whisper writer
v1.0.1
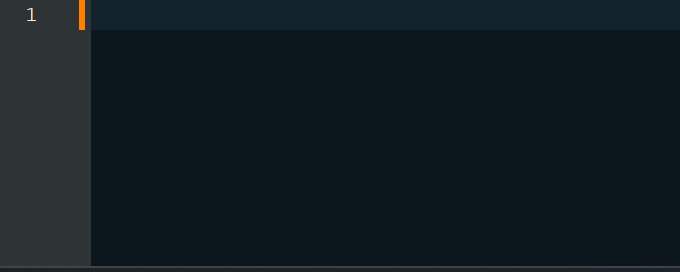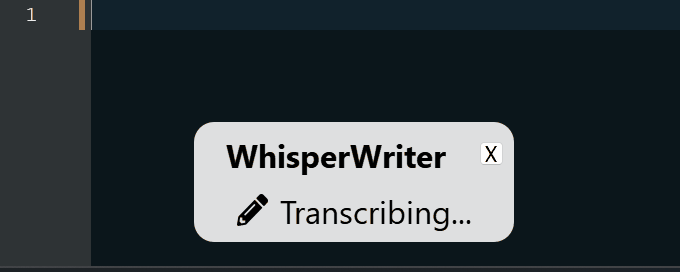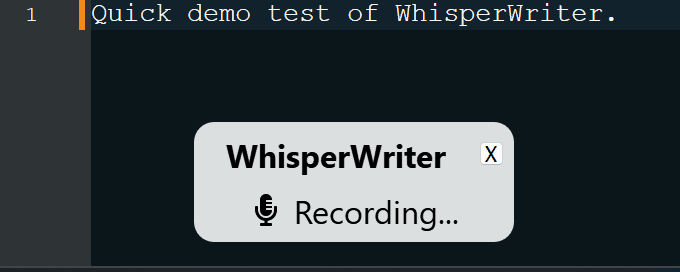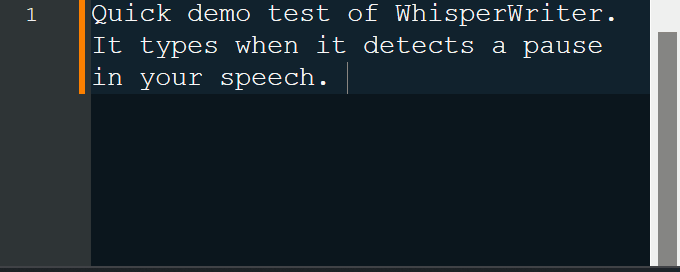
업데이트 (2024-05-28) : 나는 WhisperWriter의 주요 재 작성에서 병합되었습니다! 우리는 tkinter 사용하여 UI에 PyQt5 사용하여 마이그레이션했으며 구성을위한 새 설정 창, 새로운 연속 레코딩 모드, 로컬 API 지원 등을 추가했습니다! 그 과정에서 도입 될 수있는 버그를 해결할 때 인내심을 가지십시오. 문제가 발생하면 새로운 문제를여십시오!
WhisperWriter는 OpenAi의 Whisper 모델을 사용하여 사용자의 마이크에서 활성 창으로의 녹음을 자동으로 전환하는 작은 음성 텍스트 앱입니다.
일단 시작되면 스크립트는 백그라운드에서 실행되며 키보드 바로 가기를 누르기를 기다립니다 (기본적으로 ctrl+shift+space ). 바로 가기를 누르면 앱이 마이크에서 녹음을 시작합니다. 선택할 수있는 4 가지 녹화 모드가 있습니다.
continuous (기본값) : 연설에서 충분히 일시 정지 후 녹음이 중지됩니다. 앱이 텍스트를 전사 한 다음 다시 녹음을 시작합니다. 듣기를 중지하려면 키보드 바로 가기를 다시 누릅니다.voice_activity_detection : 연설에서 충분히 일시 중지 한 후 녹음이 중지됩니다. 키보드 단축키가 다시 누르기 전까지는 녹음이 시작되지 않습니다.press_to_toggle 녹음이 중지됩니다. 키보드 단축키가 다시 누르기 전까지는 녹음이 시작되지 않습니다.hold_to_record 녹화는 키보드 단축키가 릴리스 될 때까지 계속됩니다. 키보드 단축키가 다시 고정 될 때까지 녹음이 시작되지 않습니다. 구성 옵션에서 키보드 바로 가기 ( activation_key ) 및 녹화 모드를 변경할 수 있습니다. 기록 및 전사가 진행되는 동안 프로세스의 현재 단계를 보여주는 작은 상태 창이 표시됩니다 (그러나 이것은 꺼질 수 있음). 전사가 완료되면 전사 된 텍스트는 자동으로 활성 창에 기록됩니다.
전사는 더 빠른 창자 파이썬 패키지 또는 OpenAI의 API에 대한 요청을 통해 국부적으로 수행 될 수 있습니다. 기본적으로 앱은 로컬 모델을 사용하지만 구성 옵션에서이를 변경할 수 있습니다. API를 사용하기로 선택한 경우 OpenAI API 키를 제공하거나 기본 URL 엔드 포인트를 변경해야합니다.
재미있는 사실 : 프로젝트의 초기 릴리스의 거의 전체는 VS 코드를 사용하여 ChatGpt-4 및 Github Copilot과 쌍 프로그램을 획득했습니다. 실제로이 readme의 대부분을 포함한 모든 라인은 AI에 의해 작성되었습니다. 초기 프로토 타입이 완료된 후 WhisperWriter는 많은 프롬프트를 작성하는 데 사용되었습니다!
이 앱을 실행하기 전에 다음 소프트웨어를 설치해야합니다.
3.11 : https://www.python.org/downloads/ GPU에서 faster-whisper 실행하려면 다음 NVIDIA 라이브러리도 설치해야합니다.
아래는 faster-whisper 창고에서 직접 가져 왔습니다.
참고 : ctranslate2 의 최신 버전은 CUDA 12를 지원합니다. CUDA 11의 경우 현재 해결 방법은 ctranslate2 의 3.24.0 버전으로 다운 그레이드됩니다 ( pip install --force-reinsall ctranslate2==3.24.0 으로 수행 할 수 있음).
위에서 언급 한 NVIDIA 라이브러리를 설치하는 방법에는 여러 가지가 있습니다. 권장 방법은 공식 NVIDIA 문서에 설명되어 있지만 아래의 다른 설치 방법도 제안합니다.
라이브러리 (Cublas, CUDNN)는이 공식 Nvidia Cuda Docker 이미지에 설치되어 있습니다 : nvidia/cuda:12.0.0-runtime-ubuntu20.04 또는 nvidia/cuda:12.0.0-runtime-ubuntu22.04 .
pip (Linux 전용)로 설치 Linux에서는 이러한 라이브러리를 pip 와 함께 설치할 수 있습니다. Python을 시작하기 전에 LD_LIBRARY_PATH 설정해야합니다.
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
export LD_LIBRARY_PATH= ` python3 -c ' import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__)) ' ` 참고 : nvidia-cudnn-cu12 의 버전 9+는 CUDNN 9에 대한 의존으로 인해 문제를 일으키는 것으로 보입니다 (더 빠른 Whisper는 현재 CUDNN 9를 지원하지 않습니다). 파이썬 패키지의 버전이 CUDNN 8에 대한 것인지 확인하십시오.
Purfview의 Whisper-Standalone-Win은 단일 아카이브에서 Windows & Linux에 필요한 NVIDIA 라이브러리를 제공합니다. 아카이브를 압축하고 PATH 에 포함 된 디렉토리에 라이브러리를 배치하십시오.
프로젝트를 설정하고 실행하려면 다음을 수행하십시오.
git clone https://github.com/savbell/whisper-writer
cd whisper-writer
python -m venv venv
# For Linux and macOS:
source venv/bin/activate
# For Windows:
venvScriptsactivate
pip install -r requirements.txt
python run.py
첫 번째 실행시 설정 창이 나타납니다. 구성되고 저장되면 다른 창이 열립니다. "시작"을 눌러 키보드 리스너를 활성화하십시오. 활성화 키 ( ctrl+shift+space )를 눌러 활성 창에 기록 및 전사를 시작하십시오.
WhisperWriter는 구성 파일을 사용하여 동작을 사용자 정의합니다. 구성을 설정하려면 설정 창을 엽니 다.
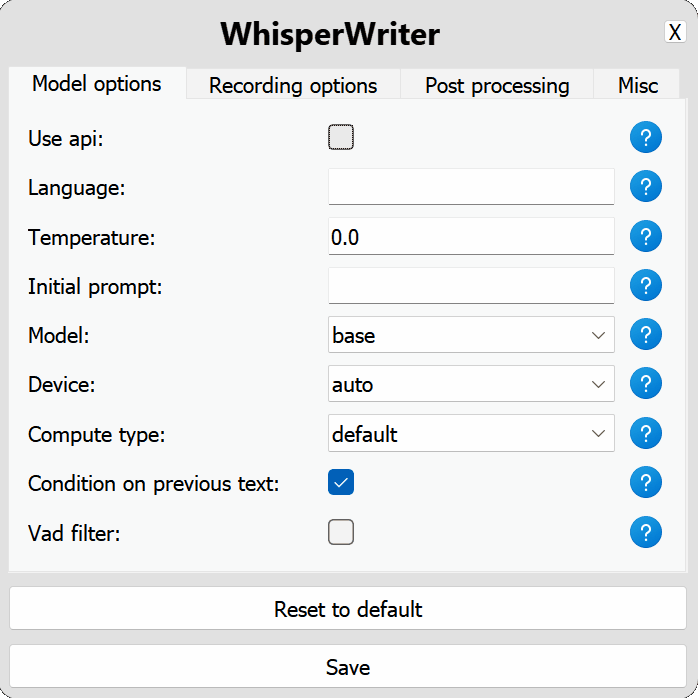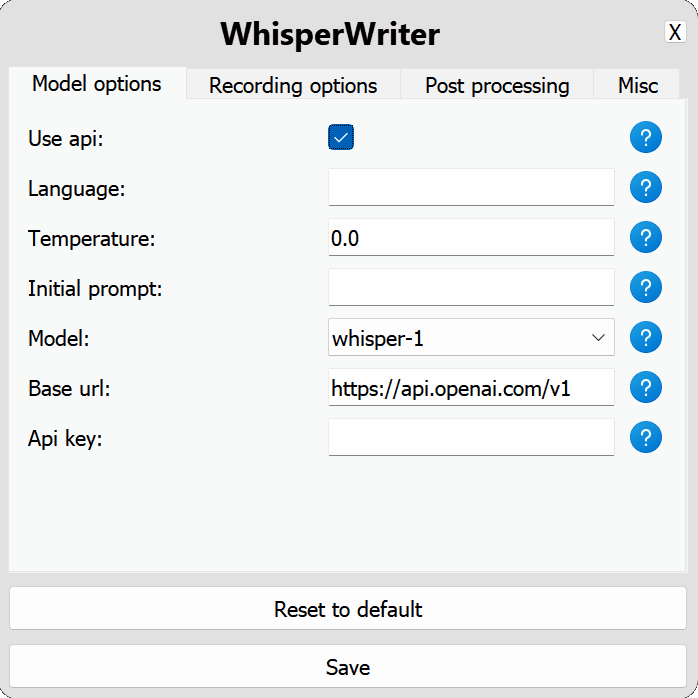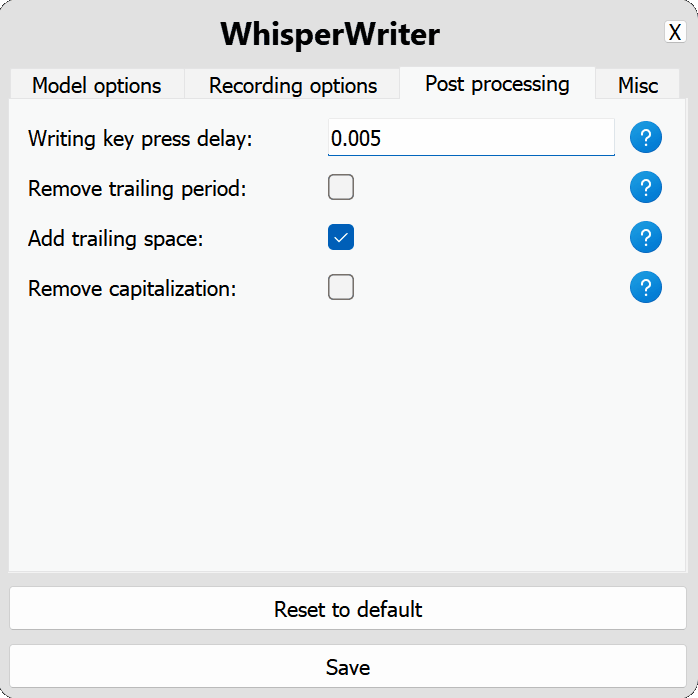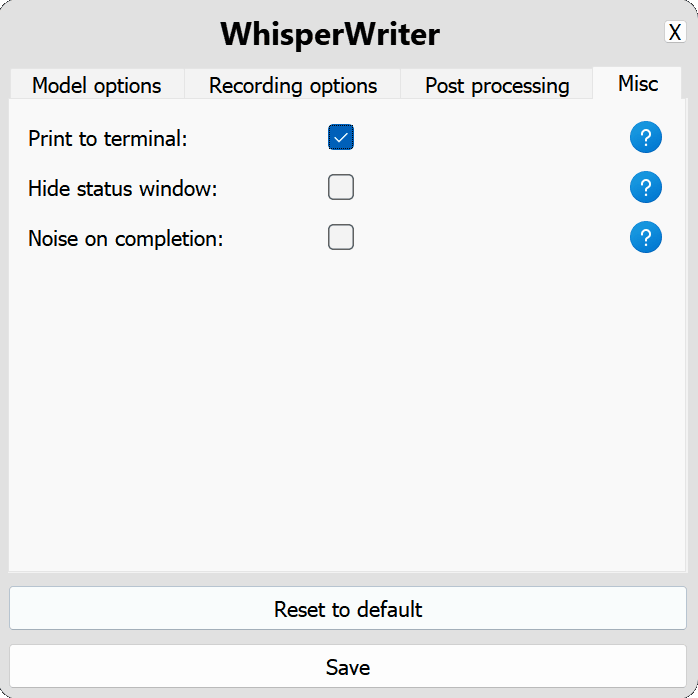
use_api : OpenAI API 또는 전사를 위해 로컬 속삭임 모델을 사용할지 여부를 선택하십시오. (기본값 : false )
common : API 및 로컬 모델 모두에 공통적 인 옵션.
language : ISO-639-1 형식의 전사 언어 코드. (기본값 : null )temperature : 전사 출력의 무작위성을 제어합니다. 낮은 값은 출력을보다 집중적이고 결정적으로 만듭니다. (기본값 : 0.0 )initial_prompt : 전사 조절을위한 초기 프롬프트로 사용되는 문자열. 추가 정보 : OpenAi 프롬프트 가이드. (기본값 : null ) api : OpenAI API의 구성 옵션. 자세한 내용은 OpenAI API 문서를 참조하십시오.
model : 전사에 사용할 모델. 현재 whisper-1 만 사용할 수 있습니다. (기본값 : whisper-1 )base_url : API의 기본 URL. LocalAI와 같은 로컬 API 엔드 포인트를 사용하도록 변경할 수 있습니다. (기본값 : https://api.openai.com/v1 )api_key : OpenAI API의 API 키. 비 국소 API 사용에 필요합니다. (기본값 : null ) local : 로컬 속삭임 모델의 구성 옵션.
model : 전사에 사용할 모델. 더 큰 모델은 더 나은 정확도를 제공하지만 더 느립니다. 사용 가능한 모델과 언어를 참조하십시오. (기본값 : base )device : 로컬 속삭임 모델을 실행하는 장치. NVIDIA GPUS 용 cuda , CPU 전용 처리 용 cpu 또는 자동으로 시스템이 최상의 장치를 선택할 수 있도록 auto 사용하십시오. (기본값 : auto )compute_type : 로컬 속삭임 모델에 사용할 컴퓨터 유형. 양자화에 대한 자세한 내용은 여기를 참조하십시오. (기본값 : default )condition_on_previous_text : 다음 전사 요청의 프롬프트로 이전에 전사 된 텍스트를 사용하도록 true 로 설정하십시오. (기본값 : true )vad_filter : VAD (Voice Activity Detection) 필터를 사용하여 레코딩에서 침묵을 제거하도록 true 로 설정하십시오. (기본값 : false )model_path : 로컬 속삭임 모델의 경로. 지정되지 않으면 기본 모델이 다운로드됩니다. (기본값 : null ) activation_key : 녹음 및 전사 프로세스를 활성화하기위한 키보드 바로 가기. a + 와 별도의 키. (기본값 : ctrl+shift+space )input_backend : 키 프레스 감지에 사용할 입력 백엔드. auto 사용 가능한 최고의 백엔드를 사용하려고합니다. (기본값 : auto )recording_mode : 사용할 레코딩 모드. 옵션에는 continuous (활성화 키가 다시 눌러질 때까지 음성 중일 후 auto-restart 기록), voice_activity_detection (음성 중지 후 녹음 중지), press_to_toggle (활성화 키가 다시 누르면 녹음 중지), hold_to_record (활성화 키가 릴리스 될 때 기록 중지)가 포함됩니다. (기본값 : continuous )sound_device : 녹음에 사용할 사운드 장치의 숫자 인덱스. 장치 번호를 찾으려면 python -m sounddevice 실행하십시오. (기본값 : null )sample_rate : 기록에 사용할 HZ의 샘플 속도. (기본값 : 16000 )silence_duration : 녹음을 중지하기 전에 침묵을 기다리는 밀리 초의 지속 시간. (기본값 : 900 )min_duration : 기록을 처리하기 위해 밀리 초의 최소 지속 시간. 이것보다 짧은 녹음은 버려집니다. (기본값 : 100 ) writing_key_press_delay : 전사 된 텍스트를 작성할 때 각 키 프레스 사이의 초 지연. (기본값 : 0.005 )remove_trailing_period : 전사 된 텍스트에서 후행 기간을 제거하려면 true 로 설정하십시오. (기본값 : false )add_trailing_space : true 로 설정하여 전사 된 텍스트 끝에 공간을 추가하십시오. (기본값 : true )remove_capitalization : 전사 된 텍스트를 소문자로 변환하도록 true 로 설정하십시오. (기본값 : false )input_method : 키보드 입력을 시뮬레이션하는 데 사용하는 방법. (기본값 : pynput ) print_to_terminal : 스크립트 상태를 인쇄하고 텍스트를 터미널에 인쇄하도록 true 로 설정하십시오. (기본값 : true )hide_status_window : 작동 중에 상태 창을 숨기도록 true 로 설정하십시오. (기본값 : false )noise_on_completion : 전사가 입력 된 후 노이즈를 재생하도록 true 로 설정하십시오. (기본값 : false )구성 옵션 중 하나가 유효하지 않거나 제공되지 않은 경우 프로그램은 기본값을 사용합니다.
이슈 트래커에서보고 된 모든 문제와 현재 상태를 볼 수 있습니다. 문제가 발생하면 가능한 경우 자세한 설명 및 재생산 단계와 함께 새로운 문제를여십시오.
다음은 가까운 시일 내에 추가 할 기능입니다.
다음은 현재 계획되지 않은 기능입니다.
구현 된 기능은 ChangeLog에서 찾을 수 있습니다.
기부금을 환영합니다! 나는 내 자신의 개인 용도 로이 프로젝트를 만들었고 그것이 많은 관심을 끌기를 기대하지 않았으므로 다른 사람들이 쉽게 기여할 수 있도록 많은 노력을 기울이지 않았습니다. 아이디어 나 제안이 있으면 풀 요청을 열거나 새로운 문제를 만들면 자유롭게하십시오. 시간이 허락하는대로 검토하고 응답하기 위해 최선을 다하겠습니다.
이 프로젝트는 GNU 일반 공개 라이센스에 따라 라이센스가 부여됩니다. 자세한 내용은 라이센스 파일을 참조하십시오.


