Multimodal GPT
1.0.0
Latih chatbot multi-modal dengan instruksi visual dan bahasa!
Berdasarkan model multi-modal open-source OpenFlamingo, kami membuat berbagai data instruksi visual dengan set data terbuka, termasuk VQA, captioning gambar, penalaran visual, teks OCR, dan dialog visual. Selain itu, kami juga melatih komponen model bahasa OpenFlamingo hanya menggunakan data instruksi hanya bahasa .
Pelatihan bersama instruksi visual dan bahasa secara efektif meningkatkan kinerja model! Untuk detail lebih lanjut silakan lihat laporan teknis kami.
Selamat datang untuk bergabung dengan kami!
Bahasa Inggris | 简体中文







Untuk menginstal paket di lingkungan yang ada, jalankan
git clone https://github.com/open-mmlab/Multimodal-GPT.git
cd Multimodal-GPT
pip install -r requirements.txt
pip install -v -e .atau menciptakan lingkungan Conda baru
conda env create -f environment.ymlUnduh bobot pra-terlatih.
Gunakan skrip ini untuk mengubah bobot llama menjadi memeluk format wajah.
Unduh model pra-terlatih OpenFlamingo dari OpenFlamingo/OpenFlamingo-9b.
Unduh berat Lora kami dari sini.
Kemudian tempatkan model -model ini di folder checkpoints seperti ini:
checkpoints
├── llama-7b_hf
│ ├── config.json
│ ├── pytorch_model-00001-of-00002.bin
│ ├── ......
│ └── tokenizer.model
├── OpenFlamingo-9B
│ └──checkpoint.pt
├──mmgpt-lora-v0-release.pt
Luncurkan Demo Gradio
python app.py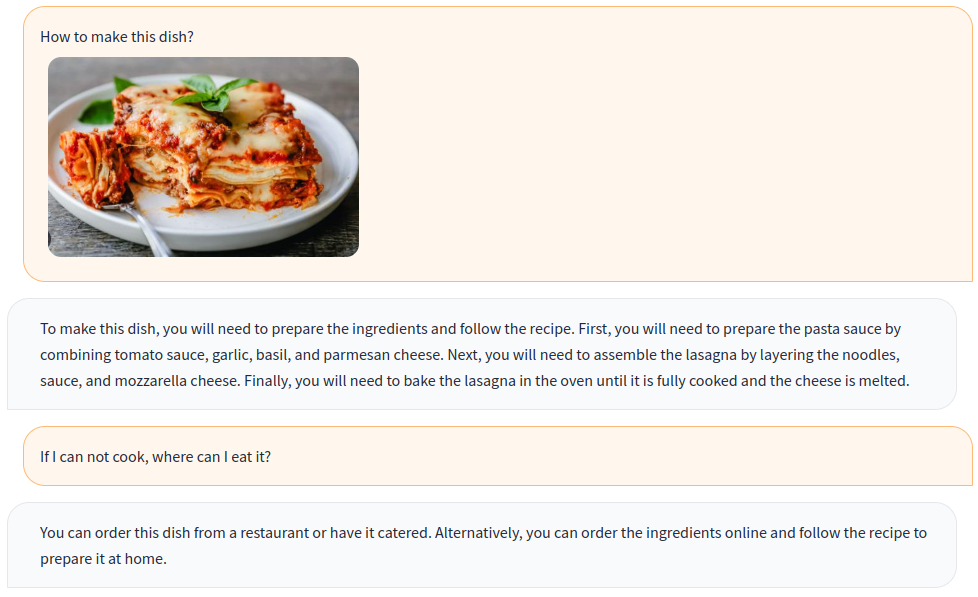
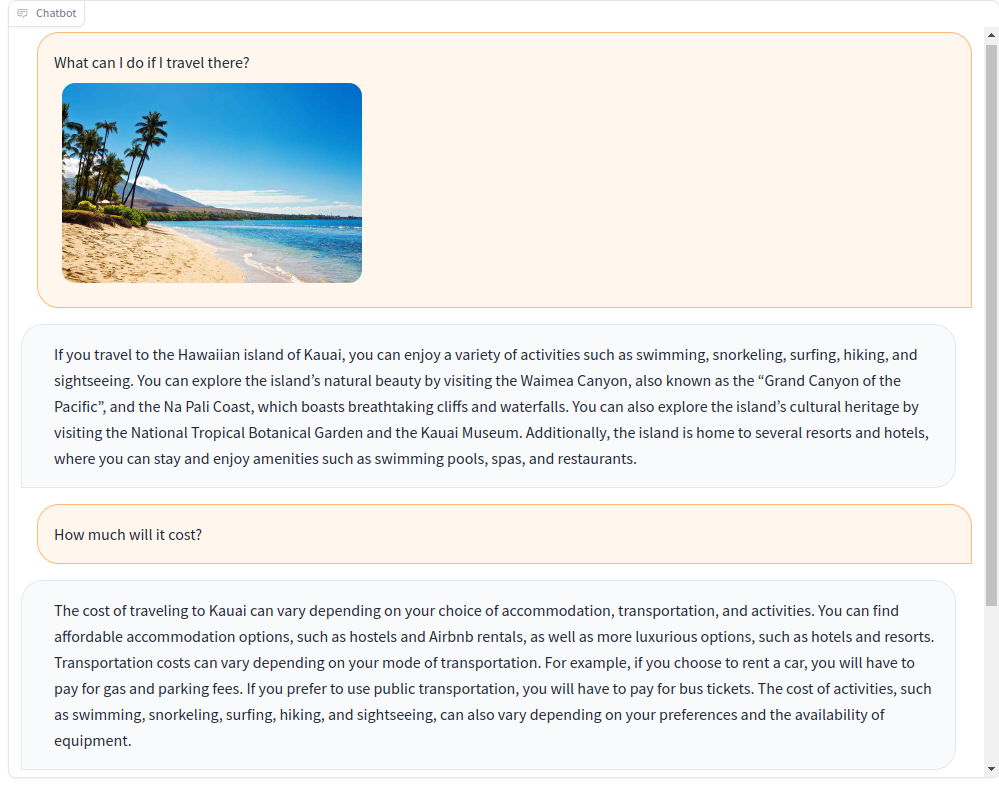
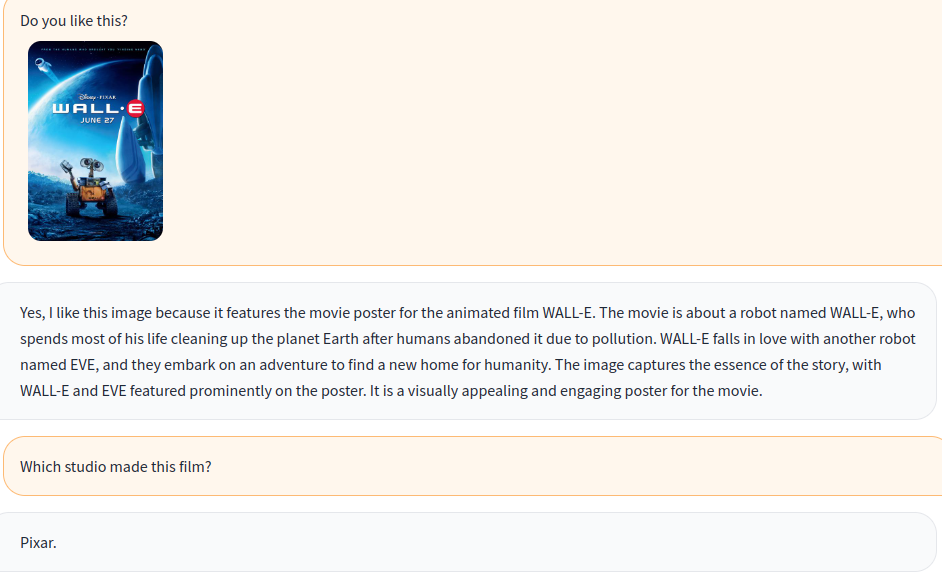
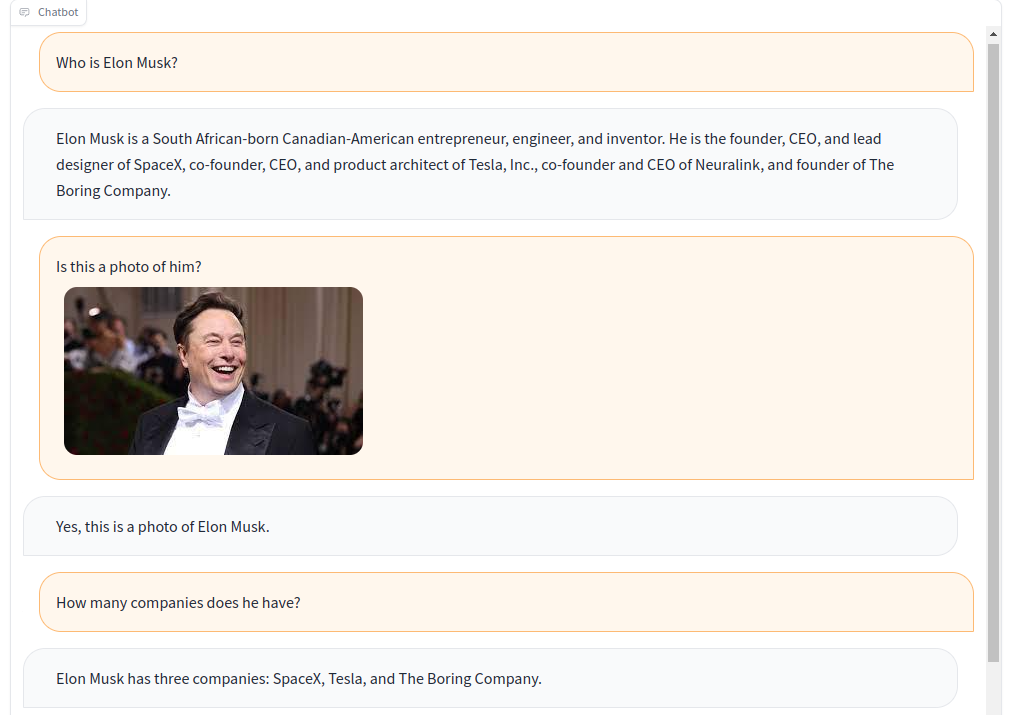
A-okvqa
Unduh anotasi dari tautan ini dan unzip ke data/aokvqa/annotations .
Ini juga membutuhkan gambar dari dataset Coco yang dapat diunduh dari sini.
Keterangan Coco
Unduh dari tautan ini dan unzip ke data/coco .
Ini juga membutuhkan gambar dari dataset Coco yang dapat diunduh dari sini.
OCR VQA
Unduh dari tautan ini dan tempatkan dalam data/OCR_VQA/ .
Llava
Unduh dari Liuhaotian/llava-instruct-150k dan tempat di data/llava/ .
Ini juga membutuhkan gambar dari dataset Coco yang dapat diunduh dari sini.
Mini-gpt4
Unduh dari vision-cair/cc_sbu_align dan tempat di data/cc_sbu_align/ .
Dolly 15k
Unduh dari databricks/databricks-dolly-15k dan letakkan di data/dolly/databricks-dolly-15k.jsonl .
Alpaca GPT4
Unduh dari tautan ini dan letakkan di data/alpaca_gpt4/alpaca_gpt4_data.json .
Anda juga dapat menyesuaikan jalur data di konfigurasi/dataset_config.py.
Kain tebal dr wol kasar
Unduh dari tautan ini dan letakkan di data/baize/quora_chat_data.json .
torchrun --nproc_per_node=8 mmgpt/train/instruction_finetune.py
--lm_path checkpoints/llama-7b_hf
--tokenizer_path checkpoints/llama-7b_hf
--pretrained_path checkpoints/OpenFlamingo-9B/checkpoint.pt
--run_name train-my-gpt4
--learning_rate 1e-5
--lr_scheduler cosine
--batch_size 1
--tuning_config configs/lora_config.py
--dataset_config configs/dataset_config.py
--report_to_wandbJika Anda menemukan proyek kami berguna untuk penelitian dan aplikasi Anda, silakan kutip menggunakan Bibtex ini:
@misc { gong2023multimodalgpt ,
title = { MultiModal-GPT: A Vision and Language Model for Dialogue with Humans } ,
author = { Tao Gong and Chengqi Lyu and Shilong Zhang and Yudong Wang and Miao Zheng and Qian Zhao and Kuikun Liu and Wenwei Zhang and Ping Luo and Kai Chen } ,
year = { 2023 } ,
eprint = { 2305.04790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

