holmes extractor
Holmes 4.0.0
Автор: Ричард Пол Хадсон, взрыв AI
Managermanager.nlpOntologySupervisedTopicTrainingBasis (возвращен из Manager.get_supervised_topic_training_basis() )SupervisedTopicModelTrainer (возвращен из SupervisedTopicTrainingBasis.train() )SupervisedTopicClassifier (возвращается из SupervisedTopicModelTrainer.classifier() и Manager.deserialize_supervised_topic_classifier() )Manager.match()Manager.topic_match_documents_against()Холмс - это библиотека Python 3 (v3.6 - V3.10), работающая на вершине Spacy (v3.1 - V3.3), которая поддерживает ряд вариантов использования, связанных с извлечением информации из английских и немецких текстов. Во всех случаях использования извлечение информации основана на анализе семантических отношений, выраженных компонентами частей каждого предложения:
В случае использования чат -бота система настроена с использованием одной или нескольких поисковых фраз . Затем Холмс ищет структуры, чьи значения соответствуют значениям этих поисковых фраз в поисковом документе , который в данном случае соответствует отдельному фрагменту текста или речи, введенной конечным пользователем. В рамках соответствия каждое слово со своим собственным значением (то есть, которое не просто выполняет грамматическую функцию) в поисковой фразе соответствует одному или нескольким таким словам в документе. И тот факт, что поисковая фраза была сопоставлена, и любая структурированная информация, которую извлечение поисковой фразы можно использовать для управления чат -ботом.
В случае использования структурных извлечений используется точно такая же технология сопоставления структурного сопоставления, что и вариант использования чат-ботов, но поиск происходит в отношении ранее существовавшего документа или документов, которые обычно намного длиннее, чем фрагменты, проанализированные в варианте использования чат-ботов, и цель состоит в том, чтобы извлечь и хранить структурированную информацию. Например, можно найти набор деловых статей, чтобы найти все места, где, как говорят, одна компания планирует взять вторую компанию. Личность соответствующих компаний может затем храниться в базе данных.
В случае использования темы используются отрывки в документе или документах, значение которого близко к значению другого документа, который принимает роль документа запроса или к той фразе запроса, введенной пользователем. Холмс извлекает ряд небольших фразетов из фразы запроса или документа запроса, соответствует документам, которые искают по каждому фраселе и связывают результаты, чтобы найти наиболее важные отрывки в документах. Поскольку нет строгого требования, чтобы каждое слово со своим собственным значением в документе запроса соответствовало конкретному слову или словам в поисковых документах, обнаружено больше совпадений, чем в случае использования структурной извлечения, но совпадения не содержат структурированную информацию, которую можно использовать при последующей обработке. В случае использования темы продемонстрируется веб -сайт, разрешающий поиск в шести романах Чарльза Диккенса (для английского) и около 350 традиционных историй (для немецкого языка).
В случае использования классификации документов используются учебные данные для изучения классификатора, который назначает одну или несколько ярлыков классификации новым документам на основе того, о чем они. Он классифицирует новый документ, сопоставляя его против фразетов, которые были извлечены из учебных документов так же, как фразеты извлекаются из документа запроса в примере использования темы. Техника вдохновлена алгоритмами классификации на основе пакетов слов, которые используют N-граммы, но направлены на получение N-граммов, компонентные слова, семантически связанные с ним, а не соседями на поверхности языка.
Во всех четырех вариантах использования отдельные слова сопоставляются с использованием ряда стратегий. Чтобы понять, соответствуют ли две грамматические структуры, которые содержат индивидуально соответствующие слова, логически и составляют совпадение, Холмс преобразует синтаксическую информацию, предоставленную библиотекой SPACY в семантические структуры, которые позволяют сравнивать тексты с использованием предикатной логики. Как пользователь Холмса, вам не нужно понимать тонкости того, как это работает, хотя есть несколько важных советов о написании эффективных поисковых фраз для чат -бота и вариантов использования структурных извлечений, которые вы должны попробовать и принять на борт.
Холмс стремится предложить обобщенные решения, которые можно использовать более или менее из коробки с относительно небольшим количеством настройки, настройки или обучения, которые быстро применимы к широкому спектру вариантов использования. В его ядро лежит логичная, запрограммированная система, основанная на правилах, которая описывает, как синтаксические представления в каждом языке выражают семантические отношения. Несмотря на то, что в качестве контролируемой классификации документов есть нейронная сеть, и, хотя библиотека Spacy, на которой Holmes Builds сама была предварительно обучена с использованием машинного обучения, по существу, основанная на правилах природа Холмса, означает, что чат-бот, структурная экстракция и совместная тема Реальные проблемы.
Холмс имеет долгую и сложную историю, и теперь мы можем опубликовать ее по лицензии MIT благодаря доброй воле и открытости нескольких компаний. Я, Ричард Хадсон, написал версии до 3,0.0 во время работы в MSG Systems, крупной международной программной консультации, расположенной недалеко от Мюнхена. В конце 2021 года я сменил работодателей и теперь работаю на взрыв, создателей Spacy и Prodigy. Элементы библиотеки Холмса освещаются американским патентом, который я сам написал в начале 2000 -х годов, работая в стартапе под названием Definiens, который с тех пор был приобретен Astrazeneca. С добравым разрешением систем Astrazeneca и MSG, я теперь поддерживаю Холмса при взрыве и могу предложить его впервые по разрешающей лицензии: любой теперь может использовать Холмс в условиях лицензии MIT, не беспокоясь о патенте.
Первоначально библиотека была разработана в MSG Systems, но в настоящее время поддерживается на Aroposion AI. Пожалуйста, направьте любые новые вопросы или обсуждения в репозиторий взрыва.
Если у вас еще нет Python 3 и PIP на вашей машине, вам нужно будет установить их перед установкой Холмса.
Установите Холмс, используя следующие команды:
Linux:
pip3 install holmes-extractor
Windows:
pip install holmes-extractor
Чтобы обновить из предыдущей версии Holmes, выпустите следующие команды, а затем переиздайте команды для загрузки моделей Spacy и Coreferee, чтобы убедиться, что у вас есть правильные версии:
Linux:
pip3 install --upgrade holmes-extractor
Windows:
pip install --upgrade holmes-extractor
Если вы хотите использовать примеры и тесты, клонируйте исходный код, используя
git clone https://github.com/explosion/holmes-extractor
Если вы хотите экспериментировать с изменением исходного кода, вы можете переопределить установленный код, запустив Python (введите python3 (Linux) или python (Windows)) в родительском каталоге каталога, где является ваш измененный код модуля holmes_extractor . Если вы проверили Холмса из GIT, это будет каталог holmes-extractor .
Если вы хотите снова удалить Холмса, это достигается путем удаления установленного файла (ы) непосредственно из файловой системы. Они могут быть найдены путем выпуска следующего из командной строки Python, начатой из любого каталога, отличного от родительского каталога holmes_extractor :
import holmes_extractor
print(holmes_extractor.__file__)
Библиотеки Spacy и Coreferee, которые Холмс создает на требуемых языковых моделях, которые необходимо загрузить отдельно, прежде чем можно будет использовать Холмс:
Linux/English:
python3 -m spacy download en_core_web_trf
python3 -m spacy download en_core_web_lg
python3 -m coreferee install en
Linux/German:
pip3 install spacy-lookups-data # (from spaCy 3.3 onwards)
python3 -m spacy download de_core_news_lg
python3 -m coreferee install de
Windows/English:
python -m spacy download en_core_web_trf
python -m spacy download en_core_web_lg
python -m coreferee install en
Windows/German:
pip install spacy-lookups-data # (from spaCy 3.3 onwards)
python -m spacy download de_core_news_lg
python -m coreferee install de
И если вы планируете провести регрессионные тесты:
Linux:
python3 -m spacy download en_core_web_sm
Windows:
python -m spacy download en_core_web_sm
Вы указываете модель Spacy для использования Holmes, когда вы создаете экземпляр класса Facade Manager. en_core_web_trf и de_core_web_lg - это модели, которые, как было установлено, дают наилучшие результаты для английского и немецкого языка соответственно. Поскольку en_core_web_trf не имеет собственных векторов слов, но Холмс требуется векторы слов для встраивания на основе на основе на основе внедрения, модель en_core_web_lg загружается в качестве векторного источника всякий раз, когда en_core_web_trf указывается в класс менеджера в качестве основной модели.
Модель en_core_web_trf требует достаточно ресурсов, чем другие модели; В той мере, где ресурсы мало, это может быть разумным компромиссом использовать en_core_web_lg в качестве основной модели.
Лучший способ интеграции Холмса в не питотонную среду-это обернуть его как спокойную службу HTTP и развернуть его как микросервис. Смотрите здесь для примера.
Поскольку Холмс выполняет сложный, интеллектуальный анализ, неизбежно, что ему требуется больше аппаратных ресурсов, чем более традиционные поисковые рамки. Варианты использования, которые включают загрузку документов - структурное извлечение и сопоставление тем - наиболее сразу применимы к крупным, но не массовым корпусам (например, все документы, принадлежащие определенной организации, все патенты на определенную тему, все книги определенного автора). По причинам стоимости Холмс не будет подходящим инструментом для анализа содержания всего Интернета!
Тем не менее, Холмс как вертикально, так и горизонтально масштабируется. При достаточном оборудовании оба эти варианты использования могут быть применены к существенно неограниченному количеству документов, используя Холмс на нескольких машинах, обрабатывая различный набор документов на каждом из них и связывая результаты. Обратите внимание, что эта стратегия уже используется для распространения сопоставления между несколькими ядрами на одной машине: класс менеджера запускает ряд рабочих процессов и распределяет зарегистрированные документы между ними.
Холмс держит загруженные документы в памяти, что связано с его предполагаемым использованием с большими, но не массовыми корпусами. Производительность загрузки документов, извлечения структурной и сопоставления тем, все сильно разлагается, если операционная система должна обмениваться страницами памяти на вторичное хранилище, потому что Холмс может потребовать памяти от множества страниц, которые должны быть адресованы при обработке одного предложения. Это означает, что важно поставлять достаточно оперативной памяти на каждой машине, чтобы держать все загруженные документы.
Обратите внимание на приведенные выше комментарии об относительных требованиях к ресурсам различных моделей.
Самый простой вариант использования, с помощью которого можно быстро получить базовое представление о том, как работает Холмс, - это вариант использования чат -ботов .
Здесь одна или несколько поисковых фраз определяются для Холмса заранее, и поисковые документы представляют собой короткие предложения или абзацы, вводимые в интерактивно конечным пользователем. В реальной жизни извлеченная информация будет использоваться для определения потока взаимодействия с конечным пользователем. В целях тестирования и демонстрации существует консоль, которая отображает ее соответствующие результаты интерактивно. Он может быть легко и быстро запустить из командной строки Python (которая сама запускается с подсказки операционной системы путем ввода python3 (Linux) или python (Windows)) или из ноутбука Jupyter.
Следующий фрагмент кода может быть введена строка для строки в командную строку Python, в ноутбук Jupyter или в IDE. Он регистрирует тот факт, что вы заинтересованы в предложениях о больших собаках, преследующих кошек, и начинает демонстрационную консоли чат -бота:
Английский:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='en_core_web_lg', number_of_workers=1)
holmes_manager.register_search_phrase('A big dog chases a cat')
holmes_manager.start_chatbot_mode_console()
Немецкий:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='de_core_news_lg', number_of_workers=1)
holmes_manager.register_search_phrase('Ein großer Hund jagt eine Katze')
holmes_manager.start_chatbot_mode_console()
Если вы теперь введете предложение, которое соответствует поисковой фразе, консоль отобразит совпадение:
Английский:
Ready for input
A big dog chased a cat
Matched search phrase with text 'A big dog chases a cat':
'big'->'big' (Matches BIG directly); 'A big dog'->'dog' (Matches DOG directly); 'chased'->'chase' (Matches CHASE directly); 'a cat'->'cat' (Matches CAT directly)
Немецкий:
Ready for input
Ein großer Hund jagte eine Katze
Matched search phrase 'Ein großer Hund jagt eine Katze':
'großer'->'groß' (Matches GROSS directly); 'Ein großer Hund'->'hund' (Matches HUND directly); 'jagte'->'jagen' (Matches JAGEN directly); 'eine Katze'->'katze' (Matches KATZE directly)
Это могло легко быть достигнуто с помощью простого алгоритма подходящего, поэтому введите несколько более сложных предложений, чтобы убедить себя в том, что Холмс действительно хватает их, и что совпадения все еще возвращаются:
Английский:
The big dog would not stop chasing the cat
The big dog who was tired chased the cat
The cat was chased by the big dog
The cat always used to be chased by the big dog
The big dog was going to chase the cat
The big dog decided to chase the cat
The cat was afraid of being chased by the big dog
I saw a cat-chasing big dog
The cat the big dog chased was scared
The big dog chasing the cat was a problem
There was a big dog that was chasing a cat
The cat chase by the big dog
There was a big dog and it was chasing a cat.
I saw a big dog. My cat was afraid of being chased by the dog.
There was a big dog. His name was Fido. He was chasing my cat.
A dog appeared. It was chasing a cat. It was very big.
The cat sneaked back into our lounge because a big dog had been chasing her.
Our big dog was excited because he had been chasing a cat.
Немецкий:
Der große Hund hat die Katze ständig gejagt
Der große Hund, der müde war, jagte die Katze
Die Katze wurde vom großen Hund gejagt
Die Katze wurde immer wieder durch den großen Hund gejagt
Der große Hund wollte die Katze jagen
Der große Hund entschied sich, die Katze zu jagen
Die Katze, die der große Hund gejagt hatte, hatte Angst
Dass der große Hund die Katze jagte, war ein Problem
Es gab einen großen Hund, der eine Katze jagte
Die Katzenjagd durch den großen Hund
Es gab einmal einen großen Hund, und er jagte eine Katze
Es gab einen großen Hund. Er hieß Fido. Er jagte meine Katze
Es erschien ein Hund. Er jagte eine Katze. Er war sehr groß.
Die Katze schlich sich in unser Wohnzimmer zurück, weil ein großer Hund sie draußen gejagt hatte
Unser großer Hund war aufgeregt, weil er eine Katze gejagt hatte
Демонстрация не завершена, не пробуя другие предложения, которые содержат одни и те же слова, но не выражают ту же идею и не замечая, что они не соответствуют:
Английский:
The dog chased a big cat
The big dog and the cat chased about
The big dog chased a mouse but the cat was tired
The big dog always used to be chased by the cat
The big dog the cat chased was scared
Our big dog was upset because he had been chased by a cat.
The dog chase of the big cat
Немецкий:
Der Hund jagte eine große Katze
Die Katze jagte den großen Hund
Der große Hund und die Katze jagten
Der große Hund jagte eine Maus aber die Katze war müde
Der große Hund wurde ständig von der Katze gejagt
Der große Hund entschloss sich, von der Katze gejagt zu werden
Die Hundejagd durch den große Katze
В приведенных выше примерах Холмс соответствовал различным структурам на уровне предложений, которые имеют одно и то же значение, но базовые формы трех слов в соответствующих документах всегда были такими же, как и три слова в поисковой фразе. Холмс предоставляет несколько дополнительных стратегий для сопоставления на индивидуальном уровне слова. В сочетании с способностью Холмса соответствовать различным структурам предложений, они могут позволить поисковой фразе соответствовать предложению документа, которое разделяет его значение даже там, где они не разделяют слова и грамматически совершенно разные.
Одна из этих дополнительных стратегий сочетания слов называется «Сопоставление»: особые слова могут быть включены в поисковые фразы, которые соответствуют целым классам имен, как люди или места. Выйдите из консоли, набрав exit , затем зарегистрируйте вторую поисковую фразу и перезапустите консоли:
Английский:
holmes_manager.register_search_phrase('An ENTITYPERSON goes into town')
holmes_manager.start_chatbot_mode_console()
Немецкий:
holmes_manager.register_search_phrase('Ein ENTITYPER geht in die Stadt')
holmes_manager.start_chatbot_mode_console()
Сейчас вы зарегистрировали свой интерес к людям, идущим в город и можете ввести соответствующие предложения в консоли:
Английский:
Ready for input
I met Richard Hudson and John Doe last week. They didn't want to go into town.
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'John Doe'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
Немецкий:
Ready for input
Letzte Woche sah ich Richard Hudson und Max Mustermann. Sie wollten nicht mehr in die Stadt gehen.
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Max Mustermann'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
На каждом из двух языков этот последний пример демонстрирует несколько дополнительных особенностей Холмса:
Для получения дополнительных примеров см. Раздел 5.
Следующие стратегии реализованы с одним модулем Python на стратегию. Хотя стандартная библиотека не поддерживает добавление стратегий на заказ через класс менеджера, для любого, у кого есть навыки программирования Python, было бы относительно легко изменить код, чтобы включить это.
word_match.type=='direct' )Прямое сопоставление между поисковыми словами и словами документов всегда активно. Стратегия опирается в основном на сопоставлении форм слов STEM, например, с подходящей английской покупкой и ребенком для купленных и детей , немецкой Steigen и добром к Stieg и Kinder . Однако, чтобы увеличить вероятность непосредственного сопоставления работы, когда анализатор обеспечивает неверную форму STEM для слова, необработанные формы как поисковой фразы, так и слов документов также учитываются во время прямого сопоставления.
word_match.type=='derivation' ) Соответствие на основе выводов включает в себя различные, но связанные слова, которые обычно принадлежат к разным классам слов, например, оценке и оценке английского языка, немецкой Jagen и Jagd . По умолчанию он активен, но может быть отключен с помощью параметра analyze_derivational_morphology , который устанавливается при создании класса Manager.
word_match.type=='entity' )Сопоставление названного суда активируется путем вставки специального идентификатора с именем в желаемой точке в поисковой фразе вместо существительного, например,
Субъект лиц отправляется в город (английский)
Ein Entityper Geht в Die Stadt (немецкий).
Поддерживаемые идентификаторы названных факторов напрямую зависят от информации о названном энте, предоставленной моделями Spacy для каждого языка (описания, скопированные из более ранней версии документации Spacy):
Английский:
| Идентификатор | Значение |
|---|---|
| Entitynoun | Любая существительная фраза. |
| Субъект | Люди, в том числе вымышленные. |
| EntityNorp | Национальности или религиозные или политические группы. |
| Entityfac | Здания, аэропорты, автомагистрали, мосты и т. Д. |
| Entityorg | Компании, агентства, учреждения и т. Д. |
| EntityGPE | Страны, города, штаты. |
| EntityLoc | Не-GPE местоположения, горные хребты, тела воды. |
| EntityProduct | Объекты, транспортные средства, продукты питания и т. Д. (Не услуги.) |
| EntityEvent | Названные ураганы, битвы, войны, спортивные мероприятия и т. Д. |
| EntityWork_of_art | Названия книг, песен и т. Д. |
| Entitylaw | Названные документы, превращенные в законы. |
| EntityLanguage | Любой названный язык. |
| EntityDate | Абсолютные или относительные даты или периоды. |
| Entitytime | Раз меньше дня. |
| Entitypercent | Процент, включая «%». |
| Entitymoney | Денежные значения, включая единицу. |
| Entityquantity | Измерения, на расстоянии веса или расстояния. |
| Entityordinal | "Первый", "второй" и т. Д. |
| EntityCardinal | Цифры, которые не попадают под другой тип. |
Немецкий:
| Идентификатор | Значение |
|---|---|
| Entitynoun | Любая существительная фраза. |
| Entityper | Названный человек или семья. |
| EntityLoc | Название политического или географически определенного местоположения (города, провинции, страны, международные регионы, тела воды, горы). |
| Entityorg | Названо корпоративным, правительственным или другим организационным объектом. |
| EntityMisc | Разные организации, например, события, национальности, продукты или произведения искусства. |
Мы добавили ENTITYNOUN к подлинным идентификаторам названного суда. Поскольку он соответствует любой существительной фразе, она ведет себя аналогичным образом с общими местоимениями. Различия в том, что ENTITYNOUN должен соответствовать конкретной существительной фразе в документе и что эта конкретная существительная фраза извлечена и доступна для дальнейшей обработки. ENTITYNOUN не поддерживается в рамках использования темы.
word_match.type=='ontology' )Онтология позволяет пользователю определять отношения между словами, которые затем учитываются при сопоставлении документов для поиска фраз. Три соответствующих типа отношений - это гипонимы (что -то является подтипом чего -то), синонимы (что -то означает то же самое, что и названные люди (что -то является конкретным примером чего -то). Три типа отношений иллюстрируются на рисунке 1:
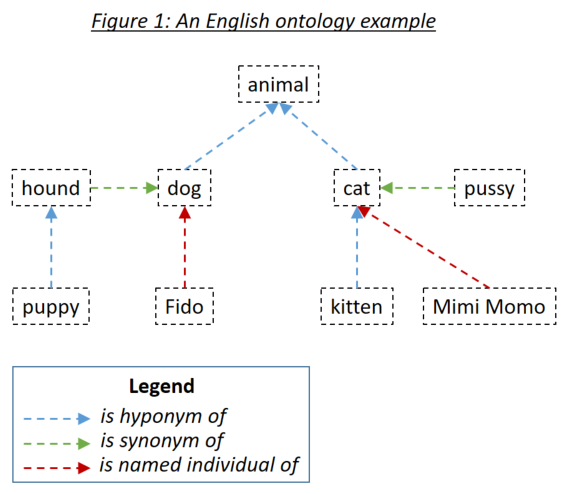
Онтологии определяются для Холмса, используя стандартную сериализованную онтологию OWL с использованием RDF/XML. Такие онтологии могут быть получены с различными инструментами. Для примеров и тестов Холмса использовали свободный протеже инструмента. Рекомендуется использовать Protege как для определения ваших собственных онтологий, так и для просмотра онтологий, которые поставляются с примерами и тестами. При сохранении онтологии под Protege выберите RDF/XML в качестве формата. Protege назначает стандартные этикетки для гипоним, синонима и названных индивидуальных отношений, которые Холмс понимает как знания по умолчанию, но это также может быть переопределено.
Записи онтологии определяются с использованием интернационализированного идентификатора ресурсов (IRI), например, http://www.semanticweb.org/hudsonr/ontologies/2019/0/animals#dog . Холмс использует только окончательный фрагмент для сопоставления, который позволяет определить омонимы (слова с одной и той же формой, но множество значений), чтобы определяться в нескольких точках в дереве онтологии.
Соответствие на основе онтологии дает наилучшие результаты с Холмсом, когда используются небольшие онтологии, которые были созданы для конкретных предметных областей и вариантов использования. Например, если вы внедряете чат -бот для случая использования страхования зданий, вы должны создать небольшую онтологию, захватывающую термины и отношения в этом конкретном домене. С другой стороны, не рекомендуется использовать большие онтологии, созданные для всех доменов на всем языке, таких как Wordnet. Это связано с тем, что многие омонимы и отношения, которые применяются только в узких предметных доменах, будут привести к большому количеству неправильных совпадений. Для общих вариантов использования сопоставление на основе встраивания будет иметь тенденцию приносить лучшие результаты.
Каждое слово в онтологии можно рассматривать как подделение, состоящее из его гипонимы, синонимов и названных людей, гипонимов, синонимов и названных людей и так далее. С помощью онтологии, установленной стандартным способом, подходящей для вариантов использования чат -бота и структурных извлечений, слово в поисковой фразе Холмса соответствует слову в документе, если слово документа находится в поддерево -поисковой фразы. Если бы онтология на рисунке 1 была определена Холмсу, в дополнение к стратегии прямого сопоставления, которая будет соответствовать каждому слову с самим собой, следующие комбинации будут соответствовать:
Английские фразовые глаголы, такие как еда и немецкие отдельные глаголы, такие как Aufessen, должны быть определены как отдельные элементы в онтологии. Когда Холмс анализирует текст и сталкивается с таким глаголом, основной глагол и частица объединяются в одно логическое слово, которое затем можно соответствовать с помощью онтологии. Это означает, что поесть в тексте совпадает с поддереем еды в онтологии, но не поддерева питания в онтологии.
Если совпадение на основе выводов активно, оно учитывается с обеих сторон потенциального матча на основе онтологии. Например, если ALTER и ANDER определяются как синонимы в онтологии, изменение и поправка также совпадают друг с другом.
В ситуациях, когда поиск соответствующих предложений является более важным, чем обеспечение логического соответствия соответствия документа с поисковыми фразами, может иметь смысл указать симметричное сопоставление при определении онтологии. Симметричное сопоставление рекомендуется для использования в соответствии с темами, но вряд ли будет подходящим для вариантов использования чат -бота или структурных извлечений. Это означает, что отношения гипернима (обратный гипоним) принимаются во внимание, а также гипоним и синонимы при сопоставлении, что приводит к более симметричной взаимосвязи между документами и поисковыми фразами. Важным правилом применяется при сопоставлении с помощью симметричной онтологии, заключается в том, что путь совпадения может не содержать как гипернам, так и гипоним, то есть вы не можете вернуться к себе. Была литология выше, определенная как симметричная, следующие комбинации соответствовали бы:
В примере использования классификации документов можно использовать две отдельные онтологии:
Структурное соответствие онтологии используется для анализа содержания как обучения, так и тестовых документов. Каждое слово из документа, который находится в онтологии, заменяется его наиболее общим предком Hypernym. Важно понимать, что онтология может работать со структурным сопоставлением для классификации документов, если она была построена специально для этой цели: такая онтология должна состоять из ряда отдельных деревьев, представляющих основные классы объекта в документах, которые будут классифицированы. В примере онтологии, показанной выше, все слова в онтологии будут заменены животным ; В крайнем случае с онтологией в стиле Wordnet все существительные в конечном итоге будут заменены вещи , что явно не является желательным результатом!
Онтология классификации используется для захвата взаимосвязи между классификационными метками: что документ имеет определенную классификацию, подразумевает, что он также имеет какие -либо классификации, чьи поддерево принадлежит эта классификация. Синонимы должны использоваться экономно, если вообще в классификационных онтологиях, потому что они добавляют сложность нейронной сети без добавления какого -либо значения; И хотя технически возможно настроить классификационную онтологию для использования симметричного сопоставления, нет никакой разумной причины для этого. Обратите внимание, что метка в рамках онтологии классификации, которая не определяется непосредственно как метка любого учебного документа, должна быть зарегистрирована специально с использованием метода SupervisedTopicTrainingBasis.register_additional_classification_label() , если он должен быть принят во внимание при обучении классификатора.
word_match.type=='embedding' )Spacy предлагает встроенные слова : сгенерированные машинным обучением численные векторные представления слов, которые отражают контексты, в которых имеет тенденцию происходить каждое слово. Два слова с аналогичным значением имеют тенденцию появляться со словами, которые близки друг к другу, и Spacy может измерить сходство косинуса между любыми двумя словами в положениях, выраженных как десятичное количество между 0,0 (без сходства) и 1,0 (одно и то же слово). Поскольку собака и кошка , как правило, появляются в аналогичном контексте, они имеют сходство 0,80; Собака и лошадь имеют меньше общего и имеют сходство 0,62; и собака и железо имеют сходство только 0,25. Сопоставление на основе встраивания активируется только для существительных, прилагательных и наречий, потому что результаты были обнаружены неудовлетворительными с другими классами слов.
Важно понимать, что тот факт, что два слова имеют схожие встроенные встроения, не подразумевает одинаковую логическую связь между ними, как при использовании онтологий, основанного на онтологии: например, тот факт, что собака и кошка имеют сходные вторжения, не означает, что собака-это тип кошки или что кошка является типом собаки. Независимо от того, является ли сопоставление на основе встраивания, тем не менее, подходящий выбор зависит от варианта использования функционального использования.
Для чат-бота, структурной извлечения и контролируемой вариантов использования классификации документов, Холмс использует сходство на основе слов с использованием параметра overall_similarity_threshold , определяемого по всему миру в классе менеджера. Соответствие обнаружено между поисковой фразой и структурой в документе всякий раз, когда геометрическое среднее сходства между отдельными парами, соответствующими парами слов, больше, чем этот порог. Интуиция, лежащая в основе этой техники, заключается в том, что там, где поисковая фраза, например, шесть лексических слов соответствовала структуре документа, где пять из этих слов точно соответствуют, и только одно соответствует за внедрение, сходство, которое должно соответствовать этому шестому слову, меньше, чем только три из слов точно соответствуют, а два других слова также соответствуют внедрению.
Сопоставление поисковой фразы с документом начинается с поиска слов в документе, которые соответствуют слову в корне (синтаксическая голова) поисковой фразы. Затем Холмс исследует структуру вокруг каждого из этих сопоставленных слов документов, чтобы проверить, соответствует ли структура документа структуре поисковой фразы в своей собственности. Слова документа, которые соответствуют корне поисковой фразы, обычно встречаются с использованием индекса. Однако, если встраивания необходимо учитывать при поиске слов документов, которые соответствуют корне поисковой фразы, каждое слово в каждом документе с достоверным классом слов следует сравнить для сходства с этим корневым словом поиска. Это имеет очень заметный удар производительности, который отображает все варианты использования, за исключением того, что вариант использования чат -ботов по сути не используется.
Чтобы избежать типично ненужного удара производительности, которая возникает в результате встраивания сопоставления корневых слов поисковой фразы, он контролируется отдельно от сопоставления на основе встраивания в целом с использованием параметра embedding_based_matching_on_root_words , который устанавливается при создании класса менеджера. Вам рекомендуется сохранить эту настройку выключаться (значение False ) для большинства вариантов использования.
Ни overall_similarity_threshold , ни параметр embedding_based_matching_on_root_words не оказывают какого -либо влияния на вариант использования темы. Здесь пороговые значения сходства на уровне слов устанавливаются с использованием параметров word_embedding_match_threshold и initial_question_word_embedding_match_threshold при вызове функции topic_match_documents_against в классе менеджера.
word_match.type=='entity_embedding' ) Совместное матч, основанный на именовании, получается между поисковым сроком, который имеет определенную метку сущности и поисковую фразу или слово документа «Запрос», встраивание которого достаточно похоже на основополагающее значение этого объекта, например, индивидуальное слово в поисковую фразу имеет аналогичное слово в основополагающем значении лейбла лица . Обратите внимание, что сопоставление на основе на основе на основе на основе на основе именных въездов никогда не бывает активным на корневых словах независимо от настройки embedding_based_matching_on_root_words .
word_match.type=='question' )Сопоставление исходного вопроса справедливости активно только во время сопоставления тем. Первоначальные слова в фразах запроса совпадают с объектами в поисковых документах, которые представляют потенциальные ответы на этот вопрос, например, при сравнении фразы запроса , когда Питер позавтракал с поисковой фразой документации Питер в 8 часов утра , вопрос слова , когда соответствовал бы временной нарезной фразе в 8 часов утра .
Сопоставление исходного вопроса по словам, включается и выключается с использованием параметра initial_question_word_behaviour при вызове функции topic_match_documents_against в классе менеджера. It is only likely to be useful when topic matching is being performed in an interactive setting where the user enters short query phrases, as opposed to when it is being used to find documents on a similar topic to an pre-existing query document: initial question words are only processed at the beginning of the first sentence of the query phrase or query document.
Linguistically speaking, if a query phrase consists of a complex question with several elements dependent on the main verb, a finding in a searched document is only an 'answer' if contains matches to all these elements. Because recall is typically more important than precision when performing topic matching with interactive query phrases, however, Holmes will match an initial question word to a searched-document phrase wherever they correspond semantically (eg wherever when corresponds to a temporal adverbial phrase) and each depend on verbs that themselves match at the word level. One possible strategy to filter out 'incomplete answers' would be to calculate the maximum possible score for a query phrase and reject topic matches that score below a threshold scaled to this maximum.
Before Holmes analyses a searched document or query document, coreference resolution is performed using the Coreferee library running on top of spaCy. This means that situations are recognised where pronouns and nouns that are located near one another within a text refer to the same entities. The information from one mention can then be applied to the analysis of further mentions:
I saw a big dog . It was chasing a cat.
I saw a big dog . The dog was chasing a cat.
Coreferee also detects situations where a noun refers back to a named entity:
We discussed AstraZeneca . The company had given us permission to publish this library under the MIT license.
If this example were to match the search phrase A company gives permission to publish something , the coreference information that the company under discussion is AstraZeneca is clearly relevant and worth extracting in addition to the word(s) directly matched to the search phrase. Such information is captured in the word_match.extracted_word field.
The concept of search phrases has already been introduced and is relevant to the chatbot use case, the structural extraction use case and to preselection within the supervised document classification use case.
It is crucial to understand that the tips and limitations set out in Section 4 do not apply in any way to query phrases in topic matching. If you are using Holmes for topic matching only, you can completely ignore this section!
Structural matching between search phrases and documents is not symmetric: there are many situations in which sentence X as a search phrase would match sentence Y within a document but where the converse would not be true. Although Holmes does its best to understand any search phrases, the results are better when the user writing them follows certain patterns and tendencies, and getting to grips with these patterns and tendencies is the key to using the relevant features of Holmes successfully.
Holmes distinguishes between: lexical words like dog , chase and cat (English) or Hund , jagen and Katze (German) in the initial example above; and grammatical words like a (English) or ein and eine (German) in the initial example above. Only lexical words match words in documents, but grammatical words still play a crucial role within a search phrase: they enable Holmes to understand it.
Dog chase cat (English)
Hund jagen Katze (German)
contain the same lexical words as the search phrases in the initial example above, but as they are not grammatical sentences Holmes is liable to misunderstand them if they are used as search phrases. This is a major difference between Holmes search phrases and the search phrases you use instinctively with standard search engines like Google, and it can take some getting used to.
A search phrase need not contain a verb:
ENTITYPERSON (English)
A big dog (English)
Interest in fishing (English)
ENTITYPER (German)
Ein großer Hund (German)
Interesse am Angeln (German)
are all perfectly valid and potentially useful search phrases.
Where a verb is present, however, Holmes delivers the best results when the verb is in the present active , as chases and jagt are in the initial example above. This gives Holmes the best chance of understanding the relationship correctly and of matching the widest range of document structures that share the target meaning.
Sometimes you may only wish to extract the object of a verb. For example, you might want to find sentences that are discussing a cat being chased regardless of who is doing the chasing. In order to avoid a search phrase containing a passive expression like
A cat is chased (English)
Eine Katze wird gejagt (German)
you can use a generic pronoun . This is a word that Holmes treats like a grammatical word in that it is not matched to documents; its sole purpose is to help the user form a grammatically optimal search phrase in the present active. Recognised generic pronouns are English something , somebody and someone and German jemand (and inflected forms of jemand ) and etwas : Holmes treats them all as equivalent. Using generic pronouns, the passive search phrases above could be re-expressed as
Somebody chases a cat (English)
Jemand jagt eine Katze (German).
Experience shows that different prepositions are often used with the same meaning in equivalent phrases and that this can prevent search phrases from matching where one would intuitively expect it. For example, the search phrases
Somebody is at the market (English)
Jemand ist auf dem Marktplatz (German)
would fail to match the document phrases
Richard was in the market (English)
Richard war am Marktplatz (German)
The best way of solving this problem is to define the prepositions in question as synonyms in an ontology.
The following types of structures are prohibited in search phrases and result in Python user-defined errors:
A dog chases a cat. A cat chases a dog (English)
Ein Hund jagt eine Katze. Eine Katze jagt einen Hund (German)
Each clause must be separated out into its own search phrase and registered individually.
A dog does not chase a cat. (Английский)
Ein Hund jagt keine Katze. (Немецкий)
Negative expressions are recognised as such in documents and the generated matches marked as negative; allowing search phrases themselves to be negative would overcomplicate the library without offering any benefits.
A dog and a lion chase a cat. (Английский)
Ein Hund und ein Löwe jagen eine Katze. (Немецкий)
Wherever conjunction occurs in documents, Holmes distributes the information among multiple matches as explained above. In the unlikely event that there should be a requirement to capture conjunction explicitly when matching, this could be achieved by using the Manager.match() function and looking for situations where the document token objects are shared by multiple match objects.
The (English)
Der (German)
A search phrase cannot be processed if it does not contain any words that can be matched to documents.
A dog chases a cat and he chases a mouse (English)
Ein Hund jagt eine Katze und er jagt eine Maus (German)
Pronouns that corefer with nouns elsewhere in the search phrase are not permitted as this would overcomplicate the library without offering any benefits.
The following types of structures are strongly discouraged in search phrases:
Dog chase cat (English)
Hund jagen Katze (German)
Although these will sometimes work, the results will be better if search phrases are expressed grammatically.
A cat is chased by a dog (English)
A dog will have chased a cat (English)
Eine Katze wird durch einen Hund gejagt (German)
Ein Hund wird eine Katze gejagt haben (German)
Although these will sometimes work, the results will be better if verbs in search phrases are expressed in the present active.
Who chases the cat? (Английский)
Wer jagt die Katze? (Немецкий)
Although questions are supported as query phrases in the topic matching use case, they are not appropriate as search phrases. Questions should be re-phrased as statements, in this case
Something chases the cat (English)
Etwas jagt die Katze (German).
Informationsextraktion (German)
Ein Stadtmittetreffen (German)
The internal structure of German compound words is analysed within searched documents as well as within query phrases in the topic matching use case, but not within search phrases. In search phrases, compound words should be reexpressed as genitive constructions even in cases where this does not strictly capture their meaning:
Extraktion der Information (German)
Ein Treffen der Stadtmitte (German)
The following types of structures should be used with caution in search phrases:
A fierce dog chases a scared cat on the way to the theatre (English)
Ein kämpferischer Hund jagt eine verängstigte Katze auf dem Weg ins Theater (German)
Holmes can handle any level of complexity within search phrases, but the more complex a structure, the less likely it becomes that a document sentence will match it. If it is really necessary to match such complex relationships with search phrases rather than with topic matching, they are typically better extracted by splitting the search phrase up, eg
A fierce dog (English)
A scared cat (English)
A dog chases a cat (English)
Something chases something on the way to the theatre (English)
Ein kämpferischer Hund (German)
Eine verängstigte Katze (German)
Ein Hund jagt eine Katze (German)
Etwas jagt etwas auf dem Weg ins Theater (German)
Correlations between the resulting matches can then be established by matching via the Manager.match() function and looking for situations where the document token objects are shared across multiple match objects.
One possible exception to this piece of advice is when embedding-based matching is active. Because whether or not each word in a search phrase matches then depends on whether or not other words in the same search phrase have been matched, large, complex search phrases can sometimes yield results that a combination of smaller, simpler search phrases would not.
The chasing of a cat (English)
Die Jagd einer Katze (German)
These will often work, but it is generally better practice to use verbal search phrases like
Something chases a cat (English)
Etwas jagt eine Katze (German)
and to allow the corresponding nominal phrases to be matched via derivation-based matching.
The chatbot use case has already been introduced: a predefined set of search phrases is used to extract information from phrases entered interactively by an end user, which in this use case act as the documents.
The Holmes source code ships with two examples demonstrating the chatbot use case, one for each language, with predefined ontologies. Having cloned the source code and installed the Holmes library, navigate to the /examples directory and type the following (Linux):
Английский:
python3 example_chatbot_EN_insurance.py
Немецкий:
python3 example_chatbot_DE_insurance.py
or click on the files in Windows Explorer (Windows).
Holmes matches syntactically distinct structures that are semantically equivalent, ie that share the same meaning. In a real chatbot use case, users will typically enter equivalent information with phrases that are semantically distinct as well, ie that have different meanings. Because the effort involved in registering a search phrase is barely greater than the time it takes to type it in, it makes sense to register a large number of search phrases for each relationship you are trying to extract: essentially all ways people have been observed to express the information you are interested in or all ways you can imagine somebody might express the information you are interested in . To assist this, search phrases can be registered with labels that do not need to be unique: a label can then be used to express the relationship an entire group of search phrases is designed to extract. Note that when many search phrases have been defined to extract the same relationship, a single user entry is likely to be sometimes matched by multiple search phrases. This must be handled appropriately by the calling application.
One obvious weakness of Holmes in the chatbot setting is its sensitivity to correct spelling and, to a lesser extent, to correct grammar. Strategies for mitigating this weakness include:
The structural extraction use case uses structural matching in the same way as the chatbot use case, and many of the same comments and tips apply to it. The principal differences are that pre-existing and often lengthy documents are scanned rather than text snippets entered ad-hoc by the user, and that the returned match objects are not used to drive a dialog flow; they are examined solely to extract and store structured information.
Code for performing structural extraction would typically perform the following tasks:
Manager.register_search_phrase() several times to define a number of search phrases specifying the information to be extracted.Manager.parse_and_register_document() several times to load a number of documents within which to search.Manager.match() to perform the matching.The topic matching use case matches a query document , or alternatively a query phrase entered ad-hoc by the user, against a set of documents pre-loaded into memory. The aim is to find the passages in the documents whose topic most closely corresponds to the topic of the query document; the output is a ordered list of passages scored according to topic similarity. Additionally, if a query phrase contains an initial question word, the output will contain potential answers to the question.
Topic matching queries may contain generic pronouns and named-entity identifiers just like search phrases, although the ENTITYNOUN token is not supported. However, an important difference from search phrases is that the topic matching use case places no restrictions on the grammatical structures permissible within the query document.
In addition to the Holmes demonstration website, the Holmes source code ships with three examples demonstrating the topic matching use case with an English literature corpus, a German literature corpus and a German legal corpus respectively. Users are encouraged to run these to get a feel for how they work.
Topic matching uses a variety of strategies to find text passages that are relevant to the query. These include resource-hungry procedures like investigating semantic relationships and comparing embeddings. Because applying these across the board would prevent topic matching from scaling, Holmes only attempts them for specific areas of the text that less resource-intensive strategies have already marked as looking promising. This and the other interior workings of topic matching are explained here.
In the supervised document classification use case, a classifier is trained with a number of documents that are each pre-labelled with a classification. The trained classifier then assigns one or more labels to new documents according to what each new document is about. As explained here, ontologies can be used both to enrichen the comparison of the content of the various documents and to capture implication relationships between classification labels.
A classifier makes use of a neural network (a multilayer perceptron) whose topology can either be determined automatically by Holmes or specified explicitly by the user. With a large number of training documents, the automatically determined topology can easily exhaust the memory available on a typical machine; if there is no opportunity to scale up the memory, this problem can be remedied by specifying a smaller number of hidden layers or a smaller number of nodes in one or more of the layers.
A trained document classification model retains no references to its training data. This is an advantage from a data protection viewpoint, although it cannot presently be guaranteed that models will not contain individual personal or company names.
A typical problem with the execution of many document classification use cases is that a new classification label is added when the system is already live but that there are initially no examples of this new classification with which to train a new model. The best course of action in such a situation is to define search phrases which preselect the more obvious documents with the new classification using structural matching. Those documents that are not preselected as having the new classification label are then passed to the existing, previously trained classifier in the normal way. When enough documents exemplifying the new classification have accumulated in the system, the model can be retrained and the preselection search phrases removed.
Holmes ships with an example script demonstrating supervised document classification for English with the BBC Documents dataset. The script downloads the documents (for this operation and for this operation alone, you will need to be online) and places them in a working directory. When training is complete, the script saves the model to the working directory. If the model file is found in the working directory on subsequent invocations of the script, the training phase is skipped and the script goes straight to the testing phase. This means that if it is wished to repeat the training phase, either the model has to be deleted from the working directory or a new working directory has to be specified to the script.
Having cloned the source code and installed the Holmes library, navigate to the /examples directory. Specify a working directory at the top of the example_supervised_topic_model_EN.py file, then type python3 example_supervised_topic_model_EN (Linux) or click on the script in Windows Explorer (Windows).
It is important to realise that Holmes learns to classify documents according to the words or semantic relationships they contain, taking any structural matching ontology into account in the process. For many classification tasks, this is exactly what is required; but there are tasks (eg author attribution according to the frequency of grammatical constructions typical for each author) where it is not. For the right task, Holmes achieves impressive results. For the BBC Documents benchmark processed by the example script, Holmes performs slightly better than benchmarks available online (see eg here) although the difference is probably too slight to be significant, especially given that the different training/test splits were used in each case: Holmes has been observed to learn models that predict the correct result between 96.9% and 98.7% of the time. The range is explained by the fact that the behaviour of the neural network is not fully deterministic.
The interior workings of supervised document classification are explained here.
Manager holmes_extractor.Manager(self, model, *, overall_similarity_threshold=1.0,
embedding_based_matching_on_root_words=False, ontology=None,
analyze_derivational_morphology=True, perform_coreference_resolution=None,
number_of_workers=None, verbose=False)
The facade class for the Holmes library.
Parameters:
model -- the name of the spaCy model, e.g. *en_core_web_trf*
overall_similarity_threshold -- the overall similarity threshold for embedding-based
matching. Defaults to *1.0*, which deactivates embedding-based matching. Note that this
parameter is not relevant for topic matching, where the thresholds for embedding-based
matching are set on the call to *topic_match_documents_against*.
embedding_based_matching_on_root_words -- determines whether or not embedding-based
matching should be attempted on search-phrase root tokens, which has a considerable
performance hit. Defaults to *False*. Note that this parameter is not relevant for topic
matching.
ontology -- an *Ontology* object. Defaults to *None* (no ontology).
analyze_derivational_morphology -- *True* if matching should be attempted between different
words from the same word family. Defaults to *True*.
perform_coreference_resolution -- *True* if coreference resolution should be taken into account
when matching. Defaults to *True*.
use_reverse_dependency_matching -- *True* if appropriate dependencies in documents can be
matched to dependencies in search phrases where the two dependencies point in opposite
directions. Defaults to *True*.
number_of_workers -- the number of worker processes to use, or *None* if the number of worker
processes should depend on the number of available cores. Defaults to *None*
verbose -- a boolean value specifying whether multiprocessing messages should be outputted to
the console. Defaults to *False*
Manager.register_serialized_document(self, serialized_document:bytes, label:str="") -> None
Parameters:
document -- a preparsed Holmes document.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.register_serialized_documents(self, document_dictionary:dict[str, bytes]) -> None
Note that this function is the most efficient way of loading documents.
Parameters:
document_dictionary -- a dictionary from labels to serialized documents.
Manager.parse_and_register_document(self, document_text:str, label:str='') -> None
Parameters:
document_text -- the raw document text.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.remove_document(self, label:str) -> None
Manager.remove_all_documents(self, labels_starting:str=None) -> None
Parameters:
labels_starting -- a string starting the labels of documents to be removed,
or 'None' if all documents are to be removed.
Manager.list_document_labels(self) -> List[str]
Returns a list of the labels of the currently registered documents.
Manager.serialize_document(self, label:str) -> Optional[bytes]
Returns a serialized representation of a Holmes document that can be
persisted to a file. If 'label' is not the label of a registered document,
'None' is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.get_document(self, label:str='') -> Optional[Doc]
Returns a Holmes document. If *label* is not the label of a registered document, *None*
is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.debug_document(self, label:str='') -> None
Outputs a debug representation for a loaded document.
Parameters:
label -- the label of the document to be serialized.
Manager.register_search_phrase(self, search_phrase_text:str, label:str=None) -> SearchPhrase
Registers and returns a new search phrase.
Parameters:
search_phrase_text -- the raw search phrase text.
label -- a label for the search phrase, which need not be unique.
If label==None, the assigned label defaults to the raw search phrase text.
Manager.remove_all_search_phrases_with_label(self, label:str) -> None
Manager.remove_all_search_phrases(self) -> None
Manager.list_search_phrase_labels(self) -> List[str]
Manager.match(self, search_phrase_text:str=None, document_text:str=None) -> List[Dict]
Matches search phrases to documents and returns the result as match dictionaries.
Parameters:
search_phrase_text -- a text from which to generate a search phrase, or 'None' if the
preloaded search phrases should be used for matching.
document_text -- a text from which to generate a document, or 'None' if the preloaded
documents should be used for matching.
topic_match_documents_against(self, text_to_match:str, *,
use_frequency_factor:bool=True,
maximum_activation_distance:int=75,
word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7,
relation_score:int=300,
reverse_only_relation_score:int=200,
single_word_score:int=50,
single_word_any_tag_score:int=20,
initial_question_word_answer_score:int=600,
initial_question_word_behaviour:str='process',
different_match_cutoff_score:int=15,
overlapping_relation_multiplier:float=1.5,
embedding_penalty:float=0.6,
ontology_penalty:float=0.9,
relation_matching_frequency_threshold:float=0.25,
embedding_matching_frequency_threshold:float=0.5,
sideways_match_extent:int=100,
only_one_result_per_document:bool=False,
number_of_results:int=10,
document_label_filter:str=None,
tied_result_quotient:float=0.9) -> List[Dict]:
Returns a list of dictionaries representing the results of a topic match between an entered text
and the loaded documents.
Properties:
text_to_match -- the text to match against the loaded documents.
use_frequency_factor -- *True* if scores should be multiplied by a factor between 0 and 1
expressing how rare the words matching each phraselet are in the corpus. Note that,
even if this parameter is set to *False*, the factors are still calculated as they are
required for determining which relation and embedding matches should be attempted.
maximum_activation_distance -- the number of words it takes for a previous phraselet
activation to reduce to zero when the library is reading through a document.
word_embedding_match_threshold -- the cosine similarity above which two words match where
the search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
relation_score -- the activation score added when a normal two-word relation is matched.
reverse_only_relation_score -- the activation score added when a two-word relation
is matched using a search phrase that can only be reverse-matched.
single_word_score -- the activation score added when a single noun is matched.
single_word_any_tag_score -- the activation score added when a single word is matched
that is not a noun.
initial_question_word_answer_score -- the activation score added when a question word is
matched to an potential answer phrase.
initial_question_word_behaviour -- 'process' if a question word in the sentence
constituent at the beginning of *text_to_match* is to be matched to document phrases
that answer it and to matching question words; 'exclusive' if only topic matches that
answer questions are to be permitted; 'ignore' if question words are to be ignored.
different_match_cutoff_score -- the activation threshold under which topic matches are
separated from one another. Note that the default value will probably be too low if
*use_frequency_factor* is set to *False*.
overlapping_relation_multiplier -- the value by which the activation score is multiplied
when two relations were matched and the matches involved a common document word.
embedding_penalty -- a value between 0 and 1 with which scores are multiplied when the
match involved an embedding. The result is additionally multiplied by the overall
similarity measure of the match.
ontology_penalty -- a value between 0 and 1 with which scores are multiplied for each
word match within a match that involved the ontology. For each such word match,
the score is multiplied by the value (abs(depth) + 1) times, so that the penalty is
higher for hyponyms and hypernyms than for synonyms and increases with the
depth distance.
relation_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches.
embedding_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches with
embedding-based matching on the second word.
sideways_match_extent -- the maximum number of words that may be incorporated into a
topic match either side of the word where the activation peaked.
only_one_result_per_document -- if 'True', prevents multiple results from being returned
for the same document.
number_of_results -- the number of topic match objects to return.
document_label_filter -- optionally, a string with which document labels must start to
be considered for inclusion in the results.
tied_result_quotient -- the quotient between a result and following results above which
the results are interpreted as tied.
Manager.get_supervised_topic_training_basis(self, *, classification_ontology:Ontology=None,
overlap_memory_size:int=10, oneshot:bool=True, match_all_words:bool=False,
verbose:bool=True) -> SupervisedTopicTrainingBasis:
Returns an object that is used to train and generate a model for the
supervised document classification use case.
Parameters:
classification_ontology -- an Ontology object incorporating relationships between
classification labels, or 'None' if no such ontology is to be used.
overlap_memory_size -- how many non-word phraselet matches to the left should be
checked for words in common with a current match.
oneshot -- whether the same word or relationship matched multiple times within a
single document should be counted once only (value 'True') or multiple times
(value 'False')
match_all_words -- whether all single words should be taken into account
(value 'True') or only single words with noun tags (value 'False')
verbose -- if 'True', information about training progress is outputted to the console.
Manager.deserialize_supervised_topic_classifier(self,
serialized_model:bytes, verbose:bool=False) -> SupervisedTopicClassifier:
Returns a classifier for the supervised document classification use case
that will use a supplied pre-trained model.
Parameters:
serialized_model -- the pre-trained model as returned from `SupervisedTopicClassifier.serialize_model()`.
verbose -- if 'True', information about matching is outputted to the console.
Manager.start_chatbot_mode_console(self)
Starts a chatbot mode console enabling the matching of pre-registered
search phrases to documents (chatbot entries) entered ad-hoc by the
user.
Manager.start_structural_search_mode_console(self)
Starts a structural extraction mode console enabling the matching of pre-registered
documents to search phrases entered ad-hoc by the user.
Manager.start_topic_matching_search_mode_console(self,
only_one_result_per_document:bool=False, word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7):
Starts a topic matching search mode console enabling the matching of pre-registered
documents to query phrases entered ad-hoc by the user.
Parameters:
only_one_result_per_document -- if 'True', prevents multiple topic match
results from being returned for the same document.
word_embedding_match_threshold -- the cosine similarity above which two words match where the
search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
Manager.close(self) -> None
Terminates the worker processes.
manager.nlp manager.nlp is the underlying spaCy Language object on which both Coreferee and Holmes have been registered as custom pipeline components. The most efficient way of parsing documents for use with Holmes is to call manager.nlp.pipe() . This yields an iterable of documents that can then be loaded into Holmes via manager.register_serialized_documents() .
The pipe() method has an argument n_process that specifies the number of processors to use. With _lg , _md and _sm spaCy models, there are some situations where it can make sense to specify a value other than 1 (the default). Note however that with transformer spaCy models ( _trf ) values other than 1 are not supported.
Ontology holmes_extractor.Ontology(self, ontology_path,
owl_class_type='http://www.w3.org/2002/07/owl#Class',
owl_individual_type='http://www.w3.org/2002/07/owl#NamedIndividual',
owl_type_link='http://www.w3.org/1999/02/22-rdf-syntax-ns#type',
owl_synonym_type='http://www.w3.org/2002/07/owl#equivalentClass',
owl_hyponym_type='http://www.w3.org/2000/01/rdf-schema#subClassOf',
symmetric_matching=False)
Loads information from an existing ontology and manages ontology
matching.
The ontology must follow the W3C OWL 2 standard. Search phrase words are
matched to hyponyms, synonyms and instances from within documents being
searched.
This class is designed for small ontologies that have been constructed
by hand for specific use cases. Where the aim is to model a large number
of semantic relationships, word embeddings are likely to offer
better results.
Holmes is not designed to support changes to a loaded ontology via direct
calls to the methods of this class. It is also not permitted to share a single instance
of this class between multiple Manager instances: instead, a separate Ontology instance
pointing to the same path should be created for each Manager.
Matching is case-insensitive.
Parameters:
ontology_path -- the path from where the ontology is to be loaded,
or a list of several such paths. See https://github.com/RDFLib/rdflib/.
owl_class_type -- optionally overrides the OWL 2 URL for types.
owl_individual_type -- optionally overrides the OWL 2 URL for individuals.
owl_type_link -- optionally overrides the RDF URL for types.
owl_synonym_type -- optionally overrides the OWL 2 URL for synonyms.
owl_hyponym_type -- optionally overrides the RDF URL for hyponyms.
symmetric_matching -- if 'True', means hypernym relationships are also taken into account.
SupervisedTopicTrainingBasis (returned from Manager.get_supervised_topic_training_basis() )Holder object for training documents and their classifications from which one or more SupervisedTopicModelTrainer objects can be derived. This class is NOT threadsafe.
SupervisedTopicTrainingBasis.parse_and_register_training_document(self, text:str, classification:str,
label:Optional[str]=None) -> None
Parses and registers a document to use for training.
Parameters:
text -- the document text
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_training_document(self, doc:Doc, classification:str,
label:Optional[str]=None) -> None
Registers a pre-parsed document to use for training.
Parameters:
doc -- the document
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_additional_classification_label(self, label:str) -> None
Register an additional classification label which no training document possesses explicitly
but that should be assigned to documents whose explicit labels are related to the
additional classification label via the classification ontology.
SupervisedTopicTrainingBasis.prepare(self) -> None
Matches the phraselets derived from the training documents against the training
documents to generate frequencies that also include combined labels, and examines the
explicit classification labels, the additional classification labels and the
classification ontology to derive classification implications.
Once this method has been called, the instance no longer accepts new training documents
or additional classification labels.
SupervisedTopicTrainingBasis.train(
self,
*,
minimum_occurrences: int = 4,
cv_threshold: float = 1.0,
learning_rate: float = 0.001,
batch_size: int = 5,
max_epochs: int = 200,
convergence_threshold: float = 0.0001,
hidden_layer_sizes: Optional[List[int]] = None,
shuffle: bool = True,
normalize: bool = True
) -> SupervisedTopicModelTrainer:
Trains a model based on the prepared state.
Parameters:
minimum_occurrences -- the minimum number of times a word or relationship has to
occur in the context of the same classification for the phraselet
to be accepted into the final model.
cv_threshold -- the minimum coefficient of variation with which a word or relationship has
to occur across the explicit classification labels for the phraselet to be
accepted into the final model.
learning_rate -- the learning rate for the Adam optimizer.
batch_size -- the number of documents in each training batch.
max_epochs -- the maximum number of training epochs.
convergence_threshold -- the threshold below which loss measurements after consecutive
epochs are regarded as equivalent. Training stops before 'max_epochs' is reached
if equivalent results are achieved after four consecutive epochs.
hidden_layer_sizes -- a list containing the number of neurons in each hidden layer, or
'None' if the topology should be determined automatically.
shuffle -- 'True' if documents should be shuffled during batching.
normalize -- 'True' if normalization should be applied to the loss function.
SupervisedTopicModelTrainer (returned from SupervisedTopicTrainingBasis.train() ) Worker object used to train and generate models. This object could be removed from the public interface ( SupervisedTopicTrainingBasis.train() could return a SupervisedTopicClassifier directly) but has been retained to facilitate testability.
This class is NOT threadsafe.
SupervisedTopicModelTrainer.classifier(self)
Returns a supervised topic classifier which contains no explicit references to the training data and that
can be serialized.
SupervisedTopicClassifier (returned from SupervisedTopicModelTrainer.classifier() and Manager.deserialize_supervised_topic_classifier() ))
SupervisedTopicClassifier.def parse_and_classify(self, text: str) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
text -- the text to parse and classify.
SupervisedTopicClassifier.classify(self, doc: Doc) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
doc -- the pre-parsed document to classify.
SupervisedTopicClassifier.serialize_model(self) -> str
Returns a serialized model that can be reloaded using
*Manager.deserialize_supervised_topic_classifier()*
Manager.match() A text-only representation of a match between a search phrase and a
document. The indexes refer to tokens.
Properties:
search_phrase_label -- the label of the search phrase.
search_phrase_text -- the text of the search phrase.
document -- the label of the document.
index_within_document -- the index of the match within the document.
sentences_within_document -- the raw text of the sentences within the document that matched.
negated -- 'True' if this match is negated.
uncertain -- 'True' if this match is uncertain.
involves_coreference -- 'True' if this match was found using coreference resolution.
overall_similarity_measure -- the overall similarity of the match, or
'1.0' if embedding-based matching was not involved in the match.
word_matches -- an array of dictionaries with the properties:
search_phrase_token_index -- the index of the token that matched from the search phrase.
search_phrase_word -- the string that matched from the search phrase.
document_token_index -- the index of the token that matched within the document.
first_document_token_index -- the index of the first token that matched within the document.
Identical to 'document_token_index' except where the match involves a multiword phrase.
last_document_token_index -- the index of the last token that matched within the document
(NOT one more than that index). Identical to 'document_token_index' except where the match
involves a multiword phrase.
structurally_matched_document_token_index -- the index of the token within the document that
structurally matched the search phrase token. Is either the same as 'document_token_index' or
is linked to 'document_token_index' within a coreference chain.
document_subword_index -- the index of the token subword that matched within the document, or
'None' if matching was not with a subword but with an entire token.
document_subword_containing_token_index -- the index of the document token that contained the
subword that matched, which may be different from 'document_token_index' in situations where a
word containing multiple subwords is split by hyphenation and a subword whose sense
contributes to a word is not overtly realised within that word.
document_word -- the string that matched from the document.
document_phrase -- the phrase headed by the word that matched from the document.
match_type -- 'direct', 'derivation', 'entity', 'embedding', 'ontology', 'entity_embedding'
or 'question'.
negated -- 'True' if this word match is negated.
uncertain -- 'True' if this word match is uncertain.
similarity_measure -- for types 'embedding' and 'entity_embedding', the similarity between the
two tokens, otherwise '1.0'.
involves_coreference -- 'True' if the word was matched using coreference resolution.
extracted_word -- within the coreference chain, the most specific term that corresponded to
the document_word.
depth -- the number of hyponym relationships linking 'search_phrase_word' and
'extracted_word', or '0' if ontology-based matching is not active. Can be negative
if symmetric matching is active.
explanation -- creates a human-readable explanation of the word match from the perspective of the
document word (e.g. to be used as a tooltip over it).
Manager.topic_match_documents_against() A text-only representation of a topic match between a search text and a document.
Properties:
document_label -- the label of the document.
text -- the document text that was matched.
text_to_match -- the search text.
rank -- a string representation of the scoring rank which can have the form e.g. '2=' in case of a tie.
index_within_document -- the index of the document token where the activation peaked.
subword_index -- the index of the subword within the document token where the activation peaked, or
'None' if the activation did not peak at a specific subword.
start_index -- the index of the first document token in the topic match.
end_index -- the index of the last document token in the topic match (NOT one more than that index).
sentences_start_index -- the token start index within the document of the sentence that contains
'start_index'
sentences_end_index -- the token end index within the document of the sentence that contains
'end_index' (NOT one more than that index).
sentences_character_start_index_in_document -- the character index of the first character of 'text'
within the document.
sentences_character_end_index_in_document -- one more than the character index of the last
character of 'text' within the document.
score -- the score
word_infos -- an array of arrays with the semantics:
[0] -- 'relative_start_index' -- the index of the first character in the word relative to
'sentences_character_start_index_in_document'.
[1] -- 'relative_end_index' -- one more than the index of the last character in the word
relative to 'sentences_character_start_index_in_document'.
[2] -- 'type' -- 'single' for a single-word match, 'relation' if within a relation match
involving two words, 'overlapping_relation' if within a relation match involving three
or more words.
[3] -- 'is_highest_activation' -- 'True' if this was the word at which the highest activation
score reported in 'score' was achieved, otherwise 'False'.
[4] -- 'explanation' -- a human-readable explanation of the word match from the perspective of
the document word (e.g. to be used as a tooltip over it).
answers -- an array of arrays with the semantics:
[0] -- the index of the first character of a potential answer to an initial question word.
[1] -- one more than the index of the last character of a potential answer to an initial question
word.
Earlier versions of Holmes could only be published under a restrictive license because of patent issues. As explained in the introduction, this is no longer the case thanks to the generosity of AstraZeneca: versions from 4.0.0 onwards are licensed under the MIT license.
The word-level matching and the high-level operation of structural matching between search-phrase and document subgraphs both work more or less as one would expect. What is perhaps more in need of further comment is the semantic analysis code subsumed in the parsing.py script as well as in the language_specific_rules.py script for each language.
SemanticAnalyzer is an abstract class that is subclassed for each language: at present by EnglishSemanticAnalyzer and GermanSemanticAnalyzer . These classes contain most of the semantic analysis code. SemanticMatchingHelper is a second abstract class, again with an concrete implementation for each language, that contains semantic analysis code that is required at matching time. Moving this out to a separate class family was necessary because, on operating systems that spawn processes rather than forking processes (eg Windows), SemanticMatchingHelper instances have to be serialized when the worker processes are created: this would not be possible for SemanticAnalyzer instances because not all spaCy models are serializable, and would also unnecessarily consume large amounts of memory.
At present, all functionality that is common to the two languages is realised in the two abstract parent classes. Especially because English and German are closely related languages, it is probable that functionality will need to be moved from the abstract parent classes to specific implementing children classes if and when new semantic analyzers are added for new languages.
The HolmesDictionary class is defined as a spaCy extension attribute that is accessed using the syntax token._.holmes . The most important information in the dictionary is a list of SemanticDependency objects. These are derived from the dependency relationships in the spaCy output ( token.dep_ ) but go through a considerable amount of processing to make them 'less syntactic' and 'more semantic'. To give but a few examples:
Some new semantic dependency labels that do not occur in spaCy outputs as values of token.dep_ are added for Holmes semantic dependencies. It is important to understand that Holmes semantic dependencies are used exclusively for matching and are therefore neither intended nor required to form a coherent set of linguistic theoretical entities or relationships; whatever works best for matching is assigned on an ad-hoc basis.
For each language, the match_implication_dict dictionary maps search-phrase semantic dependencies to matching document semantic dependencies and is responsible for the asymmetry of matching between search phrases and documents.
Topic matching involves the following steps:
SemanticMatchingHelper.topic_matching_phraselet_stop_lemmas ), which are consistently ignored throughout the whole process.SemanticMatchingHelper.phraselet_templates .SemanticMatchingHelper.topic_matching_reverse_only_parent_lemmas ) or when the frequency factor for the parent word is below the threshold for relation matching ( relation_matching_frequency_threshold , default: 0.25). These measures are necessary because matching on eg a parent preposition would lead to a large number of potential matches that would take a lot of resources to investigate: it is better to start investigation from the less frequent word within a given relation.relation_matching_frequency_threshold , default: 0.25).embedding_matching_frequency_threshold , default: 0.5), matching at all of those words where the relation template has not already been matched is retried using embeddings at the other word within the relation. A pair of words is then regarded as matching when their mutual cosine similarity is above initial_question_word_embedding_match_threshold (default: 0.7) in situations where the document word has an initial question word in its phrase or word_embedding_match_threshold (default: 0.8) in all other situations.use_frequency_factor is set to True (the default), each score is scaled by the frequency factor of its phraselet, meaning that words that occur less frequently in the corpus give rise to higher scores.maximum_activation_distance ; default: 75) of its value is subtracted from it as each new word is read.single_word_score ; default: 50), a non-noun single-word phraselet or a noun phraselet that matched a subword ( single_word_any_tag_score ; default: 20), a relation phraselet produced by a reverse-only template ( reverse_only_relation_score ; default: 200), any other (normally matched) relation phraselet ( relation_score ; default: 300), or a relation phraselet involving an initial question word ( initial_question_word_answer_score ; default: 600).embedding_penalty ; default: 0.6).ontology_penalty ; default: 0.9) once more often than the difference in depth between the two ontology entries, ie once for a synonym, twice for a child, three times for a grandchild and so on.overlapping_relation_multiplier ; default: 1.5).sideways_match_extent ; default: 100 words) within which the activation score is higher than the different_match_cutoff_score (default: 15) are regarded as belonging to a contiguous passage around the peak that is then returned as a TopicMatch object. (Note that this default will almost certainly turn out to be too low if use_frequency_factor is set to False .) A word whose activation equals the threshold exactly is included at the beginning of the area as long as the next word where activation increases has a score above the threshold. If the topic match peak is below the threshold, the topic match will only consist of the peak word.initial_question_word_behaviour is set to process (the default) or to exclusive , where a document word has matched an initial question word from the query phrase, the subtree of the matched document word is identified as a potential answer to the question and added to the dictionary to be returned. If initial_question_word_behaviour is set to exclusive , any topic matches that do not contain answers to initial question words are discarded.only_one_result_per_document = True prevents more than one result from being returned from the same document; only the result from each document with the highest score will then be returned.tied_result_quotient (default: 0.9) are labelled as tied. The supervised document classification use case relies on the same phraselets as the topic matching use case, although reverse-only templates are ignored and a different set of stop words is used ( SemanticMatchingHelper.supervised_document_classification_phraselet_stop_lemmas ). Classifiers are built and trained as follows:
oneshot ; whether single-word phraselets are generated for all words with their own meaning or only for those such words whose part-of-speech tags match the single-word phraselet template specification (essentially: noun phraselets) depends on the value of match_all_words . Wherever two phraselet matches overlap, a combined match is recorded. Combined matches are treated in the same way as other phraselet matches in further processing. This means that effectively the algorithm picks up one-word, two-word and three-word semantic combinations. See here for a discussion of the performance of this step.minimum_occurrences ; default: 4) or where the coefficient of variation (the standard deviation divided by the arithmetic mean) of the occurrences across the categories is below a threshold ( cv_threshold ; default: 1.0).oneshot==True vs. oneshot==False respectively). The outputs are the category labels, including any additional labels determined via a classification ontology. By default, the multilayer perceptron has three hidden layers where the first hidden layer has the same number of neurons as the input layer and the second and third layers have sizes in between the input and the output layer with an equally sized step between each size; the user is however free to specify any other topology.Holmes code is formatted with black.
The complexity of what Holmes does makes development impossible without a robust set of over 1400 regression tests. These can be executed individually with unittest or all at once by running the pytest utility from the Holmes source code root directory. (Note that the Python 3 command on Linux is pytest-3 .)
The pytest variant will only work on machines with sufficient memory resources. To reduce this problem, the tests are distributed across three subdirectories, so that pytest can be run three times, once from each subdirectory:
New languages can be added to Holmes by subclassing the SemanticAnalyzer and SemanticMatchingHelper classes as explained here.
The sets of matching semantic dependencies captured in the _matching_dep_dict dictionary for each language have been obtained on the basis of a mixture of linguistic-theoretical expectations and trial and error. The results would probably be improved if the _matching_dep_dict dictionaries could be derived using machine learning instead; as yet this has not been attempted because of the lack of appropriate training data.
An attempt should be made to remove personal data from supervised document classification models to make them more compliant with data protection laws.
In cases where embedding-based matching is not active, the second step of the supervised document classification procedure repeats a considerable amount of processing from the first step. Retaining the relevant information from the first step of the procedure would greatly improve training performance. This has not been attempted up to now because a large number of tests would be required to prove that such performance improvements did not have any inadvertent impacts on functionality.
The topic matching and supervised document classification use cases are both configured with a number of hyperparameters that are presently set to best-guess values derived on a purely theoretical basis. Results could be further improved by testing the use cases with a variety of hyperparameters to learn the optimal values.
The initial open-source version.
pobjp linking parents of prepositions directly with their children.MultiprocessingManager object as its facade.Manager and MultiprocessingManager classes into a single Manager class, with a redesigned public interface, that uses worker threads for everything except supervised document classification.

