Multimodal GPT
1.0.0
ฝึก chatbot แบบหลายรูปแบบด้วยคำแนะนำด้านภาพและภาษา!
จาก OpenFlamingo แบบหลายโมเดลโอเพนซอร์ซเราสร้างข้อมูล คำสั่งภาพ ที่หลากหลายด้วยชุดข้อมูลแบบเปิดรวมถึง VQA, คำบรรยายภาพ, การให้เหตุผลด้วยภาพ, ข้อความ OCR และบทสนทนาที่มองเห็น นอกจากนี้เรายังฝึกอบรมส่วนประกอบโมเดลภาษาของ OpenFlamingo โดยใช้ข้อมูล การเรียนการสอนแบบภาษาเท่านั้น
การฝึกอบรมร่วมกัน ของคำแนะนำด้านภาพและภาษาช่วยปรับปรุงประสิทธิภาพของโมเดลได้อย่างมีประสิทธิภาพ! สำหรับรายละเอียดเพิ่มเติมโปรดดูรายงานทางเทคนิคของเรา
ยินดีต้อนรับสู่เข้าร่วมกับเรา!
ภาษาอังกฤษ | 简体中文







ในการติดตั้งแพ็คเกจในสภาพแวดล้อมที่มีอยู่ให้เรียกใช้
git clone https://github.com/open-mmlab/Multimodal-GPT.git
cd Multimodal-GPT
pip install -r requirements.txt
pip install -v -e .หรือสร้างสภาพแวดล้อม conda ใหม่
conda env create -f environment.ymlดาวน์โหลดน้ำหนักที่ได้รับการฝึกอบรมล่วงหน้า
ใช้สคริปต์นี้สำหรับการแปลงน้ำหนัก Llama เป็นรูปแบบใบหน้า
ดาวน์โหลดโมเดล OpenFlamingo ที่ผ่านการฝึกอบรมล่วงหน้าจาก OpenFlamingo/OpenFlamingo-9B
ดาวน์โหลดน้ำหนัก LORA ของเราจากที่นี่
จากนั้นวางโมเดลเหล่านี้ไว้ในโฟลเดอร์ checkpoints เช่นนี้:
checkpoints
├── llama-7b_hf
│ ├── config.json
│ ├── pytorch_model-00001-of-00002.bin
│ ├── ......
│ └── tokenizer.model
├── OpenFlamingo-9B
│ └──checkpoint.pt
├──mmgpt-lora-v0-release.pt
เปิดการสาธิต gradio
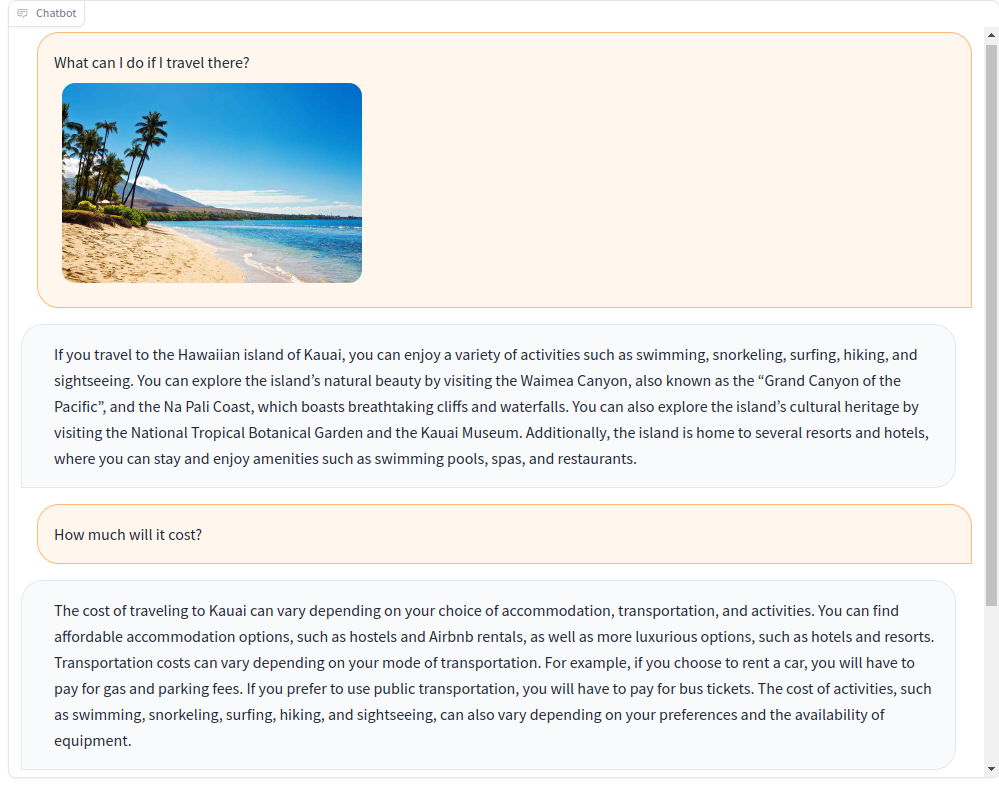
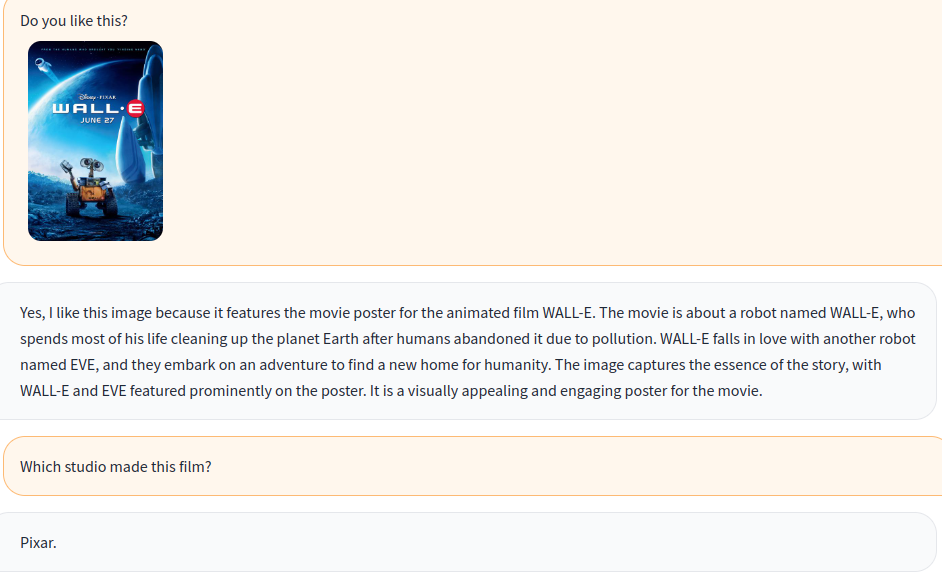
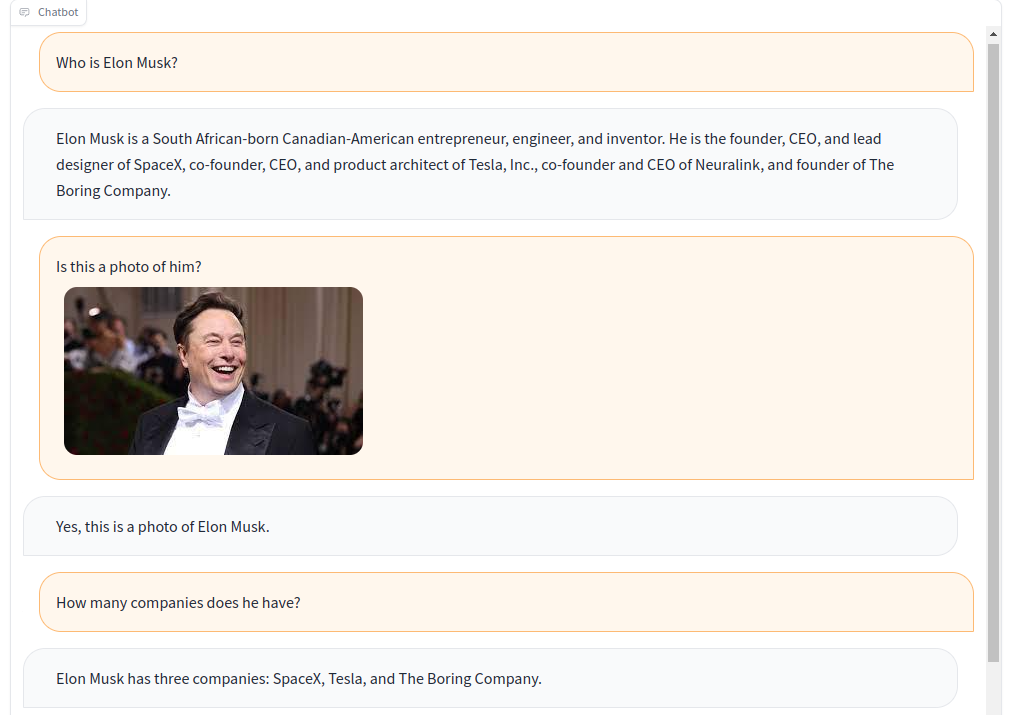
python app.py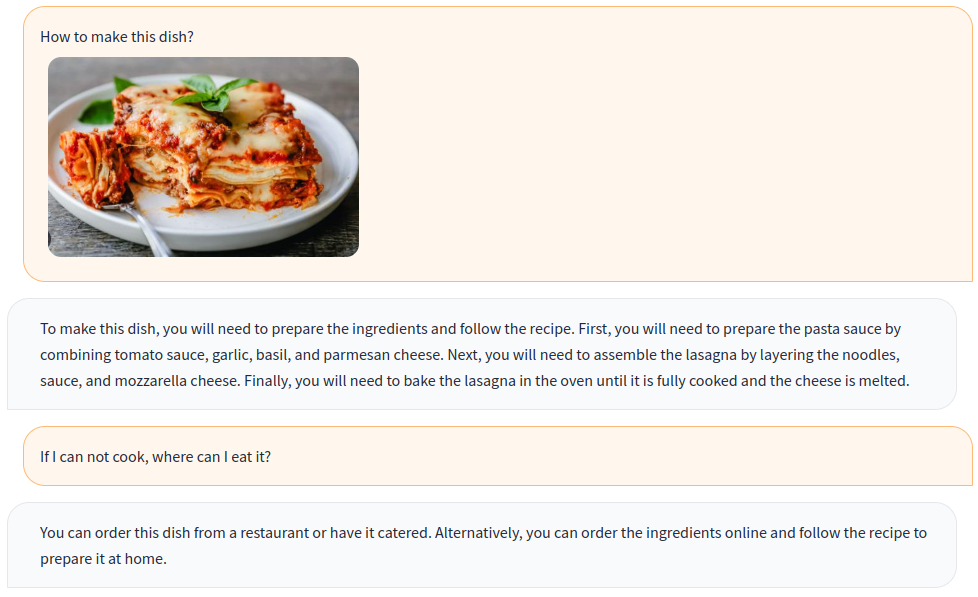
a-okvqa
ดาวน์โหลดคำอธิบายประกอบจากลิงค์นี้และคลายซิปไปยัง data/aokvqa/annotations
นอกจากนี้ยังต้องการรูปภาพจากชุดข้อมูล Coco ซึ่งสามารถดาวน์โหลดได้จากที่นี่
คำบรรยายภาพ Coco
ดาวน์โหลดจากลิงค์นี้และคลายซิปไปยัง data/coco
นอกจากนี้ยังต้องการรูปภาพจากชุดข้อมูล Coco ซึ่งสามารถดาวน์โหลดได้จากที่นี่
OCR VQA
ดาวน์โหลดจากลิงค์นี้และวางใน data/OCR_VQA/
Llava
ดาวน์โหลดจาก Liuhaotian/Llava-Instruct-150k และวางใน data/llava/
นอกจากนี้ยังต้องการรูปภาพจากชุดข้อมูล Coco ซึ่งสามารถดาวน์โหลดได้จากที่นี่
MINI-GPT4
ดาวน์โหลดจาก Vision-Cair/CC_SBU_ALIGN และวางใน data/cc_sbu_align/
Dolly 15K
ดาวน์โหลดจาก Databricks/Databricks-Dolly-15K และวางไว้ใน data/dolly/databricks-dolly-15k.jsonl
Alpaca GPT4
ดาวน์โหลดจากลิงค์นี้และวางไว้ใน data/alpaca_gpt4/alpaca_gpt4_data.json
นอกจากนี้คุณยังสามารถปรับแต่งเส้นทางข้อมูลใน configs/dataSet_config.py
บ่น
ดาวน์โหลดจากลิงค์นี้และวางไว้ใน data/baize/quora_chat_data.json
torchrun --nproc_per_node=8 mmgpt/train/instruction_finetune.py
--lm_path checkpoints/llama-7b_hf
--tokenizer_path checkpoints/llama-7b_hf
--pretrained_path checkpoints/OpenFlamingo-9B/checkpoint.pt
--run_name train-my-gpt4
--learning_rate 1e-5
--lr_scheduler cosine
--batch_size 1
--tuning_config configs/lora_config.py
--dataset_config configs/dataset_config.py
--report_to_wandbหากคุณพบว่าโครงการของเรามีประโยชน์สำหรับการวิจัยและแอปพลิเคชันของคุณโปรดอ้างอิงการใช้ BibTex นี้:
@misc { gong2023multimodalgpt ,
title = { MultiModal-GPT: A Vision and Language Model for Dialogue with Humans } ,
author = { Tao Gong and Chengqi Lyu and Shilong Zhang and Yudong Wang and Miao Zheng and Qian Zhao and Kuikun Liu and Wenwei Zhang and Ping Luo and Kai Chen } ,
year = { 2023 } ,
eprint = { 2305.04790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

