Руководство по глубокому обучению уровня производства? ⛴
?? Перевод на китайском языке
? ️ Новый: Интервью машинного обучения
️ Примечание: этот репо находится под постоянным развитием, и все отзывы и вклад очень приветствуются?
Развертывание моделей глубокого обучения в производстве может быть сложным, так как оно выходит далеко за рамки тренировочных моделей с хорошей производительностью. Несколько отдельных компонентов должны быть разработаны и разработаны, чтобы развернуть систему глубокого обучения на уровне производства (показано ниже):
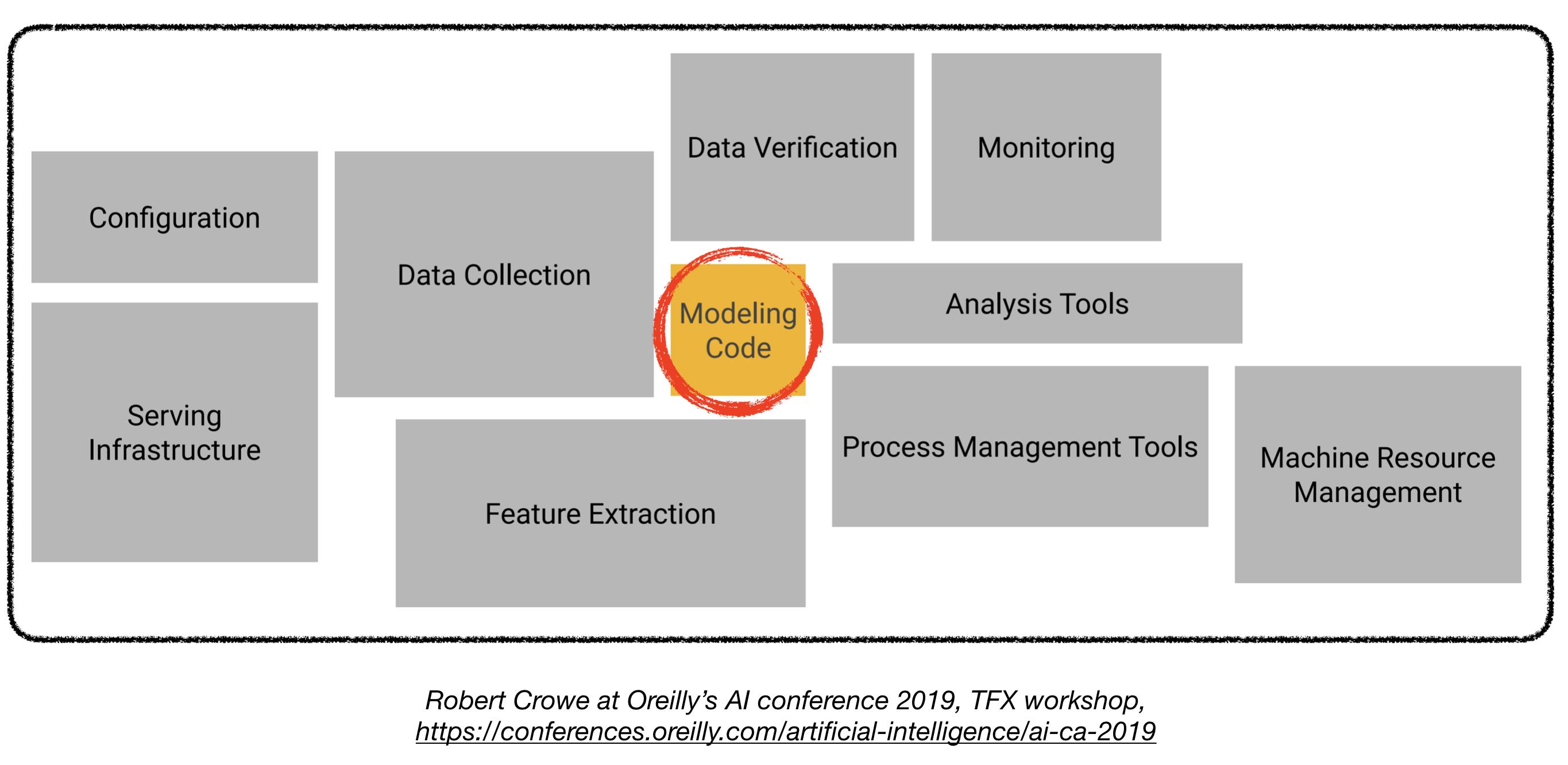
Это репошет, направленное на то, чтобы стать инженерным руководством по созданию систем глубокого обучения на уровне производства, которые будут развернуты в реальных приложениях.
Материал, представленный здесь, заимствован из полного стека глубокого обучения Bootcamp (Pieter Abbeel в UC Berkeley, Джош Тобине в Openai и Сергея Караеев в Turnitin), TFX Workshop Роберта Кроу и Pipeline.ai's Advanced Kubeflow Meetup от Криса Фрегли.
Проекты машинного обучения
Веселье ? Факт: 85% проектов искусственного интеллекта терпят неудачу . 1 Потенциальные причины включают:
- Технически невозмутимо или плохо
- Никогда не делайте прыжок на производство
- Неясные критерии успеха (метрики)
- Плохое управление командой
1. ML Проект жизненный цикл
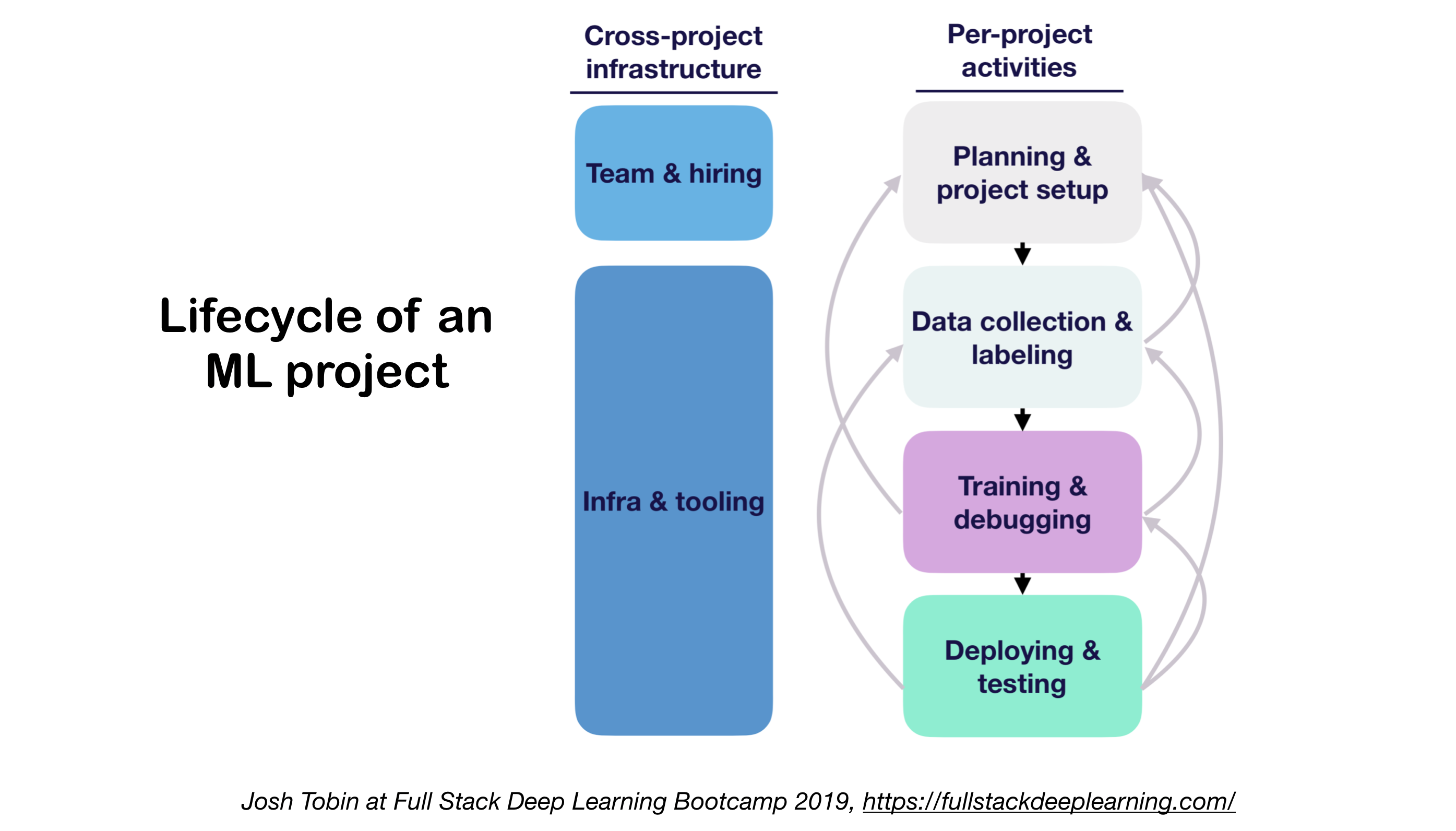
- Важность понимания состояния искусства в вашем домене:
- Помогает понять, что возможно
- Помогает узнать, что попробовать дальше
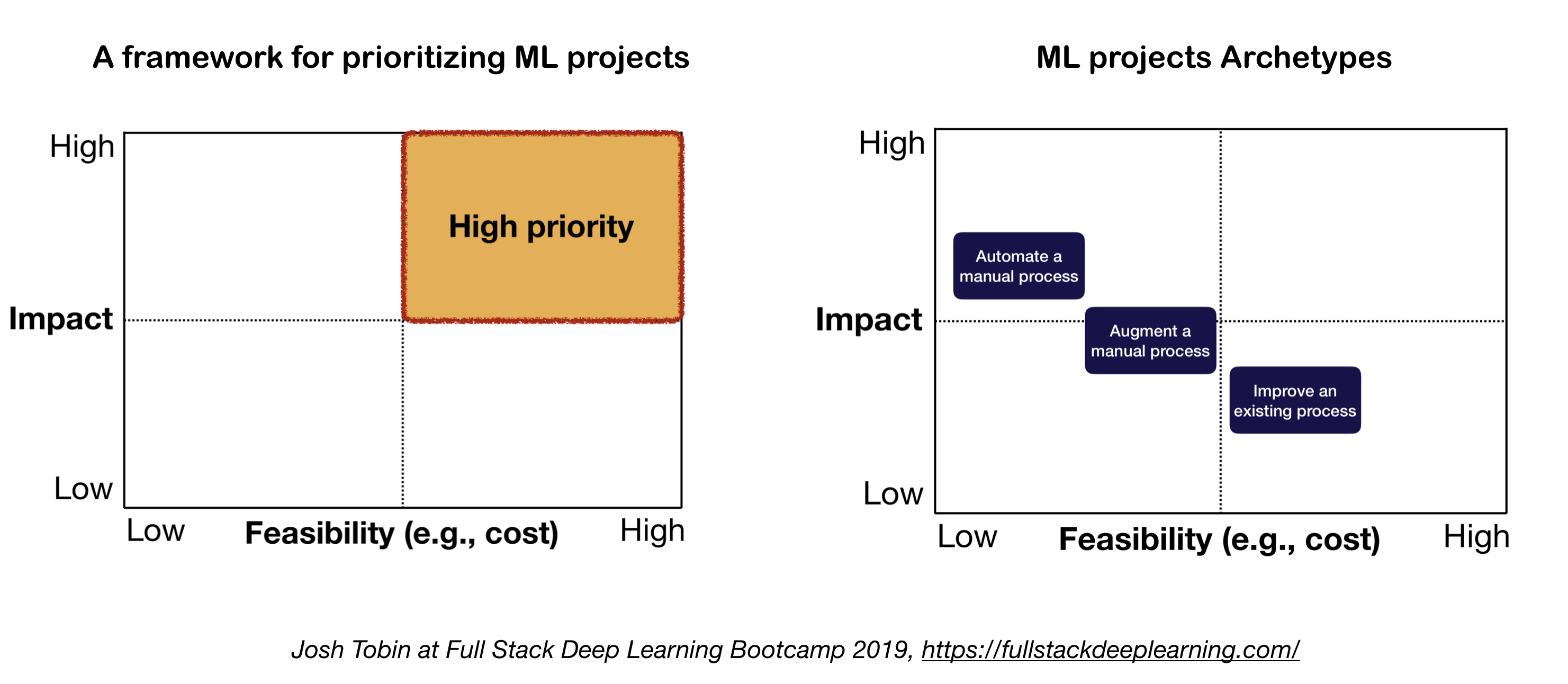
2. Ментальная модель для проекта ML
Два важных фактора, которые следует учитывать при определении и определении приоритетов проектов ML:
- Высокое влияние:
- Сложные части вашего трубопровода
- Где «дешевый прогноз» ценен
- Где автоматизация сложного ручного процесса является ценным
- Бюджетный:
- Стоимость обусловлена:
- Доступность данных
- Требования к производительности: затраты имеют тенденцию к значительному масштабированию в требованиях точности
- Проблема Сложность:
- Некоторые из сложных проблем включают: неконтролируемое обучение, обучение подкреплению и определенные категории контролируемого обучения
Полный трубопровод
Следующий рисунок представляет собой обзор высокого уровня различных компонентов в системе глубокого обучения на уровне производства:
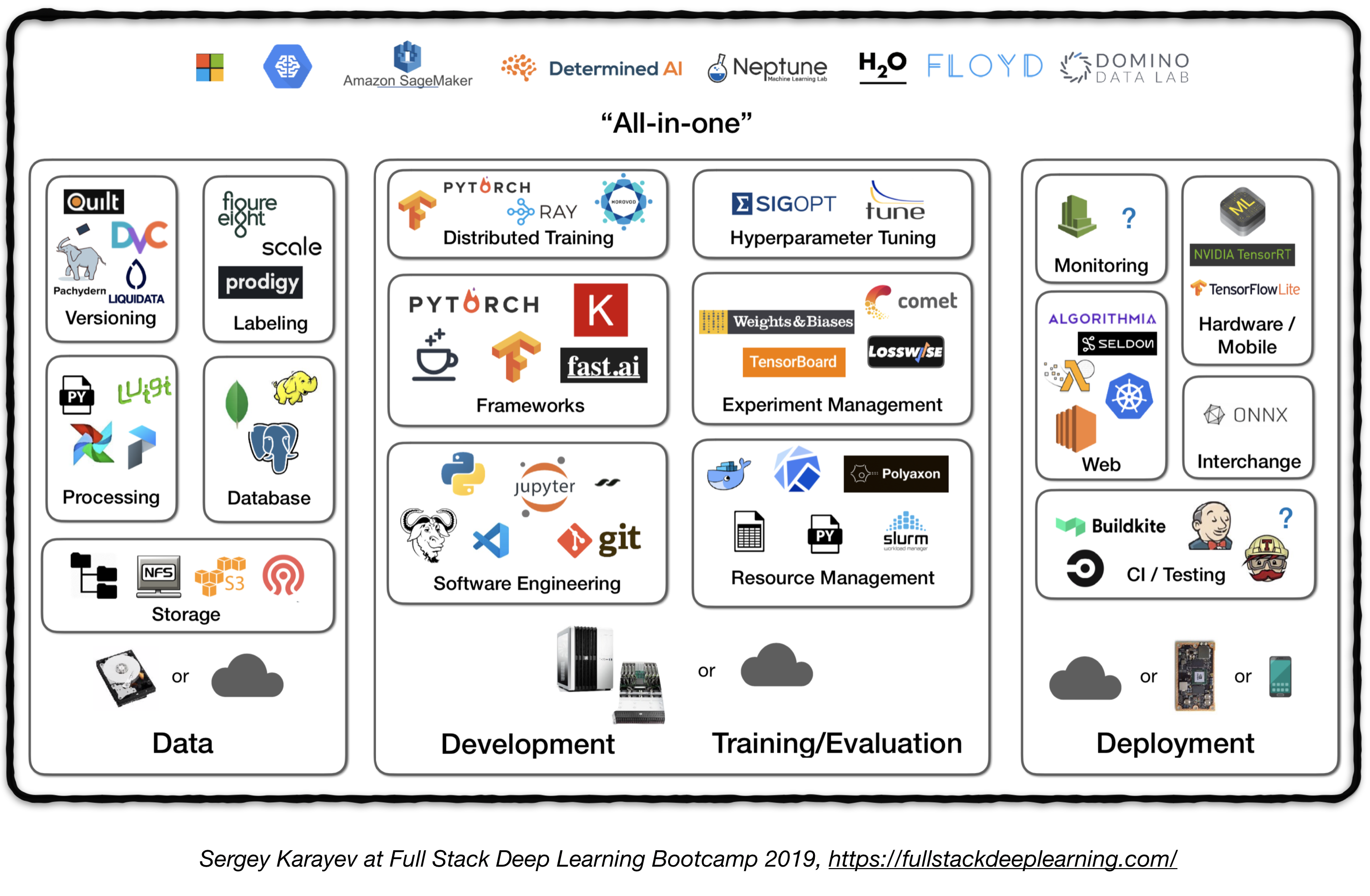
Далее мы пройдем через каждый модуль и рекомендуем наборы инструментов и структуры, а также лучшие практики от практикующих, которые соответствуют каждому компоненту.
1. Управление данными
1.1 Источники данных
- Под наблюдением глубокого обучения требуется много маркированных данных
- Маркировка собственных данных дорого!
- Вот несколько ресурсов для данных:
- Данные с открытым исходным кодом (хорошо для начала, но не преимущество)
- Увеличение данных (необходимо для компьютерного зрения, опция для NLP)
- Синтетические данные (почти всегда стоит начать с, особенно в NLP)
1.2 Маркировка данных
- Требуется: отдельный программный стек (маркировка платформ), временный труд и QC
- Источники труда для маркировки:
- Краудсорсинг (механический турок): дешевый и масштабируемый, менее надежный, нуждается в QC
- Наем собственных аннотаторов: меньше необходимого, дорогого, медленного масштабирования
- Компании по маркировке данных:
- Платформы маркировки:
- Diffgram: программное обеспечение для обучения данных (Computer Vision)
- Вундеркинд: Аннотация инструмента, основанного на активном обучении (разработчиками Spacy), текста и изображения
- Улей: ИИ как сервисная платформа для компьютерного зрения
- Наблюдательно: вся платформа компьютерного зрения
- Labelbox: Computer Vision
- Платформа данных AI Scale (Computer Vision & NLP)
1.3. Хранилище данных
- Параметры хранения данных:
- Хранение объекта : хранить двоичные данные (изображения, звуковые файлы, сжатые тексты)
- Amazon S3
- Ceph Object Store
- База данных : хранить метаданные (пути файлов, метки, активность пользователя и т. Д.).
- Postgres является правильным выбором для большинства приложений, с лучшим в своем классе SQL и отличной поддержкой неструктурированного JSON.
- Озеро данных : для агрегирования функций, которые не доступны из базы данных (например, журналы)
- Магазин функций : хранить, доступ и обмен функциями машинного обучения (извлечение функций может быть вычислительно дорогим и практически невозможным для масштабирования, поэтому повторное использование функций различными моделями и командами является ключом к высокопроизводительным командам ML).
- Праздник (Google Cloud, открытый исходный код)
- Микеланджело палитра (Uber)
- Предложение: во время обучения копируйте данные в локальную или сетевую файловую систему (NFS). 1
1.4. Версии данных
- Это «обязательно» для развернутых моделей ML:
Развернутые модели ML - это код детали, данные детали . 1 Нет версий данных не означает, что модель версий. - Платформы передачи версий данных:
- DVC: система управления версиями с открытым исходным кодом для проектов ML
- Pachyderm: контроль версий для данных
- DOLT: база данных SQL с GIT-подобным управлением версиями для данных и схемы
1.5. Обработка данных
- Обучающие данные для производственных моделей могут поступать из разных источников, включая сохраненные данные в накоплении БД и объектов , обработку журнала и выходы других классификаторов .
- Существуют зависимости между задачами, каждый должен быть запущен после завершения его зависимостей. Например, обучение по новым данным журнала требуется предварительный шаг перед обучением.
- Makefiles не масштабируемы. "Управляющий рабочим процессом становится довольно важным в этом отношении.
- Оркестровая рабочего процесса:
- Луиджи от Spotify
- Воздушный поток от Airbnb: динамичный, расширяемый, элегантный и масштабируемый (наиболее широко используется)
- DAG Workflow
- Надежное условное исполнение: повторно в случае неудачи
- Pusher поддерживает изображения Docker с помощью TensorFlow Aerding
- Весь рабочий процесс в одном файле .py
2. Разработка, обучение и оценка
2.1. Программное обеспечение
- Язык победителей: Python
- Редакторы:
- Вим
- Эмац
- VS-код (рекомендуется автором): встроенная постановка GIT и DIFF, код LINT, открытые проекты удаленно через SSH
- Записные книжки: Отличная отправная точка проектов, трудно масштабироваться (забавный факт: архитектура Netflix, управляемая ноутбуками, является исключением, которое полностью основано на Suites Nteract).
- Nteract: пользовательский интерфейс на основе реагирования на основе реагирования для ноутбуков Юпитера
- Papermill: это библиотека Nteract, созданная для параметризации , выполнения и анализа ноутбуков Jupyter.
- Commuter: еще один проект Nteract, который предоставляет отображение ноутбуков только для чтения (например, из ковшом S3).
- Уличание: интерактивный инструмент науки о данных с апплетами
- Вычислить рекомендации 1 :
- Для отдельных лиц или стартапов :
- Разработка: 4-кратный ПК архитектуры
- Обучение/оценка: используйте тот же ПК 4x графического процессора. При проведении многих экспериментов купите общие серверы или используйте облачные экземпляры.
- Для крупных компаний:
- Разработка: купите 4-кратный ПК-архитектуру на мл ученого или позвольте им использовать экземпляры V100
- Обучение/оценка: используйте облачные экземпляры с надлежащим предоставлением и обработкой неудач
- Облачные провайдеры:
- GCP: опция для подключения графических процессоров к любому экземпляру + имеет TPUS
- AWS:
2.2. Управление ресурсами
- Распределение бесплатных ресурсов на программы
- Параметры управления ресурсами:
- Планировщик рабочих мест старой школы (например, менеджер рабочей нагрузки Slurm)
- Docker + Kubernetes
- Kubeflow
- Полиаксон (платные функции)
2.3. DL Frameworks
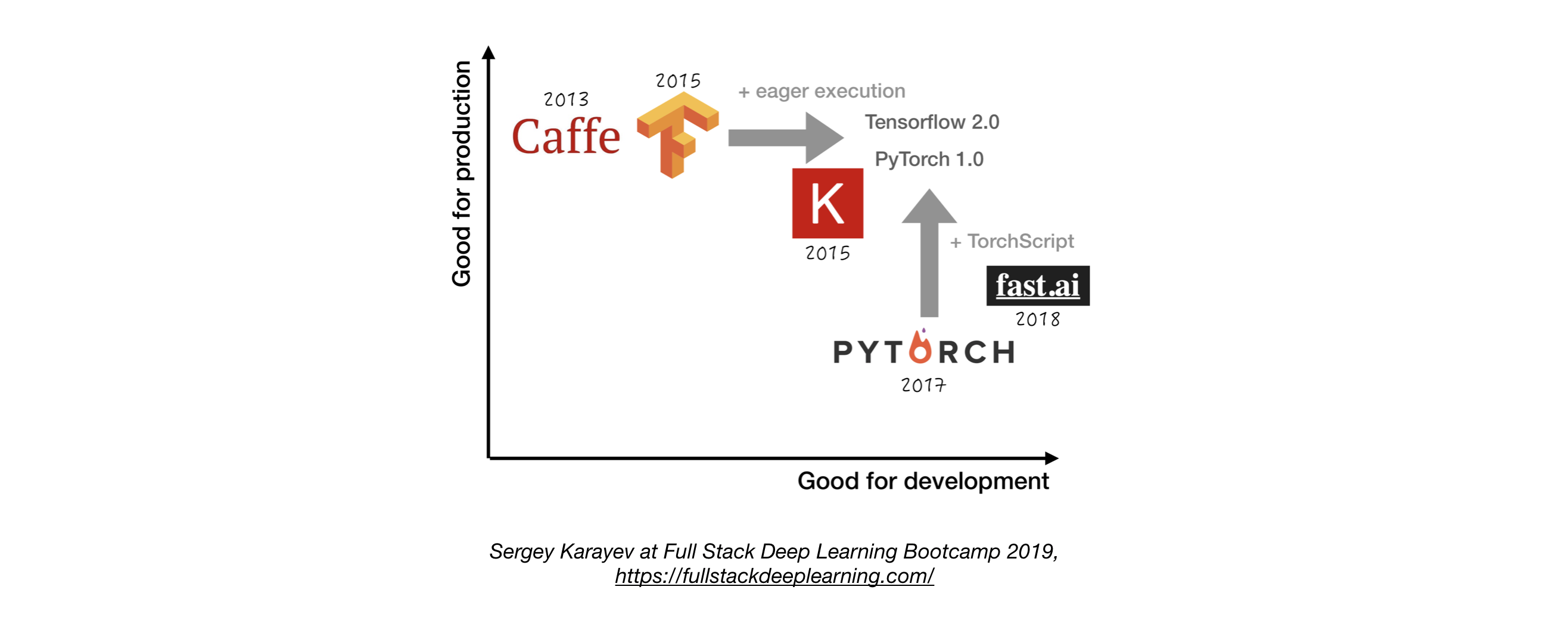
- Если не иметь веской причины, используйте Tensorflow/Keras или Pytorch. 1
- На следующем рисунке показано сравнение между различными рамками о том, как они обозначают «разработку» и «производство» .
2.4. Управление экспериментом
- Разработка, обучение и стратегия оценки:
- Всегда начинайте просто
- Тренируйте небольшую модель на небольшую партию. Только если он работает, масштабируйте до более крупных данных и моделей, а также настройку гиперпараметра!
- Инструменты управления экспериментом:
- Тенсорборд
- Обеспечивает визуализацию и инструменты, необходимые для экспериментов ML
- Потеря (мониторинг ML)
- Комета: позволяет отслеживать код, эксперименты и результаты в проектах ML
- Вес и смещения: запишите и визуализируйте каждую деталь вашего исследования с легким сотрудничеством
- Отслеживание Mlflow: для параметров журнала, кодовых версий, метрик и выходных файлов, а также визуализации результатов.
- Автоматическое отслеживание экспериментов с одной строкой кода в Python
- Бок о бок сравнение экспериментов
- Гипер -параметра настройка
- Поддерживает рабочие места на основе Kubernetes
2.5. Настройка гиперпараметра
Подходы:
- Поиск сетки
- Случайный поиск
- Байесовская оптимизация
- Гипербан и асинхронный алгоритм последовательного пополам (Asha)
- Население обучения
Платформы:
- Raytune: Ray Tune - это библиотека Python для настройки гиперпараметров в любом масштабе (с акцентом на глубокое обучение и глубокое обучение подкреплению). Поддерживает любую структуру машинного обучения, включая Pytorch, Xgboost, Mxnet и Keras.
- Katib: Нативная система Kubernete для настройки гиперпараметрических и нейронных архитектуры, вдохновленная [Google Vizier] (https://static.googleusercontent.com/media/ Research.google.com/ja//pubs/archive/ bcb15507f4b52991a0783013df42224078181814281818181818181818181818181818181818181818181818181818181818141510707141414141717171717171013301130113013013 гг. поддерживает несколько фреймворков ML/DL (например, Tensorflow, MXNET и Pytorch).
- Hyperas: простая обертка вокруг Hyperopt для керас, с простым шаблоном для определения гиперпараметрических диапазонов для настройки.
- Sigopt: масштабируемая платформа оптимизации предприятия
- Защиты от [веса и смещения] (https://www.wandb.com/): параметры явно не указаны разработчиком. Вместо этого они аппроксимированы и изучены моделью машинного обучения.
- Керас -тюнер: тюнер гиперпараметров для керов, специально для TF.keras с Tensorflow 2.0.
2.6 Распределенное обучение
- Параллелизм данных: используйте его, когда время итерации слишком длинное (как Tensorflow, так и Pytorch Support)
- Рэй Распределенный обучение
- Модель параллелизма: когда модель не подходит ни на одном графическом процессоре
- Другие решения:
3. Устранение неполадок [TBD]
4. Тестирование и развертывание
4.1. Тестирование и CI/CD
Программное обеспечение для производства машинного обучения требует более разнообразного набора тестовых наборов, чем традиционное программное обеспечение:
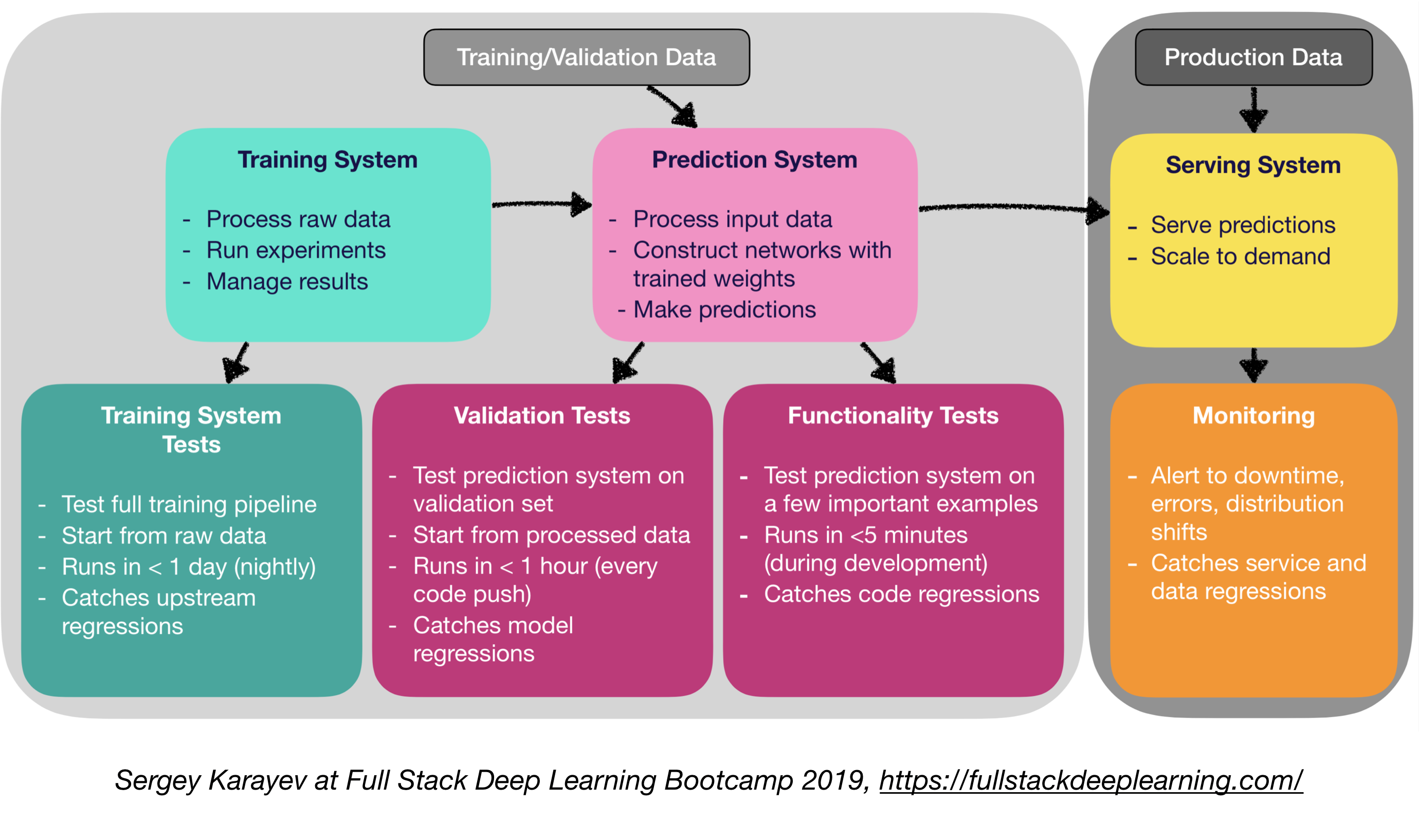
- Устройство и интеграционное тестирование:
- Типы тестов:
- Тесты обучения системы: тестирование тренировочного трубопровода
- Тесты валидации: система прогнозирования тестирования при наборе проверки
- Функциональные тесты: система прогнозирования тестирования на нескольких важных примерах
- Непрерывная интеграция: запуск тестов после каждого нового изменения кода, выдвинутого в репо.
- SaaS для непрерывной интеграции:
- Argo: Открытый исходный код Kubernetes Native Workflow Engine для оркестрации параллельных заданий (Incude Workflows, Events, CI и CD).
- Circleci: поддержка, включенная в форму, индивидуальные среды, гибкое распределение ресурсов, используемые Instacart, Lyft и StackShare.
- Трэвис CI
- Buildkite: Быстрые и стабильные сборки, агент с открытым исходным кодом работает практически на любой машине и архитектуре, свобода использования собственных инструментов и услуг
- Дженкинс: система сборки старой школы
4.2. Веб -развертывание
- Состоит из системы прогнозирования и системы обслуживания
- Система прогнозирования: входные данные процесса, делайте прогнозы
- Система обслуживания (веб -сервер):
- Служить прогнозированию с учетом масштаба
- Используйте API REST для обслуживания прогнозирования HTTP -запросов
- Вызывает систему прогнозирования ответить
- Варианты обслуживания:
- Развернуть в виртуальных машинах, масштабируя экземпляры
- Развернуть в качестве контейнеров, масштабировать оркестровку
- Контейнеры
- Контейнерная оркестровка:
- Kubernetes (самый популярный сейчас)
- Мезос
- Марафон
- Развернуть код как «без серверная функция»
- Развернуть с помощью модельного решения для обслуживания
- Модель служа:
- Специализированное веб -развертывание для моделей ML
- Запрос партий об выводе графического процессора
- Фреймворки:
- Tensorflow Aerding
- MXNET MODEL SERVER
- Клиппер (Беркли)
- SaaS Solutions
- Селдон: Подавайте и масштабируют модели, встроенные в любую структуру на Kubernetes
- Алгоритмия
- Принятие решений: процессор или графический процессор?
- Вывод процессора:
- Вывод процессора предпочтительнее, если он соответствует требованиям.
- Масштабируйте, добавив больше серверов или, став без сервера.
- Сделай по графическому графику:
- TF Forming или Clipper
- Адаптивное партия полезно
- (Бонус) Развертывание ноутбуков Юпитера:
- Kubeflow Fairing - это гибридный пакет развертывания, который позволяет вам развернуть коды ноутбуков Jupyter !
4.5 Сервисная сетка и маршрутизация трафика
- Переход от монолитных применений к распределенной архитектуре микросервиса может быть сложным.
- Сервисная сетка (состоящая из сети микросервисов) уменьшает сложность таких развертываний и облегчает нагрузку на команды разработчиков.
- ISTIO: Сервисная сетка для облегчения создания сети развернутых сервисов с балансировкой нагрузки, аутентификацией услуг на услугу, мониторингом, с небольшим изменением кода в коде обслуживания или отсутствием отсутствия.
4.4. Мониторинг:
- Цель мониторинга:
- Предупреждения о простоях, ошибках и сдвигах распределения
- Пойк услуги и регрессии данных
- Облачные поставщики решения приличные
- Kiali: консоль наблюдения для ISTIO с возможностями конфигурации сервисной сетки. Это отвечает на эти вопросы: как подключены микросервисы? Как они выступают?
Мы закончили?

4.5. Развертывание на встроенных и мобильных устройствах
- Основная задача: следование памяти и вычисления ограничений
- Решения:
- Квантование
- Уменьшенный размер модели
- Знания дистилляция
- Встроенные и мобильные фреймворки:
- Tensorflow Lite
- Pytorch Mobile
- Ядро ML
- ML Kit
- Фриц
- OpenVino
- Конверсия модели:
- Открыть обмен нейронной сетью (ONNX): формат с открытым исходным кодом для моделей глубокого обучения
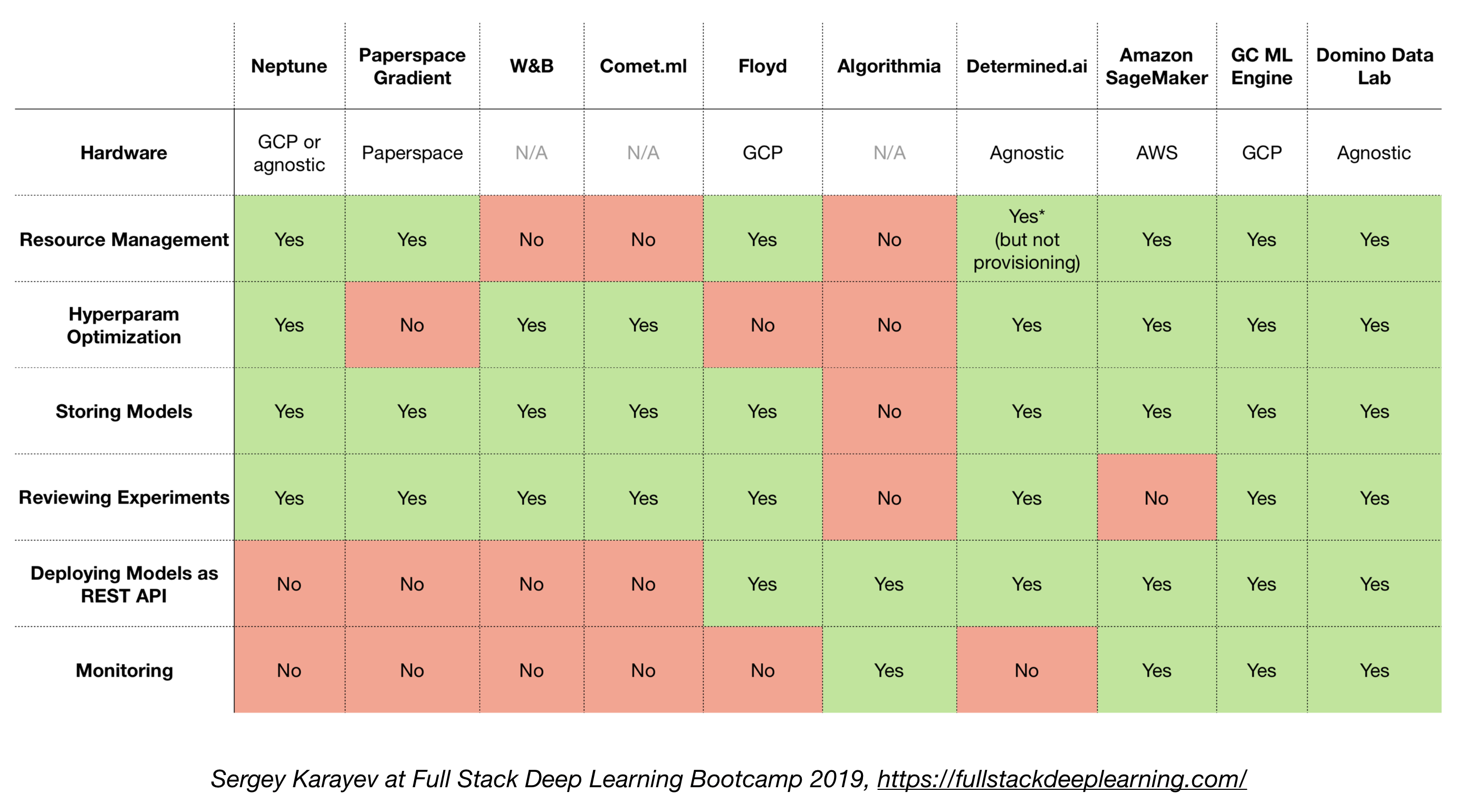
4.6 Все в одном решении
- TensorFlow расширен (TFX)
- Микеланджело (Uber)
- Google Cloud AI Платформа
- Amazon Sagemaker
- Нептун
- Флойд
- Paperspace
- Определенный AI
- Domino Data Lab
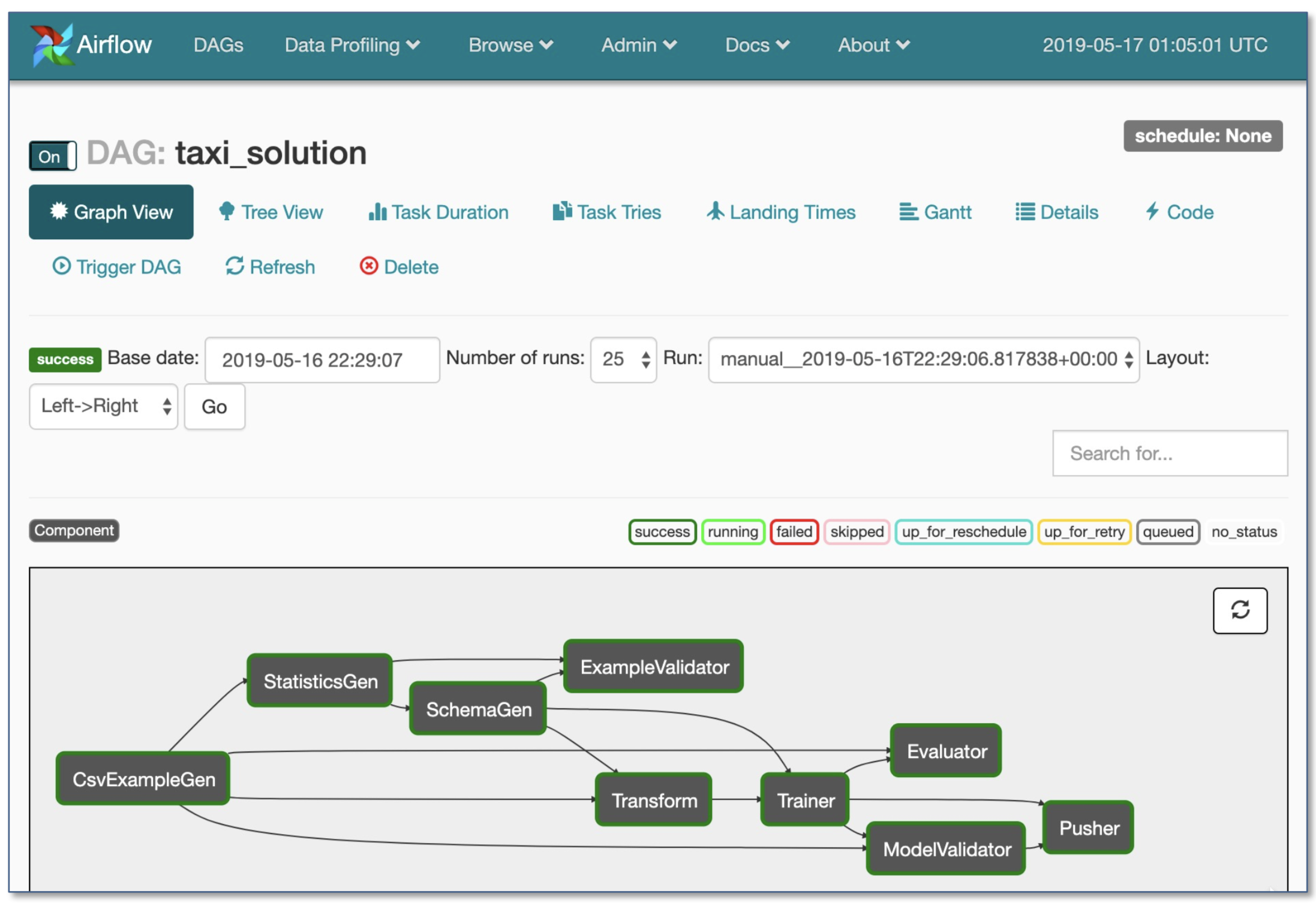
TensorFlow расширен (TFX)
[TBD]
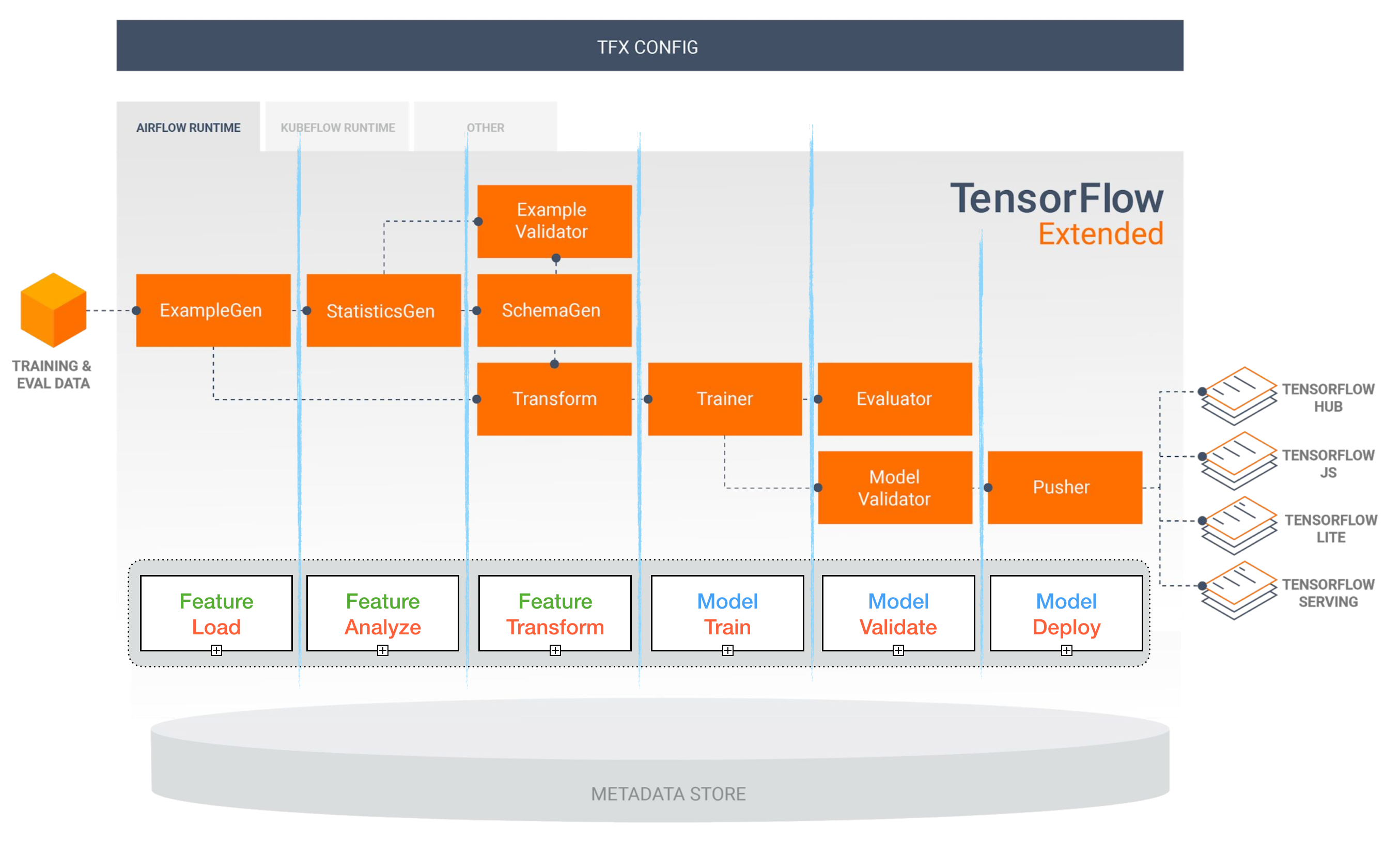
Проработка воздушного потока и кубика ML
[TBD]
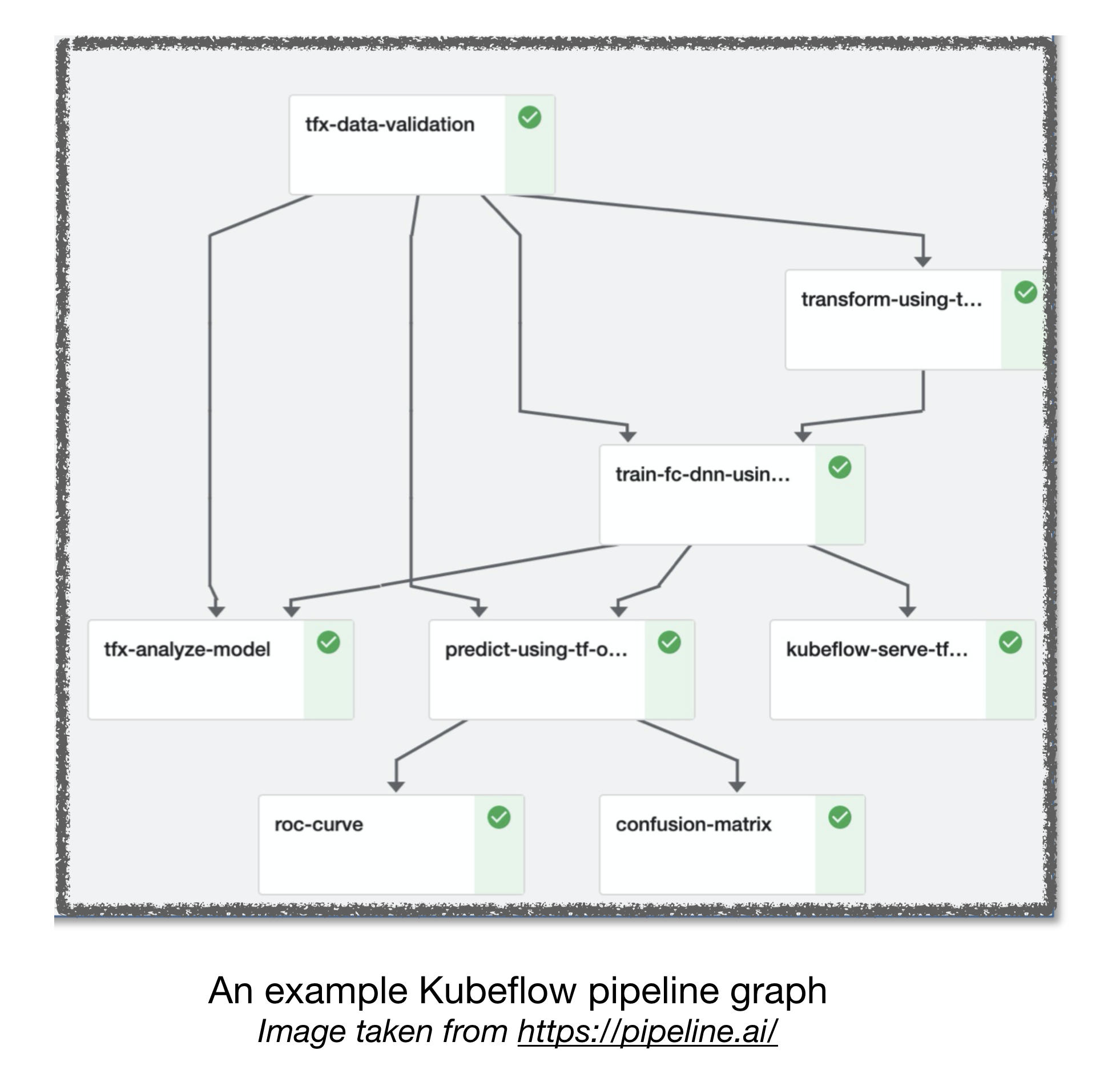
Другие полезные ссылки:
- Уроки, извлеченные из построения практических систем глубокого обучения
- Машинное обучение: кредитная карта технического долга с высокой процентной ставкой
Внося
Ссылки:
[1]: Полное стек глубокого обучения Bootcamp, ноябрь 2019.
[2]: Advanced Kubeflow Workshop от Pipeline.ai, 2019.
[3]: TFX: реальное машинное обучение в производстве


