holmes extractor
Holmes 4.0.0
Auteur: Richard Paul Hudson, Explosion AI
Managermanager.nlpOntologySupervisedTopicTrainingBasis (retourné de Manager.get_supervised_topic_training_basis() )SupervisedTopicModelTrainer (retourné de SupervisedTopicTrainingBasis.train() )SupervisedTopicClassifier (renvoyé de SupervisedTopicModelTrainer.classifier() et Manager.deserialize_supervised_topic_classifier() )Manager.match()Manager.topic_match_documents_against()Holmes est une bibliothèque Python 3 (v3.6 - V3.10) fonctionnant au-dessus de Spacy (v3.1 - V3.3) qui prend en charge un certain nombre de cas d'utilisation impliquant l'extraction d'informations à partir de textes anglais et allemands. Dans tous les cas d'utilisation, l'extraction d'informations est basée sur l'analyse des relations sémantiques exprimées par les composants de chaque phrase:
Dans le cas d'utilisation du chatbot, le système est configuré à l'aide d'une ou plusieurs phrases de recherche . Holmes recherche ensuite des structures dont les significations correspondent à celles de ces phrases de recherche dans un document recherché, qui dans ce cas correspond à un extrait individuel de texte ou de discours entré par l'utilisateur final. Dans une correspondance, chaque mot avec sa propre signification (c'est-à-dire qui ne remplit pas simplement une fonction grammaticale) dans la phrase de recherche correspond à un ou plusieurs mots de ce type dans le document. À la fois le fait qu'une phrase de recherche a été appariée et toute information structurée que les extraits de phrase de recherche peuvent être utilisées pour conduire le chatbot.
Le cas d'utilisation de l'extraction structurelle utilise exactement la même technologie de correspondance structurelle que le cas d'utilisation du chatbot, mais la recherche a lieu en ce qui concerne un document ou des documents préexistants qui sont généralement beaucoup plus longs que les extraits analysés dans le cas d'utilisation du chatbot, et l'objectif est d'extraire et de stocker des informations structurées. Par exemple, un ensemble d'articles d'entreprise pourrait être recherché pour trouver tous les endroits où une entreprise prévoyait de reprendre une deuxième entreprise. L'identité des entreprises concernées pourrait ensuite être stockée dans une base de données.
Le topie correspondant à un cas d'utilisation vise à trouver des passages dans un document ou des documents dont la signification est proche de celle d'un autre document, qui assume le rôle du document de requête , ou à celui d'une phrase de requête entrée ad-hoc par l'utilisateur. Holmes extrait un certain nombre de petits phrasélettes de la phrase de requête ou du document de requête, correspond aux documents recherchés contre chaque phrasélet et confond les résultats pour trouver les passages les plus pertinents dans les documents. Parce qu'il n'y a aucune exigence stricte que chaque mot avec sa propre signification dans le document de requête correspond à un mot ou à des mots spécifique dans les documents recherchés, plus de correspondances sont trouvées que dans le cas d'utilisation de l'extraction structurelle, mais les correspondances ne contiennent pas d'informations structurées qui peuvent être utilisées dans le traitement ultérieur. Le cas d'utilisation correspondant à un sujet est démontré par un site Web permettant des recherches dans six romans Charles Dickens (pour l'anglais) et environ 350 histoires traditionnelles (pour l'allemand).
Le cas d'utilisation de classification des documents supervisés utilise des données de formation pour apprendre un classificateur qui attribue une ou plusieurs étiquettes de classification à de nouveaux documents en fonction de ce dont ils parlent. Il classe un nouveau document en le faisant correspondre contre des phrasélettes extraits des documents de formation de la même manière que les phrasélettes sont extraites du document de requête dans le cas d'utilisation de correspondance du sujet. La technique est inspirée par des algorithmes de classification basés sur un sac de mots qui utilisent des n-grammes, mais visent à dériver des n-grammes dont les mots composants sont connexes sémantiquement plutôt que qui sont simplement des voisins dans la représentation de la surface d'une langue.
Dans les quatre cas d'utilisation, les mots individuels sont appariés en utilisant un certain nombre de stratégies. Pour déterminer si deux structures grammaticales qui contiennent des mots correspondant individuellement correspondent logiquement et constituent une correspondance, Holmes transforme les informations d'analyse syntaxique fournies par la bibliothèque Spacy en structures sémantiques qui permettent de comparer les textes à l'aide de la logique de prédicat. En tant qu'utilisateur de Holmes, vous n'avez pas besoin de comprendre les subtilités de la façon dont cela fonctionne, bien qu'il y ait des conseils importants sur la rédaction de phrases de recherche efficaces pour le chatbot et les cas d'utilisation de l'extraction structurelle que vous devriez essayer de prendre en compte.
Holmes vise à proposer des solutions généralistes qui peuvent être utilisées plus ou moins hors de la boîte avec relativement peu de réglage, de peaufinage ou de formation et qui sont rapidement applicables à un large éventail de cas d'utilisation. À son cœur se trouve un système logique, programmé basé sur des règles qui décrit comment les représentations syntaxiques dans chaque langue expriment des relations sémantiques. Although the supervised document classification use case does incorporate a neural network and although the spaCy library upon which Holmes builds has itself been pre-trained using machine learning, the essentially rule-based nature of Holmes means that the chatbot, structural extraction and topic matching use cases can be put to use out of the box without any training and that the supervised document classification use case typically requires relatively little training data, which is a great advantage because pre-labelled training data is not available for de nombreux problèmes réels.
Holmes a une histoire longue et complexe et nous sommes désormais en mesure de le publier sous la licence du MIT grâce à la bonne volonté et à l'ouverture de plusieurs sociétés. Moi, Richard Hudson, j'ai écrit les versions jusqu'à 3.0.0 tout en travaillant chez MSG Systems, une grande cabinet de cabinet logiciel international basé près de Munich. Fin 2021, j'ai changé les employeurs et je travaille maintenant pour l'explosion, les créateurs de Spacy et Prodigy. Les éléments de la bibliothèque Holmes sont couverts par un brevet américain que j'ai moi-même écrit au début des années 2000 alors qu'il travaillait dans une startup intitulée Deficiens qui a depuis été acquise par AstraZeneca. Avec l'autorisation aimable des systèmes AstraZeneca et MSG, je maintiens maintenant Holmes à l'explosion et je peux l'offrir pour la première fois sous une licence permissive: n'importe qui peut maintenant utiliser Holmes en vertu des termes de la licence du MIT sans avoir à se soucier du brevet.
La bibliothèque a été initialement développée chez MSG Systems, mais est maintenant entretenue dans l'explosion AI. Veuillez diriger tous les nouveaux problèmes ou discussions sur le référentiel d'explosion.
Si vous n'avez pas déjà Python 3 et PIP sur votre machine, vous devrez les installer avant d'installer Holmes.
Installez Holmes en utilisant les commandes suivantes:
Linux:
pip3 install holmes-extractor
Windows:
pip install holmes-extractor
Pour passer à partir d'une version précédente de Holmes, émettez les commandes suivantes, puis réédite les commandes pour télécharger les modèles Spacy et Coreferee pour vous assurer que vous en avez les versions correctes:
Linux:
pip3 install --upgrade holmes-extractor
Windows:
pip install --upgrade holmes-extractor
Si vous souhaitez utiliser les exemples et les tests, clonez le code source en utilisant
git clone https://github.com/explosion/holmes-extractor
Si vous souhaitez expérimenter la modification du code source, vous pouvez remplacer le code installé en démarrant Python (Tapez python3 (Linux) ou python (Windows)) dans le répertoire parent du répertoire où se trouve votre code de module holmes_extractor modifié. Si vous avez vérifié Holmes hors de Git, ce sera le répertoire holmes-extractor .
Si vous souhaitez désinstaller à nouveau Holmes, cela est réalisé en supprimant directement les fichiers installés à partir du système de fichiers. Ceux-ci peuvent être trouvés en émettant ce qui suit à partir de l'invite de commande Python a commencé à partir de tout répertoire autre que le répertoire parent de holmes_extractor :
import holmes_extractor
print(holmes_extractor.__file__)
Les bibliothèques Spacy et Coreferee sur lesquelles Holmes s'appuie sur les modèles spécifiques à la langue qui doivent être téléchargés séparément avant que Holmes puisse être utilisé:
Linux / anglais:
python3 -m spacy download en_core_web_trf
python3 -m spacy download en_core_web_lg
python3 -m coreferee install en
Linux / allemand:
pip3 install spacy-lookups-data # (from spaCy 3.3 onwards)
python3 -m spacy download de_core_news_lg
python3 -m coreferee install de
Windows / English:
python -m spacy download en_core_web_trf
python -m spacy download en_core_web_lg
python -m coreferee install en
Windows / German:
pip install spacy-lookups-data # (from spaCy 3.3 onwards)
python -m spacy download de_core_news_lg
python -m coreferee install de
Et si vous prévoyez d'exécuter les tests de régression:
Linux:
python3 -m spacy download en_core_web_sm
Windows:
python -m spacy download en_core_web_sm
Vous spécifiez un modèle spacy à utiliser Holmes lorsque vous instanciez la classe FACADE GESTION. en_core_web_trf et de_core_web_lg sont les modèles qui se sont avérés donner respectivement les meilleurs résultats pour l'anglais et l'allemand. Parce que en_core_web_trf n'a pas ses propres vecteurs de mots, mais Holmes nécessite des vecteurs de mots pour intégrer la correspondance basée sur le fait, le modèle en_core_web_lg est chargé en tant que source de vecteur chaque fois que le modèle en_core_web_trf est spécifié à la classe Manager comme modèle principal.
Le modèle en_core_web_trf nécessite suffisamment plus de ressources que les autres modèles; Dans une siutation où les ressources sont rares, il peut être un compromis judicieux d'utiliser à en_core_web_lg place le modèle principal.
La meilleure façon d'intégrer Holmes dans un environnement non-python est de l'envelopper en tant que service HTTP RESTful et de le déployer en microservice. Voir ici pour un exemple.
Étant donné que Holmes effectue une analyse complexe et intelligente, il est inévitable qu'il nécessite plus de ressources matérielles que des cadres de recherche plus traditionnels. Les cas d'utilisation qui impliquent le chargement des documents - l'extraction structurelle et l'appariement des sujets - sont plus immédiatement applicables à des corpus grands mais pas massifs (par exemple tous les documents appartenant à une certaine organisation, tous les brevets sur un certain sujet, tous les livres d'un certain auteur). Pour des raisons de coût, Holmes ne serait pas un outil approprié pour analyser le contenu de l'ensemble de l'Internet!
Cela dit, Holmes est à la fois verticalement et horizontalement évolutif. Avec un matériel suffisant, ces deux cas d'utilisation peuvent être appliqués à un nombre essentiellement illimité de documents en exécutant Holmes sur plusieurs machines, en traitant un ensemble différent de documents sur chacun et en confondant les résultats. Notez que cette stratégie est déjà utilisée pour distribuer la correspondance entre plusieurs cœurs sur une seule machine: la classe Manager lance un certain nombre de processus de travail et distribue des documents enregistrés entre eux.
Holmes détient des documents chargés en mémoire, ce qui est lié à son utilisation prévue avec des corpus grands mais pas massifs. Les performances du chargement des documents, de l'extraction structurelle et de la correspondance de sujets se dégradent beaucoup si le système d'exploitation doit échanger des pages de mémoire en stockage secondaire, car Holmes peut nécessiter la mémoire d'une variété de pages à traiter lors du traitement d'une seule phrase. Cela signifie qu'il est important de fournir suffisamment de RAM sur chaque machine pour contenir tous les documents chargés.
Veuillez noter les commentaires ci-dessus sur les exigences de ressources relatives des différents modèles.
Le cas d'utilisation le plus simple pour obtenir une idée de base rapide du fonctionnement de Holmes est le cas d'utilisation du chatbot .
Ici, une ou plusieurs phrases de recherche sont définies à Holmes à l'avance, et les documents recherchés sont des phrases ou des paragraphes courts tapés de manière interactive par un utilisateur final. Dans un paramètre réel, les informations extraites seraient utilisées pour déterminer le flux d'interaction avec l'utilisateur final. À des fins de test et de démonstration, il existe une console qui affiche ses résultats appariés de manière interactive. Il peut être facilement et rapidement démarré à partir de la ligne de commande Python (qui est elle-même à partir de l'invite du système d'exploitation en tapant python3 (Linux) ou python (Windows)) ou à partir d'un ordinateur portable Jupyter.
L'extrait de code suivant peut être entré en ligne pour la ligne dans la ligne de commande Python, dans un cahier Jupyter ou dans un IDE. Il enregistre le fait que vous êtes intéressé par des phrases sur les gros chiens à la poursuite des chats et commence une console de chatbot de démonstration:
Anglais:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='en_core_web_lg', number_of_workers=1)
holmes_manager.register_search_phrase('A big dog chases a cat')
holmes_manager.start_chatbot_mode_console()
Allemand:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='de_core_news_lg', number_of_workers=1)
holmes_manager.register_search_phrase('Ein großer Hund jagt eine Katze')
holmes_manager.start_chatbot_mode_console()
Si vous entrez maintenant une phrase qui correspond à la phrase de recherche, la console affichera une correspondance:
Anglais:
Ready for input
A big dog chased a cat
Matched search phrase with text 'A big dog chases a cat':
'big'->'big' (Matches BIG directly); 'A big dog'->'dog' (Matches DOG directly); 'chased'->'chase' (Matches CHASE directly); 'a cat'->'cat' (Matches CAT directly)
Allemand:
Ready for input
Ein großer Hund jagte eine Katze
Matched search phrase 'Ein großer Hund jagt eine Katze':
'großer'->'groß' (Matches GROSS directly); 'Ein großer Hund'->'hund' (Matches HUND directly); 'jagte'->'jagen' (Matches JAGEN directly); 'eine Katze'->'katze' (Matches KATZE directly)
Cela aurait facilement pu être réalisé avec un algorithme de correspondance simple, alors tapez quelques phrases plus complexes pour vous convaincre que Holmes les saisit vraiment et que les matchs sont toujours retournés:
Anglais:
The big dog would not stop chasing the cat
The big dog who was tired chased the cat
The cat was chased by the big dog
The cat always used to be chased by the big dog
The big dog was going to chase the cat
The big dog decided to chase the cat
The cat was afraid of being chased by the big dog
I saw a cat-chasing big dog
The cat the big dog chased was scared
The big dog chasing the cat was a problem
There was a big dog that was chasing a cat
The cat chase by the big dog
There was a big dog and it was chasing a cat.
I saw a big dog. My cat was afraid of being chased by the dog.
There was a big dog. His name was Fido. He was chasing my cat.
A dog appeared. It was chasing a cat. It was very big.
The cat sneaked back into our lounge because a big dog had been chasing her.
Our big dog was excited because he had been chasing a cat.
Allemand:
Der große Hund hat die Katze ständig gejagt
Der große Hund, der müde war, jagte die Katze
Die Katze wurde vom großen Hund gejagt
Die Katze wurde immer wieder durch den großen Hund gejagt
Der große Hund wollte die Katze jagen
Der große Hund entschied sich, die Katze zu jagen
Die Katze, die der große Hund gejagt hatte, hatte Angst
Dass der große Hund die Katze jagte, war ein Problem
Es gab einen großen Hund, der eine Katze jagte
Die Katzenjagd durch den großen Hund
Es gab einmal einen großen Hund, und er jagte eine Katze
Es gab einen großen Hund. Er hieß Fido. Er jagte meine Katze
Es erschien ein Hund. Er jagte eine Katze. Er war sehr groß.
Die Katze schlich sich in unser Wohnzimmer zurück, weil ein großer Hund sie draußen gejagt hatte
Unser großer Hund war aufgeregt, weil er eine Katze gejagt hatte
La démonstration n'est pas complète sans essayer d'autres phrases qui contiennent les mêmes mots mais n'expriment pas la même idée et d'observer qu'elles ne sont pas appariées:
Anglais:
The dog chased a big cat
The big dog and the cat chased about
The big dog chased a mouse but the cat was tired
The big dog always used to be chased by the cat
The big dog the cat chased was scared
Our big dog was upset because he had been chased by a cat.
The dog chase of the big cat
Allemand:
Der Hund jagte eine große Katze
Die Katze jagte den großen Hund
Der große Hund und die Katze jagten
Der große Hund jagte eine Maus aber die Katze war müde
Der große Hund wurde ständig von der Katze gejagt
Der große Hund entschloss sich, von der Katze gejagt zu werden
Die Hundejagd durch den große Katze
Dans les exemples ci-dessus, Holmes a égalé une variété de structures de niveau de phrase différentes qui partagent la même signification, mais les formes de base des trois mots dans les documents appariés ont toujours été les mêmes que les trois mots de la phrase de recherche. Holmes fournit plusieurs autres stratégies de correspondance au niveau des mots individuels. En combinaison avec la capacité de Holmes à faire correspondre différentes structures de phrases, celles-ci peuvent permettre à une phrase de recherche de faire correspondre une phrase de document qui partage sa signification même lorsque les deux ne partagent aucun mot et sont grammaticalement différentes.
L'une de ces stratégies supplémentaires de correspondance de mots est nommée de l'entrée: les mots spéciaux peuvent être inclus dans des phrases de recherche qui correspondent à des classes entières de noms comme des personnes ou des lieux. Sortez de la console en tapant exit , puis enregistrez une deuxième phrase de recherche et redémarrez la console:
Anglais:
holmes_manager.register_search_phrase('An ENTITYPERSON goes into town')
holmes_manager.start_chatbot_mode_console()
Allemand:
holmes_manager.register_search_phrase('Ein ENTITYPER geht in die Stadt')
holmes_manager.start_chatbot_mode_console()
Vous avez maintenant enregistré votre intérêt pour les personnes qui vont en ville et pouvez entrer des phrases appropriées dans la console:
Anglais:
Ready for input
I met Richard Hudson and John Doe last week. They didn't want to go into town.
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'John Doe'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
Allemand:
Ready for input
Letzte Woche sah ich Richard Hudson und Max Mustermann. Sie wollten nicht mehr in die Stadt gehen.
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Max Mustermann'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
Dans chacune des deux langues, ce dernier exemple montre plusieurs autres caractéristiques de Holmes:
Pour plus d'exemples, veuillez consulter la section 5.
Les stratégies suivantes sont mises en œuvre avec un module Python par stratégie. Bien que la bibliothèque standard ne prenne pas en charge l'ajout de stratégies sur mesure via la classe Manager, il serait relativement facile pour quiconque ayant des compétences en programmation Python pour modifier le code pour permettre cela.
word_match.type=='direct' )La correspondance directe entre les mots de la phrase de recherche et les mots de document est toujours active. La stratégie repose principalement sur les formes STEM de correspondance de mots, par exemple, l'achat anglais assorti et l'enfant à acheter et les enfants , Steigen allemand et gentil avec Stieg et Kinder . Cependant, afin d'augmenter les chances de fonctionnement direct de fonctionnement lorsque l'analyseur fournit une forme de tige incorrecte pour un mot, les formes de texte brut des mots de recherche et de document sont également pris en considération lors de l'appariement direct.
word_match.type=='derivation' ) L'appariement basé sur la dérivation implique des mots distincts mais connexes qui appartiennent généralement à différentes classes de mots, par exemple l'évaluation et l'évaluation de l'anglais, Jagen allemand et JAGD . Il est actif par défaut mais peut être éteint à l'aide du paramètre analyze_derivational_morphology , qui est défini lors de l'instanciation de la classe Manager.
word_match.type=='entity' )L'appariement de l'entité nommée est activé en insérant un identifiant spécial de l'entité nommée au point souhaité dans une phrase de recherche à la place d'un nom, par exemple
Un entité entre en ville (anglais)
Ein Entityper Geht dans Die Stadt (allemand).
Les identificateurs de l'entité nommés pris en charge dépendent directement des informations de l'entité nommée fournies par les modèles Spacy pour chaque langue (descriptions copiées à partir d'une version antérieure de la documentation Spacy):
Anglais:
| Identifiant | Signification |
|---|---|
| Entité | Toute phrase nominale. |
| Entité | Les gens, y compris fictif. |
| Entité | Nationalités ou groupes religieux ou politiques. |
| Entitéfac | Bâtiments, aéroports, autoroutes, ponts, etc. |
| Entitéorg | Entreprises, agences, institutions, etc. |
| Entitégpe | Pays, villes, États. |
| Entityloc | Emplacements non GPE, chaînes de montagnes, plans d'eau. |
| Produit entité | Objets, véhicules, aliments, etc. (pas de services.) |
| EntityEvent | Nommé des ouragans, des batailles, des guerres, des événements sportifs, etc. |
| Entitywork_of_art | Titres de livres, de chansons, etc. |
| Entitylaw | Documents nommés transformés en lois. |
| EntityLanguage | Toute langue nommée. |
| Entité | Dates ou périodes absolues ou relatives. |
| Entité | Fois plus petit qu'un jour. |
| Entité pour cent | Pourcentage, y compris "%". |
| Entité | Valeurs monétaires, y compris l'unité. |
| Entité | Mesures, comme du poids ou de la distance. |
| Entitéordinal | "d'abord", "deuxième", etc. |
| Entitécardinal | Des chiffres qui ne tombent pas sous un autre type. |
Allemand:
| Identifiant | Signification |
|---|---|
| Entité | Toute phrase nominale. |
| Entité | Personne ou famille nommée. |
| Entityloc | Nom de l'emplacement politiquement ou géographiquement défini (villes, provinces, pays, régions internationales, plans d'eau, montagnes). |
| Entitéorg | Nommé l'entreprise, le gouvernement ou toute autre entité organisationnelle. |
| Entité | Entités diverses, par exemple, événements, nationalités, produits ou œuvres d'art. |
Nous avons ajouté ENTITYNOUN aux authentiques identificateurs de l'entalité. Comme il correspond à n'importe quelle phrase nominale, elle se comporte de manière similaire aux pronoms génériques. Les différences sont que ENTITYNOUN doit correspondre à une phrase nominale spécifique au sein d'un document et que cette phrase nominale spécifique est extraite et disponible pour un traitement ultérieur. ENTITYNOUN n'est pas pris en charge dans le cas d'utilisation correspondant à la rubrique.
word_match.type=='ontology' )Une ontologie permet à l'utilisateur de définir des relations entre les mots qui sont ensuite pris en compte lors de la correspondance des documents pour rechercher des phrases. Les trois types de relations pertinents sont des hyponymes (quelque chose est un sous-type de quelque chose), des synonymes (quelque chose signifie la même chose que quelque chose) et des individus nommés (quelque chose est une instance spécifique de quelque chose). Les trois types de relations sont illustrés à la figure 1:
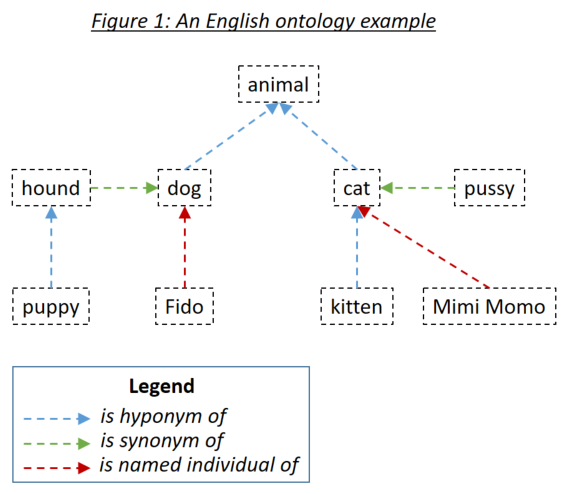
Les ontologies sont définies à Holmes en utilisant la standard OWL Ontology Serialized en utilisant RDF / XML. Ces ontologies peuvent être générées avec une variété d'outils. Pour les exemples et les tests de Holmes, le protégé de l'outil gratuit a été utilisé. Il est recommandé d'utiliser un protégé à la fois pour définir vos propres ontologies et pour parcourir les ontologies qui expédient avec les exemples et les tests. Lors de la sauvegarde d'une ontologie sous Protege, veuillez sélectionner RDF / XML comme format. Protege attribue des étiquettes standard pour l'hyponyme, le synonyme et les relations nommées nommées que Holmes comprend comme par défaut, mais cela peut également être remplacé.
Les entrées d'ontologie sont définies à l'aide d'un identifiant de ressources internationalisés (IRI), par exemple http://www.semanticweb.org/hudsonr/ontologies/2019/0/animals#dog . Holmes n'utilise que le fragment final pour la correspondance, ce qui permet de définir des homonymes (mots avec la même forme mais plusieurs significations) à plusieurs points de l'arbre de l'ontologie.
La correspondance basée sur l'ontologie donne les meilleurs résultats avec Holmes lorsque de petites ontologies sont utilisées qui ont été conçues pour des domaines de sujet et des cas d'utilisation spécifiques. Par exemple, si vous implémentez un chatbot pour un cas d'utilisation d'assurance de construction, vous devez créer une petite ontologie capturant les termes et relations dans ce domaine spécifique. D'un autre côté, il n'est pas recommandé d'utiliser de grandes ontologies conçues pour tous les domaines dans une langue entière telle que WordNet. En effet, les nombreux homonymes et relations qui ne s'appliquent que dans les domaines des sujets étroits auront tendance à conduire à un grand nombre de correspondances incorrectes. Pour les cas d'utilisation générale, l'appariement basé sur l'intégration aura tendance à donner de meilleurs résultats.
Chaque mot dans une ontologie peut être considéré comme dirigeant un sous-arbre composé de ses hyponymes, synonymes et individus nommés, ces mots «hyponymes, synonymes et individus nommés, etc. Avec une ontologie configurée de manière standard qui est appropriée pour le chatbot et les cas d'utilisation de l'extraction structurelle, un mot dans une phrase de recherche Holmes correspond à un mot dans un document si le mot de document est dans le sous-arbre du mot de phrase de recherche. Étaient l'ontologie de la figure 1 définie à Holmes, en plus de la stratégie de correspondance directe, qui correspondrait à chaque mot à lui-même, les combinaisons suivantes correspondraient:
Les verbes à phrases anglais comme manger et les verbes séparables allemands comme Aufessen doivent être définis comme des articles uniques dans les ontologies. Lorsque Holmes analyse un texte et rencontre un tel verbe, le verbe principal et la particule sont confondus en un seul mot logique qui peut ensuite être apparié via une ontologie. Cela signifie que manger dans un texte correspondrait au sous-arbre de manger dans l'ontologie mais pas le sous-arbre de manger dans l'ontologie.
Si la correspondance basée sur la dérivation est active, elle est prise en compte des deux côtés d'une correspondance potentielle basée sur l'ontologie. Par exemple, si l'alter et la modification sont définis comme des synonymes dans une ontologie, l'altération et l'amendement correspondraient également.
Dans les situations où trouver des phrases pertinentes est plus importante que d'assurer la correspondance logique des correspondances de documents aux phrases de recherche, il peut être logique de spécifier l'appariement symétrique lors de la définition de l'ontologie. L'appariement symétrique est recommandé pour le cas d'utilisation de correspondance de sujets, mais il est peu probable qu'il convienne aux cas d'utilisation du chatbot ou de l'extraction structurelle. Cela signifie que la relation hypernyme (hyponyme inversé) est prise en compte ainsi que les relations hyponym et synonyme lors de l'appariement, conduisant ainsi à une relation plus symétrique entre les documents et les phrases de recherche. Une règle importante appliquée lors de la correspondance via une ontologie symétrique est qu'un chemin de correspondance peut ne pas contenir des relations hypernym et hyponymes, c'est-à-dire que vous ne pouvez pas revenir sur vous-même. Étaient l'ontologie ci-dessus définie comme symétrique, les combinaisons suivantes correspondraient:
Dans le cas d'utilisation de classification des documents supervisés, deux ontologies distinctes peuvent être utilisées:
L'ontologie de l'appariement structurel est utilisée pour analyser le contenu des documents de formation et de test. Chaque mot d'un document trouvé dans l'ontologie est remplacé par son ancêtre hypernyme le plus général. Il est important de réaliser qu'une ontologie n'est susceptible de travailler avec une correspondance structurelle pour la classification des documents supervisés que s'il a été construit spécifiquement à cet effet: une telle ontologie devrait être composée d'un certain nombre d'arbres distincts représentant les principales classes d'objets dans les documents à classer. Dans l'exemple de l'ontologie indiquée ci-dessus, tous les mots de l'ontologie seraient remplacés par un animal ; Dans un cas extrême avec une ontologie de style WordNet, tous les noms finiraient par être remplacés par la chose , ce qui n'est clairement pas un résultat souhaitable!
L'ontologie de classification est utilisée pour saisir les relations entre les étiquettes de classification: qu'un document a une certaine classification implique qu'il a également des classifications auquel appartient le sous-arbre. Les synonymes doivent être utilisés par parcimonie, voire du tout dans les ontologies de classification car elles ajoutent à la complexité du réseau neuronal sans ajouter de valeur; Et bien qu'il soit techniquement possible de configurer une ontologie de classification pour utiliser l'appariement symétrique, il n'y a aucune raison raisonnable de le faire. Notez qu'une étiquette au sein de l'ontologie de classification qui n'est pas directement définie comme l'étiquette de tout document de formation doit être enregistrée spécifiquement à l'aide de la méthode SupervisedTopicTrainingBasis.register_additional_classification_label() si elle doit être prise en compte lors de la formation du classificateur.
word_match.type=='embedding' )Spacy propose des incorporations de mots : représentations de vecteurs numériques générés par l'apprentissage automatique des mots qui capturent les contextes dans lesquels chaque mot a tendance à se produire. Deux mots ayant un sens similaire ont tendance à émerger avec des incorporations de mots proches les unes des autres, et le spacy peut mesurer la similitude du cosinus entre les deux mots de deux mots exprimés comme une décimale entre 0,0 (pas de similitude) et 1.0 (le même mot). Parce que le chien et le chat ont tendance à apparaître dans des contextes similaires, ils ont une similitude de 0,80; Le chien et le cheval ont moins en commun et ont une similitude de 0,62; et le chien et le fer ont une similitude de seulement 0,25. L'appariement basé sur l'intégration n'est activé que pour les noms, les adjectifs et les adverbes car les résultats se sont révélés insatisfaisants avec d'autres classes de mots.
Il est important de comprendre que le fait que deux mots aient des intérêts similaires n'implique pas le même type de relation logique entre les deux que lorsque l'appariement basé sur l'ontologie est utilisé: par exemple, le fait que le chien et le chat ont des intégres similaires ne signifie ni qu'un chien est un type de chat ni qu'un chat est un type de chien. La question de savoir si une correspondance basée sur l'intégration est néanmoins un choix approprié dépend du cas d'utilisation fonctionnelle.
Pour le chatbot, l'extraction structurelle et les cas d'utilisation de classification des documents supervisés, Holmes utilise des similitudes basées sur Word-incorpation à l'aide d'un paramètre overall_similarity_threshold défini à l'échelle mondiale sur la classe Manager. Une correspondance est détectée entre une phrase de recherche et une structure dans un document chaque fois que la moyenne géométrique des similitudes entre les paires de mots correspondantes individuelles est supérieure à ce seuil. L'intuition derrière cette technique est que lorsqu'une phrase de recherche avec EG six mots lexicaux a correspondant à une structure de document où cinq de ces mots correspondent exactement et qu'un seul correspond via une incorporation, la similitude qui devrait être nécessaire pour correspondre à ce sixième mot est inférieure à ce que seuls trois des mots correspondaient exactement et deux des autres mots correspond également via Embeddings.
La correspondance d'une phrase de recherche à un document commence par trouver des mots dans le document qui correspondent au mot à la racine (tête syntaxique) de la phrase de recherche. Holmes étudie ensuite la structure autour de chacun de ces mots de document correspondants pour vérifier si la structure du document correspond à la structure de la phrase de recherche dans son entité. Les mots de document qui correspondent au mot racine de la phrase de recherche sont normalement trouvés à l'aide d'un index. Cependant, si les intégres doivent être pris en compte lors de la recherche de mots de document qui correspondent à un mot racine de phrase de recherche, chaque mot dans chaque document avec une classe de mots valide doit être comparé pour une similitude avec cette phrase de recherche mot racine. Cela a un coup de performance très notable qui rend tous les cas d'utilisation, à l'exception du cas d'utilisation du chatbot essentiellement inutilisable.
Pour éviter le coup de performance généralement inutile qui résulte de la correspondance basée sur l'intégration des mots racine de la phrase de recherche, il est contrôlé séparément de la correspondance basée sur l'intégration en général en utilisant le paramètre embedding_based_matching_on_root_words , qui est défini lors de l'instanciation de la classe Manager. Il est conseillé de maintenir ce réglage éteint (valeur False ) pour la plupart des cas d'utilisation.
Ni le paramètre overall_similarity_threshold ni le paramètre embedding_based_matching_on_root_words n'a aucun effet sur le cas d'utilisation correspondant à la rubrique. Ici, les seuils de similitude d'intégration du niveau Word sont définis à l'aide des paramètres word_embedding_match_threshold et initial_question_word_embedding_match_threshold lors de l'appel de la fonction topic_match_documents_against sur la classe Manager.
word_match.type=='entity_embedding' ) Une correspondance basée sur l'endingage nommé obtient un mot de document recherché qui a une certaine étiquette d'entité et une phrase de recherche ou un mot de document de requête dont l'intégration est suffisamment similaire à la signification sous-jacente de cette étiquette d'entité, par exemple l'étiquette individuelle du mot dans une phrase de recherche similaire à la signification sous-jacente de l'étiquette de l'entité de la personne . Notez que la correspondance basée sur la notation basée sur le délai n'est jamais active sur les mots racine quel que soit le paramètre embedding_based_matching_on_root_words .
word_match.type=='question' )L'appariement des mots-question initiale n'est actif que lors de la correspondance du sujet. Les mots de question initiaux dans les phrases de requête correspondent aux entités dans les documents recherchés qui représentent des réponses potentielles à la question, par exemple, lors de la comparaison de la phrase de requête quand Peter a-t-il pris le petit déjeuner à l'expression de document recherché Peter a pris le petit déjeuner à 8 heures du matin , le mot de question quand correspondait à la phrase adverbiale temporelle à 8 heures du matin .
La correspondance de mots-question initiale est activée et désactivée à l'aide du paramètre initial_question_word_behaviour lors de l'appel de la fonction topic_match_documents_against sur la classe Manager. It is only likely to be useful when topic matching is being performed in an interactive setting where the user enters short query phrases, as opposed to when it is being used to find documents on a similar topic to an pre-existing query document: initial question words are only processed at the beginning of the first sentence of the query phrase or query document.
Linguistically speaking, if a query phrase consists of a complex question with several elements dependent on the main verb, a finding in a searched document is only an 'answer' if contains matches to all these elements. Because recall is typically more important than precision when performing topic matching with interactive query phrases, however, Holmes will match an initial question word to a searched-document phrase wherever they correspond semantically (eg wherever when corresponds to a temporal adverbial phrase) and each depend on verbs that themselves match at the word level. One possible strategy to filter out 'incomplete answers' would be to calculate the maximum possible score for a query phrase and reject topic matches that score below a threshold scaled to this maximum.
Before Holmes analyses a searched document or query document, coreference resolution is performed using the Coreferee library running on top of spaCy. This means that situations are recognised where pronouns and nouns that are located near one another within a text refer to the same entities. The information from one mention can then be applied to the analysis of further mentions:
I saw a big dog . It was chasing a cat.
I saw a big dog . The dog was chasing a cat.
Coreferee also detects situations where a noun refers back to a named entity:
We discussed AstraZeneca . The company had given us permission to publish this library under the MIT license.
If this example were to match the search phrase A company gives permission to publish something , the coreference information that the company under discussion is AstraZeneca is clearly relevant and worth extracting in addition to the word(s) directly matched to the search phrase. Such information is captured in the word_match.extracted_word field.
The concept of search phrases has already been introduced and is relevant to the chatbot use case, the structural extraction use case and to preselection within the supervised document classification use case.
It is crucial to understand that the tips and limitations set out in Section 4 do not apply in any way to query phrases in topic matching. If you are using Holmes for topic matching only, you can completely ignore this section!
Structural matching between search phrases and documents is not symmetric: there are many situations in which sentence X as a search phrase would match sentence Y within a document but where the converse would not be true. Although Holmes does its best to understand any search phrases, the results are better when the user writing them follows certain patterns and tendencies, and getting to grips with these patterns and tendencies is the key to using the relevant features of Holmes successfully.
Holmes distinguishes between: lexical words like dog , chase and cat (English) or Hund , jagen and Katze (German) in the initial example above; and grammatical words like a (English) or ein and eine (German) in the initial example above. Only lexical words match words in documents, but grammatical words still play a crucial role within a search phrase: they enable Holmes to understand it.
Dog chase cat (English)
Hund jagen Katze (German)
contain the same lexical words as the search phrases in the initial example above, but as they are not grammatical sentences Holmes is liable to misunderstand them if they are used as search phrases. This is a major difference between Holmes search phrases and the search phrases you use instinctively with standard search engines like Google, and it can take some getting used to.
A search phrase need not contain a verb:
ENTITYPERSON (English)
A big dog (English)
Interest in fishing (English)
ENTITYPER (German)
Ein großer Hund (German)
Interesse am Angeln (German)
are all perfectly valid and potentially useful search phrases.
Where a verb is present, however, Holmes delivers the best results when the verb is in the present active , as chases and jagt are in the initial example above. This gives Holmes the best chance of understanding the relationship correctly and of matching the widest range of document structures that share the target meaning.
Sometimes you may only wish to extract the object of a verb. For example, you might want to find sentences that are discussing a cat being chased regardless of who is doing the chasing. In order to avoid a search phrase containing a passive expression like
A cat is chased (English)
Eine Katze wird gejagt (German)
you can use a generic pronoun . This is a word that Holmes treats like a grammatical word in that it is not matched to documents; its sole purpose is to help the user form a grammatically optimal search phrase in the present active. Recognised generic pronouns are English something , somebody and someone and German jemand (and inflected forms of jemand ) and etwas : Holmes treats them all as equivalent. Using generic pronouns, the passive search phrases above could be re-expressed as
Somebody chases a cat (English)
Jemand jagt eine Katze (German).
Experience shows that different prepositions are often used with the same meaning in equivalent phrases and that this can prevent search phrases from matching where one would intuitively expect it. For example, the search phrases
Somebody is at the market (English)
Jemand ist auf dem Marktplatz (German)
would fail to match the document phrases
Richard was in the market (English)
Richard war am Marktplatz (German)
The best way of solving this problem is to define the prepositions in question as synonyms in an ontology.
The following types of structures are prohibited in search phrases and result in Python user-defined errors:
A dog chases a cat. A cat chases a dog (English)
Ein Hund jagt eine Katze. Eine Katze jagt einen Hund (German)
Each clause must be separated out into its own search phrase and registered individually.
A dog does not chase a cat. (Anglais)
Ein Hund jagt keine Katze. (Allemand)
Negative expressions are recognised as such in documents and the generated matches marked as negative; allowing search phrases themselves to be negative would overcomplicate the library without offering any benefits.
A dog and a lion chase a cat. (Anglais)
Ein Hund und ein Löwe jagen eine Katze. (Allemand)
Wherever conjunction occurs in documents, Holmes distributes the information among multiple matches as explained above. In the unlikely event that there should be a requirement to capture conjunction explicitly when matching, this could be achieved by using the Manager.match() function and looking for situations where the document token objects are shared by multiple match objects.
The (English)
Der (German)
A search phrase cannot be processed if it does not contain any words that can be matched to documents.
A dog chases a cat and he chases a mouse (English)
Ein Hund jagt eine Katze und er jagt eine Maus (German)
Pronouns that corefer with nouns elsewhere in the search phrase are not permitted as this would overcomplicate the library without offering any benefits.
The following types of structures are strongly discouraged in search phrases:
Dog chase cat (English)
Hund jagen Katze (German)
Although these will sometimes work, the results will be better if search phrases are expressed grammatically.
A cat is chased by a dog (English)
A dog will have chased a cat (English)
Eine Katze wird durch einen Hund gejagt (German)
Ein Hund wird eine Katze gejagt haben (German)
Although these will sometimes work, the results will be better if verbs in search phrases are expressed in the present active.
Who chases the cat? (Anglais)
Wer jagt die Katze? (Allemand)
Although questions are supported as query phrases in the topic matching use case, they are not appropriate as search phrases. Questions should be re-phrased as statements, in this case
Something chases the cat (English)
Etwas jagt die Katze (German).
Informationsextraktion (German)
Ein Stadtmittetreffen (German)
The internal structure of German compound words is analysed within searched documents as well as within query phrases in the topic matching use case, but not within search phrases. In search phrases, compound words should be reexpressed as genitive constructions even in cases where this does not strictly capture their meaning:
Extraktion der Information (German)
Ein Treffen der Stadtmitte (German)
The following types of structures should be used with caution in search phrases:
A fierce dog chases a scared cat on the way to the theatre (English)
Ein kämpferischer Hund jagt eine verängstigte Katze auf dem Weg ins Theater (German)
Holmes can handle any level of complexity within search phrases, but the more complex a structure, the less likely it becomes that a document sentence will match it. If it is really necessary to match such complex relationships with search phrases rather than with topic matching, they are typically better extracted by splitting the search phrase up, eg
A fierce dog (English)
A scared cat (English)
A dog chases a cat (English)
Something chases something on the way to the theatre (English)
Ein kämpferischer Hund (German)
Eine verängstigte Katze (German)
Ein Hund jagt eine Katze (German)
Etwas jagt etwas auf dem Weg ins Theater (German)
Correlations between the resulting matches can then be established by matching via the Manager.match() function and looking for situations where the document token objects are shared across multiple match objects.
One possible exception to this piece of advice is when embedding-based matching is active. Because whether or not each word in a search phrase matches then depends on whether or not other words in the same search phrase have been matched, large, complex search phrases can sometimes yield results that a combination of smaller, simpler search phrases would not.
The chasing of a cat (English)
Die Jagd einer Katze (German)
These will often work, but it is generally better practice to use verbal search phrases like
Something chases a cat (English)
Etwas jagt eine Katze (German)
and to allow the corresponding nominal phrases to be matched via derivation-based matching.
The chatbot use case has already been introduced: a predefined set of search phrases is used to extract information from phrases entered interactively by an end user, which in this use case act as the documents.
The Holmes source code ships with two examples demonstrating the chatbot use case, one for each language, with predefined ontologies. Having cloned the source code and installed the Holmes library, navigate to the /examples directory and type the following (Linux):
Anglais:
python3 example_chatbot_EN_insurance.py
Allemand:
python3 example_chatbot_DE_insurance.py
or click on the files in Windows Explorer (Windows).
Holmes matches syntactically distinct structures that are semantically equivalent, ie that share the same meaning. In a real chatbot use case, users will typically enter equivalent information with phrases that are semantically distinct as well, ie that have different meanings. Because the effort involved in registering a search phrase is barely greater than the time it takes to type it in, it makes sense to register a large number of search phrases for each relationship you are trying to extract: essentially all ways people have been observed to express the information you are interested in or all ways you can imagine somebody might express the information you are interested in . To assist this, search phrases can be registered with labels that do not need to be unique: a label can then be used to express the relationship an entire group of search phrases is designed to extract. Note that when many search phrases have been defined to extract the same relationship, a single user entry is likely to be sometimes matched by multiple search phrases. This must be handled appropriately by the calling application.
One obvious weakness of Holmes in the chatbot setting is its sensitivity to correct spelling and, to a lesser extent, to correct grammar. Strategies for mitigating this weakness include:
The structural extraction use case uses structural matching in the same way as the chatbot use case, and many of the same comments and tips apply to it. The principal differences are that pre-existing and often lengthy documents are scanned rather than text snippets entered ad-hoc by the user, and that the returned match objects are not used to drive a dialog flow; they are examined solely to extract and store structured information.
Code for performing structural extraction would typically perform the following tasks:
Manager.register_search_phrase() several times to define a number of search phrases specifying the information to be extracted.Manager.parse_and_register_document() several times to load a number of documents within which to search.Manager.match() to perform the matching.The topic matching use case matches a query document , or alternatively a query phrase entered ad-hoc by the user, against a set of documents pre-loaded into memory. The aim is to find the passages in the documents whose topic most closely corresponds to the topic of the query document; the output is a ordered list of passages scored according to topic similarity. Additionally, if a query phrase contains an initial question word, the output will contain potential answers to the question.
Topic matching queries may contain generic pronouns and named-entity identifiers just like search phrases, although the ENTITYNOUN token is not supported. However, an important difference from search phrases is that the topic matching use case places no restrictions on the grammatical structures permissible within the query document.
In addition to the Holmes demonstration website, the Holmes source code ships with three examples demonstrating the topic matching use case with an English literature corpus, a German literature corpus and a German legal corpus respectively. Users are encouraged to run these to get a feel for how they work.
Topic matching uses a variety of strategies to find text passages that are relevant to the query. These include resource-hungry procedures like investigating semantic relationships and comparing embeddings. Because applying these across the board would prevent topic matching from scaling, Holmes only attempts them for specific areas of the text that less resource-intensive strategies have already marked as looking promising. This and the other interior workings of topic matching are explained here.
In the supervised document classification use case, a classifier is trained with a number of documents that are each pre-labelled with a classification. The trained classifier then assigns one or more labels to new documents according to what each new document is about. As explained here, ontologies can be used both to enrichen the comparison of the content of the various documents and to capture implication relationships between classification labels.
A classifier makes use of a neural network (a multilayer perceptron) whose topology can either be determined automatically by Holmes or specified explicitly by the user. With a large number of training documents, the automatically determined topology can easily exhaust the memory available on a typical machine; if there is no opportunity to scale up the memory, this problem can be remedied by specifying a smaller number of hidden layers or a smaller number of nodes in one or more of the layers.
A trained document classification model retains no references to its training data. This is an advantage from a data protection viewpoint, although it cannot presently be guaranteed that models will not contain individual personal or company names.
A typical problem with the execution of many document classification use cases is that a new classification label is added when the system is already live but that there are initially no examples of this new classification with which to train a new model. The best course of action in such a situation is to define search phrases which preselect the more obvious documents with the new classification using structural matching. Those documents that are not preselected as having the new classification label are then passed to the existing, previously trained classifier in the normal way. When enough documents exemplifying the new classification have accumulated in the system, the model can be retrained and the preselection search phrases removed.
Holmes ships with an example script demonstrating supervised document classification for English with the BBC Documents dataset. The script downloads the documents (for this operation and for this operation alone, you will need to be online) and places them in a working directory. When training is complete, the script saves the model to the working directory. If the model file is found in the working directory on subsequent invocations of the script, the training phase is skipped and the script goes straight to the testing phase. This means that if it is wished to repeat the training phase, either the model has to be deleted from the working directory or a new working directory has to be specified to the script.
Having cloned the source code and installed the Holmes library, navigate to the /examples directory. Specify a working directory at the top of the example_supervised_topic_model_EN.py file, then type python3 example_supervised_topic_model_EN (Linux) or click on the script in Windows Explorer (Windows).
It is important to realise that Holmes learns to classify documents according to the words or semantic relationships they contain, taking any structural matching ontology into account in the process. For many classification tasks, this is exactly what is required; but there are tasks (eg author attribution according to the frequency of grammatical constructions typical for each author) where it is not. For the right task, Holmes achieves impressive results. For the BBC Documents benchmark processed by the example script, Holmes performs slightly better than benchmarks available online (see eg here) although the difference is probably too slight to be significant, especially given that the different training/test splits were used in each case: Holmes has been observed to learn models that predict the correct result between 96.9% and 98.7% of the time. The range is explained by the fact that the behaviour of the neural network is not fully deterministic.
The interior workings of supervised document classification are explained here.
Manager holmes_extractor.Manager(self, model, *, overall_similarity_threshold=1.0,
embedding_based_matching_on_root_words=False, ontology=None,
analyze_derivational_morphology=True, perform_coreference_resolution=None,
number_of_workers=None, verbose=False)
The facade class for the Holmes library.
Parameters:
model -- the name of the spaCy model, e.g. *en_core_web_trf*
overall_similarity_threshold -- the overall similarity threshold for embedding-based
matching. Defaults to *1.0*, which deactivates embedding-based matching. Note that this
parameter is not relevant for topic matching, where the thresholds for embedding-based
matching are set on the call to *topic_match_documents_against*.
embedding_based_matching_on_root_words -- determines whether or not embedding-based
matching should be attempted on search-phrase root tokens, which has a considerable
performance hit. Defaults to *False*. Note that this parameter is not relevant for topic
matching.
ontology -- an *Ontology* object. Defaults to *None* (no ontology).
analyze_derivational_morphology -- *True* if matching should be attempted between different
words from the same word family. Defaults to *True*.
perform_coreference_resolution -- *True* if coreference resolution should be taken into account
when matching. Defaults to *True*.
use_reverse_dependency_matching -- *True* if appropriate dependencies in documents can be
matched to dependencies in search phrases where the two dependencies point in opposite
directions. Defaults to *True*.
number_of_workers -- the number of worker processes to use, or *None* if the number of worker
processes should depend on the number of available cores. Defaults to *None*
verbose -- a boolean value specifying whether multiprocessing messages should be outputted to
the console. Defaults to *False*
Manager.register_serialized_document(self, serialized_document:bytes, label:str="") -> None
Parameters:
document -- a preparsed Holmes document.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.register_serialized_documents(self, document_dictionary:dict[str, bytes]) -> None
Note that this function is the most efficient way of loading documents.
Parameters:
document_dictionary -- a dictionary from labels to serialized documents.
Manager.parse_and_register_document(self, document_text:str, label:str='') -> None
Parameters:
document_text -- the raw document text.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.remove_document(self, label:str) -> None
Manager.remove_all_documents(self, labels_starting:str=None) -> None
Parameters:
labels_starting -- a string starting the labels of documents to be removed,
or 'None' if all documents are to be removed.
Manager.list_document_labels(self) -> List[str]
Returns a list of the labels of the currently registered documents.
Manager.serialize_document(self, label:str) -> Optional[bytes]
Returns a serialized representation of a Holmes document that can be
persisted to a file. If 'label' is not the label of a registered document,
'None' is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.get_document(self, label:str='') -> Optional[Doc]
Returns a Holmes document. If *label* is not the label of a registered document, *None*
is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.debug_document(self, label:str='') -> None
Outputs a debug representation for a loaded document.
Parameters:
label -- the label of the document to be serialized.
Manager.register_search_phrase(self, search_phrase_text:str, label:str=None) -> SearchPhrase
Registers and returns a new search phrase.
Parameters:
search_phrase_text -- the raw search phrase text.
label -- a label for the search phrase, which need not be unique.
If label==None, the assigned label defaults to the raw search phrase text.
Manager.remove_all_search_phrases_with_label(self, label:str) -> None
Manager.remove_all_search_phrases(self) -> None
Manager.list_search_phrase_labels(self) -> List[str]
Manager.match(self, search_phrase_text:str=None, document_text:str=None) -> List[Dict]
Matches search phrases to documents and returns the result as match dictionaries.
Parameters:
search_phrase_text -- a text from which to generate a search phrase, or 'None' if the
preloaded search phrases should be used for matching.
document_text -- a text from which to generate a document, or 'None' if the preloaded
documents should be used for matching.
topic_match_documents_against(self, text_to_match:str, *,
use_frequency_factor:bool=True,
maximum_activation_distance:int=75,
word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7,
relation_score:int=300,
reverse_only_relation_score:int=200,
single_word_score:int=50,
single_word_any_tag_score:int=20,
initial_question_word_answer_score:int=600,
initial_question_word_behaviour:str='process',
different_match_cutoff_score:int=15,
overlapping_relation_multiplier:float=1.5,
embedding_penalty:float=0.6,
ontology_penalty:float=0.9,
relation_matching_frequency_threshold:float=0.25,
embedding_matching_frequency_threshold:float=0.5,
sideways_match_extent:int=100,
only_one_result_per_document:bool=False,
number_of_results:int=10,
document_label_filter:str=None,
tied_result_quotient:float=0.9) -> List[Dict]:
Returns a list of dictionaries representing the results of a topic match between an entered text
and the loaded documents.
Properties:
text_to_match -- the text to match against the loaded documents.
use_frequency_factor -- *True* if scores should be multiplied by a factor between 0 and 1
expressing how rare the words matching each phraselet are in the corpus. Note that,
even if this parameter is set to *False*, the factors are still calculated as they are
required for determining which relation and embedding matches should be attempted.
maximum_activation_distance -- the number of words it takes for a previous phraselet
activation to reduce to zero when the library is reading through a document.
word_embedding_match_threshold -- the cosine similarity above which two words match where
the search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
relation_score -- the activation score added when a normal two-word relation is matched.
reverse_only_relation_score -- the activation score added when a two-word relation
is matched using a search phrase that can only be reverse-matched.
single_word_score -- the activation score added when a single noun is matched.
single_word_any_tag_score -- the activation score added when a single word is matched
that is not a noun.
initial_question_word_answer_score -- the activation score added when a question word is
matched to an potential answer phrase.
initial_question_word_behaviour -- 'process' if a question word in the sentence
constituent at the beginning of *text_to_match* is to be matched to document phrases
that answer it and to matching question words; 'exclusive' if only topic matches that
answer questions are to be permitted; 'ignore' if question words are to be ignored.
different_match_cutoff_score -- the activation threshold under which topic matches are
separated from one another. Note that the default value will probably be too low if
*use_frequency_factor* is set to *False*.
overlapping_relation_multiplier -- the value by which the activation score is multiplied
when two relations were matched and the matches involved a common document word.
embedding_penalty -- a value between 0 and 1 with which scores are multiplied when the
match involved an embedding. The result is additionally multiplied by the overall
similarity measure of the match.
ontology_penalty -- a value between 0 and 1 with which scores are multiplied for each
word match within a match that involved the ontology. For each such word match,
the score is multiplied by the value (abs(depth) + 1) times, so that the penalty is
higher for hyponyms and hypernyms than for synonyms and increases with the
depth distance.
relation_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches.
embedding_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches with
embedding-based matching on the second word.
sideways_match_extent -- the maximum number of words that may be incorporated into a
topic match either side of the word where the activation peaked.
only_one_result_per_document -- if 'True', prevents multiple results from being returned
for the same document.
number_of_results -- the number of topic match objects to return.
document_label_filter -- optionally, a string with which document labels must start to
be considered for inclusion in the results.
tied_result_quotient -- the quotient between a result and following results above which
the results are interpreted as tied.
Manager.get_supervised_topic_training_basis(self, *, classification_ontology:Ontology=None,
overlap_memory_size:int=10, oneshot:bool=True, match_all_words:bool=False,
verbose:bool=True) -> SupervisedTopicTrainingBasis:
Returns an object that is used to train and generate a model for the
supervised document classification use case.
Parameters:
classification_ontology -- an Ontology object incorporating relationships between
classification labels, or 'None' if no such ontology is to be used.
overlap_memory_size -- how many non-word phraselet matches to the left should be
checked for words in common with a current match.
oneshot -- whether the same word or relationship matched multiple times within a
single document should be counted once only (value 'True') or multiple times
(value 'False')
match_all_words -- whether all single words should be taken into account
(value 'True') or only single words with noun tags (value 'False')
verbose -- if 'True', information about training progress is outputted to the console.
Manager.deserialize_supervised_topic_classifier(self,
serialized_model:bytes, verbose:bool=False) -> SupervisedTopicClassifier:
Returns a classifier for the supervised document classification use case
that will use a supplied pre-trained model.
Parameters:
serialized_model -- the pre-trained model as returned from `SupervisedTopicClassifier.serialize_model()`.
verbose -- if 'True', information about matching is outputted to the console.
Manager.start_chatbot_mode_console(self)
Starts a chatbot mode console enabling the matching of pre-registered
search phrases to documents (chatbot entries) entered ad-hoc by the
user.
Manager.start_structural_search_mode_console(self)
Starts a structural extraction mode console enabling the matching of pre-registered
documents to search phrases entered ad-hoc by the user.
Manager.start_topic_matching_search_mode_console(self,
only_one_result_per_document:bool=False, word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7):
Starts a topic matching search mode console enabling the matching of pre-registered
documents to query phrases entered ad-hoc by the user.
Parameters:
only_one_result_per_document -- if 'True', prevents multiple topic match
results from being returned for the same document.
word_embedding_match_threshold -- the cosine similarity above which two words match where the
search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
Manager.close(self) -> None
Terminates the worker processes.
manager.nlp manager.nlp is the underlying spaCy Language object on which both Coreferee and Holmes have been registered as custom pipeline components. The most efficient way of parsing documents for use with Holmes is to call manager.nlp.pipe() . This yields an iterable of documents that can then be loaded into Holmes via manager.register_serialized_documents() .
The pipe() method has an argument n_process that specifies the number of processors to use. With _lg , _md and _sm spaCy models, there are some situations where it can make sense to specify a value other than 1 (the default). Note however that with transformer spaCy models ( _trf ) values other than 1 are not supported.
Ontology holmes_extractor.Ontology(self, ontology_path,
owl_class_type='http://www.w3.org/2002/07/owl#Class',
owl_individual_type='http://www.w3.org/2002/07/owl#NamedIndividual',
owl_type_link='http://www.w3.org/1999/02/22-rdf-syntax-ns#type',
owl_synonym_type='http://www.w3.org/2002/07/owl#equivalentClass',
owl_hyponym_type='http://www.w3.org/2000/01/rdf-schema#subClassOf',
symmetric_matching=False)
Loads information from an existing ontology and manages ontology
matching.
The ontology must follow the W3C OWL 2 standard. Search phrase words are
matched to hyponyms, synonyms and instances from within documents being
searched.
This class is designed for small ontologies that have been constructed
by hand for specific use cases. Where the aim is to model a large number
of semantic relationships, word embeddings are likely to offer
better results.
Holmes is not designed to support changes to a loaded ontology via direct
calls to the methods of this class. It is also not permitted to share a single instance
of this class between multiple Manager instances: instead, a separate Ontology instance
pointing to the same path should be created for each Manager.
Matching is case-insensitive.
Parameters:
ontology_path -- the path from where the ontology is to be loaded,
or a list of several such paths. See https://github.com/RDFLib/rdflib/.
owl_class_type -- optionally overrides the OWL 2 URL for types.
owl_individual_type -- optionally overrides the OWL 2 URL for individuals.
owl_type_link -- optionally overrides the RDF URL for types.
owl_synonym_type -- optionally overrides the OWL 2 URL for synonyms.
owl_hyponym_type -- optionally overrides the RDF URL for hyponyms.
symmetric_matching -- if 'True', means hypernym relationships are also taken into account.
SupervisedTopicTrainingBasis (returned from Manager.get_supervised_topic_training_basis() )Holder object for training documents and their classifications from which one or more SupervisedTopicModelTrainer objects can be derived. This class is NOT threadsafe.
SupervisedTopicTrainingBasis.parse_and_register_training_document(self, text:str, classification:str,
label:Optional[str]=None) -> None
Parses and registers a document to use for training.
Parameters:
text -- the document text
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_training_document(self, doc:Doc, classification:str,
label:Optional[str]=None) -> None
Registers a pre-parsed document to use for training.
Parameters:
doc -- the document
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_additional_classification_label(self, label:str) -> None
Register an additional classification label which no training document possesses explicitly
but that should be assigned to documents whose explicit labels are related to the
additional classification label via the classification ontology.
SupervisedTopicTrainingBasis.prepare(self) -> None
Matches the phraselets derived from the training documents against the training
documents to generate frequencies that also include combined labels, and examines the
explicit classification labels, the additional classification labels and the
classification ontology to derive classification implications.
Once this method has been called, the instance no longer accepts new training documents
or additional classification labels.
SupervisedTopicTrainingBasis.train(
self,
*,
minimum_occurrences: int = 4,
cv_threshold: float = 1.0,
learning_rate: float = 0.001,
batch_size: int = 5,
max_epochs: int = 200,
convergence_threshold: float = 0.0001,
hidden_layer_sizes: Optional[List[int]] = None,
shuffle: bool = True,
normalize: bool = True
) -> SupervisedTopicModelTrainer:
Trains a model based on the prepared state.
Parameters:
minimum_occurrences -- the minimum number of times a word or relationship has to
occur in the context of the same classification for the phraselet
to be accepted into the final model.
cv_threshold -- the minimum coefficient of variation with which a word or relationship has
to occur across the explicit classification labels for the phraselet to be
accepted into the final model.
learning_rate -- the learning rate for the Adam optimizer.
batch_size -- the number of documents in each training batch.
max_epochs -- the maximum number of training epochs.
convergence_threshold -- the threshold below which loss measurements after consecutive
epochs are regarded as equivalent. Training stops before 'max_epochs' is reached
if equivalent results are achieved after four consecutive epochs.
hidden_layer_sizes -- a list containing the number of neurons in each hidden layer, or
'None' if the topology should be determined automatically.
shuffle -- 'True' if documents should be shuffled during batching.
normalize -- 'True' if normalization should be applied to the loss function.
SupervisedTopicModelTrainer (returned from SupervisedTopicTrainingBasis.train() ) Worker object used to train and generate models. This object could be removed from the public interface ( SupervisedTopicTrainingBasis.train() could return a SupervisedTopicClassifier directly) but has been retained to facilitate testability.
This class is NOT threadsafe.
SupervisedTopicModelTrainer.classifier(self)
Returns a supervised topic classifier which contains no explicit references to the training data and that
can be serialized.
SupervisedTopicClassifier (returned from SupervisedTopicModelTrainer.classifier() and Manager.deserialize_supervised_topic_classifier() ))
SupervisedTopicClassifier.def parse_and_classify(self, text: str) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
text -- the text to parse and classify.
SupervisedTopicClassifier.classify(self, doc: Doc) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
doc -- the pre-parsed document to classify.
SupervisedTopicClassifier.serialize_model(self) -> str
Returns a serialized model that can be reloaded using
*Manager.deserialize_supervised_topic_classifier()*
Manager.match() A text-only representation of a match between a search phrase and a
document. The indexes refer to tokens.
Properties:
search_phrase_label -- the label of the search phrase.
search_phrase_text -- the text of the search phrase.
document -- the label of the document.
index_within_document -- the index of the match within the document.
sentences_within_document -- the raw text of the sentences within the document that matched.
negated -- 'True' if this match is negated.
uncertain -- 'True' if this match is uncertain.
involves_coreference -- 'True' if this match was found using coreference resolution.
overall_similarity_measure -- the overall similarity of the match, or
'1.0' if embedding-based matching was not involved in the match.
word_matches -- an array of dictionaries with the properties:
search_phrase_token_index -- the index of the token that matched from the search phrase.
search_phrase_word -- the string that matched from the search phrase.
document_token_index -- the index of the token that matched within the document.
first_document_token_index -- the index of the first token that matched within the document.
Identical to 'document_token_index' except where the match involves a multiword phrase.
last_document_token_index -- the index of the last token that matched within the document
(NOT one more than that index). Identical to 'document_token_index' except where the match
involves a multiword phrase.
structurally_matched_document_token_index -- the index of the token within the document that
structurally matched the search phrase token. Is either the same as 'document_token_index' or
is linked to 'document_token_index' within a coreference chain.
document_subword_index -- the index of the token subword that matched within the document, or
'None' if matching was not with a subword but with an entire token.
document_subword_containing_token_index -- the index of the document token that contained the
subword that matched, which may be different from 'document_token_index' in situations where a
word containing multiple subwords is split by hyphenation and a subword whose sense
contributes to a word is not overtly realised within that word.
document_word -- the string that matched from the document.
document_phrase -- the phrase headed by the word that matched from the document.
match_type -- 'direct', 'derivation', 'entity', 'embedding', 'ontology', 'entity_embedding'
or 'question'.
negated -- 'True' if this word match is negated.
uncertain -- 'True' if this word match is uncertain.
similarity_measure -- for types 'embedding' and 'entity_embedding', the similarity between the
two tokens, otherwise '1.0'.
involves_coreference -- 'True' if the word was matched using coreference resolution.
extracted_word -- within the coreference chain, the most specific term that corresponded to
the document_word.
depth -- the number of hyponym relationships linking 'search_phrase_word' and
'extracted_word', or '0' if ontology-based matching is not active. Can be negative
if symmetric matching is active.
explanation -- creates a human-readable explanation of the word match from the perspective of the
document word (e.g. to be used as a tooltip over it).
Manager.topic_match_documents_against() A text-only representation of a topic match between a search text and a document.
Properties:
document_label -- the label of the document.
text -- the document text that was matched.
text_to_match -- the search text.
rank -- a string representation of the scoring rank which can have the form e.g. '2=' in case of a tie.
index_within_document -- the index of the document token where the activation peaked.
subword_index -- the index of the subword within the document token where the activation peaked, or
'None' if the activation did not peak at a specific subword.
start_index -- the index of the first document token in the topic match.
end_index -- the index of the last document token in the topic match (NOT one more than that index).
sentences_start_index -- the token start index within the document of the sentence that contains
'start_index'
sentences_end_index -- the token end index within the document of the sentence that contains
'end_index' (NOT one more than that index).
sentences_character_start_index_in_document -- the character index of the first character of 'text'
within the document.
sentences_character_end_index_in_document -- one more than the character index of the last
character of 'text' within the document.
score -- the score
word_infos -- an array of arrays with the semantics:
[0] -- 'relative_start_index' -- the index of the first character in the word relative to
'sentences_character_start_index_in_document'.
[1] -- 'relative_end_index' -- one more than the index of the last character in the word
relative to 'sentences_character_start_index_in_document'.
[2] -- 'type' -- 'single' for a single-word match, 'relation' if within a relation match
involving two words, 'overlapping_relation' if within a relation match involving three
or more words.
[3] -- 'is_highest_activation' -- 'True' if this was the word at which the highest activation
score reported in 'score' was achieved, otherwise 'False'.
[4] -- 'explanation' -- a human-readable explanation of the word match from the perspective of
the document word (e.g. to be used as a tooltip over it).
answers -- an array of arrays with the semantics:
[0] -- the index of the first character of a potential answer to an initial question word.
[1] -- one more than the index of the last character of a potential answer to an initial question
word.
Earlier versions of Holmes could only be published under a restrictive license because of patent issues. As explained in the introduction, this is no longer the case thanks to the generosity of AstraZeneca: versions from 4.0.0 onwards are licensed under the MIT license.
The word-level matching and the high-level operation of structural matching between search-phrase and document subgraphs both work more or less as one would expect. What is perhaps more in need of further comment is the semantic analysis code subsumed in the parsing.py script as well as in the language_specific_rules.py script for each language.
SemanticAnalyzer is an abstract class that is subclassed for each language: at present by EnglishSemanticAnalyzer and GermanSemanticAnalyzer . These classes contain most of the semantic analysis code. SemanticMatchingHelper is a second abstract class, again with an concrete implementation for each language, that contains semantic analysis code that is required at matching time. Moving this out to a separate class family was necessary because, on operating systems that spawn processes rather than forking processes (eg Windows), SemanticMatchingHelper instances have to be serialized when the worker processes are created: this would not be possible for SemanticAnalyzer instances because not all spaCy models are serializable, and would also unnecessarily consume large amounts of memory.
At present, all functionality that is common to the two languages is realised in the two abstract parent classes. Especially because English and German are closely related languages, it is probable that functionality will need to be moved from the abstract parent classes to specific implementing children classes if and when new semantic analyzers are added for new languages.
The HolmesDictionary class is defined as a spaCy extension attribute that is accessed using the syntax token._.holmes . The most important information in the dictionary is a list of SemanticDependency objects. These are derived from the dependency relationships in the spaCy output ( token.dep_ ) but go through a considerable amount of processing to make them 'less syntactic' and 'more semantic'. To give but a few examples:
Some new semantic dependency labels that do not occur in spaCy outputs as values of token.dep_ are added for Holmes semantic dependencies. It is important to understand that Holmes semantic dependencies are used exclusively for matching and are therefore neither intended nor required to form a coherent set of linguistic theoretical entities or relationships; whatever works best for matching is assigned on an ad-hoc basis.
For each language, the match_implication_dict dictionary maps search-phrase semantic dependencies to matching document semantic dependencies and is responsible for the asymmetry of matching between search phrases and documents.
Topic matching involves the following steps:
SemanticMatchingHelper.topic_matching_phraselet_stop_lemmas ), which are consistently ignored throughout the whole process.SemanticMatchingHelper.phraselet_templates .SemanticMatchingHelper.topic_matching_reverse_only_parent_lemmas ) or when the frequency factor for the parent word is below the threshold for relation matching ( relation_matching_frequency_threshold , default: 0.25). These measures are necessary because matching on eg a parent preposition would lead to a large number of potential matches that would take a lot of resources to investigate: it is better to start investigation from the less frequent word within a given relation.relation_matching_frequency_threshold , default: 0.25).embedding_matching_frequency_threshold , default: 0.5), matching at all of those words where the relation template has not already been matched is retried using embeddings at the other word within the relation. A pair of words is then regarded as matching when their mutual cosine similarity is above initial_question_word_embedding_match_threshold (default: 0.7) in situations where the document word has an initial question word in its phrase or word_embedding_match_threshold (default: 0.8) in all other situations.use_frequency_factor is set to True (the default), each score is scaled by the frequency factor of its phraselet, meaning that words that occur less frequently in the corpus give rise to higher scores.maximum_activation_distance ; default: 75) of its value is subtracted from it as each new word is read.single_word_score ; default: 50), a non-noun single-word phraselet or a noun phraselet that matched a subword ( single_word_any_tag_score ; default: 20), a relation phraselet produced by a reverse-only template ( reverse_only_relation_score ; default: 200), any other (normally matched) relation phraselet ( relation_score ; default: 300), or a relation phraselet involving an initial question word ( initial_question_word_answer_score ; default: 600).embedding_penalty ; default: 0.6).ontology_penalty ; default: 0.9) once more often than the difference in depth between the two ontology entries, ie once for a synonym, twice for a child, three times for a grandchild and so on.overlapping_relation_multiplier ; default: 1.5).sideways_match_extent ; default: 100 words) within which the activation score is higher than the different_match_cutoff_score (default: 15) are regarded as belonging to a contiguous passage around the peak that is then returned as a TopicMatch object. (Note that this default will almost certainly turn out to be too low if use_frequency_factor is set to False .) A word whose activation equals the threshold exactly is included at the beginning of the area as long as the next word where activation increases has a score above the threshold. If the topic match peak is below the threshold, the topic match will only consist of the peak word.initial_question_word_behaviour is set to process (the default) or to exclusive , where a document word has matched an initial question word from the query phrase, the subtree of the matched document word is identified as a potential answer to the question and added to the dictionary to be returned. If initial_question_word_behaviour is set to exclusive , any topic matches that do not contain answers to initial question words are discarded.only_one_result_per_document = True prevents more than one result from being returned from the same document; only the result from each document with the highest score will then be returned.tied_result_quotient (default: 0.9) are labelled as tied. The supervised document classification use case relies on the same phraselets as the topic matching use case, although reverse-only templates are ignored and a different set of stop words is used ( SemanticMatchingHelper.supervised_document_classification_phraselet_stop_lemmas ). Classifiers are built and trained as follows:
oneshot ; whether single-word phraselets are generated for all words with their own meaning or only for those such words whose part-of-speech tags match the single-word phraselet template specification (essentially: noun phraselets) depends on the value of match_all_words . Wherever two phraselet matches overlap, a combined match is recorded. Combined matches are treated in the same way as other phraselet matches in further processing. This means that effectively the algorithm picks up one-word, two-word and three-word semantic combinations. See here for a discussion of the performance of this step.minimum_occurrences ; default: 4) or where the coefficient of variation (the standard deviation divided by the arithmetic mean) of the occurrences across the categories is below a threshold ( cv_threshold ; default: 1.0).oneshot==True vs. oneshot==False respectively). The outputs are the category labels, including any additional labels determined via a classification ontology. By default, the multilayer perceptron has three hidden layers where the first hidden layer has the same number of neurons as the input layer and the second and third layers have sizes in between the input and the output layer with an equally sized step between each size; the user is however free to specify any other topology.Holmes code is formatted with black.
The complexity of what Holmes does makes development impossible without a robust set of over 1400 regression tests. These can be executed individually with unittest or all at once by running the pytest utility from the Holmes source code root directory. (Note that the Python 3 command on Linux is pytest-3 .)
The pytest variant will only work on machines with sufficient memory resources. To reduce this problem, the tests are distributed across three subdirectories, so that pytest can be run three times, once from each subdirectory:
New languages can be added to Holmes by subclassing the SemanticAnalyzer and SemanticMatchingHelper classes as explained here.
The sets of matching semantic dependencies captured in the _matching_dep_dict dictionary for each language have been obtained on the basis of a mixture of linguistic-theoretical expectations and trial and error. The results would probably be improved if the _matching_dep_dict dictionaries could be derived using machine learning instead; as yet this has not been attempted because of the lack of appropriate training data.
An attempt should be made to remove personal data from supervised document classification models to make them more compliant with data protection laws.
In cases where embedding-based matching is not active, the second step of the supervised document classification procedure repeats a considerable amount of processing from the first step. Retaining the relevant information from the first step of the procedure would greatly improve training performance. This has not been attempted up to now because a large number of tests would be required to prove that such performance improvements did not have any inadvertent impacts on functionality.
The topic matching and supervised document classification use cases are both configured with a number of hyperparameters that are presently set to best-guess values derived on a purely theoretical basis. Results could be further improved by testing the use cases with a variety of hyperparameters to learn the optimal values.
The initial open-source version.
pobjp linking parents of prepositions directly with their children.MultiprocessingManager object as its facade.Manager and MultiprocessingManager classes into a single Manager class, with a redesigned public interface, that uses worker threads for everything except supervised document classification.

