คู่มือการเรียนรู้ระดับการผลิตอย่างลึกซึ้ง?
- แปลเป็นภาษาจีน
️ใหม่: การสัมภาษณ์การเรียนรู้ของเครื่องจักร
️หมายเหตุ: repo นี้อยู่ภายใต้การพัฒนาอย่างต่อเนื่องและข้อเสนอแนะและการสนับสนุนทั้งหมดยินดีต้อนรับมาก?
การปรับใช้รูปแบบการเรียนรู้เชิงลึกในการผลิตอาจเป็นเรื่องที่ท้าทายเนื่องจากมันอยู่ไกลเกินกว่ารูปแบบการฝึกอบรมที่มีประสิทธิภาพที่ดี ส่วนประกอบที่แตกต่างหลายอย่างจำเป็นต้องได้รับการออกแบบและพัฒนาเพื่อปรับใช้ระบบการเรียนรู้ระดับลึกระดับการผลิต (เห็นด้านล่าง):
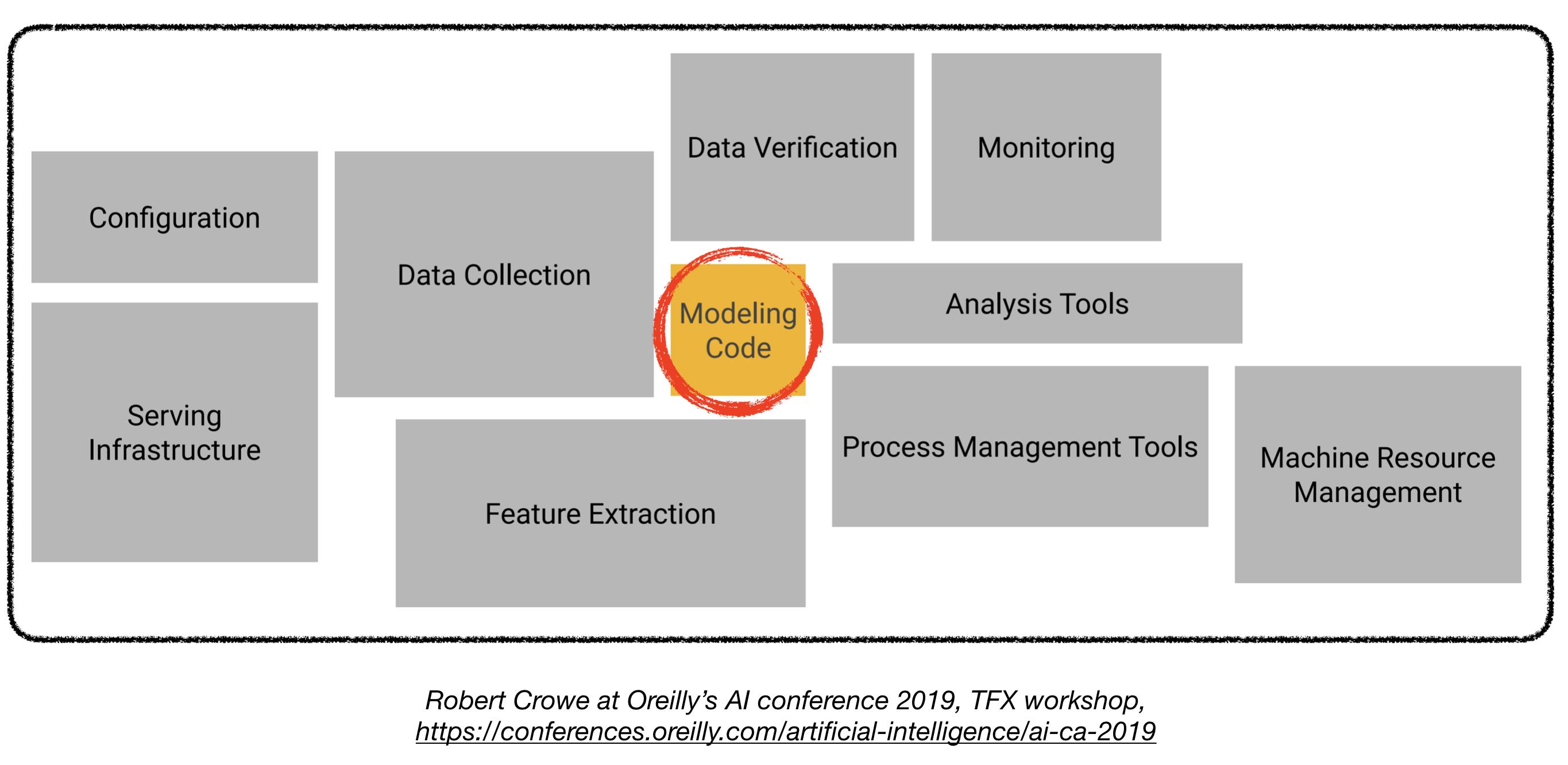
repo นี้มีวัตถุประสงค์เพื่อเป็นแนวทางทางวิศวกรรมสำหรับการสร้างระบบการเรียนรู้ระดับลึกระดับการผลิตซึ่งจะถูกนำไปใช้ในแอพพลิเคชั่นในโลกแห่งความเป็นจริง
วัสดุที่นำเสนอที่นี่ได้รับการยืมมาจากการเรียนรู้อย่างลึกล้ำการเรียนรู้อย่างลึกล้ำ bootcamp (โดย Pieter Abbeel ที่ UC Berkeley, Josh Tobin ที่ Openai และ Sergey Karayev ที่ Turnitin), TFX Workshop โดย Robert Crowe และ Pipeline
โครงการเรียนรู้ของเครื่องจักร
สนุก ? ความจริง: 85% ของโครงการ AI ล้มเหลว 1 เหตุผลที่เป็นไปได้รวมถึง:
- เทคนิคที่ไม่สามารถทำได้หรือมีขอบเขตไม่ดี
- อย่าก้าวกระโดดในการผลิต
- เกณฑ์ความสำเร็จที่ไม่ชัดเจน (ตัวชี้วัด)
- การจัดการทีมที่ไม่ดี
1. ML Projects Lifecycle
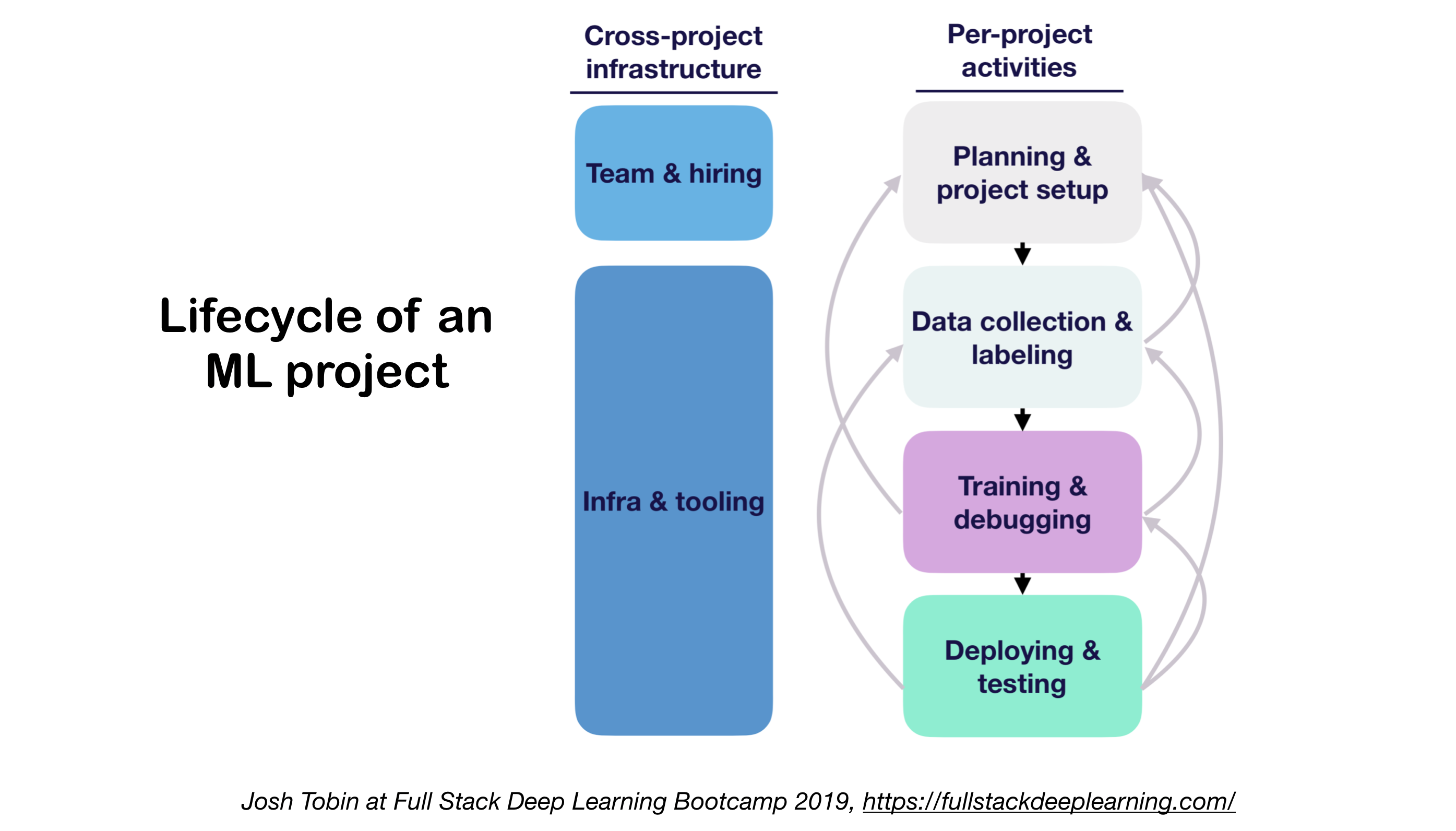
- ความสำคัญของการทำความเข้าใจสถานะของศิลปะในโดเมนของคุณ:
- ช่วยให้เข้าใจสิ่งที่เป็นไปได้
- ช่วยให้รู้ว่าจะลองทำอะไรต่อไป
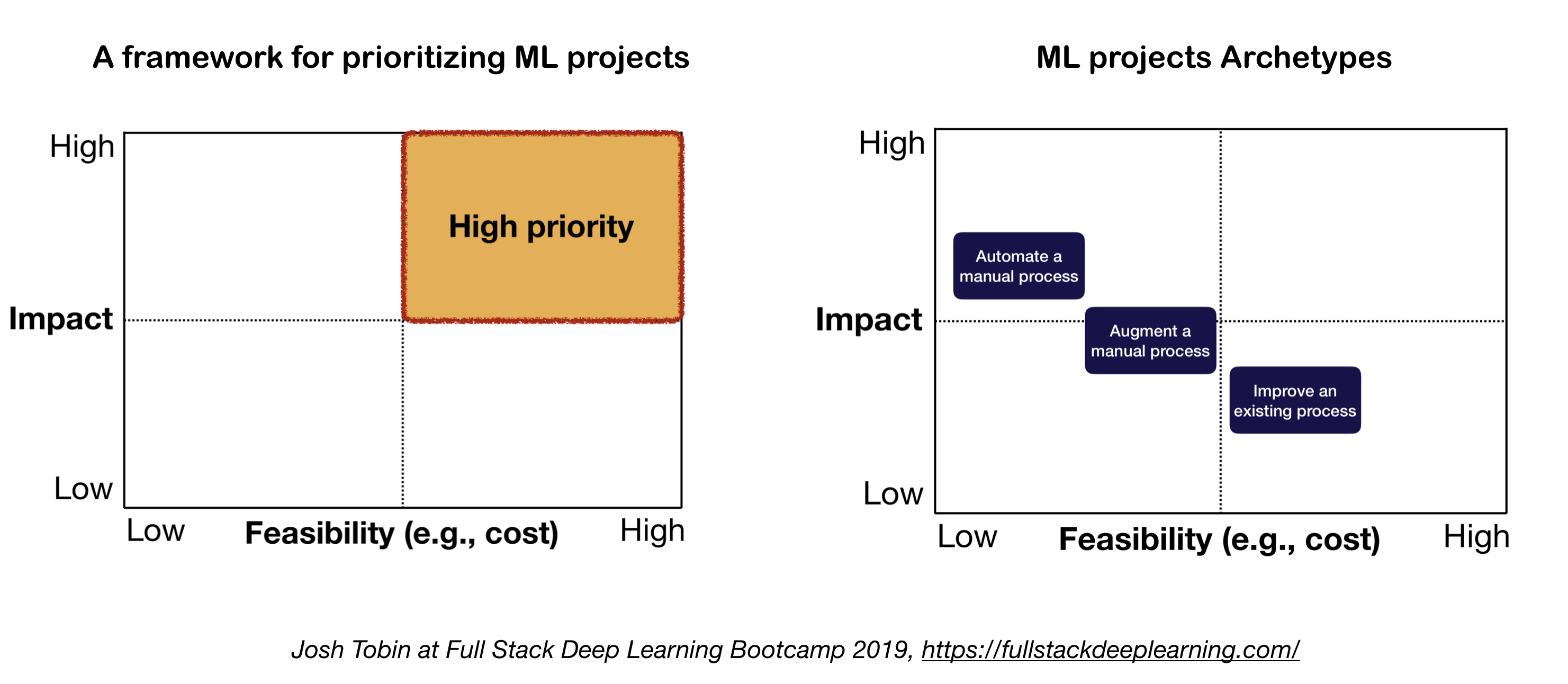
2. แบบจำลองทางจิตสำหรับโครงการ ML
ปัจจัยสำคัญสองประการที่ควรพิจารณาเมื่อกำหนดและจัดลำดับความสำคัญของโครงการ ML:
- ผลกระทบสูง:
- ส่วนที่ซับซ้อนของท่อส่งของคุณ
- ที่ "การทำนายราคาถูก" มีค่า
- โดยอัตโนมัติกระบวนการที่ซับซ้อนด้วยตนเองนั้นมีค่า
- ราคาถูก:
- ค่าใช้จ่ายขับเคลื่อนโดย:
- ความพร้อมใช้งานข้อมูล
- ข้อกำหนดด้านประสิทธิภาพ: ค่าใช้จ่ายมีแนวโน้มที่จะปรับขนาดเป็นเชิงมากในความต้องการความแม่นยำ
- ปัญหาปัญหา:
- ปัญหาที่ยากบางอย่าง ได้แก่ : การเรียนรู้ที่ไม่ได้รับการดูแลการเรียนรู้การเสริมแรงและการเรียนรู้บางประเภท
Pipeline สแต็คเต็มรูปแบบ
รูปต่อไปนี้แสดงภาพรวมระดับสูงของส่วนประกอบที่แตกต่างกันในระบบการเรียนรู้ระดับลึกระดับการผลิต:
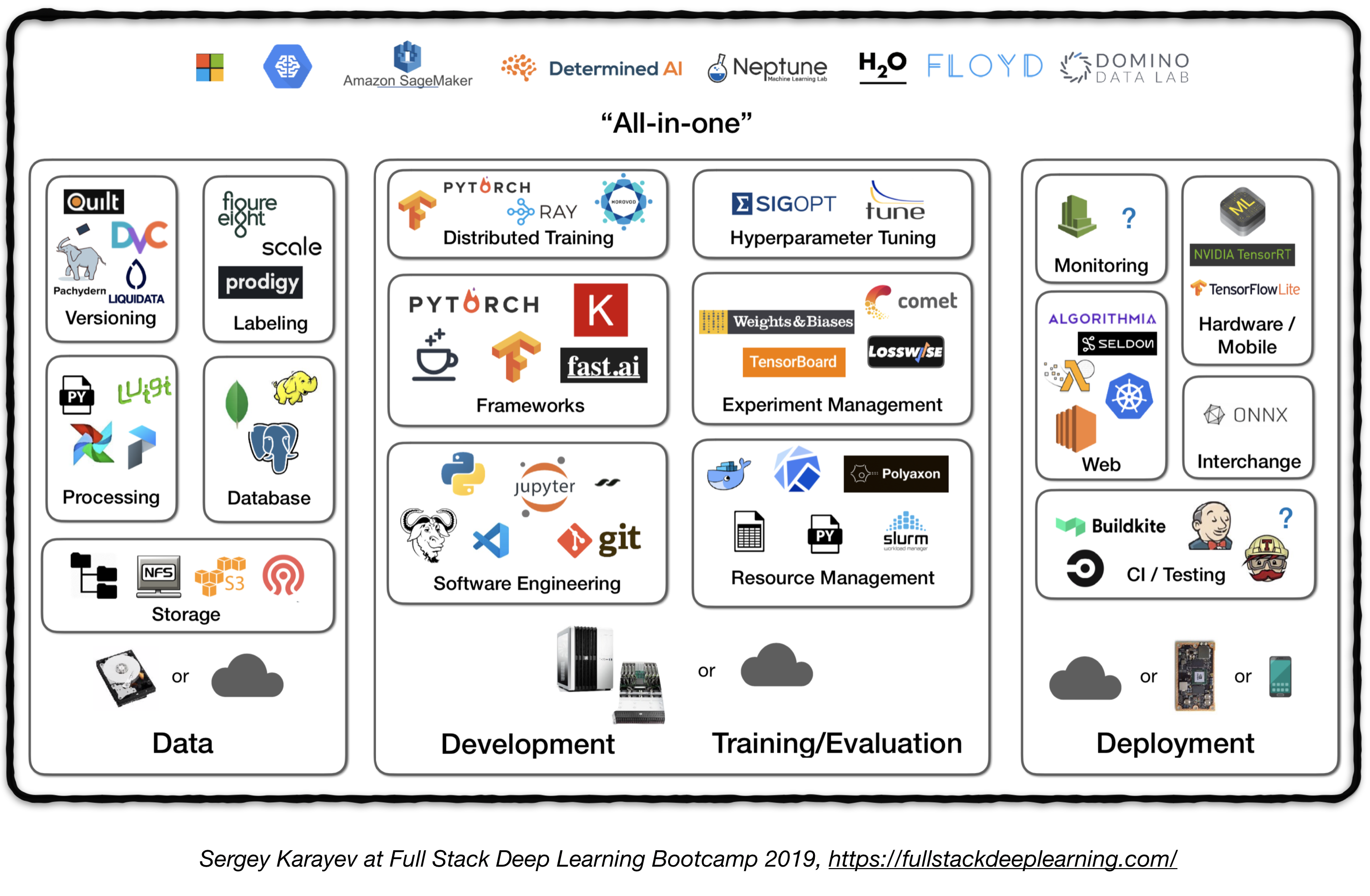
ในต่อไปนี้เราจะผ่านแต่ละโมดูลและแนะนำชุดเครื่องมือและเฟรมเวิร์กรวมถึงแนวทางปฏิบัติที่ดีที่สุดจากผู้ปฏิบัติงานที่เหมาะสมกับแต่ละองค์ประกอบ
1. การจัดการข้อมูล
1.1 แหล่งข้อมูล
- การเรียนรู้อย่างลึก
- การติดฉลากข้อมูลของตัวเองมีค่าใช้จ่ายสูง!
- นี่คือแหล่งข้อมูลบางส่วนสำหรับข้อมูล:
- ข้อมูลโอเพ่นซอร์ส (ดีเริ่มต้นด้วย แต่ไม่ใช่ข้อได้เปรียบ)
- การเพิ่มข้อมูล (ต้องใช้สำหรับการมองเห็นคอมพิวเตอร์ตัวเลือกสำหรับ NLP)
- ข้อมูลสังเคราะห์ (เกือบจะคุ้มค่าที่จะเริ่มต้นด้วย esp. ใน NLP)
1.2 การติดฉลากข้อมูล
- ต้องใช้: แยกซอฟต์แวร์สแต็ก (แพลตฟอร์มการติดฉลาก), แรงงานชั่วคราวและ QC
- แหล่งแรงงานสำหรับการติดฉลาก:
- crowdsourcing (Mechanical Turk): ราคาถูกและปรับขนาดได้น่าเชื่อถือน้อยกว่าต้องการ QC
- การจ้างคำอธิบายประกอบของตัวเอง: ต้องการ QC น้อยกว่าราคาแพงและช้าลง
- บริษัท บริการติดฉลากข้อมูล:
- แพลตฟอร์มการติดฉลาก:
- Diffgram: ซอฟต์แวร์ข้อมูลการฝึกอบรม (วิสัยทัศน์คอมพิวเตอร์)
- อัจฉริยะ: เครื่องมือคำอธิบายประกอบที่ขับเคลื่อนโดยการเรียนรู้ที่ใช้งานอยู่ (โดยนักพัฒนา Spacy) ข้อความและรูปภาพ
- Hive: AI เป็นแพลตฟอร์มบริการสำหรับการมองเห็นคอมพิวเตอร์
- อย่างเชี่ยวชาญ: แพลตฟอร์มการมองเห็นคอมพิวเตอร์ทั้งหมด
- LABLEBOX: VISION คอมพิวเตอร์
- สเกลแพลตฟอร์มข้อมูล AI (คอมพิวเตอร์วิสัยทัศน์ & NLP)
1.3. การจัดเก็บข้อมูล
- ตัวเลือกการจัดเก็บข้อมูล:
- Object Store : เก็บข้อมูลไบนารี (รูปภาพไฟล์เสียงข้อความที่บีบอัด)
- Amazon S3
- Ceph Object Store
- ฐานข้อมูล : จัดเก็บข้อมูลเมตา (พา ธ ไฟล์ป้ายกำกับกิจกรรมผู้ใช้ ฯลฯ )
- Postgres เป็นตัวเลือกที่เหมาะสมสำหรับแอปพลิเคชันส่วนใหญ่ด้วย SQL ที่ดีที่สุดในชั้นเรียนและการสนับสนุนที่ยอดเยี่ยมสำหรับ JSON ที่ไม่มีโครงสร้าง
- Data Lake : เพื่อรวมคุณสมบัติที่ไม่สามารถหาได้จากฐานข้อมูล (เช่นบันทึก)
- Feature Store : ร้านค้าการเข้าถึงและการแบ่งปันคุณสมบัติการเรียนรู้ของเครื่อง (การแยกคุณสมบัติอาจมีราคาแพงและแทบจะเป็นไปไม่ได้ที่จะปรับขนาดดังนั้นการใช้คุณสมบัติใหม่โดยรุ่นและทีมที่แตกต่างกันเป็นกุญแจสำคัญในทีม ML ที่มีประสิทธิภาพสูง)
- งานเลี้ยง (Google Cloud, Open Source)
- Michelangelo Palette (Uber)
- ข้อเสนอแนะ: ในเวลาการฝึกอบรมคัดลอกข้อมูลลงใน ระบบไฟล์ ท้องถิ่นหรือเครือข่าย (NFS) 1
1.4. การกำหนดเวอร์ชันข้อมูล
- เป็น "ต้อง" สำหรับรุ่น ML ที่ปรับใช้:
โมเดล ML ที่ปรับใช้เป็นรหัสชิ้นส่วนข้อมูลชิ้นส่วน 1 ไม่มีการกำหนดเวอร์ชันข้อมูลหมายความว่าไม่มีการกำหนดเวอร์ชันแบบจำลอง - แพลตฟอร์มการกำหนดเวอร์ชันข้อมูล:
- DVC: ระบบควบคุมเวอร์ชันโอเพ่นซอร์สสำหรับโครงการ ML
- Pachyderm: การควบคุมเวอร์ชันสำหรับข้อมูล
- DOLT: ฐานข้อมูล SQL พร้อมการควบคุมเวอร์ชัน GIT สำหรับข้อมูลและสคีมา
1.5. การประมวลผลข้อมูล
- ข้อมูลการฝึกอบรมสำหรับรูปแบบการผลิตอาจมาจากแหล่งข้อมูลที่แตกต่างกันรวมถึง ข้อมูลที่เก็บไว้ใน DB และที่เก็บวัตถุ การประมวลผลบันทึก และ ผลลัพธ์ของตัวแยกประเภทอื่น ๆ
- มีการพึ่งพาระหว่างงานแต่ละครั้งจะต้องเริ่มต้นหลังจากการพึ่งพาเสร็จสิ้น ตัวอย่างเช่นการฝึกอบรมข้อมูลบันทึกใหม่ต้องใช้ขั้นตอนการประมวลผลล่วงหน้าก่อนการฝึกอบรม
- MakeFiles ไม่สามารถปรับขนาดได้ "Workflow Manager" กลายเป็นสิ่งจำเป็นในเรื่องนี้
- เวิร์กโฟลว์ออเคสตร้า:
- Luigi โดย Spotify
- Airblow โดย Airbnb: ไดนามิกขยายได้สง่างามและปรับขนาดได้ (ใช้กันอย่างแพร่หลายมากที่สุด)
- เวิร์กโฟลว์ DAG
- การดำเนินการตามเงื่อนไขที่แข็งแกร่ง: ลองอีกครั้งในกรณีที่ล้มเหลว
- Pusher รองรับภาพ Docker ด้วยการให้บริการ tensorflow
- เวิร์กโฟลว์ทั้งหมดในไฟล์. py เดียว
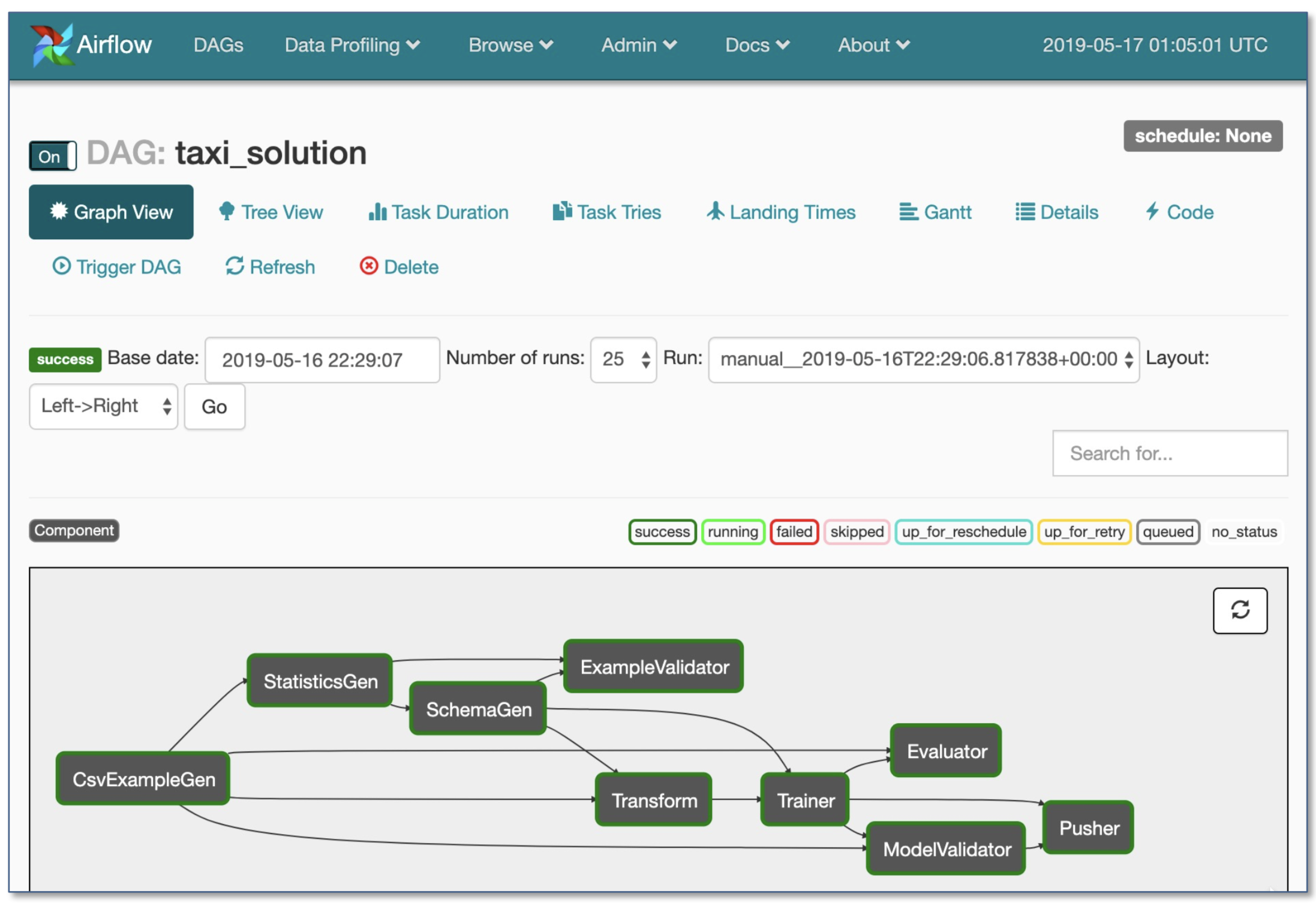
2. การพัฒนาการฝึกอบรมและการประเมินผล
2.1. วิศวกรรมซอฟต์แวร์
- ภาษาผู้ชนะ: Python
- บรรณาธิการ:
- vim
- Emacs
- VS Code (แนะนำโดยผู้เขียน): การจัดเตรียม GIT ในตัวและ Diff, Code Lint, โครงการเปิดจากระยะไกลผ่าน SSH
- สมุดบันทึก: ยอดเยี่ยมเป็นจุดเริ่มต้นของโครงการยากที่จะปรับขนาด (ความจริงสนุก: สถาปัตยกรรมที่ขับเคลื่อนด้วยโน้ตบุ๊กของ Netflix เป็นข้อยกเว้นซึ่งขึ้นอยู่กับ Nteract Suites ทั้งหมด)
- NTeract: UI ที่ใช้ React-Gen-Gens สำหรับสมุดบันทึก Jupyter
- Papermill: เป็นไลบรารี Nteract ที่สร้างขึ้นสำหรับ การปรับพารามิเตอร์ การดำเนินการ และ การวิเคราะห์ สมุดบันทึก Jupyter
- ผู้โดยสาร: โครงการ NTERACT อื่นที่ให้การแสดงสมุดบันทึกแบบอ่านอย่างเดียว (เช่นจาก Buckets S3)
- Streamlit: เครื่องมือวิทยาศาสตร์ข้อมูลแบบโต้ตอบกับ Applets
- คำแนะนำคำนวณ 1 :
- สำหรับ บุคคล หรือ startups :
- การพัฒนา: พีซีสถาปัตยกรรม 4x ทัวริง
- การฝึกอบรม/การประเมินผล: ใช้พีซี GPU 4X เดียวกัน เมื่อทำการทดลองจำนวนมากซื้อเซิร์ฟเวอร์ที่ใช้ร่วมกันหรือใช้อินสแตนซ์คลาวด์
- สำหรับ บริษัท ขนาดใหญ่:
- การพัฒนา: ซื้อพีซี 4x ทัวริงสถาปัตยกรรมต่อนักวิทยาศาสตร์มิลลิลิตรหรือให้พวกเขาใช้อินสแตนซ์ V100
- การฝึกอบรม/การประเมินผล: ใช้อินสแตนซ์คลาวด์ที่มีการจัดเตรียมและการจัดการความล้มเหลวที่เหมาะสม
- ผู้ให้บริการคลาวด์:
- GCP: ตัวเลือกในการเชื่อมต่อ GPU กับอินสแตนซ์ใด ๆ + มี TPUS
- AWS:
2.2. การจัดการทรัพยากร
- การจัดสรรทรัพยากรฟรีให้กับโปรแกรม
- ตัวเลือกการจัดการทรัพยากร:
- Old School Cluster กำหนดตารางงาน (เช่น Slurm Workload Manager)
- Docker + Kubernetes
- Kubeflow
- polyaxon (คุณสมบัติที่ชำระแล้ว)
2.3. เฟรมเวิร์ก DL
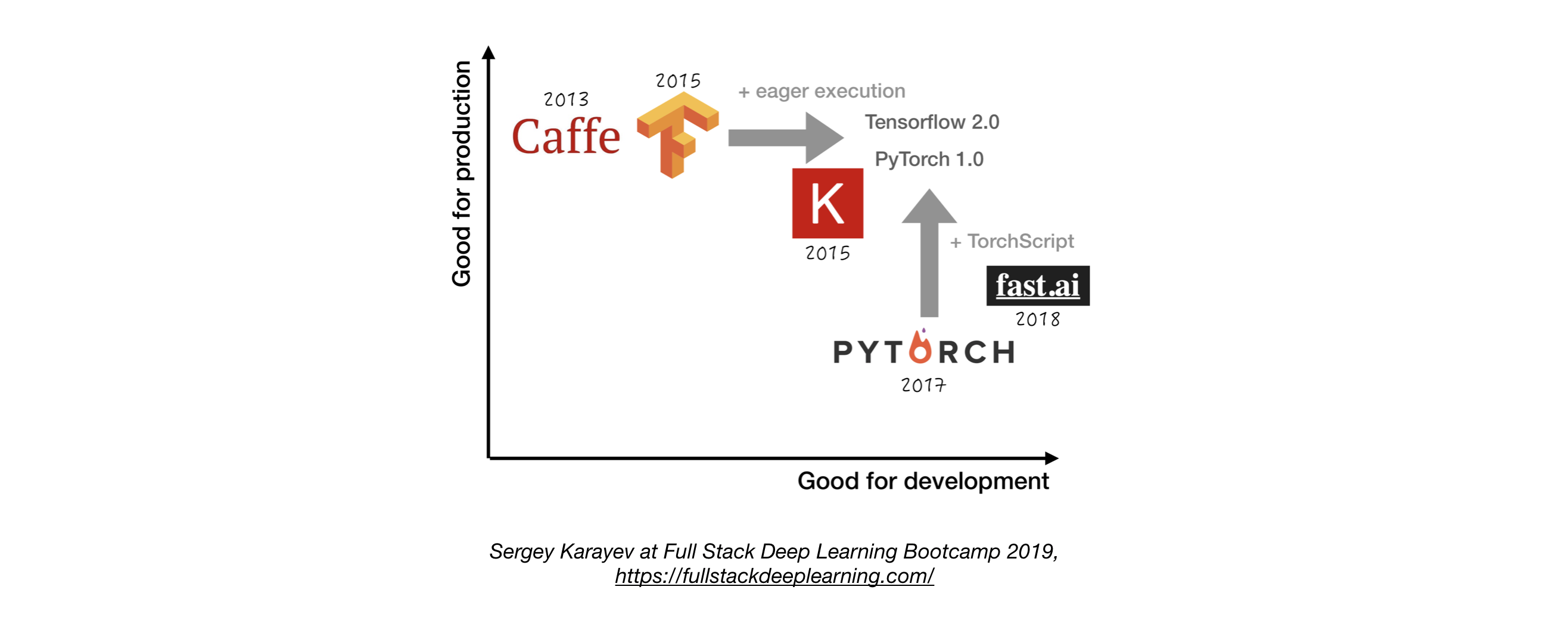
- เว้นแต่จะมีเหตุผลที่ดีที่จะไม่ใช้ tensorflow/keras หรือ pytorch 1
- รูปต่อไปนี้แสดงการเปรียบเทียบระหว่างกรอบการทำงานที่แตกต่างกันเกี่ยวกับวิธีที่พวกเขายืนหยัดเพื่อ "การพัฒนา" และ "การผลิต"
2.4. การจัดการทดลอง
- กลยุทธ์การพัฒนาการฝึกอบรมและการประเมินผล:
- เริ่ม ง่าย เสมอ
- ฝึกอบรมรุ่นเล็ก ๆ ในชุดเล็ก ๆ เฉพาะในกรณีที่ใช้งานได้ให้ปรับขนาดเป็นข้อมูลและรุ่นที่ใหญ่ขึ้นและการปรับจูนไฮเปอร์พารามิเตอร์!
- เครื่องมือการจัดการทดลอง:
- บอร์ดบอร์ด
- ให้การสร้างภาพและเครื่องมือที่จำเป็นสำหรับการทดลอง ML
- Losswise (การตรวจสอบ ML)
- ดาวหาง: ให้คุณติดตามรหัสการทดลองและผลลัพธ์ในโครงการ ML
- น้ำหนักและอคติ: บันทึกและแสดงภาพทุกรายละเอียดของการวิจัยของคุณด้วยการทำงานร่วมกันที่ง่าย
- การติดตาม MLFLOW: สำหรับพารามิเตอร์การบันทึก, เวอร์ชันรหัส, ตัวชี้วัดและไฟล์เอาต์พุตรวมถึงการสร้างภาพผลลัพธ์
- การติดตามการทดลองอัตโนมัติด้วยรหัสหนึ่งบรรทัดใน Python
- การเปรียบเทียบการทดลองด้านข้างเคียงข้างกัน
- การปรับพารามิเตอร์ไฮเปอร์
- รองรับงานตาม Kubernetes
2.5. การปรับจูนพารามิเตอร์
แนวทาง:
- การค้นหากริด
- การค้นหาแบบสุ่ม
- การเพิ่มประสิทธิภาพแบบเบย์
- อัลกอริทึมการลดลงครึ่งหนึ่งและอะซิงโครนัสแบบอะซิงโครนัส (ASHA)
- การฝึกอบรมตามประชากร
แพลตฟอร์ม:
- Raytune: Ray Tune เป็นห้องสมุด Python สำหรับการปรับจูนไฮเปอร์พารามิเตอร์ในทุกระดับ (โดยมุ่งเน้นไปที่การเรียนรู้อย่างลึกซึ้งและการเรียนรู้การเสริมแรงอย่างลึกซึ้ง) รองรับกรอบการเรียนรู้ของเครื่องใด ๆ รวมถึง Pytorch, Xgboost, MXNet และ Keras
- Katib: ระบบพื้นเมืองของ Kubernete สำหรับการปรับแต่ง hyperparameter และการค้นหาสถาปัตยกรรมประสาทซึ่งได้รับแรงบันดาลใจจาก [Google Vizier] (https://static.googleusercontent.com/media/ research.google.com/ja//pubs/archive/ BCB15507F4B52991A0783013DF4222240E942381.pdf) และรองรับเฟรมเวิร์ก ML/DL หลายเฟรม (เช่น TensorFlow, MXNet และ Pytorch)
- Hyperas: wrapper ง่าย ๆ รอบ Hyperopt สำหรับ Keras พร้อมสัญลักษณ์เทมเพลตง่าย ๆ เพื่อกำหนดช่วงพารามิเตอร์ไฮเปอร์เพื่อปรับแต่ง
- SIGOPT: แพลตฟอร์มการเพิ่มประสิทธิภาพระดับองค์กรที่ปรับขนาดได้
- การกวาดจาก [น้ำหนักและอคติ] (https://www.wandb.com/): พารามิเตอร์ไม่ได้ระบุไว้อย่างชัดเจนโดยนักพัฒนา แต่พวกเขาจะประมาณและเรียนรู้โดยรูปแบบการเรียนรู้ของเครื่อง
- Keras Tuner: เครื่องรับสัญญาณ Hyperparameter สำหรับ Keras โดยเฉพาะสำหรับ tf.keras กับ Tensorflow 2.0
2.6. การฝึกอบรมแบบกระจาย
- Data Parallelism: ใช้เมื่อเวลาวนซ้ำยาวเกินไป (ทั้งการสนับสนุน TensorFlow และ Pytorch)
- โมเดลขนาน: เมื่อโมเดลไม่พอดีกับ GPU เดียว
- วิธีแก้ปัญหาอื่น ๆ :
3. การแก้ไขปัญหา [TBD]
4. การทดสอบและการปรับใช้
4.1. การทดสอบและ CI/CD
ซอฟต์แวร์การเรียนรู้การเรียนรู้ของเครื่องต้องการชุดทดสอบชุดทดสอบที่หลากหลายกว่าซอฟต์แวร์แบบดั้งเดิม:
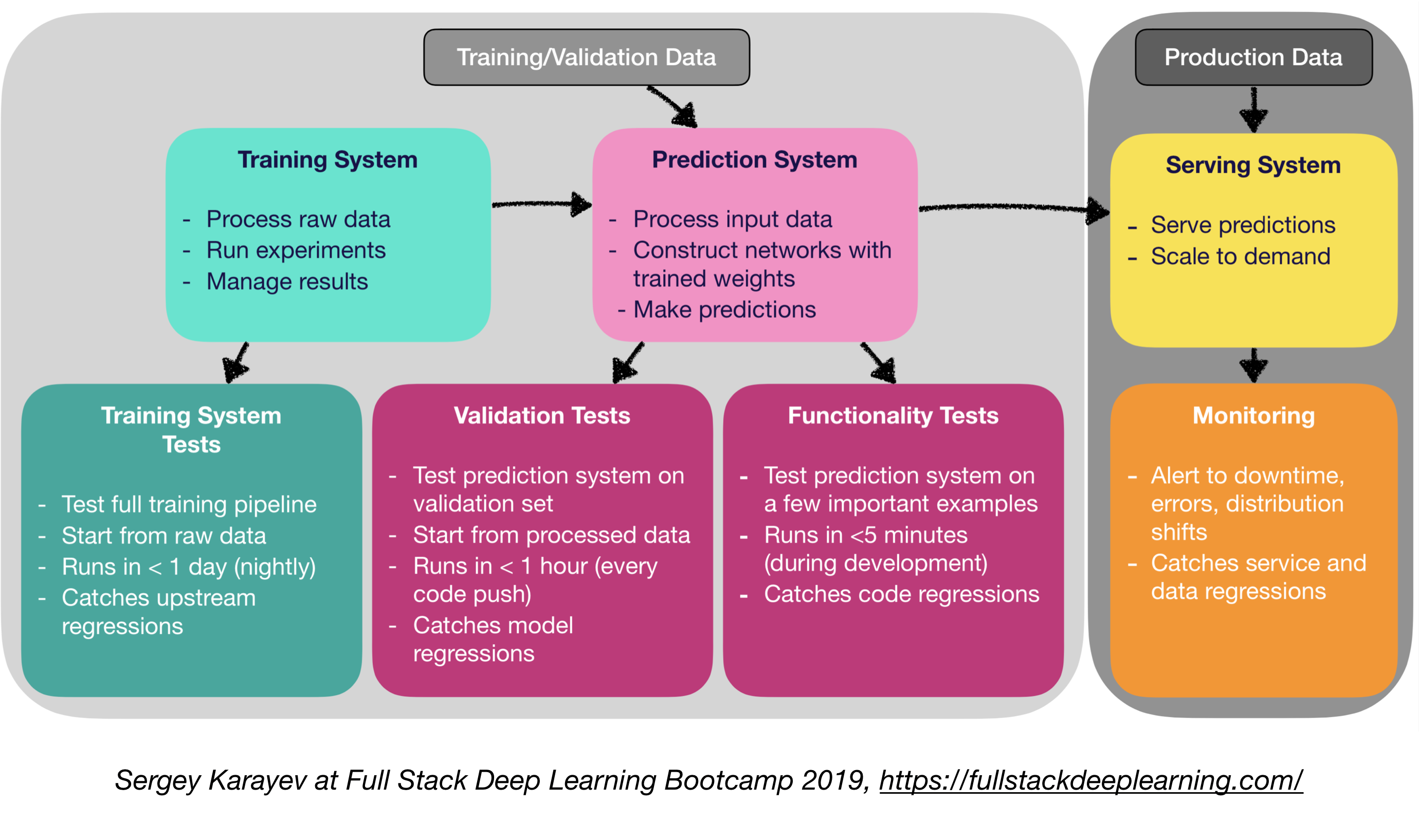
- การทดสอบหน่วยและการรวม:
- ประเภทของการทดสอบ:
- การทดสอบระบบการฝึกอบรม: การทดสอบไปป์ไลน์การฝึกอบรม
- การทดสอบการตรวจสอบความถูกต้อง: ระบบทำนายการทดสอบในชุดการตรวจสอบความถูกต้อง
- การทดสอบฟังก์ชั่น: ระบบการทดสอบการทดสอบในตัวอย่างสำคัญบางประการ
- การรวมอย่างต่อเนื่อง: รันการทดสอบหลังจากการเปลี่ยนรหัสใหม่แต่ละครั้งผลักไปยัง repo
- SaaS สำหรับการรวมอย่างต่อเนื่อง:
- Argo: Open Source Kubernetes Native Workflow Engine สำหรับการจัดเตรียมงานแบบขนาน (รวมถึงเวิร์กโฟลว์กิจกรรม CI และ CD)
- Circleci: การสนับสนุนแบบรวมภาษา, สภาพแวดล้อมที่กำหนดเอง, การจัดสรรทรัพยากรที่ยืดหยุ่น, ใช้โดย Instacart, Lyft และ Stackshare
- Travis CI
- BuildKite: Builds ที่รวดเร็วและเสถียรตัวแทนโอเพนซอร์สทำงานบนเครื่องเกือบทุกเครื่องและสถาปัตยกรรมอิสระในการใช้เครื่องมือและบริการของคุณเอง
- เจนกินส์: ระบบสร้างโรงเรียนเก่า
4.2. การปรับใช้เว็บ
- ประกอบด้วย ระบบการทำนาย และ ระบบการให้บริการ
- ระบบการทำนาย: ประมวลผลข้อมูลอินพุตทำการคาดการณ์
- ระบบให้บริการ (เว็บเซิร์ฟเวอร์):
- ให้บริการการทำนายโดยคำนึงถึงขนาด
- ใช้ REST API เพื่อตอบสนองคำขอ http
- เรียกระบบการทำนายให้ตอบสนอง
- ตัวเลือกการให้บริการ:
- ปรับใช้กับ VMS ขนาดโดยการเพิ่มอินสแตนซ์
- ปรับใช้เป็นคอนเทนเนอร์สเกลผ่าน orchestration
- ภาชนะบรรจุ
- orchestration คอนเทนเนอร์:
- Kubernetes (เป็นที่นิยมมากที่สุดในตอนนี้)
- เมโซ
- มาราธอน
- ปรับใช้รหัสเป็น "ฟังก์ชั่น Serverless"
- ปรับใช้ผ่านโซลูชัน การให้บริการแบบจำลอง
- การให้บริการแบบจำลอง:
- การปรับใช้เว็บพิเศษสำหรับรุ่น ML
- คำขอแบทช์สำหรับการอนุมาน GPU
- เฟรมเวิร์ก:
- เสิร์ฟ Tensorflow
- เซิร์ฟเวอร์ MxNet Model
- Clipper (Berkeley)
- โซลูชั่น Saas
- Seldon: เสิร์ฟและแบบจำลองขนาดที่สร้างขึ้นในกรอบใด ๆ บน Kubernetes
- อัลกอริทึม
- การตัดสินใจ: CPU หรือ GPU?
- การอนุมาน CPU:
- การอนุมาน CPU เป็นสิ่งที่ดีกว่าหากตรงตามข้อกำหนด
- ปรับขนาดโดยการเพิ่มเซิร์ฟเวอร์เพิ่มเติมหรือไม่เซิร์ฟเวอร์
- การอนุมาน GPU:
- TF เสิร์ฟหรือ Clipper
- การปรับแต่งแบทช์มีประโยชน์
- (โบนัส) การปรับใช้สมุดบันทึก Jupyter:
- Kubeflow Fairing เป็นแพ็คเกจการปรับใช้ไฮบริดที่ให้คุณปรับใช้รหัสสมุด บันทึก Jupyter ของคุณ!
4.5 บริการตาข่ายและเส้นทางการจราจร
- การเปลี่ยนจากแอพพลิเคชั่นเสาหินไปสู่สถาปัตยกรรม microservice แบบกระจายอาจเป็นสิ่งที่ท้าทาย
- ตาข่ายบริการ (ประกอบด้วยเครือข่าย microservices) ลดความซับซ้อนของการปรับใช้ดังกล่าวและช่วยลดความเครียดในทีมพัฒนา
- ISTIO: บริการตาข่ายเพื่อความสะดวกในการสร้างเครือข่ายของบริการที่ปรับใช้ด้วยโหลดบาลานซ์การตรวจสอบความถูกต้องของบริการไปยังบริการการตรวจสอบโดยมีการเปลี่ยนแปลงรหัสน้อยหรือไม่มีเลยในรหัสบริการ
4.4. การตรวจสอบ:
- วัตถุประสงค์ของการตรวจสอบ:
- การแจ้งเตือนสำหรับการหยุดทำงานข้อผิดพลาดและการกระจายการเปลี่ยนแปลง
- จับบริการและการถดถอยข้อมูล
- โซลูชันผู้ให้บริการคลาวด์นั้นดี
- Kiali: คอนโซลที่สังเกตได้สำหรับ ISTIO ที่มีความสามารถในการกำหนดค่าตาข่าย ตอบคำถามเหล่านี้: Microservices เชื่อมต่ออย่างไร? พวกเขาแสดงอย่างไร?
เราทำเสร็จแล้วหรือยัง?

4.5. การปรับใช้อุปกรณ์ที่ฝังอยู่และอุปกรณ์พกพา
- ความท้าทายหลัก: รอยเท้าหน่วยความจำและข้อ จำกัด การคำนวณ
- วิธีแก้ปัญหา:
- การวัดปริมาณ
- ลดขนาดรุ่น
- การกลั่นความรู้
- เฟรมเวิร์กแบบฝังและมือถือ:
- tensorflow lite
- Pytorch Mobile
- ML หลัก
- ชุด ML
- ฟริตซ์
- Openvino
- การแปลงแบบจำลอง:
- Open Neural Network Exchange (ONNX): รูปแบบโอเพนซอร์ซสำหรับรูปแบบการเรียนรู้ลึก
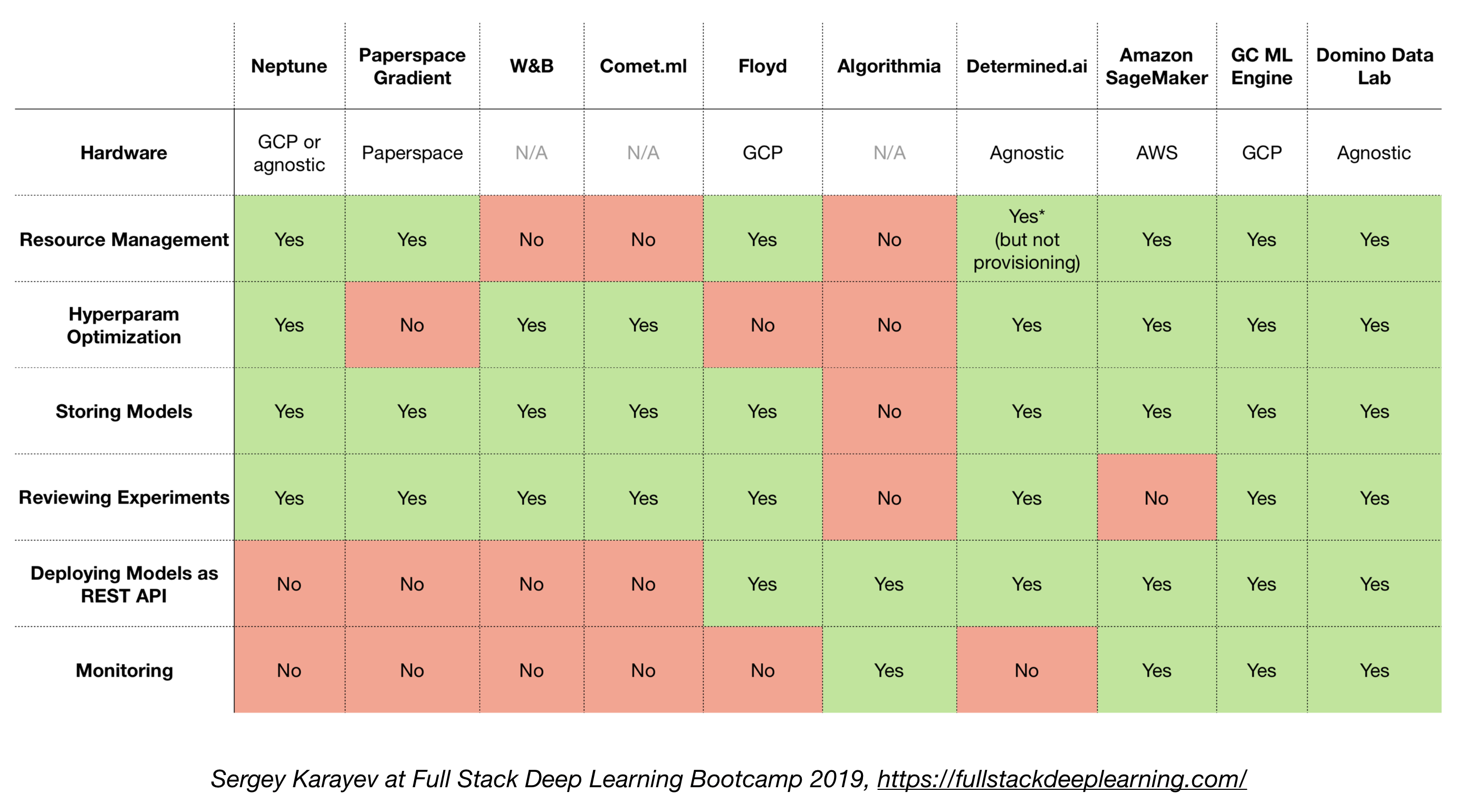
4.6. โซลูชั่นแบบ all-in-one
- Tensorflow ขยาย (TFX)
- Michelangelo (Uber)
- แพลตฟอร์ม Google Cloud AI
- Amazon Sagemaker
- เนปจูน
- ฟลอยด์
- พื้นที่กระดาษ
- กำหนด AI
- Domino Data Lab
Tensorflow ขยาย (TFX)
[TBD]
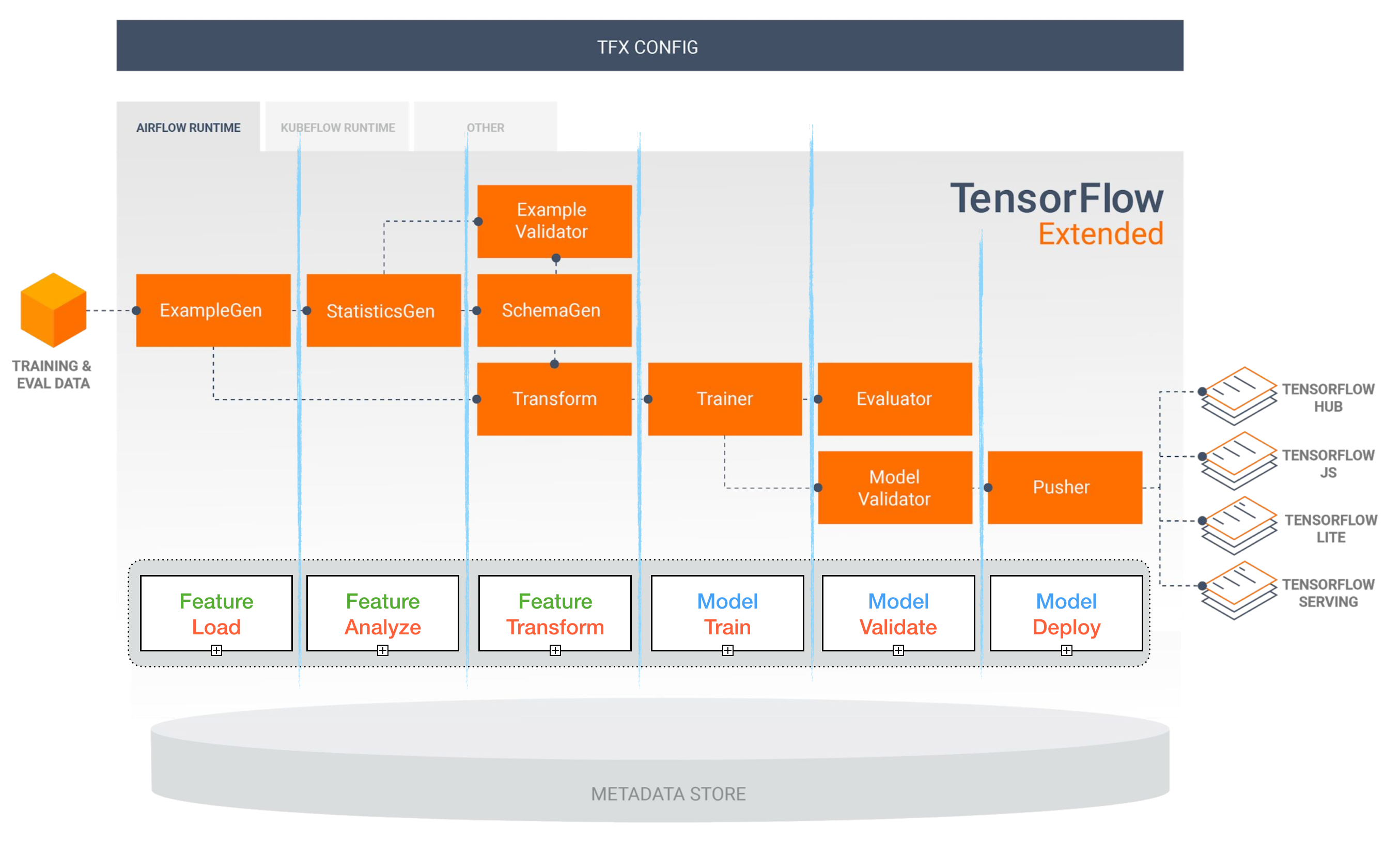
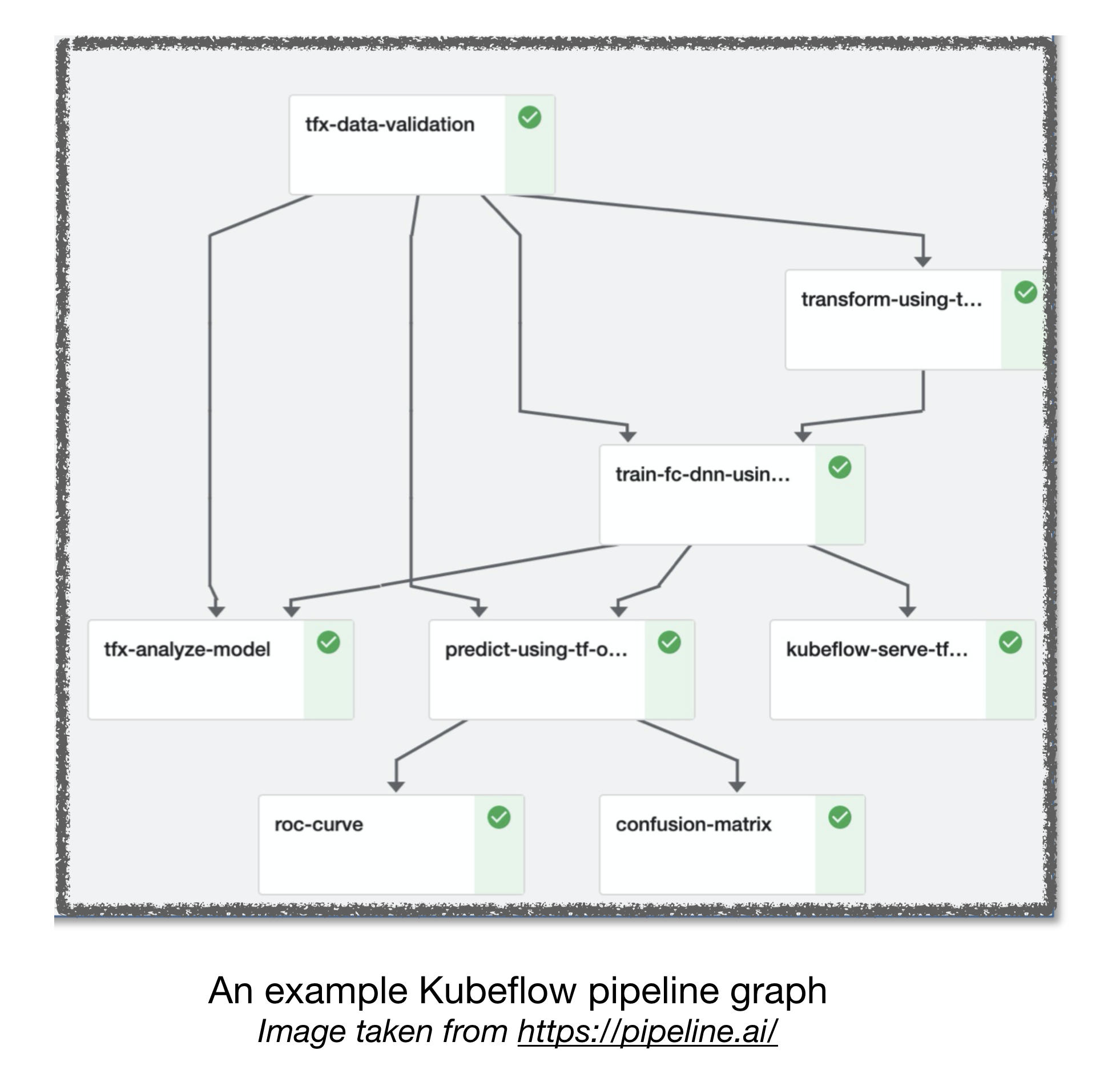
การไหลเวียนของอากาศและ Kubeflow ML
[TBD]
ลิงค์ที่มีประโยชน์อื่น ๆ :
- บทเรียนที่เรียนรู้จากการสร้างระบบการเรียนรู้เชิงลึกที่ใช้งานได้จริง
- การเรียนรู้ของเครื่อง: บัตรเครดิตที่มีดอกเบี้ยสูงของหนี้ทางเทคนิค
การบริจาค
ข้อมูลอ้างอิง:
[1]: Bootcamp การเรียนรู้อย่างลึกซึ้งสแต็ค, พ.ย. 2019
[2]: การประชุมเชิงปฏิบัติการ Kubeflow ขั้นสูงโดย Pipeline.ai, 2019
[3]: TFX: การเรียนรู้ของเครื่องจักรโลกจริงในการผลิต


