Ein Leitfaden zum Produktionsniveau Deep Learning? ⛴️
? Übersetzung auf Chinesisch
? ️ Neu: Interviews für maschinelles Lernen
? ️ HINWEIS: Dieses Repo steht unter kontinuierlicher Entwicklung und alle Feedback und Beitrag sind sehr willkommen?
Die Bereitstellung von Deep -Learning -Modellen in der Produktion kann eine Herausforderung sein, da dies weit über Trainingsmodelle mit guter Leistung hinausgeht. Es müssen mehrere unterschiedliche Komponenten entworfen und entwickelt werden, um ein Produktionsniveau Deep Learning System (siehe unten) einzusetzen:
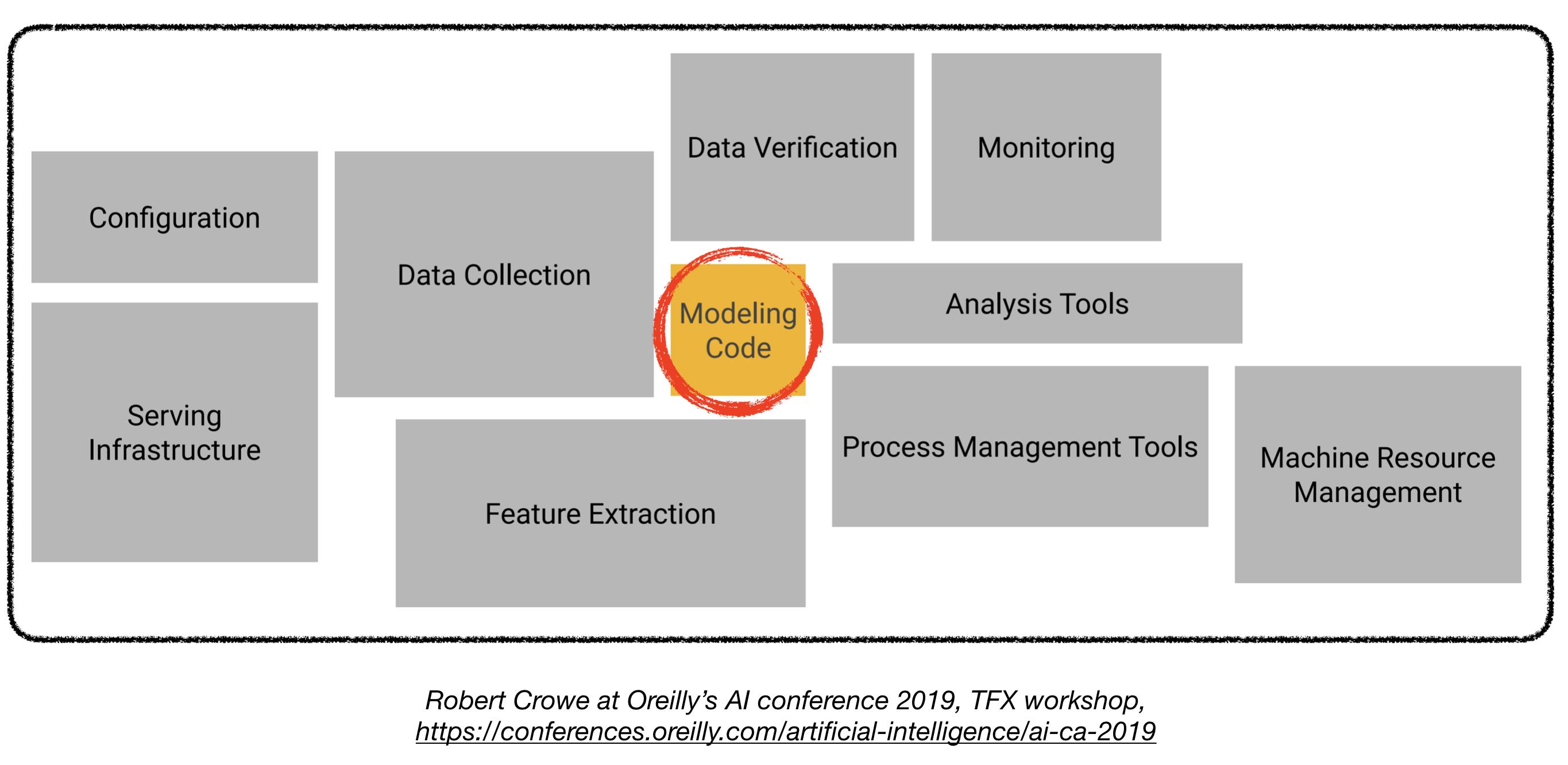
Dieses Repo zielt darauf ab, Deep-Learning-Systeme auf Bauproduktionsniveau auf Gebäudebehandlungsniveau zu erstellen, die in realen Anwendungen eingesetzt werden.
Das hier vorgestellte Material wird aus dem Full Stack Deep Learning Bootcamp (von Pieter Abbeel an der UC Berkeley, Josh Tobin in Openai und Sergey Karayev bei Turnitin), TFX -Workshop von Robert Crowe und Pipeline.ais Advanced Kubeflow Meetup von Chris Fegly entlehnt.
Projekte für maschinelles Lernen
Spaß ? Fakt: 85% der KI -Projekte scheitern . 1 Potenzielle Gründe umfassen:
- Technisch nicht realisierbar oder schlecht abgebildet
- Machen Sie niemals den Sprung in die Produktion
- Unklare Erfolgskriterien (Metriken)
- Schlechtes Teammanagement
1. ML Projekte Lebenszyklus
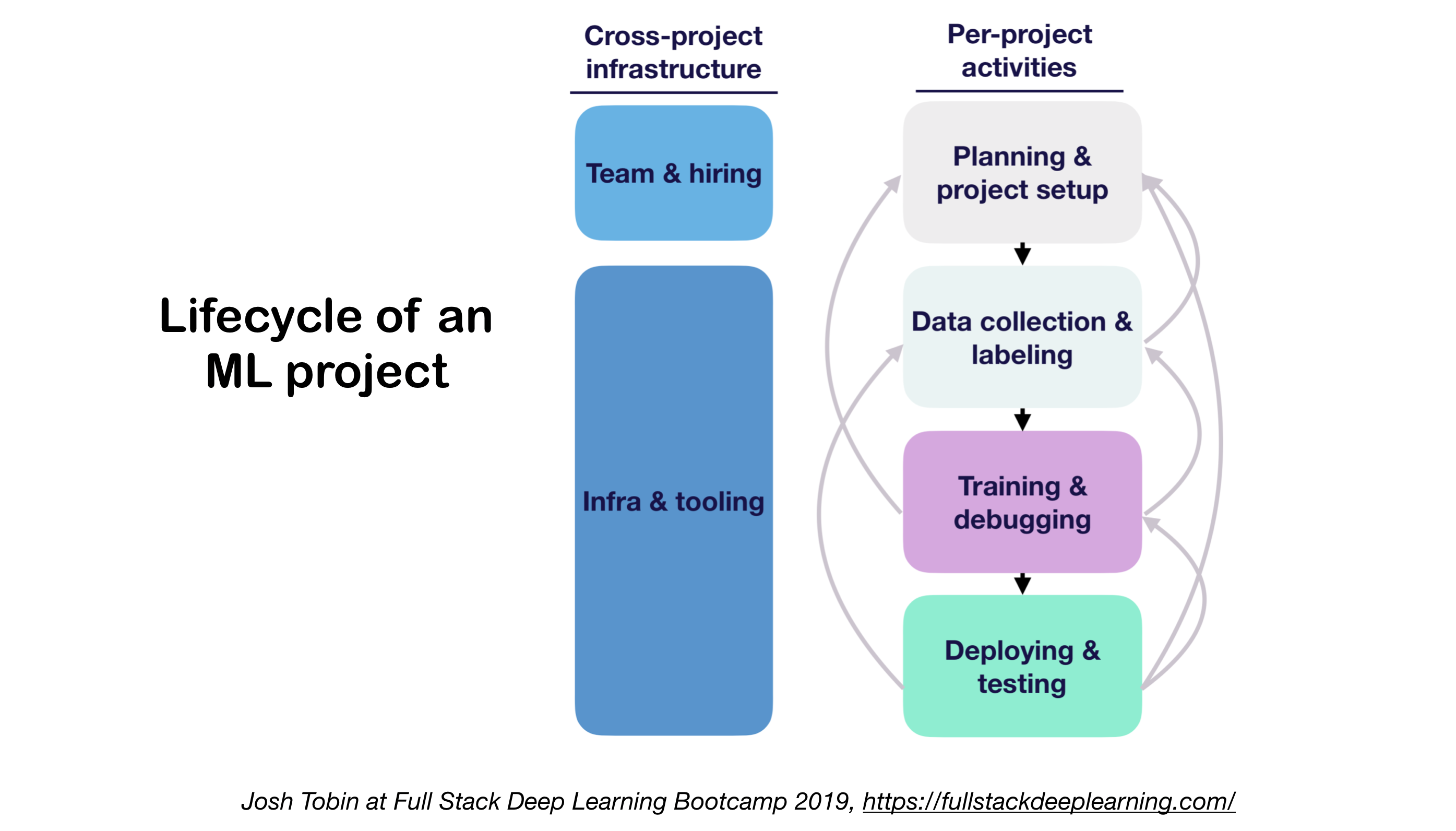
- Bedeutung des Verständnisses der Kunst der Kunst in Ihrer Domäne:
- Hilft zu verstehen, was möglich ist
- Hilft zu wissen, was ich als nächstes versuchen soll
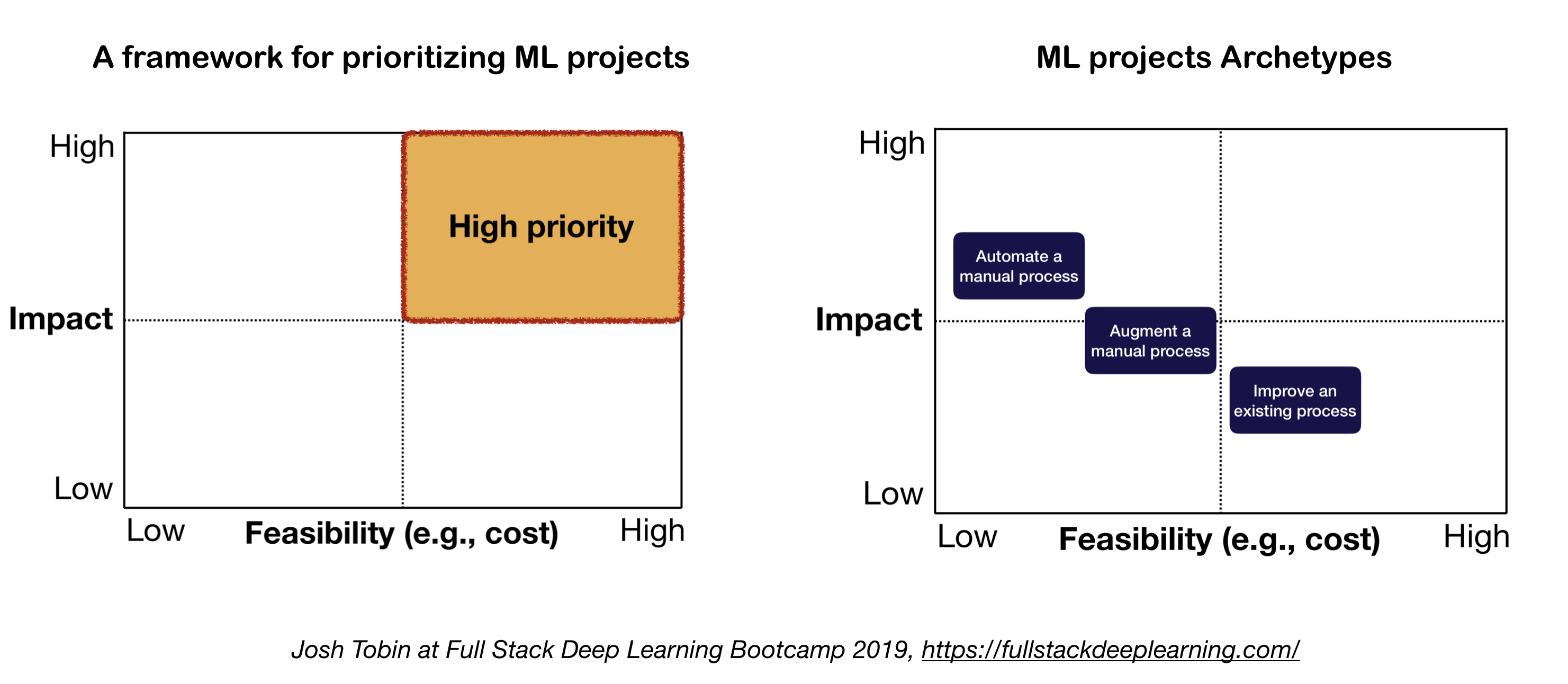
2. Mentales Modell für ML Project
Die beiden wichtigen Faktoren, die bei der Definition und Priorisierung von ML -Projekten zu berücksichtigen sind:
- Hohe Wirkung:
- Komplexe Teile Ihrer Pipeline
- Wo "billige Vorhersage" wertvoll ist
- Wenn die Automatisierung des komplizierten manuellen Prozesss wertvoll ist
- Niedrige Kosten:
- Die Kosten werden durch:
- Datenverfügbarkeit
- Leistungsanforderungen: Die Kosten skalieren in der Genauigkeitsanforderung in der Regel superlinear
- Problemschwierigkeit:
- Einige der harten Probleme sind: unbeaufsichtigtes Lernen, Verstärkungslernen und bestimmte Kategorien des überwachten Lernens
Vollstack -Pipeline
Die folgende Abbildung stellt einen Überblick über verschiedene Komponenten in einem Deep -Lern -System der Produktionsstufe dar:
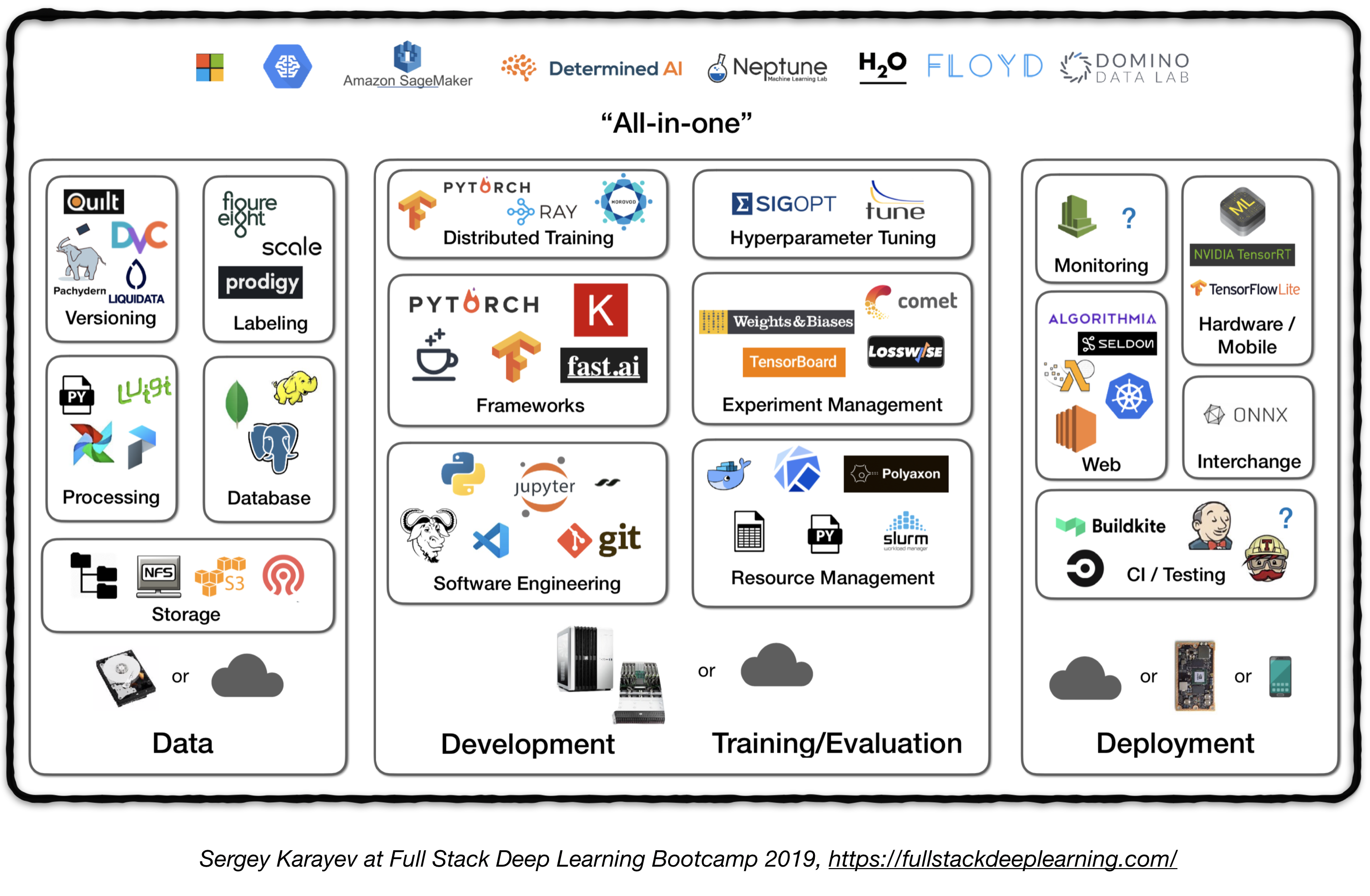
Im Folgenden werden wir jedes Modul durchlaufen und Toolsets und Frameworks sowie Best Practices von Praktikern empfehlen, die zu jeder Komponente passen.
1. Datenmanagement
1.1 Datenquellen
- Überwiegend Deep Learning erfordert viele beschriftete Daten
- Die Kennzeichnung eigener Daten ist teuer!
- Hier sind einige Ressourcen für Daten:
- Open Source -Daten (gut mit Beginn, aber kein Vorteil)
- Datenvergrößerung (ein Muss für Computer Vision, eine Option für NLP)
- Synthetische Daten (fast immer lohnt es sich, mit zu beginnen, insbesondere in NLP)
1.2 Datenkennzeichnung
- Benötigt: separate Software -Stack (Etikettierungsplattformen), temporäre Arbeitskräfte und QC
- Arbeitsquellen für die Kennzeichnung:
- Crowdsourcing (mechanischer Turk): billig und skalierbar, weniger zuverlässig, braucht QC
- Einstellung eigener Annotatoren: Weniger QC benötigt, teuer, langsam skaliert
- Datenkennzeichnungsdienstunternehmen:
- Etikettierungsplattformen:
- Diffgram: Trainingsdatensoftware (Computer Vision)
- Wunderkind: Ein Annotationsinstrument, das durch aktives Lernen (von Entwicklern von Spacy), Text und Bild betrieben wird
- Hive: AI als Serviceplattform für Computer Vision
- Supervisely: Ganze Computer Vision Platform
- Labelbox: Computer Vision
- Skalieren Sie die AI -Datenplattform (Computer Vision & NLP)
1.3. Datenspeicherung
- Datenspeicheroptionen:
- Objektspeicher : Binärdaten (Bilder, Tondateien, komprimierte Texte) speichern.
- Amazon S3
- CEPH -Objektgeschäft
- Datenbank : Speichern Sie Metadaten (Dateipfade, Beschriftungen, Benutzeraktivitäten usw.).
- Postgres ist für die meisten Anwendungen die richtige Wahl, mit der erstklassigen SQL und der großartigen Unterstützung für unstrukturierte JSON.
- Data Lake : zu aggregierende Merkmale, die nicht aus der Datenbank erhältlich sind (z. B. Protokolle)
- Feature Store : Store-, Zugriffs- und Freigabe-Funktionen für maschinelles Lernen (Feature-Extraktion kann rechnerisch teuer und nahezu unmöglich sein, weshalb die Wiederverwendung von Funktionen durch verschiedene Modelle und Teams ein Schlüssel zu hochleistungsfähigen ML-Teams ist).
- Fest (Google Cloud, Open Source)
- Michelangelo Palette (Uber)
- Vorschlag: Kopieren Sie zur Trainingszeit Daten in ein lokales oder vernetzter Dateisystem (NFS). 1
1.4. Datenversionierung
- Es ist ein "Muss" für bereitgestellte ML -Modelle:
Bereitete ML -Modelle sind Teilcode, Teildaten . 1 Keine Datenversionierung bedeutet keine Modellversionierung. - Datenversionsplattformen:
- DVC: Open Source -Versionskontrollsystem für ML -Projekte
- Pachyderm: Versionskontrolle für Daten
- Dolt: Eine SQL-Datenbank mit Git-ähnlicher Versionskontrolle für Daten und Schema
1.5. Datenverarbeitung
- Trainingsdaten für Produktionsmodelle können aus verschiedenen Quellen stammen, einschließlich gespeicherter Daten in DB und Objektspeichern , Protokollverarbeitung und Ausgaben anderer Klassifikatoren .
- Es gibt Abhängigkeiten zwischen den Aufgaben, die jeder nach Abschluss seiner Abhängigkeiten abgeschafft werden muss. Das Training mit neuen Protokolldaten erfordert beispielsweise einen Vorverarbeitungsschritt vor dem Training.
- Makefiles sind nicht skalierbar. "Workflow Manager" wird in dieser Hinsicht ziemlich wichtig.
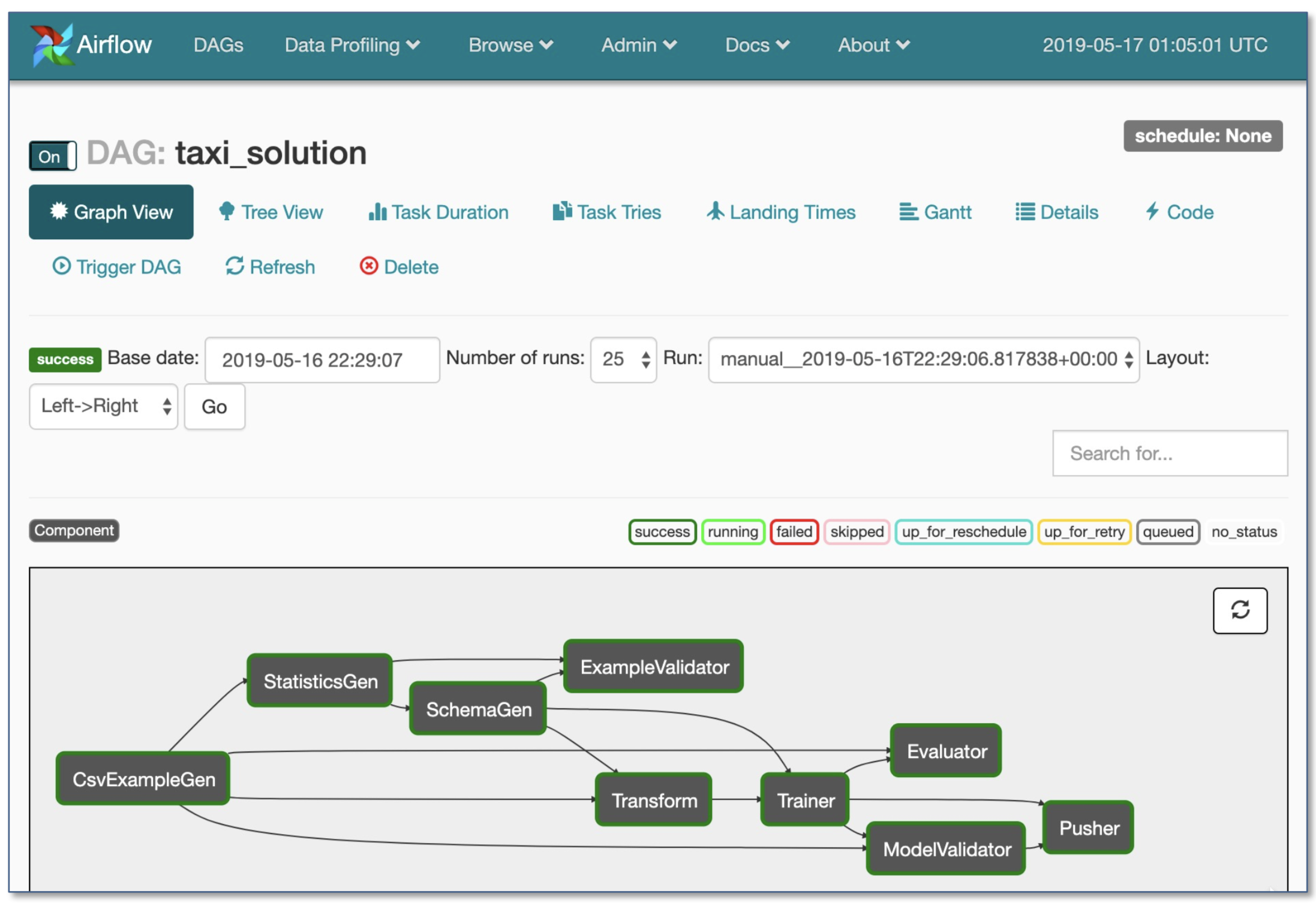
- Workflow Orchestration:
- Luigi von Spotify
- Luftstrom von Airbnb: Dynamisch, erweiterbar, elegant und skalierbar (am weitesten verbraucht)
- DAG -Workflow
- Robuste bedingte Ausführung: Wiederholung im Falle eines Fehlers
- Pusher unterstützt Docker -Bilder mit Tensorflow -Servieren
- Ganzer Workflow in einer einzelnen .py -Datei
2. Entwicklung, Schulung und Bewertung
2.1. Software -Engineering
- Gewinnersprache: Python
- Redakteure:
- Vim
- EMACs
- VS-Code (vom Autor empfohlen): Integrierte Git-Staging und Diff, Lintcode, Projekte remote über SSH eröffnen
- Notizbücher: Großartig als Ausgangspunkt der Projekte, schwer zu skalieren (lustige Tatsache: Netflixs Notebook-gesteuerte Architektur ist eine Ausnahme, die ausschließlich auf Nteract-Suiten basiert).
- Nteract: Eine React-basierte UI der nächsten Generation für Jupyter-Notizbücher
- Papermill: Ist eine Nteract -Bibliothek für die Parametrisierung , Ausführung und Analyse von Jupyter -Notizbüchern.
- Pendler: Ein weiteres Nteract-Projekt, das eine schreibgeschützte Anzeige von Notizbüchern liefert (z. B. aus S3-Eimer).
- Streamlit: Interactive Data Science Tool mit Applets
- Empfehlungen berechnen 1 :
- Für Einzelpersonen oder Startups :
- Entwicklung: ein 4-facher Turing-Architektur-PC
- Training/Bewertung: Verwenden Sie denselben 4x GPU -PC. Kaufen Sie bei vielen Experimenten entweder gemeinsame Server oder verwenden Sie Cloud -Instanzen.
- Für große Unternehmen:
- Entwicklung: Kaufen Sie einen 4-fach-Turing-Architecture-PC pro ML-Wissenschaftler oder lassen Sie sie V100-Instanzen verwenden
- Schulung/Bewertung: Verwenden Sie Cloud -Instanzen mit ordnungsgemäßer Bereitstellung und Handhabung von Fehlern
- Wolkenanbieter:
- GCP: Option zum Verbinden von GPUs an eine beliebige Instanz + hat TPUs
- AWS:
2.2. Ressourcenmanagement
- Zuordnen kostenloser Ressourcen für Programme
- Ressourcenverwaltungsoptionen:
- Old School Cluster Job Scheduler (z. B. Slurm Workload Manager)
- Docker + Kubernetes
- Kubeflow
- Polyaxon (bezahlte Merkmale)
2.3. DL Frameworks
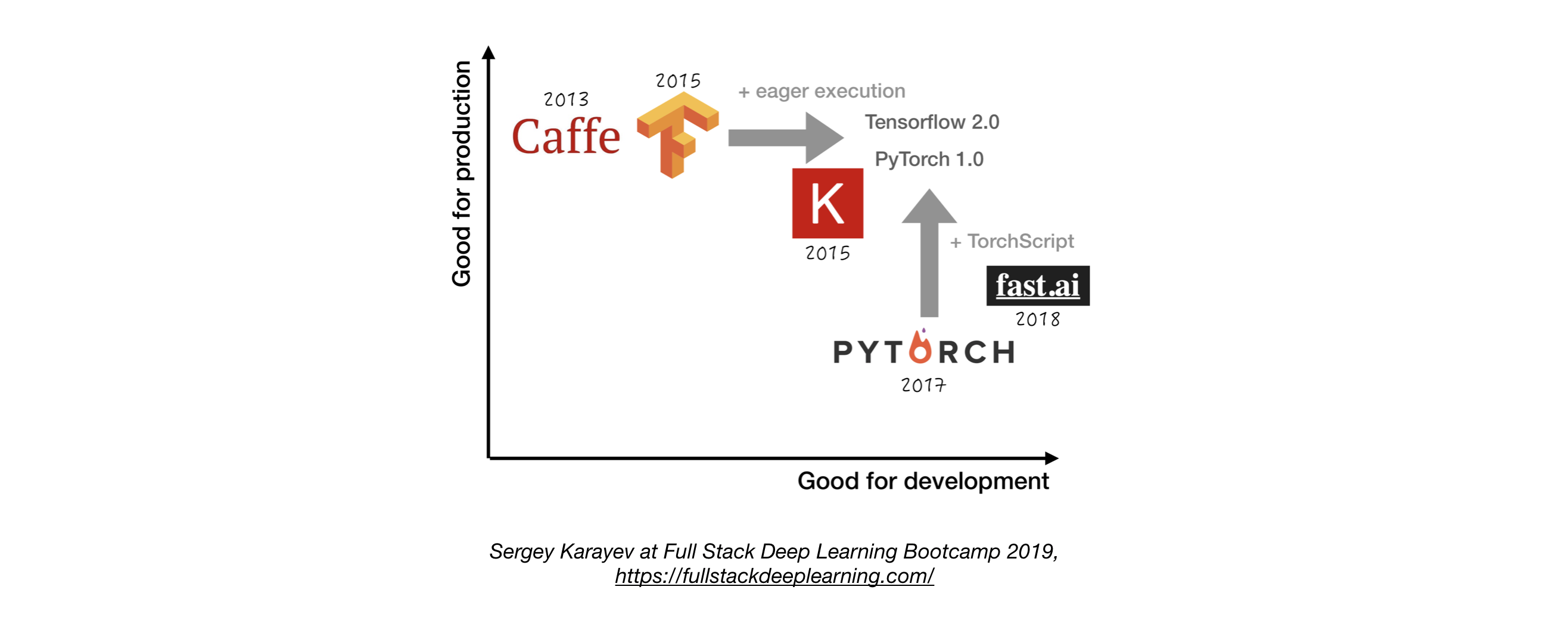
- Verwenden Sie TensorFlow/Keras oder Pytorch, es sei denn, Sie haben einen guten Grund, nicht zu haben. 1
- Die folgende Abbildung zeigt einen Vergleich zwischen verschiedenen Frameworks darüber, wie sie für "Entwicklung" und "Produktion" stehen.
2.4. Versuchsmanagement
- Entwicklungs-, Schulungs- und Bewertungsstrategie:
- Immer einfach anfangen
- Trainieren Sie ein kleines Modell auf einer kleinen Charge. Nur wenn es funktioniert, skalieren Sie zu größeren Daten und Modellen und Hyperparameter -Tuning!
- Experiment -Management -Tools:
- Tensorboard
- Bietet die Visualisierung und Werkzeuge, die für ML -Experimente benötigt wird
- Verlust (Überwachung für ML)
- Comet: Ermöglicht Sie mit Code, Experimenten und Ergebnissen bei ML -Projekten verfolgen
- Gewichte und Vorurteile: Notieren und visualisieren Sie jedes Detail Ihrer Forschung mit einfacher Zusammenarbeit
- MLFlow Tracking: Für Protokollierungsparameter, Codeversionen, Metriken und Ausgabedateien sowie die Visualisierung der Ergebnisse.
- Automatische Experimentverfolgung mit einer Codezeile in Python
- Seite an Seitenvergleich von Experimenten
- Hyperparameterabstimmung
- Unterstützt kubernetes basierende Jobs
2.5. Hyperparameterabstimmung
Ansätze:
- Gittersuche
- Zufällige Suche
- Bayes'sche Optimierung
- Hyperband und asynchron aufeinanderfolgender Halbalgorithmus (ASHA)
- Bevölkerungsbasiertes Training
Plattformen:
- Raytune: Ray Tune ist eine Python -Bibliothek für Hyperparameter -Tuning in jeder Skala (mit Schwerpunkt auf tiefem Lernen und tiefem Verstärkungslernen). Unterstützt jedes maschinelle Lernen, einschließlich Pytorch, Xgboost, MXNET und Keras.
- Katib: Das native System von Kubernete für Hyperparameter -Tuning und neuronale Architektursuche, inspiriert von [Google Vizier] (https://static.googleUsercontent.com/media/ Research.google.com/ja//pubs/archive/ BCB15507F4B52991A0783013DF4222240E942381.pdf) und unterstützt mehrere ML/DL -Frameworks (z. B. Tensorflow, Mxnet und Pytorch).
- Hyperas: Ein einfacher Wrapper um Hyperopt für Keras mit einer einfachen Vorlagennotation, um die Hyper-Parameter-Bereiche zu definieren, um sie zu stimmen.
- Sigopt: Eine skalierbare, unternehmerische Optimierungsplattform
- Sweeps von [Gewichten & Vorurteilen] (https://www.wandb.com/): Die Parameter werden von einem Entwickler nicht explizit angegeben. Stattdessen werden sie von einem Modell für maschinelles Lernen angenähert und gelernt.
- Keras -Tuner: Ein Hyperparameter -Tuner für Keras, insbesondere für TF.keras mit Tensorflow 2.0.
2.6. Verteiltes Training
- Datenparallelität: Verwenden Sie sie, wenn die Iterationszeit zu lang ist (sowohl Tensorflow als auch Pytorch -Unterstützung)
- Modellparallelität: Wenn das Modell nicht auf eine einzelne GPU passt
- Andere Lösungen:
3.. Fehlerbehebung [TBD]
4. Testen und Einsatz
4.1. Tests und CI/CD
Produktionssoftware für maschinelle Lernen erfordert eine vielfältigere Reihe von Testsuiten als herkömmliche Software:
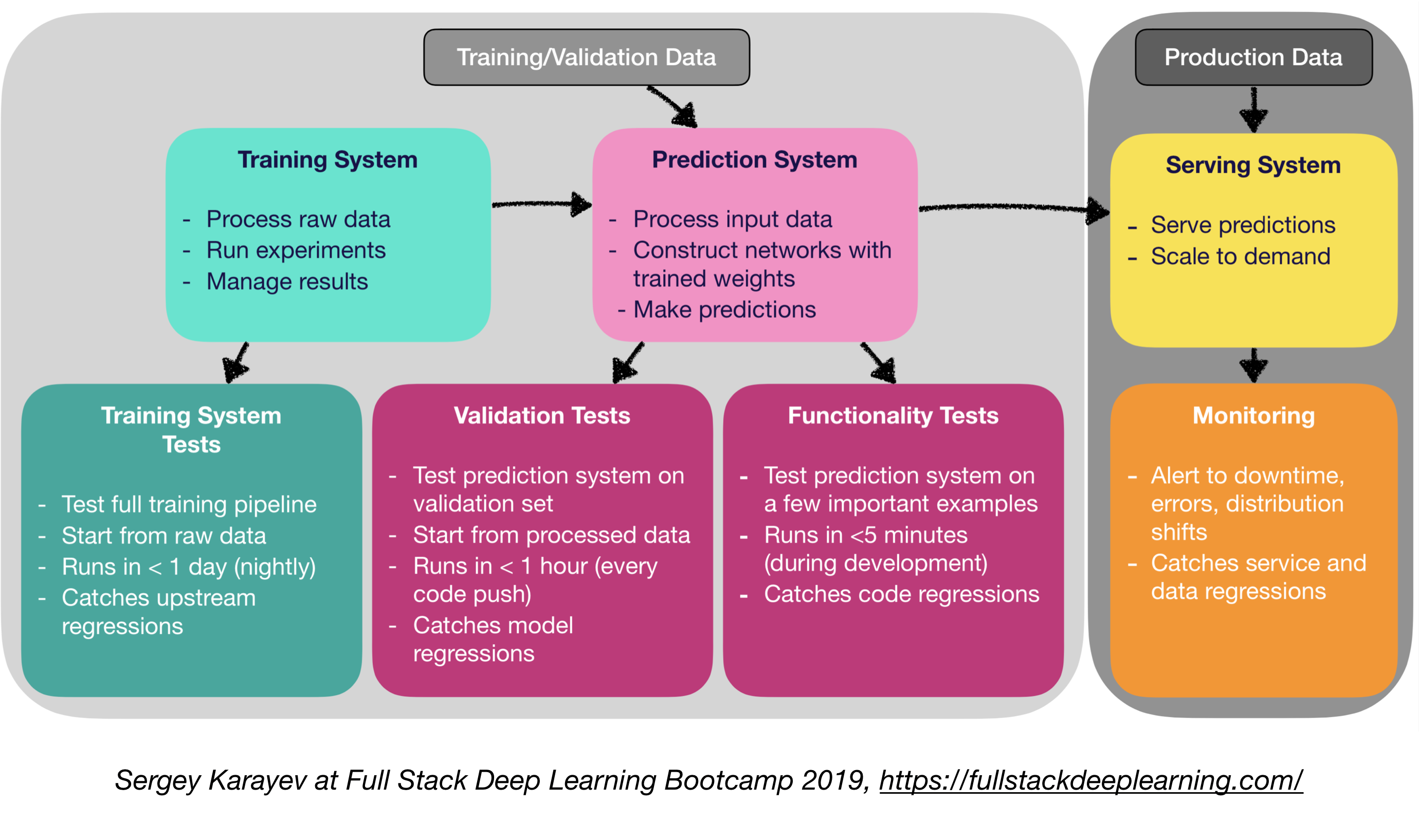
- Einheit- und Integrationstests:
- Arten von Tests:
- Trainingssystemtests: Testen der Trainingspipeline
- Validierungstests: Testen des Vorhersagesystems am Validierungssatz
- Funktionalitätstests: Testen des Vorhersagesystems an wenigen wichtigen Beispielen
- Kontinuierliche Integration: Durchführen von Tests nach jeder neuen Codeänderung in das Repo gedrückt
- SaaS für kontinuierliche Integration:
- ARGO: Open Source Kubernetes native Workflow -Engine zum Orchestrieren paralleler Jobs (ansteigt Workflows, Events, CI und CD).
- Circleci: Support für Sprache, benutzerdefinierte Umgebungen, flexible Ressourcenzuweisung, verwendet von Instacart, Lyft und Stackshare.
- Travis CI
- Buildkite: Schnelle und stabile Builds, Open Source Agent läuft auf fast jeder Maschine und jeder Architektur, Freiheit, Ihre eigenen Tools und Dienste zu nutzen
- Jenkins: Old School Build System
4.2. Webbereitstellung
- Besteht aus einem Vorhersagesystem und einem Serviersystem
- Vorhersagesystem: Prozesseingabedaten, Vorhersagen machen
- Serviersystem (Webserver):
- Vorhersage mit dem Maßstab bedienen
- Verwenden Sie die REST -API, um Vorhersage -HTTP -Anforderungen zu erfüllen
- Ruft das Vorhersagesystem an, um zu reagieren
- Servieroptionen:
- Bereitstellen in VMs, skalieren Sie durch Hinzufügen von Instanzen
- Als Container einsetzen, skalieren Sie über Orchestrierung
- Behälter
- Containerorchestrierung:
- Kubernetes (jetzt am beliebtesten)
- Mesos
- Marathon
- Code als "serverlose Funktion" bereitstellen
- Bereitstellen über eine Modell Servinglösung
- Modelldienste:
- Spezialisierte Webbereitstellung für ML -Modelle
- Chargenanfrage nach GPU -Inferenz
- Frameworks:
- Tensorflow Serving
- MXNET -Modellserver
- Clipper (Berkeley)
- SaaS -Lösungen
- Seldon: Servieren und Skalieren von Modellen, die in jedem Framework auf Kubernetes eingebaut sind
- Algorithmie
- Entscheidungsfindung: CPU oder GPU?
- CPU -Inferenz:
- CPU -Inferenz ist vorzuziehen, wenn sie den Anforderungen erfüllt.
- Skalieren Sie, indem Sie mehr Server hinzufügen oder serverlos gehen.
- GPU -Inferenz:
- TF Serving oder Clipper
- Adaptive Chargen ist nützlich
- (Bonus) Bereitstellen von Jupyter -Notizbüchern:
- Kubeflow -Verkleidung ist ein Hybrid -Bereitstellungspaket, mit dem Sie Ihre Jupyter -Notebook -Codes bereitstellen können!
4.5 Service Mesh und Verkehrsrouting
- Der Übergang von monolithischen Anwendungen in Richtung einer verteilten Microservice -Architektur könnte eine Herausforderung sein.
- Ein Service -Mesh (bestehend aus einem Netzwerk von Microservices) verringert die Komplexität solcher Bereitstellungen und erleichtert die Belastung der Entwicklungsteams.
- ISTIO: Ein Service-Mesh zur Erleichterung eines Netzwerks bereitgestellter Dienste mit Lastausgleich, Service-to-Service-Authentifizierung, Überwachung, mit wenigen oder keinen Codeänderungen im Servicecode.
4.4. Überwachung:
- Zweck der Überwachung:
- Warnungen für Ausfallzeiten, Fehler und Verteilungsverschiebungen
- Fangdienst- und Datenregressionen fangen
- Cloud -Anbieterlösungen sind anständig
- Kiali: Eine Beobachtbarkeitskonsole für ISTIO mit Service -Netzkonfigurationsfunktionen. Es beantwortet folgende Fragen: Wie sind die Microservices verbunden? Wie leisten sie?
Sind wir fertig?

4.5. Bereitstellung auf eingebetteten und mobilen Geräten
- Hauptherausforderung: Memory Footprint und Berechnenbeschränkungen
- Lösungen:
- Quantisierung
- Reduzierte Modellgröße
- Wissensdestillation
- Eingebettete und mobile Frameworks:
- Tensorflow Lite
- Pytorch Mobile
- Kernml
- ML Kit
- Fritz
- OpenVino
- Modellumwandlung:
- Open Neural Network Exchange (ONNX): Open-Source-Format für Deep-Learning-Modelle
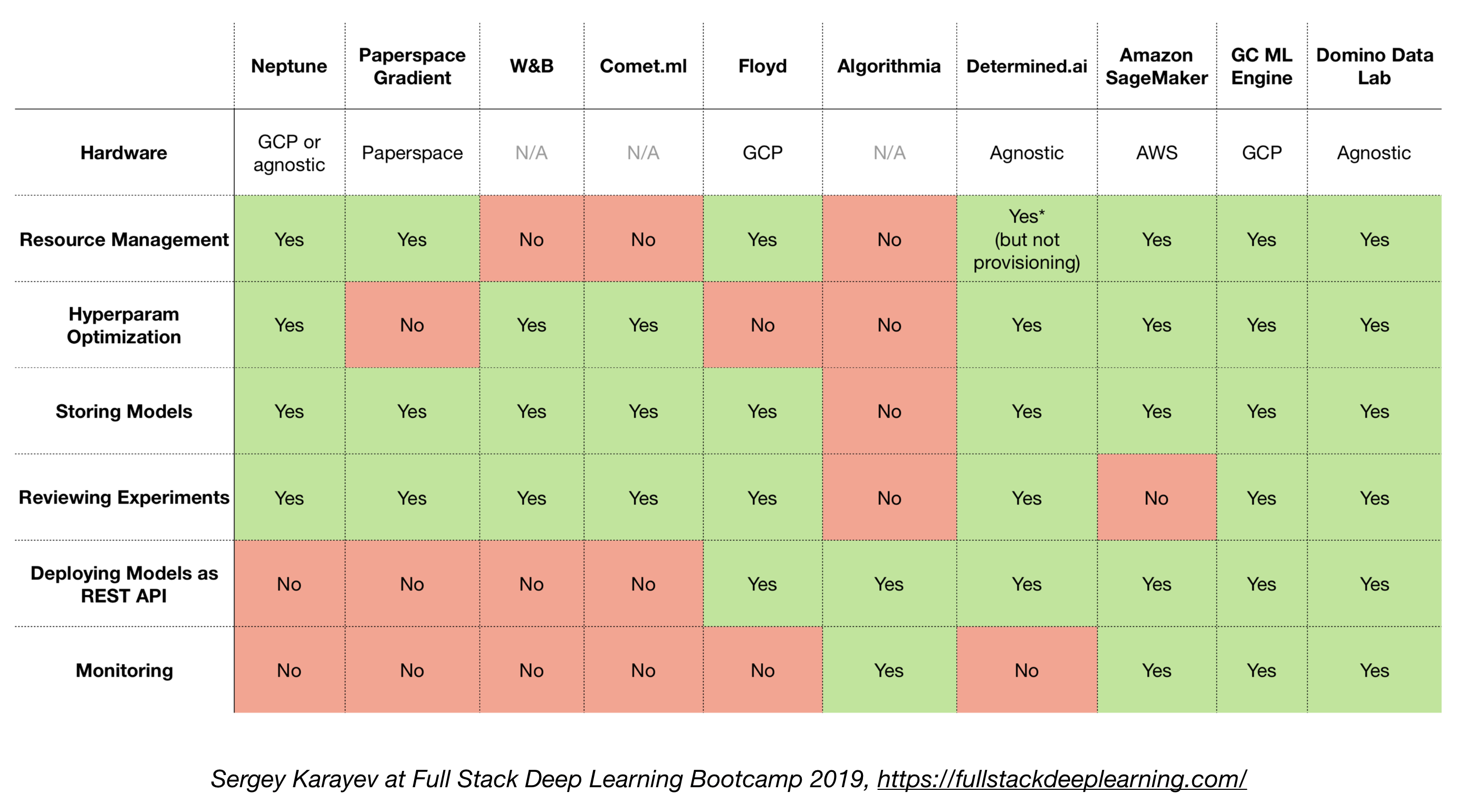
4.6. All-in-One-Lösungen
- TensorFlow erweitert (TFX)
- Michelangelo (Uber)
- Google Cloud AI -Plattform
- Amazon Sagemaker
- Neptun
- Floyd
- Papierspace
- Bestimmte AI
- Domino Data Lab
TensorFlow erweitert (TFX)
[TBD]
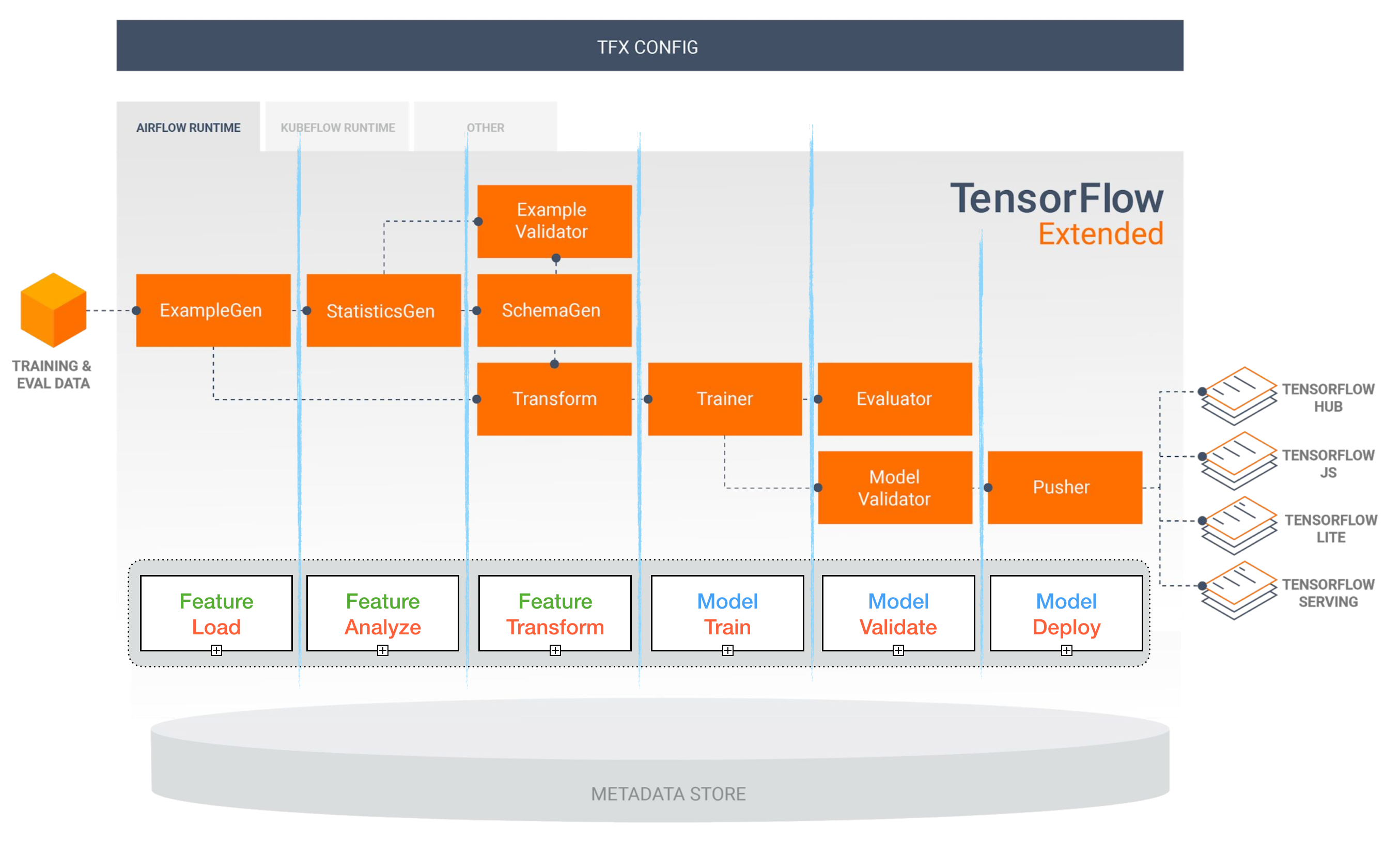
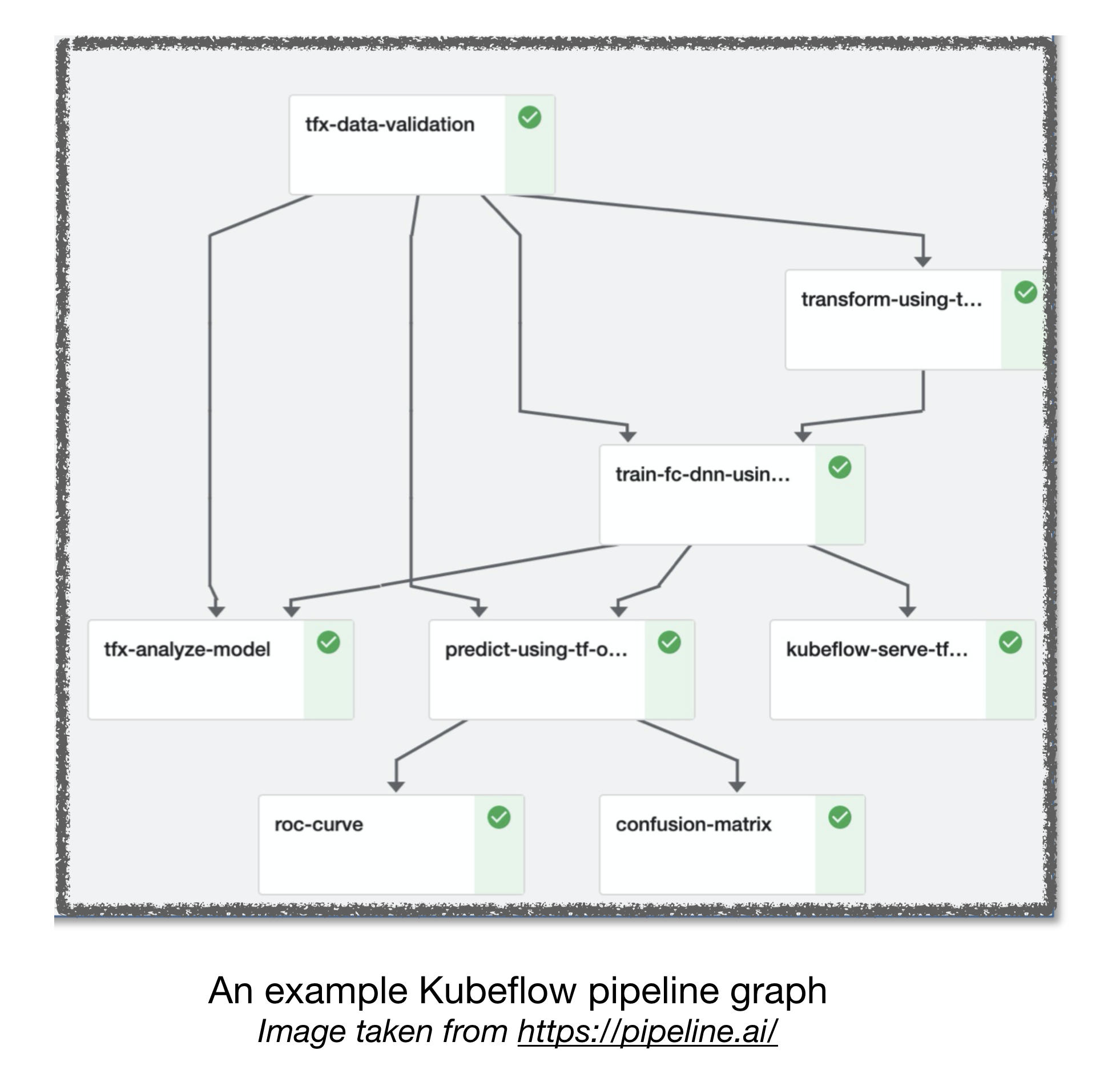
Luftstrom- und Kubeflow -ML -Pipelines
[TBD]
Andere nützliche Links:
- Lektionen, die aus dem Aufbau praktischer Deep -Lernsysteme gezogen wurden
- Maschinelles Lernen: Die hohe Zinsenkreditkarte der technischen Schulden
Beitragen
Referenzen:
[1]: Full Stack Deep Learning Bootcamp, Nov 2019.
[2]: Advanced Kubeflow Workshop von Pipeline.ai, 2019.
[3]: TFX: reales maschinelles Lernen in der Produktion in der realen Welt


