whisper writer
v1.0.1
UPDATE (2024-05-28): Saya baru saja bergabung dalam penulisan ulang utama Whisperwriter! Kami telah bermigrasi dari menggunakan tkinter untuk menggunakan PyQt5 untuk UI, menambahkan jendela pengaturan baru untuk konfigurasi, mode perekaman kontinu baru, dukungan untuk API lokal, dan banyak lagi! Harap bersabar saat saya mengerjakan bug apa pun yang mungkin telah diperkenalkan dalam prosesnya. Jika Anda mengalami masalah, buka masalah baru!
Whisperwriter adalah aplikasi ucapan-ke-teks kecil yang menggunakan model Whisper OpenAI untuk mentranskripsikan rekaman dari mikrofon pengguna ke jendela aktif.
Setelah dimulai, skrip berjalan di latar belakang dan menunggu pintasan keyboard ditekan ( ctrl+shift+space secara default). Saat jalan pintas ditekan, aplikasi mulai merekam dari mikrofon Anda. Ada empat mode perekaman untuk dipilih:
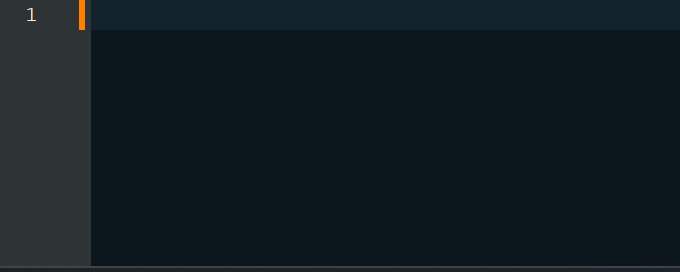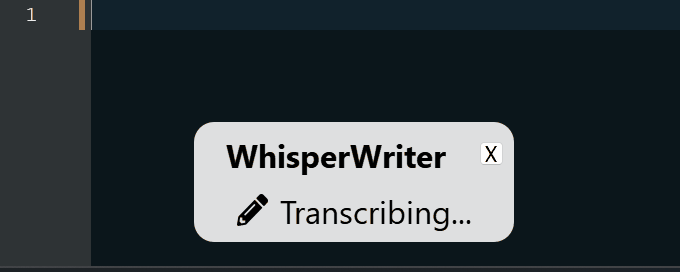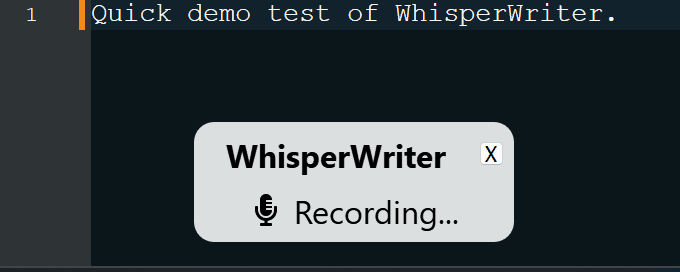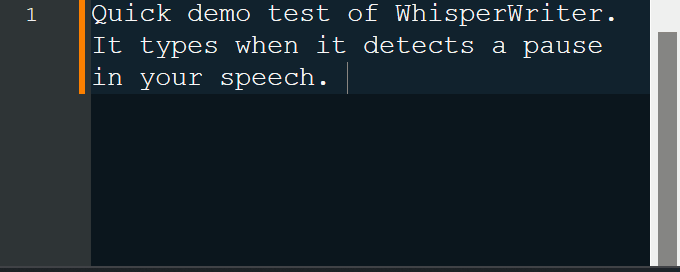
continuous (default): Rekaman akan berhenti setelah jeda yang cukup lama dalam pidato Anda. Aplikasi akan menuliskan teks dan kemudian mulai merekam lagi. Untuk berhenti mendengarkan, tekan pintasan keyboard lagi.voice_activity_detection : Rekaman akan berhenti setelah jeda yang cukup lama dalam pidato Anda. Rekaman tidak akan dimulai sampai pintasan keyboard ditekan lagi.press_to_toggle akan berhenti ketika pintasan keyboard ditekan lagi. Rekaman tidak akan dimulai sampai pintasan keyboard ditekan lagi.hold_to_record akan berlanjut hingga pintasan keyboard dirilis. Rekaman tidak akan dimulai sampai pintasan keyboard ditahan lagi. Anda dapat mengubah pintasan keyboard ( activation_key ) dan mode perekaman dalam opsi konfigurasi. Saat merekam dan menyalin, jendela status kecil ditampilkan yang menunjukkan tahap proses saat ini (tetapi ini dapat dimatikan). Setelah transkripsi selesai, teks yang ditranskripsikan akan ditulis secara otomatis ke jendela aktif.
Transkripsi dapat dilakukan secara lokal melalui paket Python yang lebih cepat atau melalui permintaan API Openai. Secara default, aplikasi akan menggunakan model lokal, tetapi Anda dapat mengubahnya di opsi konfigurasi. Jika Anda memilih untuk menggunakan API, Anda harus menyediakan kunci API OpenAI Anda atau mengubah titik akhir URL dasar.
Fakta menyenangkan: Hampir keseluruhan rilis awal proyek diprogram dengan chatgpt-4 dan github copilot menggunakan VS Code. Praktis setiap baris, termasuk sebagian besar readme ini, ditulis oleh AI. Setelah prototipe awal selesai, Whisperwriter digunakan untuk menulis banyak petunjuk juga!
Sebelum Anda dapat menjalankan aplikasi ini, Anda harus menginstal perangkat lunak berikut:
3.11 : https://www.python.org/downloads/ Jika Anda ingin menjalankan faster-whisper di GPU Anda, Anda juga harus menginstal perpustakaan NVIDIA berikut:
Di bawah ini diambil langsung dari readme faster-whisper :
Catatan: Versi terbaru dari ctranslate2 hanya mendukung CUDA 12. Untuk CUDA 11, solusi saat ini diturunkan ke versi 3.24.0 dari ctranslate2 (ini dapat dilakukan dengan pip install --force-reinsall ctranslate2==3.24.0 ).
Ada beberapa cara untuk menginstal pustaka NVIDIA yang disebutkan di atas. Cara yang disarankan dijelaskan dalam dokumentasi NVIDIA resmi, tetapi kami juga menyarankan metode instalasi lain di bawah ini.
Perpustakaan (Cublas, Cudnn) diinstal dalam gambar resmi Nvidia Cuda Docker resmi ini: nvidia/cuda:12.0.0-runtime-ubuntu20.04 atau nvidia/cuda:12.0.0-runtime-ubuntu22.04 .
pip (Linux saja) Di Linux perpustakaan ini dapat diinstal dengan pip . Perhatikan bahwa LD_LIBRARY_PATH harus ditetapkan sebelum meluncurkan python.
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
export LD_LIBRARY_PATH= ` python3 -c ' import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__)) ' ` Catatan : Versi 9+ dari nvidia-cudnn-cu12 tampaknya menyebabkan masalah karena ketergantungannya pada CUDNN 9 (lebih cepat-WHISPER saat ini tidak mendukung CUDNN 9). Pastikan versi paket Python Anda adalah untuk Cudnn 8.
Whisper-Standalone-Win dari Purfview menyediakan perpustakaan NVIDIA yang diperlukan untuk Windows & Linux dalam satu arsip. Mendekompres arsip dan menempatkan perpustakaan di direktori yang termasuk dalam PATH .
Untuk mengatur dan menjalankan proyek, ikuti langkah -langkah ini:
git clone https://github.com/savbell/whisper-writer
cd whisper-writer
python -m venv venv
# For Linux and macOS:
source venv/bin/activate
# For Windows:
venvScriptsactivate
pip install -r requirements.txt
python run.py
Pada lari pertama, jendela pengaturan akan muncul. Setelah dikonfigurasi dan disimpan, jendela lain akan terbuka. Tekan "Mulai" untuk mengaktifkan pendengar keyboard. Tekan tombol aktivasi ( ctrl+shift+space secara default) untuk mulai merekam dan menyalin ke jendela aktif.
Whisperwriter menggunakan file konfigurasi untuk menyesuaikan perilakunya. Untuk mengatur konfigurasi, buka jendela Pengaturan:
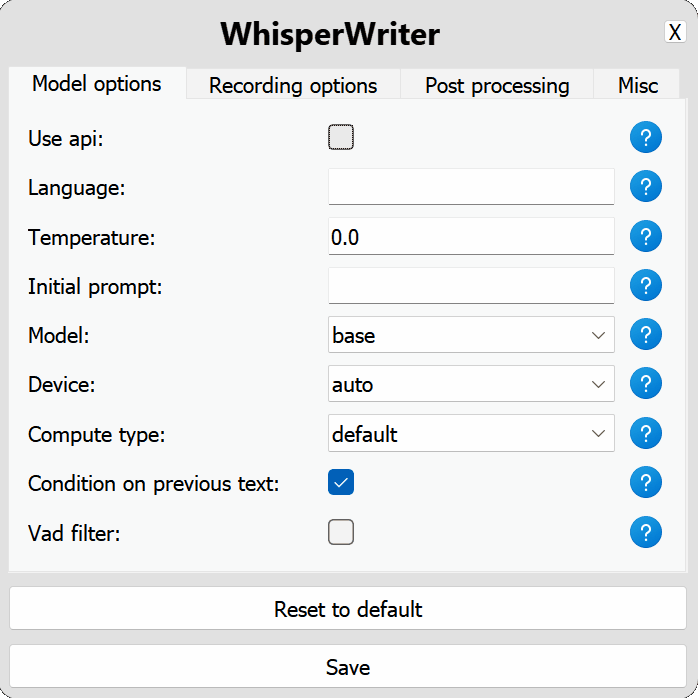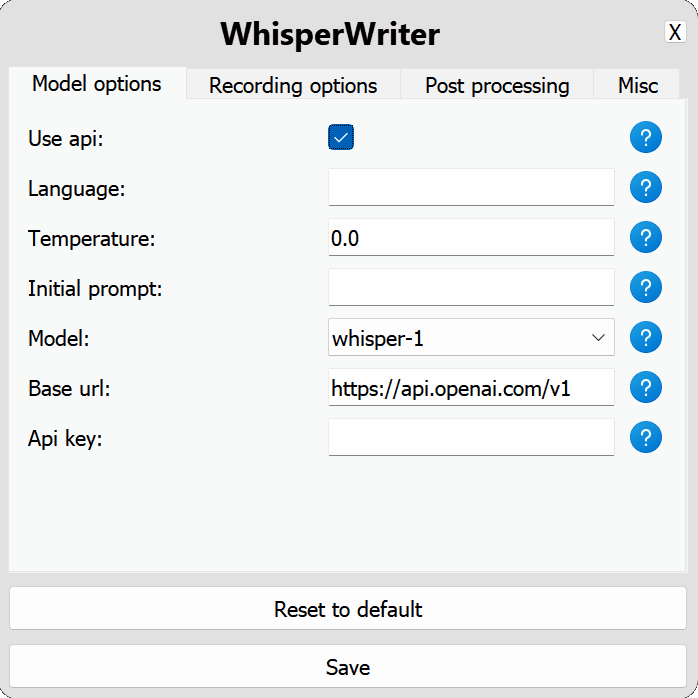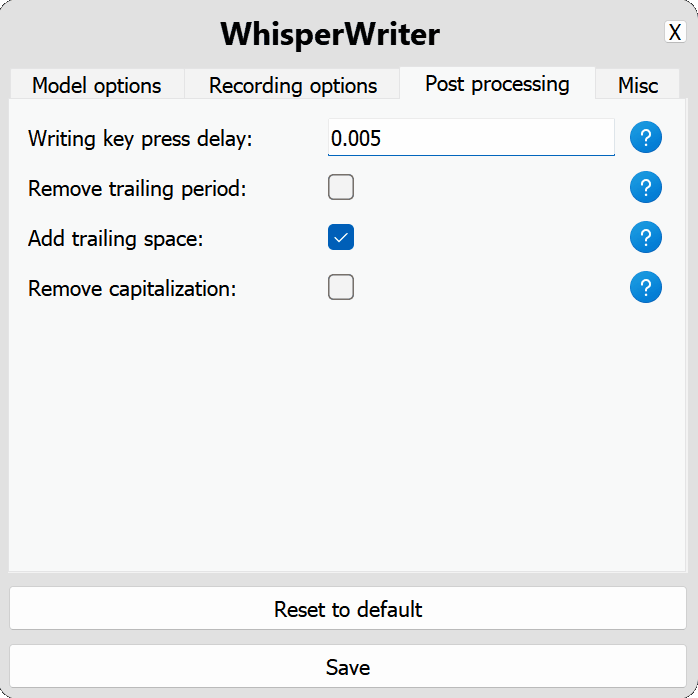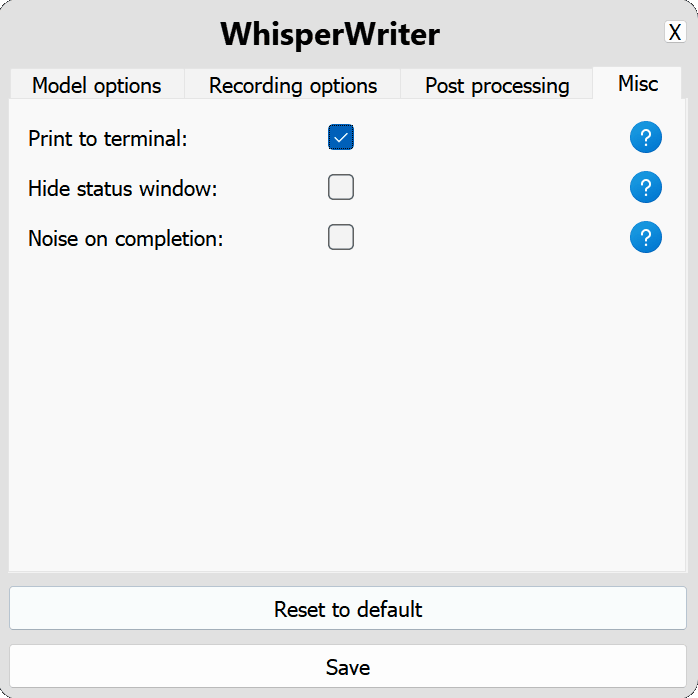
use_api : Toggle Untuk memilih apakah akan menggunakan API OpenAI atau model bisikan lokal untuk transkripsi. (Default: false )
common : Opsi umum untuk model API dan lokal.
language : Kode bahasa untuk transkripsi dalam format ISO-639-1. (Default: null )temperature : Mengontrol keacakan output transkripsi. Nilai yang lebih rendah membuat output lebih fokus dan deterministik. (Default: 0.0 )initial_prompt : String yang digunakan sebagai prompt awal untuk mengkondisikan transkripsi. Info lebih lanjut: Panduan Prompt Openai. (Default: null ) api : Opsi konfigurasi untuk API OpenAI. Lihat dokumentasi API OpenAI untuk informasi lebih lanjut.
model : Model yang akan digunakan untuk transkripsi. Saat ini, hanya whisper-1 yang tersedia. (Default: whisper-1 )base_url : URL dasar untuk API. Dapat diubah untuk menggunakan titik akhir API lokal, seperti localai. (Default: https://api.openai.com/v1 )api_key : Kunci API Anda untuk API OpenAI. Diperlukan untuk penggunaan API non-lokal. (Default: null ) local : Opsi konfigurasi untuk model bisikan lokal.
model : Model yang akan digunakan untuk transkripsi. Model yang lebih besar memberikan akurasi yang lebih baik tetapi lebih lambat. Lihat model dan bahasa yang tersedia. (Default: base )device : Perangkat untuk menjalankan model bisikan lokal. Gunakan cuda untuk NVIDIA GPU, cpu untuk pemrosesan khusus CPU, atau auto untuk membiarkan sistem secara otomatis memilih perangkat terbaik yang tersedia. (Default: auto )compute_type : Jenis komputasi yang akan digunakan untuk model bisikan lokal. Informasi lebih lanjut tentang kuantisasi di sini. (Default: default )condition_on_previous_text : Setel ke true untuk menggunakan teks yang sebelumnya ditranskripsi sebagai prompt untuk permintaan transkripsi berikutnya. (Default: true )vad_filter : Setel ke true untuk menggunakan filter Deteksi Aktivitas Suara (VAD) untuk menghilangkan keheningan dari rekaman. (Default: false )model_path : Jalan menuju model bisikan lokal. Jika tidak ditentukan, model default akan diunduh. (Default: null ) activation_key : Pintasan keyboard untuk mengaktifkan proses perekaman dan transkrip. Kunci terpisah dengan A + . (Default: ctrl+shift+space )input_backend : Backend input yang akan digunakan untuk mendeteksi tekan tombol. auto akan mencoba menggunakan backend terbaik yang tersedia. (Default: auto )recording_mode : Mode perekaman untuk digunakan. Opsi termasuk continuous (perekaman auto-restart setelah jeda dalam pidato sampai tombol aktivasi ditekan lagi), voice_activity_detection (berhenti merekam setelah jeda dalam pidato), press_to_toggle (berhenti merekam ketika tombol aktivasi ditekan lagi), hold_to_record (berhenti merekam ketika kunci aktivasi dirilis). (Default: continuous )sound_device : Indeks numerik dari perangkat suara yang akan digunakan untuk merekam. Untuk menemukan nomor perangkat, jalankan python -m sounddevice . (Default: null )sample_rate : Laju sampel dalam HZ untuk digunakan untuk perekaman. (Default: 16000 )silence_duration : Durasi dalam milidetik untuk menunggu keheningan sebelum menghentikan rekaman. (Default: 900 )min_duration : Durasi minimum dalam milidetik untuk rekaman yang akan diproses. Rekaman lebih pendek dari ini akan dibuang. (Default: 100 ) writing_key_press_delay : Penundaan detik antara setiap tekan tombol saat menulis teks yang ditranskripsikan. (Default: 0.005 )remove_trailing_period : Setel ke true untuk menghapus periode trailing dari teks yang ditranskripsikan. (Default: false )add_trailing_space : Setel ke true untuk menambahkan ruang ke ujung teks yang ditranskripsikan. (Default: true )remove_capitalization : Setel ke true untuk mengonversi teks yang ditranskrip menjadi huruf kecil. (Default: false )input_method : Metode untuk digunakan untuk mensimulasikan input keyboard. (Default: pynput ) print_to_terminal : Setel ke true untuk mencetak status skrip dan ditranskripsikan teks ke terminal. (Default: true )hide_status_window : Setel ke true untuk menyembunyikan jendela status selama operasi. (Default: false )noise_on_completion : Setel ke true untuk memainkan noise setelah transkripsi diketik. (Default: false )Jika salah satu opsi konfigurasi tidak valid atau tidak disediakan, program akan menggunakan nilai default.
Anda dapat melihat semua masalah yang dilaporkan dan status mereka saat ini dalam pelacak masalah kami. Jika Anda mengalami masalah, buka masalah baru dengan deskripsi terperinci dan langkah -langkah reproduksi, jika memungkinkan.
Di bawah ini adalah fitur yang saya rencanakan untuk ditambahkan dalam waktu dekat:
Di bawah ini adalah fitur yang tidak direncanakan saat ini:
Fitur yang diimplementasikan dapat ditemukan di Changelog.
Kontribusi dipersilakan! Saya membuat proyek ini untuk penggunaan pribadi saya sendiri dan tidak mengharapkannya untuk mendapatkan banyak perhatian, jadi saya belum berupaya menguji atau memudahkan orang lain untuk berkontribusi. Jika Anda memiliki ide atau saran, jangan ragu untuk membuka permintaan tarik atau membuat masalah baru. Saya akan melakukan yang terbaik untuk meninjau dan menanggapi sesuai waktu.
Proyek ini dilisensikan di bawah Lisensi Publik Umum GNU. Lihat file lisensi untuk detailnya.


