¿Una guía para el aprendizaje profundo de nivel de producción? ⛴️
? Traducción en chino
? ️ NUEVO: Entrevistas de aprendizaje automático
? ️ Nota: ¿Este repositorio está en desarrollo continuo, y todas las comentarios y contribuciones son muy bienvenidas?
La implementación de modelos de aprendizaje profundo en la producción puede ser un desafío, ya que está mucho más allá de los modelos de capacitación con buen rendimiento. Se deben diseñar y desarrollar varios componentes distintos para implementar un sistema de aprendizaje profundo de nivel de producción (que se ve a continuación):
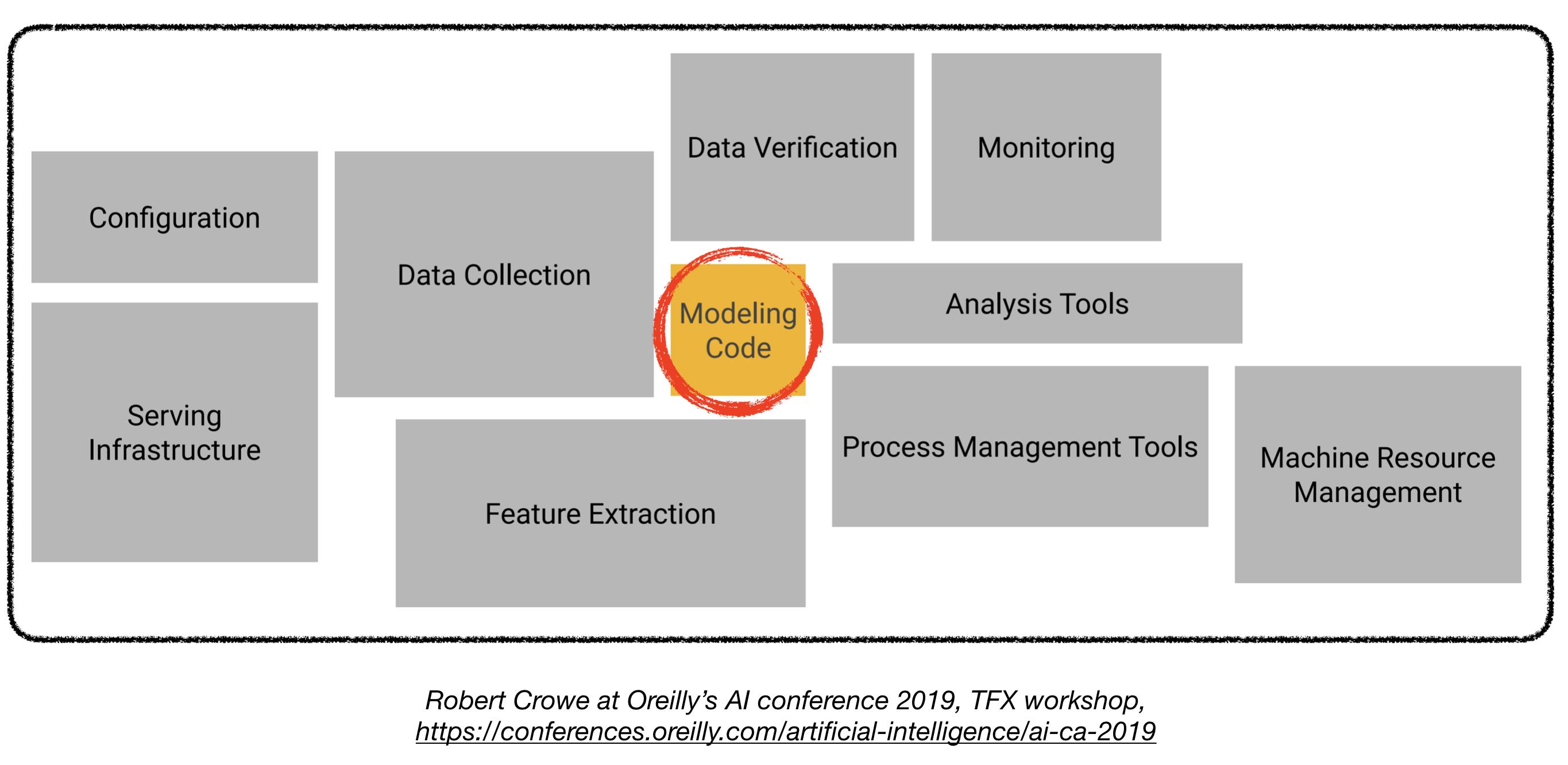
Este repositorio tiene como objetivo ser una guía de ingeniería para construir sistemas de aprendizaje profundo a nivel de producción que se implementará en aplicaciones del mundo real.
El material presentado aquí se toma prestado de Full Stack Deep Learning Bootcamp (de Pieter Abbeel en UC Berkeley, Josh Tobin en OpenAi y Sergey Karayev en Turnitin), taller TFX de Robert Crowe y el avanzado Kubeflow de Pipeline.
Proyectos de aprendizaje automático
Divertido ? Hecho: el 85% de los proyectos de IA fallan . 1 Posibles razones incluyen:
- Técnicamente nocivo o mal alcanzado
- Nunca hagas el salto a la producción
- Criterios de éxito poco claros (métricas)
- Gestión de equipo pobre
1. Ml Proyectos Ciclo de vida
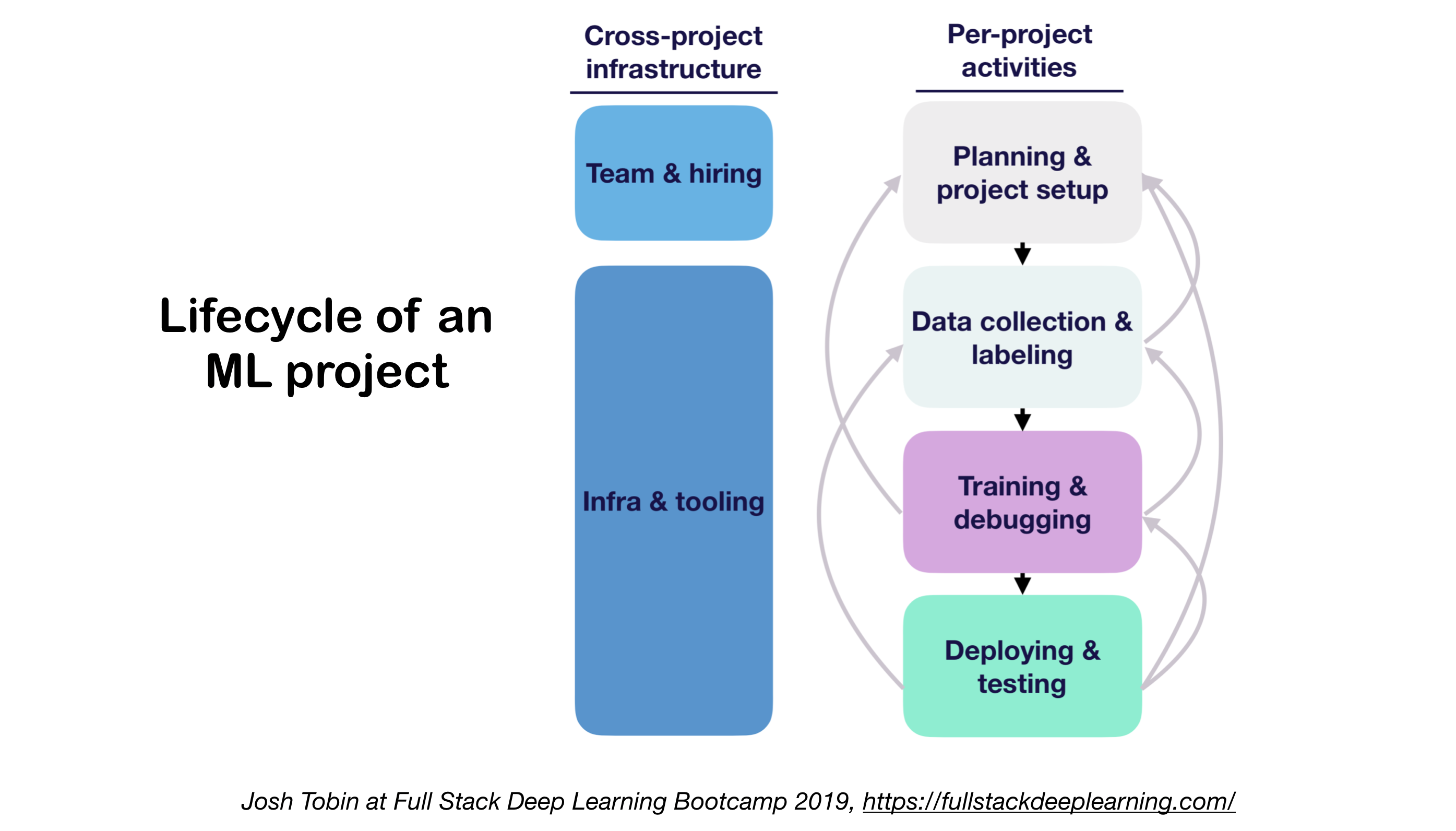
- Importancia de comprender el estado del arte en su dominio:
- Ayuda a entender lo que es posible
- Ayuda a saber qué probar a continuación
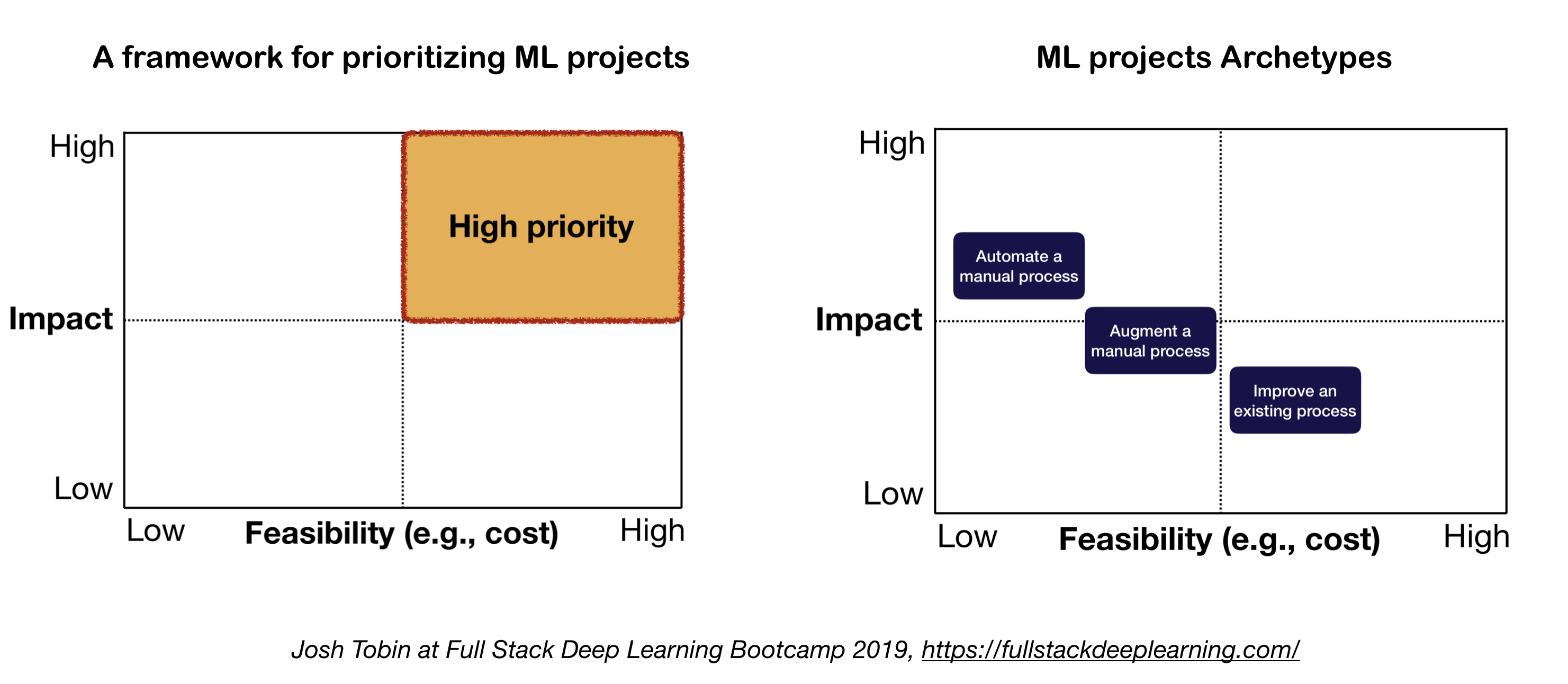
2. Modelo mental para el proyecto ML
Los dos factores importantes a considerar al definir y priorizar proyectos de ML:
- Alto impacto:
- Partes complejas de tu tubería
- Donde la "predicción barata" es valiosa
- Donde la automatización del proceso manual complicado es valioso
- Bajo costo:
- El costo es impulsado por:
- Disponibilidad de datos
- Requisitos de rendimiento: los costos tienden a escalar súper linealmente en el requisito de precisión
- Dificultad para el problema:
- Algunos de los problemas difíciles incluyen: aprendizaje no supervisado, aprendizaje de refuerzo y ciertas categorías de aprendizaje supervisado
Tubería de pila completa
La siguiente figura representa una descripción general de alto nivel de diferentes componentes en un sistema de aprendizaje profundo de nivel de producción:
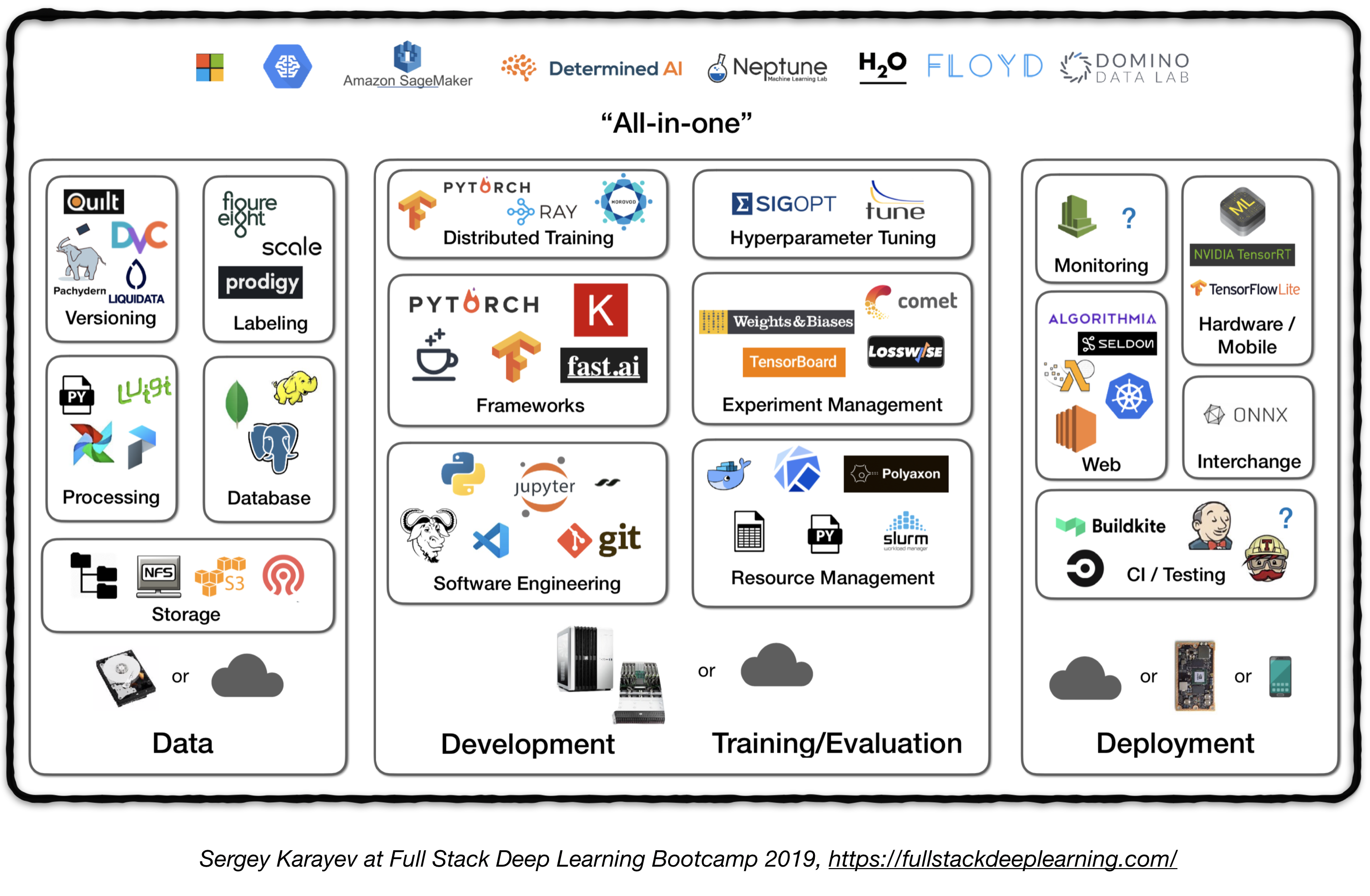
A continuación, revisaremos cada módulo y recomendaremos herramientas y marcos, así como las mejores prácticas de profesionales que se ajustan a cada componente.
1. Gestión de datos
1.1 fuentes de datos
- El aprendizaje profundo supervisado requiere muchos datos etiquetados
- ¡Etiquetar datos propios es costoso!
- Aquí hay algunos recursos para datos:
- Datos de código abierto (bueno para comenzar, pero no una ventaja)
- Aumento de datos (imprescindible para la visión por computadora, una opción para NLP)
- Datos sintéticos (casi siempre vale la pena comenzar con, especialmente en PNL)
1.2 Etiquetado de datos
- Requiere: pila de software separada (plataformas de etiquetado), mano de obra temporal y QC
- Fuentes de trabajo para el etiquetado:
- Crowdsourcing (Mechanical Turk): barato y escalable, menos confiable, necesita QC
- Contratación de anotadores propios: menos control de calidad, costoso, lento a escala
- Compañías de servicios de etiquetado de datos:
- Plataformas de etiquetado:
- Diffgram: software de datos de capacitación (visión por computadora)
- Prodigy: una herramienta de anotación alimentada por el aprendizaje activo (por desarrolladores de Spacy), texto e imagen
- Hive: AI como plataforma de servicio para la visión por computadora
- Supervisamente: plataforma completa de visión por computadora
- Labelbox: visión por computadora
- Plataforma de datos de IA de escala (Visión de Computadora y PNL)
1.3. Almacenamiento de datos
- Opciones de almacenamiento de datos:
- Tienda de objetos : almacenar datos binarios (imágenes, archivos de sonido, textos comprimidos)
- Amazon S3
- Tienda de objetos Ceph
- Base de datos : Metadatos de almacenamiento (rutas de archivo, etiquetas, actividad del usuario, etc.).
- Postgres es la opción correcta para la mayoría de las aplicaciones, con el mejor SQL de su clase y un gran soporte para JSON no estructurado.
- Data Lake : para agregar características que no se pueden obtener de la base de datos (por ejemplo, registros)
- Tienda de características : almacenar, acceder y compartir características de aprendizaje automático (la extracción de características podría ser computacionalmente costosa y casi imposible de escalar, por lo tanto, la reutilización de diferentes modelos y equipos es clave para los equipos de ML de alto rendimiento).
- Fiesta (Google Cloud, código abierto)
- Paleta Michelangelo (Uber)
- Sugerencia: en el tiempo de capacitación, copie los datos en un sistema de archivos local o en red (NFS). 1
1.4. Versión de datos
- Es un "imprescindible" para los modelos ML implementados:
Los modelos ML implementados son código de pieza, datos de pieza . 1 Sin versiones de datos significa que no hay versiones de modelo. - Plataformas de versiones de datos:
- DVC: sistema de control de versiones de código abierto para proyectos de ML
- Pachyderm: Control de versiones para datos
- Dolt: una base de datos SQL con control de versiones tipo GIT para datos y esquema
1.5. Proceso de datos
- Los datos de capacitación para modelos de producción pueden provenir de diferentes fuentes, incluidos los datos almacenados en DB y tiendas de objetos , procesamiento de registros y salidas de otros clasificadores .
- Hay dependencias entre las tareas, cada una debe ser expulsada después de que sus dependencias estén terminadas. Por ejemplo, la capacitación en nuevos datos de registro requiere un paso de preprocesamiento antes del entrenamiento.
- Los makfiles no son escalables. El "gerente de flujo de trabajo" se vuelve bastante esencial a este respecto.
- Orquestación de flujo de trabajo:
- Luigi de Spotify
- Flujo de aire por airbnb: dinámico, extensible, elegante y escalable (el más utilizado)
- Flujo de trabajo DAG
- Ejecución condicional robusta: Vuelva a intentarlo en caso de falla
- Pusher admite imágenes de Docker con TensorFlow Serving
- Flujo de trabajo completo en un solo archivo .py
2. Desarrollo, capacitación y evaluación
2.1. Ingeniería de software
- Idioma ganador: Python
- Editores:
- Empuje
- Emacs
- VS Código (recomendado por el autor): puesta en escena de git incorporada y diff, código de pelusa, proyectos abiertos de forma remota a través de SSH
- Cuadernos: excelente como punto de partida de los proyectos, difícil de escalar (Dato divertido: la arquitectura basada en cuadernos de Netflix es una excepción, que se basa completamente en las suites NTERACT).
- NTERACT: una interfaz de usuario basada en React de próxima generación para los cuadernos Jupyter
- Papermill: es una biblioteca NTERACT creada para parametrizar , ejecutar y analizar cuadernos Jupyter.
- Commuter: otro proyecto NTERACT que proporciona una pantalla de solo lectura de cuadernos (por ejemplo, de cubos S3).
- Streamlit: herramienta de ciencia de datos interactiva con applets
- Calculación de las recomendaciones 1 :
- Para individuos o nuevas empresas :
- Desarrollo: una PC 4X Turing-Architecture
- Capacitación/Evaluación: use la misma PC GPU 4x. Al ejecutar muchos experimentos, compre servidores compartidos o use instancias en la nube.
- Para las grandes empresas:
- Desarrollo: Compre una PC 4x Turing-Architecture por científico ML o permítales usar instancias V100
- Capacitación/Evaluación: use instancias en la nube con el aprovisionamiento y el manejo adecuados de las fallas
- Proveedores de nubes:
- GCP: opción para conectar GPU a cualquier instancia + tiene TPUS
- AWS:
2.2. Gestión de recursos
- Asignar recursos gratuitos a los programas
- Opciones de gestión de recursos:
- Programador de trabajo de clúster de la vieja escuela (por ejemplo, gerente de carga de trabajo de Slurm)
- Docker + Kubernetes
- Kubeflow
- Polyaxon (características pagas)
2.3. Marcos DL
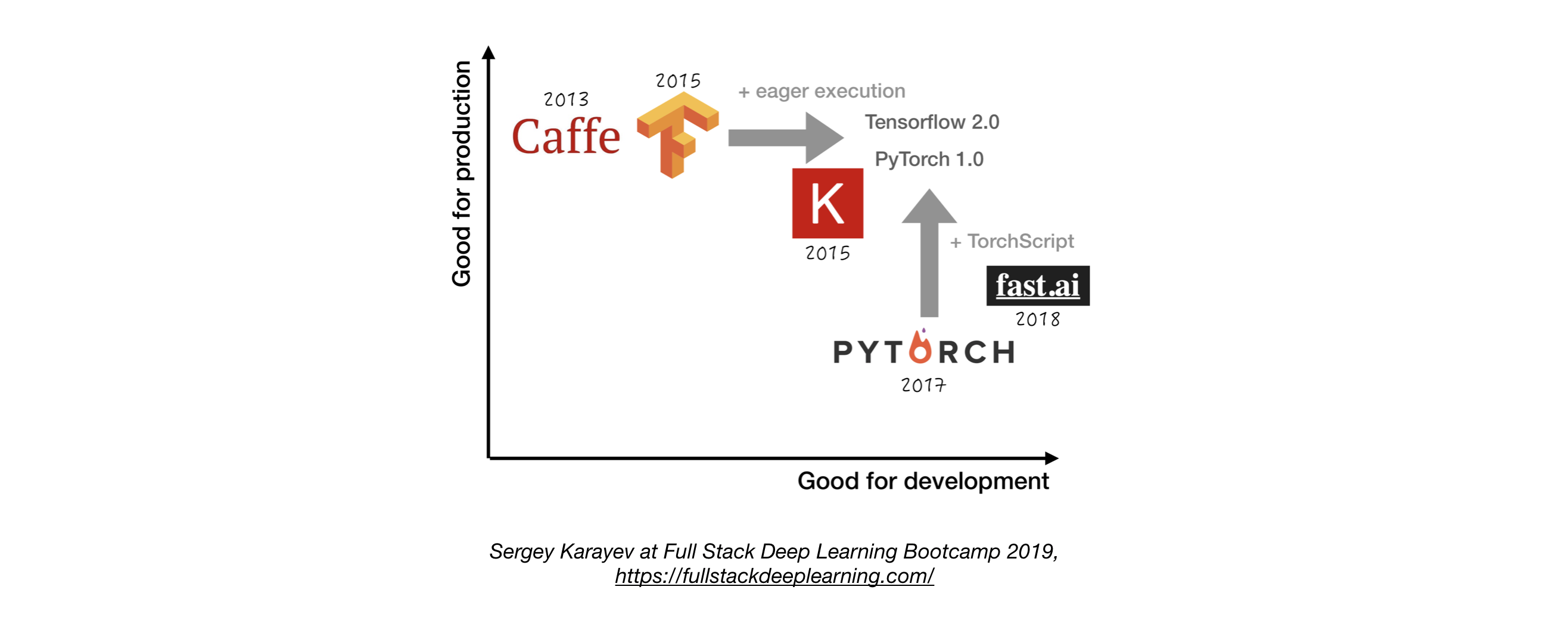
- A menos que tenga una buena razón para no hacerlo, use TensorFlow/Keras o Pytorch. 1
- La siguiente figura muestra una comparación entre diferentes marcos sobre cómo representan el "desarrollo" y la "producción" .
2.4. Gestión de experimentos
- Estrategia de desarrollo, capacitación y evaluación:
- Siempre empieza simple
- Entrena un modelo pequeño en un pequeño lote. ¡Solo si funciona, escala a datos y modelos más grandes, y ajuste de hiperparámetro!
- Herramientas de gestión de experimentos:
- Tabla tensor
- Proporciona la visualización y las herramientas necesarias para la experimentación de ML
- Frases (monitoreo para ML)
- Comet: le permite rastrear el código, los experimentos y los resultados en los proyectos de ML
- Pesos y prejuicios: registre y visualice cada detalle de su investigación con una colaboración fácil
- Seguimiento de mlflow: para parámetros de registro, versiones de código, métricas y archivos de salida, así como visualización de los resultados.
- Seguimiento automático de experimentos con una línea de código en Python
- Comparación lado a lado de experimentos
- Ajuste de hiper parámetros
- Admite trabajos basados en Kubernetes
2.5. Ajuste de hiperparameter
Aproches:
- Búsqueda de redes
- Búsqueda aleatoria
- Optimización bayesiana
- Hyperband y algoritmo de mitad de mitades sucesivo asincrónico (ASHA)
- Capacitación basada en la población
Plataformas:
- Raytune: Ray Tune es una biblioteca de Python para la sintonización de hiperparameter a cualquier escala (con un enfoque en el aprendizaje profundo y el aprendizaje de refuerzo profundo). Admite cualquier marco de aprendizaje automático, incluidos Pytorch, XGBOost, MXNET y Keras.
- Katib: el sistema nativo de Kubernete para el ajuste de hiperparameter y la búsqueda de arquitectura neuronal, inspirado en [Google Vizier] (https://static.googleusercontent.com/media/ investigador.google.com/ja//pubs/archive/ bcb15507f4b52991a0783013df4222240e9423813812382382382382 y admite múltiples marcos ML/DL (por ejemplo, TensorFlow, MXNet y Pytorch).
- Hyperas: un envoltorio simple alrededor de Hypperopt para Keras, con una simple notación de plantilla para definir rangos de hiperparaméter para sintonizar.
- Sigopt: una plataforma de optimización de grado empresarial escalable
- Barras de [Peso y Biste] (https://www.wandb.com/): los parámetros no son especificados explícitamente por un desarrollador. En cambio, son aproximados y aprendidos por un modelo de aprendizaje automático.
- Keras Tuner: un sintonizador de hiperparameter para Keras, específicamente para TF.keras con TensorFlow 2.0.
2.6. Capacitación distribuida
- Paralelismo de datos: úselo cuando el tiempo de iteración sea demasiado largo (soporte de tensorflow y pytorch)
- Capacitación distribuida de rayos
- Paralelismo del modelo: cuando el modelo no encaja en una sola GPU
- Otras soluciones:
3. Solución de problemas [TBD]
4. Pruebas e implementación
4.1. Pruebas y CI/CD
El software de producción de aprendizaje automático requiere un conjunto más diverso de suites de prueba que el software tradicional:
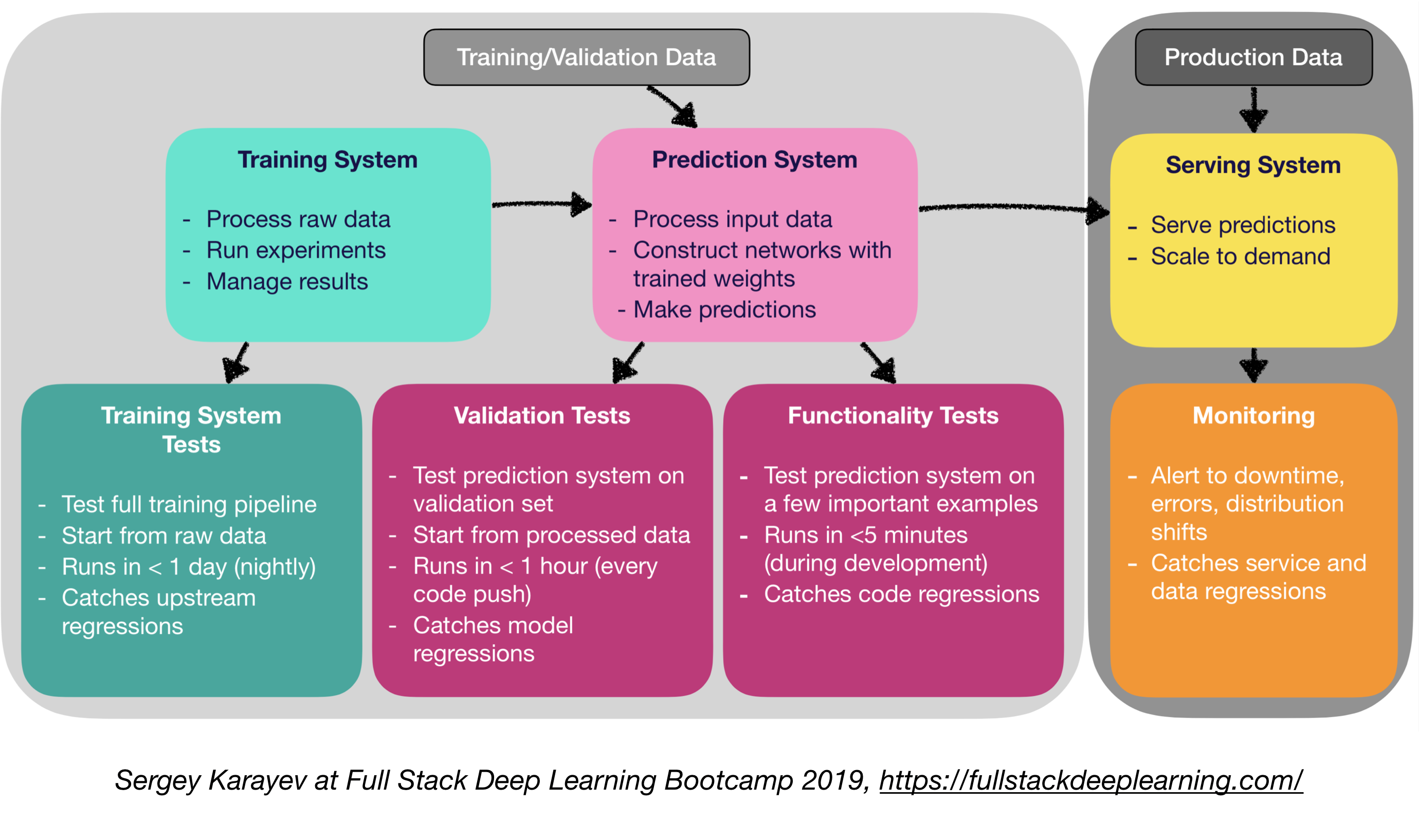
- Unidad e prueba de integración:
- Tipos de pruebas:
- Pruebas del sistema de capacitación: Probar la tubería de entrenamiento
- Pruebas de validación: Sistema de predicción de pruebas en el conjunto de validación
- Pruebas de funcionalidad: Sistema de predicción de pruebas en algunos ejemplos importantes
- Integración continua: ejecutar pruebas después de cada nuevo cambio de código presionado al repositorio
- SaaS para integración continua:
- ARGO: motor de trabajo nativo de código abierto Kubernetes para orquestar trabajos paralelos (incudios de flujos de trabajo, eventos, CI y CD).
- Circleci: soporte de lenguaje incluido, entornos personalizados, asignación de recursos flexibles, utilizada por Instacart, Lyft y Stackshare.
- Travis CI
- Buildkite: construcciones rápidas y estables, el agente de código abierto se ejecuta en casi cualquier máquina y arquitectura, libertad para usar sus propias herramientas y servicios
- Jenkins: sistema de construcción de la vieja escuela
4.2. Implementación web
- Consiste en un sistema de predicción y un sistema de servicio
- Sistema de predicción: datos de entrada de proceso, hacer predicciones
- Sistema de servicio (servidor web):
- Servir la predicción con la escala en mente
- Use la API REST para atender las solicitudes de predicción HTTP
- Llama al sistema de predicción para responder
- Opciones de servicio:
- Desplegar en máquinas virtuales, escala agregando instancias
- Desplegar como contenedores, escala a través de la orquestación
- Contenedores
- Orquestación de contenedores:
- Kubernetes (el más popular ahora)
- Mesos
- Maratón
- Implementar código como una "función sin servidor"
- Desplegar a través de una solución de servicio modelo
- Modelo de servicio:
- Implementación web especializada para modelos ML
- Solicitud de lotes de inferencia de GPU
- Marcos:
- TensorFlow Serving
- Servidor de modelos mxnet
- Clipper (Berkeley)
- SOAS SOLUCIONES
- Seldon: Servir y escalar modelos construidos en cualquier marco en Kubernetes
- Algoritmia
- Toma de decisiones: ¿CPU o GPU?
- Inferencia de la CPU:
- La inferencia de la CPU es preferible si cumple con los requisitos.
- Escala agregando más servidores o sin servidor.
- Inferencia de GPU:
- TF Sirving o Clipper
- El lote adaptativo es útil
- (Bonificación) Implementación de cuadernos Jupyter:
- ¡Kubeflow Fawing es un paquete de implementación híbrido que le permite implementar sus códigos de cuaderno Jupyter !
4.5 Mala de servicio y enrutamiento de tráfico
- La transición de aplicaciones monolíticas hacia una arquitectura de microservicio distribuido podría ser un desafío.
- Una malla de servicio (que consiste en una red de microservicios) reduce la complejidad de tales implementaciones y alivia la tensión en los equipos de desarrollo.
- ISTIO: una malla de servicio para aliviar la creación de una red de servicios implementados con equilibrio de carga, autenticación de servicio a servicio, monitoreo, con pocos o ningún cambio de código en el código de servicio.
4.4. Escucha:
- Propósito del monitoreo:
- Alertas de tiempo de inactividad, errores y cambios de distribución
- Captura de regresiones de servicio y datos
- Las soluciones de proveedores de nubes son decentes
- Kiali: una consola de observabilidad para ISTIO con capacidades de configuración de malla de servicio. Responde a estas preguntas: ¿Cómo se conectan los microservicios? ¿Cómo están funcionando?
¿Hemos terminado?

4.5. Implementación de dispositivos integrados y móviles
- Desafío principal: Restricciones de huella de memoria y cómputo
- Soluciones:
- Cuantificación
- Tamaño de modelo reducido
- Destilación de conocimiento
- Marcos integrados y móviles:
- Tensorflow lite
- Pytorch Mobile
- ML de núcleo
- Kit ml
- Fritz
- Abierto
- Conversión del modelo:
- Intercambio de red neuronal abierto (ONNX): formato de código abierto para modelos de aprendizaje profundo
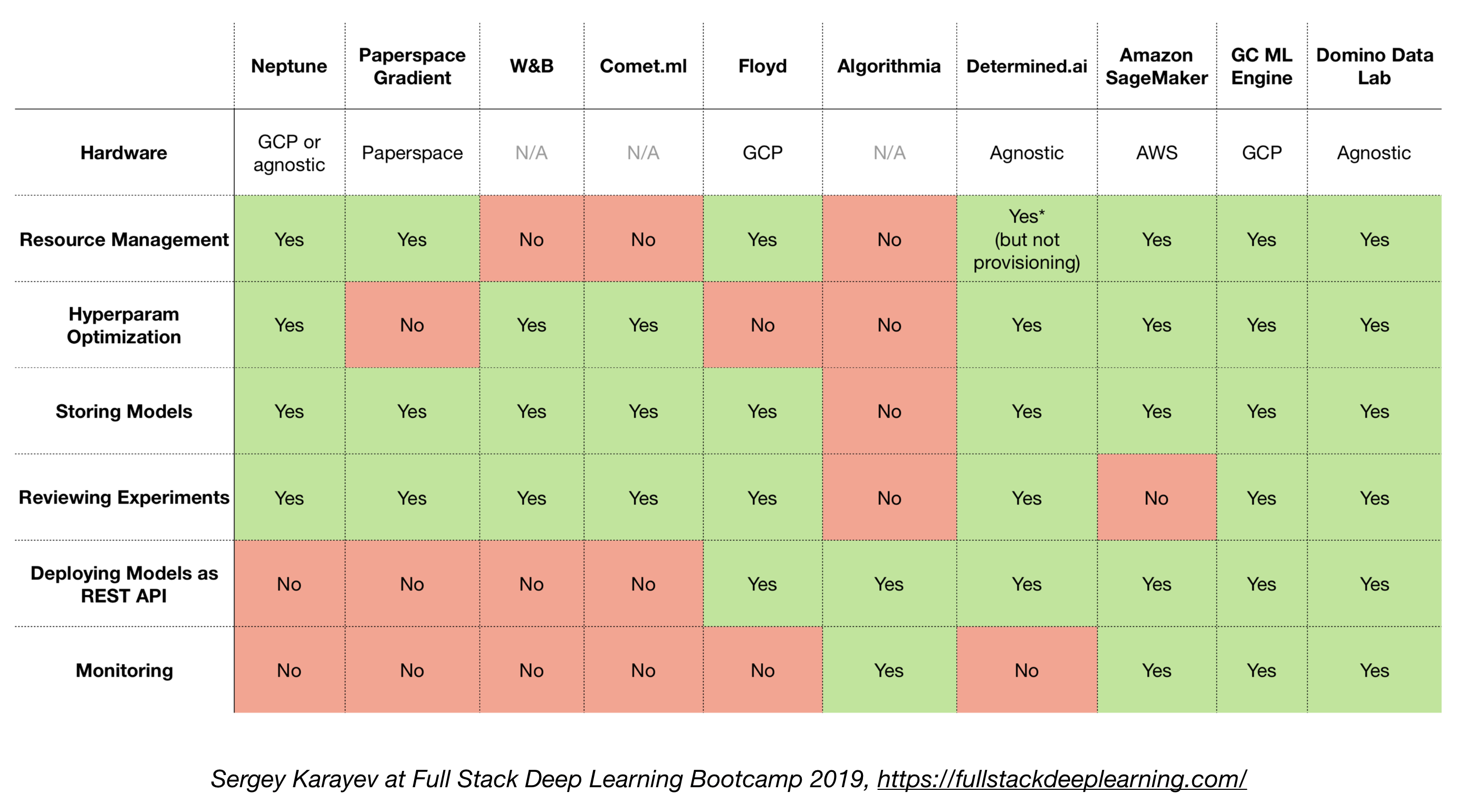
4.6. Soluciones todo en uno
- TensorFlow extendido (TFX)
- Michelangelo (Uber)
- Plataforma de AI de Google Cloud
- Amazon Sagemaker
- Neptuno
- Floy
- Espacio de papel
- AI determinada
- Laboratorio de datos de dominó
TensorFlow extendido (TFX)
[TBD]
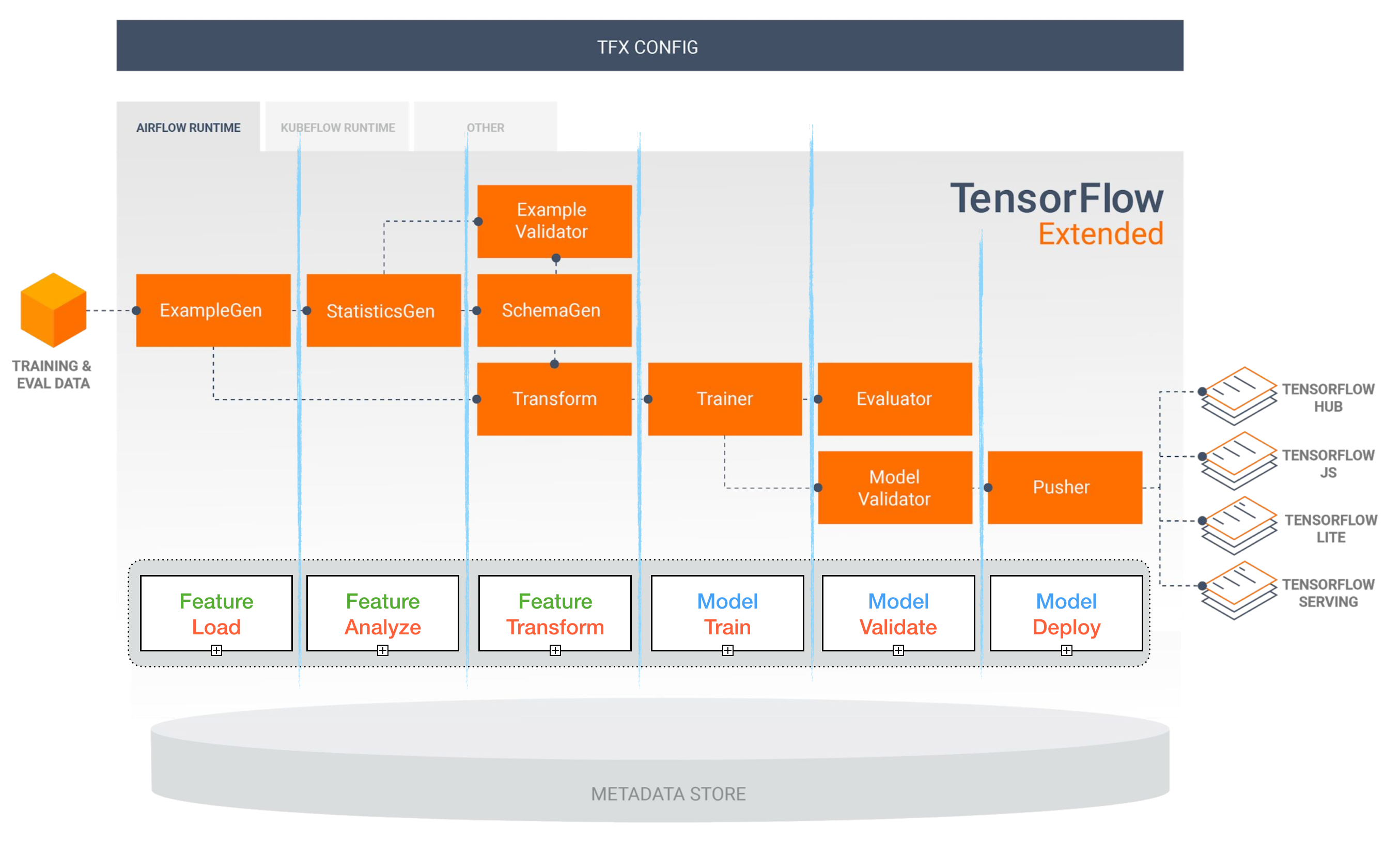
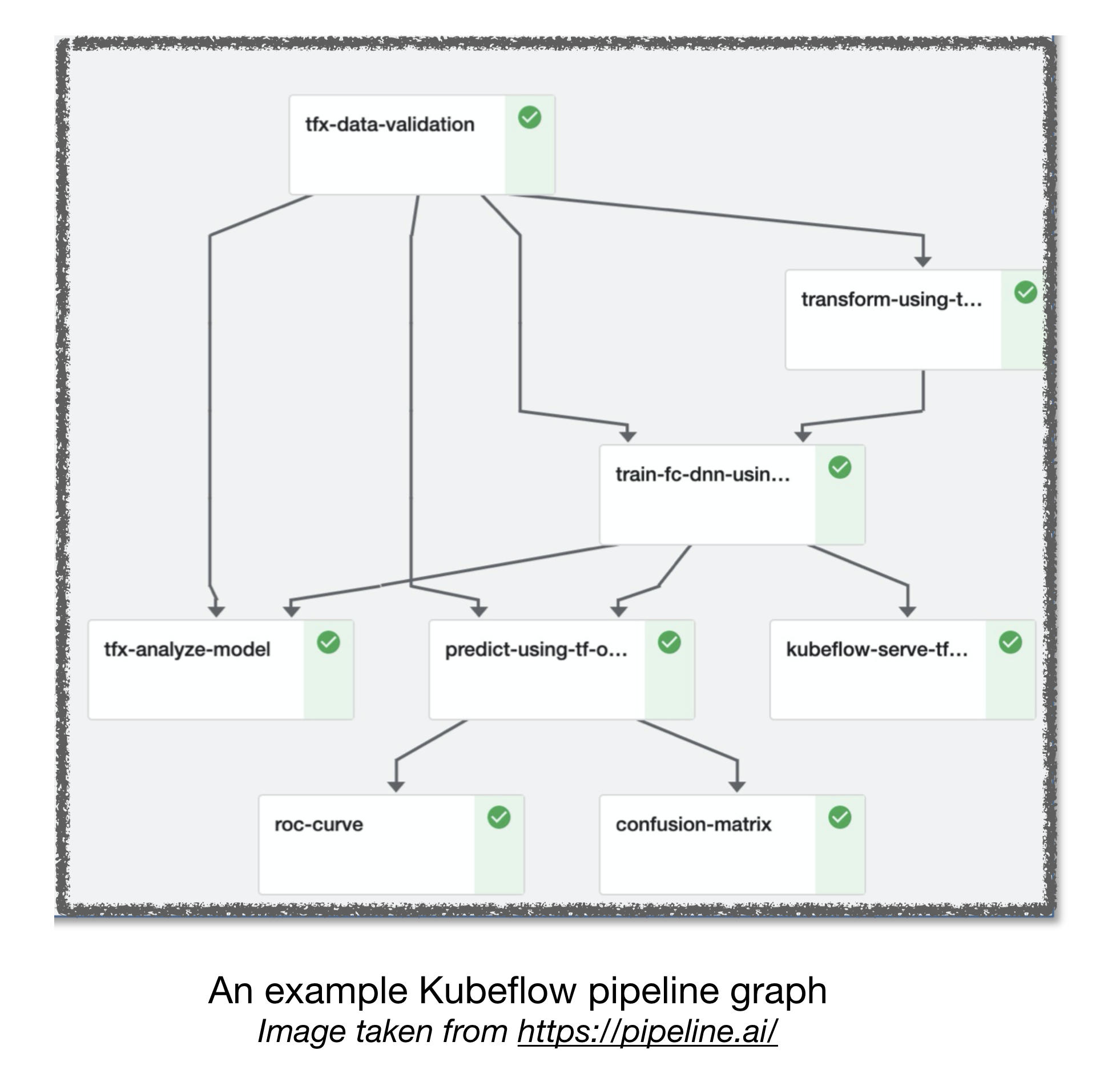
Tuberías de flujo de aire y kubeflow ml
[TBD]
Otros enlaces útiles:
- Lecciones aprendidas de la construcción de sistemas prácticos de aprendizaje profundo
- Aprendizaje automático: la tarjeta de crédito de alto interés de la deuda técnica
Que contribuye
Referencias:
[1]: Full Stack Deep Learning Bootcamp, noviembre de 2019.
[2]: Taller de Kubeflow avanzado por Pipeline.ai, 2019.
[3]: TFX: Real World Machine Learning in Production


