whisper writer
v1.0.1
ATUALIZAÇÃO (2024-05-28): Acabei de me fundir em uma grande reescrita do WhisperWriter! Migramos de usar tkinter para usar PyQt5 para a interface do usuário, adicionamos uma nova janela de configurações para configuração, um novo modo de gravação contínuo, suporte para uma API local e muito mais! Por favor, seja paciente enquanto eu resolveu quaisquer bugs que possam ter sido introduzidos no processo. Se você encontrar algum problema, abra um novo problema!
O WhisperWriter é um pequeno aplicativo de fala para texto que usa o modelo Whisper do OpenAI para transcrever automaticamente gravações do microfone de um usuário para a janela ativa.
Uma vez iniciado, o script é executado em segundo plano e aguarda o atalho de teclado a ser pressionado ( ctrl+shift+space por padrão). Quando o atalho é pressionado, o aplicativo começa a gravar no seu microfone. Existem quatro modos de gravação para escolher:
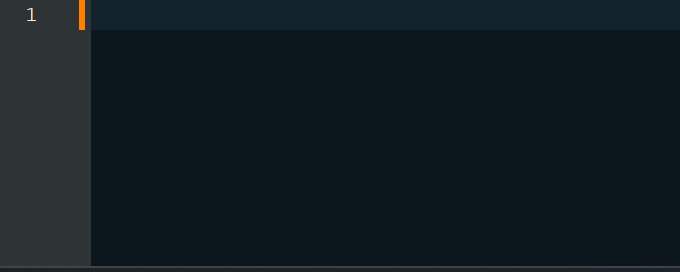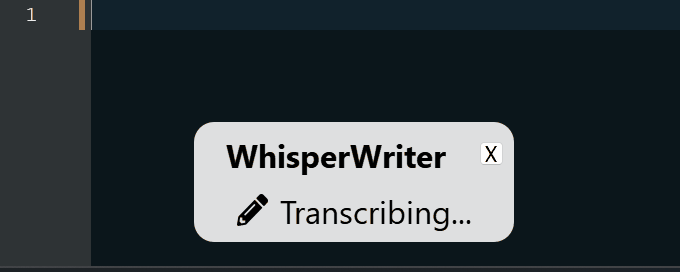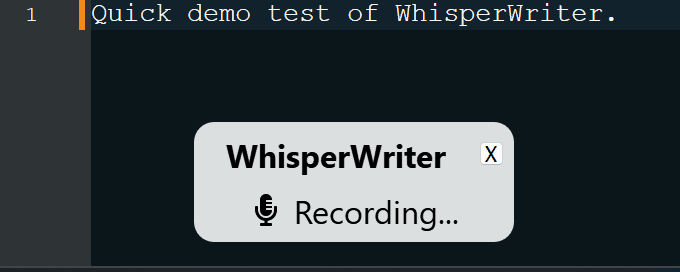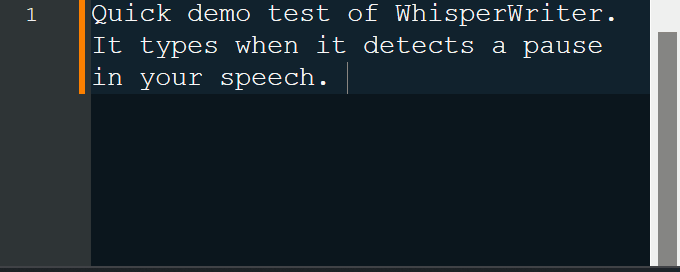
continuous (padrão): a gravação parará após uma pausa longa o suficiente em seu discurso. O aplicativo transcreverá o texto e começará a gravar novamente. Para parar de ouvir, pressione o atalho do teclado novamente.voice_activity_detection : A gravação parará após uma pausa longa em seu discurso. A gravação não começará até que o atalho do teclado seja pressionado novamente.press_to_toggle A gravação será interrompida quando o atalho do teclado for pressionado novamente. A gravação não começará até que o atalho do teclado seja pressionado novamente.hold_to_record A gravação continuará até que o atalho do teclado seja lançado. A gravação não começará até que o atalho do teclado seja retido novamente. Você pode alterar o atalho do teclado ( activation_key ) e o modo de gravação nas opções de configuração. Ao gravar e transcrever, é exibida uma pequena janela de status que mostra o estágio atual do processo (mas isso pode ser desligado). Após a conclusão da transcrição, o texto transcrito será gravado automaticamente na janela ativa.
A transcrição pode ser feita localmente através do pacote Python mais rápido ou por meio de uma solicitação à API do OpenAI. Por padrão, o aplicativo usará um modelo local, mas você pode alterar isso nas opções de configuração. Se você optar por usar a API, precisará fornecer sua chave da API OpenAI ou alterar o ponto final da URL base.
Curiosidade: quase a totalidade do lançamento inicial do projeto foi programado em pares com o ChatGPT-4 e o GitHub Copilot usando o código VS. Praticamente todas as linhas, incluindo a maior parte deste Readme, foram escritas pela IA. Depois que o protótipo inicial foi concluído, o WhisperWriter foi usado para escrever muitos dos prompts também!
Antes de executar este aplicativo, você precisará instalar o seguinte software:
3.11 : https://www.python.org/downloads/ Se você quiser correr faster-whisper na sua GPU, também precisará instalar as seguintes bibliotecas da NVIDIA:
O abaixo foi retirado diretamente do readme faster-whisper :
Nota: As versões mais recentes do ctranslate2 suportam apenas o CUDA 12. Para o CUDA 11, a solução alternativa atual está rebaixando para a versão 3.24.0 do ctranslate2 (isso pode ser feito com pip install --force-reinsall ctranslate2==3.24.0 ).
Existem várias maneiras de instalar as bibliotecas da NVIDIA mencionadas acima. A maneira recomendada é descrita na documentação oficial da NVIDIA, mas também sugerimos outros métodos de instalação abaixo.
As bibliotecas (Cublas, CUDNN) são instaladas nessas imagens oficiais do Nvidia Cuda Docker: nvidia/cuda:12.0.0-runtime-ubuntu20.04 ou nvidia/cuda:12.0.0-runtime-ubuntu22.04 .
pip (somente Linux) No Linux, essas bibliotecas podem ser instaladas com pip . Observe que LD_LIBRARY_PATH deve ser definido antes de iniciar o Python.
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
export LD_LIBRARY_PATH= ` python3 -c ' import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__)) ' ` NOTA : A versão 9+ do nvidia-cudnn-cu12 parece causar problemas devido à sua dependência do CUDNN 9 (mais rápido não suporta o CUDNN 9). Verifique se a sua versão do pacote Python é para CUDNN 8.
O Whisper-Standalone-Win da Purfview fornece as bibliotecas NVIDIA necessárias para Windows & Linux em um único arquivo. Descomprimir o arquivo e coloque as bibliotecas em um diretório incluído no PATH .
Para configurar e executar o projeto, siga estas etapas:
git clone https://github.com/savbell/whisper-writer
cd whisper-writer
python -m venv venv
# For Linux and macOS:
source venv/bin/activate
# For Windows:
venvScriptsactivate
pip install -r requirements.txt
python run.py
Na primeira execução, uma janela de configurações deve aparecer. Uma vez configurado e salvo, outra janela será aberta. Pressione "Start" para ativar o ouvinte do teclado. Pressione a tecla de ativação ( ctrl+shift+space por padrão) para começar a gravar e transcrever para a janela ativa.
O WhisperWriter usa um arquivo de configuração para personalizar seu comportamento. Para configurar a configuração, abra a janela Configurações:
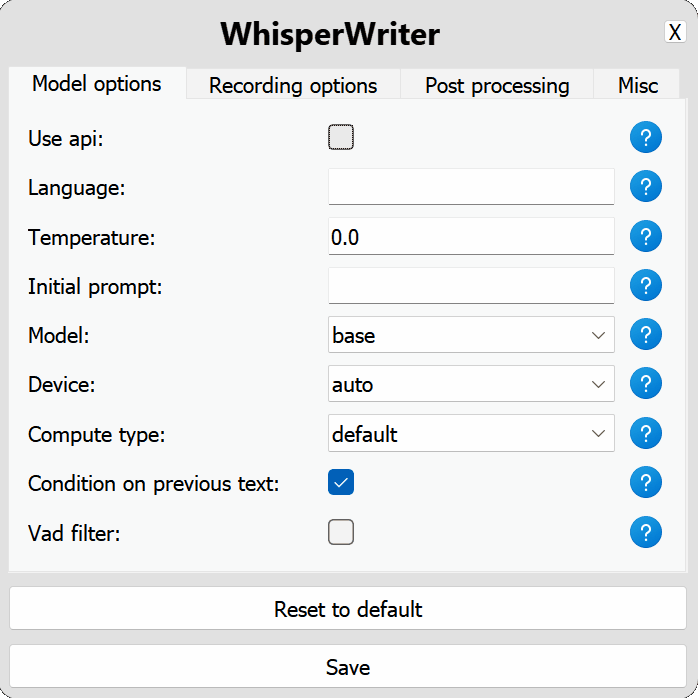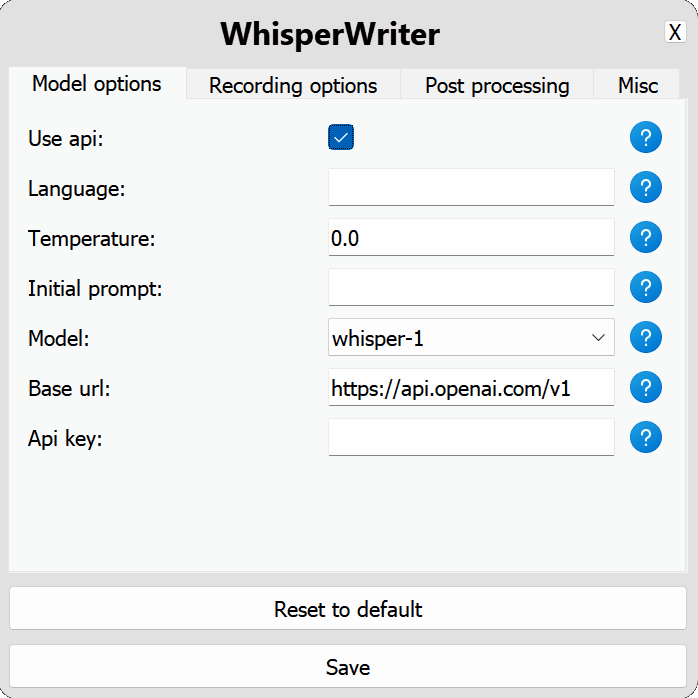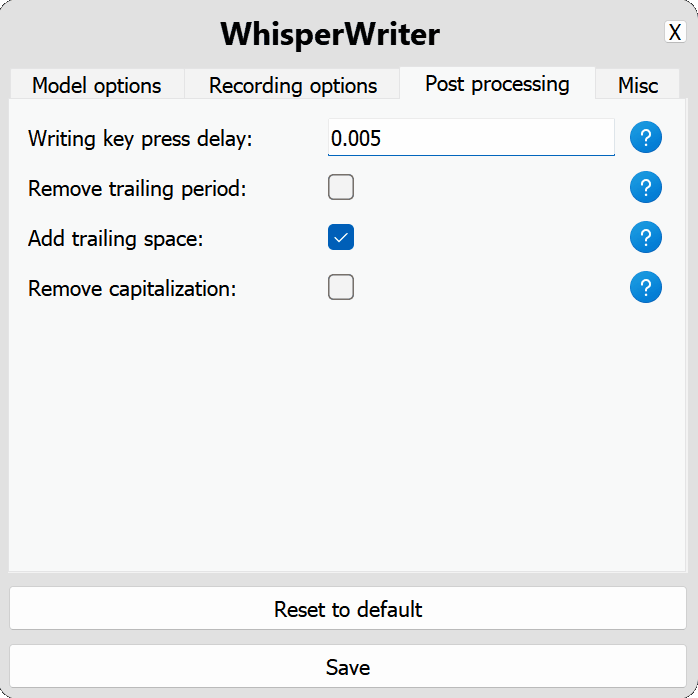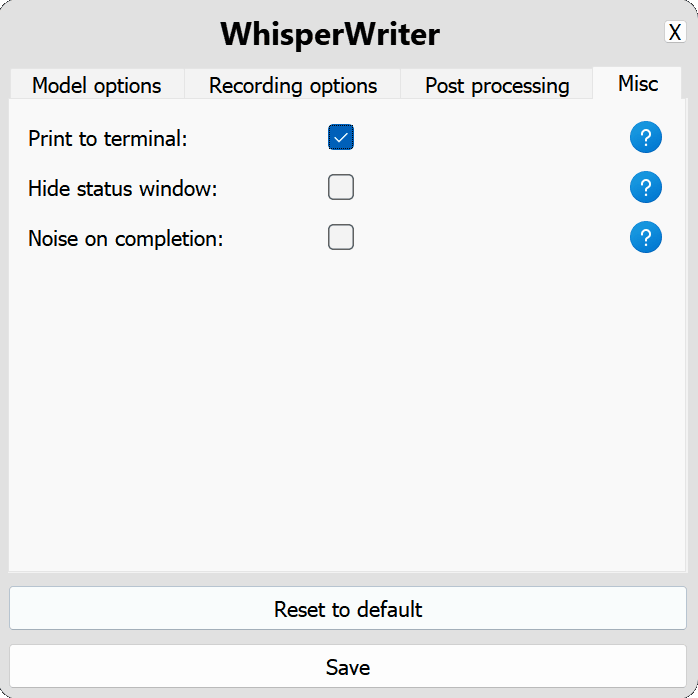
use_api : alternar para escolher se deseja usar a API OpenAI ou um modelo de sussurro local para transcrição. (Padrão: false )
common : Opções comuns tanto à API quanto aos modelos locais.
language : o código do idioma para a transcrição no formato ISO-639-1. (Padrão: null )temperature : controla a aleatoriedade da saída de transcrição. Os valores mais baixos tornam a saída mais focada e determinística. (Padrão: 0.0 )initial_prompt : uma string usada como um prompt inicial para condicionar a transcrição. Mais informações: OpenAI de guia de provas. (Padrão: null ) api : Opções de configuração para a API do OpenAI. Consulte a documentação da API do OpenAI para obter mais informações.
model : o modelo a ser usado para transcrição. Atualmente, apenas whisper-1 está disponível. (Padrão: whisper-1 )base_url : o URL base para a API. Pode ser alterado para usar um endpoint local da API, como o localai. (Padrão: https://api.openai.com/v1 )api_key : Sua chave da API para a API do OpenAI. Necessário para o uso não local da API. (Padrão: null ) local : Opções de configuração para o modelo Whisper local.
model : o modelo a ser usado para transcrição. Os modelos maiores oferecem melhor precisão, mas são mais lentos. Veja modelos e idiomas disponíveis. (Padrão: base )device : o dispositivo para executar o modelo de sussurro local. Use cuda para NVIDIA GPUs, cpu para processamento somente CPU ou auto para permitir que o sistema escolha automaticamente o melhor dispositivo disponível. (Padrão: auto )compute_type : o tipo de computação a ser usado para o modelo de sussurro local. Mais informações sobre quantização aqui. (Padrão: default )condition_on_previous_text : defina como true para usar o texto transcrito anteriormente como um prompt para a próxima solicitação de transcrição. (Padrão: true )vad_filter : defina como true para usar um filtro de detecção de atividade de voz (VAD) para remover o silêncio da gravação. (Padrão: false )model_path : o caminho para o modelo de sussurro local. Se não for especificado, o modelo padrão será baixado. (Padrão: null ) activation_key : o atalho do teclado para ativar o processo de gravação e transcrição. Chaves separadas com A + . (Padrão: ctrl+shift+space )input_backend : o back -end de entrada a ser usado para detectar pressionamentos de teclas. auto tentará usar o melhor back -end disponível. (Padrão: auto )recording_mode : o modo de gravação a ser usado. As opções incluem continuous (gravação automática-restauração após pausa na fala até que a tecla de ativação seja pressionada novamente), voice_activity_detection (pare de gravar após pausa no discurso), press_to_toggle (pare de gravar quando a tecla de ativação é pressionada novamente), hold_to_record (registro de parada quando a tecla de ativação é lançada). (Padrão: continuous )sound_device : o índice numérico do dispositivo de som a ser usado para gravar. Para encontrar números de dispositivos, execute python -m sounddevice . (Padrão: null )sample_rate : a taxa de amostragem em Hz a ser usada para gravação. (Padrão: 16000 )silence_duration : a duração em milissegundos para aguardar o silêncio antes de interromper a gravação. (Padrão: 900 )min_duration : a duração mínima em milissegundos para uma gravação a ser processada. Gravações mais curtas do que isso serão descartadas. (Padrão: 100 ) writing_key_press_delay : o atraso em segundos entre cada tecla Pressione ao gravar o texto transcrito. (Padrão: 0.005 )remove_trailing_period : Defina como true para remover o período de direita do texto transcrito. (Padrão: false )add_trailing_space : defina como true para adicionar um espaço ao final do texto transcrito. (Padrão: true )remove_capitalization : defina como true para converter o texto transcrito em minúsculas. (Padrão: false )input_method : o método a ser usado para simular a entrada do teclado. (Padrão: pynput ) print_to_terminal : defina como true para imprimir o status do script e o texto transcrito para o terminal. (Padrão: true )hide_status_window : defina como true para ocultar a janela de status durante a operação. (Padrão: false )noise_on_completion : defina como true para reproduzir um ruído após a transcrição ter sido digitada. (Padrão: false )Se alguma das opções de configuração for inválida ou não é fornecida, o programa usará os valores padrão.
Você pode ver todos os problemas relatados e seu status atual em nosso rastreador de problemas. Se você encontrar um problema, abra um novo problema com uma descrição detalhada e etapas de reprodução, se possível.
Abaixo estão os recursos que estou planejando adicionar no futuro próximo:
Abaixo estão os recursos não planejados: atualmente:
Recursos implementados podem ser encontrados no Changelog.
As contribuições são bem -vindas! Criei este projeto para meu próprio uso pessoal e não esperava que ele recebesse muita atenção, por isso não coloquei muito esforço para testar ou facilitar a contribuição de outras pessoas. Se você tiver idéias ou sugestões, sinta -se à vontade para abrir uma solicitação de tração ou criar um novo problema. Farei o meu melhor para revisar e responder conforme o tempo permitir.
Este projeto está licenciado sob a licença pública geral da GNU. Consulte o arquivo de licença para obter detalhes.


