whisper writer
v1.0.1
อัปเดต (2024-05-28): ฉันเพิ่งรวมเข้ากับการเขียนครั้งสำคัญของ WhisperWriter! เราได้ย้ายจากการใช้ tkinter เพื่อใช้ PyQt5 สำหรับ UI เพิ่มหน้าต่างการตั้งค่าใหม่สำหรับการกำหนดค่าโหมดการบันทึกอย่างต่อเนื่องใหม่รองรับ API ท้องถิ่นและอีกมากมาย! โปรดอดทนเพราะฉันหาข้อบกพร่องใด ๆ ที่อาจได้รับการแนะนำในกระบวนการ หากคุณพบปัญหาใด ๆ โปรดเปิดปัญหาใหม่!
WhisperWriter เป็นแอพพูดเป็นข้อความขนาดเล็กที่ใช้โมเดล Whisper ของ OpenAI ในการบันทึกการถ่ายโอนอัตโนมัติจากไมโครโฟนของผู้ใช้ไปยังหน้าต่างที่ใช้งานอยู่
เมื่อเริ่มต้นสคริปต์จะทำงานในพื้นหลังและรอให้กดแป้นพิมพ์ลัด ( ctrl+shift+space โดยค่าเริ่มต้น) เมื่อกดทางลัดแอปจะเริ่มบันทึกจากไมโครโฟนของคุณ มีสี่โหมดการบันทึกให้เลือก:
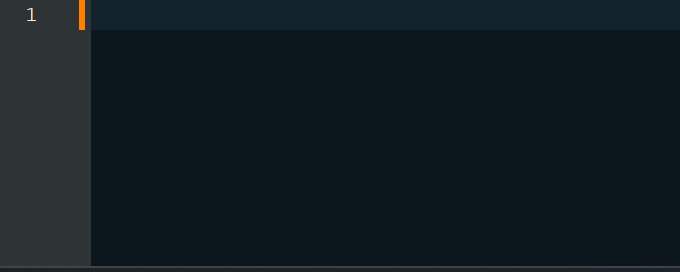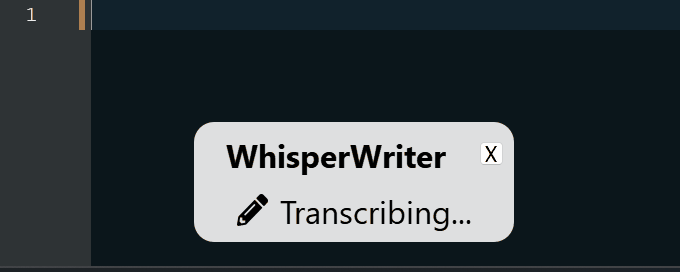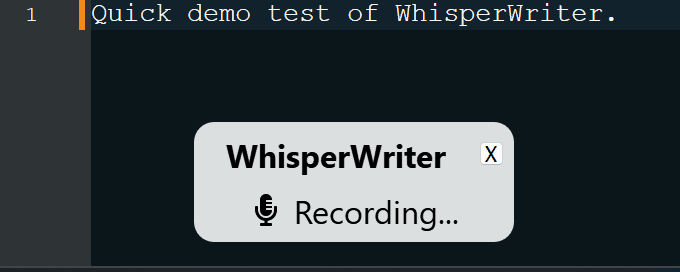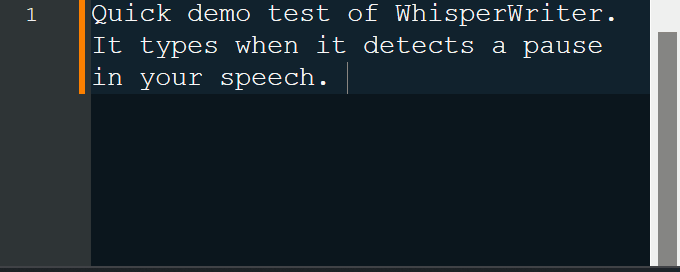
continuous (ค่าเริ่มต้น): การบันทึกจะหยุดลงหลังจากหยุดชั่วคราวนานพอในคำพูดของคุณ แอพจะถอดความข้อความแล้วเริ่มบันทึกอีกครั้ง หากต้องการหยุดฟังให้กดแป้นพิมพ์ลัดอีกครั้งvoice_activity_detection : การบันทึกจะหยุดลงหลังจากหยุดชั่วคราวนานพอในคำพูดของคุณ การบันทึกจะไม่เริ่มจนกว่าแป้นพิมพ์ลัดจะถูกกดอีกครั้งpress_to_toggle จะหยุดเมื่อกดแป้นพิมพ์อีกครั้ง การบันทึกจะไม่เริ่มจนกว่าแป้นพิมพ์ลัดจะถูกกดอีกครั้งhold_to_record จะดำเนินต่อไปจนกว่าแป้นพิมพ์จะถูกปล่อยออกมา การบันทึกจะไม่เริ่มจนกว่าแป้นพิมพ์ลัดจะถูกเก็บไว้อีกครั้ง คุณสามารถเปลี่ยนแป้นพิมพ์ลัด ( activation_key ) และโหมดการบันทึกในตัวเลือกการกำหนดค่า ในขณะที่การบันทึกและการถอดความหน้าต่างสถานะขนาดเล็กจะปรากฏขึ้นซึ่งแสดงขั้นตอนปัจจุบันของกระบวนการ (แต่สามารถปิดได้) เมื่อการถอดความเสร็จสมบูรณ์ข้อความที่ถอดความจะถูกเขียนลงในหน้าต่างที่ใช้งานโดยอัตโนมัติ
การถอดความสามารถทำได้ในพื้นที่ผ่านแพ็คเกจ Python ที่เร็วขึ้นหรือผ่านการร้องขอไปยัง API ของ Openai โดยค่าเริ่มต้นแอปจะใช้โมเดลท้องถิ่น แต่คุณสามารถเปลี่ยนสิ่งนี้ในตัวเลือกการกำหนดค่า หากคุณเลือกที่จะใช้ API คุณจะต้องจัดเตรียมคีย์ OpenAI API ของคุณหรือเปลี่ยนจุดสิ้นสุด URL พื้นฐาน
ความจริงสนุก: เกือบทั้งหมดของการเปิดตัวโครงการเริ่มต้นทั้งหมดได้รับการตั้งโปรแกรมคู่กับ CHATGPT-4 และ GitHub Copilot โดยใช้รหัส VS ในทางปฏิบัติทุกบรรทัดรวมถึง readme ส่วนใหญ่นี้เขียนโดย AI หลังจากต้นแบบเริ่มต้นเสร็จแล้ว WhisperWriter ก็ถูกใช้เพื่อเขียนพรอมต์จำนวนมากเช่นกัน!
ก่อนที่คุณจะเรียกใช้แอพนี้คุณจะต้องติดตั้งซอฟต์แวร์ต่อไปนี้:
3.11 : https://www.python.org/downloads/ หากคุณต้องการทำงาน faster-whisper บน GPU ของคุณคุณจะต้องติดตั้งไลบรารี Nvidia ต่อไปนี้:
ด้านล่างถูกนำมาโดยตรงจาก readme faster-whisper :
หมายเหตุ: ctranslate2 รุ่นล่าสุดรองรับ CUDA 12 เท่านั้น สำหรับ CUDA 11 วิธีแก้ปัญหาในปัจจุบันจะลดระดับเป็น ctranslate2 รุ่น 3.24.0 (สามารถทำได้ด้วย pip install --force-reinsall ctranslate2==3.24.0 )
มีหลายวิธีในการติดตั้งไลบรารี Nvidia ที่กล่าวถึงข้างต้น วิธีที่แนะนำได้อธิบายไว้ในเอกสารอย่างเป็นทางการของ NVIDIA แต่เรายังแนะนำวิธีการติดตั้งอื่น ๆ ด้านล่าง
ห้องสมุด (Cublas, Cudnn) ได้รับการติดตั้งในภาพ Docker Nvidia Cuda อย่างเป็นทางการเหล่านี้: nvidia/cuda:12.0.0-runtime-ubuntu20.04 หรือ nvidia/cuda:12.0.0-runtime-ubuntu22.04
pip (Linux เท่านั้น) บน Linux ไลบรารีเหล่านี้สามารถติดตั้งด้วย pip โปรดทราบว่าจะต้องตั้งค่า LD_LIBRARY_PATH ก่อนที่จะเปิดตัว Python
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
export LD_LIBRARY_PATH= ` python3 -c ' import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__)) ' ` หมายเหตุ : เวอร์ชัน 9+ ของ nvidia-cudnn-cu12 ดูเหมือนจะทำให้เกิดปัญหาเนื่องจากการพึ่งพา CUDNN 9 (เร็วขึ้น-Whisper ไม่สนับสนุน CUDNN 9) ตรวจสอบให้แน่ใจว่าแพ็คเกจ Python เวอร์ชันของคุณสำหรับ Cudnn 8
Whisper-Standalone-win ของ Purfview ให้ห้องสมุด Nvidia ที่ต้องการสำหรับ Windows & Linux ในการเก็บถาวรเดียว บีบอัดการเก็บถาวรและวางไลบรารีไว้ในไดเรกทอรีที่รวมอยู่ใน PATH
ในการตั้งค่าและเรียกใช้โครงการให้ทำตามขั้นตอนเหล่านี้:
git clone https://github.com/savbell/whisper-writer
cd whisper-writer
python -m venv venv
# For Linux and macOS:
source venv/bin/activate
# For Windows:
venvScriptsactivate
pip install -r requirements.txt
python run.py
ในการเรียกใช้ครั้งแรกหน้าต่างการตั้งค่าควรปรากฏขึ้น เมื่อกำหนดค่าและบันทึกหน้าต่างอื่นจะเปิดขึ้น กด "Start" เพื่อเปิดใช้งานคีย์บอร์ด Listener กดปุ่มเปิดใช้งาน ( ctrl+shift+space โดยค่าเริ่มต้น) เพื่อเริ่มการบันทึกและถอดความไปยังหน้าต่างที่ใช้งานอยู่
WhisperWriter ใช้ไฟล์กำหนดค่าเพื่อปรับแต่งพฤติกรรม ในการตั้งค่าการกำหนดค่าให้เปิดหน้าต่างการตั้งค่า:
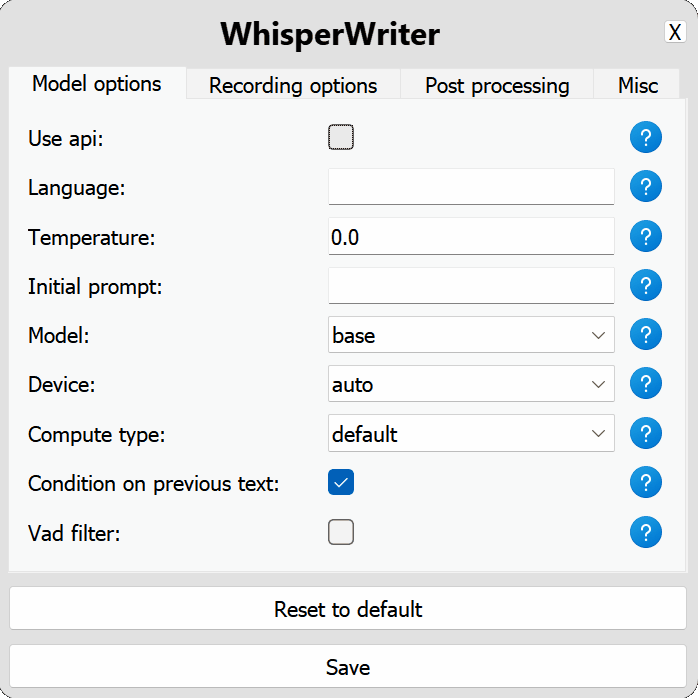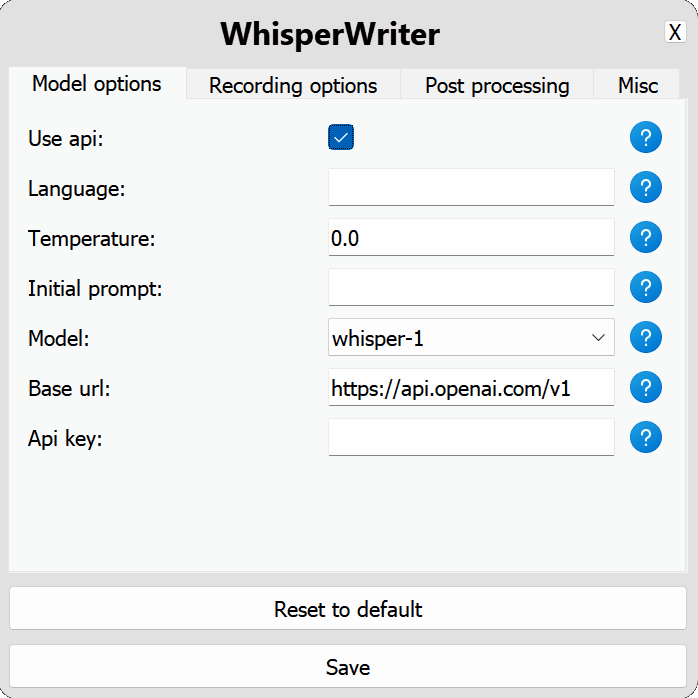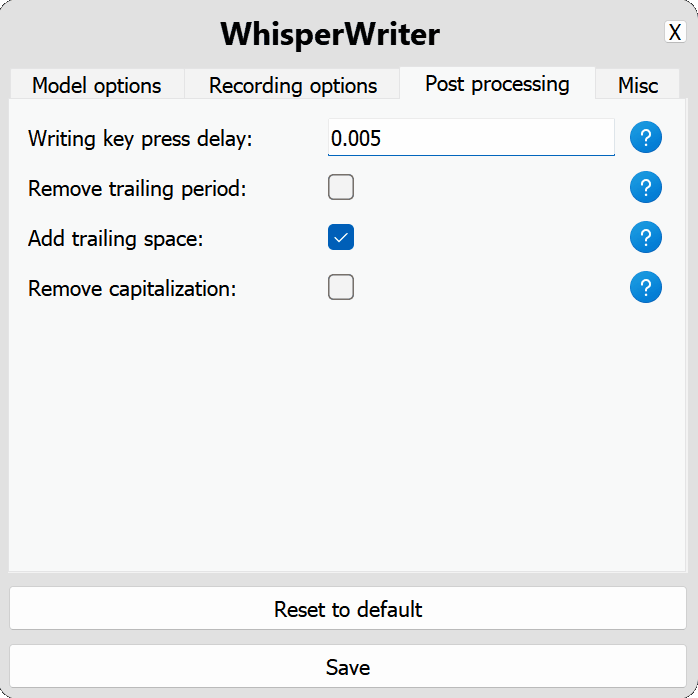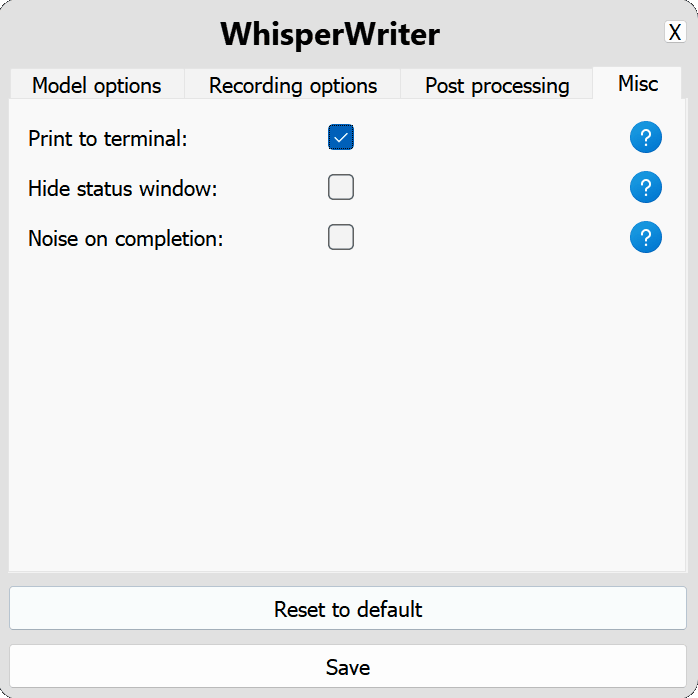
use_api : สลับเพื่อเลือกว่าจะใช้ OpenAI API หรือโมเดล Whisper ท้องถิ่นสำหรับการถอดความ (ค่าเริ่มต้น: false )
common : ตัวเลือกทั่วไปสำหรับทั้ง API และรุ่นท้องถิ่น
language : รหัสภาษาสำหรับการถอดความในรูปแบบ ISO-639-1 (ค่าเริ่มต้น: null )temperature : ควบคุมการสุ่มของเอาต์พุตการถอดรหัส ค่าที่ต่ำกว่าทำให้เอาต์พุตมุ่งเน้นและกำหนดขึ้นมากขึ้น (ค่าเริ่มต้น: 0.0 )initial_prompt : สตริงที่ใช้เป็นพรอมต์เริ่มต้นเพื่อกำหนดเงื่อนไขการถอดความ ข้อมูลเพิ่มเติม: คู่มือการแจ้งเตือน OpenAI (ค่าเริ่มต้น: null ) api : ตัวเลือกการกำหนดค่าสำหรับ OpenAI API ดูเอกสาร OpenAI API สำหรับข้อมูลเพิ่มเติม
model : โมเดลที่ใช้สำหรับการถอดความ ปัจจุบันมีเพียง whisper-1 เท่านั้น (ค่าเริ่มต้น: whisper-1 )base_url : URL พื้นฐานสำหรับ API สามารถเปลี่ยนเพื่อใช้จุดสิ้นสุด API ในพื้นที่เช่น Localai (ค่าเริ่มต้น: https://api.openai.com/v1 )api_key : คีย์ API ของคุณสำหรับ OpenAI API จำเป็นสำหรับการใช้ API ที่ไม่ใช่ท้องถิ่น (ค่าเริ่มต้น: null ) local : ตัวเลือกการกำหนดค่าสำหรับรุ่น Whisper ท้องถิ่น
model : โมเดลที่ใช้สำหรับการถอดความ รุ่นที่ใหญ่กว่าให้ความแม่นยำที่ดีขึ้น แต่ช้าลง ดูรุ่นและภาษาที่มีอยู่ (ค่าเริ่มต้น: base )device : อุปกรณ์สำหรับใช้งานรุ่น Whisper Local Local ใช้ cuda สำหรับ NVIDIA GPU, cpu สำหรับการประมวลผล CPU เท่านั้นหรือ auto เพื่อให้ระบบเลือกอุปกรณ์ที่ดีที่สุดโดยอัตโนมัติ (ค่าเริ่มต้น: auto )compute_type : ประเภทการคำนวณที่จะใช้สำหรับโมเดล Whisper ท้องถิ่น ข้อมูลเพิ่มเติมเกี่ยวกับการหาปริมาณที่นี่ (ค่าเริ่มต้น: default )condition_on_previous_text : ตั้งค่าเป็น true เพื่อใช้ข้อความที่ถอดความก่อนหน้านี้เป็นพรอมต์สำหรับคำขอการถอดความถัดไป (ค่าเริ่มต้น: true )vad_filter : ตั้งค่าเป็น true เพื่อใช้ตัวกรองการตรวจจับกิจกรรมเสียง (VAD) เพื่อลบความเงียบออกจากการบันทึก (ค่าเริ่มต้น: false )model_path : เส้นทางไปยังโมเดล Whisper ท้องถิ่น หากไม่ได้ระบุโมเดลเริ่มต้นจะถูกดาวน์โหลด (ค่าเริ่มต้น: null ) activation_key : แป้นพิมพ์ลัดเพื่อเปิดใช้งานกระบวนการบันทึกและถอดความ แยกปุ่มด้วย A + (ค่าเริ่มต้น: ctrl+shift+space )input_backend : แบ็กเอนด์อินพุตที่จะใช้สำหรับการตรวจจับการกดปุ่ม auto จะพยายามใช้แบ็กเอนด์ที่ดีที่สุด (ค่าเริ่มต้น: auto )recording_mode : โหมดการบันทึกที่จะใช้ ตัวเลือกรวมถึงการบันทึก continuous (การบันทึกเรสตาร์ตอัตโนมัติหลังจากหยุดชั่วคราวในการพูดจนกว่าจะกดปุ่มเปิดใช้งานอีกครั้ง), voice_activity_detection (หยุดการบันทึกหลังจากหยุดชั่วคราวในคำพูด), press_to_toggle (หยุดการบันทึกเมื่อกดปุ่มเปิดใช้งานอีกครั้ง), hold_to_record (ค่าเริ่มต้น: continuous )sound_device : ดัชนีตัวเลขของอุปกรณ์เสียงที่จะใช้สำหรับการบันทึก หากต้องการค้นหาหมายเลขอุปกรณ์ให้เรียกใช้ python -m sounddevice (ค่าเริ่มต้น: null )sample_rate : อัตราตัวอย่างใน Hz เพื่อใช้สำหรับการบันทึก (ค่าเริ่มต้น: 16000 )silence_duration : ระยะเวลาเป็นมิลลิวินาทีเพื่อรอความเงียบก่อนที่จะหยุดการบันทึก (ค่าเริ่มต้น: 900 )min_duration : ระยะเวลาขั้นต่ำเป็นมิลลิวินาทีสำหรับการบันทึกที่จะดำเนินการ การบันทึกสั้นกว่านี้จะถูกยกเลิก (ค่าเริ่มต้น: 100 ) writing_key_press_delay : ความล่าช้าในวินาทีระหว่างการกดปุ่มแต่ละครั้งเมื่อเขียนข้อความที่ถอดความ (ค่าเริ่มต้น: 0.005 )remove_trailing_period : ตั้งค่าเป็น true เพื่อลบระยะเวลาต่อท้ายออกจากข้อความที่ถอดความ (ค่าเริ่มต้น: false )add_trailing_space : ตั้งค่าเป็น true เพื่อเพิ่มพื้นที่ไปยังส่วนท้ายของข้อความที่ถอดความ (ค่าเริ่มต้น: true )remove_capitalization : ตั้งค่าเป็น true เพื่อแปลงข้อความที่ถอดความเป็นตัวพิมพ์เล็ก (ค่าเริ่มต้น: false )input_method : วิธีการใช้สำหรับการจำลองอินพุตแป้นพิมพ์ (ค่าเริ่มต้น: pynput ) print_to_terminal : ตั้งค่าเป็น true เพื่อพิมพ์สถานะสคริปต์และถอดความข้อความไปยังเทอร์มินัล (ค่าเริ่มต้น: true )hide_status_window : ตั้งค่าเป็น true เพื่อซ่อนหน้าต่างสถานะระหว่างการทำงาน (ค่าเริ่มต้น: false )noise_on_completion : ตั้งค่าเป็น true เพื่อเล่นเสียงรบกวนหลังจากพิมพ์การถอดความ (ค่าเริ่มต้น: false )หากตัวเลือกการกำหนดค่าใด ๆ ไม่ถูกต้องหรือไม่ได้ให้โปรแกรมจะใช้ค่าเริ่มต้น
คุณสามารถดูปัญหาที่รายงานทั้งหมดและสถานะปัจจุบันของพวกเขาในตัวติดตามปัญหาของเรา หากคุณพบปัญหาโปรดเปิดปัญหาใหม่พร้อมคำอธิบายโดยละเอียดและขั้นตอนการทำซ้ำถ้าเป็นไปได้
ด้านล่างนี้เป็นคุณสมบัติที่ฉันวางแผนจะเพิ่มในอนาคตอันใกล้:
ด้านล่างนี้เป็นคุณสมบัติที่ไม่ได้วางแผนไว้ในปัจจุบัน:
คุณสมบัติที่นำไปใช้สามารถพบได้ในการเปลี่ยนแปลง
ยินดีต้อนรับผลงาน! ฉันสร้างโครงการนี้เพื่อการใช้งานส่วนตัวของฉันเองและไม่ได้คาดหวังว่าจะได้รับความสนใจมากนักดังนั้นฉันจึงไม่ได้พยายามทดสอบหรือทำให้ผู้อื่นมีส่วนร่วมได้ง่าย หากคุณมีแนวคิดหรือข้อเสนอแนะอย่าลังเลที่จะเปิดคำขอดึงหรือสร้างปัญหาใหม่ ฉันจะพยายามอย่างเต็มที่เพื่อตรวจสอบและตอบกลับตามเวลาที่อนุญาต
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาตสาธารณะ GNU ทั่วไป ดูไฟล์ใบอนุญาตสำหรับรายละเอียด


