Multimodal GPT
1.0.0
視覚と言語の指示でマルチモーダルチャットボットをトレーニングしてください!
オープンソースのマルチモーダルモデルOpenFlamingoに基づいて、VQA、画像キャプション、視覚的推論、テキストOCR、視覚対話など、オープンデータセットを使用してさまざまな視覚命令データを作成します。さらに、言語のみの命令データのみを使用して、OpenFlamingoの言語モデルコンポーネントをトレーニングします。
視覚的および言語指示の共同トレーニングにより、モデルのパフォーマンスが効果的に向上します!詳細については、テクニカルレポートを参照してください。
ご参加へようこそ!
英語| 简体中文







既存の環境にパッケージをインストールするには、実行します
git clone https://github.com/open-mmlab/Multimodal-GPT.git
cd Multimodal-GPT
pip install -r requirements.txt
pip install -v -e .または、新しいコンドラ環境を作成します
conda env create -f environment.yml事前に訓練されたウェイトをダウンロードします。
このスクリプトを使用して、ラマウェイトを顔の形式の抱きしめに変換します。
OpenFlamingo/OpenFlamingo-9BからOpenFlamingo事前訓練を受けたモデルをダウンロードします。
ここからロラの重量をダウンロードしてください。
次に、これらのモデルをこのようなcheckpointsフォルダーに配置します。
checkpoints
├── llama-7b_hf
│ ├── config.json
│ ├── pytorch_model-00001-of-00002.bin
│ ├── ......
│ └── tokenizer.model
├── OpenFlamingo-9B
│ └──checkpoint.pt
├──mmgpt-lora-v0-release.pt
Gradio Demoを起動します
python app.py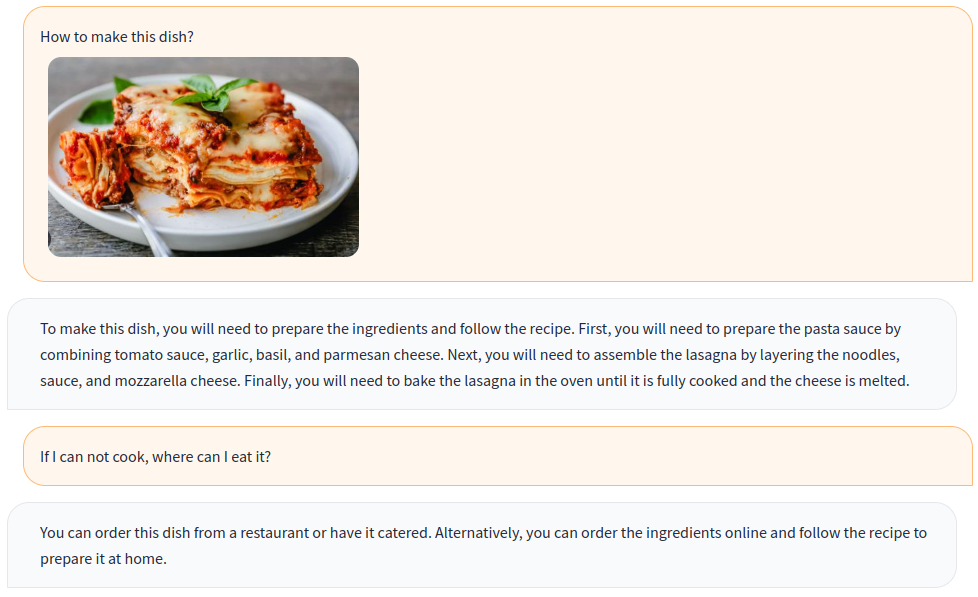
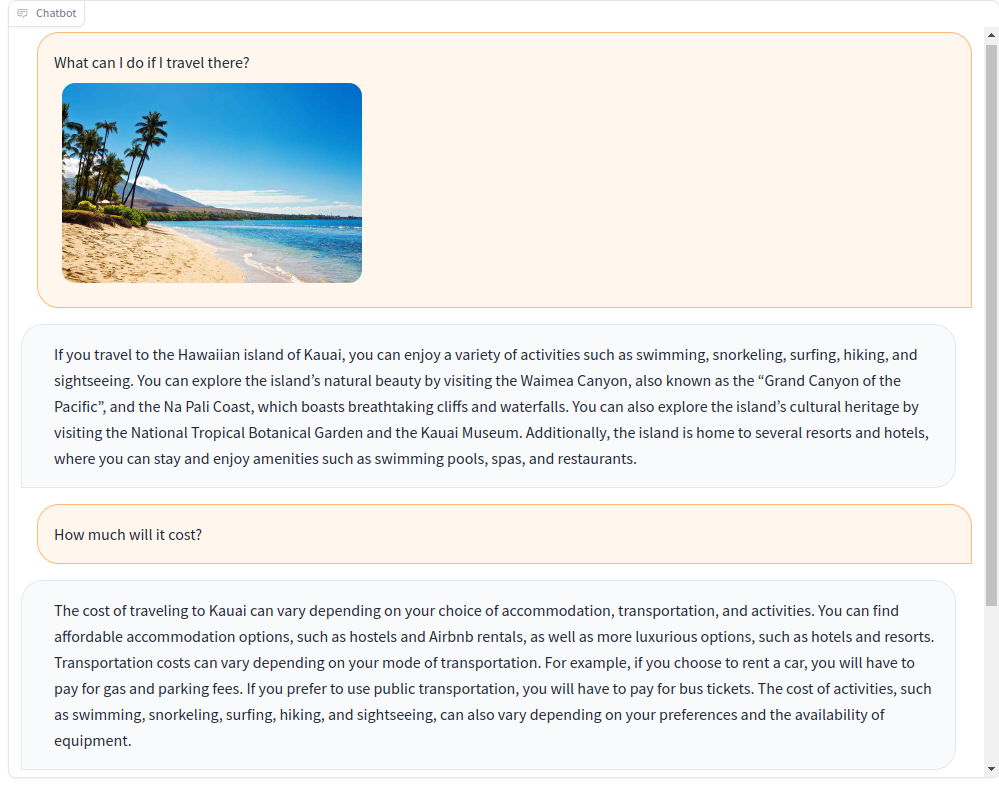
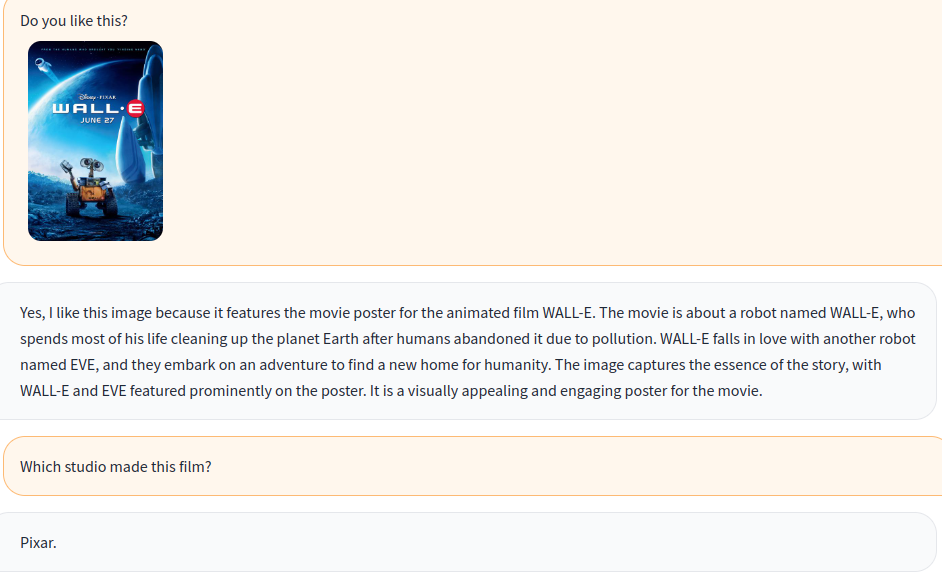
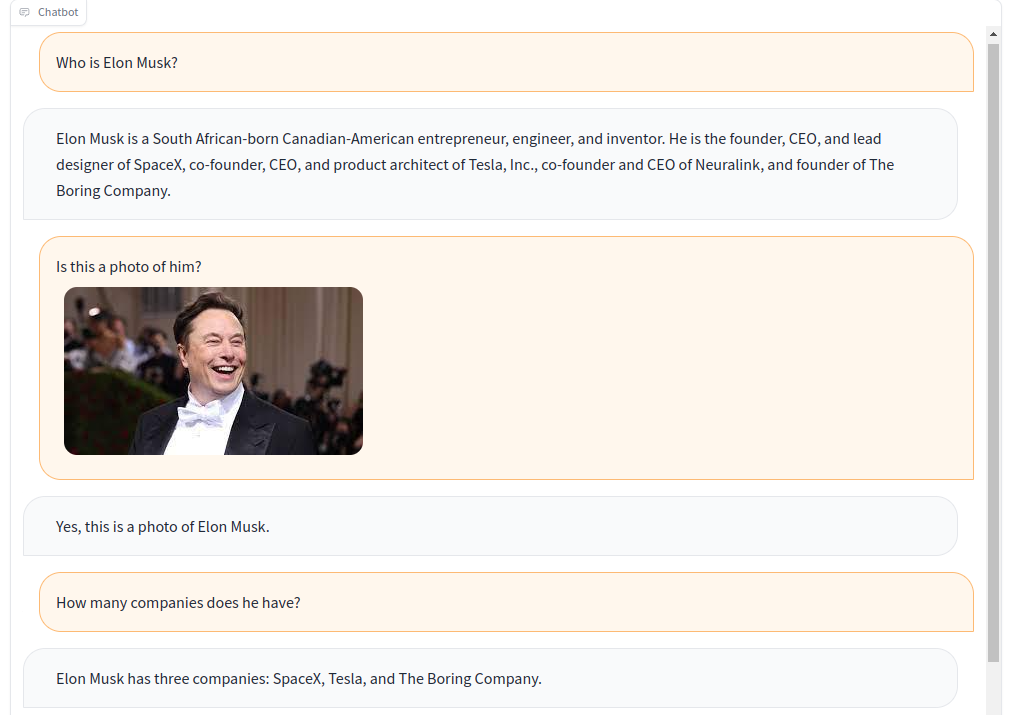
a-okvqa
このリンクから注釈をダウンロードし、 data/aokvqa/annotationsに解凍します。
また、ここからダウンロードできるCocoデータセットからの画像も必要です。
ココキャプション
このリンクからダウンロードして、 data/cocoに解凍します。
また、ここからダウンロードできるCocoデータセットからの画像も必要です。
OCR VQA
このリンクからダウンロードして、 data/OCR_VQA/に配置します。
llava
liuhaotian/llava-instruct-150kからダウンロードし、 data/llava/に配置します。
また、ここからダウンロードできるCocoデータセットからの画像も必要です。
MINI-GPT4
Vision-Cair/cc_sbu_alignからダウンロードし、 data/cc_sbu_align/に配置します。
ドリー15k
DataBricks/DataBricks-Dolly-15Kからダウンロードして、 data/dolly/databricks-dolly-15k.jsonlに配置します。
ALPACA GPT4
このリンクからダウンロードして、 data/alpaca_gpt4/alpaca_gpt4_data.jsonに配置します。
configs/dataset_config.pyのデータパスをカスタマイズすることもできます。
バイズ
このリンクからダウンロードして、 data/baize/quora_chat_data.jsonに配置します。
torchrun --nproc_per_node=8 mmgpt/train/instruction_finetune.py
--lm_path checkpoints/llama-7b_hf
--tokenizer_path checkpoints/llama-7b_hf
--pretrained_path checkpoints/OpenFlamingo-9B/checkpoint.pt
--run_name train-my-gpt4
--learning_rate 1e-5
--lr_scheduler cosine
--batch_size 1
--tuning_config configs/lora_config.py
--dataset_config configs/dataset_config.py
--report_to_wandb私たちのプロジェクトがあなたの研究とアプリケーションに役立つと思うなら、このbibtexを使用して引用してください:
@misc { gong2023multimodalgpt ,
title = { MultiModal-GPT: A Vision and Language Model for Dialogue with Humans } ,
author = { Tao Gong and Chengqi Lyu and Shilong Zhang and Yudong Wang and Miao Zheng and Qian Zhao and Kuikun Liu and Wenwei Zhang and Ping Luo and Kai Chen } ,
year = { 2023 } ,
eprint = { 2305.04790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

