Multimodal GPT
1.0.0
Тренируйте многомодальный чат-бот с визуальными и языковыми инструкциями!
Основываясь на многомодальной модели с открытым исходным кодом, мы создаем различные данные о визуальных инструкциях с открытыми наборами данных, включая VQA, подписание изображений, визуальные рассуждения, текстовый OCR и визуальный диалог. Кроме того, мы также обучаем языковую модель компонента OpenFlamingo, используя только данные инструкции только для языка .
Совместное обучение визуальных и языковых инструкций эффективно улучшает производительность модели! Для получения более подробной информации, пожалуйста, обратитесь к нашему техническому отчету.
Добро пожаловать, присоединиться к нам!
Английский | 简体中文







Чтобы установить пакет в существующей среде, запустите
git clone https://github.com/open-mmlab/Multimodal-GPT.git
cd Multimodal-GPT
pip install -r requirements.txt
pip install -v -e .или создать новую среду Conda
conda env create -f environment.ymlЗагрузите предварительно обученные веса.
Используйте этот скрипт для преобразования весов ламы в обнимающееся формат лица.
Загрузите предварительно обученную модель OpenFlamingo от OpenFlamingo/OpenFlamingo-9b.
Загрузите наш вес LORA отсюда.
Затем поместите эти модели в папки checkpoints , подобные этим:
checkpoints
├── llama-7b_hf
│ ├── config.json
│ ├── pytorch_model-00001-of-00002.bin
│ ├── ......
│ └── tokenizer.model
├── OpenFlamingo-9B
│ └──checkpoint.pt
├──mmgpt-lora-v0-release.pt
запустить демонстрацию Gradio
python app.py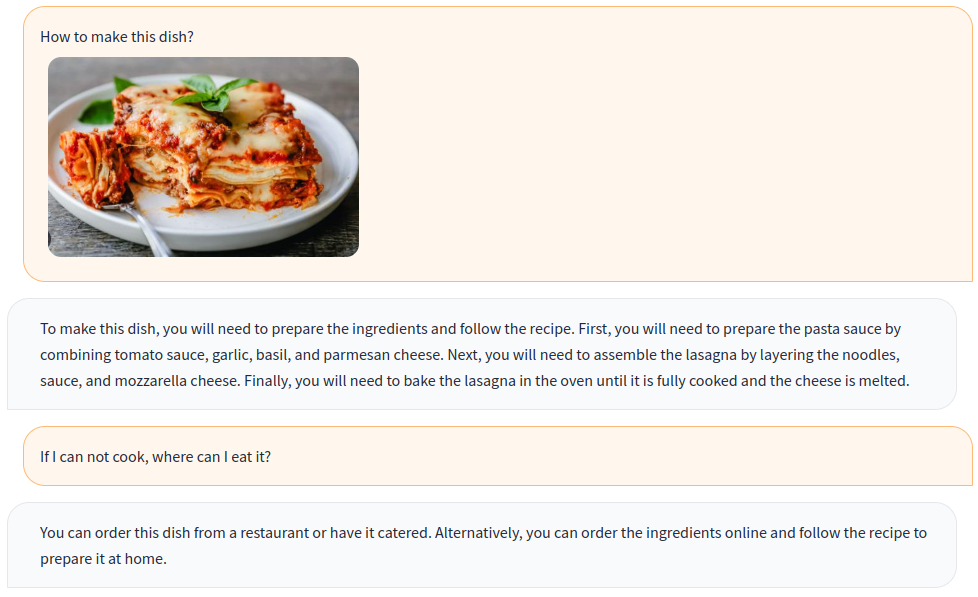
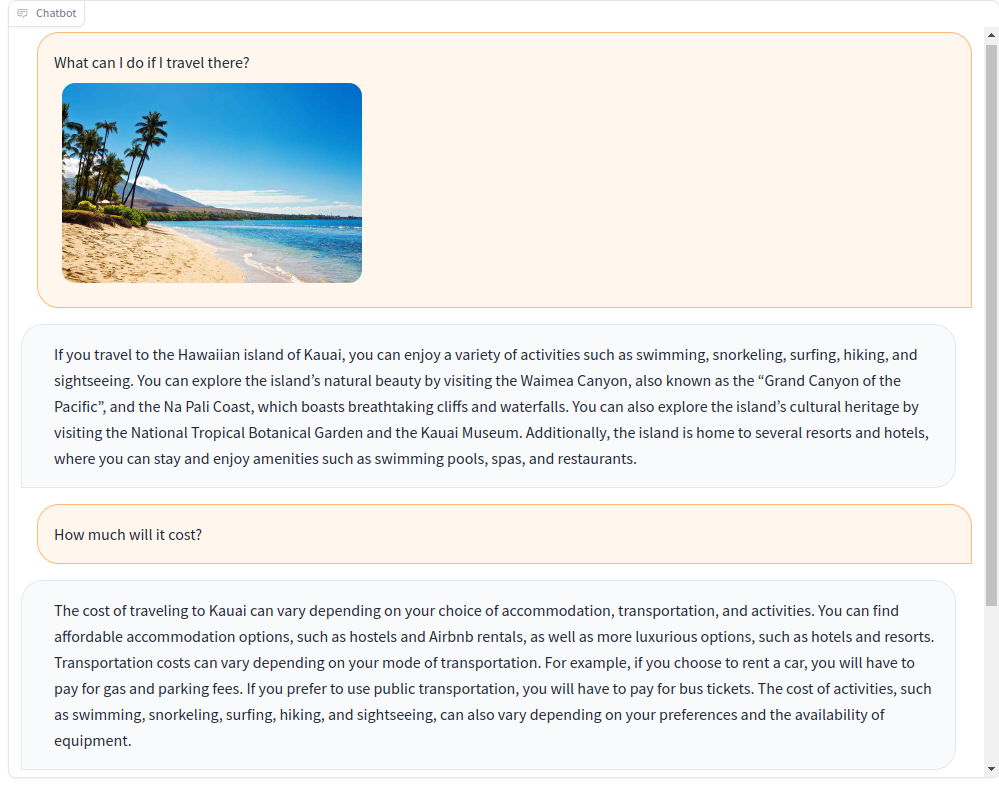
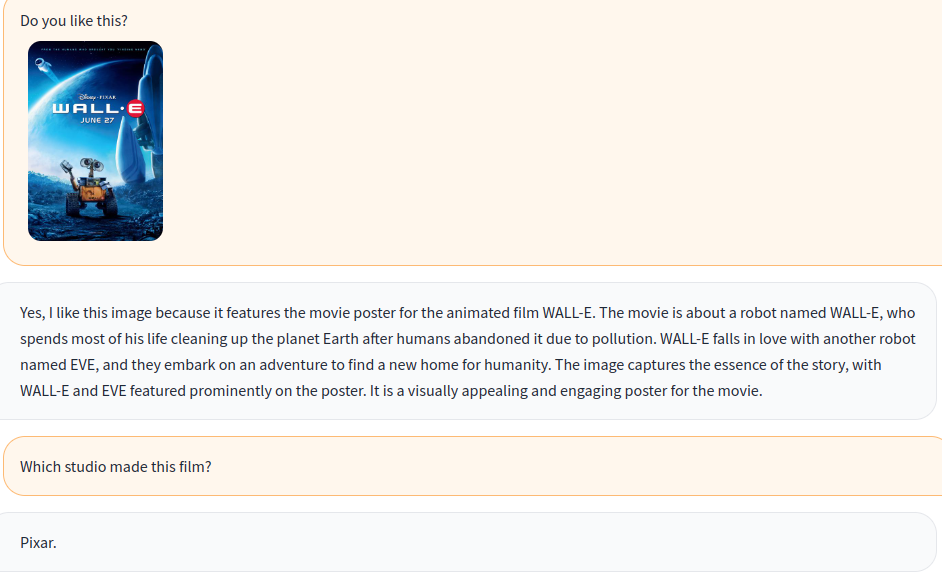
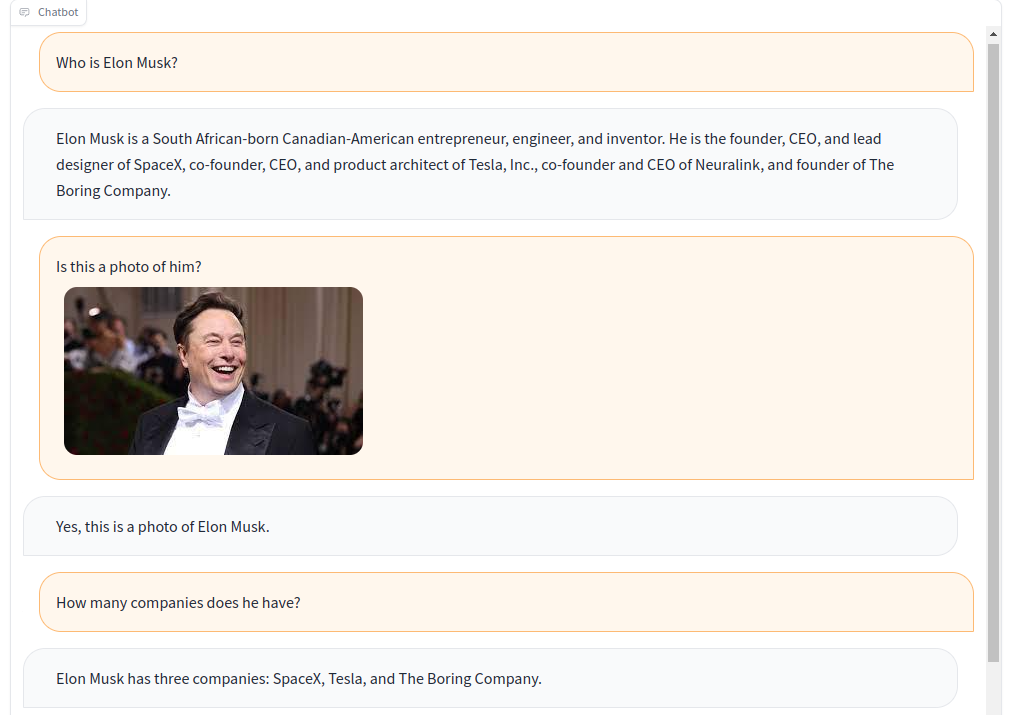
A-okvqa
Загрузите аннотацию по этой ссылке и разкачивается на data/aokvqa/annotations .
Это также требует изображений из набора данных Coco, которые можно загрузить отсюда.
Коко. Подпись
Загрузите по этой ссылке и разкачивается на data/coco .
Это также требует изображений из набора данных Coco, которые можно загрузить отсюда.
OCR VQA
Загрузите по этой ссылке и поместите в data/OCR_VQA/ .
Ллава
Скачать из Liuhootian/Llava-Instruct-150K и место в data/llava/ .
Это также требует изображений из набора данных Coco, которые можно загрузить отсюда.
Мини-GPT4
Загрузите из Vision-Cair/CC_SBU_ALIGN и поместите в data/cc_sbu_align/ .
Долли 15к
Загрузите из DataBricks/DataBricks-Dolly-15K и поместите его в data/dolly/databricks-dolly-15k.jsonl .
Alpaca GPT4
Загрузите его по этой ссылке и поместите его в data/alpaca_gpt4/alpaca_gpt4_data.json .
Вы также можете настроить путь данных в configs/dataset_config.py.
Baize
Загрузите его по этой ссылке и поместите в data/baize/quora_chat_data.json .
torchrun --nproc_per_node=8 mmgpt/train/instruction_finetune.py
--lm_path checkpoints/llama-7b_hf
--tokenizer_path checkpoints/llama-7b_hf
--pretrained_path checkpoints/OpenFlamingo-9B/checkpoint.pt
--run_name train-my-gpt4
--learning_rate 1e-5
--lr_scheduler cosine
--batch_size 1
--tuning_config configs/lora_config.py
--dataset_config configs/dataset_config.py
--report_to_wandbЕсли вы найдете наш проект полезным для ваших исследований и приложений, пожалуйста, упоминайте об этом Bibtex:
@misc { gong2023multimodalgpt ,
title = { MultiModal-GPT: A Vision and Language Model for Dialogue with Humans } ,
author = { Tao Gong and Chengqi Lyu and Shilong Zhang and Yudong Wang and Miao Zheng and Qian Zhao and Kuikun Liu and Wenwei Zhang and Ping Luo and Kai Chen } ,
year = { 2023 } ,
eprint = { 2305.04790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

