holmes extractor
Holmes 4.0.0
ผู้แต่ง: Richard Paul Hudson, Explosion AI
Managermanager.nlpOntologySupervisedTopicTrainingBasis (ส่งคืนจาก Manager.get_supervised_topic_training_basis() )SupervisedTopicModelTrainer (ส่งคืนจาก SupervisedTopicTrainingBasis.train() )SupervisedTopicClassifier (ส่งคืนจาก SupervisedTopicModelTrainer.classifier() และ Manager.deserialize_supervised_topic_classifier() )Manager.match()Manager.topic_match_documents_against()Holmes เป็นไลบรารี Python 3 (v3.6 - v3.10) ทำงานอยู่ด้านบนของ Spacy (v3.1 - v3.3) ที่รองรับกรณีการใช้งานจำนวนมากที่เกี่ยวข้องกับการสกัดข้อมูลจากข้อความภาษาอังกฤษและภาษาเยอรมัน ในทุกกรณีการใช้งานการสกัดข้อมูลจะขึ้นอยู่กับการวิเคราะห์ความสัมพันธ์เชิงความหมายที่แสดงโดยส่วนประกอบของแต่ละประโยค:
ในกรณีการใช้งาน chatbot ระบบได้รับการกำหนดค่าโดยใช้ วลีค้นหา อย่างน้อยหนึ่งวลี โฮล์มส์มองหาโครงสร้างที่มีความหมายสอดคล้องกับวลีการค้นหาเหล่านี้ภายใน เอกสาร ที่ค้นหาซึ่งในกรณีนี้สอดคล้องกับตัวอย่างของข้อความหรือคำพูดที่ป้อนโดยผู้ใช้ปลายทาง ภายในการแข่งขันแต่ละคำที่มีความหมายของตัวเอง (เช่นที่ไม่เพียง แต่เติมเต็มฟังก์ชั่นไวยากรณ์) ในวลีการค้นหาสอดคล้องกับหนึ่งคำหรือมากกว่านั้นในเอกสาร ทั้งความจริงที่ว่าวลีการค้นหาถูกจับคู่และข้อมูลที่มีโครงสร้างใด ๆ ที่วลีการค้นหาสามารถใช้ในการขับเคลื่อน chatbot
กรณีการใช้การสกัดโครงสร้างใช้เทคโนโลยีการจับคู่โครงสร้างเดียวกันกับกรณีการใช้ chatbot แต่การค้นหาเกิดขึ้นเกี่ยวกับเอกสารหรือเอกสารที่มีอยู่ก่อนซึ่งโดยทั่วไปแล้วจะนานกว่าตัวอย่างที่วิเคราะห์ในกรณีการใช้ Chatbot และเป้าหมายคือการแยกและจัดเก็บข้อมูลที่มีโครงสร้าง ตัวอย่างเช่นชุดของบทความทางธุรกิจสามารถค้นหาเพื่อค้นหาสถานที่ทั้งหมดที่ บริษัท หนึ่งกล่าวกันว่ากำลังวางแผนที่จะเข้าซื้อ บริษัท ที่สอง ตัวตนของ บริษัท ที่เกี่ยวข้องนั้นสามารถเก็บไว้ในฐานข้อมูล
เคสการใช้งานการจับคู่หัวข้อมีวัตถุประสงค์เพื่อค้นหาข้อความในเอกสารหรือเอกสารที่มีความหมายใกล้เคียงกับเอกสารอื่นซึ่งใช้ในบทบาทของ เอกสารการสืบค้น หรือ วลีแบบสอบถาม ที่ป้อนโดยผู้ใช้ โฮล์มส์สกัด วลี ขนาดเล็กจำนวนหนึ่งจากวลีแบบสอบถามหรือเอกสารการสืบค้นตรงกับเอกสารที่ถูกค้นหากับแต่ละวลีและรวมผลลัพธ์เพื่อค้นหาข้อความที่เกี่ยวข้องมากที่สุดภายในเอกสาร เนื่องจากไม่มีข้อกำหนดที่เข้มงวดว่าทุกคำที่มีความหมายของตัวเองในเอกสารการสืบค้นจับคู่คำหรือคำเฉพาะในเอกสารที่ค้นหาพบการจับคู่มากขึ้นกว่าในกรณีการใช้การสกัดโครงสร้าง แต่การจับคู่ไม่มีข้อมูลที่มีโครงสร้างที่สามารถใช้ในการประมวลผลที่ตามมา กรณีการใช้งานการจับคู่หัวข้อแสดงโดยเว็บไซต์ที่อนุญาตให้ทำการค้นหาภายในหกนวนิยาย Charles Dickens (สำหรับภาษาอังกฤษ) และเรื่องราวดั้งเดิมประมาณ 350 เรื่อง (สำหรับภาษาเยอรมัน)
กรณีการจำแนกประเภทเอกสารภายใต้การดูแลใช้ข้อมูลการฝึกอบรมเพื่อเรียนรู้ตัวจําแนกที่กำหนด ฉลากการจำแนกประเภท หนึ่งรายการขึ้นไปให้กับเอกสารใหม่ตามสิ่งที่พวกเขากำลังทำอยู่ มันจำแนกเอกสารใหม่โดยการจับคู่กับฟรุสเลตที่สกัดจากเอกสารการฝึกอบรมในลักษณะเดียวกับที่สกัดจากเอกสารการสืบค้นในกรณีการใช้งานการจับคู่หัวข้อ เทคนิคนี้ได้รับแรงบันดาลใจจากอัลกอริธึมการจำแนกประเภทของกระเป๋าที่ใช้ N-GRAMs แต่มีจุดมุ่งหมายที่จะได้รับ N-GRAM ที่มีคำพูดที่เกี่ยวข้องกับความหมายมากกว่าที่เพิ่งเกิดขึ้นเป็นเพื่อนบ้านในการแสดงพื้นผิวของภาษา
ในกรณีการใช้งานทั้งสี่คำ แต่ละคำ จะถูกจับคู่โดยใช้กลยุทธ์จำนวนมาก เพื่อหาว่าโครงสร้างไวยากรณ์สองตัวที่มีคำที่จับคู่กันเป็นรายบุคคลนั้นสอดคล้องกันอย่างมีเหตุผลและเป็นการจับคู่โฮล์มส์แปลงข้อมูลการแยกวิเคราะห์วากยสัมพันธ์ที่จัดทำโดยไลบรารี Spacy เป็นโครงสร้างความหมายที่อนุญาตให้เปรียบเทียบข้อความโดยใช้ตรรกะภาคแสดง ในฐานะผู้ใช้โฮล์มส์คุณไม่จำเป็นต้องเข้าใจความซับซ้อนของวิธีการทำงานนี้แม้ว่าจะมีเคล็ดลับสำคัญบางประการเกี่ยวกับการเขียนวลีการค้นหาที่มีประสิทธิภาพสำหรับการใช้แชทบ็อตและกรณีการใช้งานการแยกโครงสร้างที่คุณควรลอง
โฮล์มส์ตั้งเป้าหมายที่จะนำเสนอโซลูชั่นทั่วไปที่สามารถใช้งานได้มากหรือน้อยจากกล่องด้วยการปรับแต่งค่อนข้างน้อยปรับแต่งหรือฝึกอบรมและสามารถใช้งานได้อย่างรวดเร็วกับกรณีการใช้งานที่หลากหลาย ที่หลักของมันคือระบบที่มีเหตุผลตั้งโปรแกรมและตั้งโปรแกรมซึ่งอธิบายถึงวิธีการเป็นตัวแทนของวากยสัมพันธ์ในแต่ละภาษาที่แสดงความสัมพันธ์เชิงความหมาย แม้ว่ากรณีการจำแนกประเภทเอกสารภายใต้การดูแลจะรวมเครือข่ายประสาทและแม้ว่าห้องสมุด Spacy ที่โฮล์มส์สร้างเองได้รับการฝึกอบรมมาก่อนโดยใช้การเรียนรู้ของเครื่อง สำหรับปัญหาในโลกแห่งความเป็นจริง
โฮล์มส์มีประวัติศาสตร์ที่ยาวนานและซับซ้อนและตอนนี้เราสามารถเผยแพร่ได้ภายใต้ใบอนุญาต MIT ด้วยความปรารถนาดีและการเปิดกว้างของหลาย บริษัท I, Richard Hudson เขียนเวอร์ชันสูงสุด 3.0.0 ในขณะที่ทำงานที่ MSG Systems ซึ่งเป็นที่ปรึกษาด้านซอฟต์แวร์ระหว่างประเทศขนาดใหญ่ใกล้กับมิวนิค ในช่วงปลายปี 2564 ฉันเปลี่ยนนายจ้างและตอนนี้ทำงานเพื่อระเบิดผู้สร้าง Spacy และอัจฉริยะ องค์ประกอบของห้องสมุดโฮล์มส์ได้รับการคุ้มครองโดยสิทธิบัตรของสหรัฐอเมริกาที่ฉันเขียนในช่วงต้นยุค 2000 ในขณะที่ทำงานในการเริ่มต้นที่เรียกว่า Definiens ที่ได้รับจาก AstraZeneca ด้วยการอนุญาตให้ใช้ทั้งระบบ AstraZeneca และ MSG ตอนนี้ฉันยังคงรักษาโฮล์มส์ที่ระเบิดและสามารถเสนอเป็นครั้งแรกภายใต้ใบอนุญาตอนุญาต: ทุกคนสามารถใช้โฮล์มส์ภายใต้เงื่อนไขของใบอนุญาต MIT โดยไม่ต้องกังวลเกี่ยวกับสิทธิบัตร
ห้องสมุดได้รับการพัฒนาเดิมที่ระบบผงชูรส แต่ตอนนี้ได้รับการดูแลที่ระเบิด AI โปรดนำปัญหาใหม่หรือการอภิปรายไปยังที่เก็บระเบิด
หากคุณยังไม่มี Python 3 และ Pip บนเครื่องของคุณคุณจะต้องติดตั้งก่อนที่จะติดตั้งโฮล์มส์
ติดตั้งโฮล์มส์โดยใช้คำสั่งต่อไปนี้:
Linux:
pip3 install holmes-extractor
Windows:
pip install holmes-extractor
ในการอัพเกรดจากรุ่น Holmes ก่อนหน้าให้ออกคำสั่งต่อไปนี้แล้วออกคำสั่งใหม่เพื่อดาวน์โหลดรุ่น Spacy และ CoreFeree เพื่อให้แน่ใจว่าคุณมีเวอร์ชันที่ถูกต้อง:
Linux:
pip3 install --upgrade holmes-extractor
Windows:
pip install --upgrade holmes-extractor
หากคุณต้องการใช้ตัวอย่างและการทดสอบให้โคลนซอร์สโค้ดโดยใช้
git clone https://github.com/explosion/holmes-extractor
หากคุณต้องการทดสอบด้วยการเปลี่ยนซอร์สโค้ดคุณสามารถแทนที่รหัสที่ติดตั้งโดยเริ่มต้น Python (พิมพ์ python3 (Linux) หรือ python (Windows)) ในไดเรกทอรีหลักของไดเรกทอรีที่รหัสโมดูล holmes_extractor ที่เปลี่ยนแปลงของคุณคือ หากคุณตรวจสอบโฮล์มส์จาก Git นี่จะเป็นไดเรกทอรี holmes-extractor
หากคุณต้องการถอนการติดตั้ง Holmes อีกครั้งสิ่งนี้สามารถทำได้โดยการลบไฟล์ที่ติดตั้งโดยตรงจากระบบไฟล์ สิ่งเหล่านี้สามารถพบได้โดยการออกข้อความต่อไปนี้จากคำสั่ง Python เริ่มต้นจากไดเรกทอรีอื่น ๆ นอกเหนือ จากไดเรกทอรีหลักของ holmes_extractor :
import holmes_extractor
print(holmes_extractor.__file__)
ห้องสมุด Spacy และ CoreFeree ที่ Holmes สร้างขึ้นตามต้องการโมเดลเฉพาะภาษาที่ต้องดาวน์โหลดแยกต่างหากก่อนที่จะใช้โฮล์มส์:
Linux/English:
python3 -m spacy download en_core_web_trf
python3 -m spacy download en_core_web_lg
python3 -m coreferee install en
Linux/German:
pip3 install spacy-lookups-data # (from spaCy 3.3 onwards)
python3 -m spacy download de_core_news_lg
python3 -m coreferee install de
Windows/English:
python -m spacy download en_core_web_trf
python -m spacy download en_core_web_lg
python -m coreferee install en
Windows/German:
pip install spacy-lookups-data # (from spaCy 3.3 onwards)
python -m spacy download de_core_news_lg
python -m coreferee install de
และถ้าคุณวางแผนที่จะเรียกใช้การทดสอบการถดถอย:
Linux:
python3 -m spacy download en_core_web_sm
Windows:
python -m spacy download en_core_web_sm
คุณระบุโมเดล Spacy สำหรับโฮล์มส์ที่จะใช้เมื่อคุณสร้างอินสแตนซ์คลาสผู้จัดการฝ่าย en_core_web_trf และ de_core_web_lg เป็นแบบจำลองที่พบว่าให้ผลลัพธ์ที่ดีที่สุดสำหรับภาษาอังกฤษและเยอรมันตามลำดับ เนื่องจาก en_core_web_trf ไม่มีเวกเตอร์คำของตัวเอง แต่โฮล์มส์ต้องใช้เวคเตอร์คำสำหรับการจับคู่แบบฝังตัวรุ่น en_core_web_lg ถูกโหลดเป็นแหล่งเวกเตอร์เมื่อใดก็ตามที่ en_core_web_trf ระบุไว้ในคลาสผู้จัดการ
โมเดล en_core_web_trf ต้องการทรัพยากรที่เพียงพอมากกว่ารุ่นอื่น ๆ ในการจัดวางที่ทรัพยากรขาดแคลนอาจเป็นการประนีประนอมอย่างสมเหตุสมผลที่จะใช้ en_core_web_lg เป็นรุ่นหลักแทน
วิธีที่ดีที่สุดในการบูรณาการโฮล์มส์เข้ากับสภาพแวดล้อมที่ไม่ใช่ Python คือการห่อเป็นบริการ HTTP ที่พักผ่อนและปรับใช้เป็น microservice ดูตัวอย่างที่นี่
เนื่องจากโฮล์มส์ดำเนินการวิเคราะห์ที่ซับซ้อนและชาญฉลาดจึงเป็นสิ่งที่หลีกเลี่ยงไม่ได้ที่ต้องใช้ทรัพยากรฮาร์ดแวร์มากกว่าเฟรมเวิร์กการค้นหาแบบดั้งเดิม กรณีการใช้งานที่เกี่ยวข้องกับการโหลดเอกสาร - การสกัดโครงสร้างและการจับคู่หัวข้อ - ส่วนใหญ่จะใช้งานได้ทันทีกับ corpora ขนาดใหญ่ แต่ไม่ใหญ่ (เช่นเอกสารทั้งหมดที่เป็นขององค์กรบางแห่งสิทธิบัตรทั้งหมดในหัวข้อบางเล่มหนังสือทั้งหมดโดยผู้เขียนบางคน) ด้วยเหตุผลด้านต้นทุนโฮล์มส์จะไม่เป็นเครื่องมือที่เหมาะสมในการวิเคราะห์เนื้อหาของอินเทอร์เน็ตทั้งหมด!
ที่กล่าวว่าโฮล์มส์สามารถปรับขนาดได้ทั้งแนวตั้งและแนวนอน ด้วยฮาร์ดแวร์ที่เพียงพอกรณีการใช้งานทั้งสองนี้สามารถนำไปใช้กับเอกสารจำนวนไม่ จำกัด จำนวนมากโดยใช้โฮล์มส์บนเครื่องหลายเครื่องประมวลผลเอกสารที่แตกต่างกันในแต่ละเอกสารและทำให้ผลลัพธ์สับสน โปรดทราบว่ากลยุทธ์นี้ใช้แล้วเพื่อแจกจ่ายการจับคู่ระหว่างหลายแกนในเครื่องเดียว: คลาสผู้จัดการเริ่มกระบวนการของคนงานจำนวนมากและแจกจ่ายเอกสารที่ลงทะเบียนระหว่างพวกเขา
โฮล์มส์ถือเอกสารที่โหลดไว้ในหน่วยความจำซึ่งเชื่อมโยงกับการใช้งานที่ตั้งใจไว้กับ corpora ขนาดใหญ่ แต่ไม่ใหญ่ ประสิทธิภาพของการโหลดเอกสารการสกัดโครงสร้างและการจับคู่หัวข้อทั้งหมดจะลดลงอย่างมากหากระบบปฏิบัติการต้องเปลี่ยนหน้าหน่วยความจำไปยังที่เก็บข้อมูลรองเนื่องจากโฮล์มส์สามารถต้องการหน่วยความจำจากหน้าเว็บที่หลากหลายที่จะได้รับการแก้ไขเมื่อประมวลผลประโยคเดียว ซึ่งหมายความว่าเป็นสิ่งสำคัญที่จะต้องจัดหา RAM ให้เพียงพอในแต่ละเครื่องเพื่อเก็บเอกสารที่โหลดทั้งหมดไว้
โปรดทราบความคิดเห็นข้างต้นเกี่ยวกับข้อกำหนดทรัพยากรที่สัมพันธ์กันของรุ่นที่แตกต่างกัน
กรณีการใช้งานที่ง่ายที่สุดที่จะได้รับแนวคิดพื้นฐานอย่างรวดเร็วว่าโฮล์มส์ทำงานอย่างไรคือกรณีการใช้งาน ของแชทบ็อต
ที่นี่วลีการค้นหาอย่างน้อยหนึ่งวลีถูกกำหนดให้โฮล์มส์ล่วงหน้าและเอกสารที่ค้นหาเป็นประโยคสั้น ๆ หรือย่อหน้าที่พิมพ์ในแบบโต้ตอบโดยผู้ใช้ปลายทาง ในการตั้งค่าในชีวิตจริงข้อมูลที่สกัดจะถูกใช้เพื่อกำหนดการไหลของการโต้ตอบกับผู้ใช้ปลายทาง สำหรับการทดสอบและการสาธิตมีคอนโซลที่แสดงผลการวิจัยที่ตรงกัน มันสามารถเริ่มต้นได้อย่างง่ายดายและรวดเร็วจากบรรทัดคำสั่ง Python (ซึ่งเริ่มต้นจากพรอมต์ระบบปฏิบัติการโดยพิมพ์ python3 (Linux) หรือ python (Windows)) หรือจากภายในสมุดบันทึก Jupyter
ตัวอย่างโค้ดต่อไปนี้สามารถป้อนบรรทัดสำหรับบรรทัดลงในบรรทัดคำสั่ง Python ลงในสมุดบันทึก Jupyter หรือเข้าสู่ IDE มันลงทะเบียนความจริงที่ว่าคุณมีความสนใจในประโยคเกี่ยวกับสุนัขตัวใหญ่ไล่ล่าแมวและเริ่มคอนโซล Chatbot สาธิต:
ภาษาอังกฤษ:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='en_core_web_lg', number_of_workers=1)
holmes_manager.register_search_phrase('A big dog chases a cat')
holmes_manager.start_chatbot_mode_console()
เยอรมัน:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='de_core_news_lg', number_of_workers=1)
holmes_manager.register_search_phrase('Ein großer Hund jagt eine Katze')
holmes_manager.start_chatbot_mode_console()
หากคุณป้อนประโยคที่สอดคล้องกับวลีการค้นหาคอนโซลจะแสดงการจับคู่:
ภาษาอังกฤษ:
Ready for input
A big dog chased a cat
Matched search phrase with text 'A big dog chases a cat':
'big'->'big' (Matches BIG directly); 'A big dog'->'dog' (Matches DOG directly); 'chased'->'chase' (Matches CHASE directly); 'a cat'->'cat' (Matches CAT directly)
เยอรมัน:
Ready for input
Ein großer Hund jagte eine Katze
Matched search phrase 'Ein großer Hund jagt eine Katze':
'großer'->'groß' (Matches GROSS directly); 'Ein großer Hund'->'hund' (Matches HUND directly); 'jagte'->'jagen' (Matches JAGEN directly); 'eine Katze'->'katze' (Matches KATZE directly)
สิ่งนี้สามารถทำได้อย่างง่ายดายด้วยอัลกอริทึมการจับคู่ที่เรียบง่ายดังนั้นพิมพ์ประโยคที่ซับซ้อนอีกสองสามประโยคเพื่อโน้มน้าวตัวเองว่าโฮล์มส์กำลังจับพวกเขาจริงๆและการแข่งขันยังคงกลับมา:
ภาษาอังกฤษ:
The big dog would not stop chasing the cat
The big dog who was tired chased the cat
The cat was chased by the big dog
The cat always used to be chased by the big dog
The big dog was going to chase the cat
The big dog decided to chase the cat
The cat was afraid of being chased by the big dog
I saw a cat-chasing big dog
The cat the big dog chased was scared
The big dog chasing the cat was a problem
There was a big dog that was chasing a cat
The cat chase by the big dog
There was a big dog and it was chasing a cat.
I saw a big dog. My cat was afraid of being chased by the dog.
There was a big dog. His name was Fido. He was chasing my cat.
A dog appeared. It was chasing a cat. It was very big.
The cat sneaked back into our lounge because a big dog had been chasing her.
Our big dog was excited because he had been chasing a cat.
เยอรมัน:
Der große Hund hat die Katze ständig gejagt
Der große Hund, der müde war, jagte die Katze
Die Katze wurde vom großen Hund gejagt
Die Katze wurde immer wieder durch den großen Hund gejagt
Der große Hund wollte die Katze jagen
Der große Hund entschied sich, die Katze zu jagen
Die Katze, die der große Hund gejagt hatte, hatte Angst
Dass der große Hund die Katze jagte, war ein Problem
Es gab einen großen Hund, der eine Katze jagte
Die Katzenjagd durch den großen Hund
Es gab einmal einen großen Hund, und er jagte eine Katze
Es gab einen großen Hund. Er hieß Fido. Er jagte meine Katze
Es erschien ein Hund. Er jagte eine Katze. Er war sehr groß.
Die Katze schlich sich in unser Wohnzimmer zurück, weil ein großer Hund sie draußen gejagt hatte
Unser großer Hund war aufgeregt, weil er eine Katze gejagt hatte
การสาธิตไม่สมบูรณ์หากไม่ลองใช้ประโยคอื่นที่มีคำเดียวกัน แต่ไม่ได้แสดงความคิดเดียวกันและสังเกตว่าพวกเขา ไม่ ตรงกัน:
ภาษาอังกฤษ:
The dog chased a big cat
The big dog and the cat chased about
The big dog chased a mouse but the cat was tired
The big dog always used to be chased by the cat
The big dog the cat chased was scared
Our big dog was upset because he had been chased by a cat.
The dog chase of the big cat
เยอรมัน:
Der Hund jagte eine große Katze
Die Katze jagte den großen Hund
Der große Hund und die Katze jagten
Der große Hund jagte eine Maus aber die Katze war müde
Der große Hund wurde ständig von der Katze gejagt
Der große Hund entschloss sich, von der Katze gejagt zu werden
Die Hundejagd durch den große Katze
ในตัวอย่างข้างต้นโฮล์มส์ได้จับคู่โครงสร้างระดับประโยคต่าง ๆ ที่แตกต่างกันซึ่งมีความหมายเหมือนกัน แต่รูปแบบพื้นฐานของคำสามคำในเอกสารที่ตรงกันนั้นมักจะเหมือนกับคำสามคำในวลีการค้นหา โฮล์มส์ให้กลยุทธ์เพิ่มเติมอีกหลายประการสำหรับการจับคู่ในระดับคำแต่ละคำ เมื่อรวมกับความสามารถของโฮล์มส์ในการจับคู่โครงสร้างประโยคที่แตกต่างกันสิ่งเหล่านี้สามารถเปิดใช้งานวลีการค้นหาที่จะจับคู่กับประโยคเอกสารที่แบ่งปันความหมายของมันแม้ว่าทั้งสองจะไม่มีคำพูด
หนึ่งในกลยุทธ์การจับคู่คำเพิ่มเติมเหล่านี้คือการจับคู่ ementity: คำพิเศษสามารถรวมอยู่ในวลีค้นหาที่ตรงกับชื่อทั้งหมดของชื่อเช่นคนหรือสถานที่ ออกจากคอนโซลโดยการพิมพ์ exit จากนั้นลงทะเบียนวลีการค้นหาครั้งที่สองและรีสตาร์ทคอนโซล:
ภาษาอังกฤษ:
holmes_manager.register_search_phrase('An ENTITYPERSON goes into town')
holmes_manager.start_chatbot_mode_console()
เยอรมัน:
holmes_manager.register_search_phrase('Ein ENTITYPER geht in die Stadt')
holmes_manager.start_chatbot_mode_console()
ตอนนี้คุณได้ลงทะเบียนความสนใจในคนที่เข้ามาในเมืองและสามารถป้อนประโยคที่เหมาะสมลงในคอนโซล:
ภาษาอังกฤษ:
Ready for input
I met Richard Hudson and John Doe last week. They didn't want to go into town.
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'John Doe'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
เยอรมัน:
Ready for input
Letzte Woche sah ich Richard Hudson und Max Mustermann. Sie wollten nicht mehr in die Stadt gehen.
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Max Mustermann'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
ในแต่ละสองภาษาตัวอย่างสุดท้ายนี้แสดงให้เห็นถึงคุณสมบัติเพิ่มเติมของโฮล์มส์:
สำหรับตัวอย่างเพิ่มเติมโปรดดูส่วนที่ 5
กลยุทธ์ต่อไปนี้ถูกนำไปใช้กับโมดูล Python หนึ่งโมดูลต่อกลยุทธ์ แม้ว่าไลบรารีมาตรฐานไม่สนับสนุนการเพิ่มกลยุทธ์ bespoke ผ่านคลาสผู้จัดการ แต่ก็ค่อนข้างง่ายสำหรับทุกคนที่มีทักษะการเขียนโปรแกรม Python เพื่อเปลี่ยนรหัสเพื่อเปิดใช้งานสิ่งนี้
word_match.type=='direct' )การจับคู่โดยตรงระหว่างคำศัพท์การค้นหาและคำเอกสารจะทำงานอยู่เสมอ กลยุทธ์ส่วนใหญ่ขึ้นอยู่กับการจับคู่รูปแบบของคำศัพท์เช่นการจับคู่การ ซื้อ ภาษาอังกฤษและ เด็ก ที่ ซื้อ และ เด็ก ๆ steigen เยอรมันและ ใจดี กับ Stieg และ Kinder อย่างไรก็ตามเพื่อเพิ่มโอกาสในการจับคู่โดยตรงเมื่อ Parser ส่งแบบฟอร์ม STEM ที่ไม่ถูกต้องสำหรับคำว่ารูปแบบข้อความดิบของทั้งวลีการค้นหาและคำเอกสารจะถูกนำมาพิจารณาในระหว่างการจับคู่โดยตรง
word_match.type=='derivation' ) การจับคู่ที่ได้มาจากการสืบทอดนั้นเกี่ยวข้องกับคำที่แตกต่าง แต่เกี่ยวข้องซึ่งมักจะเป็นของคลาสคำที่แตกต่างกันเช่น การประเมิน และ การประเมิน ภาษาอังกฤษ, German Jagen และ Jagd มันใช้งานได้โดยค่าเริ่มต้น แต่สามารถปิดได้โดยใช้พารามิเตอร์ analyze_derivational_morphology ซึ่งตั้งค่าเมื่อตั้งค่าคลาสผู้จัดการ
word_match.type=='entity' )การจับคู่เอนทิตีที่ตั้งชื่อนั้นเปิดใช้งานโดยการใส่ตัวระบุเอนทิตีพิเศษที่จุดที่ต้องการในวลีการค้นหาแทนคำนามเช่น
Entityperson เข้าสู่เมือง (ภาษาอังกฤษ)
Ein Entityper Geht ใน Die Stadt (เยอรมัน)
ตัวระบุเอนทิตีที่ได้รับการสนับสนุนขึ้นอยู่กับข้อมูลที่มีชื่อ-ข้อมูลที่จัดทำโดยโมเดล Spacy สำหรับแต่ละภาษา (คำอธิบายที่คัดลอกมาจากเอกสาร Spacy เวอร์ชันก่อนหน้า):
ภาษาอังกฤษ:
| ตัวระบุ | ความหมาย |
|---|---|
| entityNoun | วลีคำนามใด ๆ |
| ผู้ประกอบการ | ผู้คนรวมถึงตัวละคร |
| entitynorp | เชื้อชาติหรือกลุ่มศาสนาหรือการเมือง |
| entityFac | อาคารสนามบินทางหลวงสะพาน ฯลฯ |
| entityorg | บริษัท หน่วยงานสถาบัน ฯลฯ |
| entityGPE | ประเทศเมืองรัฐ |
| entityloc | สถานที่ที่ไม่ใช่ GPE, เทือกเขา, แหล่งน้ำ |
| สิ่งอำนวยความสะดวก | วัตถุยานพาหนะอาหาร ฯลฯ (ไม่ใช่บริการ) |
| EntityEvent | ตั้งชื่อพายุเฮอริเคนการต่อสู้สงครามกิจกรรมกีฬา ฯลฯ |
| Entitywork_of_art | ชื่อหนังสือเพลง ฯลฯ |
| entitylaw | เอกสารชื่อที่ทำขึ้นเป็นกฎหมาย |
| entitylanguage | ภาษาที่มีชื่อใด ๆ |
| entityDate | วันที่หรือช่วงเวลาที่แน่นอนหรือรอบระยะเวลา |
| entitytime | ครั้งเล็กกว่าหนึ่งเท่า |
| เอนทิตีเปอร์ | เปอร์เซ็นต์รวมถึง "%" |
| สิ่งของ | ค่าเงินรวมถึงหน่วย |
| ความเป็นมิตร | การวัดตามน้ำหนักหรือระยะทาง |
| เกี่ยวกับเอนทิตี | "First", "Second" ฯลฯ |
| เกี่ยวกับสิ่งมีชีวิต | ตัวเลขที่ไม่ตกอยู่ภายใต้ประเภทอื่น |
เยอรมัน:
| ตัวระบุ | ความหมาย |
|---|---|
| entityNoun | วลีคำนามใด ๆ |
| สิ่งของ | บุคคลหรือครอบครัวที่มีชื่อ |
| entityloc | ชื่อของสถานที่ตั้งทางการเมืองหรือทางภูมิศาสตร์ (เมืองจังหวัดประเทศภูมิภาคระหว่างประเทศร่างกายน้ำภูเขา) |
| entityorg | ชื่อองค์กรรัฐบาลหรือองค์กรอื่น ๆ |
| entitymisc | หน่วยงานเบ็ดเตล็ดเช่นเหตุการณ์เช่นเชื้อชาติผลิตภัณฑ์หรืองานศิลปะ |
เราได้เพิ่ม ENTITYNOUN ให้กับตัวระบุเอนทิตีของแท้ เมื่อตรงกับวลีคำนามใด ๆ มันจะทำงานในลักษณะที่คล้ายกันกับคำสรรพนามทั่วไป ความแตกต่างคือ ENTITYNOUN ต้องจับคู่วลีคำนามเฉพาะภายในเอกสารและวลีคำนามนี้จะถูกแยกออกมาและพร้อมสำหรับการประมวลผลเพิ่มเติม ENTITYNOUN ไม่ได้รับการสนับสนุนภายในกรณีการใช้งานการจับคู่หัวข้อ
word_match.type=='ontology' )อภิปรัชญาช่วยให้ผู้ใช้สามารถกำหนดความสัมพันธ์ระหว่างคำที่นำมาพิจารณาเมื่อจับคู่เอกสารเพื่อค้นหาวลี ประเภทความสัมพันธ์ที่เกี่ยวข้องทั้งสามคือ hyponyms (บางสิ่งบางอย่างเป็นชนิดย่อยของบางสิ่งบางอย่าง), คำพ้องความหมาย (บางสิ่งบางอย่างหมายถึงบางสิ่งบางอย่าง) และ บุคคลที่มีชื่อ (บางสิ่งบางอย่างเป็นตัวอย่างที่เฉพาะเจาะจงของบางสิ่ง) สามประเภทความสัมพันธ์ได้รับการยกตัวอย่างในรูปที่ 1:
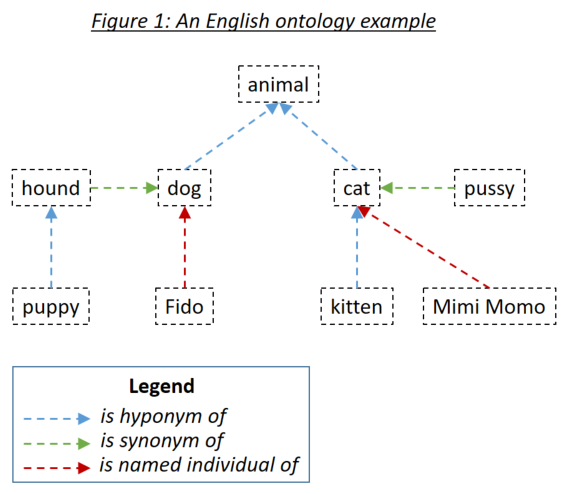
Ontologies ถูกกำหนดให้เป็น Holmes โดยใช้ Owl Ontology Standard Serialized โดยใช้ RDF/XML ontologies ดังกล่าวสามารถสร้างได้ด้วยเครื่องมือที่หลากหลาย สำหรับตัวอย่างและการทดสอบของโฮล์มส์ใช้โปรตีเออร์เครื่องมือฟรี ขอแนะนำให้คุณใช้ Protege ทั้งสองเพื่อกำหนด ontologies ของคุณเองและเพื่อเรียกดู ontologies ที่จัดส่งด้วยตัวอย่างและการทดสอบ เมื่อบันทึก ontology ภายใต้ protege โปรดเลือก RDF/XML เป็นรูปแบบ Protege กำหนดฉลากมาตรฐานสำหรับ hyponym คำพ้องความหมายและความสัมพันธ์ระหว่างบุคคลที่ Holmes เข้าใจว่าเป็นค่าเริ่มต้น แต่ก็สามารถแทนที่ได้
รายการอภิปรัชญาถูกกำหนดโดยใช้ตัวระบุทรัพยากรสากล (IRI) เช่น http://www.semanticweb.org/hudsonr/ontologies/2019/0/animals#dog โฮล์มส์ใช้ส่วนสุดท้ายสำหรับการจับคู่เท่านั้นซึ่งอนุญาตให้มีคำ homonyms (คำที่มีรูปแบบเดียวกัน แต่มีความหมายหลายอย่าง) ที่จะกำหนดไว้ที่จุดหลายจุดในต้นไม้ออนโทโลจี
การจับคู่ที่ใช้อภิปรัชญาให้ผลลัพธ์ที่ดีที่สุดกับโฮล์มส์เมื่อมีการใช้อภิปรัชญาขนาดเล็กที่ถูกสร้างขึ้นสำหรับโดเมนวิชาเฉพาะและกรณีการใช้งาน ตัวอย่างเช่นหากคุณใช้ chatbot สำหรับกรณีการใช้ประกันภัยอาคารคุณควรสร้างอภิปรัชญาขนาดเล็กที่จับคำศัพท์และความสัมพันธ์ภายในโดเมนนั้น ในทางกลับกันไม่แนะนำให้ใช้ ontologies ขนาดใหญ่ที่สร้างขึ้นสำหรับทุกโดเมนภายในภาษาทั้งหมดเช่น WordNet นี่เป็นเพราะคำว่าและความสัมพันธ์มากมายที่ใช้ในโดเมนเรื่องแคบ ๆ เท่านั้นที่จะนำไปสู่การจับคู่ที่ไม่ถูกต้องจำนวนมาก สำหรับกรณีการใช้งานทั่วไปการจับคู่แบบฝังจะมีแนวโน้มที่จะให้ผลลัพธ์ที่ดีขึ้น
แต่ละคำในภววิทยาถือได้ว่าเป็นหัวโจกของทรีที่ประกอบด้วย hyponyms คำพ้องความหมายและบุคคลที่มีชื่อ, hyponyms คำพ้องความหมายและชื่อบุคคลและอื่น ๆ ด้วยอภิปรัชญาที่ตั้งอยู่ในรูปแบบมาตรฐานที่เหมาะสมสำหรับกรณีการใช้ chatbot และการสกัดโครงสร้างคำในวลีการค้นหาโฮล์มส์ตรงกับคำในเอกสารหากคำเอกสารอยู่ในทรีย่อยของคำวลีการค้นหา ontology ในรูปที่ 1 กำหนดให้โฮล์มส์นอกเหนือจากกลยุทธ์การจับคู่โดยตรงซึ่งจะตรงกับแต่ละคำกับตัวเองชุดค่าผสมต่อไปนี้จะตรงกัน:
คำกริยาวลีภาษาอังกฤษเช่น Eat Up และคำกริยาที่แยกได้ภาษาเยอรมันเช่น Aufessen จะต้องถูกกำหนดเป็นรายการเดียวภายใน ontologies เมื่อโฮล์มส์วิเคราะห์ข้อความและพบคำกริยาดังกล่าวคำกริยาหลักและอนุภาคจะถูกรวมเข้ากับคำตรรกะเดียวที่สามารถจับคู่ได้ผ่านทางอภิปรัชญา ซึ่งหมายความว่า การกิน ภายในข้อความจะตรงกับทรีย่อยของ การกิน ภายใน ontology แต่ไม่ใช่ทรีทรีของ การกิน ภายใน ontology
หากการจับคู่ที่ได้รับมานั้นมีการใช้งานจะถูกนำมาพิจารณาทั้งสองด้านของการจับคู่ที่มีศักยภาพในการจับคู่ ontology ตัวอย่างเช่นหาก การเปลี่ยนแปลง และ แก้ไข ถูกกำหนดเป็นคำพ้องในอภิปรัชญา การเปลี่ยนแปลง และ การแก้ไข จะตรงกับซึ่งกันและกัน
ในสถานการณ์ที่การค้นหาประโยคที่เกี่ยวข้องมีความสำคัญมากกว่าการสร้างความมั่นใจในการติดต่อเชิงตรรกะของเอกสารที่ตรงกันกับวลีค้นหามันอาจเหมาะสมที่จะระบุ การจับคู่แบบสมมาตร เมื่อกำหนด ontology แนะนำให้จับคู่แบบสมมาตรสำหรับกรณีการใช้งานการจับคู่หัวข้อ แต่ไม่น่าจะเหมาะสมสำหรับกรณีการใช้ chatbot หรือการสกัดโครงสร้าง หมายความว่าความสัมพันธ์ของ Hypernym (ย้อนกลับ hyponym) ถูกนำมาพิจารณาเช่นเดียวกับความสัมพันธ์ hyponym และคำพ้องความหมายเมื่อจับคู่ดังนั้นนำไปสู่ความสัมพันธ์ที่สมมาตรมากขึ้นระหว่างเอกสารและวลีค้นหา กฎสำคัญที่ใช้เมื่อจับคู่ผ่านอภิปรัชญาแบบสมมาตรคือเส้นทางการจับคู่อาจไม่มีความสัมพันธ์ Hypernym และ Hyponym นั่นคือคุณไม่สามารถกลับไปหาตัวเองได้ ontology ข้างต้นกำหนดเป็น symmetric ชุดค่าผสมต่อไปนี้จะตรงกัน:
ในกรณีการจำแนกประเภทเอกสารภายใต้การใช้งานสามารถใช้ ontologies สองแบบแยกกันได้:
ontology การจับคู่โครงสร้าง ใช้เพื่อวิเคราะห์เนื้อหาของเอกสารการฝึกอบรมและการทดสอบ แต่ละคำจากเอกสารที่พบใน ontology จะถูกแทนที่ด้วยบรรพบุรุษ Hypernym ทั่วไปที่สุด มันเป็นสิ่งสำคัญที่จะต้องตระหนักว่าอภิปรัชญามีแนวโน้มที่จะทำงานกับการจับคู่โครงสร้างสำหรับการจำแนกเอกสารภายใต้การดูแลหากมันถูกสร้างขึ้นเพื่อวัตถุประสงค์โดยเฉพาะ: อภิปรัชญาดังกล่าวควรประกอบด้วยต้นไม้แยกต่างหากที่แสดงถึงคลาสหลักของวัตถุในเอกสารที่จะจัดประเภท ในตัวอย่าง ontology ที่แสดงข้างต้นคำทั้งหมดใน ontology จะถูกแทนที่ด้วย สัตว์ ; ในกรณีที่รุนแรงด้วยอภิปรัชญาสไตล์ Wordnet คำนามทั้งหมดจะจบลงด้วยการถูกแทนที่ด้วย สิ่งต่าง ๆ ซึ่งไม่ใช่ผลลัพธ์ที่พึงประสงค์!
อภิปรัชญาการจำแนก ประเภท ใช้เพื่อจับภาพความสัมพันธ์ระหว่างฉลากการจำแนกประเภท: เอกสารมีการจำแนกประเภทบางอย่างหมายความว่ามันยังมีการจำแนกประเภทใด ๆ ที่มีการแบ่งย่อยที่เป็นของการจำแนกประเภท คำพ้องความหมายควรใช้เท่าที่จำเป็นหากในการจำแนก ontologies เพราะพวกเขาเพิ่มความซับซ้อนของเครือข่ายประสาทโดยไม่เพิ่มค่าใด ๆ และถึงแม้ว่ามันจะเป็นไปได้ทางเทคนิคในการตั้งค่าอภิปรัชญาการจำแนกประเภทเพื่อใช้การจับคู่แบบสมมาตร แต่ก็ไม่มีเหตุผลที่สมเหตุสมผลในการทำเช่นนั้น โปรดทราบว่าฉลากภายในอภิปรัชญาการจำแนกประเภทที่ไม่ได้กำหนดโดยตรงว่าเป็นฉลากของเอกสารการฝึกอบรมใด ๆ จะต้องลงทะเบียนโดยเฉพาะโดยใช้วิธีการ SupervisedTopicTrainingBasis.register_additional_classification_label() หากต้องคำนึงถึงเมื่อฝึกอบรม
word_match.type=='embedding' )Spacy นำเสนอ การฝังคำ : การเรียนรู้เชิงตัวเลขที่สร้างจากเครื่องจักรที่สร้างขึ้นจากการเรียนรู้ของคำที่จับบริบทที่แต่ละคำมีแนวโน้มที่จะเกิดขึ้น คำสองคำที่มีความหมายคล้ายกันมีแนวโน้มที่จะเกิดขึ้นกับการฝังคำที่อยู่ใกล้กันและ Spacy สามารถวัด ความคล้ายคลึงกันของโคไซน์ ระหว่างการฝังของสองคำใด ๆ ที่แสดงเป็นทศนิยมระหว่าง 0.0 (ไม่มีความคล้ายคลึงกัน) และ 1.0 (คำเดียวกัน) เนื่องจาก สุนัข และ แมว มีแนวโน้มที่จะปรากฏในบริบทที่คล้ายกันพวกเขามีความคล้ายคลึงกัน 0.80; สุนัข และ ม้า มีความเหมือนกันน้อยกว่าและมีความคล้ายคลึงกัน 0.62; และ สุนัข และ เหล็ก มีความคล้ายคลึงกันเพียง 0.25 การจับคู่แบบฝังจะเปิดใช้งานเฉพาะคำนามคำคุณศัพท์และคำวิเศษณ์เนื่องจากผลลัพธ์ที่ได้รับการพบว่าไม่น่าพอใจกับคลาสคำอื่น ๆ
เป็นสิ่งสำคัญที่จะต้องเข้าใจว่าความจริงที่ว่าคำสองคำที่มีการฝังตัวที่คล้ายกันไม่ได้หมายความถึงความสัมพันธ์เชิงตรรกะแบบเดียวกันระหว่างทั้งสองเช่นเดียวกับเมื่อใช้การจับคู่ตามธรรมชาติ: ตัวอย่างเช่นความจริงที่ว่า สุนัข และ แมว มีการฝังตัวที่คล้ายกันหมายความว่าสุนัขชนิดหนึ่งเป็นแมวชนิดหนึ่ง ไม่ว่าการจับคู่แบบฝังที่ใช้นั้นเป็นตัวเลือกที่เหมาะสมหรือไม่นั้นขึ้นอยู่กับกรณีการใช้งานการใช้งาน
สำหรับ chatbot การสกัดโครงสร้างและกรณีการจำแนกประเภทเอกสารภายใต้การดูแลโฮล์มส์ใช้ประโยชน์จากความคล้ายคลึงกันแบบฝังคำโดยใช้พารามิเตอร์ overall_similarity_threshold ที่กำหนดไว้ทั่วโลกในคลาสผู้จัดการ ตรวจพบการจับคู่ระหว่างวลีการค้นหาและโครงสร้างภายในเอกสารเมื่อใดก็ตามที่ค่าเฉลี่ยเรขาคณิตของความคล้ายคลึงกันระหว่างคู่คำที่เกี่ยวข้องแต่ละคำจะมากกว่าเกณฑ์นี้ สัญชาตญาณที่อยู่เบื้องหลังเทคนิคนี้คือที่วลีการค้นหาที่มีคำศัพท์หกคำตรงกับโครงสร้างเอกสารที่ห้าคำเหล่านี้ตรงกับอย่างแน่นอนและมีเพียงหนึ่งเดียวที่สอดคล้องกันผ่านการฝังความคล้ายคลึงกันที่ควรจะตรงกับคำที่หกนี้น้อยกว่าเมื่อคำที่จับคู่กันเพียงสามคำ
การจับคู่วลีการค้นหากับเอกสารเริ่มต้นด้วยการค้นหาคำในเอกสารที่ตรงกับคำที่รูท (หัวไวยากรณ์) ของวลีการค้นหา โฮล์มส์ตรวจสอบโครงสร้างรอบ ๆ คำเอกสารที่จับคู่เหล่านี้แต่ละคำเพื่อตรวจสอบว่าโครงสร้างเอกสารตรงกับโครงสร้างวลีการค้นหาอย่างครบถ้วนหรือไม่ คำเอกสารที่ตรงกับคำศัพท์วลีการค้นหามักจะพบโดยใช้ดัชนี อย่างไรก็ตามหากต้องคำนึงถึงการฝังตัวเมื่อค้นหาคำเอกสารที่ตรงกับคำศัพท์การค้นหาคำศัพท์ ทุก คำใน ทุก เอกสารที่มีคลาสคำที่ถูกต้องจะต้องเปรียบเทียบกับความคล้ายคลึงกับคำศัพท์วลีรูท สิ่งนี้มีประสิทธิภาพที่เห็นได้ชัดเจนมากซึ่งทำให้กรณีการใช้งานทั้งหมดยกเว้นกรณีการใช้ chatbot ที่ไม่สามารถใช้งานได้เป็นหลัก
เพื่อหลีกเลี่ยงประสิทธิภาพที่ไม่จำเป็นโดยทั่วไปซึ่งเป็นผลมาจากการจับคู่การจับคู่คำศัพท์การค้นหาคำศัพท์รูทมันถูกควบคุมแยกต่างหากจากการจับคู่แบบฝังโดยทั่วไปโดยใช้พารามิเตอร์ embedding_based_matching_on_root_words ซึ่งตั้งค่าเมื่อสร้างอินสแตนซ์คลาสผู้จัดการ คุณควรที่จะปิดการตั้งค่านี้ปิด (ค่า False ) สำหรับกรณีการใช้งานส่วนใหญ่
ทั้งโดย overall_similarity_threshold _similarity_threshold และพารามิเตอร์ embedding_based_matching_on_root_words มีผลกระทบใด ๆ ต่อกรณีการใช้งานการจับคู่หัวข้อ ที่นี่เกณฑ์การฝังระดับความคล้ายคลึงกันถูกตั้งค่าโดยใช้ word_embedding_match_threshold และ initial_question_word_embedding_match_threshold พารามิเตอร์เมื่อเรียกฟังก์ชั่น topic_match_documents_against บนคลาสผู้จัดการ
word_match.type=='entity_embedding' ) การจับคู่ที่มีชื่อ-embedding ได้รับระหว่างคำที่ค้นหาเอกสารที่มีฉลากเอนทิตีบางอย่างและวลีการค้นหาหรือคำสืบค้นเอกสารที่มีการฝังมีความคล้ายคลึงกับความหมายพื้นฐานของฉลากเอนทิตีนั้นเช่นคำ ว่า บุคคล ในวลีการค้นหามีคำที่คล้ายกัน โปรดทราบว่าการจับคู่แบบอิง embedding ชื่อชื่อนั้นไม่เคยทำงานกับคำรูทโดยไม่คำนึงถึงการตั้งค่า embedding_based_matching_on_root_words
word_match.type=='question' )การจับคู่คำคำถามเริ่มต้นใช้งานเฉพาะในระหว่างการจับคู่หัวข้อ คำคำถามเริ่มต้นในวลีแบบสอบถามจับคู่เอนทิตีในเอกสารที่ค้นหาซึ่งแสดงถึงคำตอบที่อาจเกิดขึ้นกับคำถามเช่น เมื่อ เปรียบเทียบวลีแบบสอบถาม เมื่อปีเตอร์มีอาหารเช้า กับวลีค้นหาเอกสาร Peter ทานอาหารเช้า เวลา 8.00 น .
การจับคู่คำคำถามเริ่มต้นถูกเปิดและปิดโดยใช้พารามิเตอร์ initial_question_word_behaviour _question_word_behaviour เมื่อเรียกฟังก์ชัน topic_match_documents_against ในคลาส Manager It is only likely to be useful when topic matching is being performed in an interactive setting where the user enters short query phrases, as opposed to when it is being used to find documents on a similar topic to an pre-existing query document: initial question words are only processed at the beginning of the first sentence of the query phrase or query document.
Linguistically speaking, if a query phrase consists of a complex question with several elements dependent on the main verb, a finding in a searched document is only an 'answer' if contains matches to all these elements. Because recall is typically more important than precision when performing topic matching with interactive query phrases, however, Holmes will match an initial question word to a searched-document phrase wherever they correspond semantically (eg wherever when corresponds to a temporal adverbial phrase) and each depend on verbs that themselves match at the word level. One possible strategy to filter out 'incomplete answers' would be to calculate the maximum possible score for a query phrase and reject topic matches that score below a threshold scaled to this maximum.
Before Holmes analyses a searched document or query document, coreference resolution is performed using the Coreferee library running on top of spaCy. This means that situations are recognised where pronouns and nouns that are located near one another within a text refer to the same entities. The information from one mention can then be applied to the analysis of further mentions:
I saw a big dog . It was chasing a cat.
I saw a big dog . The dog was chasing a cat.
Coreferee also detects situations where a noun refers back to a named entity:
We discussed AstraZeneca . The company had given us permission to publish this library under the MIT license.
If this example were to match the search phrase A company gives permission to publish something , the coreference information that the company under discussion is AstraZeneca is clearly relevant and worth extracting in addition to the word(s) directly matched to the search phrase. Such information is captured in the word_match.extracted_word field.
The concept of search phrases has already been introduced and is relevant to the chatbot use case, the structural extraction use case and to preselection within the supervised document classification use case.
It is crucial to understand that the tips and limitations set out in Section 4 do not apply in any way to query phrases in topic matching. If you are using Holmes for topic matching only, you can completely ignore this section!
Structural matching between search phrases and documents is not symmetric: there are many situations in which sentence X as a search phrase would match sentence Y within a document but where the converse would not be true. Although Holmes does its best to understand any search phrases, the results are better when the user writing them follows certain patterns and tendencies, and getting to grips with these patterns and tendencies is the key to using the relevant features of Holmes successfully.
Holmes distinguishes between: lexical words like dog , chase and cat (English) or Hund , jagen and Katze (German) in the initial example above; and grammatical words like a (English) or ein and eine (German) in the initial example above. Only lexical words match words in documents, but grammatical words still play a crucial role within a search phrase: they enable Holmes to understand it.
Dog chase cat (English)
Hund jagen Katze (German)
contain the same lexical words as the search phrases in the initial example above, but as they are not grammatical sentences Holmes is liable to misunderstand them if they are used as search phrases. This is a major difference between Holmes search phrases and the search phrases you use instinctively with standard search engines like Google, and it can take some getting used to.
A search phrase need not contain a verb:
ENTITYPERSON (English)
A big dog (English)
Interest in fishing (English)
ENTITYPER (German)
Ein großer Hund (German)
Interesse am Angeln (German)
are all perfectly valid and potentially useful search phrases.
Where a verb is present, however, Holmes delivers the best results when the verb is in the present active , as chases and jagt are in the initial example above. This gives Holmes the best chance of understanding the relationship correctly and of matching the widest range of document structures that share the target meaning.
Sometimes you may only wish to extract the object of a verb. For example, you might want to find sentences that are discussing a cat being chased regardless of who is doing the chasing. In order to avoid a search phrase containing a passive expression like
A cat is chased (English)
Eine Katze wird gejagt (German)
you can use a generic pronoun . This is a word that Holmes treats like a grammatical word in that it is not matched to documents; its sole purpose is to help the user form a grammatically optimal search phrase in the present active. Recognised generic pronouns are English something , somebody and someone and German jemand (and inflected forms of jemand ) and etwas : Holmes treats them all as equivalent. Using generic pronouns, the passive search phrases above could be re-expressed as
Somebody chases a cat (English)
Jemand jagt eine Katze (German).
Experience shows that different prepositions are often used with the same meaning in equivalent phrases and that this can prevent search phrases from matching where one would intuitively expect it. For example, the search phrases
Somebody is at the market (English)
Jemand ist auf dem Marktplatz (German)
would fail to match the document phrases
Richard was in the market (English)
Richard war am Marktplatz (German)
The best way of solving this problem is to define the prepositions in question as synonyms in an ontology.
The following types of structures are prohibited in search phrases and result in Python user-defined errors:
A dog chases a cat. A cat chases a dog (English)
Ein Hund jagt eine Katze. Eine Katze jagt einen Hund (German)
Each clause must be separated out into its own search phrase and registered individually.
A dog does not chase a cat. (ภาษาอังกฤษ)
Ein Hund jagt keine Katze. (German)
Negative expressions are recognised as such in documents and the generated matches marked as negative; allowing search phrases themselves to be negative would overcomplicate the library without offering any benefits.
A dog and a lion chase a cat. (ภาษาอังกฤษ)
Ein Hund und ein Löwe jagen eine Katze. (German)
Wherever conjunction occurs in documents, Holmes distributes the information among multiple matches as explained above. In the unlikely event that there should be a requirement to capture conjunction explicitly when matching, this could be achieved by using the Manager.match() function and looking for situations where the document token objects are shared by multiple match objects.
The (English)
Der (German)
A search phrase cannot be processed if it does not contain any words that can be matched to documents.
A dog chases a cat and he chases a mouse (English)
Ein Hund jagt eine Katze und er jagt eine Maus (German)
Pronouns that corefer with nouns elsewhere in the search phrase are not permitted as this would overcomplicate the library without offering any benefits.
The following types of structures are strongly discouraged in search phrases:
Dog chase cat (English)
Hund jagen Katze (German)
Although these will sometimes work, the results will be better if search phrases are expressed grammatically.
A cat is chased by a dog (English)
A dog will have chased a cat (English)
Eine Katze wird durch einen Hund gejagt (German)
Ein Hund wird eine Katze gejagt haben (German)
Although these will sometimes work, the results will be better if verbs in search phrases are expressed in the present active.
Who chases the cat? (ภาษาอังกฤษ)
Wer jagt die Katze? (German)
Although questions are supported as query phrases in the topic matching use case, they are not appropriate as search phrases. Questions should be re-phrased as statements, in this case
Something chases the cat (English)
Etwas jagt die Katze (German).
Informationsextraktion (German)
Ein Stadtmittetreffen (German)
The internal structure of German compound words is analysed within searched documents as well as within query phrases in the topic matching use case, but not within search phrases. In search phrases, compound words should be reexpressed as genitive constructions even in cases where this does not strictly capture their meaning:
Extraktion der Information (German)
Ein Treffen der Stadtmitte (German)
The following types of structures should be used with caution in search phrases:
A fierce dog chases a scared cat on the way to the theatre (English)
Ein kämpferischer Hund jagt eine verängstigte Katze auf dem Weg ins Theater (German)
Holmes can handle any level of complexity within search phrases, but the more complex a structure, the less likely it becomes that a document sentence will match it. If it is really necessary to match such complex relationships with search phrases rather than with topic matching, they are typically better extracted by splitting the search phrase up, eg
A fierce dog (English)
A scared cat (English)
A dog chases a cat (English)
Something chases something on the way to the theatre (English)
Ein kämpferischer Hund (German)
Eine verängstigte Katze (German)
Ein Hund jagt eine Katze (German)
Etwas jagt etwas auf dem Weg ins Theater (German)
Correlations between the resulting matches can then be established by matching via the Manager.match() function and looking for situations where the document token objects are shared across multiple match objects.
One possible exception to this piece of advice is when embedding-based matching is active. Because whether or not each word in a search phrase matches then depends on whether or not other words in the same search phrase have been matched, large, complex search phrases can sometimes yield results that a combination of smaller, simpler search phrases would not.
The chasing of a cat (English)
Die Jagd einer Katze (German)
These will often work, but it is generally better practice to use verbal search phrases like
Something chases a cat (English)
Etwas jagt eine Katze (German)
and to allow the corresponding nominal phrases to be matched via derivation-based matching.
The chatbot use case has already been introduced: a predefined set of search phrases is used to extract information from phrases entered interactively by an end user, which in this use case act as the documents.
The Holmes source code ships with two examples demonstrating the chatbot use case, one for each language, with predefined ontologies. Having cloned the source code and installed the Holmes library, navigate to the /examples directory and type the following (Linux):
ภาษาอังกฤษ:
python3 example_chatbot_EN_insurance.py
German:
python3 example_chatbot_DE_insurance.py
or click on the files in Windows Explorer (Windows).
Holmes matches syntactically distinct structures that are semantically equivalent, ie that share the same meaning. In a real chatbot use case, users will typically enter equivalent information with phrases that are semantically distinct as well, ie that have different meanings. Because the effort involved in registering a search phrase is barely greater than the time it takes to type it in, it makes sense to register a large number of search phrases for each relationship you are trying to extract: essentially all ways people have been observed to express the information you are interested in or all ways you can imagine somebody might express the information you are interested in . To assist this, search phrases can be registered with labels that do not need to be unique: a label can then be used to express the relationship an entire group of search phrases is designed to extract. Note that when many search phrases have been defined to extract the same relationship, a single user entry is likely to be sometimes matched by multiple search phrases. This must be handled appropriately by the calling application.
One obvious weakness of Holmes in the chatbot setting is its sensitivity to correct spelling and, to a lesser extent, to correct grammar. Strategies for mitigating this weakness include:
The structural extraction use case uses structural matching in the same way as the chatbot use case, and many of the same comments and tips apply to it. The principal differences are that pre-existing and often lengthy documents are scanned rather than text snippets entered ad-hoc by the user, and that the returned match objects are not used to drive a dialog flow; they are examined solely to extract and store structured information.
Code for performing structural extraction would typically perform the following tasks:
Manager.register_search_phrase() several times to define a number of search phrases specifying the information to be extracted.Manager.parse_and_register_document() several times to load a number of documents within which to search.Manager.match() to perform the matching.The topic matching use case matches a query document , or alternatively a query phrase entered ad-hoc by the user, against a set of documents pre-loaded into memory. The aim is to find the passages in the documents whose topic most closely corresponds to the topic of the query document; the output is a ordered list of passages scored according to topic similarity. Additionally, if a query phrase contains an initial question word, the output will contain potential answers to the question.
Topic matching queries may contain generic pronouns and named-entity identifiers just like search phrases, although the ENTITYNOUN token is not supported. However, an important difference from search phrases is that the topic matching use case places no restrictions on the grammatical structures permissible within the query document.
In addition to the Holmes demonstration website, the Holmes source code ships with three examples demonstrating the topic matching use case with an English literature corpus, a German literature corpus and a German legal corpus respectively. Users are encouraged to run these to get a feel for how they work.
Topic matching uses a variety of strategies to find text passages that are relevant to the query. These include resource-hungry procedures like investigating semantic relationships and comparing embeddings. Because applying these across the board would prevent topic matching from scaling, Holmes only attempts them for specific areas of the text that less resource-intensive strategies have already marked as looking promising. This and the other interior workings of topic matching are explained here.
In the supervised document classification use case, a classifier is trained with a number of documents that are each pre-labelled with a classification. The trained classifier then assigns one or more labels to new documents according to what each new document is about. As explained here, ontologies can be used both to enrichen the comparison of the content of the various documents and to capture implication relationships between classification labels.
A classifier makes use of a neural network (a multilayer perceptron) whose topology can either be determined automatically by Holmes or specified explicitly by the user. With a large number of training documents, the automatically determined topology can easily exhaust the memory available on a typical machine; if there is no opportunity to scale up the memory, this problem can be remedied by specifying a smaller number of hidden layers or a smaller number of nodes in one or more of the layers.
A trained document classification model retains no references to its training data. This is an advantage from a data protection viewpoint, although it cannot presently be guaranteed that models will not contain individual personal or company names.
A typical problem with the execution of many document classification use cases is that a new classification label is added when the system is already live but that there are initially no examples of this new classification with which to train a new model. The best course of action in such a situation is to define search phrases which preselect the more obvious documents with the new classification using structural matching. Those documents that are not preselected as having the new classification label are then passed to the existing, previously trained classifier in the normal way. When enough documents exemplifying the new classification have accumulated in the system, the model can be retrained and the preselection search phrases removed.
Holmes ships with an example script demonstrating supervised document classification for English with the BBC Documents dataset. The script downloads the documents (for this operation and for this operation alone, you will need to be online) and places them in a working directory. When training is complete, the script saves the model to the working directory. If the model file is found in the working directory on subsequent invocations of the script, the training phase is skipped and the script goes straight to the testing phase. This means that if it is wished to repeat the training phase, either the model has to be deleted from the working directory or a new working directory has to be specified to the script.
Having cloned the source code and installed the Holmes library, navigate to the /examples directory. Specify a working directory at the top of the example_supervised_topic_model_EN.py file, then type python3 example_supervised_topic_model_EN (Linux) or click on the script in Windows Explorer (Windows).
It is important to realise that Holmes learns to classify documents according to the words or semantic relationships they contain, taking any structural matching ontology into account in the process. For many classification tasks, this is exactly what is required; but there are tasks (eg author attribution according to the frequency of grammatical constructions typical for each author) where it is not. For the right task, Holmes achieves impressive results. For the BBC Documents benchmark processed by the example script, Holmes performs slightly better than benchmarks available online (see eg here) although the difference is probably too slight to be significant, especially given that the different training/test splits were used in each case: Holmes has been observed to learn models that predict the correct result between 96.9% and 98.7% of the time. The range is explained by the fact that the behaviour of the neural network is not fully deterministic.
The interior workings of supervised document classification are explained here.
Manager holmes_extractor.Manager(self, model, *, overall_similarity_threshold=1.0,
embedding_based_matching_on_root_words=False, ontology=None,
analyze_derivational_morphology=True, perform_coreference_resolution=None,
number_of_workers=None, verbose=False)
The facade class for the Holmes library.
Parameters:
model -- the name of the spaCy model, e.g. *en_core_web_trf*
overall_similarity_threshold -- the overall similarity threshold for embedding-based
matching. Defaults to *1.0*, which deactivates embedding-based matching. Note that this
parameter is not relevant for topic matching, where the thresholds for embedding-based
matching are set on the call to *topic_match_documents_against*.
embedding_based_matching_on_root_words -- determines whether or not embedding-based
matching should be attempted on search-phrase root tokens, which has a considerable
performance hit. Defaults to *False*. Note that this parameter is not relevant for topic
matching.
ontology -- an *Ontology* object. Defaults to *None* (no ontology).
analyze_derivational_morphology -- *True* if matching should be attempted between different
words from the same word family. Defaults to *True*.
perform_coreference_resolution -- *True* if coreference resolution should be taken into account
when matching. Defaults to *True*.
use_reverse_dependency_matching -- *True* if appropriate dependencies in documents can be
matched to dependencies in search phrases where the two dependencies point in opposite
directions. Defaults to *True*.
number_of_workers -- the number of worker processes to use, or *None* if the number of worker
processes should depend on the number of available cores. Defaults to *None*
verbose -- a boolean value specifying whether multiprocessing messages should be outputted to
the console. Defaults to *False*
Manager.register_serialized_document(self, serialized_document:bytes, label:str="") -> None
Parameters:
document -- a preparsed Holmes document.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.register_serialized_documents(self, document_dictionary:dict[str, bytes]) -> None
Note that this function is the most efficient way of loading documents.
Parameters:
document_dictionary -- a dictionary from labels to serialized documents.
Manager.parse_and_register_document(self, document_text:str, label:str='') -> None
Parameters:
document_text -- the raw document text.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.remove_document(self, label:str) -> None
Manager.remove_all_documents(self, labels_starting:str=None) -> None
Parameters:
labels_starting -- a string starting the labels of documents to be removed,
or 'None' if all documents are to be removed.
Manager.list_document_labels(self) -> List[str]
Returns a list of the labels of the currently registered documents.
Manager.serialize_document(self, label:str) -> Optional[bytes]
Returns a serialized representation of a Holmes document that can be
persisted to a file. If 'label' is not the label of a registered document,
'None' is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.get_document(self, label:str='') -> Optional[Doc]
Returns a Holmes document. If *label* is not the label of a registered document, *None*
is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.debug_document(self, label:str='') -> None
Outputs a debug representation for a loaded document.
Parameters:
label -- the label of the document to be serialized.
Manager.register_search_phrase(self, search_phrase_text:str, label:str=None) -> SearchPhrase
Registers and returns a new search phrase.
Parameters:
search_phrase_text -- the raw search phrase text.
label -- a label for the search phrase, which need not be unique.
If label==None, the assigned label defaults to the raw search phrase text.
Manager.remove_all_search_phrases_with_label(self, label:str) -> None
Manager.remove_all_search_phrases(self) -> None
Manager.list_search_phrase_labels(self) -> List[str]
Manager.match(self, search_phrase_text:str=None, document_text:str=None) -> List[Dict]
Matches search phrases to documents and returns the result as match dictionaries.
Parameters:
search_phrase_text -- a text from which to generate a search phrase, or 'None' if the
preloaded search phrases should be used for matching.
document_text -- a text from which to generate a document, or 'None' if the preloaded
documents should be used for matching.
topic_match_documents_against(self, text_to_match:str, *,
use_frequency_factor:bool=True,
maximum_activation_distance:int=75,
word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7,
relation_score:int=300,
reverse_only_relation_score:int=200,
single_word_score:int=50,
single_word_any_tag_score:int=20,
initial_question_word_answer_score:int=600,
initial_question_word_behaviour:str='process',
different_match_cutoff_score:int=15,
overlapping_relation_multiplier:float=1.5,
embedding_penalty:float=0.6,
ontology_penalty:float=0.9,
relation_matching_frequency_threshold:float=0.25,
embedding_matching_frequency_threshold:float=0.5,
sideways_match_extent:int=100,
only_one_result_per_document:bool=False,
number_of_results:int=10,
document_label_filter:str=None,
tied_result_quotient:float=0.9) -> List[Dict]:
Returns a list of dictionaries representing the results of a topic match between an entered text
and the loaded documents.
Properties:
text_to_match -- the text to match against the loaded documents.
use_frequency_factor -- *True* if scores should be multiplied by a factor between 0 and 1
expressing how rare the words matching each phraselet are in the corpus. Note that,
even if this parameter is set to *False*, the factors are still calculated as they are
required for determining which relation and embedding matches should be attempted.
maximum_activation_distance -- the number of words it takes for a previous phraselet
activation to reduce to zero when the library is reading through a document.
word_embedding_match_threshold -- the cosine similarity above which two words match where
the search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
relation_score -- the activation score added when a normal two-word relation is matched.
reverse_only_relation_score -- the activation score added when a two-word relation
is matched using a search phrase that can only be reverse-matched.
single_word_score -- the activation score added when a single noun is matched.
single_word_any_tag_score -- the activation score added when a single word is matched
that is not a noun.
initial_question_word_answer_score -- the activation score added when a question word is
matched to an potential answer phrase.
initial_question_word_behaviour -- 'process' if a question word in the sentence
constituent at the beginning of *text_to_match* is to be matched to document phrases
that answer it and to matching question words; 'exclusive' if only topic matches that
answer questions are to be permitted; 'ignore' if question words are to be ignored.
different_match_cutoff_score -- the activation threshold under which topic matches are
separated from one another. Note that the default value will probably be too low if
*use_frequency_factor* is set to *False*.
overlapping_relation_multiplier -- the value by which the activation score is multiplied
when two relations were matched and the matches involved a common document word.
embedding_penalty -- a value between 0 and 1 with which scores are multiplied when the
match involved an embedding. The result is additionally multiplied by the overall
similarity measure of the match.
ontology_penalty -- a value between 0 and 1 with which scores are multiplied for each
word match within a match that involved the ontology. For each such word match,
the score is multiplied by the value (abs(depth) + 1) times, so that the penalty is
higher for hyponyms and hypernyms than for synonyms and increases with the
depth distance.
relation_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches.
embedding_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches with
embedding-based matching on the second word.
sideways_match_extent -- the maximum number of words that may be incorporated into a
topic match either side of the word where the activation peaked.
only_one_result_per_document -- if 'True', prevents multiple results from being returned
for the same document.
number_of_results -- the number of topic match objects to return.
document_label_filter -- optionally, a string with which document labels must start to
be considered for inclusion in the results.
tied_result_quotient -- the quotient between a result and following results above which
the results are interpreted as tied.
Manager.get_supervised_topic_training_basis(self, *, classification_ontology:Ontology=None,
overlap_memory_size:int=10, oneshot:bool=True, match_all_words:bool=False,
verbose:bool=True) -> SupervisedTopicTrainingBasis:
Returns an object that is used to train and generate a model for the
supervised document classification use case.
Parameters:
classification_ontology -- an Ontology object incorporating relationships between
classification labels, or 'None' if no such ontology is to be used.
overlap_memory_size -- how many non-word phraselet matches to the left should be
checked for words in common with a current match.
oneshot -- whether the same word or relationship matched multiple times within a
single document should be counted once only (value 'True') or multiple times
(value 'False')
match_all_words -- whether all single words should be taken into account
(value 'True') or only single words with noun tags (value 'False')
verbose -- if 'True', information about training progress is outputted to the console.
Manager.deserialize_supervised_topic_classifier(self,
serialized_model:bytes, verbose:bool=False) -> SupervisedTopicClassifier:
Returns a classifier for the supervised document classification use case
that will use a supplied pre-trained model.
Parameters:
serialized_model -- the pre-trained model as returned from `SupervisedTopicClassifier.serialize_model()`.
verbose -- if 'True', information about matching is outputted to the console.
Manager.start_chatbot_mode_console(self)
Starts a chatbot mode console enabling the matching of pre-registered
search phrases to documents (chatbot entries) entered ad-hoc by the
user.
Manager.start_structural_search_mode_console(self)
Starts a structural extraction mode console enabling the matching of pre-registered
documents to search phrases entered ad-hoc by the user.
Manager.start_topic_matching_search_mode_console(self,
only_one_result_per_document:bool=False, word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7):
Starts a topic matching search mode console enabling the matching of pre-registered
documents to query phrases entered ad-hoc by the user.
Parameters:
only_one_result_per_document -- if 'True', prevents multiple topic match
results from being returned for the same document.
word_embedding_match_threshold -- the cosine similarity above which two words match where the
search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
Manager.close(self) -> None
Terminates the worker processes.
manager.nlp manager.nlp is the underlying spaCy Language object on which both Coreferee and Holmes have been registered as custom pipeline components. The most efficient way of parsing documents for use with Holmes is to call manager.nlp.pipe() . This yields an iterable of documents that can then be loaded into Holmes via manager.register_serialized_documents() .
The pipe() method has an argument n_process that specifies the number of processors to use. With _lg , _md and _sm spaCy models, there are some situations where it can make sense to specify a value other than 1 (the default). Note however that with transformer spaCy models ( _trf ) values other than 1 are not supported.
Ontology holmes_extractor.Ontology(self, ontology_path,
owl_class_type='http://www.w3.org/2002/07/owl#Class',
owl_individual_type='http://www.w3.org/2002/07/owl#NamedIndividual',
owl_type_link='http://www.w3.org/1999/02/22-rdf-syntax-ns#type',
owl_synonym_type='http://www.w3.org/2002/07/owl#equivalentClass',
owl_hyponym_type='http://www.w3.org/2000/01/rdf-schema#subClassOf',
symmetric_matching=False)
Loads information from an existing ontology and manages ontology
matching.
The ontology must follow the W3C OWL 2 standard. Search phrase words are
matched to hyponyms, synonyms and instances from within documents being
searched.
This class is designed for small ontologies that have been constructed
by hand for specific use cases. Where the aim is to model a large number
of semantic relationships, word embeddings are likely to offer
better results.
Holmes is not designed to support changes to a loaded ontology via direct
calls to the methods of this class. It is also not permitted to share a single instance
of this class between multiple Manager instances: instead, a separate Ontology instance
pointing to the same path should be created for each Manager.
Matching is case-insensitive.
Parameters:
ontology_path -- the path from where the ontology is to be loaded,
or a list of several such paths. See https://github.com/RDFLib/rdflib/.
owl_class_type -- optionally overrides the OWL 2 URL for types.
owl_individual_type -- optionally overrides the OWL 2 URL for individuals.
owl_type_link -- optionally overrides the RDF URL for types.
owl_synonym_type -- optionally overrides the OWL 2 URL for synonyms.
owl_hyponym_type -- optionally overrides the RDF URL for hyponyms.
symmetric_matching -- if 'True', means hypernym relationships are also taken into account.
SupervisedTopicTrainingBasis (returned from Manager.get_supervised_topic_training_basis() )Holder object for training documents and their classifications from which one or more SupervisedTopicModelTrainer objects can be derived. This class is NOT threadsafe.
SupervisedTopicTrainingBasis.parse_and_register_training_document(self, text:str, classification:str,
label:Optional[str]=None) -> None
Parses and registers a document to use for training.
Parameters:
text -- the document text
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_training_document(self, doc:Doc, classification:str,
label:Optional[str]=None) -> None
Registers a pre-parsed document to use for training.
Parameters:
doc -- the document
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_additional_classification_label(self, label:str) -> None
Register an additional classification label which no training document possesses explicitly
but that should be assigned to documents whose explicit labels are related to the
additional classification label via the classification ontology.
SupervisedTopicTrainingBasis.prepare(self) -> None
Matches the phraselets derived from the training documents against the training
documents to generate frequencies that also include combined labels, and examines the
explicit classification labels, the additional classification labels and the
classification ontology to derive classification implications.
Once this method has been called, the instance no longer accepts new training documents
or additional classification labels.
SupervisedTopicTrainingBasis.train(
self,
*,
minimum_occurrences: int = 4,
cv_threshold: float = 1.0,
learning_rate: float = 0.001,
batch_size: int = 5,
max_epochs: int = 200,
convergence_threshold: float = 0.0001,
hidden_layer_sizes: Optional[List[int]] = None,
shuffle: bool = True,
normalize: bool = True
) -> SupervisedTopicModelTrainer:
Trains a model based on the prepared state.
Parameters:
minimum_occurrences -- the minimum number of times a word or relationship has to
occur in the context of the same classification for the phraselet
to be accepted into the final model.
cv_threshold -- the minimum coefficient of variation with which a word or relationship has
to occur across the explicit classification labels for the phraselet to be
accepted into the final model.
learning_rate -- the learning rate for the Adam optimizer.
batch_size -- the number of documents in each training batch.
max_epochs -- the maximum number of training epochs.
convergence_threshold -- the threshold below which loss measurements after consecutive
epochs are regarded as equivalent. Training stops before 'max_epochs' is reached
if equivalent results are achieved after four consecutive epochs.
hidden_layer_sizes -- a list containing the number of neurons in each hidden layer, or
'None' if the topology should be determined automatically.
shuffle -- 'True' if documents should be shuffled during batching.
normalize -- 'True' if normalization should be applied to the loss function.
SupervisedTopicModelTrainer (returned from SupervisedTopicTrainingBasis.train() ) Worker object used to train and generate models. This object could be removed from the public interface ( SupervisedTopicTrainingBasis.train() could return a SupervisedTopicClassifier directly) but has been retained to facilitate testability.
This class is NOT threadsafe.
SupervisedTopicModelTrainer.classifier(self)
Returns a supervised topic classifier which contains no explicit references to the training data and that
can be serialized.
SupervisedTopicClassifier (returned from SupervisedTopicModelTrainer.classifier() and Manager.deserialize_supervised_topic_classifier() ))
SupervisedTopicClassifier.def parse_and_classify(self, text: str) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
text -- the text to parse and classify.
SupervisedTopicClassifier.classify(self, doc: Doc) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
doc -- the pre-parsed document to classify.
SupervisedTopicClassifier.serialize_model(self) -> str
Returns a serialized model that can be reloaded using
*Manager.deserialize_supervised_topic_classifier()*
Manager.match() A text-only representation of a match between a search phrase and a
document. The indexes refer to tokens.
Properties:
search_phrase_label -- the label of the search phrase.
search_phrase_text -- the text of the search phrase.
document -- the label of the document.
index_within_document -- the index of the match within the document.
sentences_within_document -- the raw text of the sentences within the document that matched.
negated -- 'True' if this match is negated.
uncertain -- 'True' if this match is uncertain.
involves_coreference -- 'True' if this match was found using coreference resolution.
overall_similarity_measure -- the overall similarity of the match, or
'1.0' if embedding-based matching was not involved in the match.
word_matches -- an array of dictionaries with the properties:
search_phrase_token_index -- the index of the token that matched from the search phrase.
search_phrase_word -- the string that matched from the search phrase.
document_token_index -- the index of the token that matched within the document.
first_document_token_index -- the index of the first token that matched within the document.
Identical to 'document_token_index' except where the match involves a multiword phrase.
last_document_token_index -- the index of the last token that matched within the document
(NOT one more than that index). Identical to 'document_token_index' except where the match
involves a multiword phrase.
structurally_matched_document_token_index -- the index of the token within the document that
structurally matched the search phrase token. Is either the same as 'document_token_index' or
is linked to 'document_token_index' within a coreference chain.
document_subword_index -- the index of the token subword that matched within the document, or
'None' if matching was not with a subword but with an entire token.
document_subword_containing_token_index -- the index of the document token that contained the
subword that matched, which may be different from 'document_token_index' in situations where a
word containing multiple subwords is split by hyphenation and a subword whose sense
contributes to a word is not overtly realised within that word.
document_word -- the string that matched from the document.
document_phrase -- the phrase headed by the word that matched from the document.
match_type -- 'direct', 'derivation', 'entity', 'embedding', 'ontology', 'entity_embedding'
or 'question'.
negated -- 'True' if this word match is negated.
uncertain -- 'True' if this word match is uncertain.
similarity_measure -- for types 'embedding' and 'entity_embedding', the similarity between the
two tokens, otherwise '1.0'.
involves_coreference -- 'True' if the word was matched using coreference resolution.
extracted_word -- within the coreference chain, the most specific term that corresponded to
the document_word.
depth -- the number of hyponym relationships linking 'search_phrase_word' and
'extracted_word', or '0' if ontology-based matching is not active. Can be negative
if symmetric matching is active.
explanation -- creates a human-readable explanation of the word match from the perspective of the
document word (e.g. to be used as a tooltip over it).
Manager.topic_match_documents_against() A text-only representation of a topic match between a search text and a document.
Properties:
document_label -- the label of the document.
text -- the document text that was matched.
text_to_match -- the search text.
rank -- a string representation of the scoring rank which can have the form e.g. '2=' in case of a tie.
index_within_document -- the index of the document token where the activation peaked.
subword_index -- the index of the subword within the document token where the activation peaked, or
'None' if the activation did not peak at a specific subword.
start_index -- the index of the first document token in the topic match.
end_index -- the index of the last document token in the topic match (NOT one more than that index).
sentences_start_index -- the token start index within the document of the sentence that contains
'start_index'
sentences_end_index -- the token end index within the document of the sentence that contains
'end_index' (NOT one more than that index).
sentences_character_start_index_in_document -- the character index of the first character of 'text'
within the document.
sentences_character_end_index_in_document -- one more than the character index of the last
character of 'text' within the document.
score -- the score
word_infos -- an array of arrays with the semantics:
[0] -- 'relative_start_index' -- the index of the first character in the word relative to
'sentences_character_start_index_in_document'.
[1] -- 'relative_end_index' -- one more than the index of the last character in the word
relative to 'sentences_character_start_index_in_document'.
[2] -- 'type' -- 'single' for a single-word match, 'relation' if within a relation match
involving two words, 'overlapping_relation' if within a relation match involving three
or more words.
[3] -- 'is_highest_activation' -- 'True' if this was the word at which the highest activation
score reported in 'score' was achieved, otherwise 'False'.
[4] -- 'explanation' -- a human-readable explanation of the word match from the perspective of
the document word (e.g. to be used as a tooltip over it).
answers -- an array of arrays with the semantics:
[0] -- the index of the first character of a potential answer to an initial question word.
[1] -- one more than the index of the last character of a potential answer to an initial question
word.
Earlier versions of Holmes could only be published under a restrictive license because of patent issues. As explained in the introduction, this is no longer the case thanks to the generosity of AstraZeneca: versions from 4.0.0 onwards are licensed under the MIT license.
The word-level matching and the high-level operation of structural matching between search-phrase and document subgraphs both work more or less as one would expect. What is perhaps more in need of further comment is the semantic analysis code subsumed in the parsing.py script as well as in the language_specific_rules.py script for each language.
SemanticAnalyzer is an abstract class that is subclassed for each language: at present by EnglishSemanticAnalyzer and GermanSemanticAnalyzer . These classes contain most of the semantic analysis code. SemanticMatchingHelper is a second abstract class, again with an concrete implementation for each language, that contains semantic analysis code that is required at matching time. Moving this out to a separate class family was necessary because, on operating systems that spawn processes rather than forking processes (eg Windows), SemanticMatchingHelper instances have to be serialized when the worker processes are created: this would not be possible for SemanticAnalyzer instances because not all spaCy models are serializable, and would also unnecessarily consume large amounts of memory.
At present, all functionality that is common to the two languages is realised in the two abstract parent classes. Especially because English and German are closely related languages, it is probable that functionality will need to be moved from the abstract parent classes to specific implementing children classes if and when new semantic analyzers are added for new languages.
The HolmesDictionary class is defined as a spaCy extension attribute that is accessed using the syntax token._.holmes . The most important information in the dictionary is a list of SemanticDependency objects. These are derived from the dependency relationships in the spaCy output ( token.dep_ ) but go through a considerable amount of processing to make them 'less syntactic' and 'more semantic'. To give but a few examples:
Some new semantic dependency labels that do not occur in spaCy outputs as values of token.dep_ are added for Holmes semantic dependencies. It is important to understand that Holmes semantic dependencies are used exclusively for matching and are therefore neither intended nor required to form a coherent set of linguistic theoretical entities or relationships; whatever works best for matching is assigned on an ad-hoc basis.
For each language, the match_implication_dict dictionary maps search-phrase semantic dependencies to matching document semantic dependencies and is responsible for the asymmetry of matching between search phrases and documents.
Topic matching involves the following steps:
SemanticMatchingHelper.topic_matching_phraselet_stop_lemmas ), which are consistently ignored throughout the whole process.SemanticMatchingHelper.phraselet_templates .SemanticMatchingHelper.topic_matching_reverse_only_parent_lemmas ) or when the frequency factor for the parent word is below the threshold for relation matching ( relation_matching_frequency_threshold , default: 0.25). These measures are necessary because matching on eg a parent preposition would lead to a large number of potential matches that would take a lot of resources to investigate: it is better to start investigation from the less frequent word within a given relation.relation_matching_frequency_threshold , default: 0.25).embedding_matching_frequency_threshold , default: 0.5), matching at all of those words where the relation template has not already been matched is retried using embeddings at the other word within the relation. A pair of words is then regarded as matching when their mutual cosine similarity is above initial_question_word_embedding_match_threshold (default: 0.7) in situations where the document word has an initial question word in its phrase or word_embedding_match_threshold (default: 0.8) in all other situations.use_frequency_factor is set to True (the default), each score is scaled by the frequency factor of its phraselet, meaning that words that occur less frequently in the corpus give rise to higher scores.maximum_activation_distance ; default: 75) of its value is subtracted from it as each new word is read.single_word_score ; default: 50), a non-noun single-word phraselet or a noun phraselet that matched a subword ( single_word_any_tag_score ; default: 20), a relation phraselet produced by a reverse-only template ( reverse_only_relation_score ; default: 200), any other (normally matched) relation phraselet ( relation_score ; default: 300), or a relation phraselet involving an initial question word ( initial_question_word_answer_score ; default: 600).embedding_penalty ; default: 0.6).ontology_penalty ; default: 0.9) once more often than the difference in depth between the two ontology entries, ie once for a synonym, twice for a child, three times for a grandchild and so on.overlapping_relation_multiplier ; default: 1.5).sideways_match_extent ; default: 100 words) within which the activation score is higher than the different_match_cutoff_score (default: 15) are regarded as belonging to a contiguous passage around the peak that is then returned as a TopicMatch object. (Note that this default will almost certainly turn out to be too low if use_frequency_factor is set to False .) A word whose activation equals the threshold exactly is included at the beginning of the area as long as the next word where activation increases has a score above the threshold. If the topic match peak is below the threshold, the topic match will only consist of the peak word.initial_question_word_behaviour is set to process (the default) or to exclusive , where a document word has matched an initial question word from the query phrase, the subtree of the matched document word is identified as a potential answer to the question and added to the dictionary to be returned. If initial_question_word_behaviour is set to exclusive , any topic matches that do not contain answers to initial question words are discarded.only_one_result_per_document = True prevents more than one result from being returned from the same document; only the result from each document with the highest score will then be returned.tied_result_quotient (default: 0.9) are labelled as tied. The supervised document classification use case relies on the same phraselets as the topic matching use case, although reverse-only templates are ignored and a different set of stop words is used ( SemanticMatchingHelper.supervised_document_classification_phraselet_stop_lemmas ). Classifiers are built and trained as follows:
oneshot ; whether single-word phraselets are generated for all words with their own meaning or only for those such words whose part-of-speech tags match the single-word phraselet template specification (essentially: noun phraselets) depends on the value of match_all_words . Wherever two phraselet matches overlap, a combined match is recorded. Combined matches are treated in the same way as other phraselet matches in further processing. This means that effectively the algorithm picks up one-word, two-word and three-word semantic combinations. See here for a discussion of the performance of this step.minimum_occurrences ; default: 4) or where the coefficient of variation (the standard deviation divided by the arithmetic mean) of the occurrences across the categories is below a threshold ( cv_threshold ; default: 1.0).oneshot==True vs. oneshot==False respectively). The outputs are the category labels, including any additional labels determined via a classification ontology. By default, the multilayer perceptron has three hidden layers where the first hidden layer has the same number of neurons as the input layer and the second and third layers have sizes in between the input and the output layer with an equally sized step between each size; the user is however free to specify any other topology.Holmes code is formatted with black.
The complexity of what Holmes does makes development impossible without a robust set of over 1400 regression tests. These can be executed individually with unittest or all at once by running the pytest utility from the Holmes source code root directory. (Note that the Python 3 command on Linux is pytest-3 .)
The pytest variant will only work on machines with sufficient memory resources. To reduce this problem, the tests are distributed across three subdirectories, so that pytest can be run three times, once from each subdirectory:
New languages can be added to Holmes by subclassing the SemanticAnalyzer and SemanticMatchingHelper classes as explained here.
The sets of matching semantic dependencies captured in the _matching_dep_dict dictionary for each language have been obtained on the basis of a mixture of linguistic-theoretical expectations and trial and error. The results would probably be improved if the _matching_dep_dict dictionaries could be derived using machine learning instead; as yet this has not been attempted because of the lack of appropriate training data.
An attempt should be made to remove personal data from supervised document classification models to make them more compliant with data protection laws.
In cases where embedding-based matching is not active, the second step of the supervised document classification procedure repeats a considerable amount of processing from the first step. Retaining the relevant information from the first step of the procedure would greatly improve training performance. This has not been attempted up to now because a large number of tests would be required to prove that such performance improvements did not have any inadvertent impacts on functionality.
The topic matching and supervised document classification use cases are both configured with a number of hyperparameters that are presently set to best-guess values derived on a purely theoretical basis. Results could be further improved by testing the use cases with a variety of hyperparameters to learn the optimal values.
The initial open-source version.
pobjp linking parents of prepositions directly with their children.MultiprocessingManager object as its facade.Manager and MultiprocessingManager classes into a single Manager class, with a redesigned public interface, that uses worker threads for everything except supervised document classification.

