Un guide pour l'apprentissage en profondeur au niveau de la production? ⛴️
?? Traduction en chinois
? ️ Nouveau: entretiens d'apprentissage automatique
? ️ Remarque: ce repo est en cours de développement continu, et toutes les commentaires et contributions sont les bienvenus?
Le déploiement de modèles d'apprentissage en profondeur en production peut être difficile, car il est bien au-delà des modèles de formation avec de bonnes performances. Plusieurs composants distincts doivent être conçus et développés afin de déployer un système d'apprentissage en profondeur de niveau de production (vu ci-dessous):
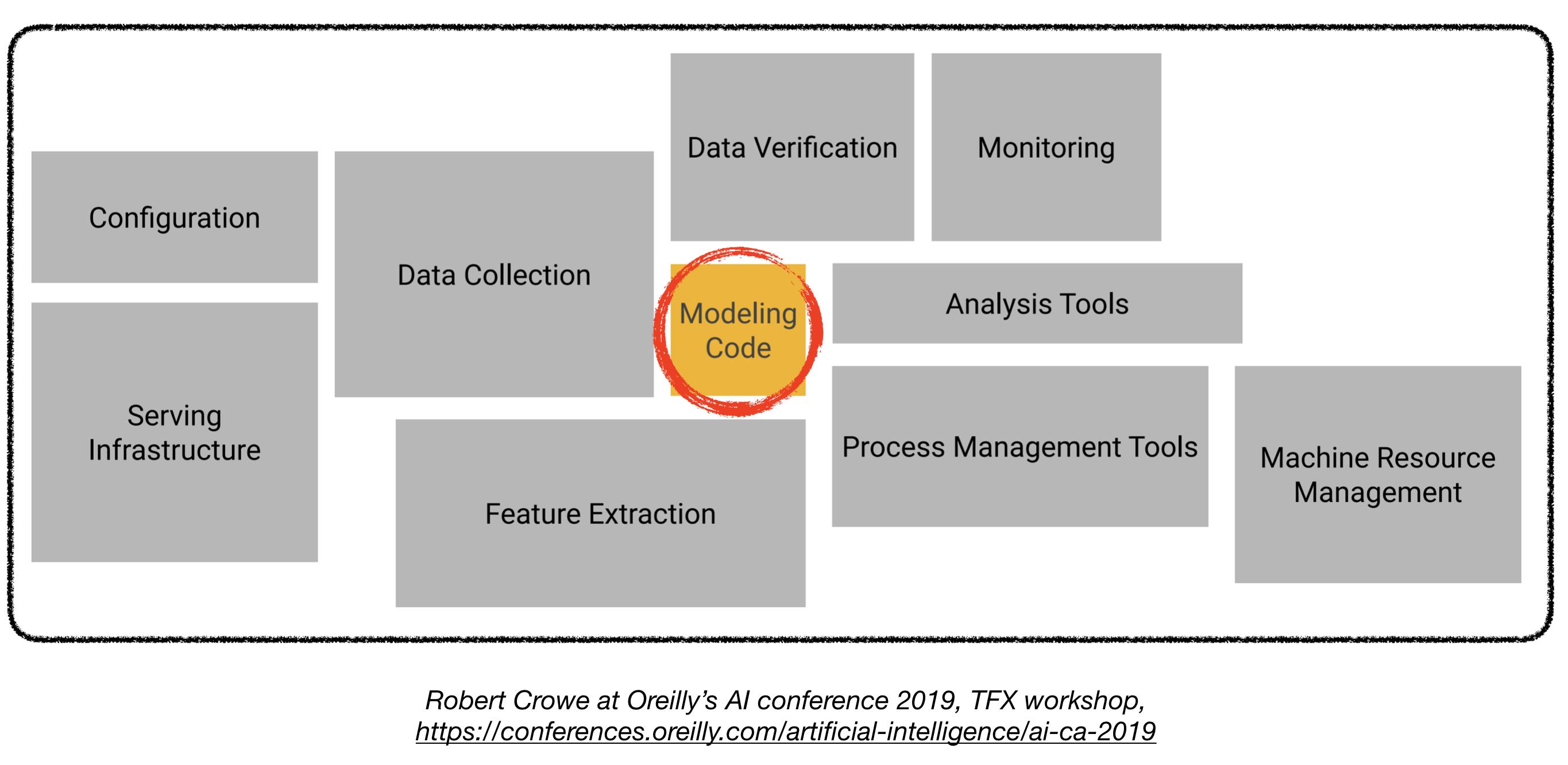
Ce dépôt vise à être une directive d'ingénierie pour construire des systèmes d'apprentissage en profondeur au niveau de la production qui seront déployés dans des applications réelles.
Le matériel présenté ici est emprunté à Full Stack Deep Learning Bootcamp (par Pieter Abbeel à UC Berkeley, Josh Tobin à Openai, et Sergey Karayev à Turnitin), TFX Atelier de Robert Crowe et Pipeline.AI'S Advanced Kubeflow Meetup de Chris Fregly.
Projets d'apprentissage automatique
Amusant ? FAIT: 85% des projets d'IA échouent . 1 raisons potentielles comprennent:
- Techniquement irréalisable ou mal portée
- Ne faites jamais le saut vers la production
- Critères de réussite peu clairs (métriques)
- Mauvaise gestion de l'équipe
1. ML Projets de cycle de vie
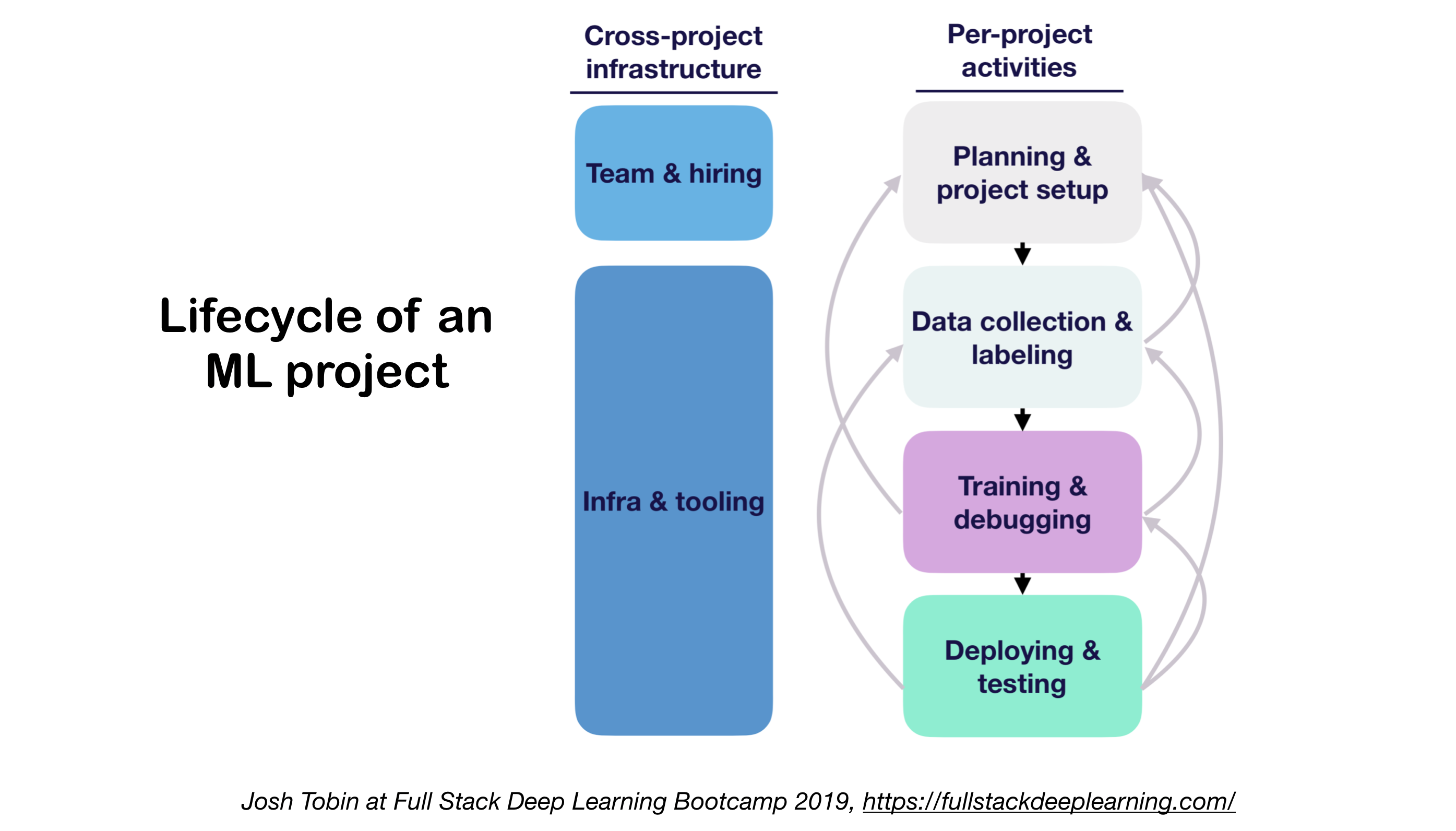
- Importance de comprendre l'état de l'art dans votre domaine:
- Aide à comprendre ce qui est possible
- Aide à savoir quoi essayer ensuite
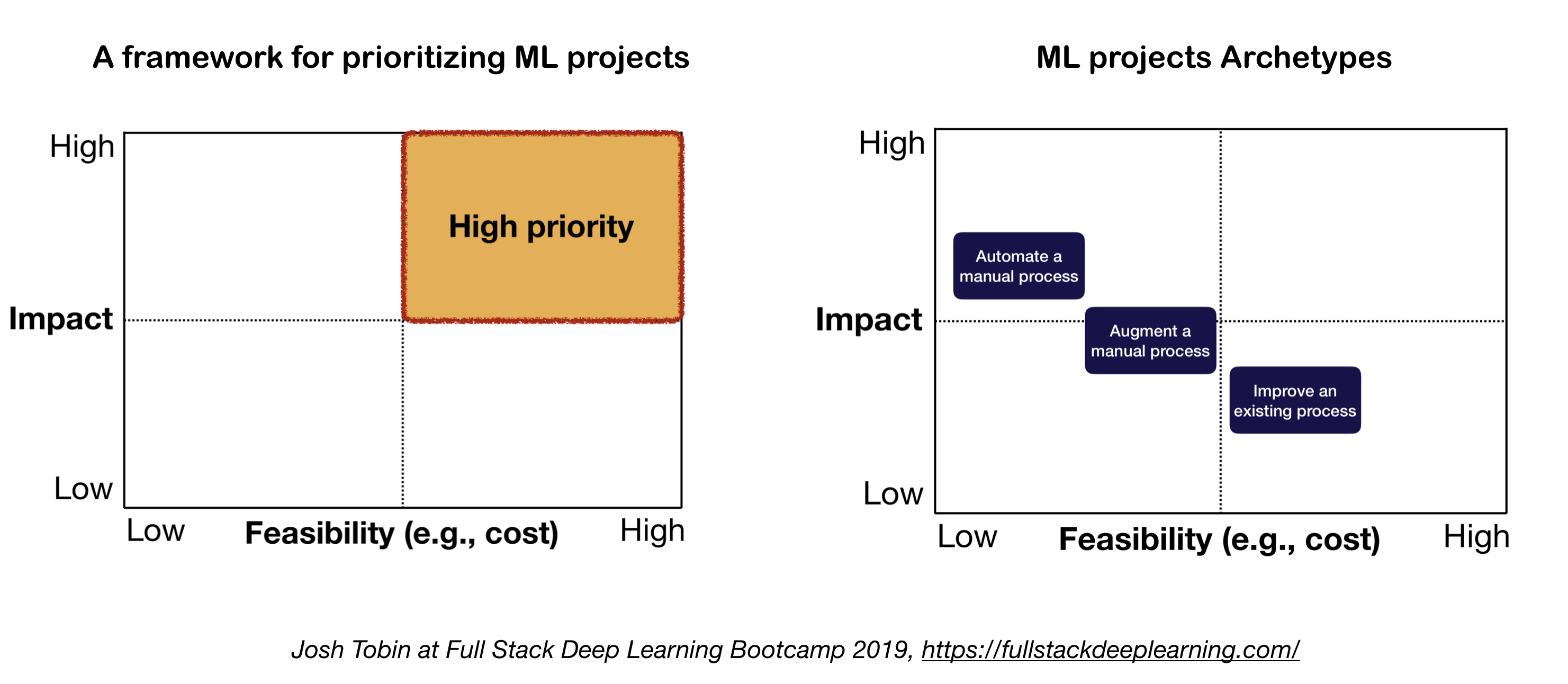
2. Modèle mental pour le projet ML
Les deux facteurs importants à considérer lors de la définition et de la hiérarchisation des projets ML:
- Impact élevé:
- Parties complexes de votre pipeline
- Où la "prédiction bon marché" est précieuse
- Où l'automatisation du processus manuel compliqué est précieux
- Faible coût:
- Le coût est entraîné par:
- Disponibilité des données
- Exigences de performance: les coûts ont tendance à évoluer super linéaire dans l'exigence de précision
- Difficulté du problème:
- Certains des problèmes difficiles incluent: l'apprentissage non surveillé, l'apprentissage du renforcement et certaines catégories d'apprentissage supervisé
Pipeline complète
La figure suivante représente un aperçu de haut niveau de différents composants dans un système d'apprentissage en profondeur de niveau:
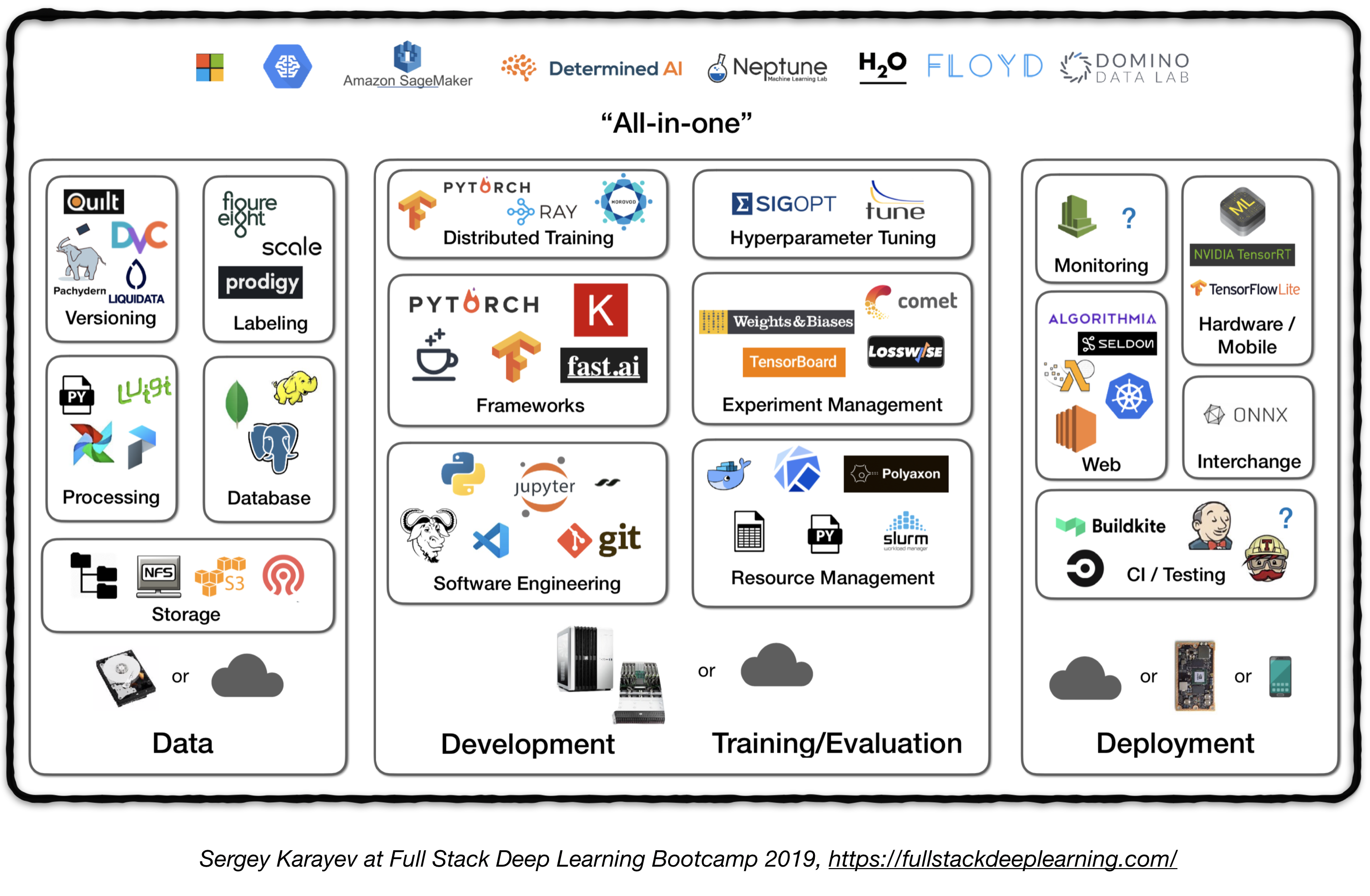
Dans ce qui suit, nous passerons par chaque module et recommanderons des outils et des cadres ainsi que les meilleures pratiques de praticiens qui correspondent à chaque composant.
1. Gestion des données
1.1 Sources de données
- L'apprentissage en profondeur supervisé nécessite beaucoup de données étiquetées
- L'étiquetage de propres données coûte cher!
- Voici quelques ressources pour les données:
- Données open source (c'est bon pour commencer, mais pas un avantage)
- Augmentation des données (un must pour la vision par ordinateur, une option pour la PNL)
- Données synthétiques (qui vaut presque toujours la peine de commencer, en particulier dans NLP)
1.2 Étiquetage des données
- Exige: une pile logicielle séparée (plates-formes d'étiquetage), un travail temporaire et QC
- Sources de travail pour l'étiquetage:
- Crowdsourcing (mécanique Turk): bon marché et évolutif, moins fiable, a besoin de qc
- Embaucher ses propres annotateurs: moins de QC nécessaire, coûteux, lent à l'échelle
- Sociétés de services d'étiquetage de données:
- Plates-formes d'étiquetage:
- Diffgram: Logiciel de données de formation (vision par ordinateur)
- Prodige: un outil d'annotation propulsé par l'apprentissage actif (par les développeurs de Spacy), le texte et l'image
- Hive: AI comme plate-forme de service pour la vision par ordinateur
- Supervisement: plate-forme de vision informatique entière
- Labelbox: vision par ordinateur
- Plate-forme de données AI à l'échelle (Vision Computer & NLP)
1.3. Stockage de données
- Options de stockage de données:
- Store d'objets : stocker des données binaires (images, fichiers sonores, textes compressés)
- Amazon S3
- Magasin d'objets Ceph
- Base de données : stocker les métadonnées (chemins de fichier, étiquettes, activité utilisateur, etc.).
- Postgres est le bon choix pour la plupart des applications, avec le meilleur SQL de classe et un excellent support pour JSON non structuré.
- Data Lake : Pour agréger les fonctionnalités qui ne peuvent pas être obtenues à partir de la base de données (par exemple les journaux)
- Store de fonction : les fonctionnalités de stockage, d'accès et de partage d'apprentissage automatique (l'extraction des fonctionnalités peut être coûteuse en calcul et presque impossible à évoluer, la réutilisation des fonctionnalités par différents modèles et équipes est une clé des équipes ML à haute performance).
- Fête (Google Cloud, open source)
- Palette Michel-Ange (Uber)
- Suggestion: au moment de la formation, copiez des données dans un système de fichiers local ou en réseau (NFS). 1
1.4. Version de données
- C'est un "must" pour les modèles ML déployés:
Les modèles ML déployés sont le code partie, les données des pièces . 1 Aucune version de données ne signifie pas de version de modèle. - Plates-formes de version de données:
- DVC: système de contrôle de version open source pour les projets ML
- Pachyderm: Contrôle de version pour les données
- Dolt: une base de données SQL avec contrôle de version de type Git pour les données et le schéma
1.5. Informatique
- Les données de formation pour les modèles de production peuvent provenir de différentes sources, y compris des données stockées dans les magasins DB et d'objets , le traitement des journaux et les sorties d'autres classificateurs .
- Il y a des dépendances entre les tâches, chacune doit être lancée une fois ses dépendances terminées. Par exemple, la formation sur les nouvelles données de journal nécessite une étape de prétraitement avant la formation.
- Les makefiles ne sont pas évolutifs. Les "Workflow Manager" sont assez essentiels à cet égard.
- Orchestration du flux de travail:
- Luigi par Spotify
- Flux d'air par Airbnb: dynamique, extensible, élégant et évolutif (le plus largement utilisé)
- Flux de travail DAG
- Exécution conditionnelle robuste: réessayer en cas de défaillance
- Pusher prend en charge les images Docker avec le service TensorFlow
- Flux de travail entier dans un seul fichier .py
2. Développement, formation et évaluation
2.1. Génie logiciel
- Langue des gagnants: Python
- Éditeurs:
- Vim
- Emacs
- VS Code (recommandé par l'auteur): Stage Git intégré et diff, code de peluche, projets ouverts à distance via SSH
- Notes de carnet: super en tant que point de départ des projets, difficile à échelle (fait amusant: l'architecture axée sur les ordinateurs portables de Netflix est une exception, qui est entièrement basée sur des suites Nteract).
- NTERACT: Une interface utilisateur basée sur la nouvelle génération pour les cahiers Jupyter
- PAPERMILL: est une bibliothèque NTERACT conçue pour paramétrer , exécuter et analyser des cahiers de jupyter.
- Commuter: un autre projet Nteract qui fournit un affichage en lecture seule des cahiers (par exemple des seaux S3).
- Rationalisation: outil interactif de science des données avec des applets
- Calculez les recommandations 1 :
- Pour les individus ou les startups :
- Développement: un PC 4x Turing-Architecture
- Formation / évaluation: utilisez le même PC 4x GPU. Lorsque vous exécutez de nombreuses expériences, achetez des serveurs partagés ou utilisez des instances de cloud.
- Pour les grandes entreprises:
- Développement: Achetez un PC 4x Turing-Architecture par ML Scientist ou laissez-les utiliser des instances V100
- Formation / évaluation: utilisez des instances de cloud avec un approvisionnement et une manipulation appropriés des échecs
- Fournisseurs de cloud:
- GCP: option pour connecter les GPU à n'importe quelle instance + a des TPU
- AWS:
2.2. Gestion des ressources
- Allouer des ressources gratuites aux programmes
- Options de gestion des ressources:
- Old School Cluster Job Scheduler (par exemple Slurm Workload Manager)
- Docker + kubernetes
- Kubeflow
- Polyaxon (fonctionnalités payantes)
2.3. Frameworks DL
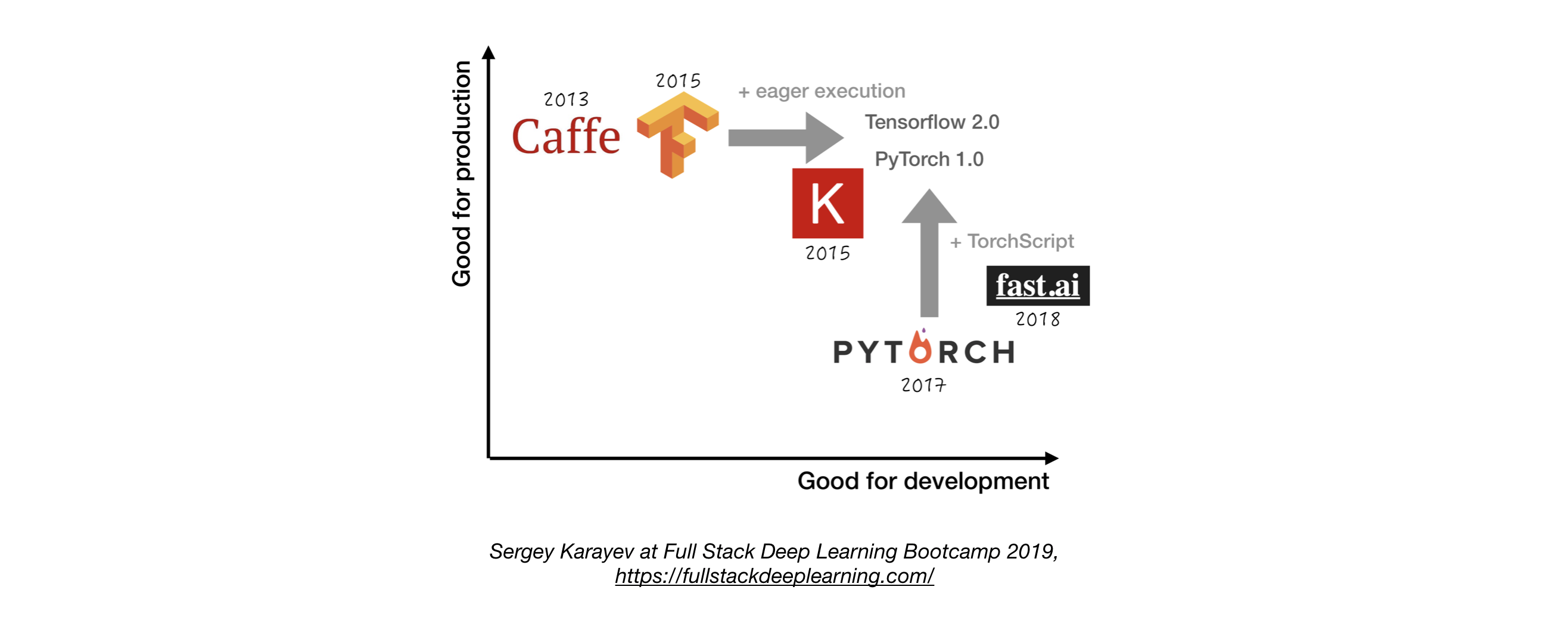
- Sauf n'ayant pas une bonne raison de ne pas le faire, utilisez TensorFlow / Keras ou Pytorch. 1
- La figure suivante montre une comparaison entre les différents cadres sur la façon dont ils représentent le "développement" et la "production" .
2.4. Gestion des expériences
- Élaboration, formation et stratégie d'évaluation:
- Commencez toujours simple
- Formez un petit modèle sur un petit lot. Seulement si cela fonctionne, évoluer vers des données et des modèles plus importants et un réglage hyperparamètre!
- Outils de gestion des expériences:
- Tensorboard
- Fournit la visualisation et l'outillage nécessaires à l'expérimentation ML
- Losswise (surveillance de ML)
- COMET: vous permet de suivre le code, les expériences et les résultats sur les projets ML
- Poids et biais: enregistrez et visualisez chaque détail de vos recherches avec une collaboration facile
- Suivi MLFlow: pour les paramètres de journalisation, les versions de code, les métriques et les fichiers de sortie ainsi que la visualisation des résultats.
- Suivi automatique de l'expérience avec une ligne de code dans Python
- Comparaison côte à côte des expériences
- Réglage des paramètres hyper
- Prend en charge les travaux basés sur Kubernetes
2.5. Réglage hyperparamètre
Approches:
- Recherche de grille
- Recherche aléatoire
- Optimisation bayésienne
- Hyperband et algorithme de moitié successif asynchrone (ASHA)
- Formation en population
Plateformes:
- Raytune: Ray Tune est une bibliothèque Python pour le réglage hyperparamètre à n'importe quelle échelle (en mettant l'accent sur l'apprentissage en profondeur et l'apprentissage en renforcement profond). Prend en charge tout cadre d'apprentissage automatique, y compris Pytorch, XGBoost, MXNET et KERAS.
- Katib: Système natif de Kubernete pour le réglage de l'hyperparamètre et la recherche d'architecture neurale, inspiré de [Google Vizir] (https://static.googleusercontent.com/media/ recherche.google.com/ja//pubs/archive/ BCB15507F4B52991A0783013DF4222240E942381.pdf) et prend en charge plusieurs frameworks ML / DL (par exemple TensorFlow, MXNET et PYTORCH).
- Hyperas: un simple emballage autour de Hyperopt pour Keras, avec une notation de modèle simple pour définir des gammes d'hyper-paramètres à régler.
- SIGOPT: une plate-forme d'optimisation évolutive de qualité d'entreprise
- Balaye de [poids et biais] (https://www.wandb.com/): les paramètres ne sont pas explicitement spécifiés par un développeur. Au lieu de cela, ils sont approximés et appris par un modèle d'apprentissage automatique.
- KERAS TUNER: Un tuner hyperparamètre pour Keras, spécifiquement pour TF.KARAS avec TensorFlow 2.0.
2.6. Formation distribuée
- Parallélisme des données: utilisez-le lorsque le temps d'itération est trop long (support TensorFlow et Pytorch)
- Ray Trainted Distributed Training
- Parallélisme du modèle: lorsque le modèle ne correspond pas à un seul GPU
- Autres solutions:
3. Dépannage [TBD]
4. Test et déploiement
4.1. Tests et CI / CD
Le logiciel de production d'apprentissage automatique nécessite un ensemble plus diversifié de suites de test que les logiciels traditionnels:
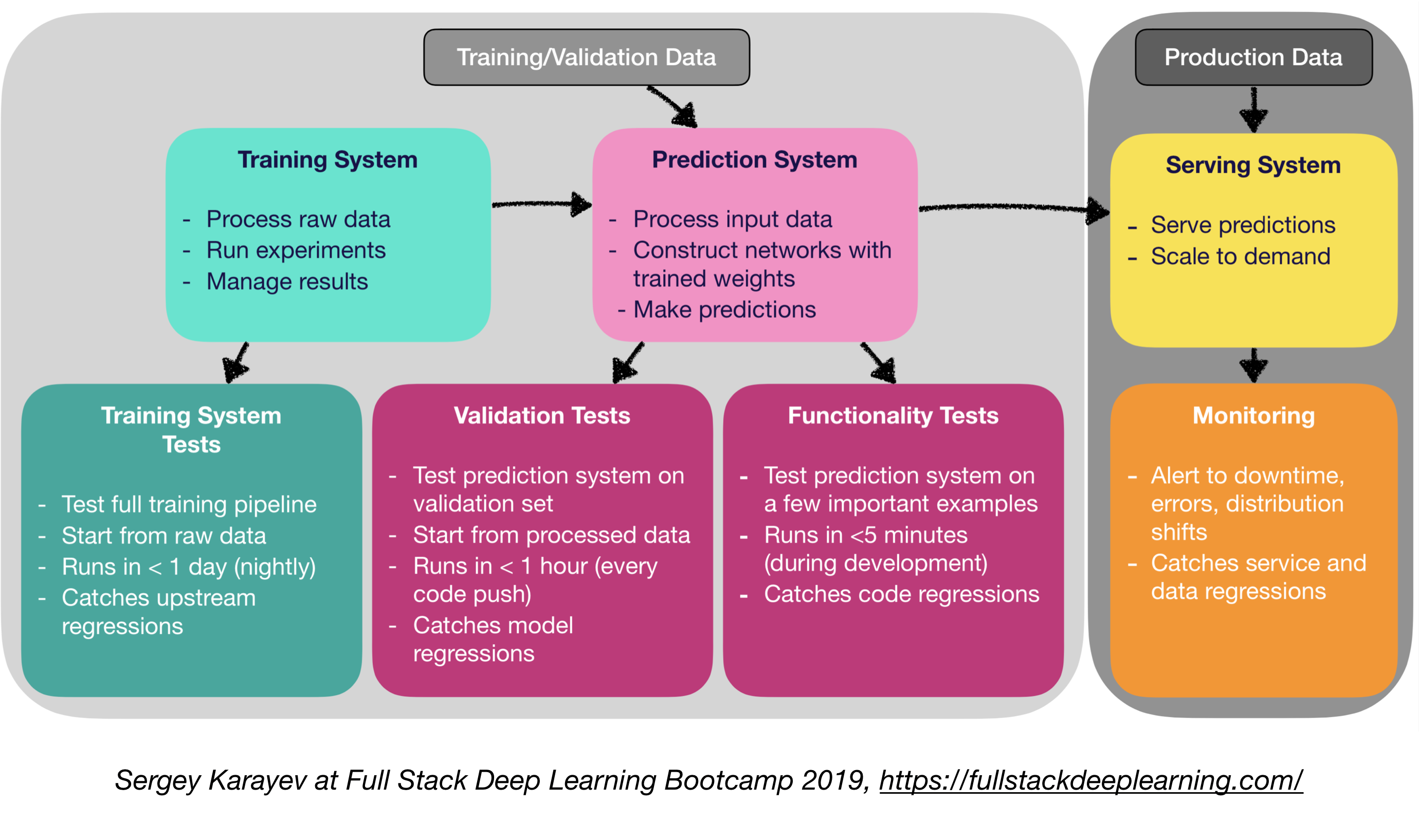
- Test d'unité et d'intégration:
- Types de tests:
- Tests du système de formation: Tester Pipeline Training Pipeline
- Tests de validation: Testing Système de prédiction sur l'ensemble de validation
- Tests de la fonctionnalité: test du système de prédiction sur quelques exemples importants
- Intégration continue: exécution des tests après chaque nouveau changement de code poussé vers le repo
- SaaS pour l'intégration continue:
- ARGO: moteur de workflow natif de Kubernetes open source pour orchestrer les travaux parallèles (incombe les workflows, les événements, CI et CD).
- Circleci: Support inclusif du langage, environnements personnalisés, allocation de ressources flexibles, utilisée par Instacart, Lyft et StackShare.
- Travis CI
- BuildKite: construction rapide et stable, l'agent open source fonctionne sur presque n'importe quelle machine et architecture, liberté d'utiliser vos propres outils et services
- Jenkins: Système de construction à l'ancienne
4.2. Déploiement Web
- Consiste en un système de prédiction et un système de service
- Système de prédiction: traite les données d'entrée, faire des prédictions
- Système de service (serveur Web):
- Servir la prédiction avec l'échelle à l'esprit
- Utilisez l'API REST pour servir les demandes HTTP de prédiction
- Appelle le système de prédiction pour répondre
- Options de service:
- Déployer dans les machines virtuelles, à l'échelle en ajoutant des instances
- Déployer sous forme de conteneurs, évoluer par orchestration
- Conteneurs
- Orchestration des conteneurs:
- Kubernetes (le plus populaire maintenant)
- Mésos
- Marathon
- Déployer le code comme une "fonction sans serveur"
- Déployer via une solution de service modèle
- Modèle de service:
- Déploiement Web spécialisé pour les modèles ML
- Demande de lots d'inférence GPU
- Frameworks:
- Tensorflow Service
- Serveur de modèle MXNET
- Clipper (Berkeley)
- Solutions SaaS
- Seldon: des modèles de service et d'échelle construits dans n'importe quel cadre sur Kubernetes
- Algorithmie
- Prise de décision: CPU ou GPU?
- Inférence du processeur:
- L'inférence du processeur est préférable si elle répond aux exigences.
- Échelle en ajoutant plus de serveurs ou sans serveur.
- Inférence GPU:
- TF Service ou Clipper
- Le lot adaptatif est utile
- (Bonus) Déploiement de cahiers de jupyter:
- Kubeflow Fairring est un package de déploiement hybride qui vous permet de déployer vos codes de carnet de jupyter !
4.5 Mesh de service et routage du trafic
- La transition des applications monolithiques vers une architecture de microservice distribuée pourrait être difficile.
- Un maillage de service (composé d'un réseau de microservices) réduit la complexité de ces déploiements et assouplit la pression sur les équipes de développement.
- Istio: un maillage de service pour faciliter la création d'un réseau de services déployés avec l'équilibrage de charge, l'authentification du service à service, la surveillance, avec peu ou pas de modifications de code dans le code de service.
4.4. Surveillance:
- Objectif de surveillance:
- Alertes pour les temps d'arrêt, les erreurs et les changements de distribution
- Catching Service and Data Régressions
- Les solutions de fournisseurs de cloud sont décentes
- Kiali: une console d'observabilité pour Istio avec des capacités de configuration de maillage de service. Il répond à ces questions: comment les microservices sont-ils connectés? Comment se produisent-ils?
Avons-nous fini?

4.5. Déploiement sur des appareils intégrés et mobiles
- Défi principal: empreinte de la mémoire et contraintes de calcul
- Solutions:
- Quantification
- Taille du modèle réduit
- Distillation des connaissances
- Cadres intégrés et mobiles:
- TensorFlow Lite
- Pytorch mobile
- Noyau ML
- Kit ML
- Fritz
- Openvino
- Conversion du modèle:
- Exchange de réseaux de neurones ouverts (ONNX): format open source pour les modèles d'apprentissage en profondeur
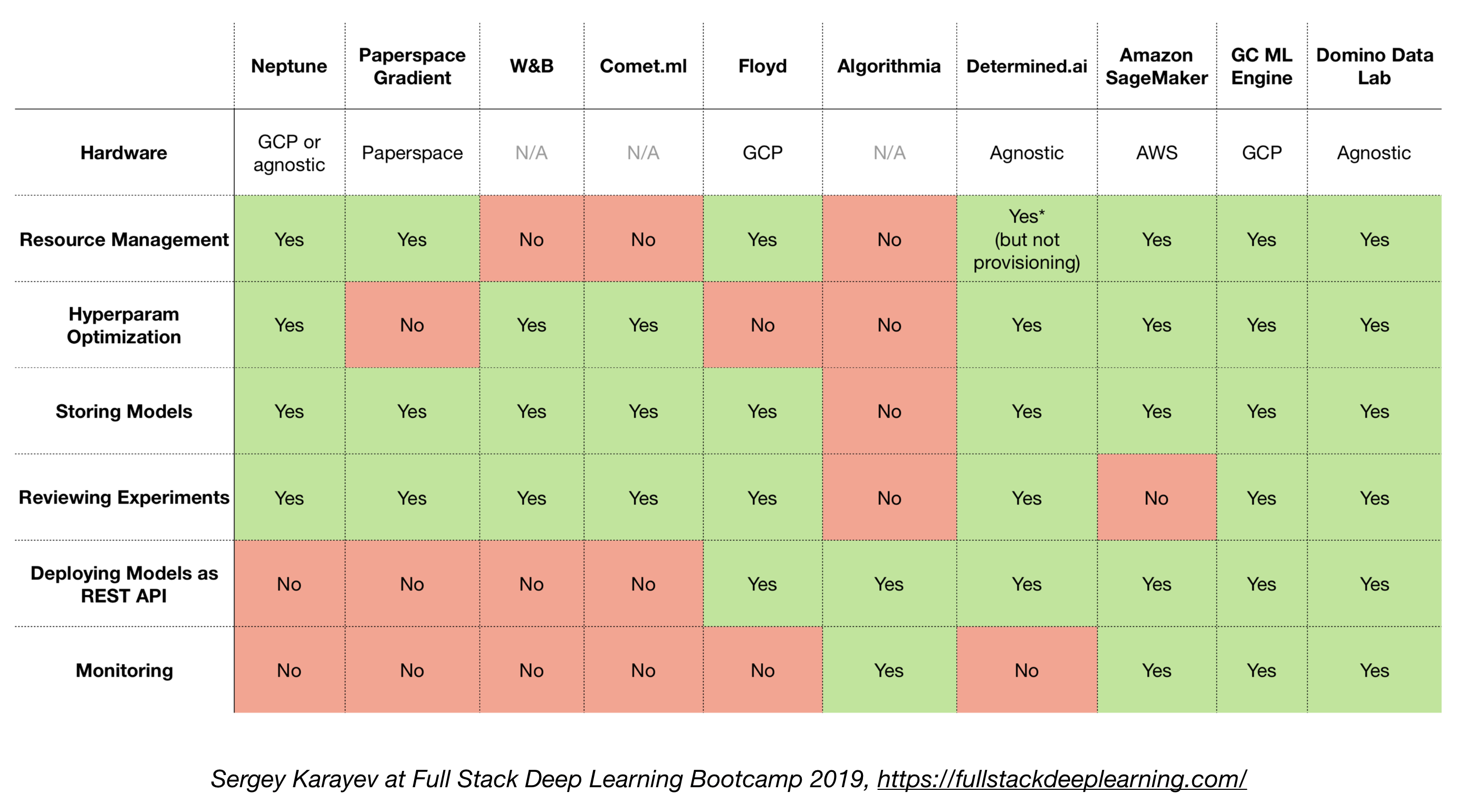
4.6. Solutions tout-en-un
- TensorFlow étendu (TFX)
- Michel-Ange (Uber)
- Plateforme Google Cloud AI
- Amazon Sagemaker
- Neptune
- Floyd
- Espace de papiers
- AI déterminé
- Domino Data Lab
TensorFlow étendu (TFX)
[TBD]
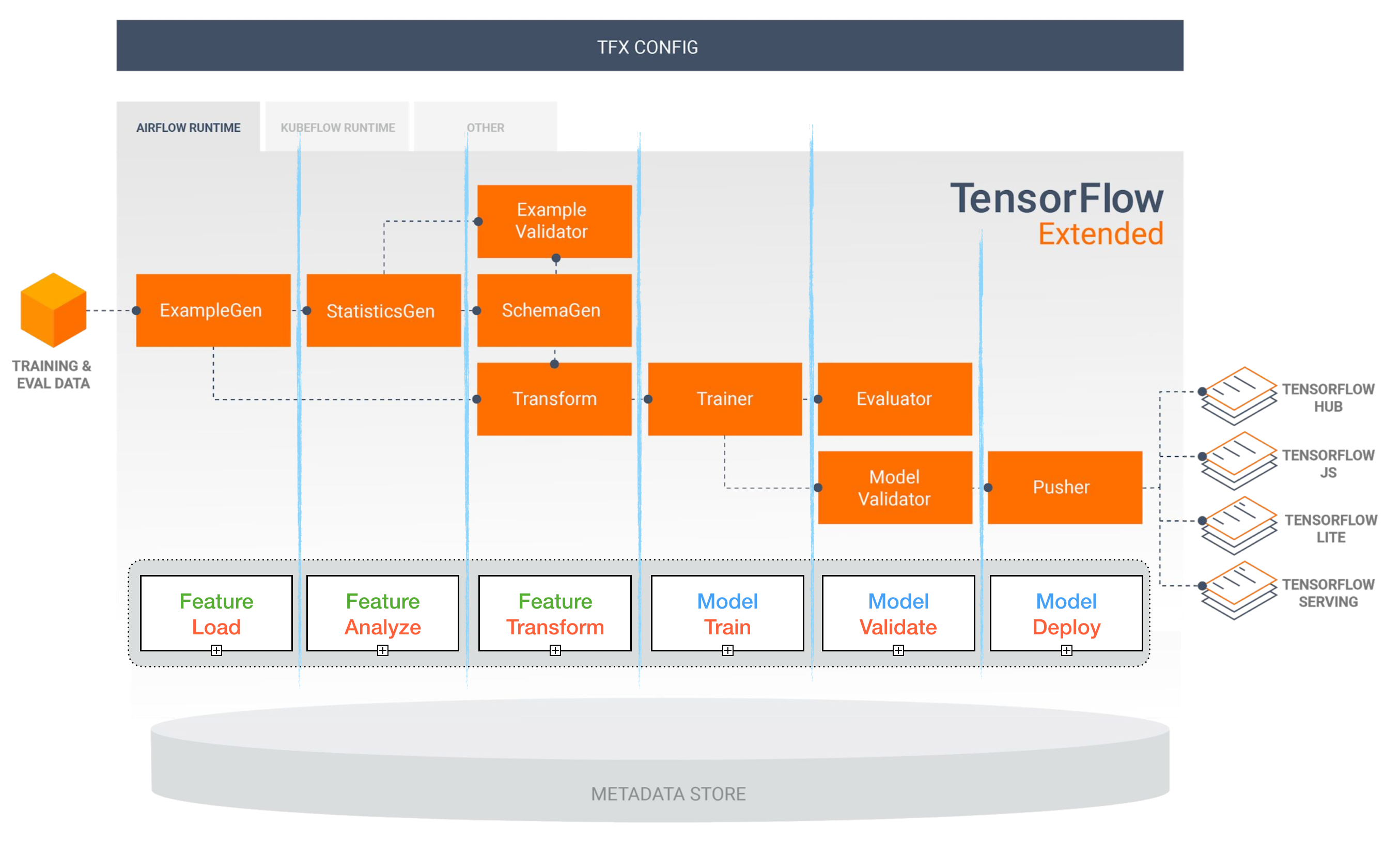
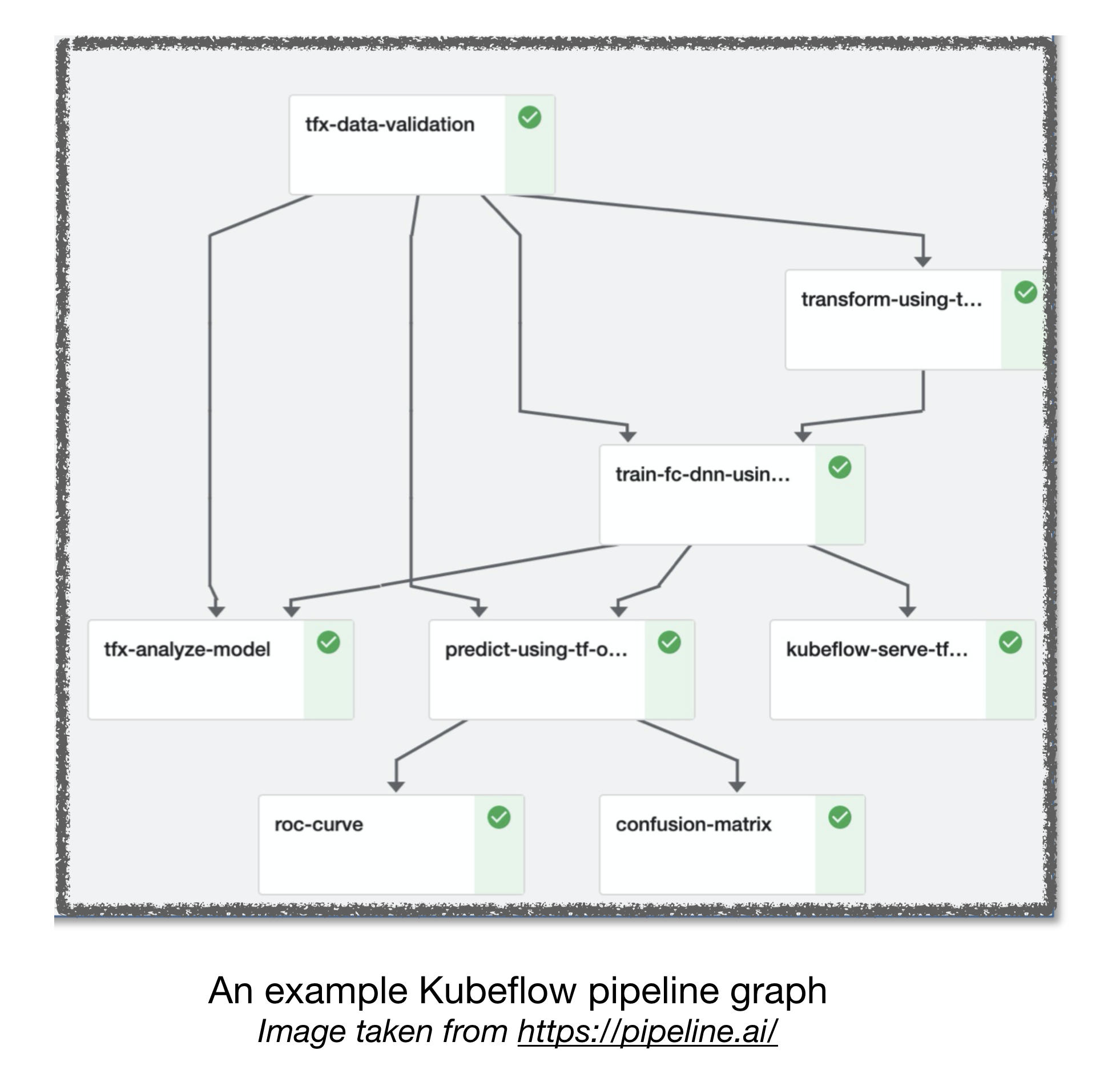
Pipelines Airflow et Kubeflow ML
[TBD]
Autres liens utiles:
- Les leçons tirées de la construction de systèmes d'apprentissage en profondeur pratiques
- Apprentissage automatique: la carte de crédit à intérêt élevé de la dette technique
Contributif
Références:
[1]: Full Stack Deep Learning Bootcamp, novembre 2019.
[2]: Advanced Kubeflow Workshop by Pipeline.ai, 2019.
[3]: TFX: apprentissage automatique du monde réel en production


