Um guia para o aprendizado profundo do nível de produção? ⛴️
? Tradução em chinês
? Aste Novo: Entrevistas de aprendizado de máquina
? Sustta: este repositório está sob desenvolvimento contínuo e todo feedback e contribuição são muito bem -vindos?
A implantação de modelos de aprendizado profundo na produção pode ser um desafio, pois está muito além dos modelos de treinamento com bom desempenho. Vários componentes distintos precisam ser projetados e desenvolvidos para implantar um sistema de aprendizado profundo no nível de produção (visto abaixo):
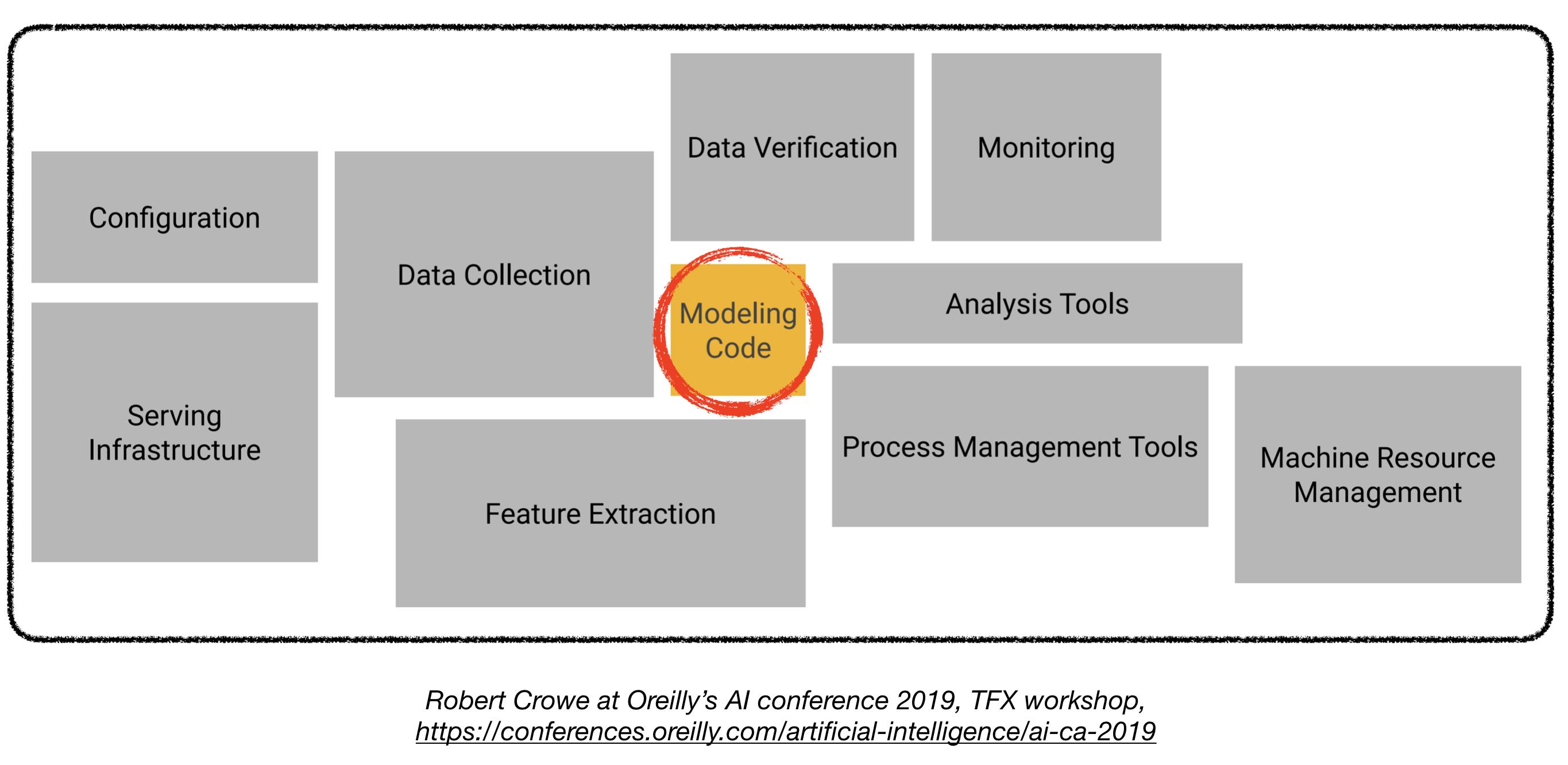
Este repositório pretende ser uma diretriz de engenharia para a construção de sistemas de aprendizado profundo no nível de produção que serão implantados em aplicações do mundo real.
O material apresentado aqui é emprestado do Bootcamp de aprendizado profundo de pilha completa (por Pieter Abbeel na UC Berkeley, Josh Tobin em Openai e Sergey Karayev em Turnitin), Workshop TFX de Robert Crowe e Pipeline.ai Avançado Kubeflow Meetup por Chris Fregly.
Projetos de aprendizado de máquina
Diversão ? Fato: 85% dos projetos de IA falham . 1 motivos potenciais incluem:
- Tecnicamente inviável ou pouco escopo
- Nunca dê o salto para a produção
- Critérios de sucesso pouco claros (métricas)
- Má gestão de equipes
1. ML Projetos Lifecycle
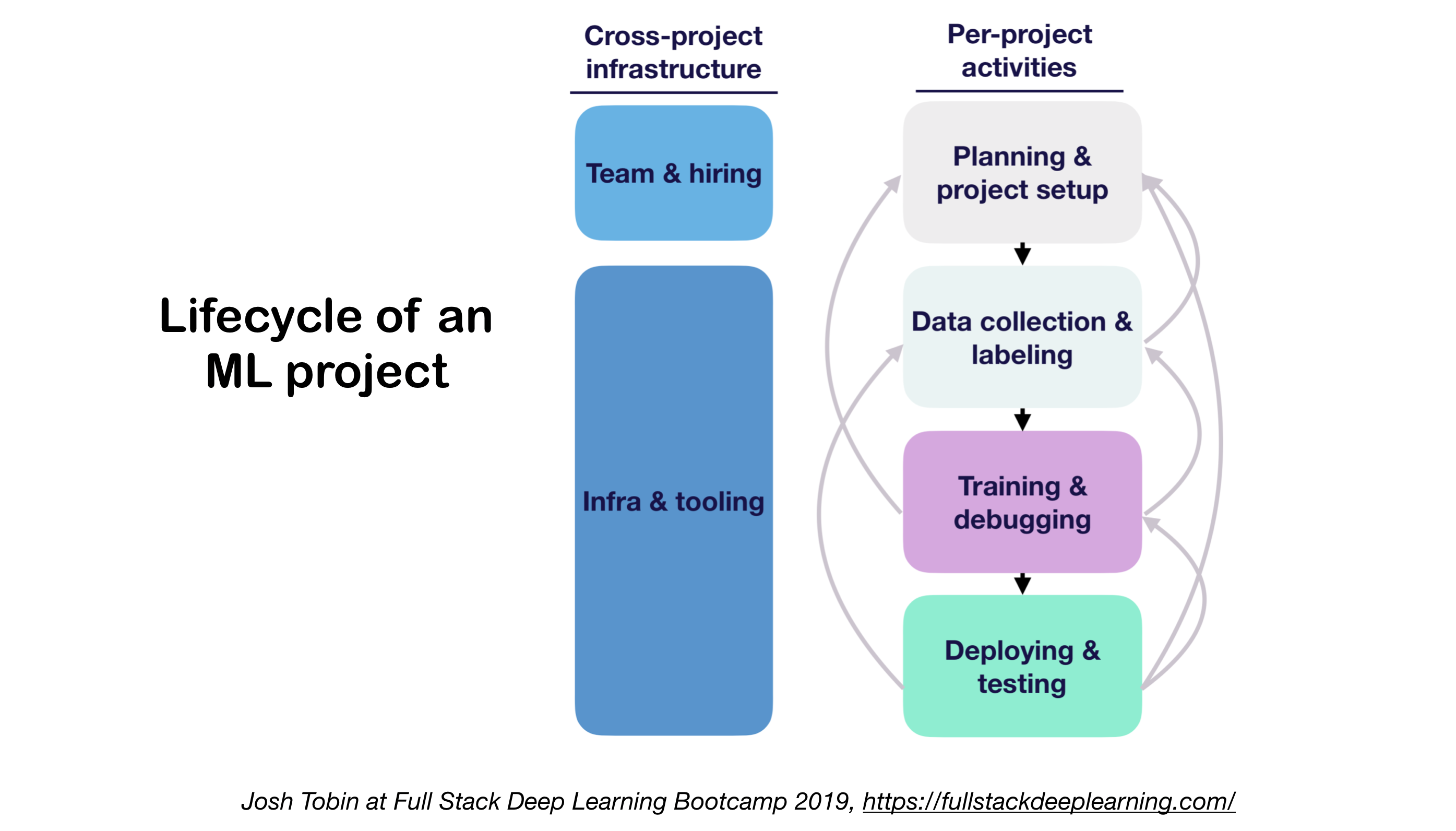
- Importância de entender o estado da arte em seu domínio:
- Ajuda a entender o que é possível
- Ajuda a saber o que tentar a seguir
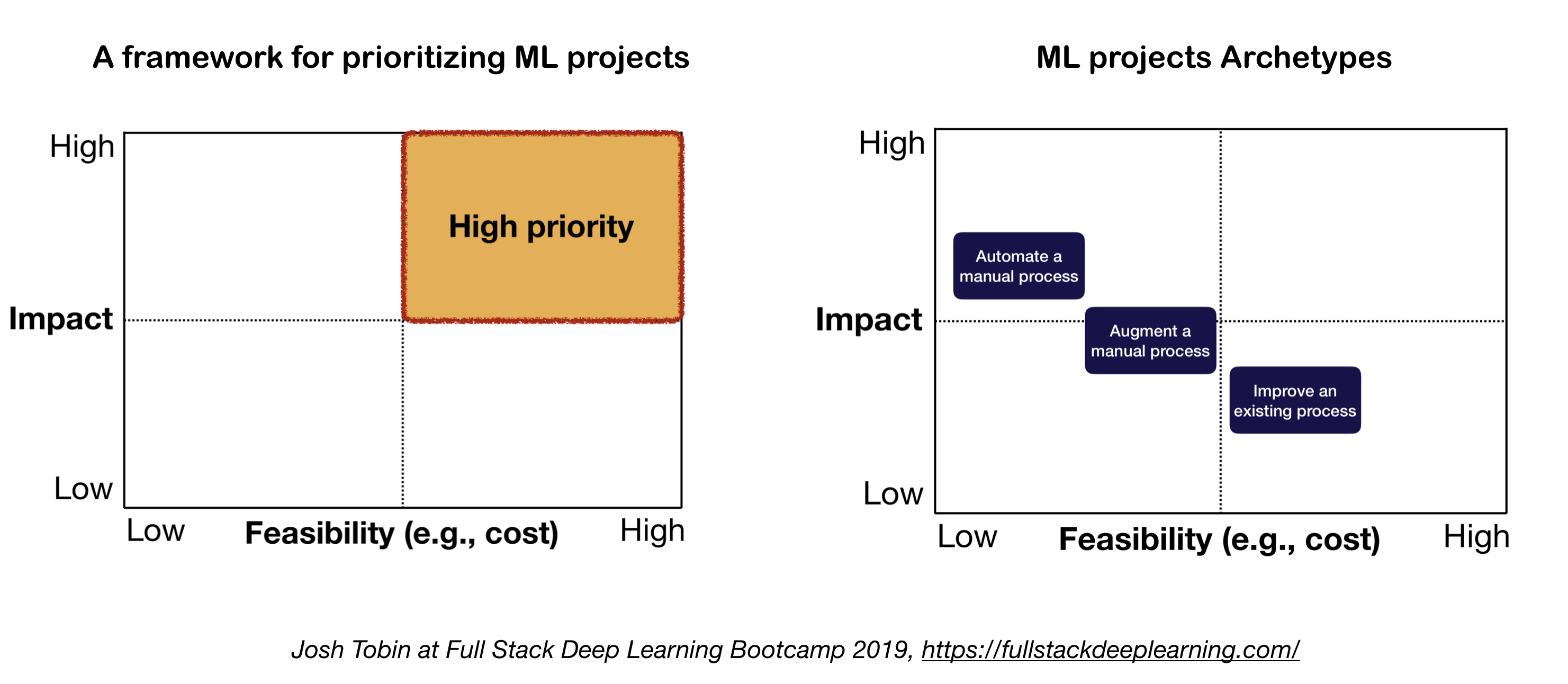
2. Modelo Mental para Projeto ML
Os dois fatores importantes a considerar ao definir e priorizar projetos de ML:
- Alto impacto:
- Partes complexas do seu pipeline
- Onde "previsão barata" é valiosa
- Onde automatizar o processo manual complicado é valioso
- Baixo custo:
- O custo é impulsionado por:
- Disponibilidade de dados
- Requisitos de desempenho: os custos tendem a escalar super-linearmente no requisito de precisão
- Dificuldade de problema:
- Alguns dos problemas difíceis incluem: aprendizado não supervisionado, aprendizado de reforço e certas categorias de aprendizado supervisionado
Oleoduto completo
A figura a seguir representa uma visão geral de alto nível de diferentes componentes em um sistema de aprendizado profundo no nível de produção:
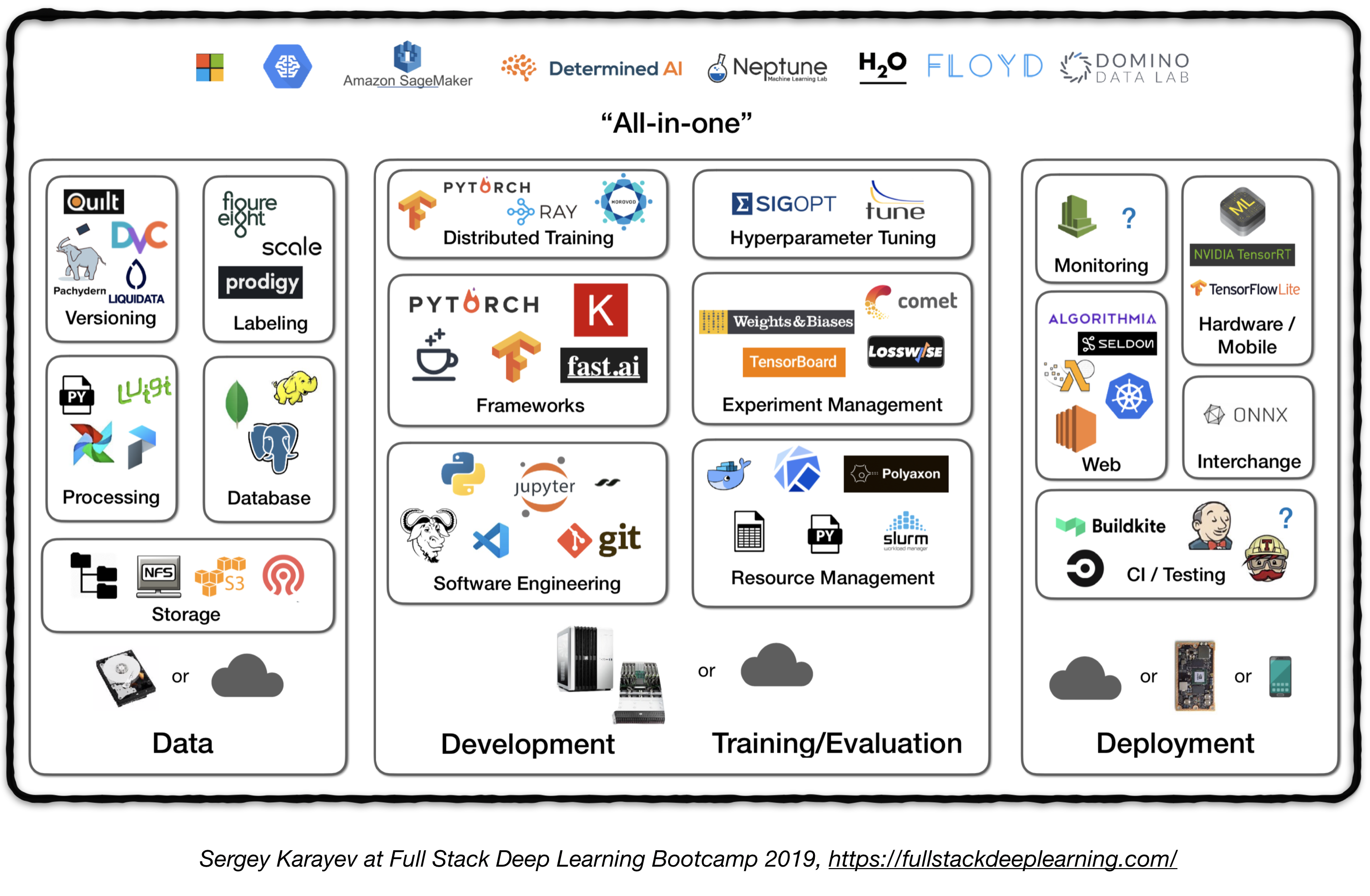
A seguir, passaremos por cada módulo e recomendaremos os conjuntos de ferramentas e estruturas, bem como as melhores práticas de profissionais que se encaixam em cada componente.
1. Gerenciamento de dados
1.1 fontes de dados
- Aprendizagem profunda supervisionada requer muitos dados rotulados
- Rotular os próprios dados é caro!
- Aqui estão alguns recursos para dados:
- Dados de código aberto (bom para começar, mas não uma vantagem)
- Aumento de dados (um obrigatório para visão computacional, uma opção para PNL)
- Dados sintéticos (quase sempre vale a pena começar, especialmente na NLP)
1.2 Rotulagem de dados
- Requer: pilha de software separada (plataformas de rotulagem), trabalho temporário e QC
- Fontes de trabalho para rotular:
- Crowdsourcing (turco mecânico): barato e escalável, menos confiável, precisa de QC
- Contratando seus próprios anotadores: menos QC necessário, caro, lento para escalar
- Empresas de serviço de rotulagem de dados:
- Plataformas de rotulagem:
- Diffgram: Software de Dados de Treinamento (Visão Computador)
- Prodigy: uma ferramenta de anotação alimentada por aprendizado ativo (por desenvolvedores de spacy), texto e imagem
- Hive: AI como uma plataforma de serviço para visão computacional
- Supervisamente: toda a plataforma de visão computacional
- LabelBox: Visão computacional
- Escala de plataforma de dados AI (Visão computacional e NLP)
1.3. Armazenamento de dados
- Opções de armazenamento de dados:
- Armazenamento de objetos : armazenar dados binários (imagens, arquivos de som, textos compactados)
- Amazon S3
- Ceph Object Store
- Banco de dados : armazenar metadados (caminhos de arquivo, etiquetas, atividade do usuário, etc.).
- O Postgres é a escolha certa para a maioria das aplicações, com o melhor SQL da categoria e ótimo suporte para JSON não estruturado.
- Data Lake : para agregar recursos que não são obtidos no banco de dados (por exemplo, logs)
- Armazenamento de recursos : armazenar, acessar e compartilhar recursos de aprendizado de máquina (a extração de recursos pode ser computacionalmente cara e quase impossível de dimensionar, portanto, reutilizar os recursos de diferentes modelos e equipes é a chave para as equipes de ML de alto desempenho).
- Feast (Google Cloud, Open Source)
- Paleta Michelangelo (Uber)
- Sugestão: No horário de treinamento, copie os dados em um sistema de arquivos local ou em rede (NFS). 1
1.4. Versão de dados
- É um "obrigatório" para os modelos ML implantados:
Os modelos ML implantados são código de peça, dados de peça . 1 Nenhuma versão de dados significa nenhuma versão do modelo. - Plataformas de versão de dados:
- DVC: sistema de controle de versão de código aberto para projetos de ML
- Pachyderm: controle de versão para dados
- Dolt: um banco de dados SQL com controle de versão do tipo Git para dados e esquema
1.5. Processamento de dados
- Os dados de treinamento para modelos de produção podem vir de diferentes fontes, incluindo dados armazenados em armazenamento de banco de dados e objetos , processamento de logs e saídas de outros classificadores .
- Existem dependências entre as tarefas, cada uma precisa ser iniciada após o término de suas dependências. Por exemplo, o treinamento sobre novos dados de log requer uma etapa de pré -processamento antes do treinamento.
- Makefiles não são escaláveis. O "Workflow Manager" se torna bastante essencial a esse respeito.
- Orquestração do fluxo de trabalho:
- Luigi por Spotify
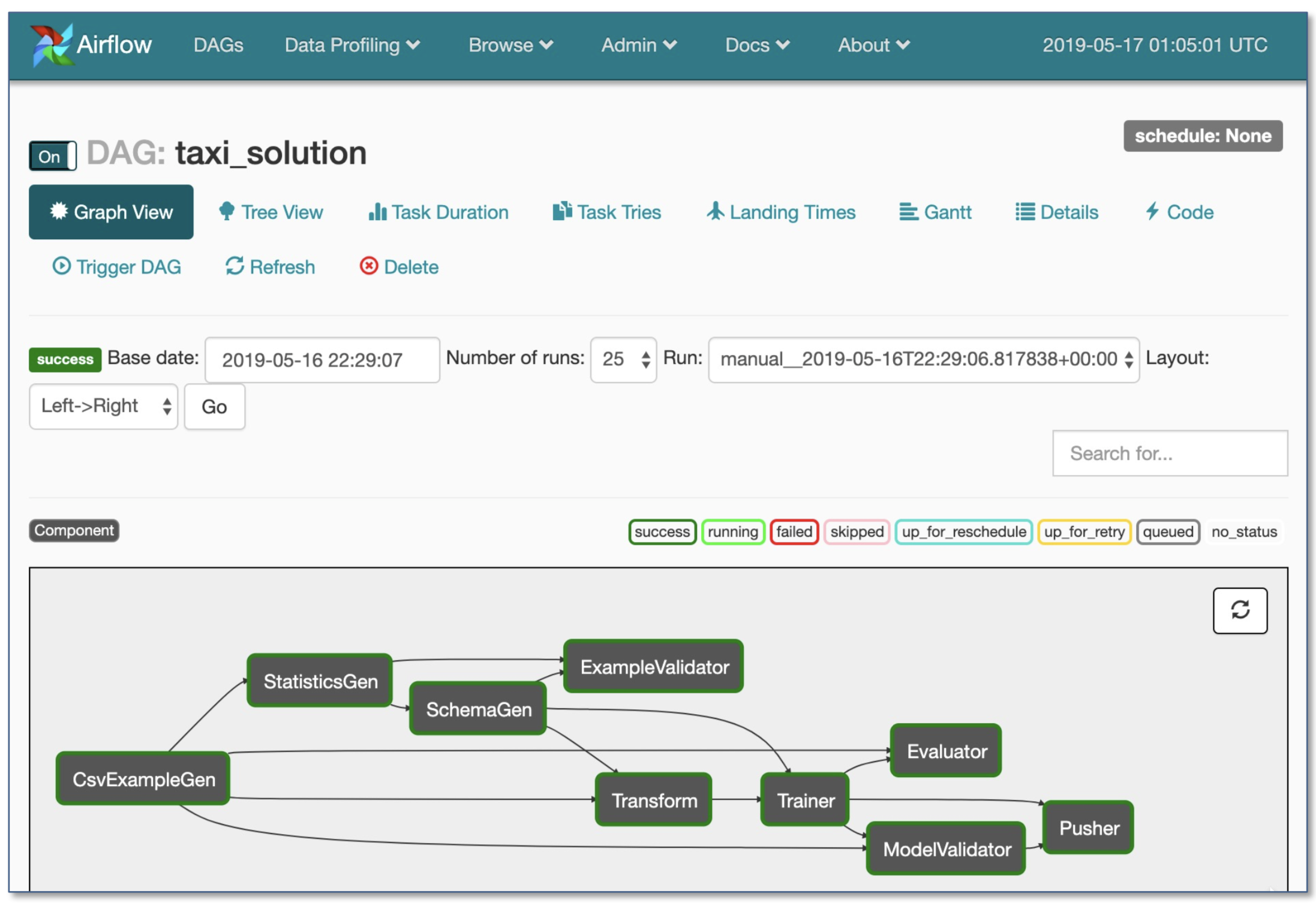
- Fluxo de ar por Airbnb: dinâmico, extensível, elegante e escalável (o mais amplamente utilizado)
- DAG Fluxo de trabalho
- Execução condicional robusta: novamente novamente em caso de falha
- Pusher suporta imagens do Docker com porção de tensorflow
- Fluxo de trabalho inteiro em um único arquivo .py
2. Desenvolvimento, treinamento e avaliação
2.1. Engenharia de software
- Idioma do vencedor: Python
- Editores:
- Vim
- Emacs
- Vs código (recomendado pelo autor): estadiamento Git interno e diff, código de fiapos, projetos abertos remotamente através do SSH
- Notebooks: Ótimo como ponto de partida dos projetos, difícil de dimensionar (Fato divertido: a arquitetura orientada a notebooks da Netflix é uma exceção, que é inteiramente baseada em suítes NTERACT).
- NTERACT: Uma interface do usuário baseada em reagir de última geração para notebooks Jupyter
- Papgemill: é uma biblioteca NTERACT construída para parametrização , execução e análise de notebooks Jupyter.
- Computação: Outro projeto NTERACT que fornece uma exibição somente leitura de notebooks (por exemplo, da S3 Buckets).
- Relacionamento: ferramenta interativa de ciência de dados com applets
- Computar Recomendações 1 :
- Para indivíduos ou startups :
- Desenvolvimento: um PC de 4x Turing-Architecture
- Treinamento/avaliação: use o mesmo PC 4x GPU. Ao executar muitos experimentos, compre servidores compartilhados ou use instâncias em nuvem.
- Para grandes empresas:
- Desenvolvimento: Compre um PC 4x Turing-Architecture por ML Scientist ou deixe-os usar instâncias V100
- Treinamento/Avaliação: Use instâncias de nuvem com provisionamento e manuseio adequados de falhas
- Provedores de nuvem:
- GCP: opção para conectar as GPUs a qualquer instância + tem TPUs
- AWS:
2.2. Gerenciamento de recursos
- Alocando recursos gratuitos para programas
- Opções de gerenciamento de recursos:
- Antigo agendador de trabalhos de cluster da escola (por exemplo, Slurm Workload Manager)
- Docker + Kubernetes
- Kubeflow
- Polyaxon (recursos pagos)
2.3. Estruturas DL
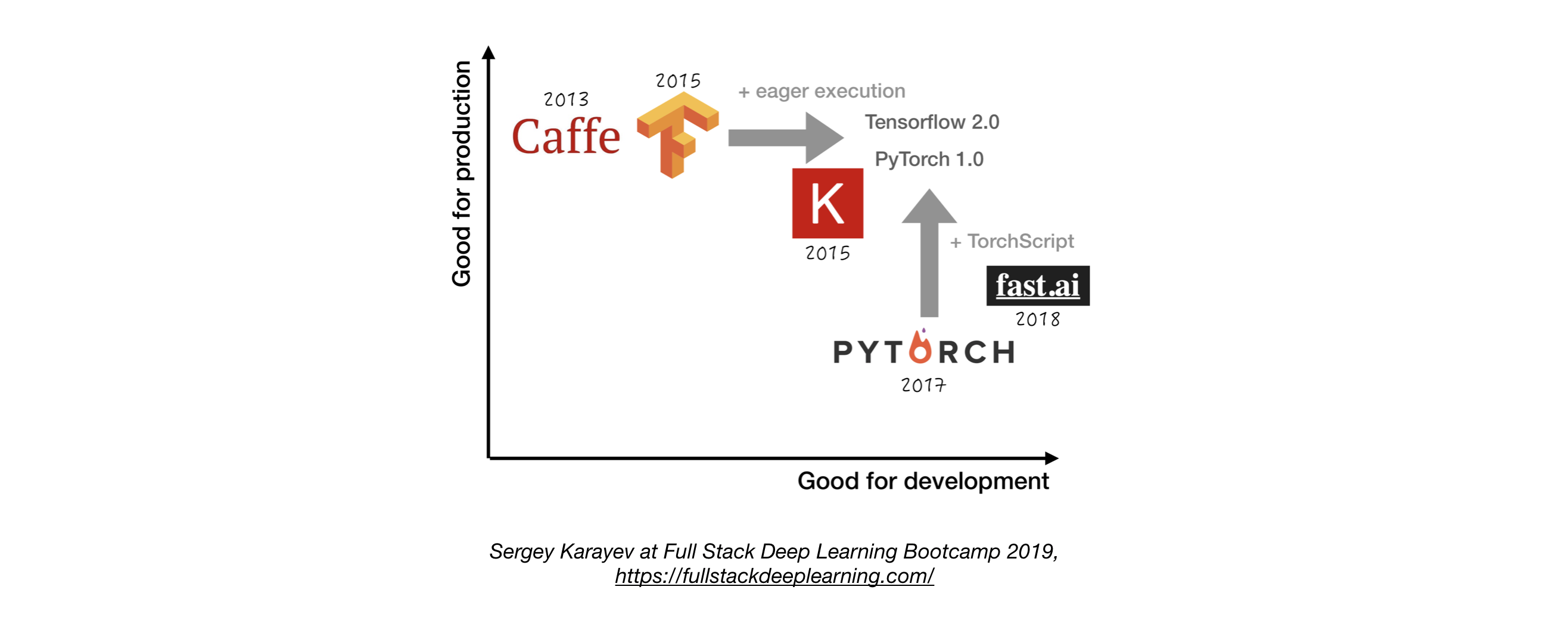
- A menos que tenha um bom motivo para não, use Tensorflow/Keras ou Pytorch. 1
- A figura a seguir mostra uma comparação entre diferentes estruturas sobre como elas representam "desenvolvimento" e "produção" .
2.4. Gerenciamento de experimentos
- Estratégia de Desenvolvimento, Treinamento e Avaliação:
- Sempre comece simples
- Treine um modelo pequeno em um pequeno lote. Somente se funcionar, escala para dados e modelos maiores e ajuste hiperparâmetro!
- Ferramentas de gerenciamento de experimentos:
- Tensorboard
- fornece a visualização e ferramentas necessárias para a experimentação de ML
- Perdas (monitoramento para ML)
- Cometa: permite rastrear código, experimentos e resultados em projetos de ML
- Pesos e vieses: registre e visualize todos os detalhes de sua pesquisa com fácil colaboração
- Rastreamento MLFlow: para parâmetros de registro, versões de código, métricas e arquivos de saída, bem como a visualização dos resultados.
- Rastreamento automático de experimentos com uma linha de código no Python
- Comparação lado a lado de experimentos
- Ajuste de parâmetro hiper
- Suporta empregos baseados em Kubernetes
2.5. Ajuste hiperparâmetro
Abordagens:
- Pesquisa de grade
- Pesquisa aleatória
- Otimização bayesiana
- Algoritmo sucessivo de hiperband e sucessivo pela metade (Asha) (Asha)
- Treinamento de base populacional
Plataformas:
- RayTune: Ray Tune é uma biblioteca Python para o ajuste de hiperparâmetro em qualquer escala (com foco no aprendizado profundo e no aprendizado de reforço profundo). Suporta qualquer estrutura de aprendizado de máquina, incluindo Pytorch, XGboost, MXNET e Keras.
- Katib: Kubernete's Native System for Hyperparameter Tuning and Neural Architecture Search, inspired by [Google vizier](https://static.googleusercontent.com/media/ research.google.com/ja//pubs/archive/ bcb15507f4b52991a0783013df4222240e942381.pdf) e suporta várias estruturas ML/DL (por exemplo, Tensorflow, MxNet e Pytorch).
- Hiperas: um invólucro simples em torno do hiporopt para as Keras, com uma notação de modelo simples para definir intervalos de hiper-parâmetro para sintonizar.
- SIGOpt: uma plataforma de otimização escalável e de grau corporativo
- Varreduras de [pesos e vieses] (https://www.wandb.com/): os parâmetros não são explicitamente especificados por um desenvolvedor. Em vez disso, eles são aproximados e aprendidos por um modelo de aprendizado de máquina.
- Afinador de Keras: um sintonizador de hiperparâmetro para Keras, especificamente para tf.keras com tensorflow 2.0.
2.6. Treinamento distribuído
- Paralelismo de dados: use -o quando o tempo de iteração for muito longo (suporte de tensorflow e pytorch)
- Treinamento distribuído de Ray
- Paralelismo do modelo: quando o modelo não se encaixa em uma única GPU
- Outras soluções:
3. Solução de problemas [TBD]
4. Teste e implantação
4.1. Teste e CI/CD
O software de produção de aprendizado de máquina requer um conjunto mais diversificado de suítes de teste do que o software tradicional:
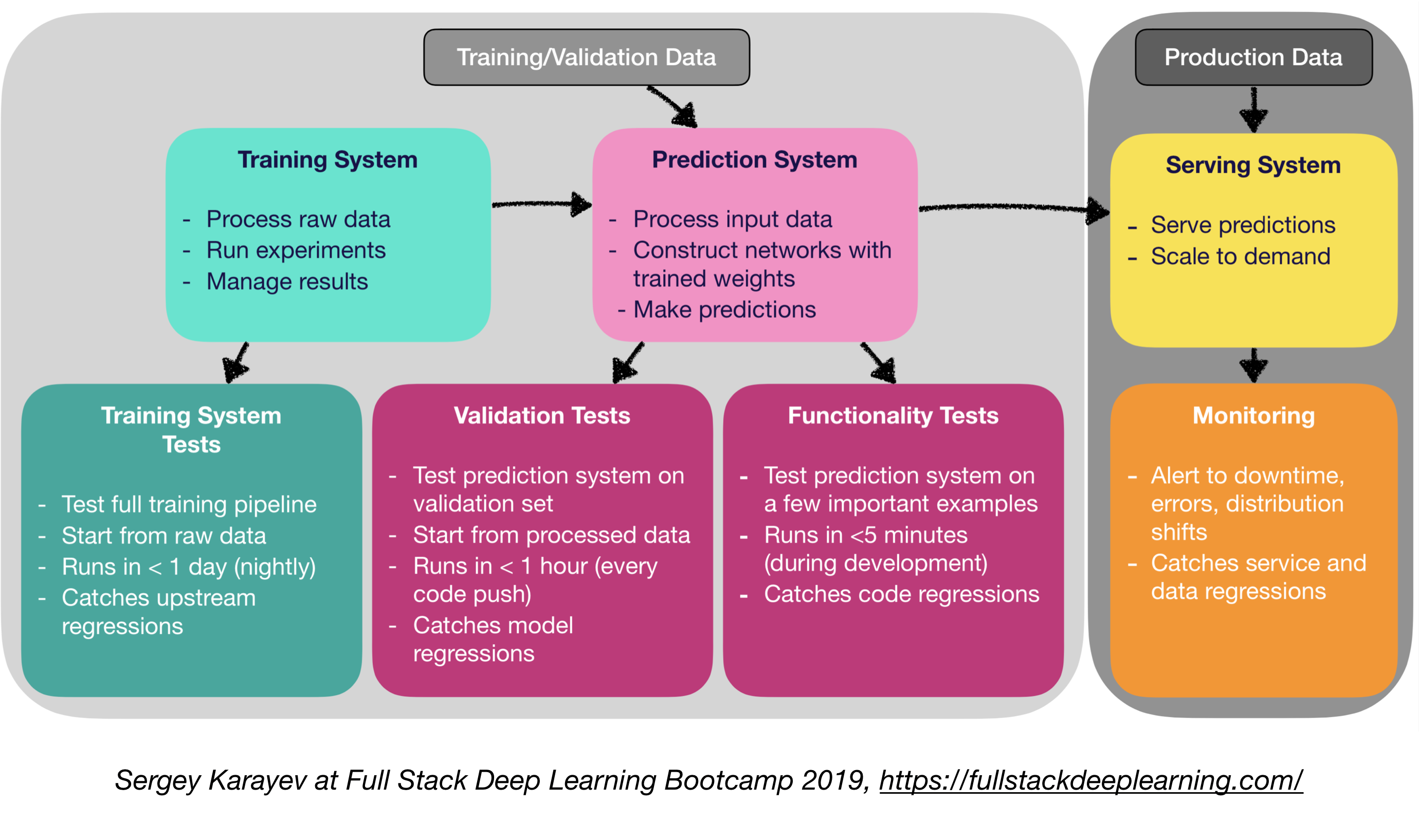
- Teste de unidade e integração:
- Tipos de testes:
- Testes do sistema de treinamento: Testando o pipeline de treinamento
- Testes de validação: sistema de previsão de teste no conjunto de validação
- Testes de funcionalidade: Testando o sistema de previsão em poucos exemplos importantes
- Integração contínua: executando testes após cada nova mudança de código empurrada para o repositório
- SaaS para integração contínua:
- Argo: Open Source Kubernetes Native Workflow Engine para orquestrar trabalhos paralelos (incuda fluxos de trabalho, eventos, CI e CD).
- CircleCi: Suporte incluído em linguagem, ambientes personalizados, alocação de recursos flexíveis, usada por Instacart, Lyft e StackShare.
- Travis CI
- BuildKite: Construções rápidas e estáveis, agente de código aberto é executado em quase qualquer máquina e arquitetura, liberdade para usar suas próprias ferramentas e serviços
- Jenkins: Sistema de construção da velha escola
4.2. Implantação da web
- Consiste em um sistema de previsão e um sistema de porção
- Sistema de Previsão: Processar dados de entrada, fazer previsões
- Sistema de servir (servidor da web):
- Servir previsão com escala em mente
- Use REST API para servir solicitações HTTP de previsão
- Chama o sistema de previsão para responder
- Opções de servir:
- Implantar para VMs, escala adicionando instâncias
- Implantar como contêineres, escala via orquestração
- Contêineres
- Orquestração de contêineres:
- Kubernetes (o mais popular agora)
- Mesos
- Maratona
- Implante o código como uma "função sem servidor"
- Implantar através de uma solução de porção de modelo
- Modelo Serviço:
- Implantação especializada na web para modelos ML
- Lotes de solicitação de inferência de GPU
- Estruturas:
- Serviço Tensorflow
- MXNET Model Server
- Clipper (Berkeley)
- Soluções SaaS
- Seldon: servir e escalar modelos construídos em qualquer estrutura em Kubernetes
- Algoritmia
- Tomada de decisão: CPU ou GPU?
- Inferência da CPU:
- A inferência da CPU é preferível se atender aos requisitos.
- Escala adicionando mais servidores ou sem servidor.
- Inferência da GPU:
- TF Serviço ou Clipper
- Lotes adaptativos são úteis
- (Bônus) implantando notebooks Jupyter:
- A Kubeflow Fairing é um pacote de implantação híbrido que permite implantar seus códigos de notebook Jupyter !
4.5 malha de serviço e roteamento de tráfego
- A transição de aplicações monolíticas para uma arquitetura de microsserviço distribuída pode ser um desafio.
- Uma malha de serviço (composta por uma rede de microsserviços) reduz a complexidade de tais implantações e facilita a tensão nas equipes de desenvolvimento.
- ISTIO: Uma malha de serviço para facilitar a criação de uma rede de serviços implantados com balanceamento de carga, autenticação de serviço a serviço, monitoramento, com poucas ou nenhuma alteração de código no código de serviço.
4.4. Monitoramento:
- Objetivo do monitoramento:
- Alertas para o tempo de inatividade, erros e turnos de distribuição
- Catching Service and Data Regressions
- As soluções de provedores de nuvem são decentes
- Kiali: um console de observabilidade para o ISTIO com recursos de configuração de malha de serviço. Ele responde a estas perguntas: Como os microsserviços estão conectados? Como eles estão se saindo?
Terminamos?

4.5. Implantando em dispositivos incorporados e móveis
- Desafio principal: pegada de memória e restrições de computação
- Soluções:
- Quantização
- Tamanho do modelo reduzido
- Destilação do conhecimento
- Estruturas incorporadas e móveis:
- Tensorflow Lite
- Pytorch Mobile
- Core Ml
- Kit ML
- Fritz
- Openvino
- Conversão de modelo:
- Open Neural Network Exchange (ONNX): formato de código aberto para modelos de aprendizado profundo
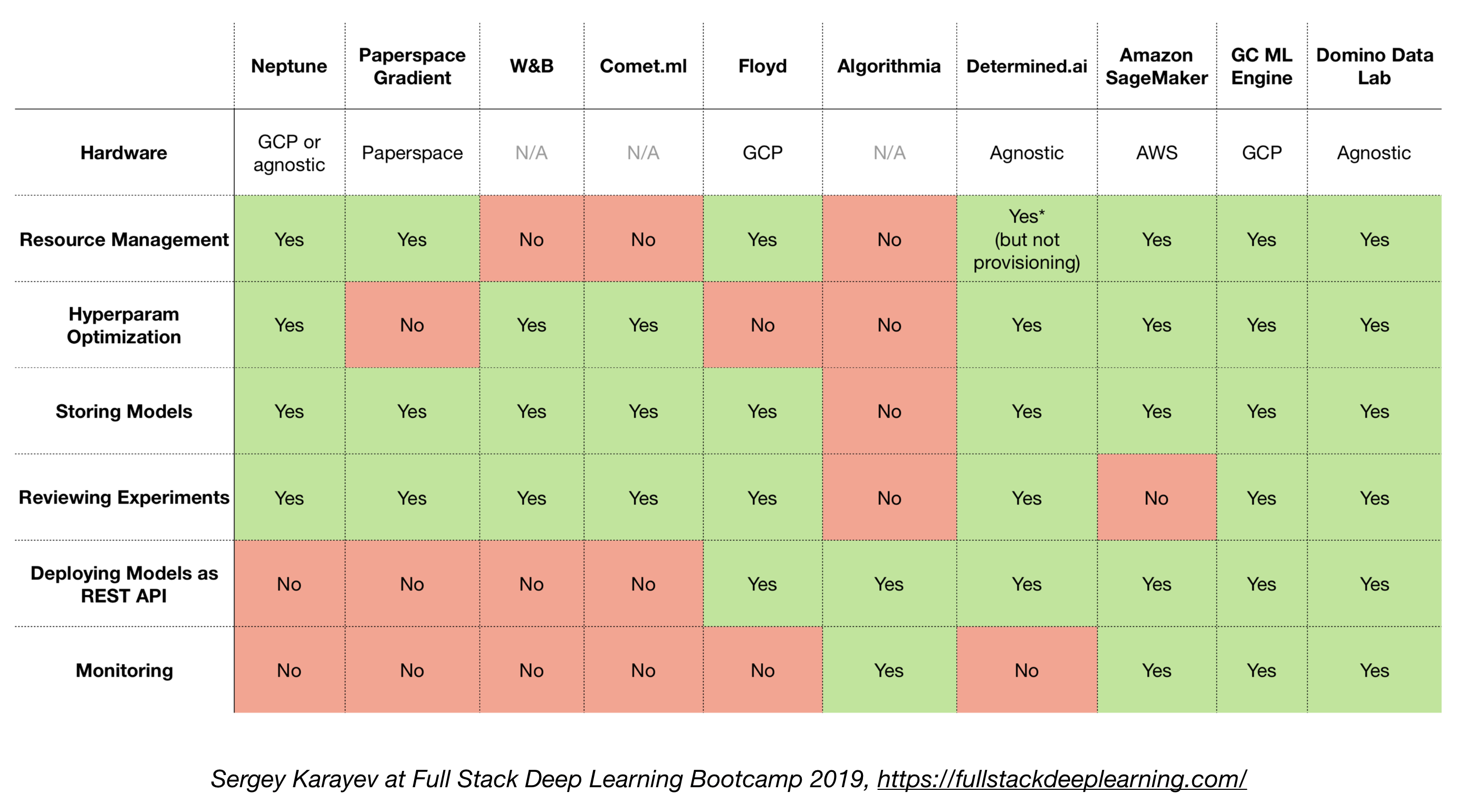
4.6. Soluções all-in-one
- Tensorflow estendido (TFX)
- Michelangelo (Uber)
- Plataforma do Google Cloud AI
- Amazon Sagemaker
- Netuno
- Floyd
- Paperspace
- AI determinada
- Domino Data Data Lab
Tensorflow estendido (TFX)
[TBD]
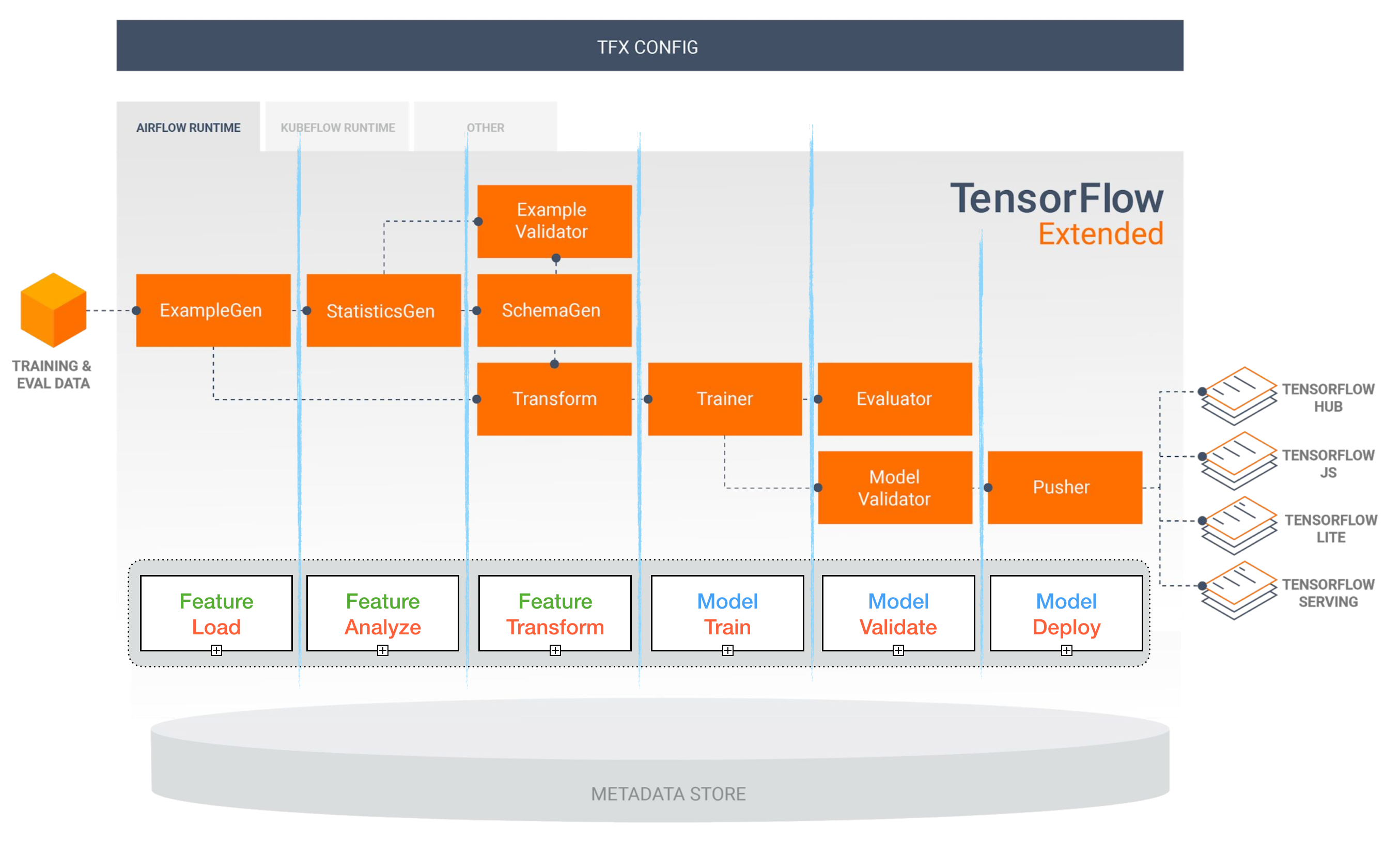
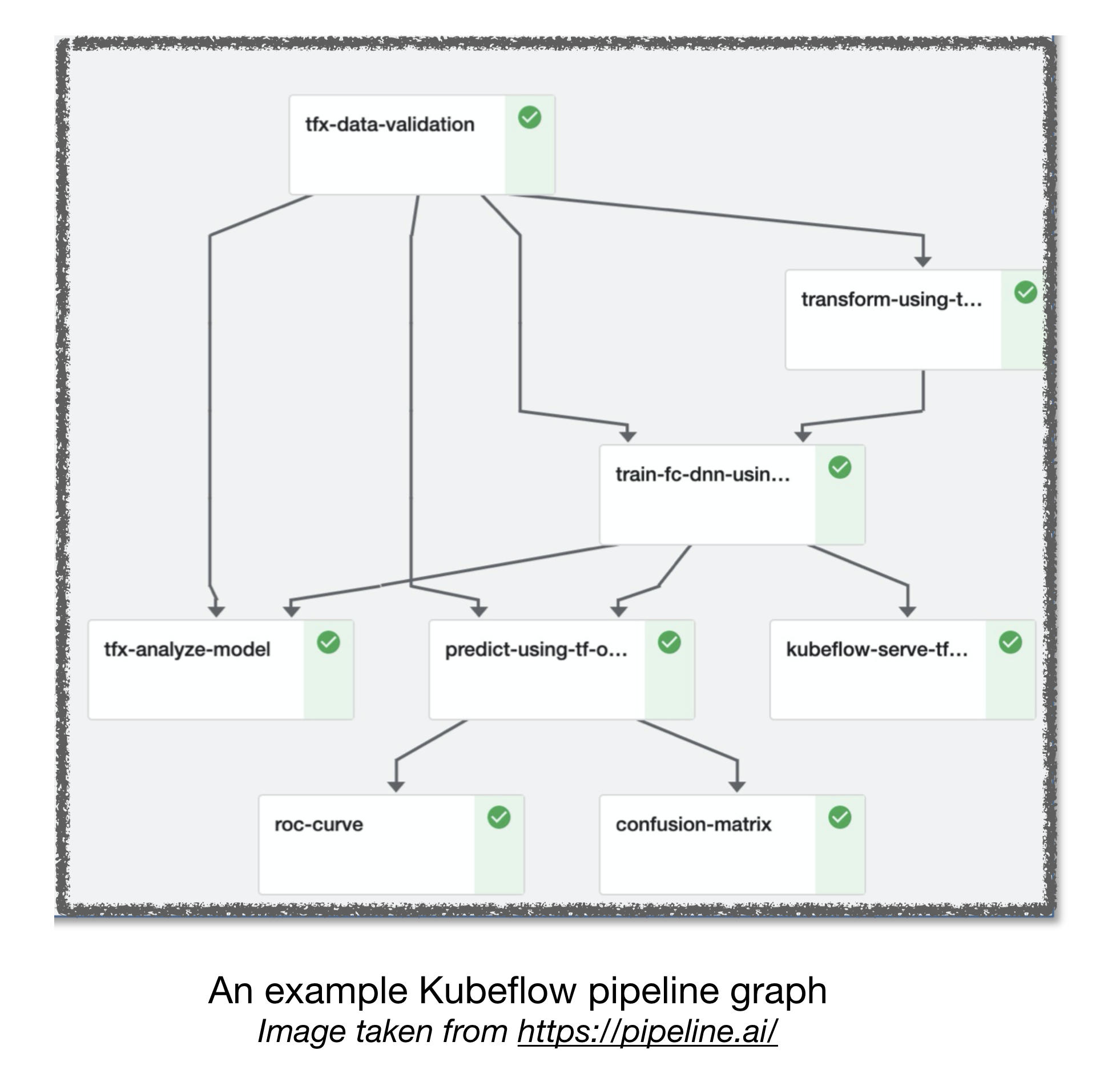
Pipelines de fluxo de ar e kubeflow
[TBD]
Outros links úteis:
- Lições aprendidas com a construção de sistemas práticos de aprendizado profundo
- Aprendizado de máquina: o cartão de crédito de alto juros de dívida técnica
Contribuindo
Referências:
[1]: Full Stack Deep Learning Bootcamp, novembro de 2019.
[2]: Workshop avançado de Kubeflow por pipeline.ai, 2019.
[3]: TFX: aprendizado de máquina do mundo real em produção


