whisper writer
v1.0.1
ACTUALIZACIÓN (2024-05-28): ¡Acabo de fusionar una importante reescritura de WhisperWriter! Hemos migrado de usar tkinter a usar PyQt5 para la interfaz de usuario, agregamos una nueva ventana de configuración para la configuración, un nuevo modo de grabación continua, soporte para una API local y más. Tenga paciencia mientras resuelva cualquier error que pueda haberse introducido en el proceso. Si encuentra algún problema, ¡abra un nuevo problema!
WhisperWriter es una pequeña aplicación de voz a texto que utiliza el modelo Whisper de OpenAI para transcribir automáticamente las grabaciones desde el micrófono de un usuario a la ventana activa.
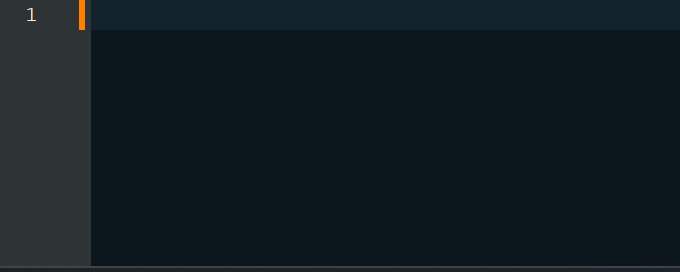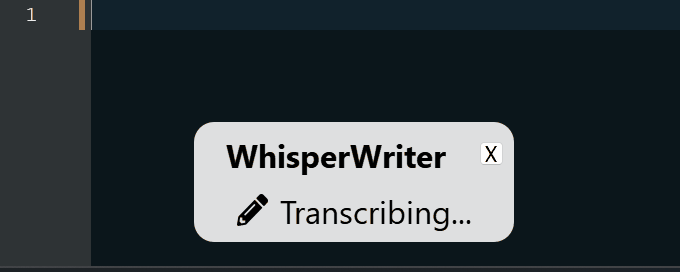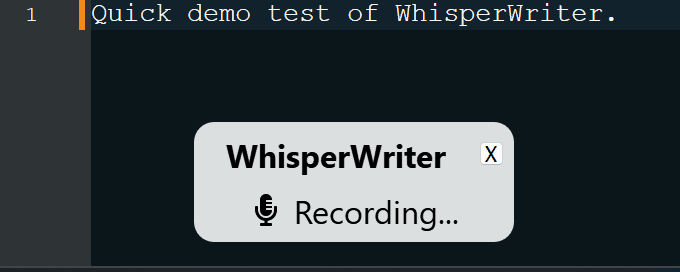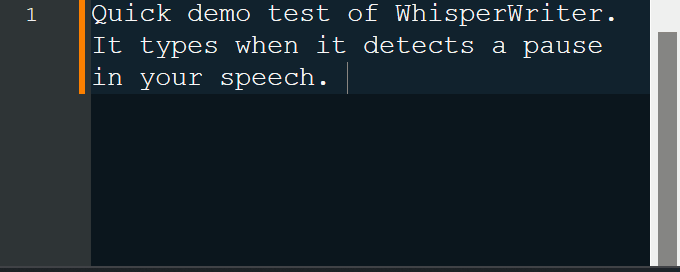
Una vez iniciado, el script se ejecuta en segundo plano y espera a que se presione un atajo de teclado ( ctrl+shift+space de forma predeterminada). Cuando se presiona el atajo, la aplicación comienza a grabar desde su micrófono. Hay cuatro modos de grabación para elegir:
continuous (predeterminado): la grabación se detendrá después de una pausa lo suficientemente larga en su discurso. La aplicación transcribirá el texto y luego comenzará a grabar nuevamente. Para dejar de escuchar, presione el atajo del teclado nuevamente.voice_activity_detection : la grabación se detendrá después de una pausa lo suficientemente larga en su discurso. La grabación no comenzará hasta que se presione nuevamente el atajo del teclado.press_to_toggle La grabación se detendrá cuando se presione el acceso directo del teclado nuevamente. La grabación no comenzará hasta que se presione nuevamente el atajo del teclado.hold_to_record La grabación continuará hasta que se lance el acceso directo del teclado. La grabación no comenzará hasta que el acceso directo del teclado se retire nuevamente. Puede cambiar el acceso directo del teclado ( activation_key ) y el modo de grabación en las opciones de configuración. Al registrar y transcribir, se muestra una pequeña ventana de estado que muestra la etapa actual del proceso (pero esto se puede apagar). Una vez que se complete la transcripción, el texto transcrito se escribirá automáticamente en la ventana activa.
La transcripción se puede realizar localmente a través del paquete Python más rápido o mediante una solicitud de API de OpenAI. Por defecto, la aplicación usará un modelo local, pero puede cambiar esto en las opciones de configuración. Si elige usar la API, deberá proporcionar su tecla API OpenAI o cambiar el punto final de URL base.
Dato curioso: casi la totalidad de la versión inicial del proyecto fue programada por pares con CHATGPT-4 y Copilot GitHub utilizando el código VS. Prácticamente cada línea, incluida la mayor parte de este readme, fue escrita por AI. Después de que se terminó el prototipo inicial, ¡WhisperWriter se usó para escribir muchas de las indicaciones también!
Antes de poder ejecutar esta aplicación, deberá tener el siguiente software instalado:
3.11 : https://www.python.org/downloads/ Si desea ejecutar faster-whisper en su GPU, también necesitará instalar las siguientes bibliotecas NVIDIA:
El siguiente fue tomado directamente del readme faster-whisper :
Nota: Las últimas versiones de ctranslate2 soportan solo CUDA 12. Para CUDA 11, la solución actual se baja a la versión 3.24.0 de ctranslate2 (esto se puede hacer con pip install --force-reinsall ctranslate2==3.24.0 ).
Hay varias formas de instalar las bibliotecas NVIDIA mencionadas anteriormente. La forma recomendada se describe en la documentación oficial de NVIDIA, pero también sugerimos otros métodos de instalación a continuación.
Las bibliotecas (CUBLAS, CUDNN) se instalan en estas imágenes oficiales de Nvidia Cuda Docker: nvidia/cuda:12.0.0-runtime-ubuntu20.04 o nvidia/cuda:12.0.0-runtime-ubuntu22.04 .
pip (solo Linux) En Linux, estas bibliotecas se pueden instalar con pip . Tenga en cuenta que LD_LIBRARY_PATH debe establecerse antes de lanzar Python.
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
export LD_LIBRARY_PATH= ` python3 -c ' import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__)) ' ` Nota : La versión 9+ de nvidia-cudnn-cu12 parece causar problemas debido a su dependencia de CUDNN 9 (más rápido no es compatible con Cudnn 9). Asegúrese de que su versión del paquete Python sea para Cudnn 8.
Whisper-Standalone-Win de Purfview proporciona las bibliotecas NVIDIA requeridas para Windows y Linux en un solo archivo. Descomprima el archivo y coloque las bibliotecas en un directorio incluida en la PATH .
Para configurar y ejecutar el proyecto, siga estos pasos:
git clone https://github.com/savbell/whisper-writer
cd whisper-writer
python -m venv venv
# For Linux and macOS:
source venv/bin/activate
# For Windows:
venvScriptsactivate
pip install -r requirements.txt
python run.py
En la primera ejecución, debe aparecer una ventana de configuración. Una vez configurado y guardado, se abrirá otra ventana. Presione "Inicio" para activar el oyente del teclado. Presione la tecla de activación ( ctrl+shift+space de forma predeterminada) para comenzar a grabar y transcribir a la ventana activa.
WhisperWriter usa un archivo de configuración para personalizar su comportamiento. Para configurar la configuración, abra la ventana Configuración:
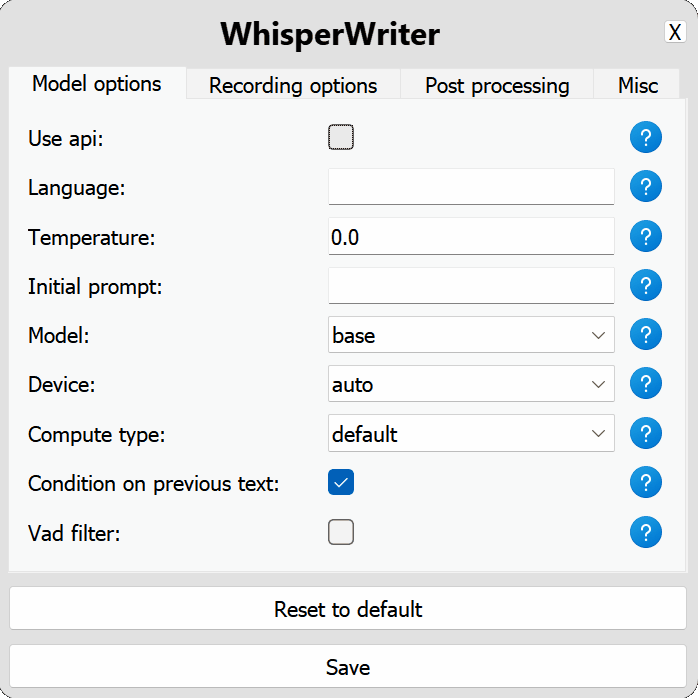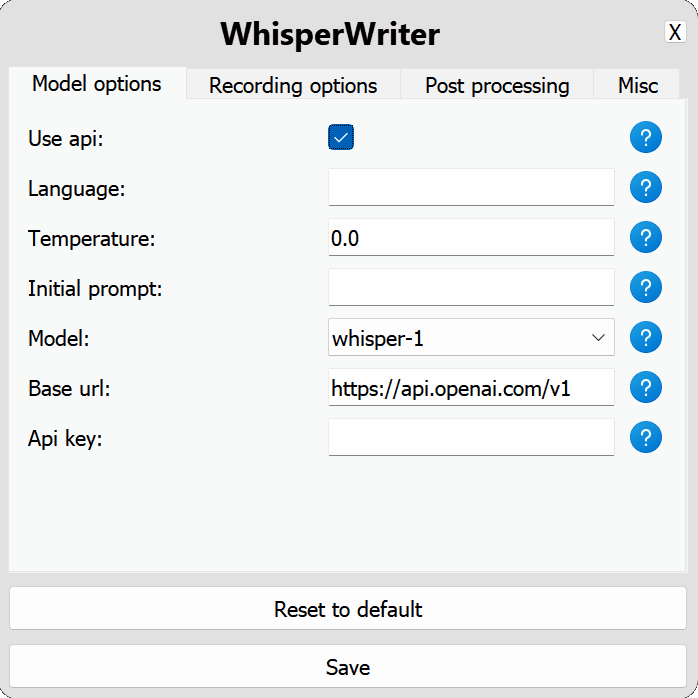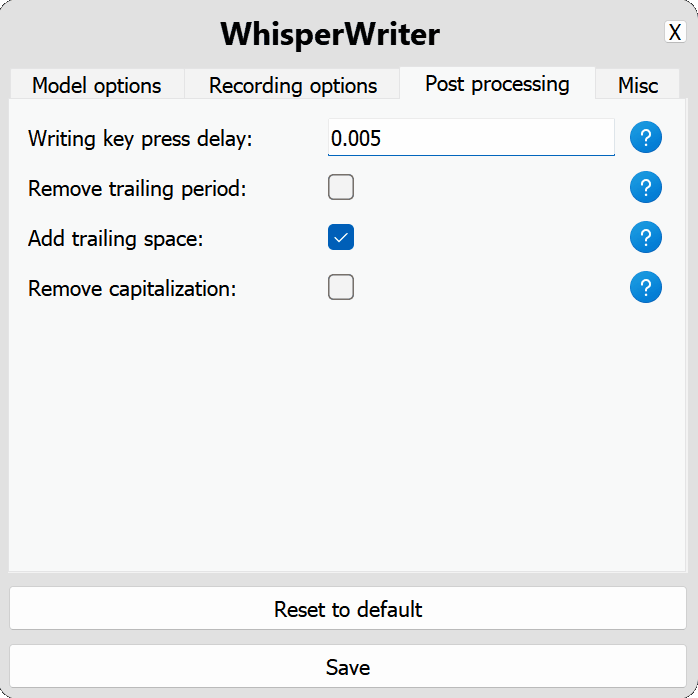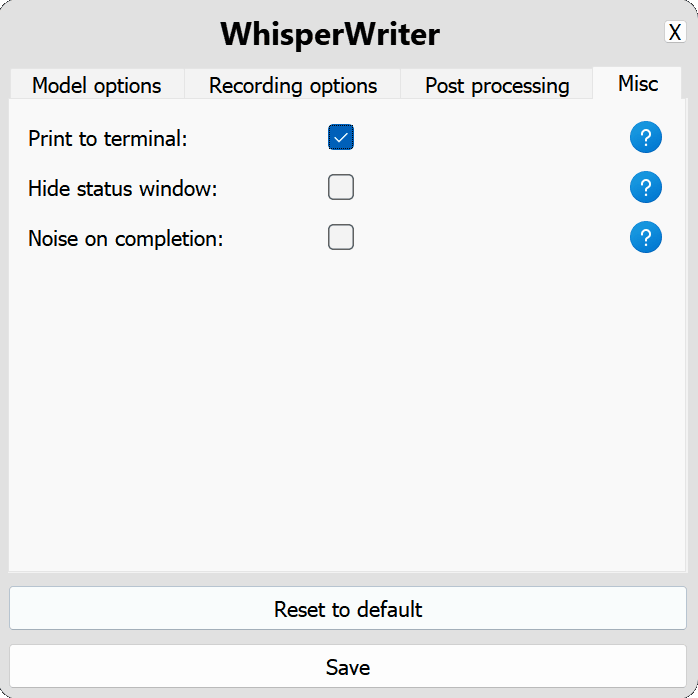
use_api : alternar para elegir si se utiliza la API OpenAI o un modelo Whisper local para la transcripción. (Predeterminado: false )
common : Opciones comunes tanto a la API como a los modelos locales.
language : el código de idioma para la transcripción en formato ISO-639-1. (Predeterminado: null )temperature : controla la aleatoriedad de la salida de la transcripción. Los valores más bajos hacen que la salida sea más enfocada y determinista. (Predeterminado: 0.0 )initial_prompt : una cadena utilizada como un mensaje inicial para acondicionar la transcripción. Más información: Guía de solicitud de OpenAI. (Predeterminado: null ) api : opciones de configuración para la API de OpenAI. Consulte la documentación de la API de OpenAI para obtener más información.
model : el modelo a usar para la transcripción. Actualmente, solo whisper-1 está disponible. (Predeterminado: whisper-1 )base_url : la URL base para la API. Se puede cambiar para usar un punto final API local, como LocalAi. (Predeterminado: https://api.openai.com/v1 )api_key : Tu clave API para la API de OpenAI. Requerido para el uso de API no local. (Predeterminado: null ) local : Opciones de configuración para el modelo Whisper local.
model : el modelo a usar para la transcripción. Los modelos más grandes proporcionan una mejor precisión pero son más lentas. Ver modelos e idiomas disponibles. (Predeterminado: base )device : el dispositivo para ejecutar el modelo de susurro local. Use cuda para las GPU NVIDIA, cpu para el procesamiento de solo CPU o auto para que el sistema elija automáticamente el mejor dispositivo disponible. (Predeterminado: auto )compute_type : el tipo de cómputo para usar para el modelo de susurro local. Más información sobre la cuantización aquí. (Predeterminado: default )condition_on_previous_text : Establezca en true para usar el texto transcrito previamente como un mensaje para la siguiente solicitud de transcripción. (Predeterminado: true )vad_filter : Establezca en true para usar un filtro de detección de actividad de voz (VAD) para eliminar el silencio de la grabación. (Predeterminado: false )model_path : la ruta al modelo de susurro local. Si no se especifica, se descargará el modelo predeterminado. (Predeterminado: null ) activation_key : el atajo de teclado para activar el proceso de grabación y transcripción. Llaves separadas con a + . (Predeterminado: ctrl+shift+space )input_backend : el backend de entrada para usar para detectar presiones de teclas. auto intentará usar el mejor backend disponible. (Predeterminado: auto )recording_mode : el modo de grabación para usar. Las opciones incluyen continuous (grabación de retrato automático después de pausa en el discurso hasta que se presione la tecla de activación nuevamente), voice_activity_detection (pare de grabación después de pausa en el discurso), press_to_toggle (pare de grabación cuando la tecla de activación se presiona nuevamente), hold_to_record (Stop Reging cuando se lanza la tecla de activación). (Predeterminado: continuous )sound_device : el índice numérico del dispositivo de sonido que se utilizará para la grabación. Para encontrar números de dispositivo, ejecute python -m sounddevice . (Predeterminado: null )sample_rate : la frecuencia de muestreo en HZ para usar para la grabación. (Predeterminado: 16000 )silence_duration : la duración en milisegundos para esperar el silencio antes de detener la grabación. (Predeterminado: 900 )min_duration : la duración mínima en milisegundos para que se procese una grabación. Las grabaciones más cortas que esto se descartarán. (Predeterminado: 100 ) writing_key_press_delay : el retraso en segundos entre cada tecla Presione al escribir el texto transcrito. (Predeterminado: 0.005 )remove_trailing_period : Establezca en true para eliminar el período de finalización del texto transcrito. (Predeterminado: false )add_trailing_space : Establezca en true para agregar un espacio al final del texto transcrito. (Predeterminado: true )remove_capitalization : configurar en true para convertir el texto transcrito en minúsculas. (Predeterminado: false )input_method : el método para usar para simular la entrada del teclado. (Predeterminado: pynput ) print_to_terminal : Establezca en true para imprimir el estado del script y el texto transcrito al terminal. (Predeterminado: true )hide_status_window : Establezca en true para ocultar la ventana de estado durante la operación. (Predeterminado: false )noise_on_completion : Establezca en true para reproducir un ruido después de que se haya escrito la transcripción. (Predeterminado: false )Si alguna de las opciones de configuración no es válida o no se proporciona, el programa utilizará los valores predeterminados.
Puede ver todos los problemas informados y su estado actual en nuestro rastreador de problemas. Si encuentra un problema, abra un nuevo problema con una descripción detallada y pasos de reproducción, si es posible.
A continuación se presentan características que planeo agregar en el futuro cercano:
A continuación se presentan las características que no están planificadas actualmente:
Las características implementadas se pueden encontrar en ChangeLog.
¡Las contribuciones son bienvenidas! Creé este proyecto para mi propio uso personal y no esperaba que recibiera mucha atención, por lo que no he hecho mucho esfuerzo en probar o facilitar que otros contribuyan. Si tiene ideas o sugerencias, no dude en abrir una solicitud de extracción o crear un nuevo problema. Haré todo lo posible para revisar y responder según lo permita el tiempo.
Este proyecto tiene licencia bajo la Licencia Pública General de GNU. Consulte el archivo de licencia para obtener más detalles.


