenn Sie erfolgreich sind, sollten Sie den folgenden Startbildschirm sehen:
Fühlen Sie sich frei, die mobile App zu erkunden und ihre Funktionen zu testen!
Das Projekt verwendet Nginx und GuniCorn zum Ausgleich von Ladungen und dem Servieren des Django -Backends. Nginx fungiert als Reverse Proxy -Server, während Gunicorn der Django -Anwendung dient.
Installieren Sie Nginx:
sudo apt-get update
sudo apt-get install nginxGunicorn installieren:
pip install gunicornKonfigurieren nginx:
/nginx/nginx.conf .Starten Sie Nginx und Gunicorn:
sudo systemctl start nginxgunicorn backend.wsgi:application Greifen Sie auf das Backend unter http://<server_ip>:8000/ zu.
Fühlen Sie sich frei, die NGINX -Konfiguration und die Gunicorn -Einstellungen nach Bedarf für Ihre Bereitstellung anzupassen.
Das Projekt kann mit Docker für einfache Bereitstellung und Skalierung konstruiert werden. Sie können Docker -Bilder für Frontend-, Backend- und KI/ML -Modelle erstellen.
Erstellen Sie die Docker -Bilder:
docker compose up --buildDie Docker -Bilder werden für die Modelle Frontend, Backend und KI/ML erstellt. Überprüfen Sie die Bilder mit:
docker imagesWenn Sie auf Fehler stoßen, versuchen Sie, Ihr Bild wieder aufzubauen, ohne den Cache zu verwenden, da der Cache von Docker möglicherweise Probleme verursacht.
docker-compose build --no-cacheWir haben auch Kubernetes -Bereitstellungsdateien für die Backend- und Frontend -Dienste hinzugefügt. Sie können die Dienste über die bereitgestellten YAML -Dateien auf einem Kubernetes -Cluster bereitstellen.
Stellen Sie den Backend -Dienst ein:
kubectl apply -f kubernetes/backend-deployment.yamlStellen Sie den Frontend -Service ein:
kubectl apply -f kubernetes/frontend-deployment.yamlDie Dienstleistungen freilegen:
kubectl expose deployment moodify-backend --type=LoadBalancer --port=8000
kubectl expose deployment moodify-frontend --type=LoadBalancer --port=3000Greifen Sie mit dem LOADBalancer IP auf die Dienste zu:
http://<backend_loadbalancer_ip>:8000 zugreifen.http://<frontend_loadbalancer_ip>:3000 zugreifen. Besuchen Sie das kubernetes -Verzeichnis, um weitere Informationen zu den Bereitstellungsdateien und Konfigurationen zu erhalten.
Wir haben auch das Jenkins -Pipeline -Skript zum Automatisieren des Build- und Bereitstellungsprozesses aufgenommen. Sie können Jenkins verwenden, um den CI/CD -Prozess für die Moodify -App zu automatisieren.
Installieren Sie Jenkins auf Ihrem Server oder lokalen Computer.
Erstellen Sie einen neuen Jenkins -Pipeline -Job:
Jenkinsfile im jenkins -Verzeichnis verwendet wird.Führen Sie die Jenkins -Pipeline aus:
Erkunden Sie das Jenkins -Pipeline -Skript im Jenkinsfile und passen Sie es nach Bedarf für Ihren Bereitstellungsprozess an.
Beiträge sind willkommen! Fühlen Sie sich frei, das Repository aufzugeben und eine Pull -Anfrage einzureichen.
Beachten Sie, dass dieses Projekt noch aktiv entwickelt wird und alle Beiträge geschätzt werden.
Wenn Sie Vorschläge, Feature -Anfragen oder Fehlerberichte haben, können Sie hier ein Problem eröffnen.
Happy Coding und Vibin '! ?
Erstellt mit ❤️ von Son Nguyen im Jahr 2024.
? Zurück nach oben


