holmes extractor
Holmes 4.0.0
Autor: Richard Paul Hudson, Explosão AI
Managermanager.nlpOntologySupervisedTopicTrainingBasis (devolvido de Manager.get_supervised_topic_training_basis() )SupervisedTopicModelTrainer (devolvido de SupervisedTopicTrainingBasis.train() )SupervisedTopicClassifier (devolvido de SupervisedTopicModelTrainer.classifier() e Manager.deserialize_supervised_topic_classifier() )Manager.match()Manager.topic_match_documents_against()Holmes é uma biblioteca Python 3 (v3.6 - v3.10), executando em cima de Spacy (v3.1 - v3.3) que suporta vários casos de uso que envolvem extração de informações dos textos em inglês e alemão. Em todos os casos de uso, a extração de informações é baseada na análise das relações semânticas expressas pelas partes componentes de cada frase:
No caso de uso do chatbot, o sistema é configurado usando uma ou mais frases de pesquisa . Holmes procura estruturas cujos significados correspondam aos dessas frases de pesquisa em um documento pesquisado, que neste caso corresponde a um trecho individual de texto ou fala inserido pelo usuário final. Dentro de uma correspondência, cada palavra com seu próprio significado (ou seja, que não apenas cumpre uma função gramatical) na frase de pesquisa corresponde a uma ou mais palavras dessas palavras no documento. Tanto o fato de que uma frase de pesquisa foi correspondida e qualquer informação estruturada que os extratos de frase de pesquisa possam ser usados para acionar o chatbot.
O caso de uso de extração estrutural usa exatamente a mesma tecnologia de correspondência estrutural que o caso de uso do chatbot, mas a pesquisa ocorre em relação a um documento ou documentos pré-existentes que normalmente são muito mais longos do que os snippets analisados no caso de uso do chatbot, e o objetivo é extrair e armazenar informações estruturadas. Por exemplo, um conjunto de artigos comerciais pode ser pesquisado para encontrar todos os lugares onde se diz que uma empresa planeja assumir uma segunda empresa. As identidades das empresas envolvidas podem ser armazenadas em um banco de dados.
O caso de uso do tópico que corresponde ao objetivo de encontrar passagens em um documento ou documentos cujo significado é próximo ao de outro documento, que assume a função do documento de consulta ou com o de uma frase de consulta inserida ad-hoc pelo usuário. Holmes extrai várias frases pequenas da frase de consulta ou documento de consulta, corresponde aos documentos pesquisados com cada phraselet e confunde os resultados para encontrar as passagens mais relevantes nos documentos. Como não existe um requisito rigoroso de que cada palavra com seu próprio significado no documento consulta corresponda a uma palavra ou palavras específicas nos documentos pesquisados, mais correspondências são encontradas do que no caso de uso de extração estrutural, mas as correspondências não contêm informações estruturadas que podem ser usadas no processamento subsequente. O caso de uso que corresponde ao tópico é demonstrado por um site, permitindo pesquisas em seis romances de Charles Dickens (para inglês) e cerca de 350 histórias tradicionais (para alemão).
O caso de uso de classificação de documentos supervisionado usa dados de treinamento para aprender um classificador que atribui um ou mais etiquetas de classificação a novos documentos com base no que são. Ele classifica um novo documento, combinando -o com phraselets que foram extraídos dos documentos de treinamento da mesma maneira que as phraselets são extraídas do documento de consulta no caso de uso de tópico correspondente. A técnica é inspirada em algoritmos de classificação baseados em saco de palavras que usam n-gramas, mas pretendem derivar n-gramas cujas palavras componentes são relacionadas semanticamente, em vez de isso ser vizinho na representação da superfície de um idioma.
Nos quatro casos de uso, as palavras individuais são correspondidas usando várias estratégias. Para descobrir se duas estruturas gramaticais que contêm palavras correspondentes individualmente correspondem logicamente e constituem uma correspondência, Holmes transforma as informações de análise sintática fornecidas pela Biblioteca Spacy em estruturas semânticas que permitem que os textos sejam comparados usando a lógica de predicado. Como usuário do Holmes, você não precisa entender os meandros de como isso funciona, embora existam algumas dicas importantes sobre a escrita de frases de pesquisa eficazes para os casos de uso do chatbot e extração estrutural que você deve tentar aceitar.
A Holmes visa oferecer soluções generalistas que podem ser usadas mais ou menos prontas para uso com relativamente pouco ajuste, ajustes ou treinamento e que são rapidamente aplicáveis a uma ampla gama de casos de uso. Em sua essência, encontra-se um sistema lógico, programado e baseado em regras que descreve como as representações sintáticas em cada idioma expressam relacionamentos semânticos. Although the supervised document classification use case does incorporate a neural network and although the spaCy library upon which Holmes builds has itself been pre-trained using machine learning, the essentially rule-based nature of Holmes means that the chatbot, structural extraction and topic matching use cases can be put to use out of the box without any training and that the supervised document classification use case typically requires relatively little training data, which is a great advantage because pre-labelled training data is not available for many Problemas do mundo real.
Holmes tem uma história longa e complexa e agora podemos publicá -la sob a licença do MIT, graças à boa vontade e abertura de várias empresas. Eu, Richard Hudson, escrevi as versões até 3.0.0 enquanto trabalhava na MSG Systems, uma grande consultoria de software internacional com sede perto de Munique. No final de 2021, mudei de empregadores e agora trabalho para explosão, os criadores de Spacy e Prodigy. Os elementos da biblioteca de Holmes são cobertos por uma patente dos EUA que eu mesmo escrevi no início dos anos 2000, enquanto trabalhava em uma startup chamada Definiens que foi adquirida pela AstraZeneca. Com a gentil permissão dos sistemas AstraZeneca e MSG, agora estou mantendo Holmes na explosão e posso oferecê -lo pela primeira vez sob uma licença permissiva: qualquer pessoa pode agora usar Holmes nos termos da licença do MIT sem precisar se preocupar com a patente.
A biblioteca foi originalmente desenvolvida na MSG Systems, mas agora está sendo mantida na explosão AI. Por favor, direcione quaisquer novos problemas ou discussões para o repositório de explosão.
Se você ainda não possui o Python 3 e o PIP em sua máquina, precisará instalá -los antes de instalar o Holmes.
Instale Holmes usando os seguintes comandos:
Linux:
pip3 install holmes-extractor
Windows:
pip install holmes-extractor
Para atualizar a partir de uma versão anterior de Holmes, emita os seguintes comandos e, em seguida, reedite os comandos para baixar os modelos Spacy e CoreFreee para garantir que você tenha as versões corretas deles:
Linux:
pip3 install --upgrade holmes-extractor
Windows:
pip install --upgrade holmes-extractor
Se você deseja usar os exemplos e testes, clone o código -fonte usando
git clone https://github.com/explosion/holmes-extractor
Se você deseja experimentar a alteração do código -fonte, poderá substituir o código instalado iniciando o Python (tipo python3 (Linux) ou python (Windows)) no diretório pai do diretório em que o código do módulo holmes_extractor alterado é. Se você verificou Holmes fora do Git, este será o diretório holmes-extractor .
Se você deseja desinstalar o Holmes novamente, isso é obtido excluindo o (s) arquivo (s) instalado (s) diretamente do sistema de arquivos. Estes podem ser encontrados emitindo o seguinte a partir do prompt de comando python iniciado em qualquer diretório que não seja o diretório pai de holmes_extractor :
import holmes_extractor
print(holmes_extractor.__file__)
As bibliotecas Spacy e CoreFreee nas quais Holmes se baseia requer modelos específicos de idioma que precisam ser baixados separadamente antes que Holmes possa ser usado:
Linux/English:
python3 -m spacy download en_core_web_trf
python3 -m spacy download en_core_web_lg
python3 -m coreferee install en
Linux/Alemão:
pip3 install spacy-lookups-data # (from spaCy 3.3 onwards)
python3 -m spacy download de_core_news_lg
python3 -m coreferee install de
Windows/Inglês:
python -m spacy download en_core_web_trf
python -m spacy download en_core_web_lg
python -m coreferee install en
Windows/Alemão:
pip install spacy-lookups-data # (from spaCy 3.3 onwards)
python -m spacy download de_core_news_lg
python -m coreferee install de
E se você planeja executar os testes de regressão:
Linux:
python3 -m spacy download en_core_web_sm
Windows:
python -m spacy download en_core_web_sm
Você especifica um modelo Spacy para Holmes usar quando instancia a classe Facade do gerente. en_core_web_trf e de_core_web_lg são os modelos que foram encontrados para produzir os melhores resultados para inglês e alemão, respectivamente. Como en_core_web_trf não possui seus próprios vetores de palavras, mas o holmes requer vetores de palavras para a combinação baseada em incorporação, o modelo en_core_web_lg é carregado como uma fonte vetorial sempre que en_core_web_trf é especificado para a classe gerente como modelo principal.
O modelo en_core_web_trf requer suficientemente mais recursos do que os outros modelos; Em uma Siutação em que os recursos são escassos, pode ser um compromisso sensato usar en_core_web_lg como o modelo principal.
A melhor maneira de integrar o Holmes em um ambiente não python é envolvê-lo como um serviço HTTP repousante e implantá-lo como um microsserviço. Veja aqui para um exemplo.
Como o Holmes realiza uma análise inteligente e complexa, é inevitável que requer mais recursos de hardware do que as estruturas de pesquisa mais tradicionais. Os casos de uso que envolvem documentos de carregamento - extração estrutural e correspondência de tópicos - são mais imediatamente aplicáveis a corpora grande, mas não massiva (por exemplo, todos os documentos pertencentes a uma determinada organização, todas as patentes sobre um determinado tópico, todos os livros de um determinado autor). Por motivos de custo, Holmes não seria uma ferramenta apropriada para analisar o conteúdo de toda a Internet!
Dito isto, Holmes é vertical e horizontalmente escalável. Com hardware suficiente, esses dois casos de uso podem ser aplicados a um número essencialmente ilimitado de documentos executando Holmes em várias máquinas, processando um conjunto diferente de documentos em cada um e confundindo os resultados. Observe que essa estratégia já está empregada para distribuir a correspondência entre vários núcleos em uma única máquina: a classe do gerente inicia uma série de processos e distribui documentos registrados entre eles.
Holmes mantém documentos carregados na memória, que se relacionam com o uso pretendido a corpora grande, mas não massiva. O desempenho do carregamento de documentos, extração estrutural e correspondência de tópicos se degradam muito se o sistema operacional precisar trocar as páginas de memória para o armazenamento secundário, porque Holmes pode exigir memória de várias páginas a serem abordadas ao processar uma única frase. Isso significa que é importante fornecer RAM suficiente em cada máquina para manter todos os documentos carregados.
Observe os comentários acima sobre os requisitos de recursos relativos dos diferentes modelos.
O caso de uso mais fácil para ter uma idéia básica rápida de como Holmes funciona é o caso de uso do chatbot .
Aqui, uma ou mais frases de pesquisa são definidas para Holmes com antecedência, e os documentos pesquisados são frases ou parágrafos curtos digitados em interativamente por um usuário final. Em uma configuração da vida real, as informações extraídas seriam usadas para determinar o fluxo de interação com o usuário final. Para fins de teste e demonstração, existe um console que exibe suas descobertas correspondentes interativamente. Ele pode ser iniciado de maneira fácil e rápida a partir da linha de comando Python (que é iniciada no sistema operacional Prompt digitando python3 (Linux) ou python (Windows)) ou de um notebook Jupyter.
O snippet de código a seguir pode ser inserido na linha para a linha na linha de comando python, em um notebook Jupyter ou em um IDE. Ele registra o fato de você estar interessado em frases sobre os cães grandes perseguindo gatos e inicia um console de Chatbot de demonstração:
Inglês:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='en_core_web_lg', number_of_workers=1)
holmes_manager.register_search_phrase('A big dog chases a cat')
holmes_manager.start_chatbot_mode_console()
Alemão:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='de_core_news_lg', number_of_workers=1)
holmes_manager.register_search_phrase('Ein großer Hund jagt eine Katze')
holmes_manager.start_chatbot_mode_console()
Se você agora inserir uma frase que corresponde à frase de pesquisa, o console exibirá uma correspondência:
Inglês:
Ready for input
A big dog chased a cat
Matched search phrase with text 'A big dog chases a cat':
'big'->'big' (Matches BIG directly); 'A big dog'->'dog' (Matches DOG directly); 'chased'->'chase' (Matches CHASE directly); 'a cat'->'cat' (Matches CAT directly)
Alemão:
Ready for input
Ein großer Hund jagte eine Katze
Matched search phrase 'Ein großer Hund jagt eine Katze':
'großer'->'groß' (Matches GROSS directly); 'Ein großer Hund'->'hund' (Matches HUND directly); 'jagte'->'jagen' (Matches JAGEN directly); 'eine Katze'->'katze' (Matches KATZE directly)
Isso poderia facilmente ter sido alcançado com um algoritmo simples de correspondência, então digite algumas frases mais complexas para se convencer de que Holmes está realmente agarrando -os e que as correspondências ainda são devolvidas:
Inglês:
The big dog would not stop chasing the cat
The big dog who was tired chased the cat
The cat was chased by the big dog
The cat always used to be chased by the big dog
The big dog was going to chase the cat
The big dog decided to chase the cat
The cat was afraid of being chased by the big dog
I saw a cat-chasing big dog
The cat the big dog chased was scared
The big dog chasing the cat was a problem
There was a big dog that was chasing a cat
The cat chase by the big dog
There was a big dog and it was chasing a cat.
I saw a big dog. My cat was afraid of being chased by the dog.
There was a big dog. His name was Fido. He was chasing my cat.
A dog appeared. It was chasing a cat. It was very big.
The cat sneaked back into our lounge because a big dog had been chasing her.
Our big dog was excited because he had been chasing a cat.
Alemão:
Der große Hund hat die Katze ständig gejagt
Der große Hund, der müde war, jagte die Katze
Die Katze wurde vom großen Hund gejagt
Die Katze wurde immer wieder durch den großen Hund gejagt
Der große Hund wollte die Katze jagen
Der große Hund entschied sich, die Katze zu jagen
Die Katze, die der große Hund gejagt hatte, hatte Angst
Dass der große Hund die Katze jagte, war ein Problem
Es gab einen großen Hund, der eine Katze jagte
Die Katzenjagd durch den großen Hund
Es gab einmal einen großen Hund, und er jagte eine Katze
Es gab einen großen Hund. Er hieß Fido. Er jagte meine Katze
Es erschien ein Hund. Er jagte eine Katze. Er war sehr groß.
Die Katze schlich sich in unser Wohnzimmer zurück, weil ein großer Hund sie draußen gejagt hatte
Unser großer Hund war aufgeregt, weil er eine Katze gejagt hatte
A demonstração não está completa sem experimentar outras frases que contêm as mesmas palavras, mas não expressam a mesma idéia e observarem que elas não são correspondidas:
Inglês:
The dog chased a big cat
The big dog and the cat chased about
The big dog chased a mouse but the cat was tired
The big dog always used to be chased by the cat
The big dog the cat chased was scared
Our big dog was upset because he had been chased by a cat.
The dog chase of the big cat
Alemão:
Der Hund jagte eine große Katze
Die Katze jagte den großen Hund
Der große Hund und die Katze jagten
Der große Hund jagte eine Maus aber die Katze war müde
Der große Hund wurde ständig von der Katze gejagt
Der große Hund entschloss sich, von der Katze gejagt zu werden
Die Hundejagd durch den große Katze
Nos exemplos acima, Holmes correspondeu a uma variedade de estruturas diferentes no nível da frase que compartilham o mesmo significado, mas as formas básicas das três palavras nos documentos correspondentes sempre foram as mesmas que as três palavras na frase de pesquisa. Holmes fornece várias estratégias adicionais para a correspondência no nível de palavra individual. Em combinação com a capacidade de Holmes de combinar diferentes estruturas de frases, elas podem permitir que uma frase de pesquisa seja correspondente a uma frase de documento que compartilha seu significado mesmo onde os dois não compartilham palavras e são gramaticalmente completamente diferentes.
Uma dessas estratégias adicionais de correspondência de palavras é denominada correspondência de entidades: palavras especiais podem ser incluídas em frases de pesquisa que correspondem a classes inteiras de nomes como pessoas ou lugares. Saia do console digitando exit , registre uma segunda frase de pesquisa e reinicie o console:
Inglês:
holmes_manager.register_search_phrase('An ENTITYPERSON goes into town')
holmes_manager.start_chatbot_mode_console()
Alemão:
holmes_manager.register_search_phrase('Ein ENTITYPER geht in die Stadt')
holmes_manager.start_chatbot_mode_console()
Agora você registrou seu interesse em pessoas que entram na cidade e podem inserir frases apropriadas no console:
Inglês:
Ready for input
I met Richard Hudson and John Doe last week. They didn't want to go into town.
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'John Doe'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
Alemão:
Ready for input
Letzte Woche sah ich Richard Hudson und Max Mustermann. Sie wollten nicht mehr in die Stadt gehen.
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Max Mustermann'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
Em cada um dos dois idiomas, este último exemplo demonstra vários outros recursos de Holmes:
Para mais exemplos, consulte a Seção 5.
As seguintes estratégias são implementadas com um módulo Python por estratégia. Embora a biblioteca padrão não suporta adicionar estratégias sob medida por meio da classe do gerente, seria relativamente fácil para qualquer pessoa com habilidades de programação Python alterar o código para ativar isso.
word_match.type=='direct' )A correspondência direta entre as palavras da frase de pesquisa e as palavras do documento está sempre ativa. A estratégia depende principalmente de formas de palavras com STEM correspondentes, por exemplo, compra em inglês e criança para comprar e crianças , Steigen e gentil com Stieg e Kinder . No entanto, para aumentar a chance de combinar direta funcionar quando o analisador fornece um formulário de haste incorreto para uma palavra, as formas de texto bruto de frase de pesquisa e palavras de documento também são levadas em consideração durante a correspondência direta.
word_match.type=='derivation' ) A correspondência baseada em derivação envolve palavras distintas, mas relacionadas, que normalmente pertencem a diferentes classes de palavras, por exemplo, avaliar e avaliar o inglês, Jagen e Jagd alemão. É ativo por padrão, mas pode ser desligado usando o parâmetro analyze_derivational_morphology , que é definido ao instanciar a classe Gerenciador.
word_match.type=='entity' )A correspondência de entidade nomeada é ativada inserindo um identificador especial de entrada denominada no ponto desejado em uma frase de pesquisa no lugar de um substantivo, por exemplo,
Um entityPerson vai para a cidade (inglês)
Ein Entityper Geht em Die Stadt (alemão).
Os identificadores de entrada nomeada suportada dependem diretamente das informações de entrada nomeada fornecidas pelos modelos de spacy para cada idioma (descrições copiadas de uma versão anterior da documentação de Spacy):
Inglês:
| Identificador | Significado |
|---|---|
| Entitynoun | Qualquer frase substantiva. |
| EntityPerson | Pessoas, incluindo fictício. |
| EntityNorp | Nacionalidades ou grupos religiosos ou políticos. |
| Entityfac | Edifícios, aeroportos, rodovias, pontes, etc. |
| Entityorg | Empresas, agências, instituições, etc. |
| Entitygpe | Países, cidades, estados. |
| EntityLoc | Locais não-GPE, cadeias de montanhas, corpos de água. |
| Entityproduct | Objetos, veículos, alimentos, etc. (não serviços.) |
| EntityEvent | Chamados furacões, batalhas, guerras, eventos esportivos, etc. |
| Entitywork_of_art | Títulos de livros, músicas, etc. |
| EntityLaw | Documentos nomeados feitos em leis. |
| EntityLanguage | Qualquer idioma nomeado. |
| Entitydate | Datas ou períodos absolutos ou relativos. |
| Entidade | Vezes menor que um dia. |
| EntityPercent | Porcentagem, incluindo "%". |
| EntityMoney | Valores monetários, incluindo unidade. |
| Entityquantity | Medições, por peso ou distância. |
| EntityorDinal | "Primeiro", "Segundo", etc. |
| EntityCardinal | Numerais que não se enquadram em outro tipo. |
Alemão:
| Identificador | Significado |
|---|---|
| Entitynoun | Qualquer frase substantiva. |
| Entityper | Pessoa ou família nomeada. |
| EntityLoc | Nome de localização política ou geograficamente definida (cidades, províncias, países, regiões internacionais, corpos de água, montanhas). |
| Entityorg | Nomeado entidade corporativa, governamental ou outra organização. |
| Entitymisc | Entidades diversas, por exemplo, eventos, nacionalidades, produtos ou obras de arte. |
Adicionamos ENTITYNOUN aos identificadores genuínos de entrada denominados. Como corresponde a qualquer frase substantiva, ele se comporta de maneira semelhante aos pronomes genéricos. As diferenças são que ENTITYNOUN deve corresponder a uma frase substantiva específica dentro de um documento e que essa frase substantiva específica é extraída e disponível para processamento adicional. ENTITYNOUN não é suportado no caso de uso de tópico correspondente.
word_match.type=='ontology' )Uma ontologia permite ao usuário definir relacionamentos entre palavras que são levadas em consideração ao corresponder documentos para pesquisar frases. Os três tipos de relacionamento relevantes são hipônimos (algo é um subtipo de algo), sinônimos (algo significa o mesmo que algo) e nomeado indivíduos (algo é uma instância específica de algo). Os três tipos de relacionamento são exemplificados na Figura 1:
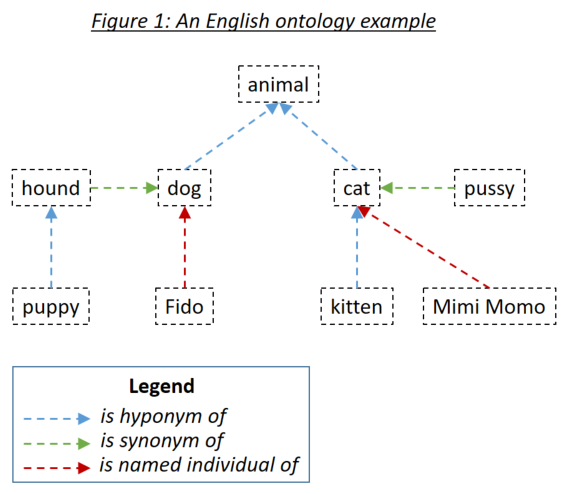
As ontologias são definidas para Holmes usando o padrão de ontologia da OWL serializada usando RDF/XML. Tais ontologias podem ser geradas com uma variedade de ferramentas. Para os exemplos e testes de Holmes, o protegido de ferramenta gratuito foi usado. Recomenda -se que você use protege tanto para definir suas próprias ontologias quanto para navegar as ontologias que enviam com os exemplos e testes. Ao salvar uma ontologia em Protege, selecione RDF/XML como formato. O Protege atribui rótulos padrão para os relacionamentos hiponym, sinônimo e individual nomeado que Holmes entende como padrões, mas que também podem ser substituídos.
As entradas de ontologia são definidas usando um Identificador de Recursos Internacionalizados (IRI), por exemplo, http://www.semanticweb.org/hudsonr/ontologies/2019/0/animals#dog . Holmes usa apenas o fragmento final para a correspondência, que permite que os homônimos (palavras com a mesma forma, mas múltiplos significados) sejam definidos em vários pontos da árvore de ontologia.
A correspondência baseada em ontologia fornece os melhores resultados com Holmes quando pequenas ontologias são usadas que foram construídas para domínios específicos de assuntos e casos de uso. Por exemplo, se você estiver implementando um chatbot para um caso de uso de seguro de construção, crie uma pequena ontologia capturando os termos e relacionamentos dentro desse domínio específico. Por outro lado, não é recomendável usar grandes ontologias construídas para todos os domínios em um idioma inteiro, como o WordNet. Isso ocorre porque os muitos homônimos e relacionamentos que se aplicam apenas em domínios estreitos tendem a levar a um grande número de correspondências incorretas. Para casos de uso geral, a correspondência baseada em incorporação tenderá a produzir melhores resultados.
Cada palavra em uma ontologia pode ser considerada como liderança de uma subárvore que consiste em seus hiponys, sinônimos e indivíduos nomeados, hiponias, sinônimos e indivíduos nomeados, e assim por diante. Com uma ontologia configurada da maneira padrão, apropriada para os casos de uso de uso de extração estrutural e uma palavra em uma frase de pesquisa de Holmes corresponde a uma palavra em um documento se a palavra do documento estiver dentro da subárvore da palavra da frase de pesquisa. Se a ontologia na Figura 1 definida para Holmes, além da estratégia de correspondência direta, que corresponderia a cada palavra a si mesma, as seguintes combinações corresponderiam:
Os verbos frasais ingleses como Eat Up Up e verbos separáveis alemães, como Aufessen, devem ser definidos como itens únicos dentro das ontologias. Quando Holmes está analisando um texto e se depara com esse verbo, o verbo principal e a partícula são confundidos em uma única palavra lógica que pode ser correspondida por meio de uma ontologia. Isso significa que comer dentro de um texto corresponderia à subárvore de comer dentro da ontologia, mas não a subárvore de comer dentro da ontologia.
Se a correspondência baseada em derivação estiver ativa, ela será levada em consideração nos dois lados de uma possível correspondência baseada em ontologia. Por exemplo, se o Alter e a alteração forem definidos como sinônimos em uma ontologia, alteração e alteração também se corresponderiam.
Em situações em que encontrar frases relevantes é mais importante do que garantir a correspondência lógica de correspondências de documentos para as frases de pesquisa, pode fazer sentido especificar correspondência simétrica ao definir a ontologia. A correspondência simétrica é recomendada para o caso de uso de correspondência de tópicos, mas é improvável que seja apropriado para o chatbot ou casos de uso de extração estrutural. Isso significa que o relacionamento Hypernym (reverso de hipoônimo) é levado em consideração, bem como os relacionamentos hiponym e sinônimo ao corresponder, levando a uma relação mais simétrica entre documentos e frases de pesquisa. Uma regra importante aplicada ao corresponder através de uma ontologia simétrica é que um caminho de correspondência pode não conter os relacionamentos de hipernym e hipoônimo, ou seja, você não pode voltar a si mesmo. As ontologia acima foram definidas como simétricas, as seguintes combinações correspondem:
No caso de uso de classificação de documentos supervisionado, duas ontologias separadas podem ser usadas:
A ontologia de correspondência estrutural é usada para analisar o conteúdo dos documentos de treinamento e teste. Cada palavra de um documento encontrada na ontologia é substituída por seu ancestral mais geral do Hypernym. É importante perceber que é provável que uma ontologia só trabalhe com a correspondência estrutural para classificação de documentos supervisionada, se foi construída especificamente para esse fim: tal ontologia deve consistir em várias árvores separadas representando as principais classes de objeto nos documentos a serem classificados. No exemplo da ontologia mostrada acima, todas as palavras na ontologia seriam substituídas por animais ; Em um caso extremo com uma ontologia no estilo WordNet, todos os substantivos acabariam sendo substituídos por coisas , o que claramente não é um resultado desejável!
A ontologia de classificação é usada para capturar as relações entre os rótulos de classificação: que um documento possui uma certa classificação implica que também possui classificações para cujo subárvore que a classificação pertence. Os sinônimos devem ser usados com moderação, se em ontologias de classificação, porque adicionam à complexidade da rede neural sem agregar valor; E embora seja tecnicamente possível configurar uma ontologia de classificação para usar a correspondência simétrica, não há motivo sensato para fazê -lo. Observe que um rótulo dentro da ontologia de classificação que não é diretamente definido como o rótulo de qualquer documento de treinamento deve ser registrado especificamente usando o método SupervisedTopicTrainingBasis.register_additional_classification_label() teatro de teatro.
word_match.type=='embedding' )O Spacy oferece incorporações de palavras : representações numéricas de vetores numéricas geradas por máquina de aprendizado de máquina que capturam os contextos nos quais cada palavra tende a ocorrer. Duas palavras com significado semelhante tendem a surgir com incorporações de palavras próximas uma da outra, e Spacy pode medir a similaridade de cosseno entre as incorporações de duas palavras expressas como um decimal entre 0,0 (sem semelhança) e 1,0 (a mesma palavra). Como cães e gatos tendem a aparecer em contextos semelhantes, eles têm uma semelhança de 0,80; Dog e cavalo têm menos em comum e têm uma semelhança de 0,62; e cachorro e ferro têm uma semelhança de apenas 0,25. A correspondência baseada em incorporação é ativada apenas para substantivos, adjetivos e advérbios porque os resultados foram considerados insatisfatórios com outras classes de palavras.
É importante entender que o fato de duas palavras terem incorporações semelhantes não implica o mesmo tipo de relação lógica entre os dois que quando a correspondência baseada na ontologia é usada: por exemplo, o fato de que cão e gato têm incorporações semelhantes significa que um cão é um tipo de gato nem que um gato é um tipo de cachorro. Ainda assim, se a correspondência baseada em incorporação é ou não uma escolha apropriada depende do caso de uso funcional.
Para o chatbot, a extração estrutural e os casos de uso de classificação de documentos supervisionados, Holmes utiliza semelhanças baseadas em incorporação de palavras usando um parâmetro overall_similarity_threshold definido globalmente na classe do gerente. Uma correspondência é detectada entre uma frase de pesquisa e uma estrutura dentro de um documento sempre que a média geométrica das semelhanças entre os pares de palavras correspondentes individuais é maior que esse limite. A intuição por trás dessa técnica é que, onde uma frase de pesquisa com o EG Seis palavras lexicais corresponde a uma estrutura de documentos em que cinco dessas palavras correspondem exatamente e apenas uma corresponde por meio de uma incorporação, a semelhança que deve ser necessária para corresponder a esta sexta palavra é menor que quando apenas três das palavras correspondem exatamente e duas das outras palavras também correspondem por meio de incorporação.
Combinando uma frase de pesquisa a um documento começa encontrando palavras no documento que correspondem à palavra na raiz (cabeça sintática) da frase de pesquisa. Holmes então investiga a estrutura em torno de cada uma dessas palavras de documentos correspondentes para verificar se a estrutura do documento corresponde à estrutura da frase de pesquisa em sua item. As palavras do documento que correspondem à palavra raiz da frase de pesquisa são normalmente encontradas usando um índice. No entanto, se as incorporações precisarem ser levadas em consideração ao encontrar palavras de documentos que correspondam a uma palavra raiz de frase de pesquisa, cada palavra em todos os documentos com uma classe de palavras válidos deve ser comparada quanto à semelhança com essa frase de pesquisa da palavra root. Isso tem um desempenho muito perceptível que torna todos os casos de uso, exceto o caso de uso do chatbot essencialmente inutilizável.
Para evitar o desempenho tipicamente desnecessário que resulta da correspondência baseada em incorporação das palavras raiz da frase de pesquisa, ele é controlado separadamente da correspondência baseada em incorporação em geral, usando o parâmetro embedding_based_matching_on_root_words , que é definido ao instantar a classe Gerenciador. Você é aconselhado a manter essa configuração desligada (valor False ) para a maioria dos casos de uso.
Nem o overall_similarity_threshold nem o parâmetro embedding_based_matching_on_root_words têm algum efeito no caso de uso de correspondência de tópico. Aqui, os limites de similaridade de incorporação no nível da palavra são definidos usando o word_embedding_match_threshold e initial_question_word_embedding_match_threshold parâmetros ao chamar a função topic_match_documents_against na classe Manager.
word_match.type=='entity_embedding' ) Uma correspondência baseada em incorporação de entrada nomeada é obtida entre uma palavra de documento pesquisado que possui uma certa etiqueta de entidade e uma frase de pesquisa ou uma palavra de documento de consulta cuja incorporação é suficientemente semelhante ao significado subjacente desse rótulo de entidade, por exemplo, a palavra individual em uma frase de pesquisa tem uma palavra semelhante incorporada ao significado subjacente da entidade- pessoa . Observe que a correspondência baseada em embutimento de entrada de entrada de nome nunca é ativa nas palavras root, independentemente da configuração embedding_based_matching_on_root_words .
word_match.type=='question' )A correspondência de palavras-perguntas iniciais é ativa apenas durante a correspondência de tópicos. Palavras de pergunta inicial em frases de consulta combinam entidades nos documentos pesquisados que representam respostas em potencial para a pergunta, por exemplo, ao comparar a frase de consulta quando Peter tomou café da manhã com a frase de documento pesquisado Peter tomou café da manhã às 8h , a palavra da pergunta quando corresponderia à frase adverbial temporal às 8h .
A correspondência de palavras-perguntas iniciais é ligada e desativada usando o parâmetro initial_question_word_behaviour ao chamar a função topic_match_documents_against na classe Manager. It is only likely to be useful when topic matching is being performed in an interactive setting where the user enters short query phrases, as opposed to when it is being used to find documents on a similar topic to an pre-existing query document: initial question words are only processed at the beginning of the first sentence of the query phrase or query document.
Linguistically speaking, if a query phrase consists of a complex question with several elements dependent on the main verb, a finding in a searched document is only an 'answer' if contains matches to all these elements. Because recall is typically more important than precision when performing topic matching with interactive query phrases, however, Holmes will match an initial question word to a searched-document phrase wherever they correspond semantically (eg wherever when corresponds to a temporal adverbial phrase) and each depend on verbs that themselves match at the word level. One possible strategy to filter out 'incomplete answers' would be to calculate the maximum possible score for a query phrase and reject topic matches that score below a threshold scaled to this maximum.
Before Holmes analyses a searched document or query document, coreference resolution is performed using the Coreferee library running on top of spaCy. This means that situations are recognised where pronouns and nouns that are located near one another within a text refer to the same entities. The information from one mention can then be applied to the analysis of further mentions:
I saw a big dog . It was chasing a cat.
I saw a big dog . The dog was chasing a cat.
Coreferee also detects situations where a noun refers back to a named entity:
We discussed AstraZeneca . The company had given us permission to publish this library under the MIT license.
If this example were to match the search phrase A company gives permission to publish something , the coreference information that the company under discussion is AstraZeneca is clearly relevant and worth extracting in addition to the word(s) directly matched to the search phrase. Such information is captured in the word_match.extracted_word field.
The concept of search phrases has already been introduced and is relevant to the chatbot use case, the structural extraction use case and to preselection within the supervised document classification use case.
It is crucial to understand that the tips and limitations set out in Section 4 do not apply in any way to query phrases in topic matching. If you are using Holmes for topic matching only, you can completely ignore this section!
Structural matching between search phrases and documents is not symmetric: there are many situations in which sentence X as a search phrase would match sentence Y within a document but where the converse would not be true. Although Holmes does its best to understand any search phrases, the results are better when the user writing them follows certain patterns and tendencies, and getting to grips with these patterns and tendencies is the key to using the relevant features of Holmes successfully.
Holmes distinguishes between: lexical words like dog , chase and cat (English) or Hund , jagen and Katze (German) in the initial example above; and grammatical words like a (English) or ein and eine (German) in the initial example above. Only lexical words match words in documents, but grammatical words still play a crucial role within a search phrase: they enable Holmes to understand it.
Dog chase cat (English)
Hund jagen Katze (German)
contain the same lexical words as the search phrases in the initial example above, but as they are not grammatical sentences Holmes is liable to misunderstand them if they are used as search phrases. This is a major difference between Holmes search phrases and the search phrases you use instinctively with standard search engines like Google, and it can take some getting used to.
A search phrase need not contain a verb:
ENTITYPERSON (English)
A big dog (English)
Interest in fishing (English)
ENTITYPER (German)
Ein großer Hund (German)
Interesse am Angeln (German)
are all perfectly valid and potentially useful search phrases.
Where a verb is present, however, Holmes delivers the best results when the verb is in the present active , as chases and jagt are in the initial example above. This gives Holmes the best chance of understanding the relationship correctly and of matching the widest range of document structures that share the target meaning.
Sometimes you may only wish to extract the object of a verb. For example, you might want to find sentences that are discussing a cat being chased regardless of who is doing the chasing. In order to avoid a search phrase containing a passive expression like
A cat is chased (English)
Eine Katze wird gejagt (German)
you can use a generic pronoun . This is a word that Holmes treats like a grammatical word in that it is not matched to documents; its sole purpose is to help the user form a grammatically optimal search phrase in the present active. Recognised generic pronouns are English something , somebody and someone and German jemand (and inflected forms of jemand ) and etwas : Holmes treats them all as equivalent. Using generic pronouns, the passive search phrases above could be re-expressed as
Somebody chases a cat (English)
Jemand jagt eine Katze (German).
Experience shows that different prepositions are often used with the same meaning in equivalent phrases and that this can prevent search phrases from matching where one would intuitively expect it. For example, the search phrases
Somebody is at the market (English)
Jemand ist auf dem Marktplatz (German)
would fail to match the document phrases
Richard was in the market (English)
Richard war am Marktplatz (German)
The best way of solving this problem is to define the prepositions in question as synonyms in an ontology.
The following types of structures are prohibited in search phrases and result in Python user-defined errors:
A dog chases a cat. A cat chases a dog (English)
Ein Hund jagt eine Katze. Eine Katze jagt einen Hund (German)
Each clause must be separated out into its own search phrase and registered individually.
A dog does not chase a cat. (Inglês)
Ein Hund jagt keine Katze. (Alemão)
Negative expressions are recognised as such in documents and the generated matches marked as negative; allowing search phrases themselves to be negative would overcomplicate the library without offering any benefits.
A dog and a lion chase a cat. (Inglês)
Ein Hund und ein Löwe jagen eine Katze. (Alemão)
Wherever conjunction occurs in documents, Holmes distributes the information among multiple matches as explained above. In the unlikely event that there should be a requirement to capture conjunction explicitly when matching, this could be achieved by using the Manager.match() function and looking for situations where the document token objects are shared by multiple match objects.
The (English)
Der (German)
A search phrase cannot be processed if it does not contain any words that can be matched to documents.
A dog chases a cat and he chases a mouse (English)
Ein Hund jagt eine Katze und er jagt eine Maus (German)
Pronouns that corefer with nouns elsewhere in the search phrase are not permitted as this would overcomplicate the library without offering any benefits.
The following types of structures are strongly discouraged in search phrases:
Dog chase cat (English)
Hund jagen Katze (German)
Although these will sometimes work, the results will be better if search phrases are expressed grammatically.
A cat is chased by a dog (English)
A dog will have chased a cat (English)
Eine Katze wird durch einen Hund gejagt (German)
Ein Hund wird eine Katze gejagt haben (German)
Although these will sometimes work, the results will be better if verbs in search phrases are expressed in the present active.
Who chases the cat? (Inglês)
Wer jagt die Katze? (Alemão)
Although questions are supported as query phrases in the topic matching use case, they are not appropriate as search phrases. Questions should be re-phrased as statements, in this case
Something chases the cat (English)
Etwas jagt die Katze (German).
Informationsextraktion (German)
Ein Stadtmittetreffen (German)
The internal structure of German compound words is analysed within searched documents as well as within query phrases in the topic matching use case, but not within search phrases. In search phrases, compound words should be reexpressed as genitive constructions even in cases where this does not strictly capture their meaning:
Extraktion der Information (German)
Ein Treffen der Stadtmitte (German)
The following types of structures should be used with caution in search phrases:
A fierce dog chases a scared cat on the way to the theatre (English)
Ein kämpferischer Hund jagt eine verängstigte Katze auf dem Weg ins Theater (German)
Holmes can handle any level of complexity within search phrases, but the more complex a structure, the less likely it becomes that a document sentence will match it. If it is really necessary to match such complex relationships with search phrases rather than with topic matching, they are typically better extracted by splitting the search phrase up, eg
A fierce dog (English)
A scared cat (English)
A dog chases a cat (English)
Something chases something on the way to the theatre (English)
Ein kämpferischer Hund (German)
Eine verängstigte Katze (German)
Ein Hund jagt eine Katze (German)
Etwas jagt etwas auf dem Weg ins Theater (German)
Correlations between the resulting matches can then be established by matching via the Manager.match() function and looking for situations where the document token objects are shared across multiple match objects.
One possible exception to this piece of advice is when embedding-based matching is active. Because whether or not each word in a search phrase matches then depends on whether or not other words in the same search phrase have been matched, large, complex search phrases can sometimes yield results that a combination of smaller, simpler search phrases would not.
The chasing of a cat (English)
Die Jagd einer Katze (German)
These will often work, but it is generally better practice to use verbal search phrases like
Something chases a cat (English)
Etwas jagt eine Katze (German)
and to allow the corresponding nominal phrases to be matched via derivation-based matching.
The chatbot use case has already been introduced: a predefined set of search phrases is used to extract information from phrases entered interactively by an end user, which in this use case act as the documents.
The Holmes source code ships with two examples demonstrating the chatbot use case, one for each language, with predefined ontologies. Having cloned the source code and installed the Holmes library, navigate to the /examples directory and type the following (Linux):
Inglês:
python3 example_chatbot_EN_insurance.py
Alemão:
python3 example_chatbot_DE_insurance.py
or click on the files in Windows Explorer (Windows).
Holmes matches syntactically distinct structures that are semantically equivalent, ie that share the same meaning. In a real chatbot use case, users will typically enter equivalent information with phrases that are semantically distinct as well, ie that have different meanings. Because the effort involved in registering a search phrase is barely greater than the time it takes to type it in, it makes sense to register a large number of search phrases for each relationship you are trying to extract: essentially all ways people have been observed to express the information you are interested in or all ways you can imagine somebody might express the information you are interested in . To assist this, search phrases can be registered with labels that do not need to be unique: a label can then be used to express the relationship an entire group of search phrases is designed to extract. Note that when many search phrases have been defined to extract the same relationship, a single user entry is likely to be sometimes matched by multiple search phrases. This must be handled appropriately by the calling application.
One obvious weakness of Holmes in the chatbot setting is its sensitivity to correct spelling and, to a lesser extent, to correct grammar. Strategies for mitigating this weakness include:
The structural extraction use case uses structural matching in the same way as the chatbot use case, and many of the same comments and tips apply to it. The principal differences are that pre-existing and often lengthy documents are scanned rather than text snippets entered ad-hoc by the user, and that the returned match objects are not used to drive a dialog flow; they are examined solely to extract and store structured information.
Code for performing structural extraction would typically perform the following tasks:
Manager.register_search_phrase() several times to define a number of search phrases specifying the information to be extracted.Manager.parse_and_register_document() several times to load a number of documents within which to search.Manager.match() to perform the matching.The topic matching use case matches a query document , or alternatively a query phrase entered ad-hoc by the user, against a set of documents pre-loaded into memory. The aim is to find the passages in the documents whose topic most closely corresponds to the topic of the query document; the output is a ordered list of passages scored according to topic similarity. Additionally, if a query phrase contains an initial question word, the output will contain potential answers to the question.
Topic matching queries may contain generic pronouns and named-entity identifiers just like search phrases, although the ENTITYNOUN token is not supported. However, an important difference from search phrases is that the topic matching use case places no restrictions on the grammatical structures permissible within the query document.
In addition to the Holmes demonstration website, the Holmes source code ships with three examples demonstrating the topic matching use case with an English literature corpus, a German literature corpus and a German legal corpus respectively. Users are encouraged to run these to get a feel for how they work.
Topic matching uses a variety of strategies to find text passages that are relevant to the query. These include resource-hungry procedures like investigating semantic relationships and comparing embeddings. Because applying these across the board would prevent topic matching from scaling, Holmes only attempts them for specific areas of the text that less resource-intensive strategies have already marked as looking promising. This and the other interior workings of topic matching are explained here.
In the supervised document classification use case, a classifier is trained with a number of documents that are each pre-labelled with a classification. The trained classifier then assigns one or more labels to new documents according to what each new document is about. As explained here, ontologies can be used both to enrichen the comparison of the content of the various documents and to capture implication relationships between classification labels.
A classifier makes use of a neural network (a multilayer perceptron) whose topology can either be determined automatically by Holmes or specified explicitly by the user. With a large number of training documents, the automatically determined topology can easily exhaust the memory available on a typical machine; if there is no opportunity to scale up the memory, this problem can be remedied by specifying a smaller number of hidden layers or a smaller number of nodes in one or more of the layers.
A trained document classification model retains no references to its training data. This is an advantage from a data protection viewpoint, although it cannot presently be guaranteed that models will not contain individual personal or company names.
A typical problem with the execution of many document classification use cases is that a new classification label is added when the system is already live but that there are initially no examples of this new classification with which to train a new model. The best course of action in such a situation is to define search phrases which preselect the more obvious documents with the new classification using structural matching. Those documents that are not preselected as having the new classification label are then passed to the existing, previously trained classifier in the normal way. When enough documents exemplifying the new classification have accumulated in the system, the model can be retrained and the preselection search phrases removed.
Holmes ships with an example script demonstrating supervised document classification for English with the BBC Documents dataset. The script downloads the documents (for this operation and for this operation alone, you will need to be online) and places them in a working directory. When training is complete, the script saves the model to the working directory. If the model file is found in the working directory on subsequent invocations of the script, the training phase is skipped and the script goes straight to the testing phase. This means that if it is wished to repeat the training phase, either the model has to be deleted from the working directory or a new working directory has to be specified to the script.
Having cloned the source code and installed the Holmes library, navigate to the /examples directory. Specify a working directory at the top of the example_supervised_topic_model_EN.py file, then type python3 example_supervised_topic_model_EN (Linux) or click on the script in Windows Explorer (Windows).
It is important to realise that Holmes learns to classify documents according to the words or semantic relationships they contain, taking any structural matching ontology into account in the process. For many classification tasks, this is exactly what is required; but there are tasks (eg author attribution according to the frequency of grammatical constructions typical for each author) where it is not. For the right task, Holmes achieves impressive results. For the BBC Documents benchmark processed by the example script, Holmes performs slightly better than benchmarks available online (see eg here) although the difference is probably too slight to be significant, especially given that the different training/test splits were used in each case: Holmes has been observed to learn models that predict the correct result between 96.9% and 98.7% of the time. The range is explained by the fact that the behaviour of the neural network is not fully deterministic.
The interior workings of supervised document classification are explained here.
Manager holmes_extractor.Manager(self, model, *, overall_similarity_threshold=1.0,
embedding_based_matching_on_root_words=False, ontology=None,
analyze_derivational_morphology=True, perform_coreference_resolution=None,
number_of_workers=None, verbose=False)
The facade class for the Holmes library.
Parameters:
model -- the name of the spaCy model, e.g. *en_core_web_trf*
overall_similarity_threshold -- the overall similarity threshold for embedding-based
matching. Defaults to *1.0*, which deactivates embedding-based matching. Note that this
parameter is not relevant for topic matching, where the thresholds for embedding-based
matching are set on the call to *topic_match_documents_against*.
embedding_based_matching_on_root_words -- determines whether or not embedding-based
matching should be attempted on search-phrase root tokens, which has a considerable
performance hit. Defaults to *False*. Note that this parameter is not relevant for topic
matching.
ontology -- an *Ontology* object. Defaults to *None* (no ontology).
analyze_derivational_morphology -- *True* if matching should be attempted between different
words from the same word family. Defaults to *True*.
perform_coreference_resolution -- *True* if coreference resolution should be taken into account
when matching. Defaults to *True*.
use_reverse_dependency_matching -- *True* if appropriate dependencies in documents can be
matched to dependencies in search phrases where the two dependencies point in opposite
directions. Defaults to *True*.
number_of_workers -- the number of worker processes to use, or *None* if the number of worker
processes should depend on the number of available cores. Defaults to *None*
verbose -- a boolean value specifying whether multiprocessing messages should be outputted to
the console. Defaults to *False*
Manager.register_serialized_document(self, serialized_document:bytes, label:str="") -> None
Parameters:
document -- a preparsed Holmes document.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.register_serialized_documents(self, document_dictionary:dict[str, bytes]) -> None
Note that this function is the most efficient way of loading documents.
Parameters:
document_dictionary -- a dictionary from labels to serialized documents.
Manager.parse_and_register_document(self, document_text:str, label:str='') -> None
Parameters:
document_text -- the raw document text.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.remove_document(self, label:str) -> None
Manager.remove_all_documents(self, labels_starting:str=None) -> None
Parameters:
labels_starting -- a string starting the labels of documents to be removed,
or 'None' if all documents are to be removed.
Manager.list_document_labels(self) -> List[str]
Returns a list of the labels of the currently registered documents.
Manager.serialize_document(self, label:str) -> Optional[bytes]
Returns a serialized representation of a Holmes document that can be
persisted to a file. If 'label' is not the label of a registered document,
'None' is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.get_document(self, label:str='') -> Optional[Doc]
Returns a Holmes document. If *label* is not the label of a registered document, *None*
is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.debug_document(self, label:str='') -> None
Outputs a debug representation for a loaded document.
Parameters:
label -- the label of the document to be serialized.
Manager.register_search_phrase(self, search_phrase_text:str, label:str=None) -> SearchPhrase
Registers and returns a new search phrase.
Parameters:
search_phrase_text -- the raw search phrase text.
label -- a label for the search phrase, which need not be unique.
If label==None, the assigned label defaults to the raw search phrase text.
Manager.remove_all_search_phrases_with_label(self, label:str) -> None
Manager.remove_all_search_phrases(self) -> None
Manager.list_search_phrase_labels(self) -> List[str]
Manager.match(self, search_phrase_text:str=None, document_text:str=None) -> List[Dict]
Matches search phrases to documents and returns the result as match dictionaries.
Parameters:
search_phrase_text -- a text from which to generate a search phrase, or 'None' if the
preloaded search phrases should be used for matching.
document_text -- a text from which to generate a document, or 'None' if the preloaded
documents should be used for matching.
topic_match_documents_against(self, text_to_match:str, *,
use_frequency_factor:bool=True,
maximum_activation_distance:int=75,
word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7,
relation_score:int=300,
reverse_only_relation_score:int=200,
single_word_score:int=50,
single_word_any_tag_score:int=20,
initial_question_word_answer_score:int=600,
initial_question_word_behaviour:str='process',
different_match_cutoff_score:int=15,
overlapping_relation_multiplier:float=1.5,
embedding_penalty:float=0.6,
ontology_penalty:float=0.9,
relation_matching_frequency_threshold:float=0.25,
embedding_matching_frequency_threshold:float=0.5,
sideways_match_extent:int=100,
only_one_result_per_document:bool=False,
number_of_results:int=10,
document_label_filter:str=None,
tied_result_quotient:float=0.9) -> List[Dict]:
Returns a list of dictionaries representing the results of a topic match between an entered text
and the loaded documents.
Properties:
text_to_match -- the text to match against the loaded documents.
use_frequency_factor -- *True* if scores should be multiplied by a factor between 0 and 1
expressing how rare the words matching each phraselet are in the corpus. Note that,
even if this parameter is set to *False*, the factors are still calculated as they are
required for determining which relation and embedding matches should be attempted.
maximum_activation_distance -- the number of words it takes for a previous phraselet
activation to reduce to zero when the library is reading through a document.
word_embedding_match_threshold -- the cosine similarity above which two words match where
the search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
relation_score -- the activation score added when a normal two-word relation is matched.
reverse_only_relation_score -- the activation score added when a two-word relation
is matched using a search phrase that can only be reverse-matched.
single_word_score -- the activation score added when a single noun is matched.
single_word_any_tag_score -- the activation score added when a single word is matched
that is not a noun.
initial_question_word_answer_score -- the activation score added when a question word is
matched to an potential answer phrase.
initial_question_word_behaviour -- 'process' if a question word in the sentence
constituent at the beginning of *text_to_match* is to be matched to document phrases
that answer it and to matching question words; 'exclusive' if only topic matches that
answer questions are to be permitted; 'ignore' if question words are to be ignored.
different_match_cutoff_score -- the activation threshold under which topic matches are
separated from one another. Note that the default value will probably be too low if
*use_frequency_factor* is set to *False*.
overlapping_relation_multiplier -- the value by which the activation score is multiplied
when two relations were matched and the matches involved a common document word.
embedding_penalty -- a value between 0 and 1 with which scores are multiplied when the
match involved an embedding. The result is additionally multiplied by the overall
similarity measure of the match.
ontology_penalty -- a value between 0 and 1 with which scores are multiplied for each
word match within a match that involved the ontology. For each such word match,
the score is multiplied by the value (abs(depth) + 1) times, so that the penalty is
higher for hyponyms and hypernyms than for synonyms and increases with the
depth distance.
relation_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches.
embedding_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches with
embedding-based matching on the second word.
sideways_match_extent -- the maximum number of words that may be incorporated into a
topic match either side of the word where the activation peaked.
only_one_result_per_document -- if 'True', prevents multiple results from being returned
for the same document.
number_of_results -- the number of topic match objects to return.
document_label_filter -- optionally, a string with which document labels must start to
be considered for inclusion in the results.
tied_result_quotient -- the quotient between a result and following results above which
the results are interpreted as tied.
Manager.get_supervised_topic_training_basis(self, *, classification_ontology:Ontology=None,
overlap_memory_size:int=10, oneshot:bool=True, match_all_words:bool=False,
verbose:bool=True) -> SupervisedTopicTrainingBasis:
Returns an object that is used to train and generate a model for the
supervised document classification use case.
Parameters:
classification_ontology -- an Ontology object incorporating relationships between
classification labels, or 'None' if no such ontology is to be used.
overlap_memory_size -- how many non-word phraselet matches to the left should be
checked for words in common with a current match.
oneshot -- whether the same word or relationship matched multiple times within a
single document should be counted once only (value 'True') or multiple times
(value 'False')
match_all_words -- whether all single words should be taken into account
(value 'True') or only single words with noun tags (value 'False')
verbose -- if 'True', information about training progress is outputted to the console.
Manager.deserialize_supervised_topic_classifier(self,
serialized_model:bytes, verbose:bool=False) -> SupervisedTopicClassifier:
Returns a classifier for the supervised document classification use case
that will use a supplied pre-trained model.
Parameters:
serialized_model -- the pre-trained model as returned from `SupervisedTopicClassifier.serialize_model()`.
verbose -- if 'True', information about matching is outputted to the console.
Manager.start_chatbot_mode_console(self)
Starts a chatbot mode console enabling the matching of pre-registered
search phrases to documents (chatbot entries) entered ad-hoc by the
user.
Manager.start_structural_search_mode_console(self)
Starts a structural extraction mode console enabling the matching of pre-registered
documents to search phrases entered ad-hoc by the user.
Manager.start_topic_matching_search_mode_console(self,
only_one_result_per_document:bool=False, word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7):
Starts a topic matching search mode console enabling the matching of pre-registered
documents to query phrases entered ad-hoc by the user.
Parameters:
only_one_result_per_document -- if 'True', prevents multiple topic match
results from being returned for the same document.
word_embedding_match_threshold -- the cosine similarity above which two words match where the
search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
Manager.close(self) -> None
Terminates the worker processes.
manager.nlp manager.nlp is the underlying spaCy Language object on which both Coreferee and Holmes have been registered as custom pipeline components. The most efficient way of parsing documents for use with Holmes is to call manager.nlp.pipe() . This yields an iterable of documents that can then be loaded into Holmes via manager.register_serialized_documents() .
The pipe() method has an argument n_process that specifies the number of processors to use. With _lg , _md and _sm spaCy models, there are some situations where it can make sense to specify a value other than 1 (the default). Note however that with transformer spaCy models ( _trf ) values other than 1 are not supported.
Ontology holmes_extractor.Ontology(self, ontology_path,
owl_class_type='http://www.w3.org/2002/07/owl#Class',
owl_individual_type='http://www.w3.org/2002/07/owl#NamedIndividual',
owl_type_link='http://www.w3.org/1999/02/22-rdf-syntax-ns#type',
owl_synonym_type='http://www.w3.org/2002/07/owl#equivalentClass',
owl_hyponym_type='http://www.w3.org/2000/01/rdf-schema#subClassOf',
symmetric_matching=False)
Loads information from an existing ontology and manages ontology
matching.
The ontology must follow the W3C OWL 2 standard. Search phrase words are
matched to hyponyms, synonyms and instances from within documents being
searched.
This class is designed for small ontologies that have been constructed
by hand for specific use cases. Where the aim is to model a large number
of semantic relationships, word embeddings are likely to offer
better results.
Holmes is not designed to support changes to a loaded ontology via direct
calls to the methods of this class. It is also not permitted to share a single instance
of this class between multiple Manager instances: instead, a separate Ontology instance
pointing to the same path should be created for each Manager.
Matching is case-insensitive.
Parameters:
ontology_path -- the path from where the ontology is to be loaded,
or a list of several such paths. See https://github.com/RDFLib/rdflib/.
owl_class_type -- optionally overrides the OWL 2 URL for types.
owl_individual_type -- optionally overrides the OWL 2 URL for individuals.
owl_type_link -- optionally overrides the RDF URL for types.
owl_synonym_type -- optionally overrides the OWL 2 URL for synonyms.
owl_hyponym_type -- optionally overrides the RDF URL for hyponyms.
symmetric_matching -- if 'True', means hypernym relationships are also taken into account.
SupervisedTopicTrainingBasis (returned from Manager.get_supervised_topic_training_basis() )Holder object for training documents and their classifications from which one or more SupervisedTopicModelTrainer objects can be derived. This class is NOT threadsafe.
SupervisedTopicTrainingBasis.parse_and_register_training_document(self, text:str, classification:str,
label:Optional[str]=None) -> None
Parses and registers a document to use for training.
Parameters:
text -- the document text
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_training_document(self, doc:Doc, classification:str,
label:Optional[str]=None) -> None
Registers a pre-parsed document to use for training.
Parameters:
doc -- the document
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_additional_classification_label(self, label:str) -> None
Register an additional classification label which no training document possesses explicitly
but that should be assigned to documents whose explicit labels are related to the
additional classification label via the classification ontology.
SupervisedTopicTrainingBasis.prepare(self) -> None
Matches the phraselets derived from the training documents against the training
documents to generate frequencies that also include combined labels, and examines the
explicit classification labels, the additional classification labels and the
classification ontology to derive classification implications.
Once this method has been called, the instance no longer accepts new training documents
or additional classification labels.
SupervisedTopicTrainingBasis.train(
self,
*,
minimum_occurrences: int = 4,
cv_threshold: float = 1.0,
learning_rate: float = 0.001,
batch_size: int = 5,
max_epochs: int = 200,
convergence_threshold: float = 0.0001,
hidden_layer_sizes: Optional[List[int]] = None,
shuffle: bool = True,
normalize: bool = True
) -> SupervisedTopicModelTrainer:
Trains a model based on the prepared state.
Parameters:
minimum_occurrences -- the minimum number of times a word or relationship has to
occur in the context of the same classification for the phraselet
to be accepted into the final model.
cv_threshold -- the minimum coefficient of variation with which a word or relationship has
to occur across the explicit classification labels for the phraselet to be
accepted into the final model.
learning_rate -- the learning rate for the Adam optimizer.
batch_size -- the number of documents in each training batch.
max_epochs -- the maximum number of training epochs.
convergence_threshold -- the threshold below which loss measurements after consecutive
epochs are regarded as equivalent. Training stops before 'max_epochs' is reached
if equivalent results are achieved after four consecutive epochs.
hidden_layer_sizes -- a list containing the number of neurons in each hidden layer, or
'None' if the topology should be determined automatically.
shuffle -- 'True' if documents should be shuffled during batching.
normalize -- 'True' if normalization should be applied to the loss function.
SupervisedTopicModelTrainer (returned from SupervisedTopicTrainingBasis.train() ) Worker object used to train and generate models. This object could be removed from the public interface ( SupervisedTopicTrainingBasis.train() could return a SupervisedTopicClassifier directly) but has been retained to facilitate testability.
This class is NOT threadsafe.
SupervisedTopicModelTrainer.classifier(self)
Returns a supervised topic classifier which contains no explicit references to the training data and that
can be serialized.
SupervisedTopicClassifier (returned from SupervisedTopicModelTrainer.classifier() and Manager.deserialize_supervised_topic_classifier() ))
SupervisedTopicClassifier.def parse_and_classify(self, text: str) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
text -- the text to parse and classify.
SupervisedTopicClassifier.classify(self, doc: Doc) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
doc -- the pre-parsed document to classify.
SupervisedTopicClassifier.serialize_model(self) -> str
Returns a serialized model that can be reloaded using
*Manager.deserialize_supervised_topic_classifier()*
Manager.match() A text-only representation of a match between a search phrase and a
document. The indexes refer to tokens.
Properties:
search_phrase_label -- the label of the search phrase.
search_phrase_text -- the text of the search phrase.
document -- the label of the document.
index_within_document -- the index of the match within the document.
sentences_within_document -- the raw text of the sentences within the document that matched.
negated -- 'True' if this match is negated.
uncertain -- 'True' if this match is uncertain.
involves_coreference -- 'True' if this match was found using coreference resolution.
overall_similarity_measure -- the overall similarity of the match, or
'1.0' if embedding-based matching was not involved in the match.
word_matches -- an array of dictionaries with the properties:
search_phrase_token_index -- the index of the token that matched from the search phrase.
search_phrase_word -- the string that matched from the search phrase.
document_token_index -- the index of the token that matched within the document.
first_document_token_index -- the index of the first token that matched within the document.
Identical to 'document_token_index' except where the match involves a multiword phrase.
last_document_token_index -- the index of the last token that matched within the document
(NOT one more than that index). Identical to 'document_token_index' except where the match
involves a multiword phrase.
structurally_matched_document_token_index -- the index of the token within the document that
structurally matched the search phrase token. Is either the same as 'document_token_index' or
is linked to 'document_token_index' within a coreference chain.
document_subword_index -- the index of the token subword that matched within the document, or
'None' if matching was not with a subword but with an entire token.
document_subword_containing_token_index -- the index of the document token that contained the
subword that matched, which may be different from 'document_token_index' in situations where a
word containing multiple subwords is split by hyphenation and a subword whose sense
contributes to a word is not overtly realised within that word.
document_word -- the string that matched from the document.
document_phrase -- the phrase headed by the word that matched from the document.
match_type -- 'direct', 'derivation', 'entity', 'embedding', 'ontology', 'entity_embedding'
or 'question'.
negated -- 'True' if this word match is negated.
uncertain -- 'True' if this word match is uncertain.
similarity_measure -- for types 'embedding' and 'entity_embedding', the similarity between the
two tokens, otherwise '1.0'.
involves_coreference -- 'True' if the word was matched using coreference resolution.
extracted_word -- within the coreference chain, the most specific term that corresponded to
the document_word.
depth -- the number of hyponym relationships linking 'search_phrase_word' and
'extracted_word', or '0' if ontology-based matching is not active. Can be negative
if symmetric matching is active.
explanation -- creates a human-readable explanation of the word match from the perspective of the
document word (e.g. to be used as a tooltip over it).
Manager.topic_match_documents_against() A text-only representation of a topic match between a search text and a document.
Properties:
document_label -- the label of the document.
text -- the document text that was matched.
text_to_match -- the search text.
rank -- a string representation of the scoring rank which can have the form e.g. '2=' in case of a tie.
index_within_document -- the index of the document token where the activation peaked.
subword_index -- the index of the subword within the document token where the activation peaked, or
'None' if the activation did not peak at a specific subword.
start_index -- the index of the first document token in the topic match.
end_index -- the index of the last document token in the topic match (NOT one more than that index).
sentences_start_index -- the token start index within the document of the sentence that contains
'start_index'
sentences_end_index -- the token end index within the document of the sentence that contains
'end_index' (NOT one more than that index).
sentences_character_start_index_in_document -- the character index of the first character of 'text'
within the document.
sentences_character_end_index_in_document -- one more than the character index of the last
character of 'text' within the document.
score -- the score
word_infos -- an array of arrays with the semantics:
[0] -- 'relative_start_index' -- the index of the first character in the word relative to
'sentences_character_start_index_in_document'.
[1] -- 'relative_end_index' -- one more than the index of the last character in the word
relative to 'sentences_character_start_index_in_document'.
[2] -- 'type' -- 'single' for a single-word match, 'relation' if within a relation match
involving two words, 'overlapping_relation' if within a relation match involving three
or more words.
[3] -- 'is_highest_activation' -- 'True' if this was the word at which the highest activation
score reported in 'score' was achieved, otherwise 'False'.
[4] -- 'explanation' -- a human-readable explanation of the word match from the perspective of
the document word (e.g. to be used as a tooltip over it).
answers -- an array of arrays with the semantics:
[0] -- the index of the first character of a potential answer to an initial question word.
[1] -- one more than the index of the last character of a potential answer to an initial question
word.
Earlier versions of Holmes could only be published under a restrictive license because of patent issues. As explained in the introduction, this is no longer the case thanks to the generosity of AstraZeneca: versions from 4.0.0 onwards are licensed under the MIT license.
The word-level matching and the high-level operation of structural matching between search-phrase and document subgraphs both work more or less as one would expect. What is perhaps more in need of further comment is the semantic analysis code subsumed in the parsing.py script as well as in the language_specific_rules.py script for each language.
SemanticAnalyzer is an abstract class that is subclassed for each language: at present by EnglishSemanticAnalyzer and GermanSemanticAnalyzer . These classes contain most of the semantic analysis code. SemanticMatchingHelper is a second abstract class, again with an concrete implementation for each language, that contains semantic analysis code that is required at matching time. Moving this out to a separate class family was necessary because, on operating systems that spawn processes rather than forking processes (eg Windows), SemanticMatchingHelper instances have to be serialized when the worker processes are created: this would not be possible for SemanticAnalyzer instances because not all spaCy models are serializable, and would also unnecessarily consume large amounts of memory.
At present, all functionality that is common to the two languages is realised in the two abstract parent classes. Especially because English and German are closely related languages, it is probable that functionality will need to be moved from the abstract parent classes to specific implementing children classes if and when new semantic analyzers are added for new languages.
The HolmesDictionary class is defined as a spaCy extension attribute that is accessed using the syntax token._.holmes . The most important information in the dictionary is a list of SemanticDependency objects. These are derived from the dependency relationships in the spaCy output ( token.dep_ ) but go through a considerable amount of processing to make them 'less syntactic' and 'more semantic'. To give but a few examples:
Some new semantic dependency labels that do not occur in spaCy outputs as values of token.dep_ are added for Holmes semantic dependencies. It is important to understand that Holmes semantic dependencies are used exclusively for matching and are therefore neither intended nor required to form a coherent set of linguistic theoretical entities or relationships; whatever works best for matching is assigned on an ad-hoc basis.
For each language, the match_implication_dict dictionary maps search-phrase semantic dependencies to matching document semantic dependencies and is responsible for the asymmetry of matching between search phrases and documents.
Topic matching involves the following steps:
SemanticMatchingHelper.topic_matching_phraselet_stop_lemmas ), which are consistently ignored throughout the whole process.SemanticMatchingHelper.phraselet_templates .SemanticMatchingHelper.topic_matching_reverse_only_parent_lemmas ) or when the frequency factor for the parent word is below the threshold for relation matching ( relation_matching_frequency_threshold , default: 0.25). These measures are necessary because matching on eg a parent preposition would lead to a large number of potential matches that would take a lot of resources to investigate: it is better to start investigation from the less frequent word within a given relation.relation_matching_frequency_threshold , default: 0.25).embedding_matching_frequency_threshold , default: 0.5), matching at all of those words where the relation template has not already been matched is retried using embeddings at the other word within the relation. A pair of words is then regarded as matching when their mutual cosine similarity is above initial_question_word_embedding_match_threshold (default: 0.7) in situations where the document word has an initial question word in its phrase or word_embedding_match_threshold (default: 0.8) in all other situations.use_frequency_factor is set to True (the default), each score is scaled by the frequency factor of its phraselet, meaning that words that occur less frequently in the corpus give rise to higher scores.maximum_activation_distance ; default: 75) of its value is subtracted from it as each new word is read.single_word_score ; default: 50), a non-noun single-word phraselet or a noun phraselet that matched a subword ( single_word_any_tag_score ; default: 20), a relation phraselet produced by a reverse-only template ( reverse_only_relation_score ; default: 200), any other (normally matched) relation phraselet ( relation_score ; default: 300), or a relation phraselet involving an initial question word ( initial_question_word_answer_score ; default: 600).embedding_penalty ; default: 0.6).ontology_penalty ; default: 0.9) once more often than the difference in depth between the two ontology entries, ie once for a synonym, twice for a child, three times for a grandchild and so on.overlapping_relation_multiplier ; default: 1.5).sideways_match_extent ; default: 100 words) within which the activation score is higher than the different_match_cutoff_score (default: 15) are regarded as belonging to a contiguous passage around the peak that is then returned as a TopicMatch object. (Note that this default will almost certainly turn out to be too low if use_frequency_factor is set to False .) A word whose activation equals the threshold exactly is included at the beginning of the area as long as the next word where activation increases has a score above the threshold. If the topic match peak is below the threshold, the topic match will only consist of the peak word.initial_question_word_behaviour is set to process (the default) or to exclusive , where a document word has matched an initial question word from the query phrase, the subtree of the matched document word is identified as a potential answer to the question and added to the dictionary to be returned. If initial_question_word_behaviour is set to exclusive , any topic matches that do not contain answers to initial question words are discarded.only_one_result_per_document = True prevents more than one result from being returned from the same document; only the result from each document with the highest score will then be returned.tied_result_quotient (default: 0.9) are labelled as tied. The supervised document classification use case relies on the same phraselets as the topic matching use case, although reverse-only templates are ignored and a different set of stop words is used ( SemanticMatchingHelper.supervised_document_classification_phraselet_stop_lemmas ). Classifiers are built and trained as follows:
oneshot ; whether single-word phraselets are generated for all words with their own meaning or only for those such words whose part-of-speech tags match the single-word phraselet template specification (essentially: noun phraselets) depends on the value of match_all_words . Wherever two phraselet matches overlap, a combined match is recorded. Combined matches are treated in the same way as other phraselet matches in further processing. This means that effectively the algorithm picks up one-word, two-word and three-word semantic combinations. See here for a discussion of the performance of this step.minimum_occurrences ; default: 4) or where the coefficient of variation (the standard deviation divided by the arithmetic mean) of the occurrences across the categories is below a threshold ( cv_threshold ; default: 1.0).oneshot==True vs. oneshot==False respectively). The outputs are the category labels, including any additional labels determined via a classification ontology. By default, the multilayer perceptron has three hidden layers where the first hidden layer has the same number of neurons as the input layer and the second and third layers have sizes in between the input and the output layer with an equally sized step between each size; the user is however free to specify any other topology.Holmes code is formatted with black.
The complexity of what Holmes does makes development impossible without a robust set of over 1400 regression tests. These can be executed individually with unittest or all at once by running the pytest utility from the Holmes source code root directory. (Note that the Python 3 command on Linux is pytest-3 .)
The pytest variant will only work on machines with sufficient memory resources. To reduce this problem, the tests are distributed across three subdirectories, so that pytest can be run three times, once from each subdirectory:
New languages can be added to Holmes by subclassing the SemanticAnalyzer and SemanticMatchingHelper classes as explained here.
The sets of matching semantic dependencies captured in the _matching_dep_dict dictionary for each language have been obtained on the basis of a mixture of linguistic-theoretical expectations and trial and error. The results would probably be improved if the _matching_dep_dict dictionaries could be derived using machine learning instead; as yet this has not been attempted because of the lack of appropriate training data.
An attempt should be made to remove personal data from supervised document classification models to make them more compliant with data protection laws.
In cases where embedding-based matching is not active, the second step of the supervised document classification procedure repeats a considerable amount of processing from the first step. Retaining the relevant information from the first step of the procedure would greatly improve training performance. This has not been attempted up to now because a large number of tests would be required to prove that such performance improvements did not have any inadvertent impacts on functionality.
The topic matching and supervised document classification use cases are both configured with a number of hyperparameters that are presently set to best-guess values derived on a purely theoretical basis. Results could be further improved by testing the use cases with a variety of hyperparameters to learn the optimal values.
The initial open-source version.
pobjp linking parents of prepositions directly with their children.MultiprocessingManager object as its facade.Manager and MultiprocessingManager classes into a single Manager class, with a redesigned public interface, that uses worker threads for everything except supervised document classification.

