생산 수준의 딥 러닝 가이드? ⛴️
?? 중국어로 번역
? ️ New : 기계 학습 인터뷰
? ️ 참고 :이 리포지기는 지속적인 개발 중이며 모든 피드백과 기여는 매우 환영합니다.
프로덕션에 딥 러닝 모델을 배치하는 것은 성능이 우수한 교육 모델을 훨씬 뛰어 넘기 때문에 어려울 수 있습니다. 생산 수준의 딥 러닝 시스템을 배포하려면 몇 가지 고유 한 구성 요소를 설계하고 개발해야합니다 (아래 참조).
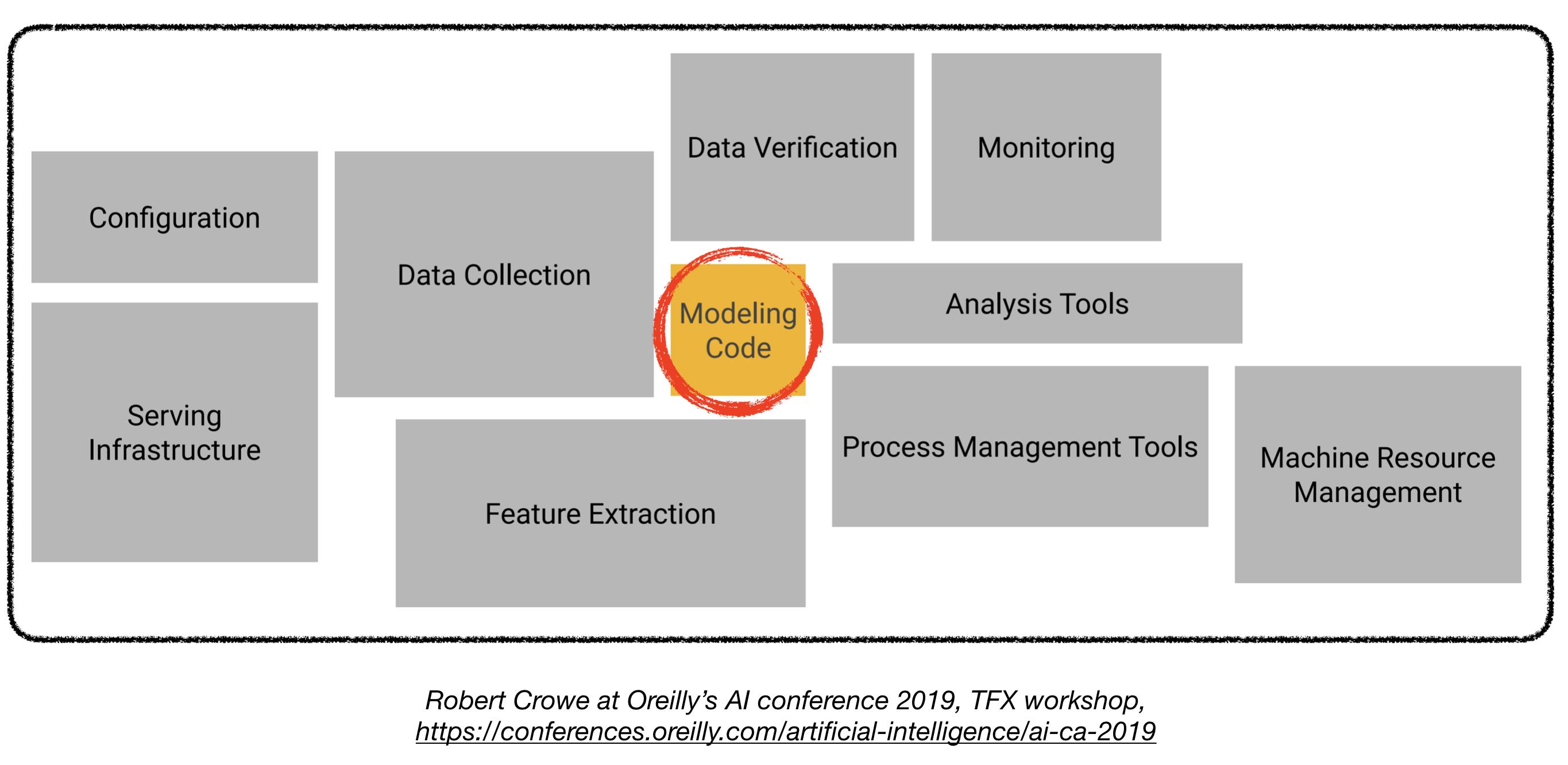
이 repo는 실제 응용 프로그램에 배치 될 생산 수준의 딥 러닝 시스템을 구축하기위한 엔지니어링 가이드 라인이되는 것을 목표로합니다.
여기에 제시된 자료는 Full Stack Deep Learning Bootcamp (UC Berkeley의 Pieter Abbeel, Openai의 Josh Tobin 및 Turnitin의 Sergey Karayev), Robert Crowe의 TFX 워크샵 및 Chris Fregly의 고급 Kubeflow Meetup에서 차용됩니다.
기계 학습 프로젝트
재미있는 ? 사실 : AI 프로젝트의 85%가 실패합니다 . 1 가지 잠재적 인 이유는 다음과 같습니다.
- 기술적으로 불가능하거나 범위가 저하되었습니다
- 절대 생산으로 도약하지 마십시오
- 불분명 한 성공 기준 (메트릭)
- 가난한 팀 관리
1. ML 프로젝트 수명주기
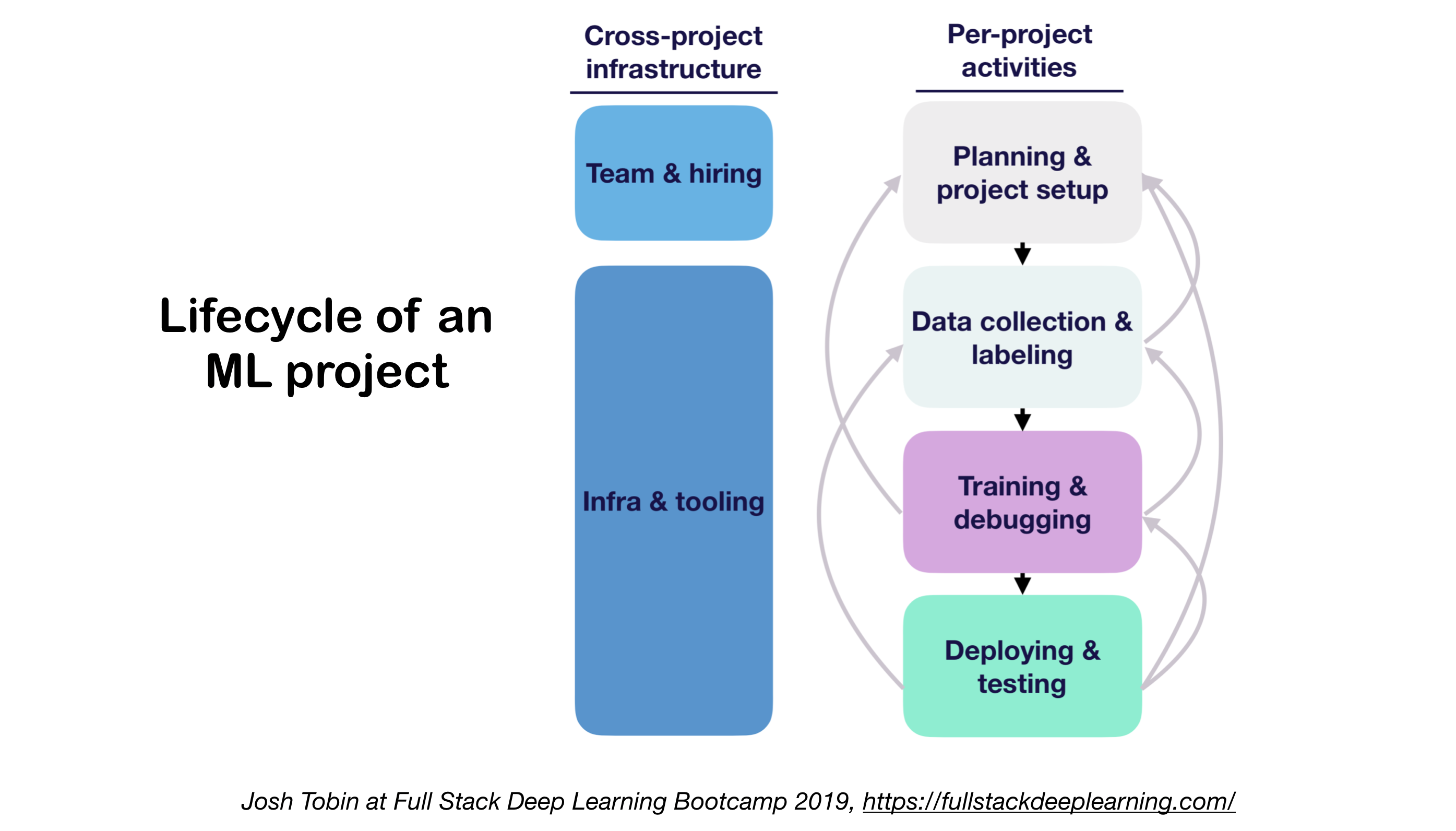
- 영역에서 기술 상태를 이해하는 것의 중요성 :
- 가능한 것이 무엇인지 이해하는 데 도움이됩니다
- 다음에 무엇을 시도 해야할지 아는 데 도움이됩니다
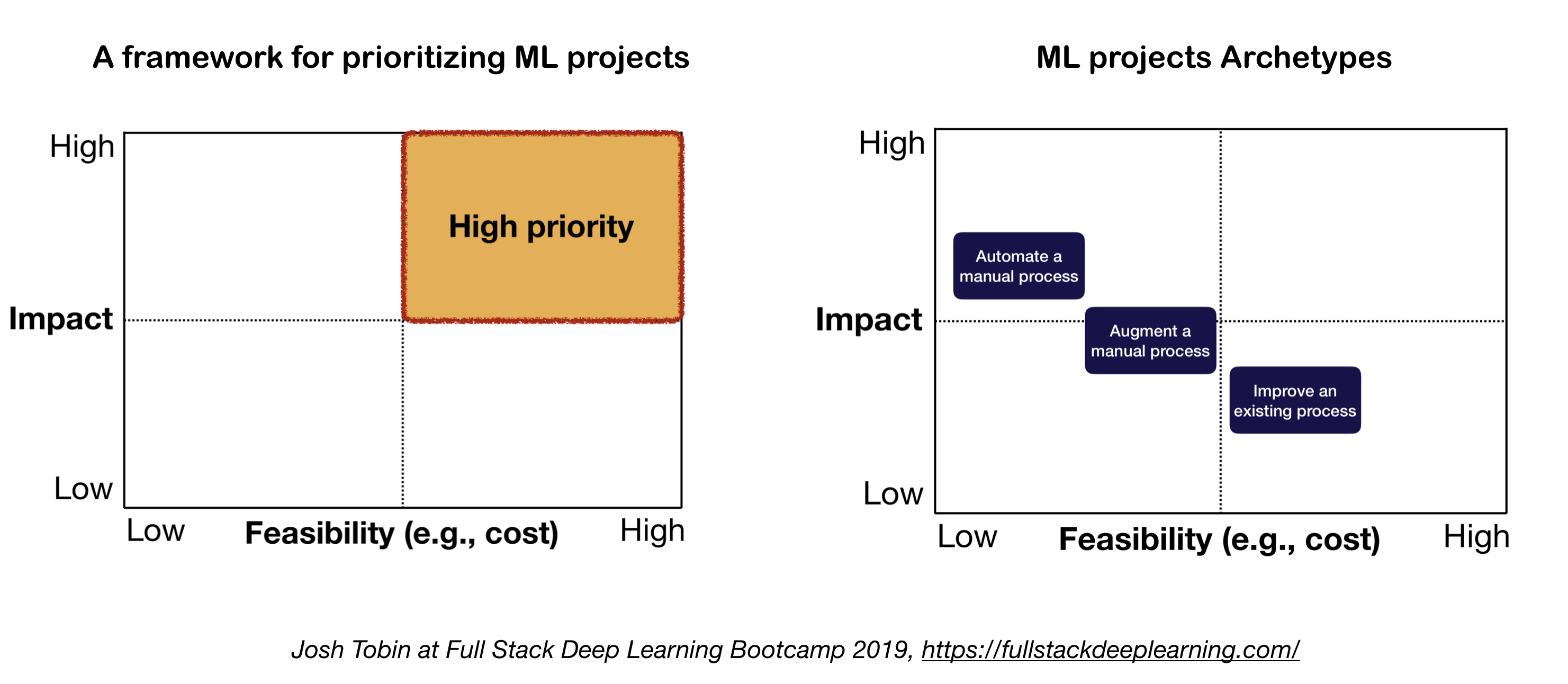
2. ML 프로젝트의 정신 모델
ML 프로젝트를 정의하고 우선 순위를 정할 때 고려해야 할 두 가지 중요한 요소 :
- 높은 충격 :
- 파이프 라인의 복잡한 부분
- "저렴한 예측"은 가치가 있습니다
- 복잡한 수동 프로세스를 자동화하는 것이 가치가 있습니다
- 저렴한 비용 :
- 비용은 다음과 같습니다.
- 데이터 가용성
- 성능 요구 사항 : 비용은 정확도 요구 사항에서 초대형으로 확장되는 경향이 있습니다.
- 문제 난이도 :
- 어려운 문제 중 일부는 다음과 같습니다. 감독되지 않은 학습, 강화 학습 및 특정 범주의 감독 학습
전체 스택 파이프 라인
다음 그림은 생산 수준의 딥 러닝 시스템에서 다양한 구성 요소에 대한 높은 수준의 개요를 나타냅니다.
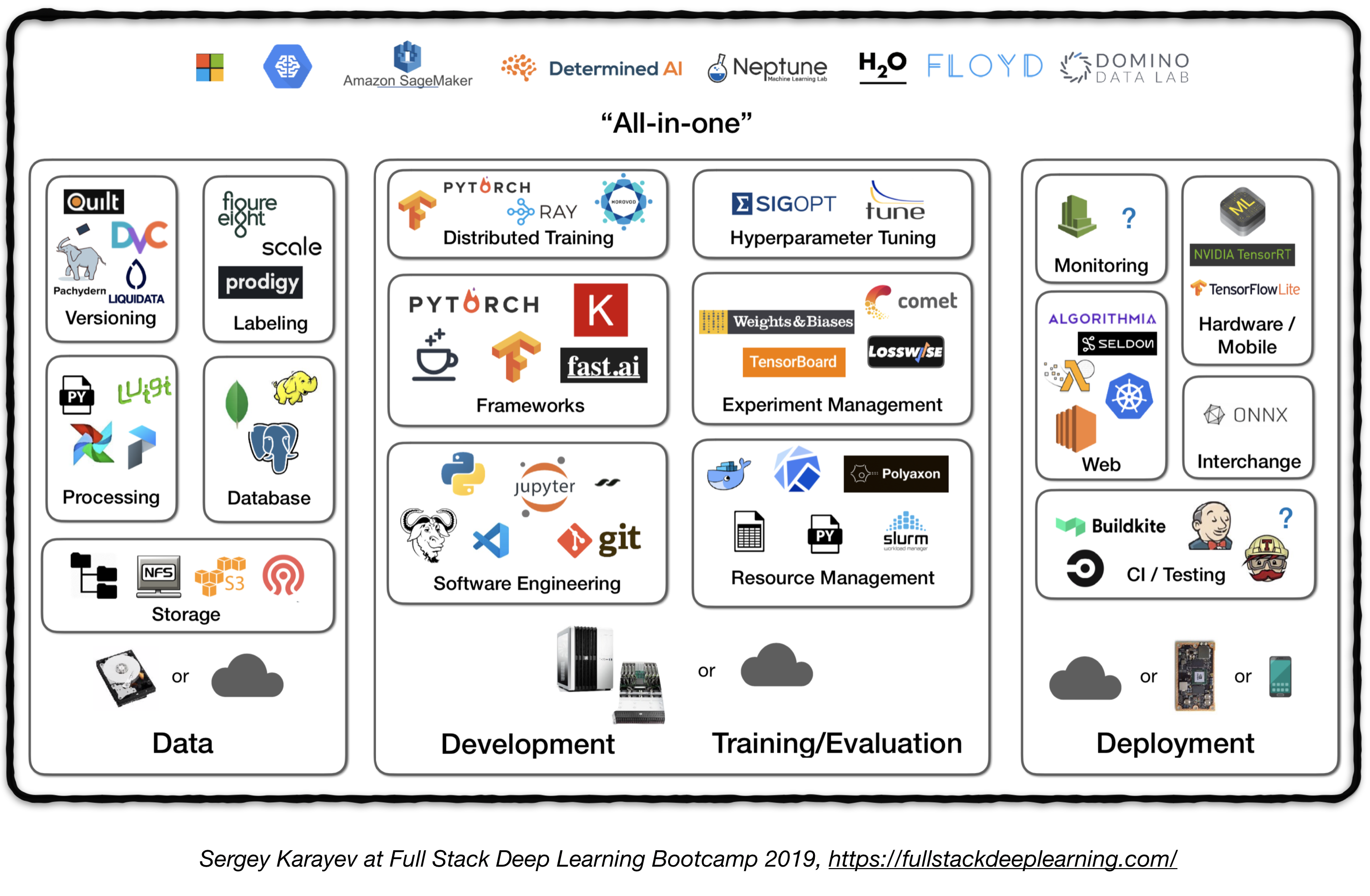
다음에서는 각 모듈을 살펴보고 각 구성 요소에 맞는 실무자의 모범 사례뿐만 아니라 도구 세트 및 프레임 워크를 추천합니다.
1. 데이터 관리
1.1 데이터 소스
- 감독 된 딥 러닝에는 많은 라벨이 붙은 데이터가 필요합니다
- 자체 데이터 라벨링 비용이 많이 듭니다!
- 데이터를위한 몇 가지 리소스는 다음과 같습니다.
- 오픈 소스 데이터 (시작하기에 좋지만 이점은 아닙니다)
- 데이터 확대 (컴퓨터 비전을위한 필수, NLP 옵션)
- 합성 데이터 (NLP에서 거의 항상 시작할 가치가 있습니다)
1.2 데이터 라벨링
- 요구 사항 : 별도의 소프트웨어 스택 (라벨링 플랫폼), 임시 노동 및 QC
- 라벨링을위한 노동 원 :
- 크라우드 소싱 (기계적 터크) : 저렴하고 확장 가능하며 신뢰성이 떨어지며 QC가 필요합니다.
- 자신의 주석 채용 : QC가 필요하지 않음, 비싸고, 느리게 스케일링
- 데이터 라벨링 서비스 회사 :
- 라벨링 플랫폼 :
- Diffgram : 교육 데이터 소프트웨어 (컴퓨터 비전)
- Prodigy : Active Learning (Spacy 개발자), 텍스트 및 이미지로 구동되는 주석 도구
- Hive : 컴퓨터 비전을위한 서비스 플랫폼으로 AI
- 감독 : 전체 컴퓨터 비전 플랫폼
- 레이블 박스 : 컴퓨터 비전
- 스케일 AI 데이터 플랫폼 (컴퓨터 비전 및 NLP)
1.3. 데이터 저장
- 데이터 저장 옵션 :
- 객체 저장소 : 이진 데이터 저장 (이미지, 사운드 파일, 압축 텍스트)
- 데이터베이스 : 메타 데이터 저장 (파일 경로, 레이블, 사용자 활동 등).
- Postgres는 대부분의 응용 프로그램에 적합한 선택이며, 동급 최고의 SQL과 구조화되지 않은 JSON에 대한 큰 지원을 제공합니다.
- Data Lake : 데이터베이스에서 얻을 수없는 기능 (예 : 로그)
- 기능 저장소 : 매장, 액세스 및 공유 기계 학습 기능 (기능 추출은 계산 비용이 많이 들고 확장하기가 거의 불가능할 수 있으므로 다양한 모델과 팀의 기능을 재사용하는 것이 고성능 ML 팀의 핵심입니다).
- 축제 (Google Cloud, 오픈 소스)
- 미켈란젤로 팔레트 (Uber)
- 제안 : 교육 시간에 데이터를 로컬 또는 네트워크 파일 시스템 (NFS)으로 복사하십시오. 1
1.4. 데이터 버전 작성
- 배포 된 ML 모델의 "필수"입니다.
배포 된 ML 모델은 부품 코드, 부품 데이터입니다 . 1 데이터 버전화는 모델 버전화가 없음을 의미합니다. - 데이터 버전화 플랫폼 :
- DVC : ML 프로젝트 용 오픈 소스 버전 제어 시스템
- Pachyderm : 데이터에 대한 버전 제어
- DOLT : 데이터 및 스키마에 대한 git- 유사 버전 제어 기능이있는 SQL 데이터베이스
1.5. 데이터 처리
- 생산 모델에 대한 교육 데이터는 DB 및 객체 저장에 저장된 데이터 , 로그 처리 및 다른 분류기의 출력을 포함하여 다른 소스에서 나올 수 있습니다.
- 작업간에 종속성이 있으며 종속성이 완료된 후에 각각 시작해야합니다. 예를 들어, 새로운 로그 데이터에 대한 교육에는 훈련 전에 전처리 단계가 필요합니다.
- Makefiles는 확장 할 수 없습니다. "워크 플로 관리자"는 이와 관련하여 꽤 필수적입니다.
- 워크 플로 오케스트레이션 :
- Spotify의 Luigi
- 에어 비앤비에 의한 공기 흐름 : 역동적이고, 확장 가능, 우아하며, 확장 가능 (가장 널리 사용되는 것)
- DAG 워크 플로
- 강력한 조건부 실행 : 고장시 재 시도
- 푸셔는 텐서 플로우 서빙으로 Docker 이미지를 지원합니다
- 단일 .py 파일의 전체 워크 플로
2. 개발, 훈련 및 평가
2.1. 소프트웨어 엔지니어링
- 수상자 언어 : 파이썬
- 편집자 :
- 정력
- EMACS
- vs 코드 (저자가 권장) : 내장 GIT 스테이징 및 차이, 보풀 코드, SSH를 통해 원격 프로젝트 오픈 프로젝트
- 노트북 : 프로젝트의 출발점으로 훌륭하고 확장하기 어렵습니다 (재미있는 사실 : Netflix의 노트북 구동 아키텍처는 전적으로 Nteract Suites를 기반으로하는 예외입니다).
- NTERACT : Jupyter 노트북을위한 차세대 반응 기반 UI
- Papermill : Jupyter 노트북 매개 변수화 , 실행 및 분석을 위해 구축 된 Nteract 라이브러리입니다.
- 통근 : 노트북의 읽기 전용 표시 (예 : S3 버킷)를 제공하는 또 다른 NTERACT 프로젝트.
- 간소 : 애플릿이있는 대화식 데이터 과학 도구
- 추천 계산 1 :
- 개인 또는 신생 기업 의 경우 :
- 개발 : 4X Turing-Arachitecture PC
- 교육/평가 : 동일한 4x GPU PC를 사용하십시오. 많은 실험을 실행할 때 공유 서버를 구매하거나 클라우드 인스턴스를 사용하십시오.
- 대기업의 경우 :
- 개발 : ML 과학자 당 4X 튜링 아카데입 PC를 구매하거나 V100 인스턴스를 사용하도록하십시오.
- 교육/평가 : 적절한 프로비저닝 및 실패 처리와 함께 클라우드 인스턴스 사용
- 클라우드 제공 업체 :
- GCP : GPU를 모든 인스턴스에 연결하는 옵션 + + TPU가 있습니다.
- AWS :
2.2. 자원 관리
- 무료 리소스를 프로그램에 할당
- 자원 관리 옵션 :
- 구식 클러스터 작업 스케줄러 (예 : Slurm Workload Manager)
- Docker + Kubernetes
- Kubeflow
- Polyaxon (유료 기능)
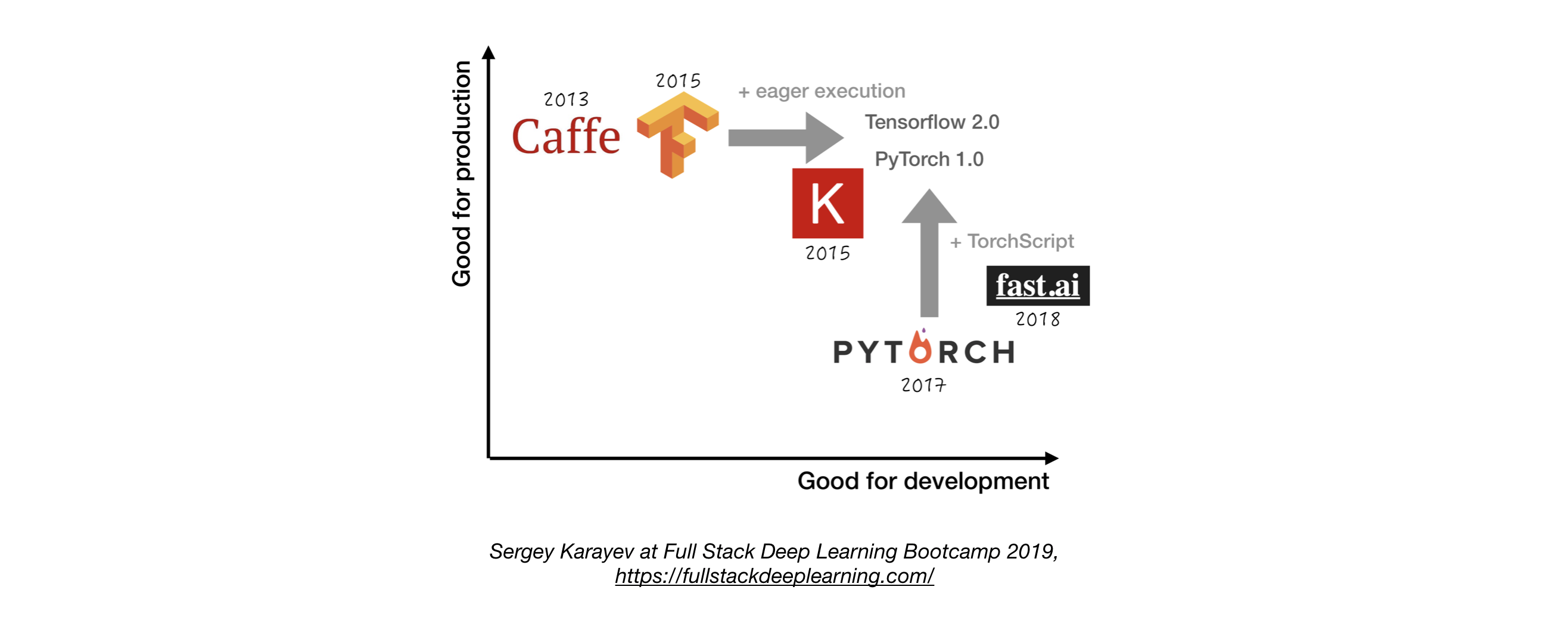
2.3. DL 프레임 워크
- 그만한 이유가 없다면 Tensorflow/Keras 또는 Pytorch를 사용하십시오. 1
- 다음 그림은 "개발" 과 "생산"을 나타내는 방법에 대한 다른 프레임 워크 간의 비교를 보여줍니다.
2.4. 실험 관리
- 개발, 교육 및 평가 전략 :
- 항상 간단하게 시작하십시오
- 작은 배치에서 작은 모델을 훈련하십시오. 작동하는 경우에만 더 큰 데이터 및 모델로 확장하고 하이퍼 파라미터 튜닝!
- 실험 관리 도구 :
- 텐서 보드
- ML 실험에 필요한 시각화 및 툴링을 제공합니다
- Losswise (ML 모니터링)
- 혜성 : ML 프로젝트에 대한 코드, 실험 및 결과를 추적 할 수 있습니다.
- 웨이트 및 바이어스 : 쉽게 협력하여 연구의 모든 세부 사항을 기록하고 시각화합니다.
- MLFLOW 추적 : 매개 변수, 코드 버전, 메트릭 및 출력 파일 및 결과 시각화의 경우.
- 파이썬에서 한 줄의 코드를 사용한 자동 실험 추적
- 실험의 나란히 비교
- 하이퍼 파라미터 튜닝
- Kubernetes 기반 작업을 지원합니다
2.5. 하이퍼 파라미터 튜닝
구혼:
- 그리드 검색
- 임의의 검색
- 베이지안 최적화
- 하이퍼 밴드 및 비동기 연속적인 절단 알고리즘 (ASHA)
- 인구 기반 훈련
플랫폼 :
- Raytune : Ray Tune은 모든 규모의 하이퍼 파라미터 튜닝을위한 파이썬 라이브러리입니다 (딥 러닝 및 깊은 강화 학습에 중점을 둔). Pytorch, Xgboost, MXnet 및 Keras를 포함한 모든 기계 학습 프레임 워크를 지원합니다.
- Katib: Kubernete's Native System for Hyperparameter Tuning and Neural Architecture Search, inspired by [Google vizier](https://static.googleusercontent.com/media/ research.google.com/ja//pubs/archive/ bcb15507f4b52991a0783013df4222240e942381.pdf) 여러 ML/DL 프레임 워크 (예 : TensorFlow, MXNet 및 Pytorch)를 지원합니다.
- Hyperas : Keras 용 Hyperopt 주변의 간단한 래퍼. 간단한 템플릿 표기법으로 하이퍼 매개 변수 범위를 정의 할 수 있습니다.
- SIGOPT : 확장 가능한 엔터프라이즈 등급 최적화 플랫폼
- [weights & biases] (https://www.wandb.com/)의 스윕 : 매개 변수는 개발자가 명시 적으로 지정하지 않습니다. 대신 그들은 머신 러닝 모델에 의해 근사화되고 배웁니다.
- Keras Tuner : Keras의 초 파라미터 튜너, 특히 TF.KERAS 용 TENSORFLOW 2.0을위한 튜너.
2.6. 분산 교육
- 데이터 병렬 처리 : 반복 시간이 너무 길면 사용하십시오 (Tensorflow 및 Pytorch Support)
- 모델 병렬 처리 : 모델이 단일 GPU에 맞지 않는 경우
- 기타 솔루션 :
3. 문제 해결 [TBD]
4. 테스트 및 배포
4.1. 테스트 및 CI/CD
기계 학습 제작 소프트웨어에는 기존 소프트웨어보다 더 다양한 테스트 스위트가 필요합니다.
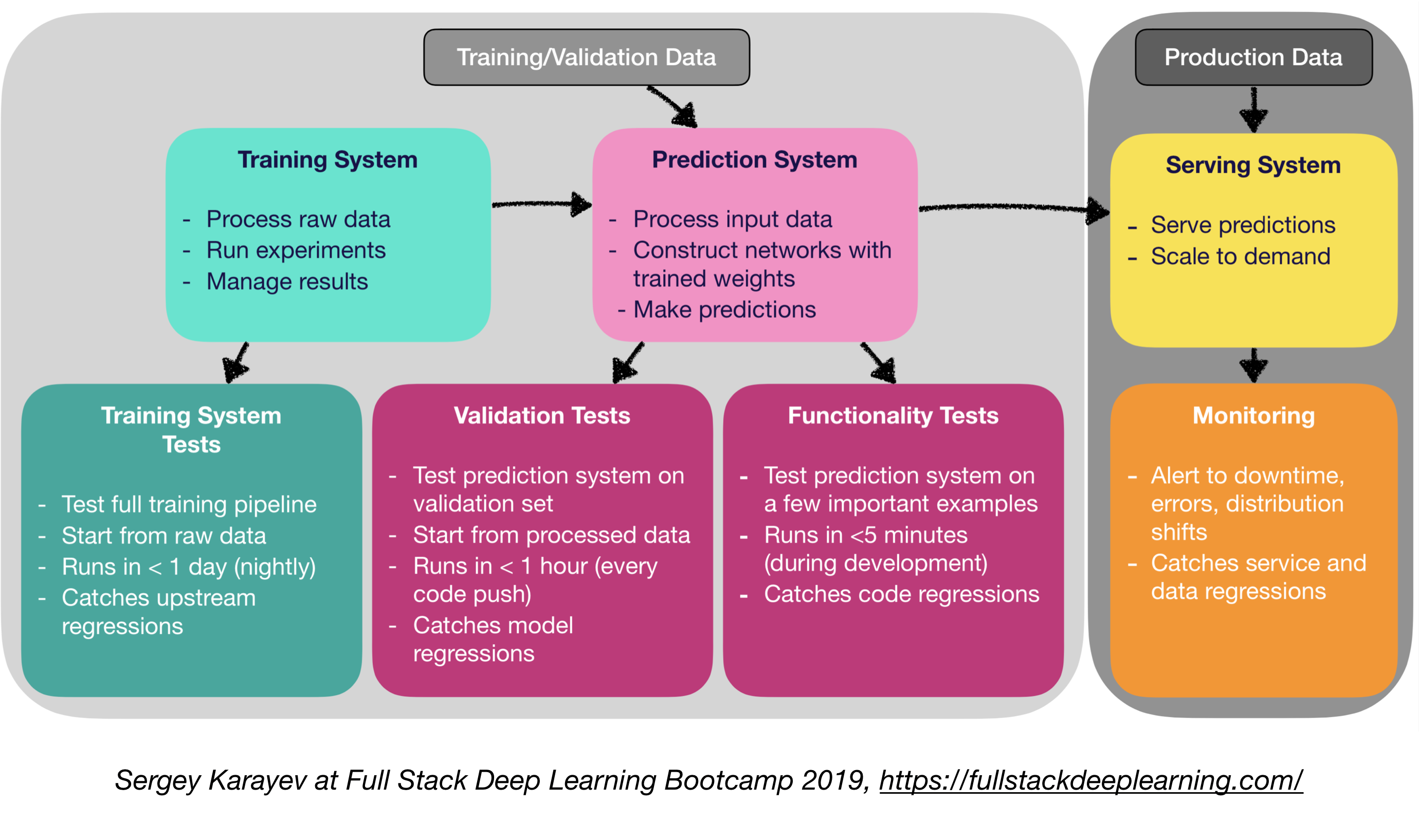
- 단위 및 통합 테스트 :
- 테스트 유형 :
- 교육 시스템 테스트 : 교육 파이프 라인 테스트
- 유효성 검사 테스트 : 유효성 검사 세트에서 예측 시스템 테스트
- 기능 테스트 : 몇 가지 중요한 예에 대한 예측 시스템 테스트
- 연속 통합 : 각각의 새로운 코드 변경 후 실행중인 테스트 실행
- 지속적인 통합을위한 SaaS :
- ARGO : 평행 작업을 조정하기위한 오픈 소스 Kubernetes 기본 워크 플로 엔진 (워크 플로, 이벤트, CI 및 CD).
- Circleci : 언어 포함 지원, 맞춤형 환경, 유연한 리소스 할당, Instacart, Lyft 및 Stackshare에서 사용합니다.
- 트래비스 CI
- BuildKite : 빠르고 안정적인 빌드, 오픈 소스 에이전트는 거의 모든 기계 및 아키텍처에서 실행되며 자신의 도구 및 서비스를 사용할 수있는 자유
- Jenkins : 구식 건축 시스템
4.2. 웹 배포
- 예측 시스템 과 서빙 시스템 으로 구성됩니다
- 예측 시스템 : 프로세스 입력 데이터, 예측을합니다
- 서빙 시스템 (웹 서버) :
- 규모를 염두에두고 예측을 제공하십시오
- REST API를 사용하여 예측 HTTP 요청을 제공하십시오
- 예측 시스템에 전화하여 응답합니다
- 서빙 옵션 :
- 인스턴스를 추가하여 vms에 배포하고 스케일
- 오케스트레이션을 통해 컨테이너로 배포하십시오
- 컨테이너
- 컨테이너 오케스트레이션 :
- Kubernetes (현재 가장 인기있는)
- 메소스
- 마라톤
- "서버리스 함수"로 코드를 배포
- 모델 서빙 솔루션을 통해 배포하십시오
- 모델 서빙 :
- ML 모델을위한 특수 웹 배포
- GPU 추론에 대한 배치 요청
- 프레임 워크 :
- 텐서 플로우 서빙
- MXNET 모델 서버
- 클리퍼 (버클리)
- Saas 솔루션
- Seldon : Kubernetes의 모든 프레임 워크에 구축 된 서빙 및 스케일 모델
- 알고리즘
- 의사 결정 : CPU 또는 GPU?
- CPU 추론 :
- CPU 추론이 요구 사항을 충족하는 경우 바람직합니다.
- 더 많은 서버를 추가하거나 서버리스로 이동하여 스케일.
- GPU 추론 :
- TF 서빙 또는 클리퍼
- 적응 형 배치가 유용합니다
- (보너스) Jupyter 노트북 배포 :
- KubeFlow Faireing은 Jupyter 노트북 코드를 배포 할 수있는 하이브리드 배포 패키지입니다!
4.5 서비스 메쉬 및 트래픽 라우팅
- 모 놀리 식 응용에서 분산 마이크로 서비스 아키텍처로의 전환은 어려울 수 있습니다.
- 서비스 메쉬 (마이크로 서비스 네트워크로 구성된)는 이러한 배포의 복잡성을 줄이고 개발 팀의 긴장을 완화시킵니다.
- ISTIO : 서비스 코드의 코드 변경이 거의 없거나 전혀없는로드 밸런싱, 서비스 간 서비스 인증, 모니터링을 갖춘 배포 된 서비스 네트워크를 쉽게 만들기위한 서비스 메시.
4.4. 모니터링 :
- 모니터링 목적 :
- 가동 중지 시간, 오류 및 분배 변화에 대한 경고
- 서비스 및 데이터 회귀 분석
- 클라우드 제공 업체 솔루션은 괜찮습니다
- Kiali : 서비스 메쉬 구성 기능이있는 Istio의 관찰 가능성 콘솔. 이 질문에 대한 답변 : 마이크로 서비스는 어떻게 연결되어 있습니까? 그들은 어떻게 공연하고 있습니까?
우리가 끝났나요?

4.5. 임베디드 및 모바일 장치에 배포
- 주요 과제 : 메모리 풋 프린트 및 계산 제약 조건
- 솔루션 :
- 임베디드 및 모바일 프레임 워크 :
- 텐서 플로우 라이트
- Pytorch 모바일
- 핵심 ML
- ML 키트
- 프리츠
- OpenVino
- 모델 변환 :
- ONNX (Open Neural Network Exchange) : 딥 러닝 모델을위한 오픈 소스 형식
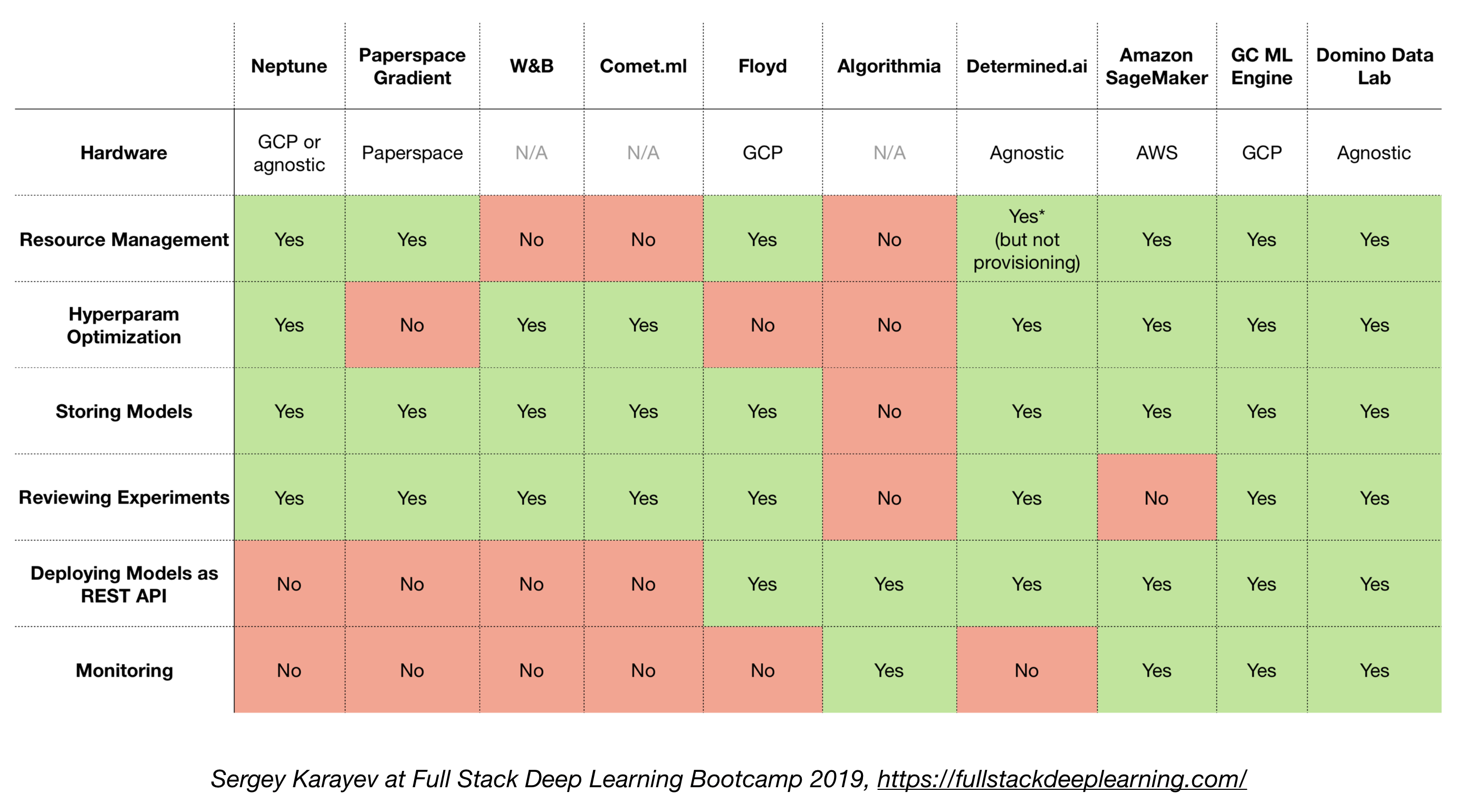
4.6. 올인원 솔루션
- 텐서 플로 확장 (TFX)
- 미켈란젤로 (Uber)
- Google Cloud AI 플랫폼
- 아마존 Sagemaker
- 해왕성
- 플로이드
- 종이 공간
- 결정된 AI
- 도미노 데이터 실험실
텐서 플로 확장 (TFX)
[TBD]
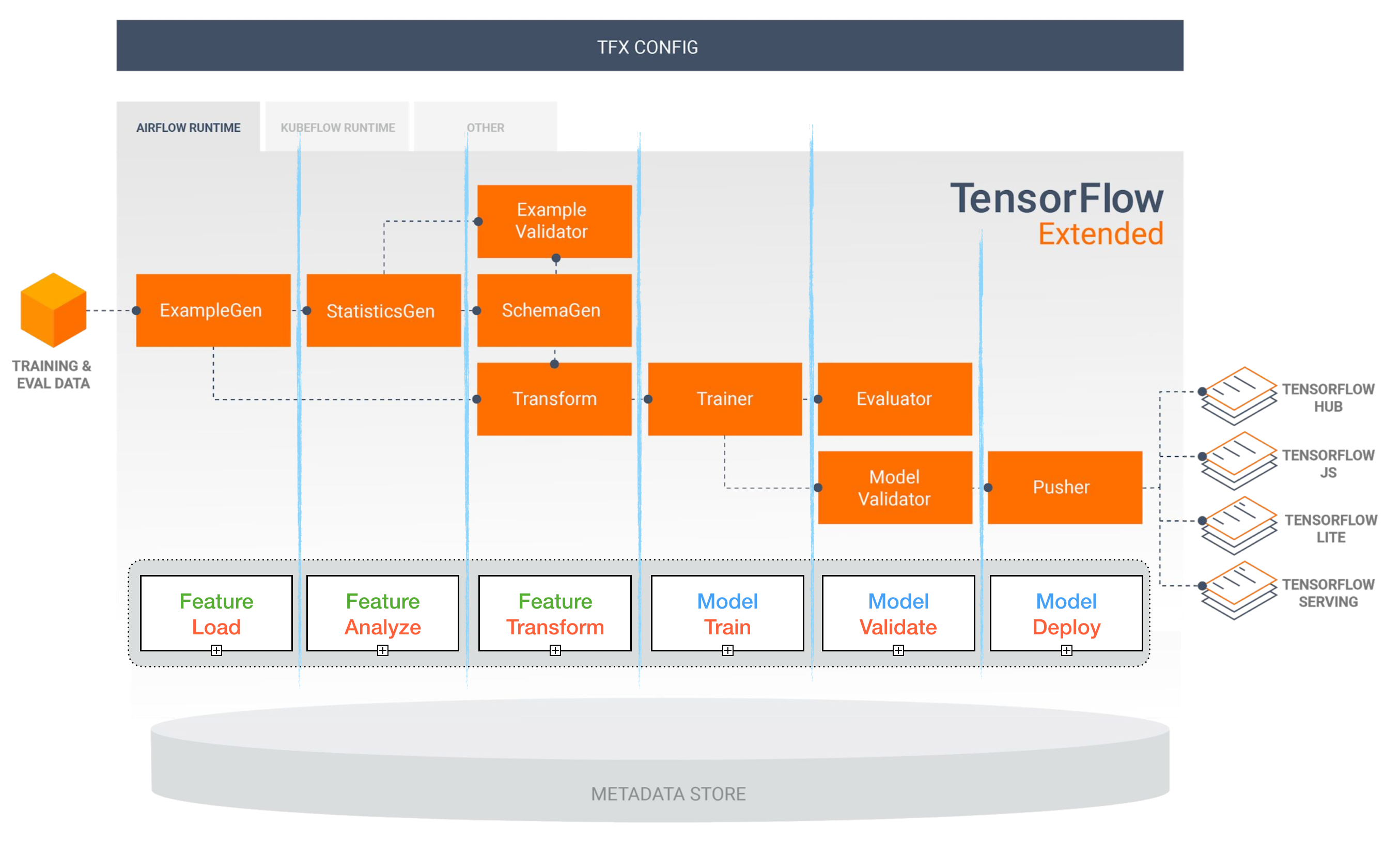
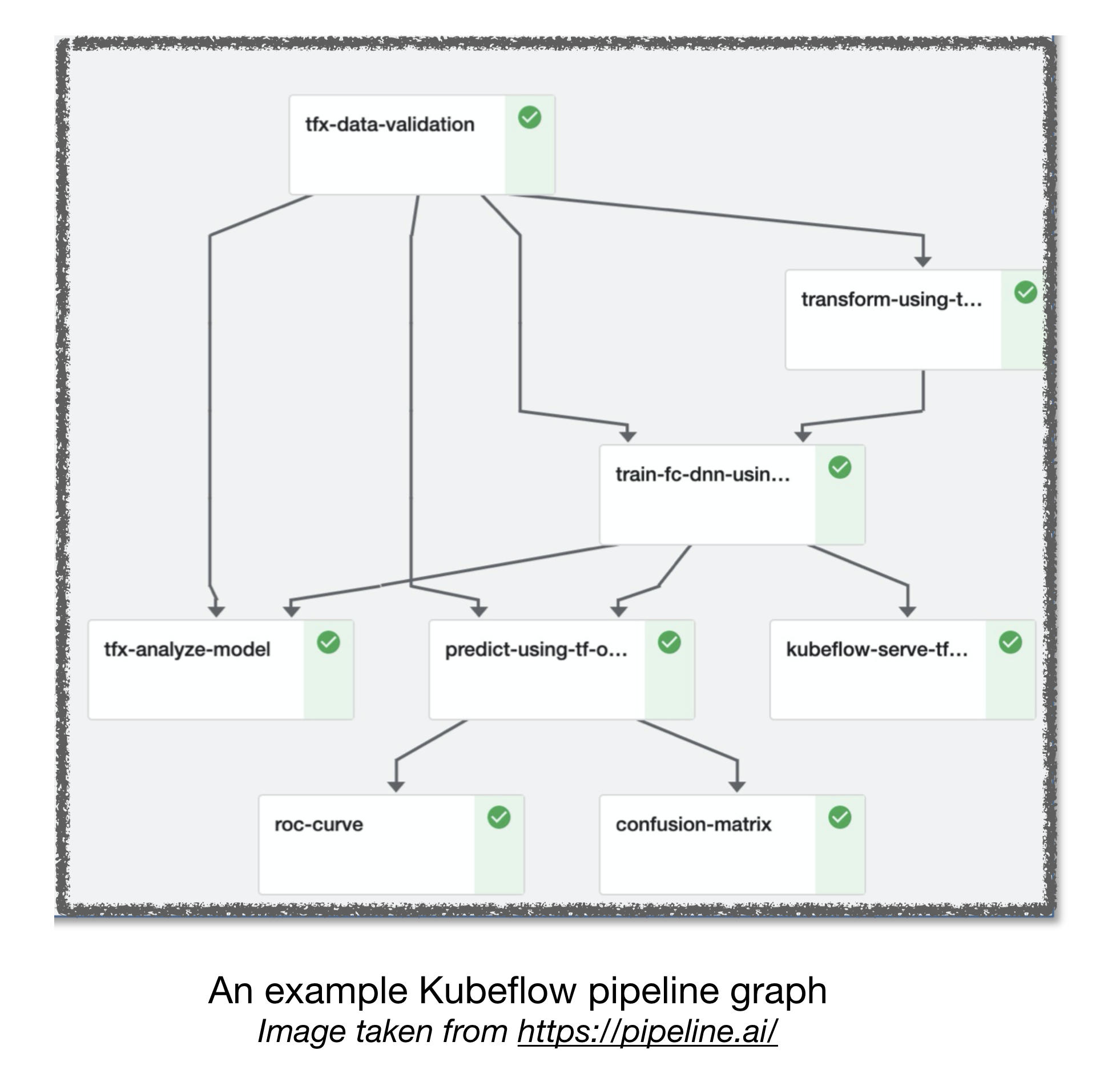
공기 흐름 및 쿠브 플로우 ML 파이프 라인
[TBD]
기타 유용한 링크 :
- 실용적인 딥 러닝 시스템을 구축함으로써 배운 교훈
- 기계 학습 : 기술 부채의 높은이자 신용 카드
기여
참조 :
[1] : 풀 스택 딥 러닝 부트 캠프, 2019 년 11 월.
[2] : Pipeline.ai의 고급 Kubeflow 워크숍, 2019.
[3] : TFX 생산에서 실제 기계 학습


