whisper writer
v1.0.1
UPDATE (2024-05-28): Ich habe gerade in einem großen Umschreiben von WhisperWriter zusammengefasst! Wir haben von der Verwendung von tkinter zur Verwendung von PyQt5 für die Benutzeroberfläche migriert, ein neues Einstellungsfenster für die Konfiguration, einen neuen kontinuierlichen Aufnahmemodus, Unterstützung für eine lokale API und vieles mehr hinzugefügt! Bitte seien Sie geduldig, während ich Fehler ausarbeite, die möglicherweise dabei eingeführt wurden. Wenn Sie auf Probleme stoßen, öffnen Sie bitte ein neues Problem!
WhisperWriter ist eine kleine Sprach-Text-App, mit der das Flüstermodell von OpenAI automatisch über das Mikrofon eines Benutzers bis zum aktiven Fenster transchreibt.
Nach dem Start wird das Skript im Hintergrund ausgeführt und wartet darauf, dass eine Tastaturverknüpfung gedrückt wird (standardmäßig ctrl+shift+space ). Wenn die Verknüpfung gedrückt wird, beginnt die App mit der Aufzeichnung von Ihrem Mikrofon. Es stehen vier Aufzeichnungsmodi zur Auswahl:
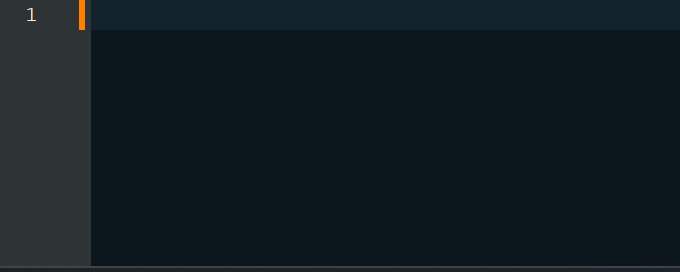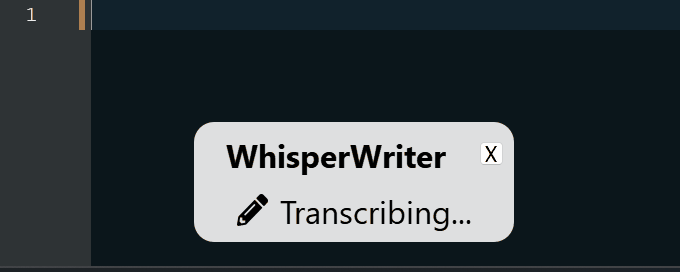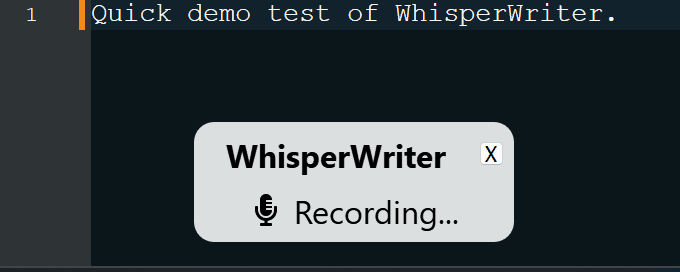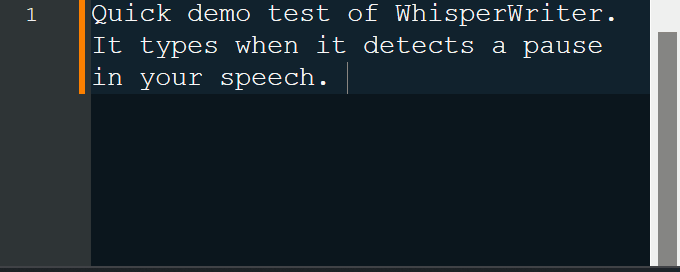
continuous (Standard): Die Aufzeichnung hört nach einer langen Pause in Ihrer Rede auf. Die App transkribieren den Text und beginnt dann erneut mit der Aufzeichnung. Um das Hören zu stoppen, drücken Sie die Tastaturverknüpfung erneut.voice_activity_detection : Die Aufzeichnung wird nach einer langen Pause in Ihrer Rede aufhören. Die Aufzeichnung beginnt erst dann, wenn die Tastaturverknüpfung erneut gedrückt wird.press_to_toggle , wenn die Tastaturverknüpfung erneut gedrückt wird. Die Aufzeichnung beginnt erst dann, wenn die Tastaturverknüpfung erneut gedrückt wird.hold_to_record wird fortgesetzt, bis die Tastaturverknüpfung veröffentlicht wird. Die Aufzeichnung beginnt erst, wenn die Tastaturverknüpfung erneut abgehalten wird. Sie können die Tastaturverknüpfung ( activation_key ) und den Aufzeichnungsmodus in den Konfigurationsoptionen ändern. Während der Aufnahme und Transkription wird ein kleines Statusfenster angezeigt, das die aktuelle Stufe des Prozesses anzeigt (dies kann jedoch ausgeschaltet werden). Sobald die Transkription abgeschlossen ist, wird der transkribierte Text automatisch in das aktive Fenster geschrieben.
Die Transkription kann entweder lokal durch das schnellere Python-Paket oder durch eine Anfrage zur Openai-API durchgeführt werden. Standardmäßig verwendet die App ein lokales Modell, können dies jedoch in den Konfigurationsoptionen ändern. Wenn Sie die API verwenden, müssen Sie entweder Ihre OpenAI -API -Taste angeben oder den Basis -URL -Endpunkt ändern.
Lustige Tatsache: Fast die gesamte Erstveröffentlichung des Projekts wurde mit ChatGPT-4 und Github Copilot unter Verwendung von VS-Code mit ChatGPT-4 und Github-Copilot gepaart. Praktisch jede Zeile, einschließlich des größten Teils dieser Readme, wurde von AI geschrieben. Nachdem der erste Prototyp fertig war, wurde WhisperWriter verwendet, um auch viele Eingabeaufforderungen zu schreiben!
Bevor Sie diese App ausführen können, müssen Sie die folgende Software installieren:
3.11 : https://www.python.org/downloads/ Wenn Sie auf Ihrer GPU faster-whisper ausführen möchten, müssen Sie auch die folgenden NVIDIA-Bibliotheken installieren:
Das folgende wurde direkt aus dem faster-whisper Readme genommen:
Hinweis: Die neuesten Versionen von ctranslate2 unterstützen nur CUDA 12. Für CUDA 11 stellt die aktuelle Problemumgehung auf die 3.24.0 Version von ctranslate2 herab (dies kann mit pip install --force-reinsall ctranslate2==3.24.0 ).
Es gibt mehrere Möglichkeiten, die oben genannten NVIDIA -Bibliotheken zu installieren. Der empfohlene Weg wird in der offiziellen NVIDIA -Dokumentation beschrieben, aber wir schlagen auch andere Installationsmethoden nachstehend vor.
Die Bibliotheken (Cublas, Cudnn) sind in diesen offiziellen Nvidia Cuda Docker-Bildern installiert: nvidia/cuda:12.0.0-runtime-ubuntu20.04 oder nvidia/cuda:12.0.0-runtime-ubuntu22.04 .
pip (nur Linux) Unter Linux können diese Bibliotheken mit pip installiert werden. Beachten Sie, dass LD_LIBRARY_PATH vor dem Start von Python festgelegt werden muss.
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
export LD_LIBRARY_PATH= ` python3 -c ' import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__)) ' ` HINWEIS : Version 9+ von nvidia-cudnn-cu12 scheint Probleme zu verursachen, die aufgrund ihrer Abhängigkeit von Cudnn 9 zu Problemen zu kommen (schnellerer Whisper unterstützt derzeit nicht Cudnn 9). Stellen Sie sicher, dass Ihre Version des Python -Pakets für Cudnn 8 gilt.
Purfviews Whisper-Standalone-Win bietet die erforderlichen NVIDIA-Bibliotheken für Windows & Linux in einem einzigen Archiv. Dekomprimieren Sie das Archiv und legen Sie die Bibliotheken in ein im PATH enthaltener Verzeichnis.
Befolgen Sie die folgenden Schritte, um das Projekt einzurichten und auszuführen:
git clone https://github.com/savbell/whisper-writer
cd whisper-writer
python -m venv venv
# For Linux and macOS:
source venv/bin/activate
# For Windows:
venvScriptsactivate
pip install -r requirements.txt
python run.py
Beim ersten Auslauf sollte ein Einstellungsfenster angezeigt werden. Sobald es konfiguriert und gespeichert ist, wird ein weiteres Fenster geöffnet. Drücken Sie "Start", um den Tastaturhörer zu aktivieren. Drücken Sie standardmäßig die Aktivierungs -Taste ( ctrl+shift+space ), um die Aufzeichnung und das Transkribieren in das aktive Fenster zu starten.
WhisperWriter verwendet eine Konfigurationsdatei, um sein Verhalten anzupassen. Öffnen Sie zum Einrichten der Konfiguration das Einstellungsfenster:
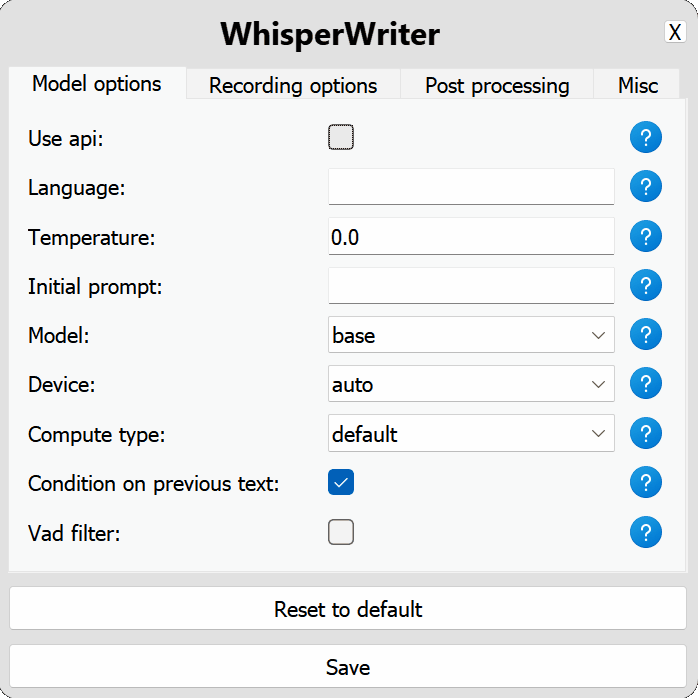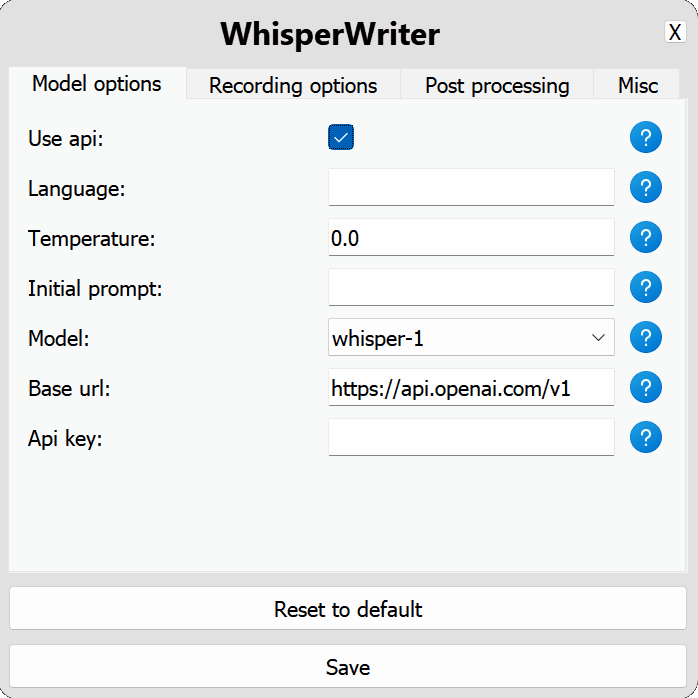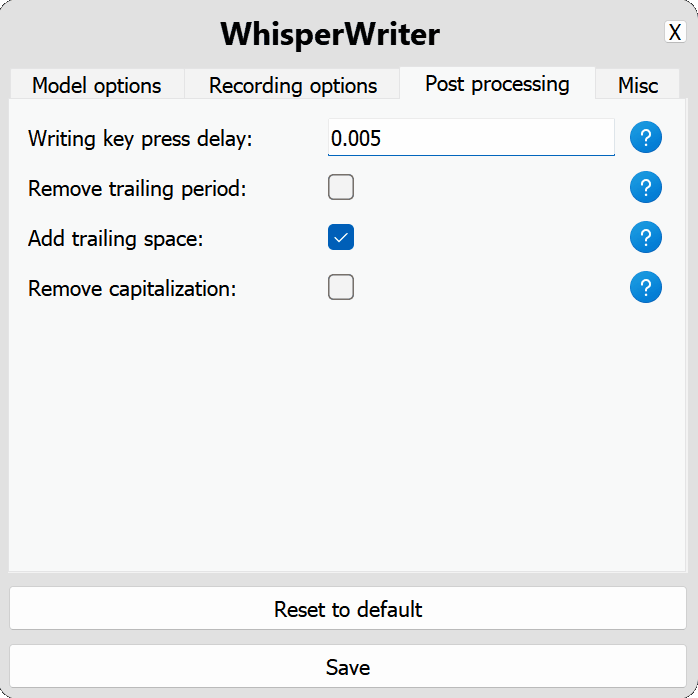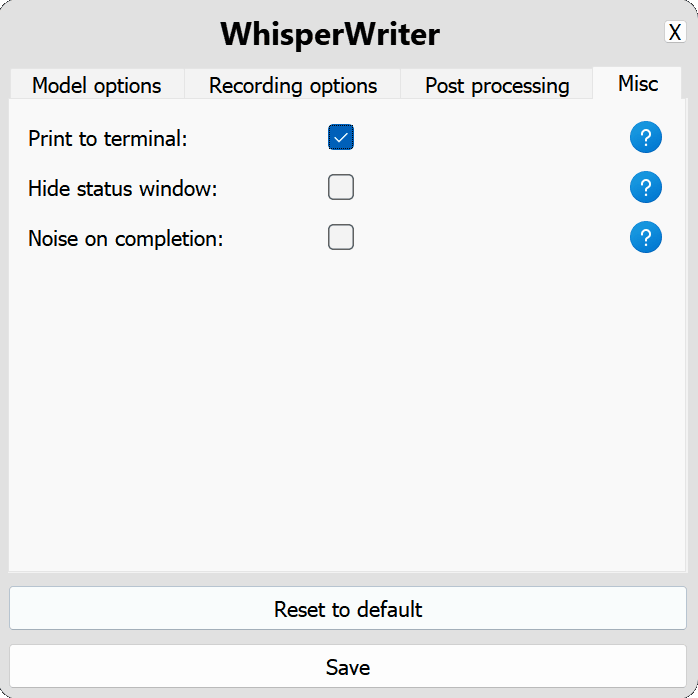
use_api : Wechseln Sie, um zu wählen, ob die OpenAI -API oder ein lokales Flüstermodell für die Transkription verwendet werden soll. (Standard: false )
common : Optionen, die sowohl API- als auch lokalen Modellen gemeinsam sind.
language : Der Sprachcode für die Transkription im ISO-639-1-Format. (Standard: null )temperature : Steuert die Zufälligkeit des Transkriptionsausgangs. Niedrigere Werte machen die Ausgabe fokussierter und deterministischer. (Standard: 0.0 )initial_prompt : Eine Zeichenfolge, die als Erstaufforderung verwendet wird, um die Transkription zu konditionieren. Weitere Info: OpenAI -Aufforderung zur Anleitung. (Standard: null ) api : Konfigurationsoptionen für die OpenAI -API. Weitere Informationen finden Sie in der OpenAI -API -Dokumentation.
model : Das Modell zur Transkription. Derzeit ist nur whisper-1 verfügbar. (Standard: whisper-1 )base_url : Die Basis -URL für die API. Kann geändert werden, um einen lokalen API -Endpunkt wie Localai zu verwenden. (Standard: https://api.openai.com/v1 )api_key : Ihr API -Schlüssel für die OpenAI -API. Für nicht lokale API-Verwendung erforderlich. (Standard: null ) local : Konfigurationsoptionen für das lokale Flüstermodell.
model : Das Modell zur Transkription. Die größeren Modelle bieten eine bessere Genauigkeit, sind aber langsamer. Siehe verfügbare Modelle und Sprachen. (Standard: base )device : Das Gerät zum Ausführen des lokalen Flüstermodells eingeschaltet. Verwenden Sie cuda für NVIDIA-GPUs, cpu für CPU-Nur-Verarbeitung oder auto , um das System automatisch das beste verfügbare Gerät auszuwählen. (Standard: auto )compute_type : Der Rechenart für das lokale Flüstermodell. Weitere Informationen zur Quantisierung hier. (Standard: default )condition_on_previous_text : Setzen Sie auf true , um den zuvor transkribierten Text als Aufforderung für die nächste Transkriptionsanforderung zu verwenden. (Standard: true )vad_filter : Setzen Sie auf true , um einen VAD -Filter (Voice Activity Detection) zu verwenden, um die Stille aus der Aufzeichnung zu entfernen. (Standard: false )model_path : Der Pfad zum lokalen Flüstermodell. Wenn nicht angegeben, wird das Standardmodell heruntergeladen. (Standard: null ) activation_key : Die Tastaturverknüpfung zum Aktivieren des Aufzeichnungs- und Transkriptionsprozesses. Trennende Schlüssel mit A + . (Standard: ctrl+shift+space )input_backend : Das Eingabe -Backend zum Erkennen von Tastenpressen. auto wird versuchen, das beste verfügbare Backend zu verwenden. (Standard: auto )recording_mode : Der zu verwendende Aufzeichnungsmodus. Zu den Optionen gehören continuous (automatisch-restart-Aufzeichnung nach Pause in der Sprache, bis die Aktivierungsschlüssel erneut gedrückt wird), voice_activity_detection (Stoppenaufzeichnung nach Pause in der Sprache), press_to_toggle (Stoppenaufzeichnung, wenn die Aktivierungsschlüssel erneut gedrückt wird), hold_to_record (Stopp-Aufzeichnung, wenn die Aktivierungsschlüssel freigegeben wird). (Standard: continuous )sound_device : Der numerische Index des Sound -Geräts für die Aufnahme. Um Gerätenummern zu finden, führen Sie python -m sounddevice aus. (Standard: null )sample_rate : Die Beispielrate in HZ, die für die Aufzeichnung verwendet werden soll. (Standard: 16000 )silence_duration : Die Dauer in Millisekunden, um auf die Stille zu warten, bevor die Aufnahme gestoppt wird. (Standard: 900 )min_duration : Die Mindestdauer in Millisekunden für eine Aufzeichnung zu verarbeiten. Aufnahmen kürzer als diese werden verworfen. (Standard: 100 ) writing_key_press_delay : Die Verzögerung in Sekunden zwischen den einzelnen Taste drücken beim Schreiben des transkribierten Textes. (Standard: 0.005 )remove_trailing_period : Setzen Sie auf true , um die nachverfolgende Periode aus dem transkribierten Text zu entfernen. (Standard: false )add_trailing_space : Setzen Sie auf true , um zum Ende des transkribierten Textes einen Platz hinzuzufügen. (Standard: true )remove_capitalization : Setzen Sie auf true , um den transkribierten Text in Kleinbuchstaben umzuwandeln. (Standard: false )input_method : Die Methode zur Simulation der Tastatureingabe. (Standard: pynput ) print_to_terminal : auf true einstellen, um den Skriptstatus und den transkribierten Text in das Terminal zu drucken. (Standard: true )hide_status_window : auf true einstellen, um das Statusfenster während der Operation zu verbergen. (Standard: false )noise_on_completion : Setzen Sie nach dem Eingeben der Transkription auf true , um ein Rauschen zu spielen. (Standard: false )Wenn eine der Konfigurationsoptionen ungültig ist oder nicht angegeben ist, verwendet das Programm die Standardwerte.
Sie können alle gemeldeten Probleme und ihren aktuellen Status in unserem Ausgaben -Tracker sehen. Wenn Sie auf ein Problem stoßen, öffnen Sie bitte ein neues Problem mit einer detaillierten Beschreibung und Reproduktionsschritte.
Im Folgenden finden Sie Funktionen, die ich in naher Zukunft hinzufügen möchte:
Im Folgenden finden Sie Funktionen, die derzeit nicht geplant sind:
Implementierte Funktionen finden Sie im Changelog.
Beiträge sind willkommen! Ich habe dieses Projekt für meinen persönlichen Gebrauch erstellt und habe nicht erwartet, dass es viel Aufmerksamkeit erregt, daher habe ich nicht viel Mühe in das Testen oder den Beitrag zu machen, um einen Beitrag zu leisten. Wenn Sie Ideen oder Vorschläge haben, können Sie eine Pull -Anfrage öffnen oder ein neues Problem erstellen. Ich werde mein Bestes tun, um zu überprüfen und zu antworten, wie es die Zeit erlaubt.
Dieses Projekt ist unter der GNU General Public Lizenz lizenziert. Weitere Informationen finden Sie in der Lizenzdatei.


