whisper writer
v1.0.1
更新(2024-05-28): Whisperwriterの主要な書き直しに合併しました! tkinterの使用からUIにPyQt5の使用に移行し、構成用の新しい設定ウィンドウ、新しい連続記録モード、ローカルAPIのサポートなどを追加しました!その過程で導入された可能性のあるバグを解決するので、我慢してください。問題が発生した場合は、新しい問題を開いてください!
Whisperwriterは、OpenaiのWhisperモデルを使用して、ユーザーのマイクからアクティブウィンドウまで録音を自動転写する小さなスピーチツーテキストアプリです。
開始すると、スクリプトはバックグラウンドで実行され、キーボードショートカットが押されるのを待ちます(デフォルトではctrl+shift+space )。ショートカットが押されると、アプリはマイクから録音を開始します。次の4つの録音モードがあります。
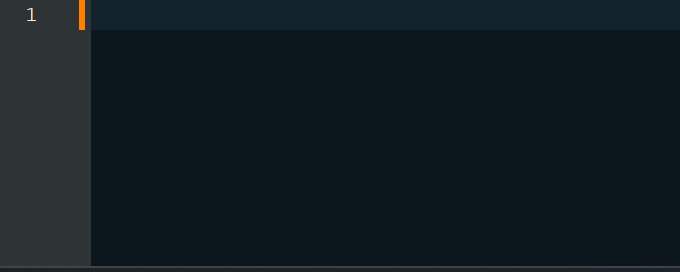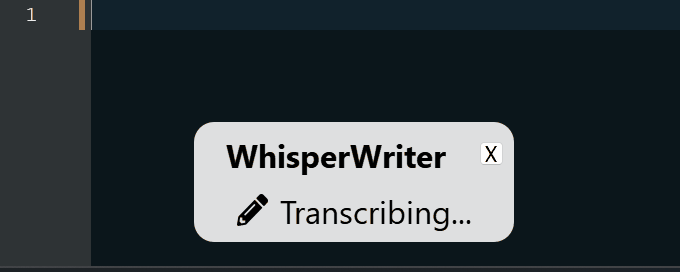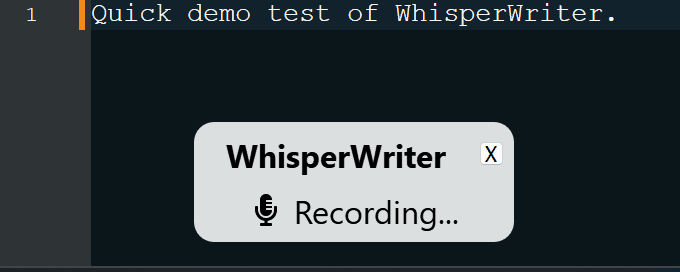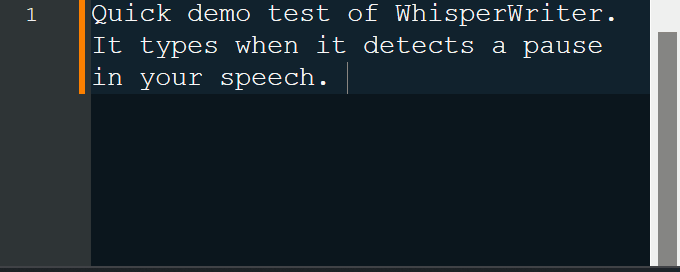
continuous (デフォルト):録音は、あなたのスピーチで十分な長い一時停止の後に停止します。アプリはテキストを転写し、再度録画を開始します。リスニングを停止するには、キーボードショートカットをもう一度押します。voice_activity_detection :録音は、スピーチで十分な一時停止の後に停止します。キーボードショートカットが再び押されるまで、録音は開始されません。press_to_toggle録音が停止します。キーボードショートカットが再び押されるまで、録音は開始されません。hold_to_record録音は、キーボードショートカットがリリースされるまで続きます。録音は、キーボードショートカットが再び保持されるまで開始されません。構成オプションでキーボードショートカット( activation_key )と記録モードを変更できます。記録と転写中に、プロセスの現在の段階を示す小さなステータスウィンドウが表示されます(ただし、これはオフにできます)。転写が完了すると、転写されたテキストがアクティブウィンドウに自動的に書き込まれます。
転写は、より速いウィスパーPythonパッケージを介して、またはOpenaiのAPIへのリクエストを通じてローカルに行うことができます。デフォルトでは、アプリはローカルモデルを使用しますが、これを構成オプションで変更できます。 APIを使用することを選択した場合、OpenAI APIキーを提供するか、ベースURLエンドポイントを変更する必要があります。
楽しい事実:プロジェクトの最初のリリースのほぼ全体が、VSコードを使用してChatGPT-4およびGitHub Copilotでペアプログラムされました。このReadMeのほとんどを含む実際には、すべての行がAIによって書かれました。最初のプロトタイプが終了した後、Whisperwriterも使用され、多くのプロンプトを書きました!
このアプリを実行する前に、次のソフトウェアをインストールする必要があります。
3.11 :https://www.python.org/downloads/ GPUでfaster-whisperを実行したい場合は、次のNVIDIAライブラリをインストールする必要があります。
以下はfaster-whisper READMEから直接取られました。
注: ctranslate2の最新バージョンはCUDA 12のみをサポートしています。 CUDA 11の場合、現在の回避策はctranslate2の3.24.0バージョンに格下げされています(これはpip install --force-reinsall ctranslate2==3.24.0で実行できます)。
上記のNVIDIAライブラリをインストールする方法は複数あります。推奨される方法は、公式のNVIDIAドキュメントで説明されていますが、以下の他のインストール方法もお勧めします。
図書館(Cublas、Cudnn)は、これらの公式Nvidia Cuda Docker画像にインストールされています。Nvidia nvidia/cuda:12.0.0-runtime-ubuntu20.04またはnvidia/cuda:12.0.0-runtime-ubuntu22.04 。
pip (Linuxのみ)でインストールするLinuxでは、これらのライブラリはpipでインストールできます。 Pythonを起動する前に、 LD_LIBRARY_PATHを設定する必要があることに注意してください。
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
export LD_LIBRARY_PATH= ` python3 -c ' import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__)) ' `注: nvidia-cudnn-cu12のバージョン9+は、Cudnn 9に依存しているために問題を引き起こしているように見えます(より速いウィスパーは現在Cudnn 9をサポートしていません)。 PythonパッケージのバージョンがCudnn 8用であることを確認してください。
PurfviewのWhisper-Standalone-Winは、単一のアーカイブでWindows&Linuxに必要なNVIDIAライブラリを提供します。アーカイブを解凍し、ライブラリをPATHに含まれるディレクトリに配置します。
プロジェクトをセットアップして実行するには、次の手順に従ってください。
git clone https://github.com/savbell/whisper-writer
cd whisper-writer
python -m venv venv
# For Linux and macOS:
source venv/bin/activate
# For Windows:
venvScriptsactivate
pip install -r requirements.txt
python run.py
最初の実行では、設定ウィンドウが表示されます。構成して保存すると、別のウィンドウが開きます。 「開始」を押して、キーボードリスナーをアクティブにします。アクティベーションキー( ctrl+shift+space )を押して、アクティブウィンドウの記録と転写を開始します。
Whisperwriterは、構成ファイルを使用して動作をカスタマイズします。構成を設定するには、[設定]ウィンドウを開きます。
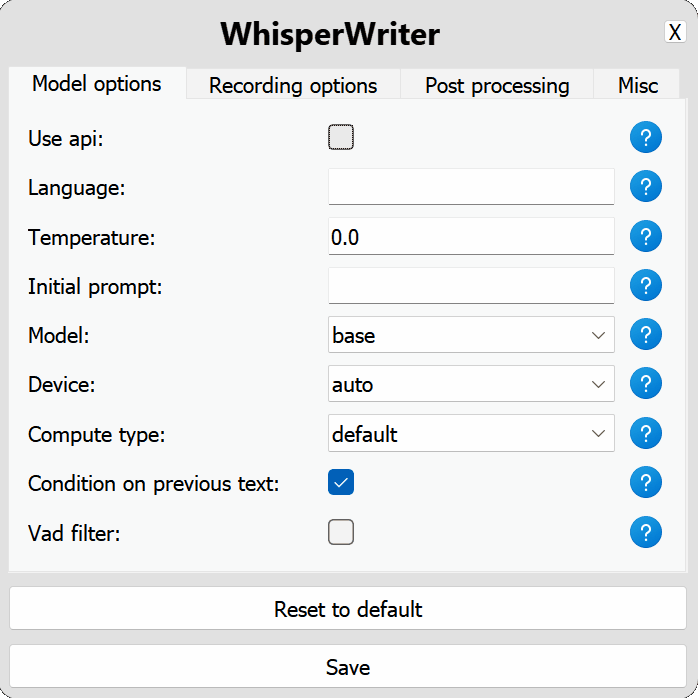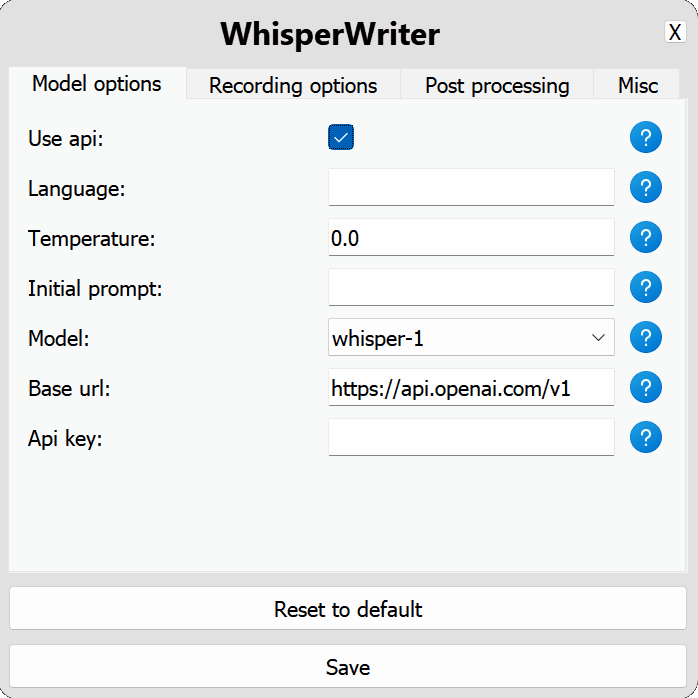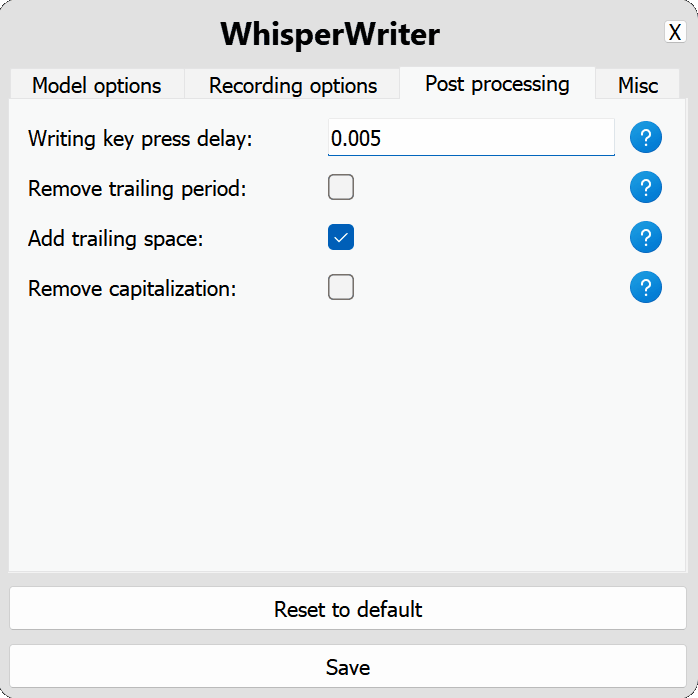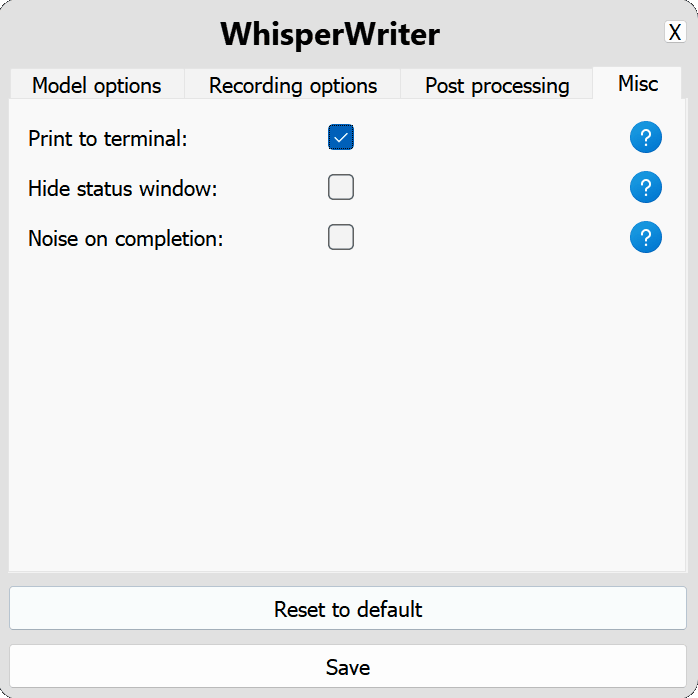
use_api :トグルOpenai APIを使用するか、転写にローカルウィスパーモデルを使用するかを選択します。 (デフォルト: false )
common :APIモデルとローカルモデルの両方に共通するオプション。
language :ISO-639-1形式の転写の言語コード。 (デフォルト: null )temperature :転写出力のランダム性を制御します。値が低いと、出力がより集中し、決定論的になります。 (デフォルト: 0.0 )initial_prompt :転写を条件付けるために初期プロンプトとして使用される文字列。詳細:Openaiプロンプトガイド。 (デフォルト: null ) api :Openai APIの構成オプション。詳細については、Openai APIドキュメントを参照してください。
model :転写に使用するモデル。現在、 whisper-1のみが利用可能です。 (デフォルト: whisper-1 )base_url :APIのベースURL。ローカライなどのローカルAPIエンドポイントを使用するように変更できます。 (デフォルト: https://api.openai.com/v1 )api_key :OpenAI APIのAPIキー。非ローカルAPI使用に必要です。 (デフォルト: null ) local :ローカルウィスパーモデルの構成オプション。
model :転写に使用するモデル。より大きなモデルはより良い精度を提供しますが、遅いです。利用可能なモデルと言語を参照してください。 (デフォルト: base )device :ローカルウィスパーモデルをオンにするデバイス。 NVIDIA GPUにはcuda使用し、CPUのみの処理にはcpu 、またはシステムがauto利用可能なデバイスを自動的に選択できるようにします。 (デフォルト: auto )compute_type :ローカルウィスパーモデルに使用する計算タイプ。量子化の詳細については、こちら。 (デフォルト: default )condition_on_previous_text :以前に転写されたテキストを次の転写リクエストのプロンプトとして使用するtrueに設定します。 (デフォルト: true )vad_filter :音声アクティビティ検出(VAD)フィルターを使用するようにtrueに設定して、録音から沈黙を削除します。 (デフォルト: false )model_path :ローカルウィスパーモデルへのパス。指定されていない場合、デフォルトモデルはダウンロードされます。 (デフォルト: null ) activation_key :録音と転写プロセスをアクティブにするキーボードショートカット。 A +でキーを分離します。 (デフォルト: ctrl+shift+space )input_backend :キープレスの検出に使用する入力バックエンド。 auto 、利用可能な最高のバックエンドを使用しようとします。 (デフォルト: auto )recording_mode :使用する録音モード。オプションには、 continuous (アクティベーションキーが再び押されるまで音声で一時停止した後のオートリスターアート記録)、 voice_activity_detection (音声で一時停止後に記録を停止)、 press_to_toggle (アクティベーションキーが再び押されたときに録音を停止)、 hold_to_record (アクティベーションキーが解放されたときに録音を停止) (デフォルト: continuous )sound_device :録音に使用するサウンドデバイスの数値インデックス。デバイス番号を見つけるには、 python -m sounddeviceを実行します。 (デフォルト: null )sample_rate :録音に使用するHzのサンプルレート。 (デフォルト: 16000 )silence_duration :録音を停止する前に沈黙を待つミリ秒単位の期間。 (デフォルト: 900 )min_duration :記録を処理するためのミリ秒単位での最小期間。これより短い録音は破棄されます。 (デフォルト: 100 ) writing_key_press_delay :転写されたテキストを書くときに各キーを押す間の数秒の遅延。 (デフォルト: 0.005 )remove_trailing_period : trueに設定して、転写されたテキストからトレーリング期間を削除します。 (デフォルト: false )add_trailing_space : trueに設定して、転写されたテキストの最後にスペースを追加します。 (デフォルト: true )remove_capitalization : trueに設定して、転写されたテキストを小文字に変換します。 (デフォルト: false )input_method :キーボード入力のシミュレーションに使用する方法。 (デフォルト: pynput ) print_to_terminal :スクリプトステータスと転写されたテキストをターミナルに印刷するようにtrueに設定します。 (デフォルト: true )hide_status_window :操作中にステータスウィンドウをtrue表示にするように設定します。 (デフォルト: false )noise_on_completion :転写が入力された後、ノイズを再生するようにtrueに設定します。 (デフォルト: false )構成オプションのいずれかが無効であるか、提供されていない場合、プログラムはデフォルト値を使用します。
私たちの問題トラッカーで報告されたすべての問題とその現在のステータスを見ることができます。問題が発生した場合は、可能であれば、詳細な説明と複製手順を備えた新しい問題を開きます。
以下は、近い将来に追加する予定の機能です。
以下は、現在計画されていない機能です。
実装された機能は、Changelogにあります。
貢献は大歓迎です!私は自分の個人的な使用のためにこのプロジェクトを作成しましたが、それがあまり注目されるとは思っていなかったので、他の人が貢献しやすいテストやそれを簡単にすることにあまり労力を費やしていません。アイデアや提案がある場合は、プルリクエストを開いたり、新しい問題を作成したりしてください。時間が許す限り、レビューして応答するために最善を尽くします。
このプロジェクトは、GNU General Publicライセンスの下でライセンスされています。詳細については、ライセンスファイルを参照してください。


