Multimodal GPT
1.0.0
Formez un chatbot multimodal avec des instructions visuelles et linguistiques!
Sur la base du modèle multimodal open source OpenFlamingo, nous créons diverses données d'instructions visuelles avec des ensembles de données ouverts, y compris le VQA, le sous-titrage de l'image, le raisonnement visuel, le Text OCR et le dialogue visuel. De plus, nous formons également le composant du modèle de langue d'OpenFlamingo en utilisant uniquement des données d'instructions linguistiques .
La formation conjointe des instructions visuelles et linguistiques améliore efficacement les performances du modèle! Pour plus de détails, veuillez vous référer à notre rapport technique.
Bienvenue à nous rejoindre!
Anglais | 简体中文







Pour installer le package dans un environnement existant, exécutez
git clone https://github.com/open-mmlab/Multimodal-GPT.git
cd Multimodal-GPT
pip install -r requirements.txt
pip install -v -e .ou créer un nouvel environnement conda
conda env create -f environment.ymlTéléchargez les poids pré-formés.
Utilisez ce script pour convertir les poids de lama au format de visage étreint.
Téléchargez le modèle pré-formé OpenFlamingo à partir d'OpenFlamingo / OpenFlamingo-9b.
Téléchargez notre poids Lora à partir d'ici.
Ensuite, placez ces modèles dans des dossiers checkpoints comme celui-ci:
checkpoints
├── llama-7b_hf
│ ├── config.json
│ ├── pytorch_model-00001-of-00002.bin
│ ├── ......
│ └── tokenizer.model
├── OpenFlamingo-9B
│ └──checkpoint.pt
├──mmgpt-lora-v0-release.pt
Lancez la démo Gradio
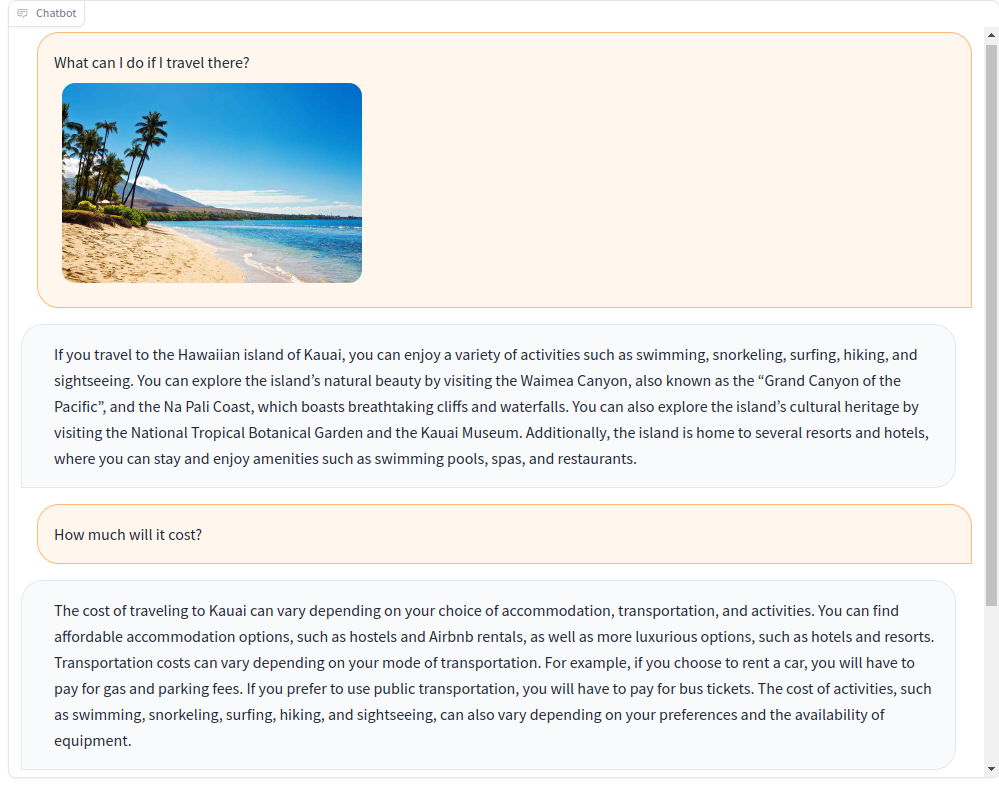
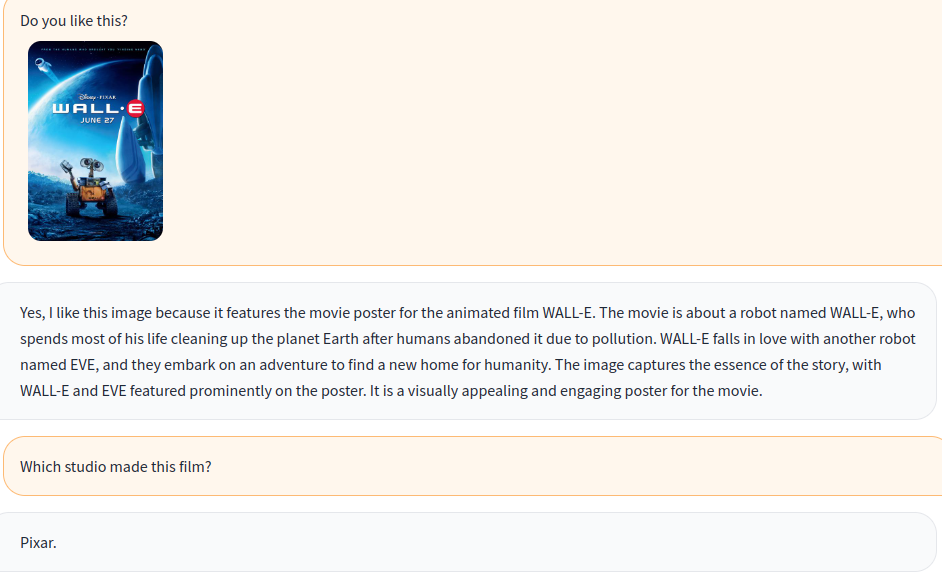
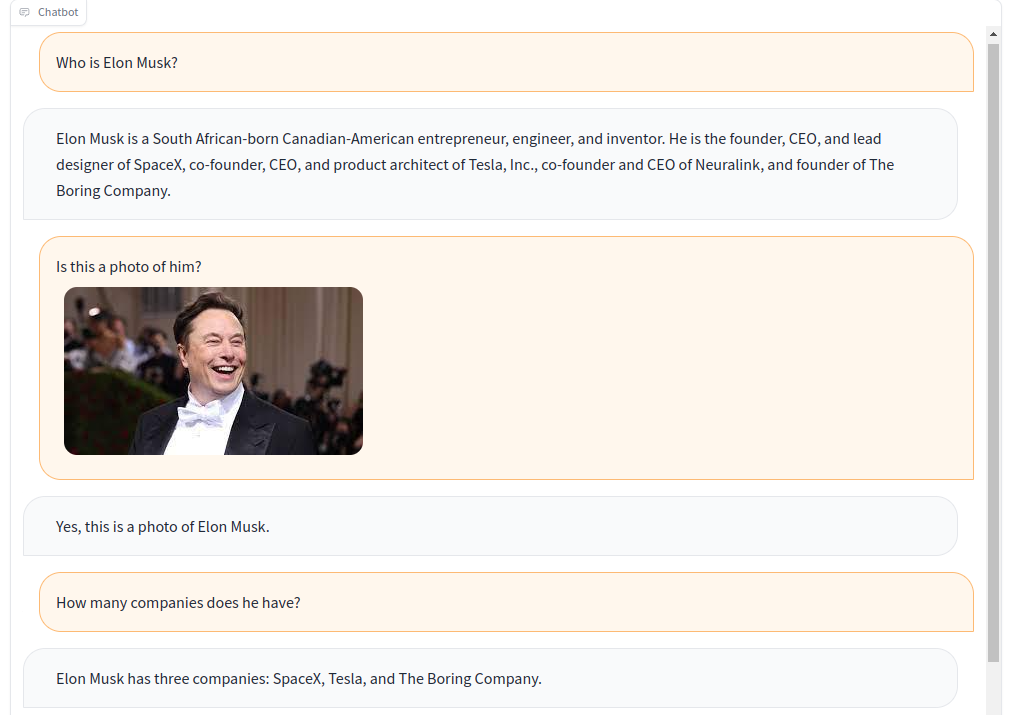
python app.py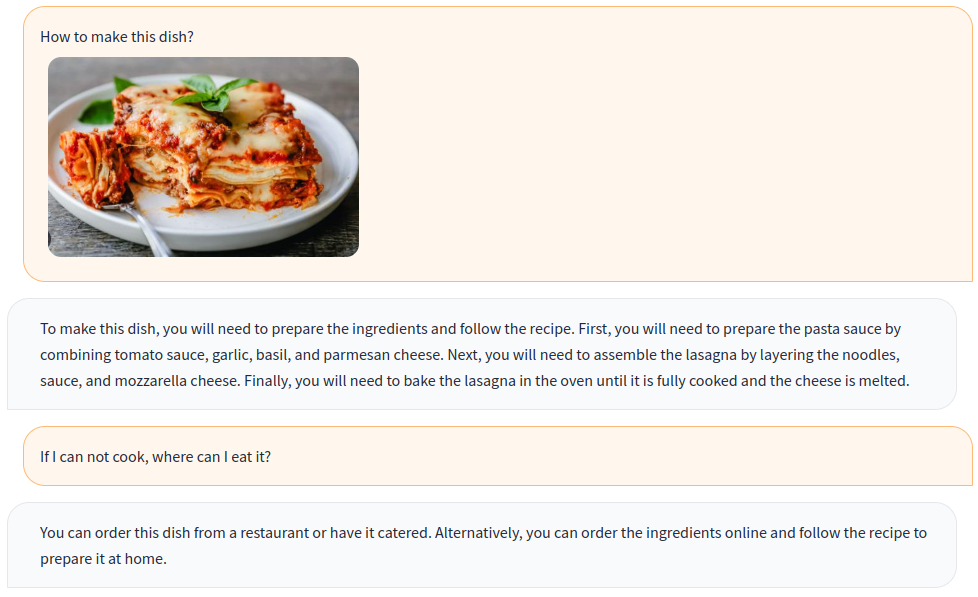
A-okvqa
Téléchargez l'annotation à partir de ce lien et dézip vers data/aokvqa/annotations .
Il nécessite également des images de l'ensemble de données CoCo qui peuvent être téléchargées à partir d'ici.
Coco Légende
Téléchargez à partir de ce lien et dézip à data/coco .
Il nécessite également des images de l'ensemble de données CoCo qui peuvent être téléchargées à partir d'ici.
OCR VQA
Téléchargez à partir de ce lien et placez-le dans data/OCR_VQA/ .
Llave
Téléchargez depuis Liuhaotian / Llava-Instruct-150k et placez dans data/llava/ .
Il nécessite également des images de l'ensemble de données CoCo qui peuvent être téléchargées à partir d'ici.
Mini-gpt4
Téléchargez à partir de Vision-Cair / CC_SBU_ALIGN et placez-le dans data/cc_sbu_align/ .
Dolly 15K
Téléchargez à partir de Databricks / Databricks-Dolly-15K et placez-les dans data/dolly/databricks-dolly-15k.jsonl .
Alpaga gpt4
Téléchargez-le à partir de ce lien et placez-le dans data/alpaca_gpt4/alpaca_gpt4_data.json .
Vous pouvez également personnaliser le chemin de données dans les configs / dataset_config.py.
Tapis
Téléchargez-le à partir de ce lien et placez-le dans data/baize/quora_chat_data.json .
torchrun --nproc_per_node=8 mmgpt/train/instruction_finetune.py
--lm_path checkpoints/llama-7b_hf
--tokenizer_path checkpoints/llama-7b_hf
--pretrained_path checkpoints/OpenFlamingo-9B/checkpoint.pt
--run_name train-my-gpt4
--learning_rate 1e-5
--lr_scheduler cosine
--batch_size 1
--tuning_config configs/lora_config.py
--dataset_config configs/dataset_config.py
--report_to_wandbSi vous trouvez notre projet utile pour vos recherches et vos applications, veuillez citer en utilisant ce bibtex:
@misc { gong2023multimodalgpt ,
title = { MultiModal-GPT: A Vision and Language Model for Dialogue with Humans } ,
author = { Tao Gong and Chengqi Lyu and Shilong Zhang and Yudong Wang and Miao Zheng and Qian Zhao and Kuikun Liu and Wenwei Zhang and Ping Luo and Kai Chen } ,
year = { 2023 } ,
eprint = { 2305.04790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

