holmes extractor
Holmes 4.0.0
著者:リチャード・ポール・ハドソン、爆発AI
Managermanager.nlpOntologySupervisedTopicTrainingBasis ( Manager.get_supervised_topic_training_basis() )から返品SupervisedTopicModelTrainer ( SupervisedTopicTrainingBasis.train() )から返品SupervisedTopicClassifier ( SupervisedTopicModelTrainer.classifier()およびManager.deserialize_supervised_topic_classifier() )から返送Manager.match()から返された辞書Manager.topic_match_documents_against()から返送ホームズは、英語とドイツ語のテキストからの情報抽出を含む多くのユースケースをサポートするスペイシー(v3.1 — V3.3)の上で実行されるPython 3ライブラリ(v3.6 — V3.10)です。すべてのユースケースで、情報抽出は、各文のコンポーネント部分によって表されるセマンティック関係の分析に基づいています。
チャットボットのユースケースでは、システムは1つ以上の検索フレーズを使用して構成されています。その後、ホームズは、検索されたドキュメント内のこれらの検索フレーズの意味に対応する構造を探します。この場合、この場合、エンドユーザーが入力したテキストまたはスピーチの個々のスニペットに対応します。試合内では、検索フレーズの独自の意味(つまり、文法機能を満たすだけではない)を持つ各単語は、ドキュメント内の1つ以上のそのような単語に対応しています。検索フレーズが一致したという事実と、検索フレーズ抽出物を使用してチャットボットを駆動できるという事実の両方。
構造抽出ユースケースは、チャットボットの使用ケースとまったく同じ構造マッチングテクノロジーを使用しますが、検索は、チャットボットのユースケースで分析されたスニペットよりもはるかに長い既存のドキュメントまたはドキュメントに関して行われ、目的は構造化された情報を抽出および保存することです。たとえば、一連のビジネス記事を検索して、1つの会社が2番目の会社を引き継ぐことを計画していると言われているすべての場所を見つけることができます。関係する企業のアイデンティティは、データベースに保存される可能性があります。
一致するユースケースのトピックは、クエリドキュメントの役割を引き受ける別のドキュメントの意味に意味があるドキュメントまたはドキュメントの文書に文書またはドキュメントの文書を見つけることを目的としています。 Holmesは、クエリフレーズまたはクエリドキュメントから多くの小さなフラートレットを抽出し、各フラセルトに対して検索されているドキュメントと一致し、結果を組み立ててドキュメント内の最も関連性の高いパッセージを見つけます。クエリドキュメントに独自の意味を持つすべての単語が検索されたドキュメントの特定の単語または単語が一致するという厳格な要件はないため、構造抽出の使用ケースよりも多くの一致が見つかりますが、一致には後続の処理で使用できる構造化された情報は含まれていません。トピックマッチングユースケースは、6つのチャールズディケンズの小説(英語)と約350の伝統的なストーリー(ドイツ語)内で検索を許可するWebサイトによって実証されています。
監督されたドキュメント分類ユースケースは、トレーニングデータを使用して、1つ以上の分類ラベルを新しいドキュメントに基づいて新しいドキュメントに割り当てる分類子を学習します。これは、トピックのユースケースと一致するクエリドキュメントからフラセレットが抽出されるのと同じ方法で、トレーニングドキュメントから抽出されたフラートレットと一致させることにより、新しいドキュメントを分類します。この手法は、n-gramsを使用するが、コンポーネントの単語が言語の表面表現の隣人であるよりも意味的に関連するn-gramsを導き出すことを目的とした、n-gramsを使用するバッグベースの分類アルゴリズムに触発されています。
4つのユースケースすべてで、個々の単語は多くの戦略を使用して一致します。個別に一致する単語を含む2つの文法構造が論理的に対応し、一致を構成するかどうかを判断するために、ホームズは、Spacyライブラリが提供する構文解析情報を、述語ロジックを使用してテキストを比較できるテキストを可能にする意味構造に変換します。 Holmesのユーザーとして、これがどのように機能するかの複雑さを理解する必要はありませんが、チャットボットの効果的な検索フレーズを作成し、搭載しようとする必要がある構造的抽出使用ケースを作成することに関する重要なヒントがいくつかあります。
Holmesは、比較的少ないチューニング、微調整、トレーニングで、多かれ少なかれ箱から出して使用できるジェネラリストのソリューションを提供することを目指しています。その中心には、各言語の構文表現が意味関係を表現する方法を説明する論理的でプログラムされたルールベースのシステムがあります。監視されたドキュメント分類ユースケースにはニューラルネットワークが組み込まれていますが、ホームズが構築するスペイシーライブラリは機械学習を使用して事前に訓練されていますが、ホームズの本質的にルールベースの性質は、チャットボット、構造抽出、トピックマッチングユースケースを使用することができます。多くの現実世界の問題。
ホームズには長く複雑な歴史があり、いくつかの企業の善意と開放性のおかげで、MITライセンスの下でそれを公開することができます。私、リチャード・ハドソンは、ミュンヘン近くに拠点を置く大規模な国際ソフトウェアコンサルタントであるMSG Systemsで働いている間に、3.0.0までのバージョンを書きました。 2021年後半、私は雇用主を変え、現在はスペイシーと天才の作成者である爆発のために働いています。ホームズ図書館の要素は、2000年代初頭に私自身が書いた米国の特許でカバーされています。 AstrazenecaとMSGシステムの両方の親切な許可を得て、私は現在、ホームズを爆発時に維持しており、寛容なライセンスの下で初めて提供できます。
ライブラリはもともとMSGシステムで開発されていましたが、現在は爆発AIで維持されています。爆発リポジトリに新しい問題や議論を指示してください。
マシンにPython 3とPIPがまだない場合は、Holmesをインストールする前にインストールする必要があります。
次のコマンドを使用してホームズをインストールします。
Linux:
pip3 install holmes-extractor
Windows:
pip install holmes-extractor
以前のHolmesバージョンからアップグレードするには、次のコマンドを発行し、コマンドを再発行してSpacyおよびCorefereeモデルをダウンロードして、正しいバージョンを確実に持っていることを確認してください。
Linux:
pip3 install --upgrade holmes-extractor
Windows:
pip install --upgrade holmes-extractor
例とテストを使用する場合は、使用してソースコードをクローンします
git clone https://github.com/explosion/holmes-extractor
ソースコードの変更を試してみたい場合は、変更されたholmes_extractorモジュールコードが変更されているディレクトリの親ディレクトリで、python( python3 (linux)またはpython (windows)を入力)を起動して、インストールされたコードをオーバーライドできます。 GitからHolmesをチェックした場合、これはholmes-extractorディレクトリになります。
Holmesを再度アンインストールする場合は、これはファイルシステムからインストールされたファイルを直接削除することで実現されます。これらは、 holmes_extractorの親ディレクトリ以外の任意のディレクトリから開始されたPythonコマンドプロンプトから以下を発行することで見つけることができます。
import holmes_extractor
print(holmes_extractor.__file__)
ホームズが構築するスペイシーとコアファリーのライブラリは、ホームズを使用する前に個別にダウンロードする必要がある言語固有のモデルを必要とします。
Linux/英語:
python3 -m spacy download en_core_web_trf
python3 -m spacy download en_core_web_lg
python3 -m coreferee install en
Linux/ドイツ語:
pip3 install spacy-lookups-data # (from spaCy 3.3 onwards)
python3 -m spacy download de_core_news_lg
python3 -m coreferee install de
Windows/英語:
python -m spacy download en_core_web_trf
python -m spacy download en_core_web_lg
python -m coreferee install en
Windows/ドイツ語:
pip install spacy-lookups-data # (from spaCy 3.3 onwards)
python -m spacy download de_core_news_lg
python -m coreferee install de
そして、回帰テストを実行する予定がある場合:
Linux:
python3 -m spacy download en_core_web_sm
Windows:
python -m spacy download en_core_web_sm
マネージャーファサードクラスをインスタンス化するときに、ホームズが使用するスペイシーモデルを指定します。 en_core_web_trfとde_core_web_lgは、それぞれ英語とドイツ語に最適な結果をもたらすことがわかったモデルです。 en_core_web_trfには独自の単語ベクトルがないが、ホームズは埋め込みベースのマッチングにワードベクトルを必要とするため、 en_core_web_lgモデルは、 en_core_web_trfがメインモデルとしてマネージャークラスに指定されるたびにベクトルソースとしてロードされます。
en_core_web_trfモデルは、他のモデルよりも十分に多くのリソースを必要とします。リソースが不足しているsiutionでは、代わりにen_core_web_lgメインモデルとして使用することは賢明な妥協かもしれません。
Holmesを非Python環境に統合する最良の方法は、Restful HTTPサービスとしてそれを包み、マイクロサービスとして展開することです。例については、こちらをご覧ください。
Holmesは複雑でインテリジェントな分析を実行するため、従来の検索フレームワークよりも多くのハードウェアリソースを必要とすることは避けられません。ドキュメントの読み込み(構造抽出とトピックマッチング)が含まれるユースケースは、大規模ではないが大規模なコーパスにはすぐに適用できます(たとえば、特定の組織に属するすべての文書、特定のトピックのすべての特許、特定の著者によるすべての本)。コストの理由から、ホームズはインターネット全体のコンテンツを分析するための適切なツールではありません!
とはいえ、ホームズは垂直方向と水平方向の両方のスケーラブルです。十分なハードウェアを使用すると、これらのユースケースは両方とも、複数のマシンでホームズを実行し、それぞれに異なるドキュメントセットを処理して結果を混同することにより、本質的に無制限の数のドキュメントに適用できます。この戦略は、単一のマシン上の複数のコア間のマッチングを配布するために既に採用されていることに注意してください。マネージャークラスは、多くのワーカープロセスを開始し、それらの間に登録されたドキュメントを配布します。
ホームズは、ロードされたドキュメントをメモリに保持しています。これは、大規模ではなく大規模なコーパスでの使用を意図した使用と結びついています。ホームズが単一の文を処理するときにさまざまなページからのメモリをアドレス指定する必要があるため、オペレーティングシステムがメモリページをセカンダリストレージに交換する必要がある場合、オペレーティングシステムがメモリページをセカンダリストレージに交換する必要がある場合、ドキュメントの読み込み、構造抽出、およびトピックマッチングのパフォーマンスはすべて大きく劣化します。これは、すべてのロードされたドキュメントを保持するために、各マシンに十分なRAMを供給することが重要であることを意味します。
さまざまなモデルの相対的なリソース要件に関する上記のコメントに注意してください。
ホームズの仕組みについて簡単に基本的なアイデアを得るための最も簡単なユースケースは、チャットボットのユースケースです。
ここでは、1つ以上の検索フレーズがHolmesに事前に定義されており、検索されたドキュメントは、エンドユーザーがインタラクティブに入力した短い文または段落です。実際の設定では、抽出された情報を使用して、エンドユーザーとの相互作用の流れを決定します。テストとデモンストレーションのために、一致した調査結果をインタラクティブに表示するコンソールがあります。 Pythonコマンドライン( python3 (Linux)またはpython (Windows)を入力することでオペレーティングシステムプロンプトから開始)またはJupyter Notebook内から簡単かつ迅速に開始できます。
次のコードスニペットは、Pythonコマンドライン、Jupyterノートブック、またはIDEにラインのラインを入力できます。それは、あなたが猫を追いかけている大きな犬についての文に興味があるという事実を登録し、デモンストレーションチャットボットコンソールを開始します。
英語:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='en_core_web_lg', number_of_workers=1)
holmes_manager.register_search_phrase('A big dog chases a cat')
holmes_manager.start_chatbot_mode_console()
ドイツ語:
import holmes_extractor as holmes
holmes_manager = holmes.Manager(model='de_core_news_lg', number_of_workers=1)
holmes_manager.register_search_phrase('Ein großer Hund jagt eine Katze')
holmes_manager.start_chatbot_mode_console()
検索フレーズに対応する文を入力した場合、コンソールはマッチを表示します。
英語:
Ready for input
A big dog chased a cat
Matched search phrase with text 'A big dog chases a cat':
'big'->'big' (Matches BIG directly); 'A big dog'->'dog' (Matches DOG directly); 'chased'->'chase' (Matches CHASE directly); 'a cat'->'cat' (Matches CAT directly)
ドイツ語:
Ready for input
Ein großer Hund jagte eine Katze
Matched search phrase 'Ein großer Hund jagt eine Katze':
'großer'->'groß' (Matches GROSS directly); 'Ein großer Hund'->'hund' (Matches HUND directly); 'jagte'->'jagen' (Matches JAGEN directly); 'eine Katze'->'katze' (Matches KATZE directly)
これは、単純な一致するアルゴリズムで簡単に達成できた可能性があるため、ホームズが本当に把握していて、マッチがまだ返されていることを自分自身に納得させるために、さらに複雑な文章を入力してください。
英語:
The big dog would not stop chasing the cat
The big dog who was tired chased the cat
The cat was chased by the big dog
The cat always used to be chased by the big dog
The big dog was going to chase the cat
The big dog decided to chase the cat
The cat was afraid of being chased by the big dog
I saw a cat-chasing big dog
The cat the big dog chased was scared
The big dog chasing the cat was a problem
There was a big dog that was chasing a cat
The cat chase by the big dog
There was a big dog and it was chasing a cat.
I saw a big dog. My cat was afraid of being chased by the dog.
There was a big dog. His name was Fido. He was chasing my cat.
A dog appeared. It was chasing a cat. It was very big.
The cat sneaked back into our lounge because a big dog had been chasing her.
Our big dog was excited because he had been chasing a cat.
ドイツ語:
Der große Hund hat die Katze ständig gejagt
Der große Hund, der müde war, jagte die Katze
Die Katze wurde vom großen Hund gejagt
Die Katze wurde immer wieder durch den großen Hund gejagt
Der große Hund wollte die Katze jagen
Der große Hund entschied sich, die Katze zu jagen
Die Katze, die der große Hund gejagt hatte, hatte Angst
Dass der große Hund die Katze jagte, war ein Problem
Es gab einen großen Hund, der eine Katze jagte
Die Katzenjagd durch den großen Hund
Es gab einmal einen großen Hund, und er jagte eine Katze
Es gab einen großen Hund. Er hieß Fido. Er jagte meine Katze
Es erschien ein Hund. Er jagte eine Katze. Er war sehr groß.
Die Katze schlich sich in unser Wohnzimmer zurück, weil ein großer Hund sie draußen gejagt hatte
Unser großer Hund war aufgeregt, weil er eine Katze gejagt hatte
デモンストレーションは、同じ単語を含むが同じアイデアを表現していない他の文を試しても、それらが一致していないことを観察せずに完全ではありません。
英語:
The dog chased a big cat
The big dog and the cat chased about
The big dog chased a mouse but the cat was tired
The big dog always used to be chased by the cat
The big dog the cat chased was scared
Our big dog was upset because he had been chased by a cat.
The dog chase of the big cat
ドイツ語:
Der Hund jagte eine große Katze
Die Katze jagte den großen Hund
Der große Hund und die Katze jagten
Der große Hund jagte eine Maus aber die Katze war müde
Der große Hund wurde ständig von der Katze gejagt
Der große Hund entschloss sich, von der Katze gejagt zu werden
Die Hundejagd durch den große Katze
上記の例では、ホームズは同じ意味を共有するさまざまな文レベルの構造と一致していますが、一致したドキュメントの3つの単語の基本形式は、検索フレーズの3つの単語と常に同じでした。ホームズは、個々の単語レベルでマッチングするためのいくつかのさらなる戦略を提供します。さまざまな文構造を一致させるホームズの能力と組み合わせて、これらは検索フレーズを文書文に一致させることができます。この文は、2つが単語を共有せず、文法的に完全に異なる場合でも意味を共有します。
これらの追加の単語マッチング戦略の1つは、名前が付けられたマッチングです。特別な単語は、人や場所などの名前のクラス全体に一致する検索フレーズに含めることができます。 exitを入力してコンソールを終了し、2番目の検索フレーズを登録し、コンソールを再起動します。
英語:
holmes_manager.register_search_phrase('An ENTITYPERSON goes into town')
holmes_manager.start_chatbot_mode_console()
ドイツ語:
holmes_manager.register_search_phrase('Ein ENTITYPER geht in die Stadt')
holmes_manager.start_chatbot_mode_console()
あなたは今、町に行く人々にあなたの関心を登録し、コンソールに適切な文章を入力することができます:
英語:
Ready for input
I met Richard Hudson and John Doe last week. They didn't want to go into town.
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
Matched search phrase with text 'An ENTITYPERSON goes into town'; negated; uncertain; involves coreference:
'John Doe'->'ENTITYPERSON' (Has an entity label matching ENTITYPERSON); 'go'->'go' (Matches GO directly); 'into'->'into' (Matches INTO directly); 'town'->'town' (Matches TOWN directly)
ドイツ語:
Ready for input
Letzte Woche sah ich Richard Hudson und Max Mustermann. Sie wollten nicht mehr in die Stadt gehen.
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Richard Hudson'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
Matched search phrase with text 'Ein ENTITYPER geht in die Stadt'; negated; uncertain; involves coreference:
'Max Mustermann'->'ENTITYPER' (Has an entity label matching ENTITYPER); 'gehen'->'gehen' (Matches GEHEN directly); 'in'->'in' (Matches IN directly); 'die Stadt'->'stadt' (Matches STADT directly)
2つの言語のそれぞれで、この最後の例は、ホームズのいくつかのさらなる特徴を示しています。
その他の例については、セクション5を参照してください。
次の戦略は、戦略ごとに1つのPythonモジュールで実装されています。標準的なライブラリは、マネージャークラスを介してオーダーメイドの戦略の追加をサポートしていませんが、Pythonプログラミングスキルを持っている人なら誰でもこれを有効にするためにコードを変更することは比較的簡単です。
word_match.type=='direct' )検索フレーズワードとドキュメントワード間の直接一致は常にアクティブです。この戦略は、主に茎の形の単語を一致させることに依存しています。たとえば、英語の買い物や子供を買った子供と子供、ドイツのシュタイゲンとスティーグとキンダーに一致させることに依存しています。ただし、パーサーが単語に対して間違ったステムフォームを提供する場合、直接一致する動作の可能性を高めるために、直接一致中に検索とドキュメントの両方の単語の生のテキストフォームも考慮されます。
word_match.type=='derivation' )派生ベースのマッチングには、通常、異なる単語クラスに属する明確で関連する単語、例えば英語の評価と評価、ドイツのジャゲンとジャグドが含まれます。デフォルトではアクティブですが、Managerクラスをインスタンス化するときに設定されるanalyze_derivational_morphologyパラメーターを使用してオフにすることができます。
word_match.type=='entity' )名詞のマッチングは、名詞の代わりに検索フレーズの目的のポイントに特別な名前付きエンティティ識別子を挿入することによりアクティブになります。
エンティティパーソンが町に行く(英語)
Die Stadt(ドイツ語)のein entityper geht 。
サポートされている指名されたエンティティ識別子は、各言語のSPACYモデルによって提供される名前付きエンティティ情報に直接依存します(SPACYドキュメントの以前のバージョンからコピーされた説明):
英語:
| 識別子 | 意味 |
|---|---|
| EntityNoun | 任意の名詞句。 |
| エンティティパーソン | 架空の人々を含む人々。 |
| EntityNorp | 国籍または宗教的または政治グループ。 |
| EntityFac | 建物、空港、高速道路、橋など |
| Entityorg | 企業、代理店、機関など |
| entitygpe | 国、都市、州。 |
| entityloc | 非GPEの場所、山脈、水域。 |
| EntityProduct | オブジェクト、車両、食品など(サービスではありません。) |
| EntityEvent | ハリケーン、戦闘、戦争、スポーツイベントなどと名付けられました。 |
| entitywork_of_art | 本、歌などのタイトル |
| エンティリロー | 名前の文書は法律に巻き込まれました。 |
| entityLanguage | 名前付き言語。 |
| EntityDate | 絶対的または相対的な日付または期間。 |
| エンティティタイム | 1日よりも小さくなります。 |
| entitypercent | 「%」を含む割合。 |
| EntityMoney | ユニットを含む金銭的価値。 |
| entityQuantity | 重量または距離の測定。 |
| 存在 | 「最初」、「セカンド」など |
| EntityCardinal | 別のタイプに該当しない数字。 |
ドイツ語:
| 識別子 | 意味 |
|---|---|
| EntityNoun | 任意の名詞句。 |
| EntityPer | 名前が付けられた人または家族。 |
| entityloc | 政治的または地理的に定義された場所(都市、州、国、国際地域、水域、山)の名前。 |
| Entityorg | コーポレート、政府、またはその他の組織エンティティと名付けられました。 |
| EntityMisc | その他のエンティティ、例:イベント、国籍、製品、または芸術作品。 |
本物の名前付きエンティティ識別子にENTITYNOUN追加しました。名詞句と一致するため、一般的な代名詞と同様の方法で動作します。違いは、 ENTITYNOUNドキュメント内の特定の名詞句と一致する必要があり、この特定の名詞句が抽出され、さらに処理できることです。 ENTITYNOUNは、ユースケースを一致するトピック内でサポートされていません。
word_match.type=='ontology' )オントロジーにより、ユーザーは、ドキュメントを一致させてフレーズを検索するときに考慮される単語間の関係を定義できます。 3つの関連する関係タイプは、短命(何かが何かのサブタイプ)、同義語(何かが何かを意味する)、名前の個人(何かは何かの特定の例です)です。 3つの関係タイプは、図1に例示されています。
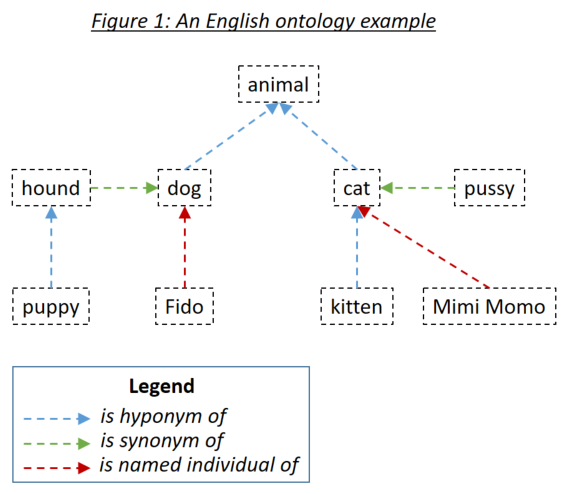
オントロジーは、RDF/XMLを使用してシリアル化されたOwl Ontology Standardを使用してHolmesに定義されます。このようなオントロジーは、さまざまなツールで生成できます。ホームズの例とテストでは、無料のツールプロテッジが使用されました。 Protegeの両方を使用して、独自のオントロジーを定義し、例とテストで出荷するオントロジーを閲覧することをお勧めします。 Protegeでオントロジーを保存する場合は、 RDF/XMLをフォーマットとして選択してください。 Protegeは、ホームズがデフォルトとして理解しているが、オーバーライドする可能性のある仮説、同義語、名前付き個人的な関係に標準ラベルを割り当てます。
オントロジーエントリは、国際化さhttp://www.semanticweb.org/hudsonr/ontologies/2019/0/animals#dogたリソース識別子(IRI)を使用して定義されます。ホームズは、一致するために最終的なフラグメントのみを使用します。これにより、オントロジーツリーの複数のポイントで同音異義語(同じ形式の単語)が定義されます。
オントロジーベースのマッチングは、特定のサブジェクトドメインとユースケース用に構築された小さなオントロジーが使用されている場合、ホームズで最良の結果をもたらします。たとえば、建物の保険の使用ケースのためにチャットボットを実装している場合は、その特定のドメイン内の条件と関係をキャプチャする小さなオントロジーを作成する必要があります。一方、WordNetなどの言語全体のすべてのドメインに構築された大きなオントロジーを使用することはお勧めしません。これは、狭いサブジェクトドメインにのみ適用される多くの同音異義語と関係が、多数の誤った一致につながる傾向があるためです。一般的なユースケースの場合、埋め込みベースのマッチングはより良い結果をもたらす傾向があります。
オントロジーの各単語は、その分野、同義語、名前の個人、それらの単語の低音、同義語、名前の個人などで構成されるサブツリーの見出しと見なすことができます。チャットボットと構造抽出のユースケースに適した標準的な方法でオントロジーが設定されているため、ドキュメントワードが検索フレーズワードのサブツリー内にある場合、ホームズ検索フレーズの単語はドキュメントの単語と一致します。図1のオントロジーは、各単語をそれ自体に一致させる直接的なマッチング戦略に加えて、ホームズに定義されていた場合、次の組み合わせと一致します。
Eat UpやAufessenのようなドイツの分離可能な動詞のような英語の句動詞は、オントロジー内の単一のアイテムとして定義する必要があります。ホームズがテキストを分析し、そのような動詞に出くわすと、主動詞と粒子は、オントロジーを介して一致させることができる単一の論理的単語に混同されます。これは、テキスト内で食べると、オントロジー内の食事のサブツリーと一致するが、オントロジー内の食事のサブツリーとは一致しないことを意味します。
派生ベースのマッチングがアクティブである場合、潜在的なオントロジーベースの一致の両側で考慮されます。たとえば、変更と修正がオントロジーの同義語として定義されている場合、変更と修正も互いに一致します。
関連文を見つけることが、ドキュメントの一致の論理的対応を検索フレーズに保証するよりも重要である状況では、オントロジーを定義するときに対称マッチングを指定することは理にかなっているかもしれません。対称マッチングは、トピックマッチングユースケースに推奨されますが、チャットボットや構造抽出のユースケースに適している可能性は低いです。つまり、一致する際に、ハイパーニーム(逆の仮説)の関係と、仮説と同義語の関係が考慮されることを意味します。したがって、ドキュメントと検索フレーズの間のより対称的な関係につながります。対称オントロジーを介して一致するときに適用される重要なルールは、一致パスにはHyperNymと仮説の関係の両方が含まれていない可能性があるということです。つまり、自分に戻ることはできません。上記のオントロジーは対称として定義されていた場合、次の組み合わせが一致します。
監視されているドキュメント分類ユースケースでは、2つの個別のオントロジーを使用できます。
構造マッチングオントロジーは、トレーニングドキュメントとテスト文書の両方の内容を分析するために使用されます。オントロジーにあるドキュメントからの各単語は、最も一般的なHyperNymの祖先に置き換えられます。オントロジーは、目的のために特別に構築された場合、監視されたドキュメント分類のために構造的マッチングとのみ機能する可能性が高いことを認識することが重要です。このようなオントロジーは、分類されるドキュメント内のオブジェクトの主要なクラスを表す多数の別の木で構成する必要があります。上記のオントロジーの例では、オントロジー内のすべての単語は動物に置き換えられます。 WordNetスタイルのオントロジーの極端なケースでは、すべての名詞が物に置き換えられることになりますが、これは明らかに望ましい結果ではありません。
分類オントロジーは、分類ラベル間の関係をキャプチャするために使用されます。ドキュメントには特定の分類があるということは、分類が属するサブツリーに分類もあることを意味します。分類オントロジーでは、価値を追加せずにニューラルネットワークの複雑さを増すため、同義語は控えめに使用する必要があります。また、対称マッチングを使用するように分類オントロジーを設定することは技術的には可能ですが、そうする賢明な理由はありません。任意のトレーニング文書のラベルとして直接定義されていない分類オントロジー内のラベルは、 SupervisedTopicTrainingBasis.register_additional_classification_label()メソッドを使用して特別に登録する必要があることに注意してください。
word_match.type=='embedding' )Spacyは単語の埋め込みを提供します。各単語が発生する傾向があるコンテキストをキャプチャする単語の機械学習で生成された数値ベクトル表現。同様の意味を持つ2つの単語は、互いに近い単語の埋め込みで現れる傾向があり、スペイシーは、0.0(類似性なし)と1.0(同じ単語)の間で小数点として表される2つの単語の埋め込みの間のコサインの類似性を測定できます。犬と猫は同様の文脈で現れる傾向があるため、0.80の類似性があります。犬と馬の共通点が少なく、0.62の類似性があります。犬と鉄の類似性はわずか0.25です。埋め込みベースのマッチングは、結果が他の単語クラスでは不十分であることがわかっているため、名詞、形容詞、副詞に対してのみアクティブになります。
2つの単語が類似した埋め込みを持っているという事実は、オントロジーベースのマッチングが使用される場合と同じ種類の論理的関係を意味するものではないことを理解することが重要です。たとえば、犬と猫が類似した埋め込みを持っているという事実は、犬が猫の一種でも猫でもないことを意味します。それにもかかわらず、埋め込みベースのマッチングが適切な選択が機能的ユースケースに依存するかどうか。
チャットボット、構造抽出、ドキュメント分類の使用ケースの場合、ホームズは、マネージャークラスでグローバルに定義されたoverall_similarity_thresholdパラメーターを使用して、単語埋め込みベースの類似性を使用します。対応する単語のペア間の類似性の幾何学的平均がこのしきい値よりも大きい場合、検索フレーズとドキュメント内の構造の間で一致が検出されます。この手法の背後にある直感は、例えば6つの語彙的単語を持つ検索フレーズがドキュメント構造と一致する場合、これらの単語の5つが正確に一致し、1つだけが埋め込みを介して対応する場合、この6番目の単語と一致するために必要な類似性は、正確に一致する3つの単語のみが少なく、他の2つの単語も埋め込みで対応する場合よりも少ないことです。
検索フレーズをドキュメントに一致させることは、検索フレーズのルート(構文ヘッド)の単語と一致するドキュメント内の単語を見つけることから始まります。ホームズは次に、これらのそれぞれの一致したドキュメントワードの周囲の構造を調査して、ドキュメント構造が全体の検索フレーズ構造と一致するかどうかを確認します。検索フレーズルートワードに一致するドキュメントワードは、通常、インデックスを使用して見つかります。ただし、検索フレーズルートワードに一致するドキュメントワードを見つけるときに埋め込みを考慮する必要がある場合、有効な単語クラスを使用したすべてのドキュメントのすべての単語を、その検索フレーズルートワードと類似して比較する必要があります。これには、チャットボットのユースケースが本質的に使用不可を除くすべてのユースケースをレンダリングする非常に顕著なパフォーマンスヒットがあります。
検索フレーズのルートワードの埋め込みベースのマッチングに起因する通常の不必要なパフォーマンスヒットを回避するために、埋め込みembedding_based_matching_on_root_wordsパラメーターを使用して、埋め込みベースのマッチングとは別に制御されます。ほとんどのユースケースでは、この設定をオフ(値False )に保つことをお勧めします。
overall_similarity_thresholdもembedding_based_matching_on_root_wordsパラメーターも、トピックに一致するユースケースに影響を与えることはありません。ここで、ワードレベルの埋め込み類似性しきい値topic_match_documents_against word_embedding_match_thresholdおよびinitial_question_word_embedding_match_thresholdパラメータを使用して設定されます。
word_match.type=='entity_embedding' )特定のエンティティラベルを持つ検索ドキュメントワードと、埋め込みがそのエンティティラベルの根本的な意味と埋め込まれている検索フレーズまたはクエリドキュメントワードを持つ検索ドキュメントワードとの間で、例:個人エンティティラベルの根本的な意味と同様の単語の埋め込みがあります。 embedding_based_matching_on_root_words設定に関係なく、指定されたエンティティ巻き取りベースのマッチングはルートワードではアクティブではないことに注意してください。
word_match.type=='question' )初期質問ワードマッチングは、トピックマッチング中にのみアクティブになります。クエリフレーズの最初の質問ワードは、質問に対する潜在的な答えを表す検索されたドキュメントのエンティティを一致させます。
Managerクラスでtopic_match_documents_against関数を呼び出すときに、 initial_question_word_behaviourパラメーターを使用して、initial-question-wordマッチングがオンとオフに切り替えられます。 It is only likely to be useful when topic matching is being performed in an interactive setting where the user enters short query phrases, as opposed to when it is being used to find documents on a similar topic to an pre-existing query document: initial question words are only processed at the beginning of the first sentence of the query phrase or query document.
Linguistically speaking, if a query phrase consists of a complex question with several elements dependent on the main verb, a finding in a searched document is only an 'answer' if contains matches to all these elements. Because recall is typically more important than precision when performing topic matching with interactive query phrases, however, Holmes will match an initial question word to a searched-document phrase wherever they correspond semantically (eg wherever when corresponds to a temporal adverbial phrase) and each depend on verbs that themselves match at the word level. One possible strategy to filter out 'incomplete answers' would be to calculate the maximum possible score for a query phrase and reject topic matches that score below a threshold scaled to this maximum.
Before Holmes analyses a searched document or query document, coreference resolution is performed using the Coreferee library running on top of spaCy. This means that situations are recognised where pronouns and nouns that are located near one another within a text refer to the same entities. The information from one mention can then be applied to the analysis of further mentions:
I saw a big dog . It was chasing a cat.
I saw a big dog . The dog was chasing a cat.
Coreferee also detects situations where a noun refers back to a named entity:
We discussed AstraZeneca . The company had given us permission to publish this library under the MIT license.
If this example were to match the search phrase A company gives permission to publish something , the coreference information that the company under discussion is AstraZeneca is clearly relevant and worth extracting in addition to the word(s) directly matched to the search phrase. Such information is captured in the word_match.extracted_word field.
The concept of search phrases has already been introduced and is relevant to the chatbot use case, the structural extraction use case and to preselection within the supervised document classification use case.
It is crucial to understand that the tips and limitations set out in Section 4 do not apply in any way to query phrases in topic matching. If you are using Holmes for topic matching only, you can completely ignore this section!
Structural matching between search phrases and documents is not symmetric: there are many situations in which sentence X as a search phrase would match sentence Y within a document but where the converse would not be true. Although Holmes does its best to understand any search phrases, the results are better when the user writing them follows certain patterns and tendencies, and getting to grips with these patterns and tendencies is the key to using the relevant features of Holmes successfully.
Holmes distinguishes between: lexical words like dog , chase and cat (English) or Hund , jagen and Katze (German) in the initial example above; and grammatical words like a (English) or ein and eine (German) in the initial example above. Only lexical words match words in documents, but grammatical words still play a crucial role within a search phrase: they enable Holmes to understand it.
Dog chase cat (English)
Hund jagen Katze (German)
contain the same lexical words as the search phrases in the initial example above, but as they are not grammatical sentences Holmes is liable to misunderstand them if they are used as search phrases. This is a major difference between Holmes search phrases and the search phrases you use instinctively with standard search engines like Google, and it can take some getting used to.
A search phrase need not contain a verb:
ENTITYPERSON (English)
A big dog (English)
Interest in fishing (English)
ENTITYPER (German)
Ein großer Hund (German)
Interesse am Angeln (German)
are all perfectly valid and potentially useful search phrases.
Where a verb is present, however, Holmes delivers the best results when the verb is in the present active , as chases and jagt are in the initial example above. This gives Holmes the best chance of understanding the relationship correctly and of matching the widest range of document structures that share the target meaning.
Sometimes you may only wish to extract the object of a verb. For example, you might want to find sentences that are discussing a cat being chased regardless of who is doing the chasing. In order to avoid a search phrase containing a passive expression like
A cat is chased (English)
Eine Katze wird gejagt (German)
you can use a generic pronoun . This is a word that Holmes treats like a grammatical word in that it is not matched to documents; its sole purpose is to help the user form a grammatically optimal search phrase in the present active. Recognised generic pronouns are English something , somebody and someone and German jemand (and inflected forms of jemand ) and etwas : Holmes treats them all as equivalent. Using generic pronouns, the passive search phrases above could be re-expressed as
Somebody chases a cat (English)
Jemand jagt eine Katze (German).
Experience shows that different prepositions are often used with the same meaning in equivalent phrases and that this can prevent search phrases from matching where one would intuitively expect it. For example, the search phrases
Somebody is at the market (English)
Jemand ist auf dem Marktplatz (German)
would fail to match the document phrases
Richard was in the market (English)
Richard war am Marktplatz (German)
The best way of solving this problem is to define the prepositions in question as synonyms in an ontology.
The following types of structures are prohibited in search phrases and result in Python user-defined errors:
A dog chases a cat. A cat chases a dog (English)
Ein Hund jagt eine Katze. Eine Katze jagt einen Hund (German)
Each clause must be separated out into its own search phrase and registered individually.
A dog does not chase a cat. (英語)
Ein Hund jagt keine Katze. (German)
Negative expressions are recognised as such in documents and the generated matches marked as negative; allowing search phrases themselves to be negative would overcomplicate the library without offering any benefits.
A dog and a lion chase a cat. (英語)
Ein Hund und ein Löwe jagen eine Katze. (German)
Wherever conjunction occurs in documents, Holmes distributes the information among multiple matches as explained above. In the unlikely event that there should be a requirement to capture conjunction explicitly when matching, this could be achieved by using the Manager.match() function and looking for situations where the document token objects are shared by multiple match objects.
The (English)
Der (German)
A search phrase cannot be processed if it does not contain any words that can be matched to documents.
A dog chases a cat and he chases a mouse (English)
Ein Hund jagt eine Katze und er jagt eine Maus (German)
Pronouns that corefer with nouns elsewhere in the search phrase are not permitted as this would overcomplicate the library without offering any benefits.
The following types of structures are strongly discouraged in search phrases:
Dog chase cat (English)
Hund jagen Katze (German)
Although these will sometimes work, the results will be better if search phrases are expressed grammatically.
A cat is chased by a dog (English)
A dog will have chased a cat (English)
Eine Katze wird durch einen Hund gejagt (German)
Ein Hund wird eine Katze gejagt haben (German)
Although these will sometimes work, the results will be better if verbs in search phrases are expressed in the present active.
Who chases the cat? (英語)
Wer jagt die Katze? (German)
Although questions are supported as query phrases in the topic matching use case, they are not appropriate as search phrases. Questions should be re-phrased as statements, in this case
Something chases the cat (English)
Etwas jagt die Katze (German).
Informationsextraktion (German)
Ein Stadtmittetreffen (German)
The internal structure of German compound words is analysed within searched documents as well as within query phrases in the topic matching use case, but not within search phrases. In search phrases, compound words should be reexpressed as genitive constructions even in cases where this does not strictly capture their meaning:
Extraktion der Information (German)
Ein Treffen der Stadtmitte (German)
The following types of structures should be used with caution in search phrases:
A fierce dog chases a scared cat on the way to the theatre (English)
Ein kämpferischer Hund jagt eine verängstigte Katze auf dem Weg ins Theater (German)
Holmes can handle any level of complexity within search phrases, but the more complex a structure, the less likely it becomes that a document sentence will match it. If it is really necessary to match such complex relationships with search phrases rather than with topic matching, they are typically better extracted by splitting the search phrase up, eg
A fierce dog (English)
A scared cat (English)
A dog chases a cat (English)
Something chases something on the way to the theatre (English)
Ein kämpferischer Hund (German)
Eine verängstigte Katze (German)
Ein Hund jagt eine Katze (German)
Etwas jagt etwas auf dem Weg ins Theater (German)
Correlations between the resulting matches can then be established by matching via the Manager.match() function and looking for situations where the document token objects are shared across multiple match objects.
One possible exception to this piece of advice is when embedding-based matching is active. Because whether or not each word in a search phrase matches then depends on whether or not other words in the same search phrase have been matched, large, complex search phrases can sometimes yield results that a combination of smaller, simpler search phrases would not.
The chasing of a cat (English)
Die Jagd einer Katze (German)
These will often work, but it is generally better practice to use verbal search phrases like
Something chases a cat (English)
Etwas jagt eine Katze (German)
and to allow the corresponding nominal phrases to be matched via derivation-based matching.
The chatbot use case has already been introduced: a predefined set of search phrases is used to extract information from phrases entered interactively by an end user, which in this use case act as the documents.
The Holmes source code ships with two examples demonstrating the chatbot use case, one for each language, with predefined ontologies. Having cloned the source code and installed the Holmes library, navigate to the /examples directory and type the following (Linux):
英語:
python3 example_chatbot_EN_insurance.py
ドイツ語:
python3 example_chatbot_DE_insurance.py
or click on the files in Windows Explorer (Windows).
Holmes matches syntactically distinct structures that are semantically equivalent, ie that share the same meaning. In a real chatbot use case, users will typically enter equivalent information with phrases that are semantically distinct as well, ie that have different meanings. Because the effort involved in registering a search phrase is barely greater than the time it takes to type it in, it makes sense to register a large number of search phrases for each relationship you are trying to extract: essentially all ways people have been observed to express the information you are interested in or all ways you can imagine somebody might express the information you are interested in . To assist this, search phrases can be registered with labels that do not need to be unique: a label can then be used to express the relationship an entire group of search phrases is designed to extract. Note that when many search phrases have been defined to extract the same relationship, a single user entry is likely to be sometimes matched by multiple search phrases. This must be handled appropriately by the calling application.
One obvious weakness of Holmes in the chatbot setting is its sensitivity to correct spelling and, to a lesser extent, to correct grammar. Strategies for mitigating this weakness include:
The structural extraction use case uses structural matching in the same way as the chatbot use case, and many of the same comments and tips apply to it. The principal differences are that pre-existing and often lengthy documents are scanned rather than text snippets entered ad-hoc by the user, and that the returned match objects are not used to drive a dialog flow; they are examined solely to extract and store structured information.
Code for performing structural extraction would typically perform the following tasks:
Manager.register_search_phrase() several times to define a number of search phrases specifying the information to be extracted.Manager.parse_and_register_document() several times to load a number of documents within which to search.Manager.match() to perform the matching.The topic matching use case matches a query document , or alternatively a query phrase entered ad-hoc by the user, against a set of documents pre-loaded into memory. The aim is to find the passages in the documents whose topic most closely corresponds to the topic of the query document; the output is a ordered list of passages scored according to topic similarity. Additionally, if a query phrase contains an initial question word, the output will contain potential answers to the question.
Topic matching queries may contain generic pronouns and named-entity identifiers just like search phrases, although the ENTITYNOUN token is not supported. However, an important difference from search phrases is that the topic matching use case places no restrictions on the grammatical structures permissible within the query document.
In addition to the Holmes demonstration website, the Holmes source code ships with three examples demonstrating the topic matching use case with an English literature corpus, a German literature corpus and a German legal corpus respectively. Users are encouraged to run these to get a feel for how they work.
Topic matching uses a variety of strategies to find text passages that are relevant to the query. These include resource-hungry procedures like investigating semantic relationships and comparing embeddings. Because applying these across the board would prevent topic matching from scaling, Holmes only attempts them for specific areas of the text that less resource-intensive strategies have already marked as looking promising. This and the other interior workings of topic matching are explained here.
In the supervised document classification use case, a classifier is trained with a number of documents that are each pre-labelled with a classification. The trained classifier then assigns one or more labels to new documents according to what each new document is about. As explained here, ontologies can be used both to enrichen the comparison of the content of the various documents and to capture implication relationships between classification labels.
A classifier makes use of a neural network (a multilayer perceptron) whose topology can either be determined automatically by Holmes or specified explicitly by the user. With a large number of training documents, the automatically determined topology can easily exhaust the memory available on a typical machine; if there is no opportunity to scale up the memory, this problem can be remedied by specifying a smaller number of hidden layers or a smaller number of nodes in one or more of the layers.
A trained document classification model retains no references to its training data. This is an advantage from a data protection viewpoint, although it cannot presently be guaranteed that models will not contain individual personal or company names.
A typical problem with the execution of many document classification use cases is that a new classification label is added when the system is already live but that there are initially no examples of this new classification with which to train a new model. The best course of action in such a situation is to define search phrases which preselect the more obvious documents with the new classification using structural matching. Those documents that are not preselected as having the new classification label are then passed to the existing, previously trained classifier in the normal way. When enough documents exemplifying the new classification have accumulated in the system, the model can be retrained and the preselection search phrases removed.
Holmes ships with an example script demonstrating supervised document classification for English with the BBC Documents dataset. The script downloads the documents (for this operation and for this operation alone, you will need to be online) and places them in a working directory. When training is complete, the script saves the model to the working directory. If the model file is found in the working directory on subsequent invocations of the script, the training phase is skipped and the script goes straight to the testing phase. This means that if it is wished to repeat the training phase, either the model has to be deleted from the working directory or a new working directory has to be specified to the script.
Having cloned the source code and installed the Holmes library, navigate to the /examples directory. Specify a working directory at the top of the example_supervised_topic_model_EN.py file, then type python3 example_supervised_topic_model_EN (Linux) or click on the script in Windows Explorer (Windows).
It is important to realise that Holmes learns to classify documents according to the words or semantic relationships they contain, taking any structural matching ontology into account in the process. For many classification tasks, this is exactly what is required; but there are tasks (eg author attribution according to the frequency of grammatical constructions typical for each author) where it is not. For the right task, Holmes achieves impressive results. For the BBC Documents benchmark processed by the example script, Holmes performs slightly better than benchmarks available online (see eg here) although the difference is probably too slight to be significant, especially given that the different training/test splits were used in each case: Holmes has been observed to learn models that predict the correct result between 96.9% and 98.7% of the time. The range is explained by the fact that the behaviour of the neural network is not fully deterministic.
The interior workings of supervised document classification are explained here.
Manager holmes_extractor.Manager(self, model, *, overall_similarity_threshold=1.0,
embedding_based_matching_on_root_words=False, ontology=None,
analyze_derivational_morphology=True, perform_coreference_resolution=None,
number_of_workers=None, verbose=False)
The facade class for the Holmes library.
Parameters:
model -- the name of the spaCy model, e.g. *en_core_web_trf*
overall_similarity_threshold -- the overall similarity threshold for embedding-based
matching. Defaults to *1.0*, which deactivates embedding-based matching. Note that this
parameter is not relevant for topic matching, where the thresholds for embedding-based
matching are set on the call to *topic_match_documents_against*.
embedding_based_matching_on_root_words -- determines whether or not embedding-based
matching should be attempted on search-phrase root tokens, which has a considerable
performance hit. Defaults to *False*. Note that this parameter is not relevant for topic
matching.
ontology -- an *Ontology* object. Defaults to *None* (no ontology).
analyze_derivational_morphology -- *True* if matching should be attempted between different
words from the same word family. Defaults to *True*.
perform_coreference_resolution -- *True* if coreference resolution should be taken into account
when matching. Defaults to *True*.
use_reverse_dependency_matching -- *True* if appropriate dependencies in documents can be
matched to dependencies in search phrases where the two dependencies point in opposite
directions. Defaults to *True*.
number_of_workers -- the number of worker processes to use, or *None* if the number of worker
processes should depend on the number of available cores. Defaults to *None*
verbose -- a boolean value specifying whether multiprocessing messages should be outputted to
the console. Defaults to *False*
Manager.register_serialized_document(self, serialized_document:bytes, label:str="") -> None
Parameters:
document -- a preparsed Holmes document.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.register_serialized_documents(self, document_dictionary:dict[str, bytes]) -> None
Note that this function is the most efficient way of loading documents.
Parameters:
document_dictionary -- a dictionary from labels to serialized documents.
Manager.parse_and_register_document(self, document_text:str, label:str='') -> None
Parameters:
document_text -- the raw document text.
label -- a label for the document which must be unique. Defaults to the empty string,
which is intended for use cases involving single documents (typically user entries).
Manager.remove_document(self, label:str) -> None
Manager.remove_all_documents(self, labels_starting:str=None) -> None
Parameters:
labels_starting -- a string starting the labels of documents to be removed,
or 'None' if all documents are to be removed.
Manager.list_document_labels(self) -> List[str]
Returns a list of the labels of the currently registered documents.
Manager.serialize_document(self, label:str) -> Optional[bytes]
Returns a serialized representation of a Holmes document that can be
persisted to a file. If 'label' is not the label of a registered document,
'None' is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.get_document(self, label:str='') -> Optional[Doc]
Returns a Holmes document. If *label* is not the label of a registered document, *None*
is returned instead.
Parameters:
label -- the label of the document to be serialized.
Manager.debug_document(self, label:str='') -> None
Outputs a debug representation for a loaded document.
Parameters:
label -- the label of the document to be serialized.
Manager.register_search_phrase(self, search_phrase_text:str, label:str=None) -> SearchPhrase
Registers and returns a new search phrase.
Parameters:
search_phrase_text -- the raw search phrase text.
label -- a label for the search phrase, which need not be unique.
If label==None, the assigned label defaults to the raw search phrase text.
Manager.remove_all_search_phrases_with_label(self, label:str) -> None
Manager.remove_all_search_phrases(self) -> None
Manager.list_search_phrase_labels(self) -> List[str]
Manager.match(self, search_phrase_text:str=None, document_text:str=None) -> List[Dict]
Matches search phrases to documents and returns the result as match dictionaries.
Parameters:
search_phrase_text -- a text from which to generate a search phrase, or 'None' if the
preloaded search phrases should be used for matching.
document_text -- a text from which to generate a document, or 'None' if the preloaded
documents should be used for matching.
topic_match_documents_against(self, text_to_match:str, *,
use_frequency_factor:bool=True,
maximum_activation_distance:int=75,
word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7,
relation_score:int=300,
reverse_only_relation_score:int=200,
single_word_score:int=50,
single_word_any_tag_score:int=20,
initial_question_word_answer_score:int=600,
initial_question_word_behaviour:str='process',
different_match_cutoff_score:int=15,
overlapping_relation_multiplier:float=1.5,
embedding_penalty:float=0.6,
ontology_penalty:float=0.9,
relation_matching_frequency_threshold:float=0.25,
embedding_matching_frequency_threshold:float=0.5,
sideways_match_extent:int=100,
only_one_result_per_document:bool=False,
number_of_results:int=10,
document_label_filter:str=None,
tied_result_quotient:float=0.9) -> List[Dict]:
Returns a list of dictionaries representing the results of a topic match between an entered text
and the loaded documents.
Properties:
text_to_match -- the text to match against the loaded documents.
use_frequency_factor -- *True* if scores should be multiplied by a factor between 0 and 1
expressing how rare the words matching each phraselet are in the corpus. Note that,
even if this parameter is set to *False*, the factors are still calculated as they are
required for determining which relation and embedding matches should be attempted.
maximum_activation_distance -- the number of words it takes for a previous phraselet
activation to reduce to zero when the library is reading through a document.
word_embedding_match_threshold -- the cosine similarity above which two words match where
the search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
relation_score -- the activation score added when a normal two-word relation is matched.
reverse_only_relation_score -- the activation score added when a two-word relation
is matched using a search phrase that can only be reverse-matched.
single_word_score -- the activation score added when a single noun is matched.
single_word_any_tag_score -- the activation score added when a single word is matched
that is not a noun.
initial_question_word_answer_score -- the activation score added when a question word is
matched to an potential answer phrase.
initial_question_word_behaviour -- 'process' if a question word in the sentence
constituent at the beginning of *text_to_match* is to be matched to document phrases
that answer it and to matching question words; 'exclusive' if only topic matches that
answer questions are to be permitted; 'ignore' if question words are to be ignored.
different_match_cutoff_score -- the activation threshold under which topic matches are
separated from one another. Note that the default value will probably be too low if
*use_frequency_factor* is set to *False*.
overlapping_relation_multiplier -- the value by which the activation score is multiplied
when two relations were matched and the matches involved a common document word.
embedding_penalty -- a value between 0 and 1 with which scores are multiplied when the
match involved an embedding. The result is additionally multiplied by the overall
similarity measure of the match.
ontology_penalty -- a value between 0 and 1 with which scores are multiplied for each
word match within a match that involved the ontology. For each such word match,
the score is multiplied by the value (abs(depth) + 1) times, so that the penalty is
higher for hyponyms and hypernyms than for synonyms and increases with the
depth distance.
relation_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches.
embedding_matching_frequency_threshold -- the frequency threshold above which single
word matches are used as the basis for attempting relation matches with
embedding-based matching on the second word.
sideways_match_extent -- the maximum number of words that may be incorporated into a
topic match either side of the word where the activation peaked.
only_one_result_per_document -- if 'True', prevents multiple results from being returned
for the same document.
number_of_results -- the number of topic match objects to return.
document_label_filter -- optionally, a string with which document labels must start to
be considered for inclusion in the results.
tied_result_quotient -- the quotient between a result and following results above which
the results are interpreted as tied.
Manager.get_supervised_topic_training_basis(self, *, classification_ontology:Ontology=None,
overlap_memory_size:int=10, oneshot:bool=True, match_all_words:bool=False,
verbose:bool=True) -> SupervisedTopicTrainingBasis:
Returns an object that is used to train and generate a model for the
supervised document classification use case.
Parameters:
classification_ontology -- an Ontology object incorporating relationships between
classification labels, or 'None' if no such ontology is to be used.
overlap_memory_size -- how many non-word phraselet matches to the left should be
checked for words in common with a current match.
oneshot -- whether the same word or relationship matched multiple times within a
single document should be counted once only (value 'True') or multiple times
(value 'False')
match_all_words -- whether all single words should be taken into account
(value 'True') or only single words with noun tags (value 'False')
verbose -- if 'True', information about training progress is outputted to the console.
Manager.deserialize_supervised_topic_classifier(self,
serialized_model:bytes, verbose:bool=False) -> SupervisedTopicClassifier:
Returns a classifier for the supervised document classification use case
that will use a supplied pre-trained model.
Parameters:
serialized_model -- the pre-trained model as returned from `SupervisedTopicClassifier.serialize_model()`.
verbose -- if 'True', information about matching is outputted to the console.
Manager.start_chatbot_mode_console(self)
Starts a chatbot mode console enabling the matching of pre-registered
search phrases to documents (chatbot entries) entered ad-hoc by the
user.
Manager.start_structural_search_mode_console(self)
Starts a structural extraction mode console enabling the matching of pre-registered
documents to search phrases entered ad-hoc by the user.
Manager.start_topic_matching_search_mode_console(self,
only_one_result_per_document:bool=False, word_embedding_match_threshold:float=0.8,
initial_question_word_embedding_match_threshold:float=0.7):
Starts a topic matching search mode console enabling the matching of pre-registered
documents to query phrases entered ad-hoc by the user.
Parameters:
only_one_result_per_document -- if 'True', prevents multiple topic match
results from being returned for the same document.
word_embedding_match_threshold -- the cosine similarity above which two words match where the
search phrase word does not govern an interrogative pronoun.
initial_question_word_embedding_match_threshold -- the cosine similarity above which two
words match where the search phrase word governs an interrogative pronoun.
Manager.close(self) -> None
Terminates the worker processes.
manager.nlp manager.nlp is the underlying spaCy Language object on which both Coreferee and Holmes have been registered as custom pipeline components. The most efficient way of parsing documents for use with Holmes is to call manager.nlp.pipe() . This yields an iterable of documents that can then be loaded into Holmes via manager.register_serialized_documents() .
The pipe() method has an argument n_process that specifies the number of processors to use. With _lg , _md and _sm spaCy models, there are some situations where it can make sense to specify a value other than 1 (the default). Note however that with transformer spaCy models ( _trf ) values other than 1 are not supported.
Ontology holmes_extractor.Ontology(self, ontology_path,
owl_class_type='http://www.w3.org/2002/07/owl#Class',
owl_individual_type='http://www.w3.org/2002/07/owl#NamedIndividual',
owl_type_link='http://www.w3.org/1999/02/22-rdf-syntax-ns#type',
owl_synonym_type='http://www.w3.org/2002/07/owl#equivalentClass',
owl_hyponym_type='http://www.w3.org/2000/01/rdf-schema#subClassOf',
symmetric_matching=False)
Loads information from an existing ontology and manages ontology
matching.
The ontology must follow the W3C OWL 2 standard. Search phrase words are
matched to hyponyms, synonyms and instances from within documents being
searched.
This class is designed for small ontologies that have been constructed
by hand for specific use cases. Where the aim is to model a large number
of semantic relationships, word embeddings are likely to offer
better results.
Holmes is not designed to support changes to a loaded ontology via direct
calls to the methods of this class. It is also not permitted to share a single instance
of this class between multiple Manager instances: instead, a separate Ontology instance
pointing to the same path should be created for each Manager.
Matching is case-insensitive.
Parameters:
ontology_path -- the path from where the ontology is to be loaded,
or a list of several such paths. See https://github.com/RDFLib/rdflib/.
owl_class_type -- optionally overrides the OWL 2 URL for types.
owl_individual_type -- optionally overrides the OWL 2 URL for individuals.
owl_type_link -- optionally overrides the RDF URL for types.
owl_synonym_type -- optionally overrides the OWL 2 URL for synonyms.
owl_hyponym_type -- optionally overrides the RDF URL for hyponyms.
symmetric_matching -- if 'True', means hypernym relationships are also taken into account.
SupervisedTopicTrainingBasis (returned from Manager.get_supervised_topic_training_basis() )Holder object for training documents and their classifications from which one or more SupervisedTopicModelTrainer objects can be derived. This class is NOT threadsafe.
SupervisedTopicTrainingBasis.parse_and_register_training_document(self, text:str, classification:str,
label:Optional[str]=None) -> None
Parses and registers a document to use for training.
Parameters:
text -- the document text
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_training_document(self, doc:Doc, classification:str,
label:Optional[str]=None) -> None
Registers a pre-parsed document to use for training.
Parameters:
doc -- the document
classification -- the classification label
label -- a label with which to identify the document in verbose training output,
or 'None' if a random label should be assigned.
SupervisedTopicTrainingBasis.register_additional_classification_label(self, label:str) -> None
Register an additional classification label which no training document possesses explicitly
but that should be assigned to documents whose explicit labels are related to the
additional classification label via the classification ontology.
SupervisedTopicTrainingBasis.prepare(self) -> None
Matches the phraselets derived from the training documents against the training
documents to generate frequencies that also include combined labels, and examines the
explicit classification labels, the additional classification labels and the
classification ontology to derive classification implications.
Once this method has been called, the instance no longer accepts new training documents
or additional classification labels.
SupervisedTopicTrainingBasis.train(
self,
*,
minimum_occurrences: int = 4,
cv_threshold: float = 1.0,
learning_rate: float = 0.001,
batch_size: int = 5,
max_epochs: int = 200,
convergence_threshold: float = 0.0001,
hidden_layer_sizes: Optional[List[int]] = None,
shuffle: bool = True,
normalize: bool = True
) -> SupervisedTopicModelTrainer:
Trains a model based on the prepared state.
Parameters:
minimum_occurrences -- the minimum number of times a word or relationship has to
occur in the context of the same classification for the phraselet
to be accepted into the final model.
cv_threshold -- the minimum coefficient of variation with which a word or relationship has
to occur across the explicit classification labels for the phraselet to be
accepted into the final model.
learning_rate -- the learning rate for the Adam optimizer.
batch_size -- the number of documents in each training batch.
max_epochs -- the maximum number of training epochs.
convergence_threshold -- the threshold below which loss measurements after consecutive
epochs are regarded as equivalent. Training stops before 'max_epochs' is reached
if equivalent results are achieved after four consecutive epochs.
hidden_layer_sizes -- a list containing the number of neurons in each hidden layer, or
'None' if the topology should be determined automatically.
shuffle -- 'True' if documents should be shuffled during batching.
normalize -- 'True' if normalization should be applied to the loss function.
SupervisedTopicModelTrainer (returned from SupervisedTopicTrainingBasis.train() ) Worker object used to train and generate models. This object could be removed from the public interface ( SupervisedTopicTrainingBasis.train() could return a SupervisedTopicClassifier directly) but has been retained to facilitate testability.
This class is NOT threadsafe.
SupervisedTopicModelTrainer.classifier(self)
Returns a supervised topic classifier which contains no explicit references to the training data and that
can be serialized.
SupervisedTopicClassifier (returned from SupervisedTopicModelTrainer.classifier() and Manager.deserialize_supervised_topic_classifier() ))
SupervisedTopicClassifier.def parse_and_classify(self, text: str) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
text -- the text to parse and classify.
SupervisedTopicClassifier.classify(self, doc: Doc) -> Optional[OrderedDict]:
Returns a dictionary from classification labels to probabilities
ordered starting with the most probable, or *None* if the text did
not contain any words recognised by the model.
Parameters:
doc -- the pre-parsed document to classify.
SupervisedTopicClassifier.serialize_model(self) -> str
Returns a serialized model that can be reloaded using
*Manager.deserialize_supervised_topic_classifier()*
Manager.match() A text-only representation of a match between a search phrase and a
document. The indexes refer to tokens.
Properties:
search_phrase_label -- the label of the search phrase.
search_phrase_text -- the text of the search phrase.
document -- the label of the document.
index_within_document -- the index of the match within the document.
sentences_within_document -- the raw text of the sentences within the document that matched.
negated -- 'True' if this match is negated.
uncertain -- 'True' if this match is uncertain.
involves_coreference -- 'True' if this match was found using coreference resolution.
overall_similarity_measure -- the overall similarity of the match, or
'1.0' if embedding-based matching was not involved in the match.
word_matches -- an array of dictionaries with the properties:
search_phrase_token_index -- the index of the token that matched from the search phrase.
search_phrase_word -- the string that matched from the search phrase.
document_token_index -- the index of the token that matched within the document.
first_document_token_index -- the index of the first token that matched within the document.
Identical to 'document_token_index' except where the match involves a multiword phrase.
last_document_token_index -- the index of the last token that matched within the document
(NOT one more than that index). Identical to 'document_token_index' except where the match
involves a multiword phrase.
structurally_matched_document_token_index -- the index of the token within the document that
structurally matched the search phrase token. Is either the same as 'document_token_index' or
is linked to 'document_token_index' within a coreference chain.
document_subword_index -- the index of the token subword that matched within the document, or
'None' if matching was not with a subword but with an entire token.
document_subword_containing_token_index -- the index of the document token that contained the
subword that matched, which may be different from 'document_token_index' in situations where a
word containing multiple subwords is split by hyphenation and a subword whose sense
contributes to a word is not overtly realised within that word.
document_word -- the string that matched from the document.
document_phrase -- the phrase headed by the word that matched from the document.
match_type -- 'direct', 'derivation', 'entity', 'embedding', 'ontology', 'entity_embedding'
or 'question'.
negated -- 'True' if this word match is negated.
uncertain -- 'True' if this word match is uncertain.
similarity_measure -- for types 'embedding' and 'entity_embedding', the similarity between the
two tokens, otherwise '1.0'.
involves_coreference -- 'True' if the word was matched using coreference resolution.
extracted_word -- within the coreference chain, the most specific term that corresponded to
the document_word.
depth -- the number of hyponym relationships linking 'search_phrase_word' and
'extracted_word', or '0' if ontology-based matching is not active. Can be negative
if symmetric matching is active.
explanation -- creates a human-readable explanation of the word match from the perspective of the
document word (e.g. to be used as a tooltip over it).
Manager.topic_match_documents_against() A text-only representation of a topic match between a search text and a document.
Properties:
document_label -- the label of the document.
text -- the document text that was matched.
text_to_match -- the search text.
rank -- a string representation of the scoring rank which can have the form e.g. '2=' in case of a tie.
index_within_document -- the index of the document token where the activation peaked.
subword_index -- the index of the subword within the document token where the activation peaked, or
'None' if the activation did not peak at a specific subword.
start_index -- the index of the first document token in the topic match.
end_index -- the index of the last document token in the topic match (NOT one more than that index).
sentences_start_index -- the token start index within the document of the sentence that contains
'start_index'
sentences_end_index -- the token end index within the document of the sentence that contains
'end_index' (NOT one more than that index).
sentences_character_start_index_in_document -- the character index of the first character of 'text'
within the document.
sentences_character_end_index_in_document -- one more than the character index of the last
character of 'text' within the document.
score -- the score
word_infos -- an array of arrays with the semantics:
[0] -- 'relative_start_index' -- the index of the first character in the word relative to
'sentences_character_start_index_in_document'.
[1] -- 'relative_end_index' -- one more than the index of the last character in the word
relative to 'sentences_character_start_index_in_document'.
[2] -- 'type' -- 'single' for a single-word match, 'relation' if within a relation match
involving two words, 'overlapping_relation' if within a relation match involving three
or more words.
[3] -- 'is_highest_activation' -- 'True' if this was the word at which the highest activation
score reported in 'score' was achieved, otherwise 'False'.
[4] -- 'explanation' -- a human-readable explanation of the word match from the perspective of
the document word (e.g. to be used as a tooltip over it).
answers -- an array of arrays with the semantics:
[0] -- the index of the first character of a potential answer to an initial question word.
[1] -- one more than the index of the last character of a potential answer to an initial question
word.
Earlier versions of Holmes could only be published under a restrictive license because of patent issues. As explained in the introduction, this is no longer the case thanks to the generosity of AstraZeneca: versions from 4.0.0 onwards are licensed under the MIT license.
The word-level matching and the high-level operation of structural matching between search-phrase and document subgraphs both work more or less as one would expect. What is perhaps more in need of further comment is the semantic analysis code subsumed in the parsing.py script as well as in the language_specific_rules.py script for each language.
SemanticAnalyzer is an abstract class that is subclassed for each language: at present by EnglishSemanticAnalyzer and GermanSemanticAnalyzer . These classes contain most of the semantic analysis code. SemanticMatchingHelper is a second abstract class, again with an concrete implementation for each language, that contains semantic analysis code that is required at matching time. Moving this out to a separate class family was necessary because, on operating systems that spawn processes rather than forking processes (eg Windows), SemanticMatchingHelper instances have to be serialized when the worker processes are created: this would not be possible for SemanticAnalyzer instances because not all spaCy models are serializable, and would also unnecessarily consume large amounts of memory.
At present, all functionality that is common to the two languages is realised in the two abstract parent classes. Especially because English and German are closely related languages, it is probable that functionality will need to be moved from the abstract parent classes to specific implementing children classes if and when new semantic analyzers are added for new languages.
The HolmesDictionary class is defined as a spaCy extension attribute that is accessed using the syntax token._.holmes . The most important information in the dictionary is a list of SemanticDependency objects. These are derived from the dependency relationships in the spaCy output ( token.dep_ ) but go through a considerable amount of processing to make them 'less syntactic' and 'more semantic'. To give but a few examples:
Some new semantic dependency labels that do not occur in spaCy outputs as values of token.dep_ are added for Holmes semantic dependencies. It is important to understand that Holmes semantic dependencies are used exclusively for matching and are therefore neither intended nor required to form a coherent set of linguistic theoretical entities or relationships; whatever works best for matching is assigned on an ad-hoc basis.
For each language, the match_implication_dict dictionary maps search-phrase semantic dependencies to matching document semantic dependencies and is responsible for the asymmetry of matching between search phrases and documents.
Topic matching involves the following steps:
SemanticMatchingHelper.topic_matching_phraselet_stop_lemmas ), which are consistently ignored throughout the whole process.SemanticMatchingHelper.phraselet_templates .SemanticMatchingHelper.topic_matching_reverse_only_parent_lemmas ) or when the frequency factor for the parent word is below the threshold for relation matching ( relation_matching_frequency_threshold , default: 0.25). These measures are necessary because matching on eg a parent preposition would lead to a large number of potential matches that would take a lot of resources to investigate: it is better to start investigation from the less frequent word within a given relation.relation_matching_frequency_threshold , default: 0.25).embedding_matching_frequency_threshold , default: 0.5), matching at all of those words where the relation template has not already been matched is retried using embeddings at the other word within the relation. A pair of words is then regarded as matching when their mutual cosine similarity is above initial_question_word_embedding_match_threshold (default: 0.7) in situations where the document word has an initial question word in its phrase or word_embedding_match_threshold (default: 0.8) in all other situations.use_frequency_factor is set to True (the default), each score is scaled by the frequency factor of its phraselet, meaning that words that occur less frequently in the corpus give rise to higher scores.maximum_activation_distance ; default: 75) of its value is subtracted from it as each new word is read.single_word_score ; default: 50), a non-noun single-word phraselet or a noun phraselet that matched a subword ( single_word_any_tag_score ; default: 20), a relation phraselet produced by a reverse-only template ( reverse_only_relation_score ; default: 200), any other (normally matched) relation phraselet ( relation_score ; default: 300), or a relation phraselet involving an initial question word ( initial_question_word_answer_score ; default: 600).embedding_penalty ; default: 0.6).ontology_penalty ; default: 0.9) once more often than the difference in depth between the two ontology entries, ie once for a synonym, twice for a child, three times for a grandchild and so on.overlapping_relation_multiplier ; default: 1.5).sideways_match_extent ; default: 100 words) within which the activation score is higher than the different_match_cutoff_score (default: 15) are regarded as belonging to a contiguous passage around the peak that is then returned as a TopicMatch object. (Note that this default will almost certainly turn out to be too low if use_frequency_factor is set to False .) A word whose activation equals the threshold exactly is included at the beginning of the area as long as the next word where activation increases has a score above the threshold. If the topic match peak is below the threshold, the topic match will only consist of the peak word.initial_question_word_behaviour is set to process (the default) or to exclusive , where a document word has matched an initial question word from the query phrase, the subtree of the matched document word is identified as a potential answer to the question and added to the dictionary to be returned. If initial_question_word_behaviour is set to exclusive , any topic matches that do not contain answers to initial question words are discarded.only_one_result_per_document = True prevents more than one result from being returned from the same document; only the result from each document with the highest score will then be returned.tied_result_quotient (default: 0.9) are labelled as tied. The supervised document classification use case relies on the same phraselets as the topic matching use case, although reverse-only templates are ignored and a different set of stop words is used ( SemanticMatchingHelper.supervised_document_classification_phraselet_stop_lemmas ). Classifiers are built and trained as follows:
oneshot ; whether single-word phraselets are generated for all words with their own meaning or only for those such words whose part-of-speech tags match the single-word phraselet template specification (essentially: noun phraselets) depends on the value of match_all_words . Wherever two phraselet matches overlap, a combined match is recorded. Combined matches are treated in the same way as other phraselet matches in further processing. This means that effectively the algorithm picks up one-word, two-word and three-word semantic combinations. See here for a discussion of the performance of this step.minimum_occurrences ; default: 4) or where the coefficient of variation (the standard deviation divided by the arithmetic mean) of the occurrences across the categories is below a threshold ( cv_threshold ; default: 1.0).oneshot==True vs. oneshot==False respectively). The outputs are the category labels, including any additional labels determined via a classification ontology. By default, the multilayer perceptron has three hidden layers where the first hidden layer has the same number of neurons as the input layer and the second and third layers have sizes in between the input and the output layer with an equally sized step between each size; the user is however free to specify any other topology.Holmes code is formatted with black.
The complexity of what Holmes does makes development impossible without a robust set of over 1400 regression tests. These can be executed individually with unittest or all at once by running the pytest utility from the Holmes source code root directory. (Note that the Python 3 command on Linux is pytest-3 .)
The pytest variant will only work on machines with sufficient memory resources. To reduce this problem, the tests are distributed across three subdirectories, so that pytest can be run three times, once from each subdirectory:
New languages can be added to Holmes by subclassing the SemanticAnalyzer and SemanticMatchingHelper classes as explained here.
The sets of matching semantic dependencies captured in the _matching_dep_dict dictionary for each language have been obtained on the basis of a mixture of linguistic-theoretical expectations and trial and error. The results would probably be improved if the _matching_dep_dict dictionaries could be derived using machine learning instead; as yet this has not been attempted because of the lack of appropriate training data.
An attempt should be made to remove personal data from supervised document classification models to make them more compliant with data protection laws.
In cases where embedding-based matching is not active, the second step of the supervised document classification procedure repeats a considerable amount of processing from the first step. Retaining the relevant information from the first step of the procedure would greatly improve training performance. This has not been attempted up to now because a large number of tests would be required to prove that such performance improvements did not have any inadvertent impacts on functionality.
The topic matching and supervised document classification use cases are both configured with a number of hyperparameters that are presently set to best-guess values derived on a purely theoretical basis. Results could be further improved by testing the use cases with a variety of hyperparameters to learn the optimal values.
The initial open-source version.
pobjp linking parents of prepositions directly with their children.MultiprocessingManager object as its facade.Manager and MultiprocessingManager classes into a single Manager class, with a redesigned public interface, that uses worker threads for everything except supervised document classification.

