whisper writer
v1.0.1
Mise à jour (2024-05-28): Je viens de fusionner dans une réécriture majeure de Whisperwriter! Nous avons migré de l'utilisation tkinter vers l'utilisation de PyQt5 pour l'interface utilisateur, ajouté une nouvelle fenêtre de paramètres pour la configuration, un nouveau mode d'enregistrement continu, une prise en charge d'une API locale, et plus encore! Soyez patient pendant que j'écoute tous les bogues qui pourraient avoir été introduits dans le processus. Si vous rencontrez des problèmes, veuillez ouvrir un nouveau problème!
Whisperwriter est une petite application de discours à texte qui utilise le modèle Whisper d'Openai pour transcrire automatiquement les enregistrements du microphone d'un utilisateur à la fenêtre active.
Une fois commencé, le script s'exécute en arrière-plan et attend qu'un raccourci clavier soit enfoncé ( ctrl+shift+space par défaut). Lorsque le raccourci est pressé, l'application commence à enregistrer à partir de votre microphone. Il y a quatre modes d'enregistrement au choix:
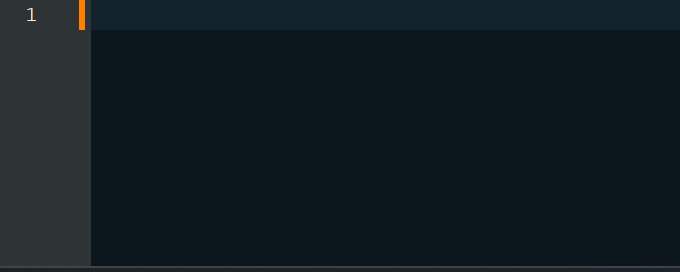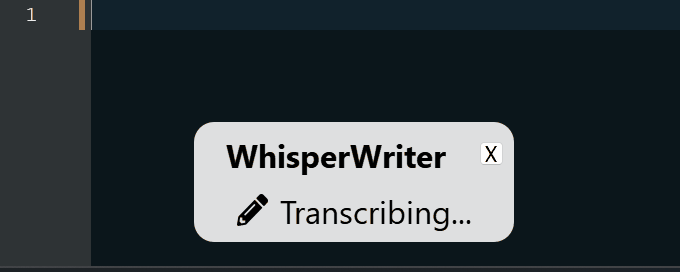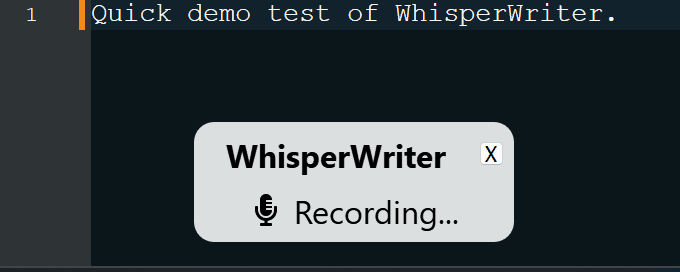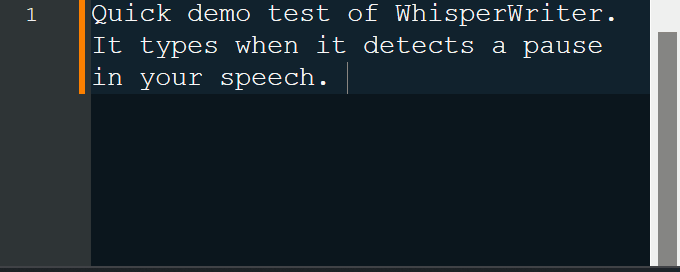
continuous (par défaut): l'enregistrement s'arrêtera après une pause suffisamment longue dans votre discours. L'application transcrira le texte puis recommencera à enregistrer. Pour arrêter d'écouter, appuyez à nouveau sur le raccourci du clavier.voice_activity_detection : l'enregistrement s'arrêtera après une pause suffisamment longue dans votre discours. L'enregistrement ne démarrera pas tant que le raccourci du clavier sera à nouveau pressé.press_to_toggle s'arrêtera lorsque le raccourci du clavier sera appuyé à nouveau. L'enregistrement ne démarrera pas tant que le raccourci du clavier sera à nouveau pressé.hold_to_record se poursuivra jusqu'à la sortie du raccourci clavier. L'enregistrement ne commencera pas avant que le raccourci clavier ne soit retenu. Vous pouvez modifier le raccourci du clavier ( activation_key ) et le mode d'enregistrement dans les options de configuration. Lors de l'enregistrement et de la transcription, une petite fenêtre d'état s'affiche qui montre l'étape actuelle du processus (mais cela peut être désactivé). Une fois la transcription terminée, le texte transcrit sera automatiquement écrit dans la fenêtre active.
La transcription peut être effectuée localement via le package Python plus rapide ou via une demande à l'API d'Openai. Par défaut, l'application utilisera un modèle local, mais vous pouvez le modifier dans les options de configuration. Si vous choisissez d'utiliser l'API, vous devrez soit fournir votre clé API OpenAI ou modifier le point de terminaison de l'URL de base.
Fait amusant: presque l'intégralité de la version initiale du projet a été programmée par paire avec ChatGPT-4 et GitHub Copilot en utilisant le code VS. Pratiquement toutes les lignes, y compris la plupart de cette lecture, ont été écrites par l'IA. Une fois le prototype initial terminé, Whisperwriter a été utilisé pour écrire beaucoup des invites également!
Avant de pouvoir exécuter cette application, vous devrez installer le logiciel suivant:
3.11 : https://www.python.org/downloads/ Si vous souhaitez fonctionner faster-whisper sur votre GPU, vous devrez également installer les bibliothèques NVIDIA suivantes:
Ce qui précède a été tiré directement du réadme faster-whisper :
Remarque: Les dernières versions de ctranslate2 ne soutiennent que CUDA 12. Pour CUDA 11, la solution de contournement actuelle est rétrogradée à la version 3.24.0 de ctranslate2 (cela peut être fait avec pip install --force-reinsall ctranslate2==3.24.0 ).
Il existe plusieurs façons d'installer les bibliothèques NVIDIA mentionnées ci-dessus. La manière recommandée est décrite dans la documentation officielle de NVIDIA, mais nous suggérons également d'autres méthodes d'installation ci-dessous.
Les bibliothèques (Cublin, Cudnn) sont installées dans ces images officielles de Nvidia Cuda Docker: nvidia/cuda:12.0.0-runtime-ubuntu20.04 ou nvidia/cuda:12.0.0-runtime-ubuntu22.04 .
pip (Linux uniquement) Sur Linux, ces bibliothèques peuvent être installées avec pip . Notez que LD_LIBRARY_PATH doit être défini avant de lancer Python.
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
export LD_LIBRARY_PATH= ` python3 -c ' import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__)) ' ` Remarque : La version 9+ de nvidia-cudnn-cu12 semble entraîner des problèmes en raison de sa dépendance à CUDNN 9 (plus rapide, ne soutient pas actuellement CUDNN 9). Assurez-vous que votre version du package Python est pour CUDNN 8.
Whisper-standalone-win de Purfview fournit les bibliothèques NVIDIA requises pour Windows & Linux dans une seule archive. Décompressez les archives et placez les bibliothèques dans un répertoire inclus dans le PATH .
Pour configurer et exécuter le projet, suivez ces étapes:
git clone https://github.com/savbell/whisper-writer
cd whisper-writer
python -m venv venv
# For Linux and macOS:
source venv/bin/activate
# For Windows:
venvScriptsactivate
pip install -r requirements.txt
python run.py
Lors de la première exécution, une fenêtre de paramètres doit apparaître. Une fois configuré et enregistré, une autre fenêtre s'ouvrira. Appuyez sur "Démarrer" pour activer l'écouteur du clavier. Appuyez sur la touche d'activation ( ctrl+shift+space par défaut) pour commencer l'enregistrement et la transcription à la fenêtre active.
Whisperwriter utilise un fichier de configuration pour personnaliser son comportement. Pour configurer la configuration, ouvrez la fenêtre Paramètres:
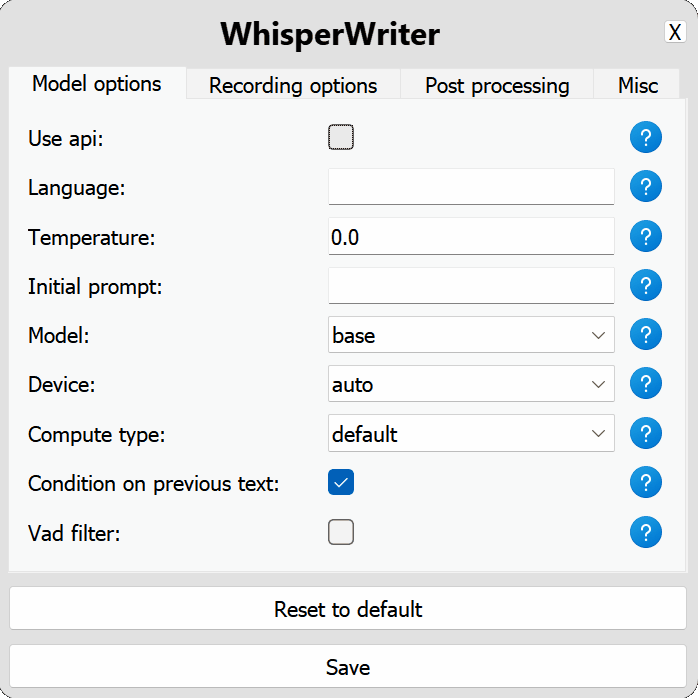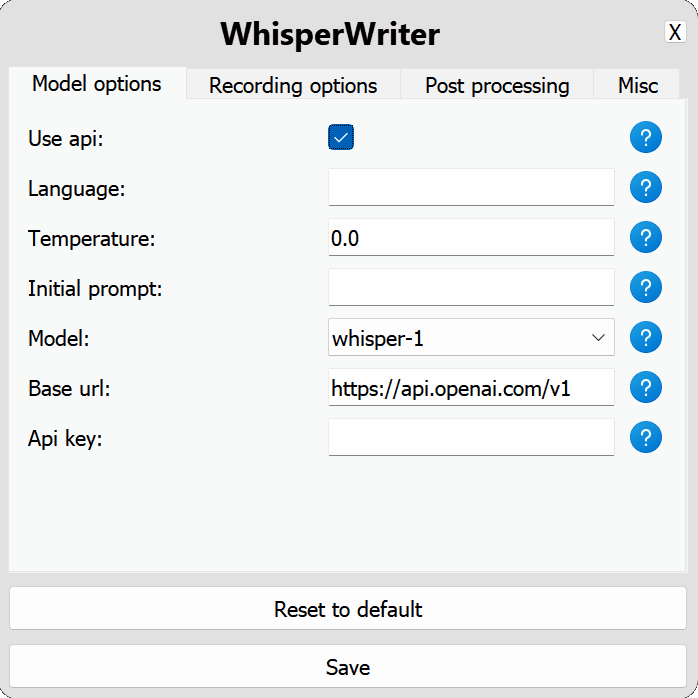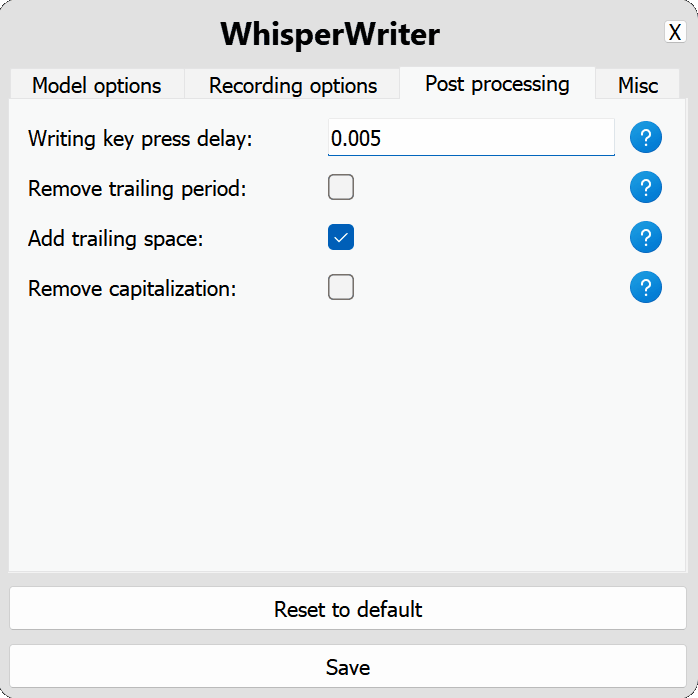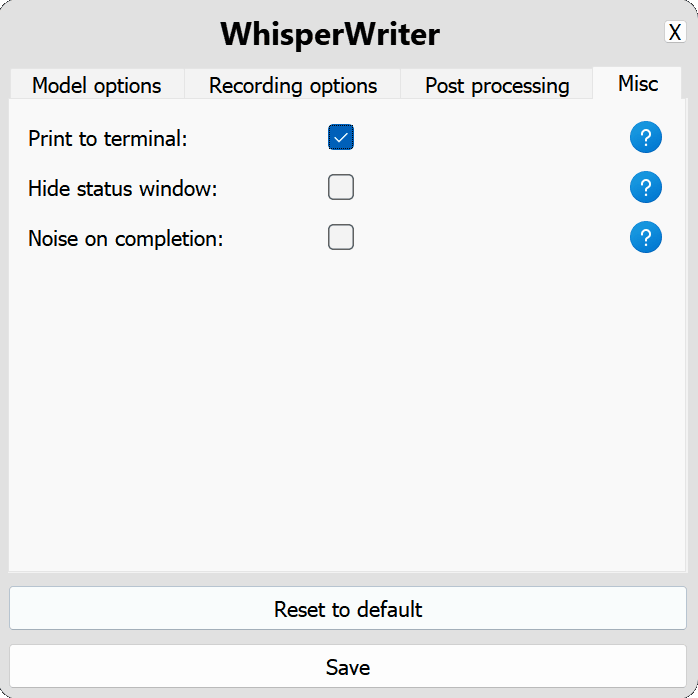
use_api : basculer pour choisir d'utiliser l'API OpenAI ou un modèle de chuchotement local pour la transcription. (Par défaut: false )
common : options communes aux modèles API et locaux.
language : le code linguistique de la transcription au format ISO-639-1. (Par défaut: null )temperature : contrôle l'aléatoire de la sortie de transcription. Des valeurs plus faibles rendent la sortie plus ciblée et déterministe. (Par défaut: 0.0 )initial_prompt : une chaîne utilisée comme invite initiale pour conditionner la transcription. Plus d'informations: Openai Invite Guide. (Par défaut: null ) api : Options de configuration pour l'API OpenAI. Voir la documentation de l'API OpenAI pour plus d'informations.
model : le modèle à utiliser pour la transcription. Actuellement, seul whisper-1 est disponible. (Par défaut: whisper-1 )base_url : l'URL de base de l'API. Peut être modifié pour utiliser un point de terminaison API local, comme localai. (Par défaut: https://api.openai.com/v1 )api_key : Votre clé API pour l'API OpenAI. Requis pour l'utilisation non locale de l'API. (Par défaut: null ) local : Options de configuration pour le modèle Whisper local.
model : le modèle à utiliser pour la transcription. Les modèles plus grands offrent une meilleure précision mais sont plus lents. Voir les modèles et les langues disponibles. (Par défaut: base )device : l'appareil pour exécuter le modèle de chuchotement local. Utilisez cuda pour les GPU NVIDIA, cpu pour le traitement CPU uniquement ou auto pour permettre au système de choisir automatiquement le meilleur appareil disponible. (Par défaut: auto )compute_type : le type de calcul à utiliser pour le modèle de chuchotement local. Plus d'informations sur la quantification ici. (Par défaut: default )condition_on_previous_text : défini sur true pour utiliser le texte transcrit précédemment comme invite pour la prochaine demande de transcription. (Par défaut: true )vad_filter : Définissez true pour utiliser un filtre de détection d'activité vocale (VAD) pour supprimer le silence de l'enregistrement. (Par défaut: false )model_path : Le chemin du modèle de chuchotement local. S'il n'est pas spécifié, le modèle par défaut sera téléchargé. (Par défaut: null ) activation_key : le raccourci du clavier pour activer le processus d'enregistrement et de transcription. Séparez les touches avec A + . (Par défaut: ctrl+shift+space )input_backend : le backend d'entrée à utiliser pour détecter les appuyés sur les touches. auto essaiera d'utiliser le meilleur backend disponible. (Par défaut: auto )recording_mode : le mode d'enregistrement à utiliser. Les options incluent continuous (enregistrement automatique-re-start après une pause dans le discours jusqu'à ce que la touche d'activation soit à nouveau enfoncée), voice_activity_detection (arrêtez l'enregistrement après la pause dans le discours), press_to_toggle (arrêt d'enregistrement lorsque la touche d'activation est à nouveau appuyée sur la hold_to_record ). (Par défaut: continuous )sound_device : l'index numérique du périphérique sonore à utiliser pour l'enregistrement. Pour trouver des numéros d'appareil, exécutez python -m sounddevice . (Par défaut: null )sample_rate : La fréquence d'échantillonnage en Hz à utiliser pour l'enregistrement. (Par défaut: 16000 )silence_duration : La durée en millisecondes pour attendre le silence avant d'arrêter l'enregistrement. (Par défaut: 900 )min_duration : la durée minimale en millisecondes pour un enregistrement à traiter. Des enregistrements plus courts que celui-ci seront jetés. (Par défaut: 100 ) writing_key_press_delay : le retard en secondes entre chaque touche, appuyez sur le texte transcrit. (Par défaut: 0.005 )remove_trailing_period : réglé sur true pour supprimer la période de fuite du texte transcrit. (Par défaut: false )add_trailing_space : défini sur true pour ajouter un espace à la fin du texte transcrit. (Par défaut: true )remove_capitalization : réglé sur true pour convertir le texte transcrit en minuscules. (Par défaut: false )input_method : la méthode à utiliser pour simuler l'entrée du clavier. (Par défaut: pynput ) print_to_terminal : défini sur true pour imprimer l'état du script et le texte transcrit au terminal. (Par défaut: true )hide_status_window : Définissez sur true pour masquer la fenêtre d'état pendant l'opération. (Par défaut: false )noise_on_completion : réglé sur true pour jouer un bruit une fois la transcription à saisir. (Par défaut: false )Si l'une des options de configuration n'est pas valide ou non fournie, le programme utilisera les valeurs par défaut.
Vous pouvez voir tous les problèmes signalés et leur statut actuel dans notre tracker de problèmes. Si vous rencontrez un problème, veuillez ouvrir un nouveau problème avec une description détaillée et des étapes de reproduction, si possible.
Vous trouverez ci-dessous des fonctionnalités que je prévois d'ajouter dans un avenir proche:
Vous trouverez ci-dessous les fonctionnalités qui ne sont pas prévues:
Les fonctionnalités implémentées peuvent être trouvées dans le Changelog.
Les contributions sont les bienvenues! J'ai créé ce projet pour mon usage personnel et je ne m'attendais pas à ce qu'il attire beaucoup d'attention, donc je n'ai pas fait beaucoup d'efforts dans les tests ou facilite la contribution des autres. Si vous avez des idées ou des suggestions, n'hésitez pas à ouvrir une demande de traction ou à créer un nouveau problème. Je ferai de mon mieux pour revoir et répondre comme le temps le permet.
Ce projet est autorisé en vertu de la licence publique générale de GNU. Voir le fichier de licence pour plus de détails.


