Panduan untuk tingkat produksi belajar yang mendalam? ⛴️
?? Terjemahan dalam bahasa Cina
? ️ BARU: Wawancara Pembelajaran Mesin
? ️ Catatan: Repo ini sedang dalam pengembangan berkelanjutan, dan semua umpan balik dan kontribusi sangat disambut?
Menyebarkan model pembelajaran yang mendalam dalam produksi bisa menjadi tantangan, karena jauh di luar model pelatihan dengan kinerja yang baik. Beberapa komponen berbeda perlu dirancang dan dikembangkan untuk menggunakan sistem pembelajaran tingkat produksi (terlihat di bawah):
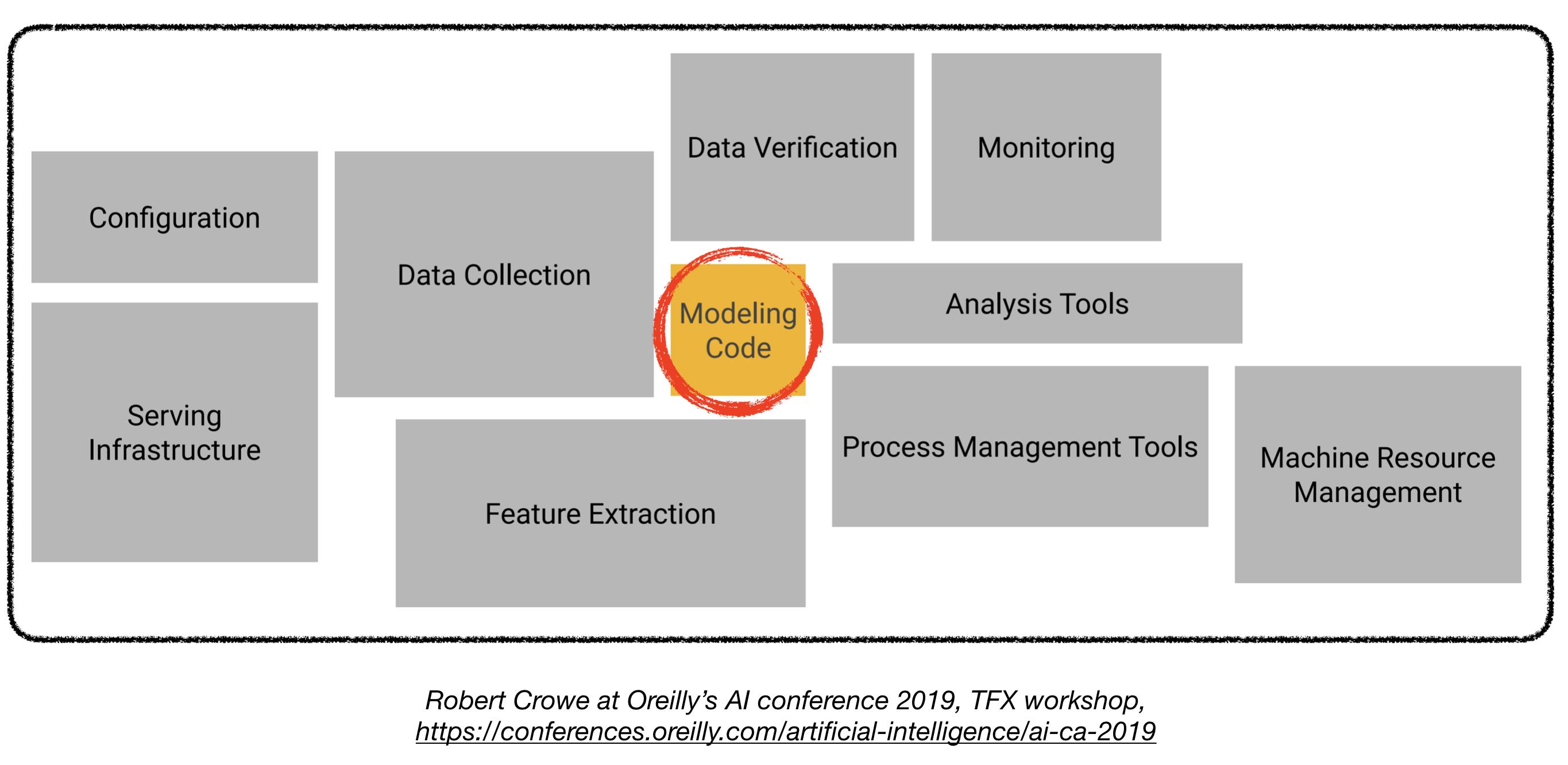
Repo ini bertujuan untuk menjadi pedoman teknik untuk membangun sistem pembelajaran dalam tingkat produksi yang akan digunakan dalam aplikasi dunia nyata.
Materi yang disajikan di sini dipinjam dari bootcamp pembelajaran dalam tumpukan penuh (oleh Pieter Abbeel di UC Berkeley, Josh Tobin di Openai, dan Sergey Karayev di Turnitin), lokakarya TFX oleh Robert Crowe, dan Pipeline.ai's Advanced Kubeflow Meetup oleh Chris Fregly.
Proyek Pembelajaran Mesin
Seru ? Fakta: 85% dari proyek AI gagal . 1 alasan potensial meliputi:
- Secara teknis tidak layak atau tidak terselubung
- Jangan pernah membuat lompatan untuk produksi
- Kriteria keberhasilan yang tidak jelas (metrik)
- Manajemen tim yang buruk
1. ML Proyek Siklus Hidup
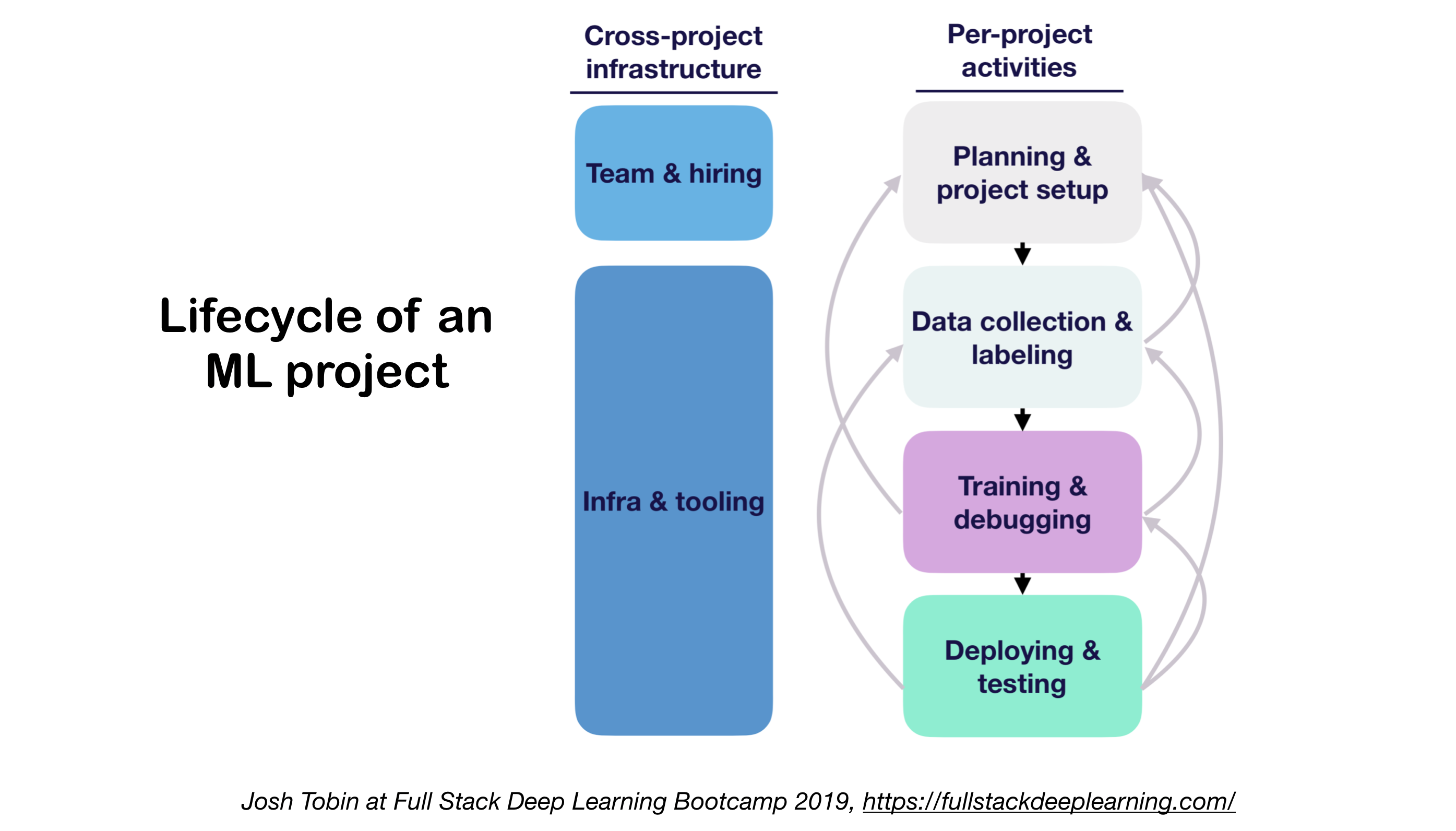
- Pentingnya memahami keadaan seni di domain Anda:
- Membantu memahami apa yang mungkin
- Membantu mengetahui apa yang harus dicoba selanjutnya
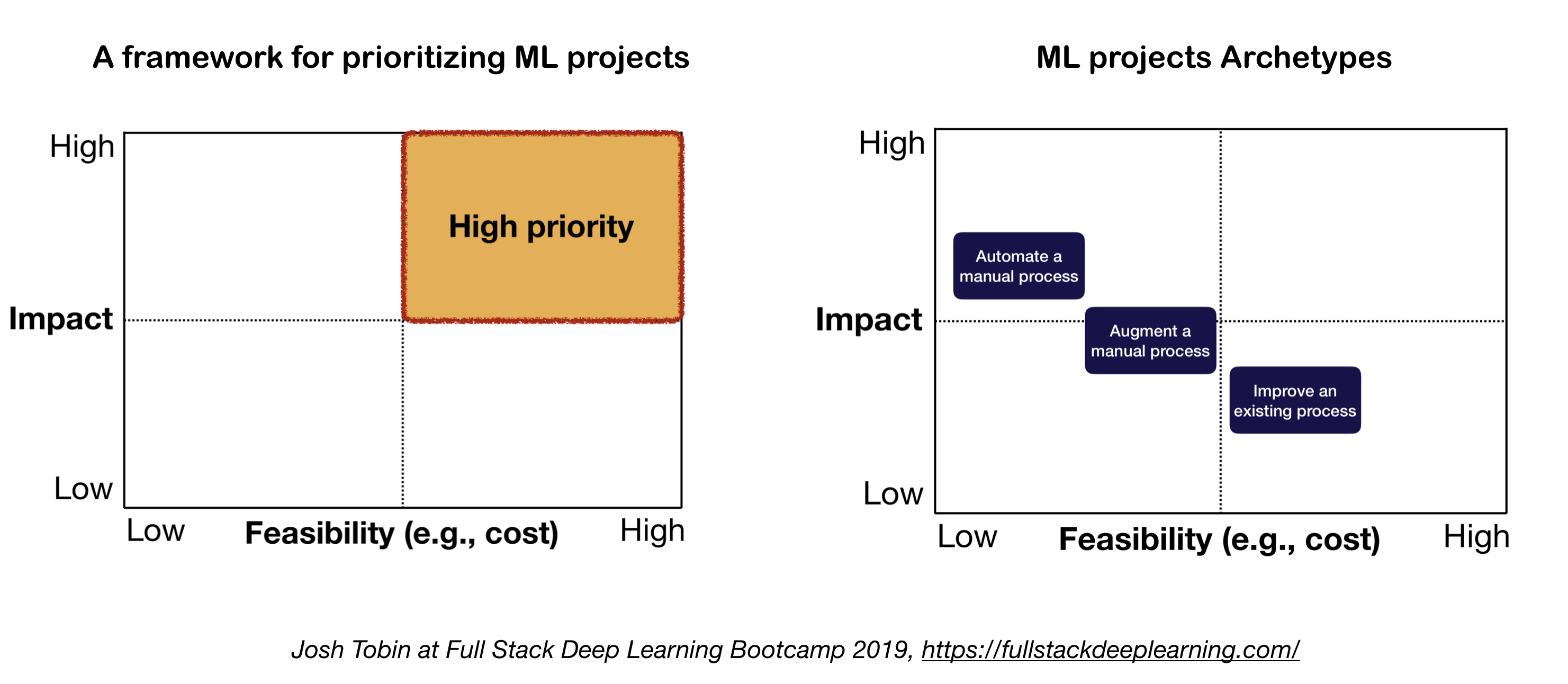
2. Model Mental untuk Proyek ML
Dua faktor penting yang perlu dipertimbangkan saat mendefinisikan dan memprioritaskan proyek ML:
- Dampak Tinggi:
- Bagian kompleks dari pipa Anda
- Di mana "prediksi murah" berharga
- Di mana mengotomatiskan proses manual yang rumit sangat berharga
- Biaya rendah:
- Biaya didorong oleh:
- Ketersediaan data
- Persyaratan Kinerja: Biaya cenderung skala super-linier dalam persyaratan akurasi
- Kesulitan Masalah:
- Beberapa masalah sulit meliputi: pembelajaran tanpa pengawasan, pembelajaran penguatan, dan kategori pembelajaran yang diawasi tertentu
Pipa tumpukan penuh
Gambar berikut mewakili tinjauan tingkat tinggi komponen yang berbeda dalam sistem pembelajaran dalam tingkat produksi:
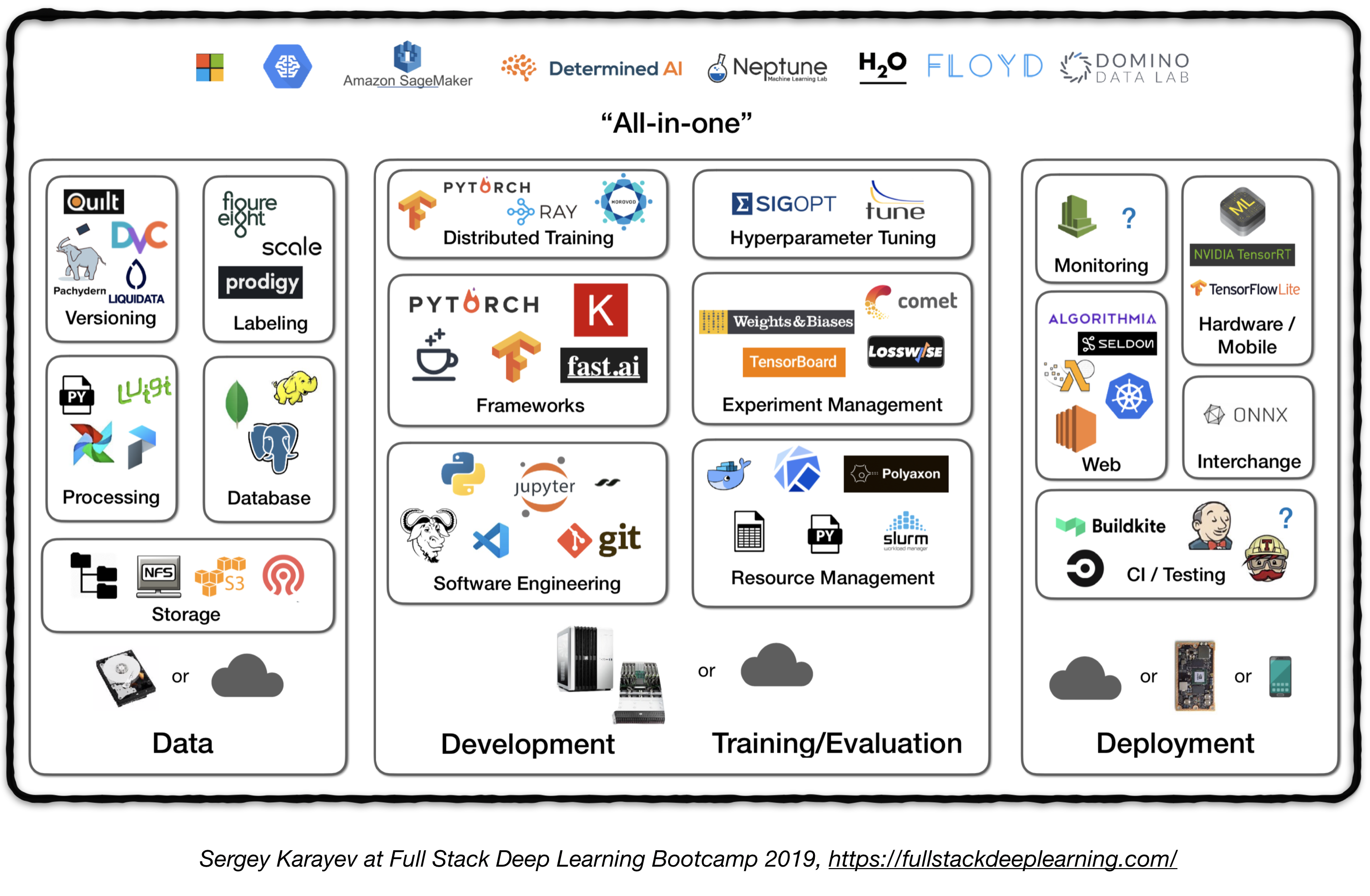
Berikut ini, kami akan melalui setiap modul dan merekomendasikan peralatan dan kerangka kerja serta praktik terbaik dari praktisi yang sesuai dengan setiap komponen.
1. Manajemen Data
1.1 Sumber Data
- Pembelajaran mendalam yang diawasi membutuhkan banyak data berlabel
- Memberi label data sendiri mahal!
- Berikut adalah beberapa sumber daya untuk data:
- Data sumber terbuka (bagus untuk memulai, tetapi bukan keuntungan)
- Augmentasi data (keharusan untuk visi komputer, opsi untuk NLP)
- Data sintetis (hampir selalu layak untuk dimulai dengan, esp. Di NLP)
1.2 Pelabelan Data
- Membutuhkan: Tumpukan perangkat lunak terpisah (platform pelabelan), tenaga kerja sementara, dan QC
- Sumber tenaga kerja untuk pelabelan:
- Crowdsourcing (Mechanical Turki): Murah dan diskalakan, kurang dapat diandalkan, membutuhkan QC
- Mempekerjakan Annotator Sendiri: Kurang QC Dibutuhkan, Mahal, Lambat Untuk Skala
- Perusahaan Layanan Pelabelan Data:
- Platform pelabelan:
- Diffgram: Perangkat Lunak Data Pelatihan (Visi Komputer)
- Prodigy: Alat anotasi yang ditenagai oleh pembelajaran aktif (oleh pengembang spacy), teks dan gambar
- Hive: AI sebagai platform layanan untuk visi komputer
- Pengawasan: Seluruh platform visi komputer
- LabelBox: Visi Komputer
- Platform Data Skala AI (Visi Komputer & NLP)
1.3. Penyimpanan data
- Opsi Penyimpanan Data:
- Object Store : Store Data Biner (Gambar, File Suara, Teks Terkompresi)
- Amazon S3
- Toko objek Ceph
- Database : Store metadata (jalur file, label, aktivitas pengguna, dll).
- Postgres adalah pilihan yang tepat untuk sebagian besar aplikasi, dengan SQL terbaik di kelasnya dan dukungan besar untuk JSON yang tidak terstruktur.
- Data Lake : untuk agregat fitur yang tidak dapat diperoleh dari database (misalnya log)
- Fitur Toko : Store, Access, dan Bagikan Fitur Pembelajaran Mesin (ekstraksi fitur bisa mahal secara komputasi dan hampir tidak mungkin untuk diukur, sehingga menggunakan kembali fitur oleh model dan tim yang berbeda adalah kunci untuk tim ML kinerja tinggi).
- Pesta (Google Cloud, Open Source)
- Michelangelo Palette (Uber)
- Saran: Pada waktu pelatihan, salin data ke sistem file lokal atau jaringan (NFS). 1
1.4. Versi Data
- Ini adalah "harus" untuk model ML yang digunakan:
Model ML yang digunakan adalah kode bagian, data bagian . 1 Tidak ada versi data berarti tidak ada versi model. - Platform Versi Data:
- DVC: Sistem Kontrol Versi Sumber Terbuka untuk Proyek ML
- Pachyderm: Kontrol Versi untuk Data
- DOLT: Database SQL dengan kontrol versi seperti GIT untuk data dan skema
1.5. Pengolahan data
- Data pelatihan untuk model produksi dapat berasal dari berbagai sumber, termasuk data yang disimpan di penyimpanan DB dan objek , pemrosesan log , dan output dari pengklasifikasi lain .
- Ada ketergantungan antara tugas, masing -masing perlu dikeluarkan setelah ketergantungannya selesai. Misalnya, pelatihan tentang data log baru, membutuhkan langkah preprocessing sebelum pelatihan.
- Makefile tidak dapat diukur. "Manajer Workflow menjadi sangat penting dalam hal ini.
- Orkestrasi alur kerja:
- Luigi oleh Spotify
- Airflow oleh Airbnb: Dinamis, Diperpanjang, Elegan, dan Dapat Diukur (yang paling banyak digunakan)
- Alur kerja DAG
- Eksekusi kondisional yang kuat: coba lagi jika terjadi kegagalan
- Pusher mendukung gambar docker dengan tensorflow porsi
- Seluruh alur kerja dalam satu file .py
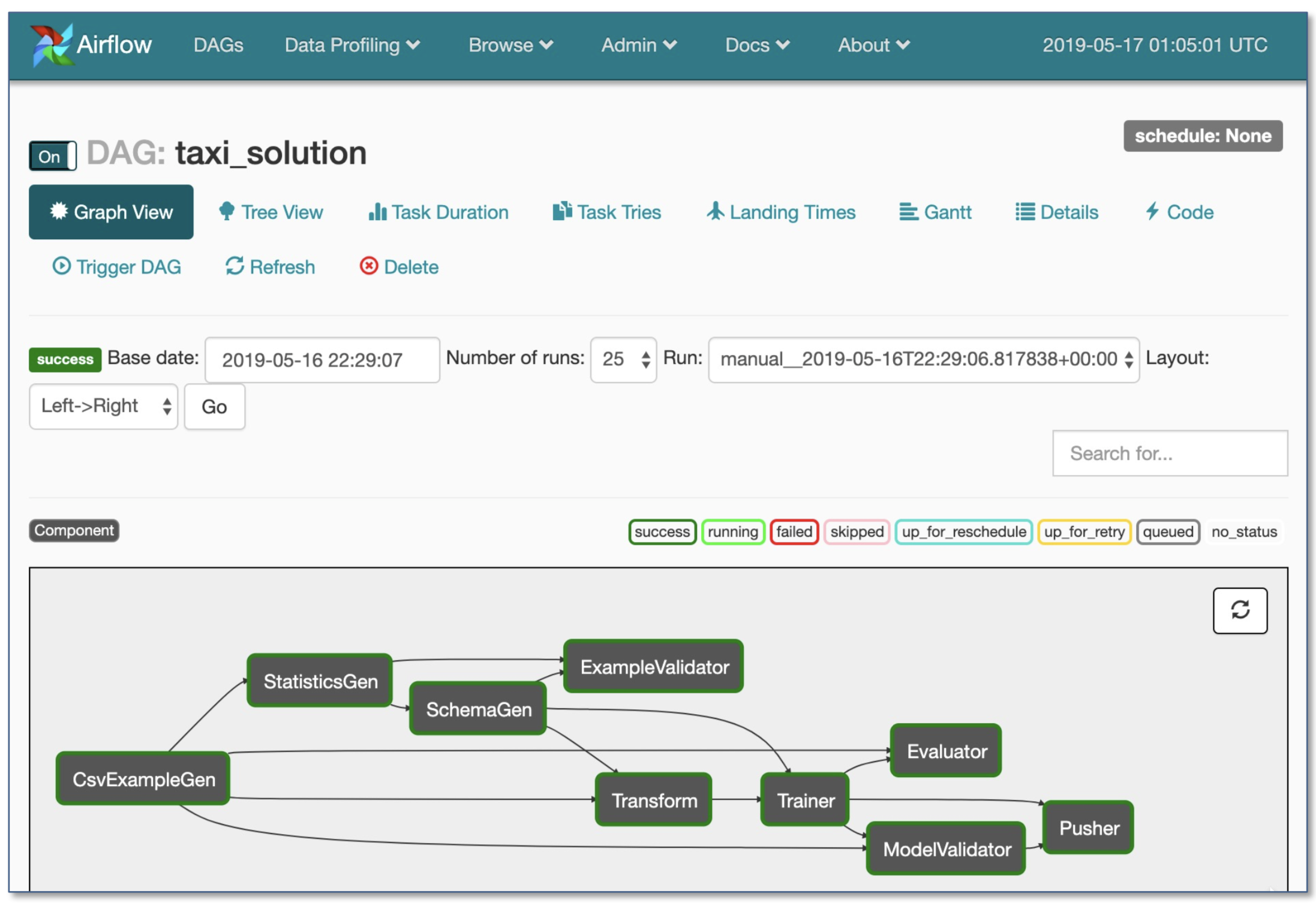
2. Pengembangan, pelatihan, dan evaluasi
2.1. Rekayasa Perangkat Lunak
- Bahasa Pemenang: Python
- Editor:
- Vim
- Emacs
- VS Code (Direkomendasikan oleh Penulis): Pementasan Git bawaan dan diff, kode serat, proyek terbuka dari jarak jauh melalui SSH
- Notebook: Hebat sebagai titik awal proyek, sulit untuk skala (fakta menyenangkan: Arsitektur Netflix yang digerakkan oleh notflix adalah pengecualian, yang sepenuhnya didasarkan pada suite nteract).
- NTERACT: UI berbasis reaksi generasi berikutnya untuk Jupyter Notebooks
- Papermill: adalah perpustakaan nteract yang dibangun untuk parameterisasi , mengeksekusi , dan menganalisis buku catatan Jupyter.
- Komuter: Proyek Nteract lain yang menyediakan tampilan notebook hanya baca (misalnya dari S3 ember).
- StreamLit: Alat Ilmu Data Interaktif dengan Applet
- Rekomendasi Hitung 1 :
- Untuk individu atau startup :
- Pengembangan: PC arsitektur 4x Turing
- Pelatihan/Evaluasi: Gunakan PC 4x GPU yang sama. Saat menjalankan banyak percobaan, beli server bersama atau gunakan instance cloud.
- Untuk perusahaan besar:
- Pengembangan: Beli PC Arsitektur 4x Turing Per ML Scientist atau biarkan mereka menggunakan V100 V100
- Pelatihan/Evaluasi: Gunakan instance cloud dengan penyediaan dan penanganan kegagalan yang tepat
- Penyedia cloud:
- GCP: Opsi untuk menghubungkan GPU ke contoh apa pun + memiliki TPU
- AWS:
2.2. Manajemen Sumber Daya
- Mengalokasikan sumber daya gratis untuk program
- Opsi manajemen sumber daya:
- Penjadwal Pekerjaan Cluster Sekolah Lama (misalnya Manajer Beban Kerja Slurm)
- Docker + Kubernetes
- Kubeflow
- Polyaxon (fitur berbayar)
2.3. Kerangka kerja DL
- Kecuali jika memiliki alasan yang baik untuk tidak, gunakan TensorFlow/Keras atau Pytorch. 1
- Gambar berikut menunjukkan perbandingan antara kerangka kerja yang berbeda tentang bagaimana mereka berdiri untuk "pengembangan" dan "produksi" .
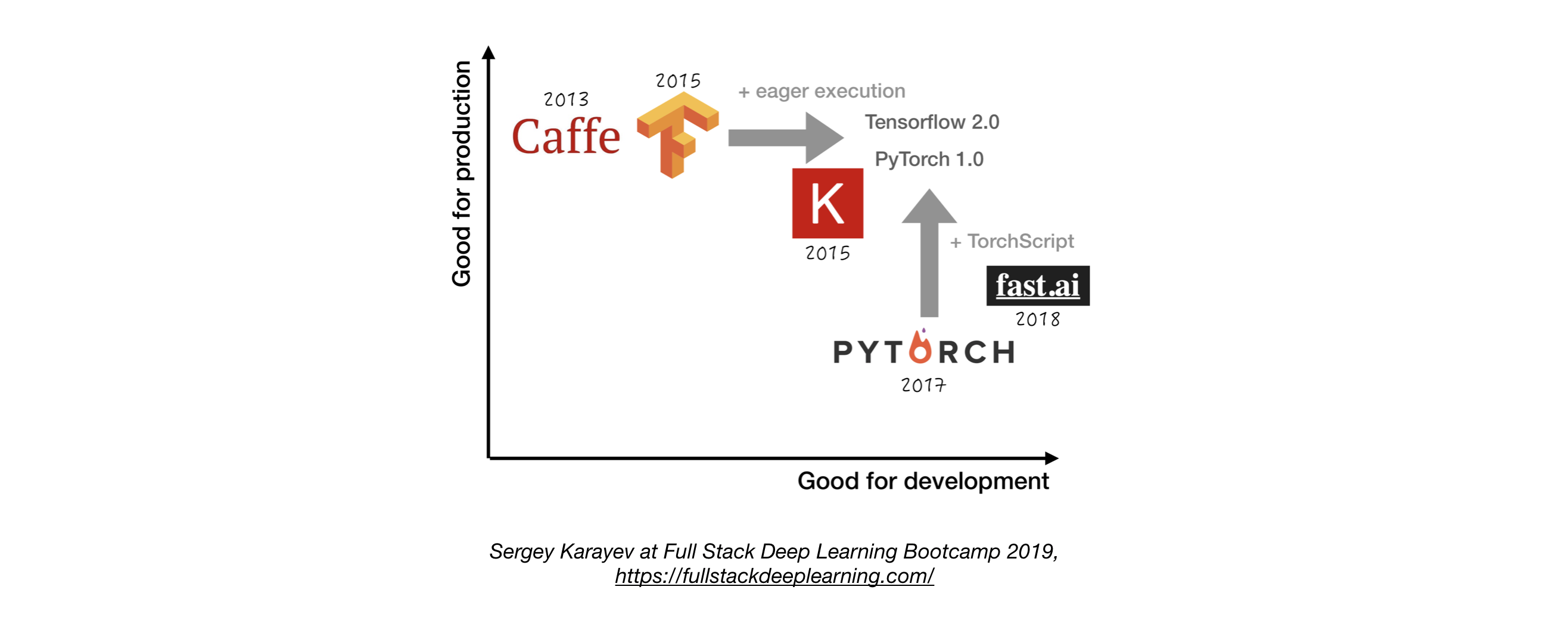
2.4. Manajemen Eksperimen
- Strategi Pengembangan, Pelatihan, dan Evaluasi:
- Selalu mulai sederhana
- Latih model kecil pada batch kecil. Hanya jika berfungsi, skala ke data dan model yang lebih besar, dan penyetelan hiperparameter!
- Alat manajemen percobaan:
- Tensorboard
- Memberikan visualisasi dan alat yang diperlukan untuk eksperimen ML
- Losswise (pemantauan untuk ML)
- COMET: Memungkinkan Anda melacak kode, percobaan, dan hasil pada proyek ML
- Bobot & Bias: Catat dan visualisasikan setiap detail penelitian Anda dengan kolaborasi yang mudah
- Pelacakan MLFLOW: Untuk parameter logging, versi kode, metrik, dan file output serta visualisasi hasil.
- Pelacakan Eksperimen Otomatis dengan satu baris kode dalam Python
- Perbandingan eksperimen berdampingan
- Penyetelan parameter hiper
- Mendukung pekerjaan berbasis Kubernetes
2.5. Penyetelan hiperparameter
Pendekatan:
- Pencarian Kisi
- Pencarian acak
- Optimalisasi Bayesian
- Algoritma Hyperband dan Asynchronous Secorsif Thurving (Asha)
- Pelatihan berbasis populasi
Platform:
- Raytune: Ray Tune adalah perpustakaan Python untuk penyetelan hiperparameter pada skala apa pun (dengan fokus pada pembelajaran yang mendalam dan pembelajaran penguatan yang mendalam). Mendukung kerangka kerja pembelajaran mesin apa pun, termasuk Pytorch, XGBoost, MXNet, dan Keras.
- KATIB: Sistem asli Kubernete untuk pencarian tuning hiperparameter dan arsitektur saraf, terinspirasi oleh [Google Vizier] (https://static.googleusercontent.com/media/ riset.google.com/ja/pubs/archive/ BCB15507F4B52991A078830717830178307830783078830 dan mendukung beberapa kerangka kerja ML/DL (misalnya TensorFlow, MXNet, dan Pytorch).
- Hyperas: Pembungkus sederhana di sekitar hyperopt untuk keras, dengan notasi templat sederhana untuk mendefinisikan rentang hyper-parameter untuk disetujui.
- SIGOPT: Platform optimisasi tingkat perusahaan yang dapat diskalakan
- Menyapu dari [bobot & bias] (https://www.wandb.com/): Parameter tidak secara eksplisit ditentukan oleh pengembang. Sebaliknya mereka diperkirakan dan dipelajari oleh model pembelajaran mesin.
- Keras Tuner: Tuner hyperparameter untuk keras, khususnya untuk tf.keras dengan TensorFlow 2.0.
2.6. Pelatihan Terdistribusi
- Paralelisme Data: Gunakan ketika waktu iterasi terlalu lama (baik dukungan TensorFlow dan Pytorch)
- Pelatihan Terdistribusi Ray
- Model Parallelism: When Model tidak sesuai dengan satu GPU tunggal
- Solusi lain:
3. Pemecahan Masalah [TBD]
4. Pengujian dan Penempatan
4.1. Pengujian dan CI/CD
Perangkat lunak produksi pembelajaran mesin membutuhkan serangkaian suite tes yang lebih beragam daripada perangkat lunak tradisional:
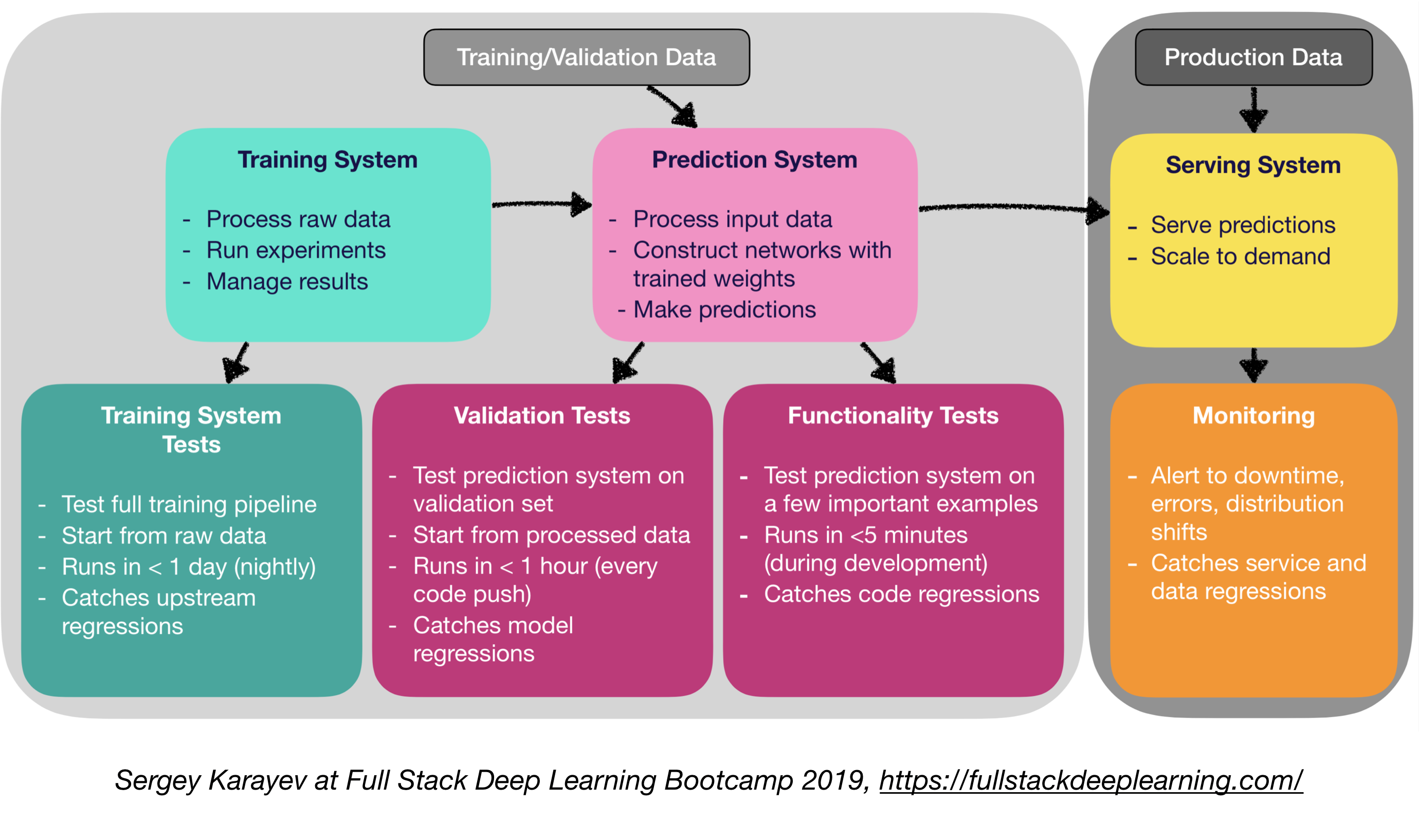
- Pengujian Unit dan Integrasi:
- Jenis tes:
- Tes Sistem Pelatihan: Pengujian Pipa Pelatihan
- Tes Validasi: Sistem Prediksi Pengujian pada Set Validasi
- Tes fungsionalitas: Menguji sistem prediksi pada beberapa contoh penting
- Integrasi Berkelanjutan: Menjalankan Tes Setelah setiap perubahan kode baru didorong ke repo
- SaaS untuk integrasi berkelanjutan:
- ARGO: Open Source Kubernetes Mesin Alur Kerja Asli untuk Mengatur Pekerjaan Paralel (Menimbulkan Alur Kerja, Acara, CI dan CD).
- Circleci: Dukungan inklusif bahasa, lingkungan khusus, alokasi sumber daya yang fleksibel, digunakan oleh Instacart, Lyft, dan Stackshare.
- Travis CI
- Buildkite: Bangunan cepat dan stabil, agen open source berjalan di hampir semua mesin dan arsitektur, kebebasan untuk menggunakan alat dan layanan Anda sendiri
- Jenkins: Sistem pembangunan sekolah lama
4.2. Penyebaran Web
- Terdiri dari sistem prediksi dan sistem penyajian
- Sistem Prediksi: Proses Data Input, Buat Prediksi
- Sistem Melayani (Server Web):
- Melayani prediksi dengan skala dalam pikiran
- Gunakan API REST untuk melayani permintaan prediksi http
- Memanggil sistem prediksi untuk merespons
- Opsi Melayani:
- Menyebarkan ke VM, skala dengan menambahkan instance
- Menyebarkan sebagai wadah, skala melalui orkestrasi
- Wadah
- Orkestrasi Kontainer:
- Kubernetes (yang paling populer sekarang)
- Mesos
- Maraton
- Menerapkan kode sebagai "fungsi tanpa server"
- Menyebarkan melalui solusi penyajian model
- Model Layanan:
- Penyebaran web khusus untuk model ML
- Permintaan batch untuk inferensi GPU
- Kerangka kerja:
- Tensorflow melayani
- Server Model MXNet
- Clipper (Berkeley)
- Solusi SaaS
- Seldon: Model melayani dan skala yang dibangun dalam kerangka apa pun di Kubernetes
- Algoritmia
- Pengambilan Keputusan: CPU atau GPU?
- Inferensi CPU:
- Inferensi CPU lebih disukai jika memenuhi persyaratan.
- Skala dengan menambahkan lebih banyak server, atau pergi tanpa server.
- Inferensi GPU:
- TF melayani atau clipper
- Batching adaptif bermanfaat
- (Bonus) Menyebarkan buku catatan Jupyter:
- Kubeflow Fairing adalah paket penyebaran hibrida yang memungkinkan Anda menggunakan kode notebook Jupyter Anda!
4.5 Layanan Mesh dan Routing Lalu Lintas
- Transisi dari aplikasi monolitik ke arsitektur layanan mikro terdistribusi bisa menjadi tantangan.
- Sebuah mesh layanan (terdiri dari jaringan layanan microser) mengurangi kompleksitas penyebaran tersebut, dan memudahkan ketegangan pada tim pengembangan.
- ISTIO: Mesh layanan untuk memudahkan pembuatan jaringan layanan yang digunakan dengan penyeimbangan beban, otentikasi layanan-ke-layanan, pemantauan, dengan sedikit atau tidak ada perubahan kode dalam kode layanan.
4.4. Pemantauan:
- Tujuan pemantauan:
- Peringatan untuk downtime, kesalahan, dan shift distribusi
- Menangkap layanan dan regresi data
- Solusi penyedia cloud layak
- Kiali: Konsol observabilitas untuk ISTIO dengan kemampuan konfigurasi layanan. Ini menjawab pertanyaan -pertanyaan ini: Bagaimana layanan microser terhubung? Bagaimana kinerjanya?
Apakah kita selesai?

4.5. Menyebarkan perangkat yang tertanam dan seluler
- Tantangan Utama: Jejak Memori dan Kendala Hitung
- Solusi:
- Kuantisasi
- Ukuran model yang dikurangi
- Distilasi Pengetahuan
- Kerangka kerja tertanam dan seluler:
- Tensorflow Lite
- Pytorch Mobile
- Inti ML
- Kit ML
- Fritz
- Openvino
- Konversi Model:
- Open Neural Network Exchange (ONNX): Format sumber terbuka untuk model pembelajaran yang mendalam
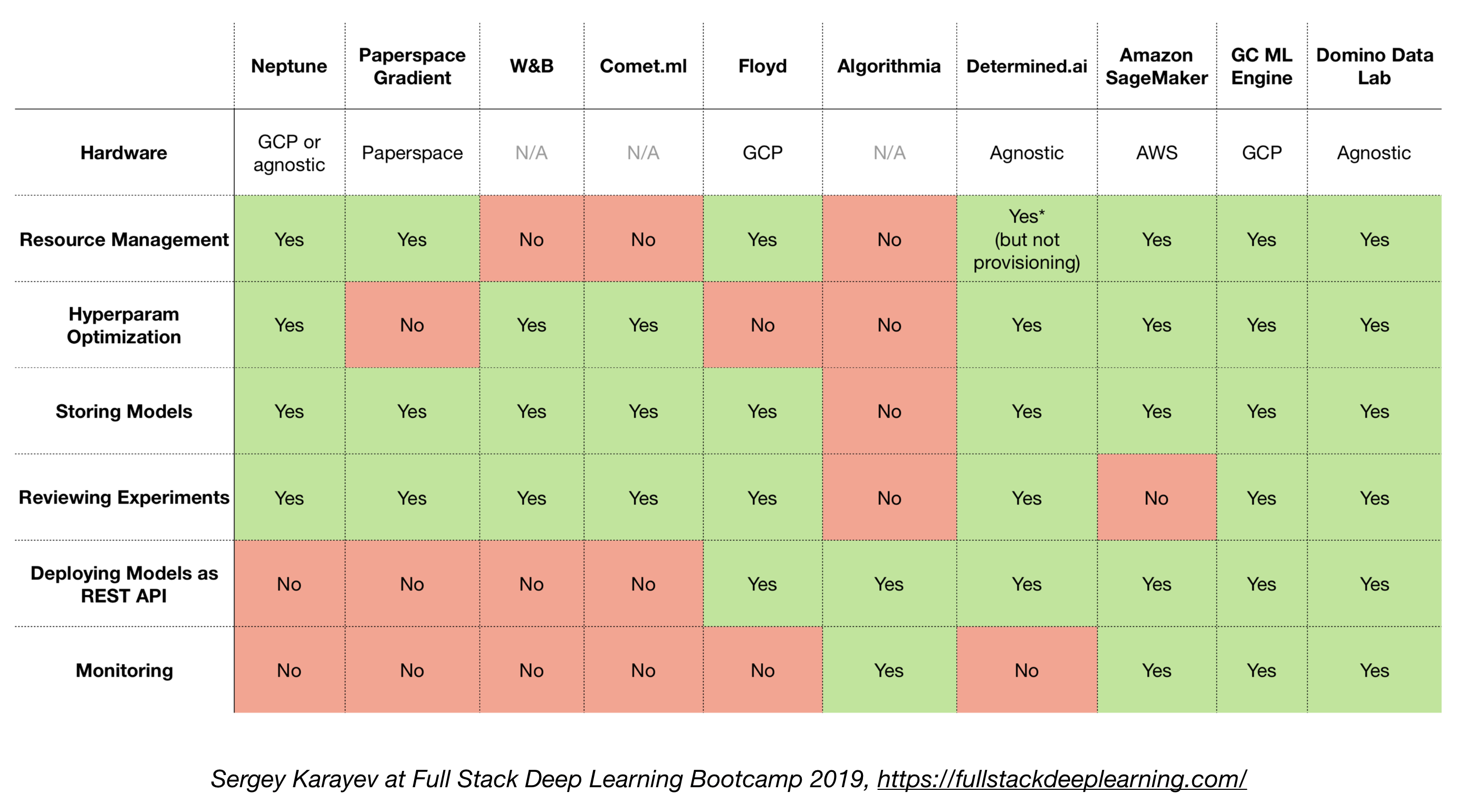
4.6. Solusi all-in-one
- TensorFlow Extended (TFX)
- Michelangelo (Uber)
- Platform Google Cloud AI
- Amazon Sagemaker
- Neptunus
- Floyd
- Ruang kertas
- AI yang ditentukan
- Lab Data Domino
TensorFlow Extended (TFX)
[TBD]
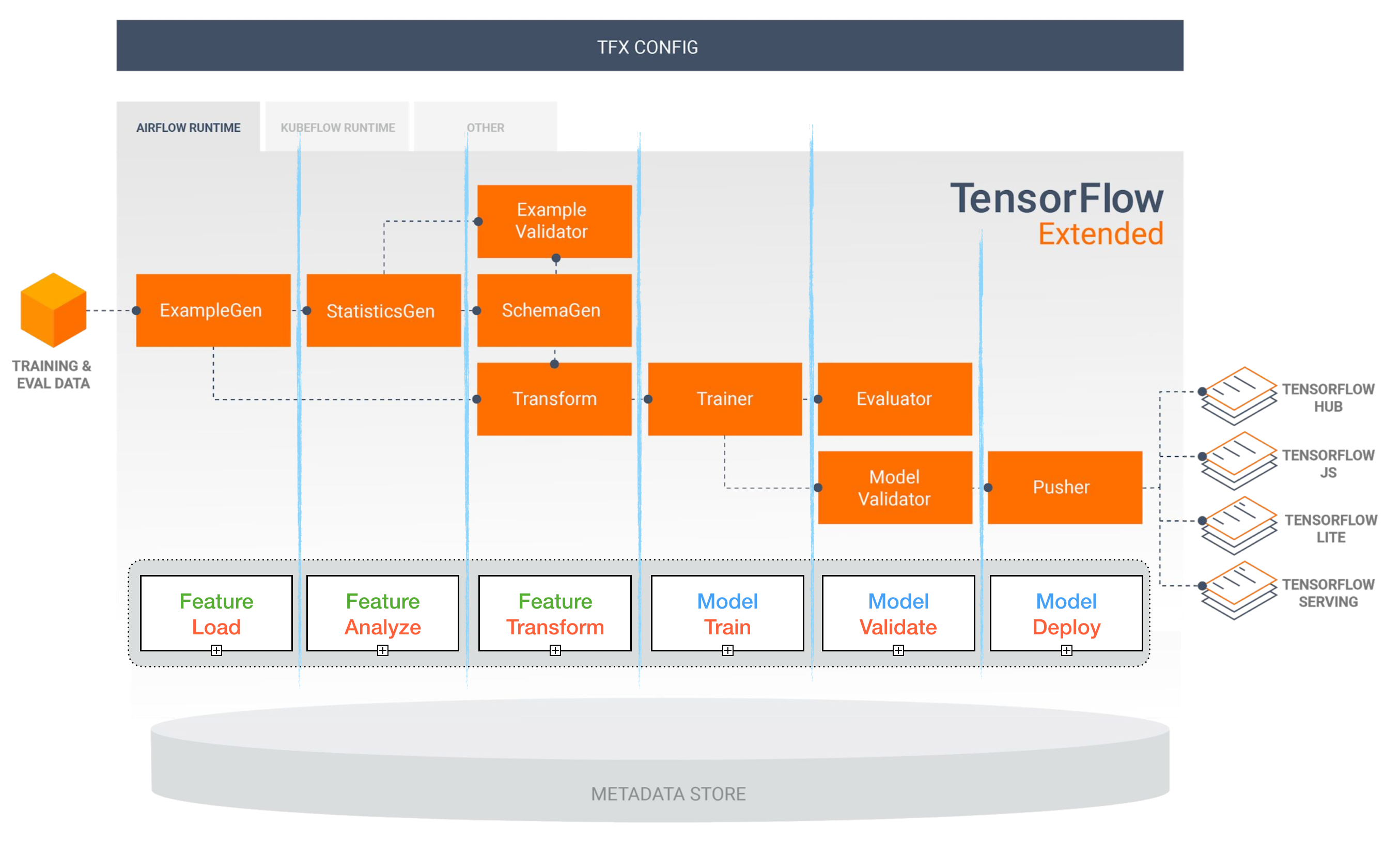
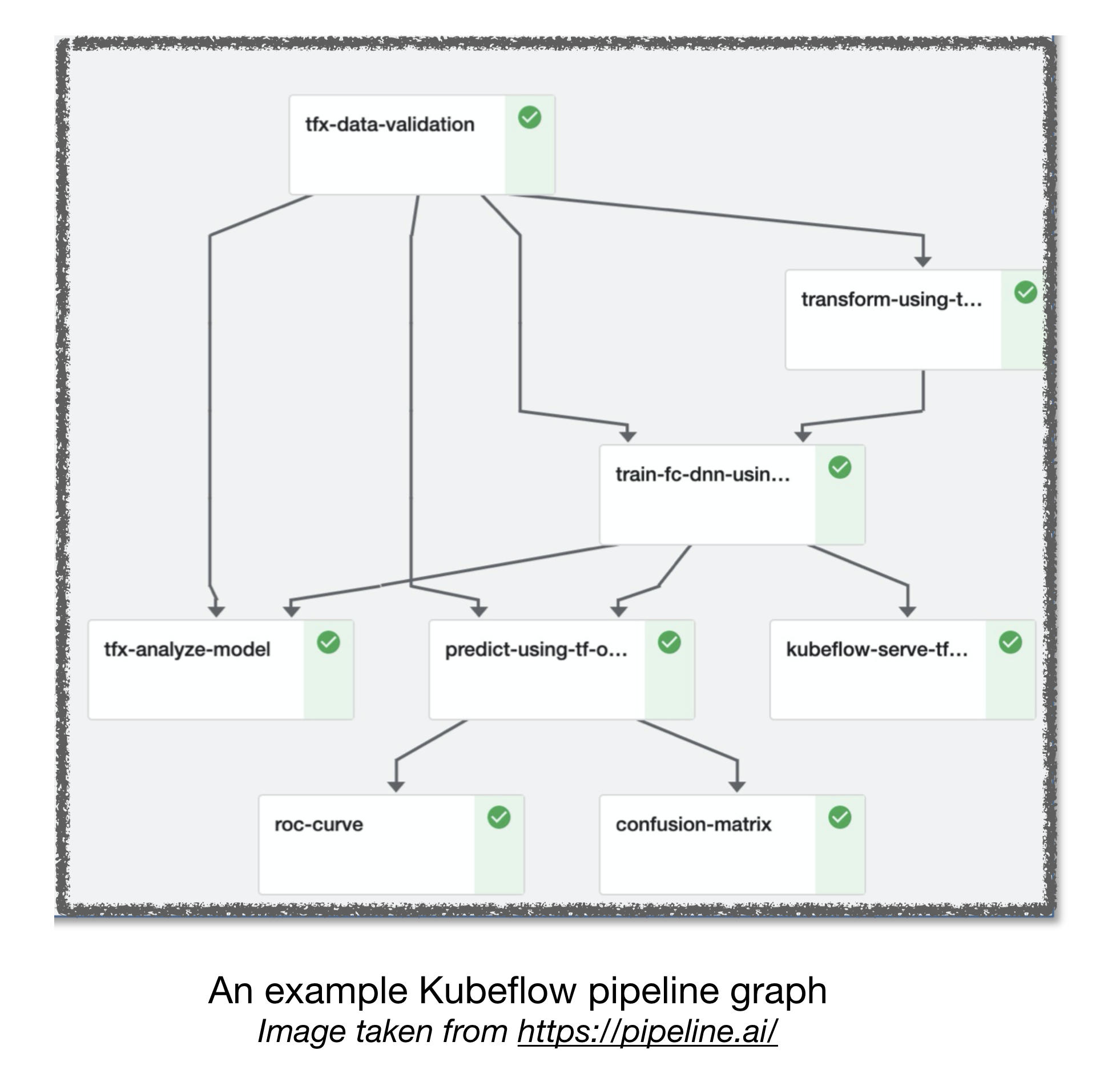
Pipa aliran udara dan kubeflow ml
[TBD]
Tautan Berguna Lainnya:
- Pelajaran yang Dipetik Dari Membangun Sistem Pembelajaran Deep Praktis
- Pembelajaran Mesin: Kartu Kredit Bunga Tinggi Hutang Teknis
Berkontribusi
Referensi:
[1]: Bootcamp Deep Learning Stack Full, Nov 2019.
[2]: Lokakarya Kubeflow Lanjutan oleh Pipeline.ai, 2019.
[3]: TFX: Pembelajaran Mesin Dunia Nyata dalam Produksi


