llama dfdx
1.0.0
Этот репо содержит популярную языковую модель Llama 7b, полностью реализованную на языке программирования Rust!
Использует тензоры DFDX и ускорение CUDA.
Это работает непосредственно в F16, что означает, что на процессоре нет аппаратного ускорения. Использование CUDA широко рекомендуется.
Вот модель 7B, работающая на графическом процессоре A10:
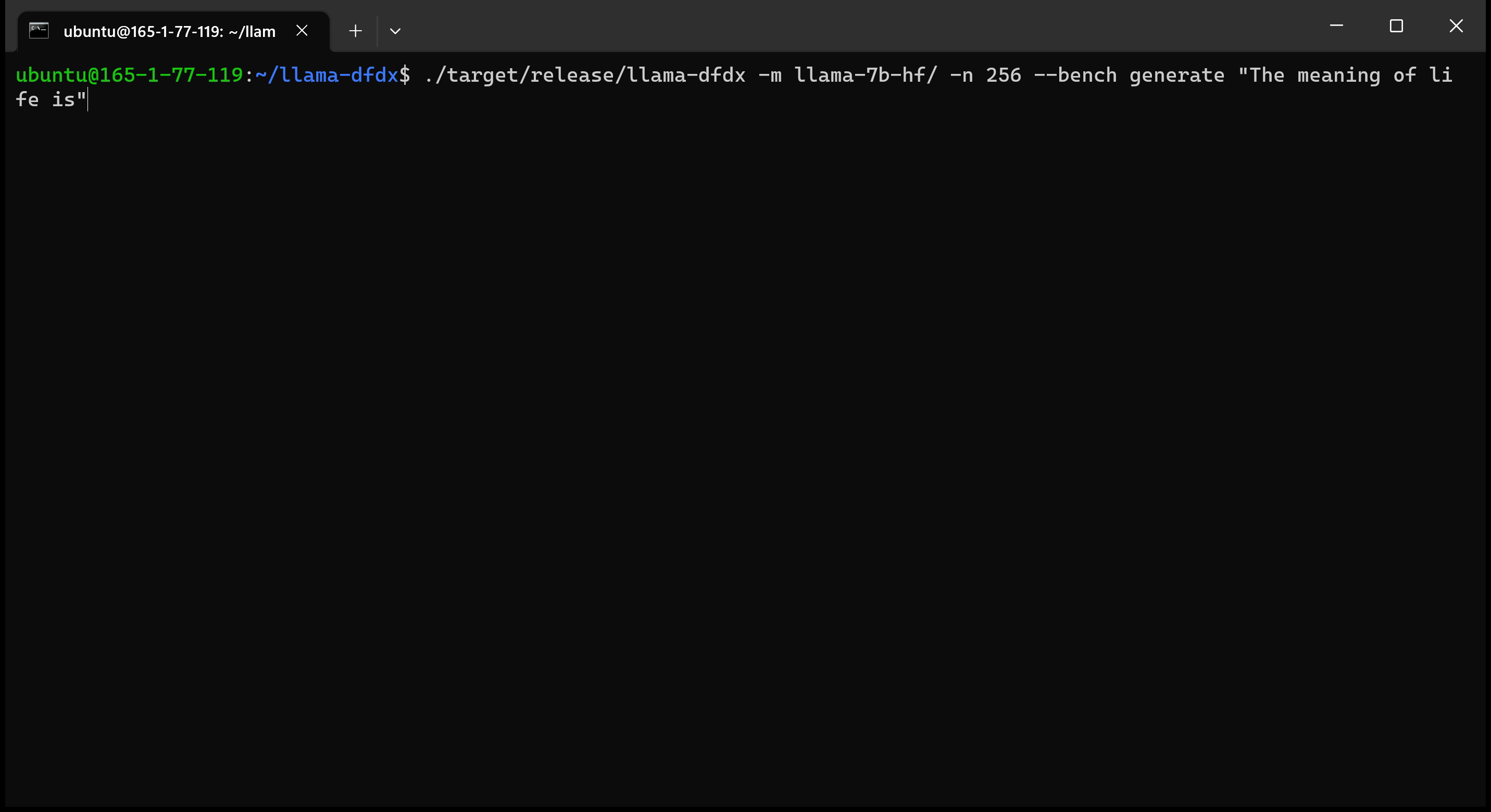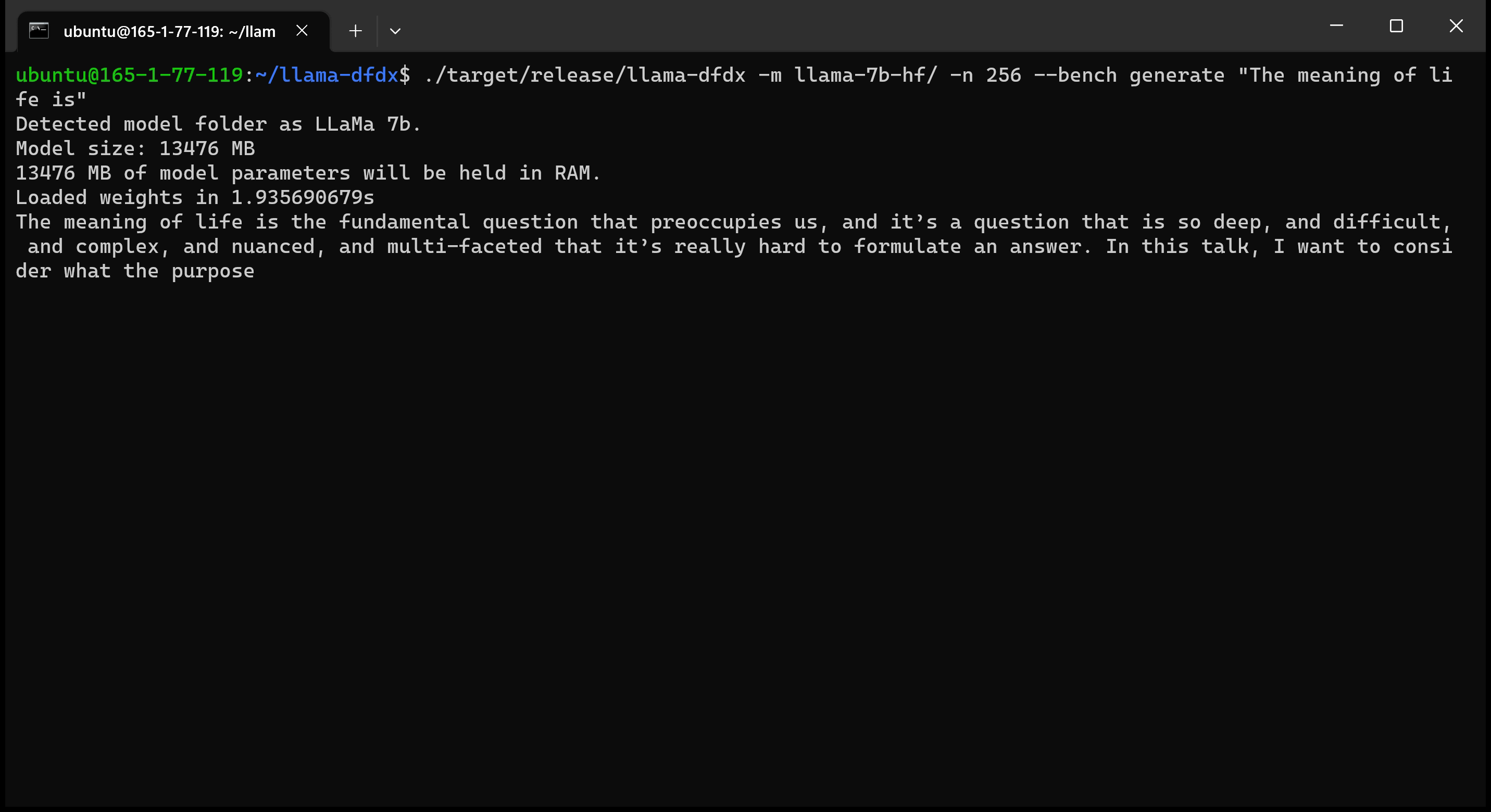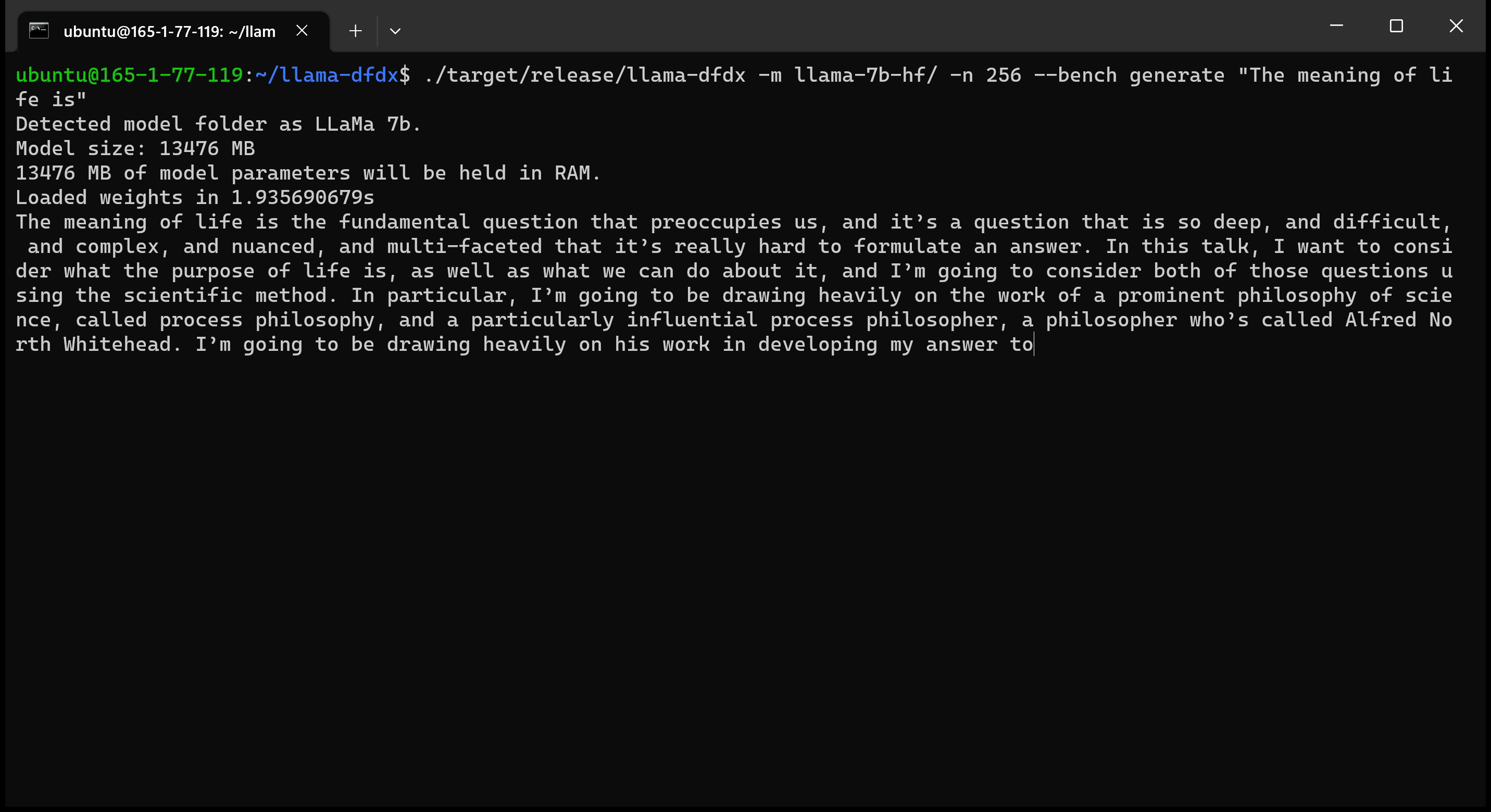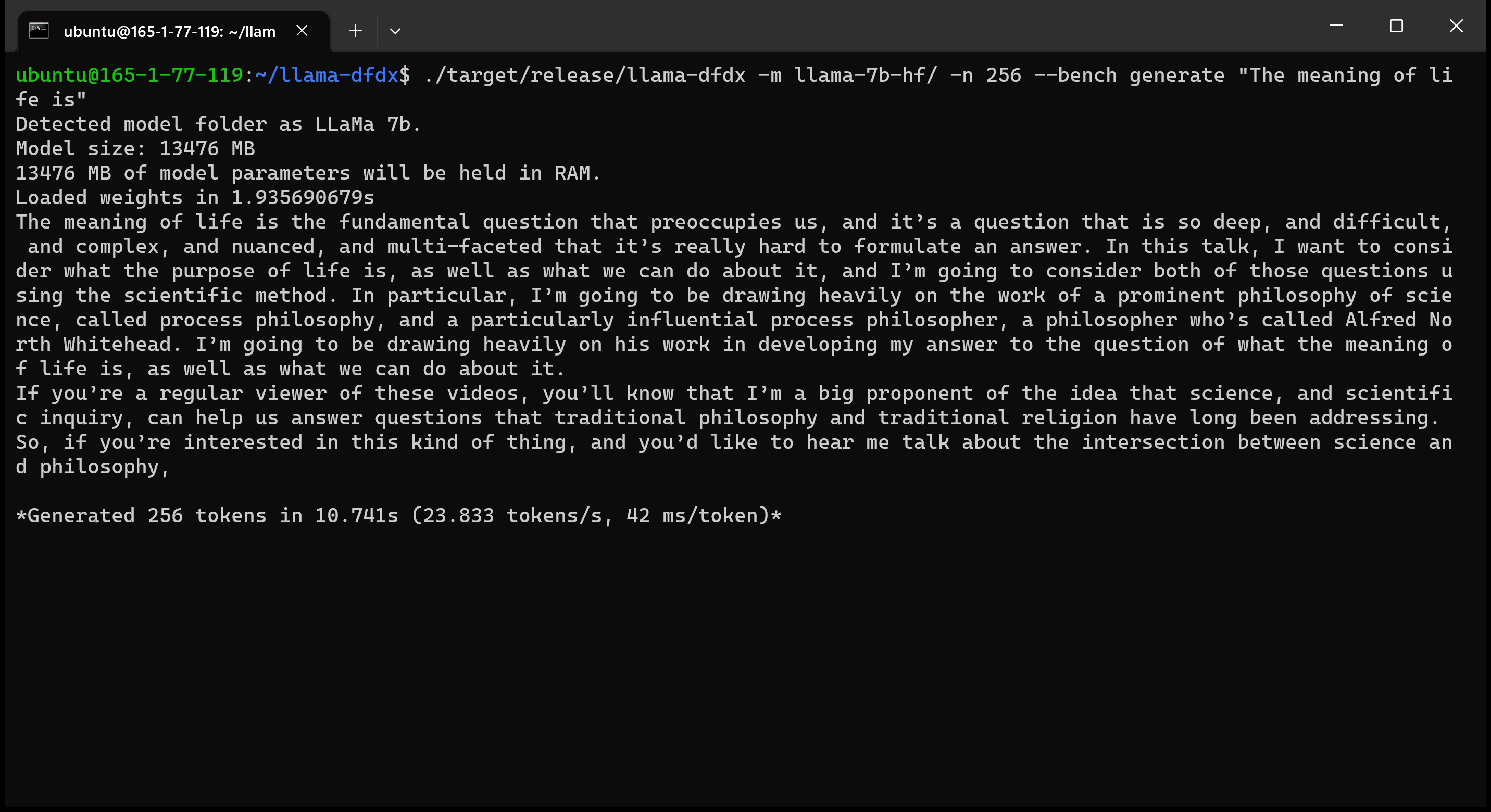
sudo apt install git-lfsgit lfs install .git clone https://huggingface.co/decapoda-research/llama-7b-hfgit clone https://huggingface.co/decapoda-research/llama-13b-hfgit clone https://huggingface.co/decapoda-research/llama-65b-hfpython3.x -m venv <my_env_name> создать виртуальную среду Python, где x является вашей предпочтительной версией Pythonsource <my_env_name>binactivate (или <my_env_name>Scriptsactivate если в Windows), чтобы активировать средуpip install numpy torchpython convert.py , чтобы преобразовать веса модели в ржавчину понятный формат: a. Llama 7b: python convert.py b. Llama 13b: python convert.py llama-13b-hf c. Llama 65b: python convert.py llama-65b-hf Вы можете компилировать с обычными командами ржавчины:
С Cuda:
cargo build --release -F cudaБез cuda:
cargo build --releaseС ARGS по умолчанию:
./target/release/llama-dfdx --model < model-dir > generate " <prompt> "
./target/release/llama-dfdx --model < model-dir > chat
./target/release/llama-dfdx --model < model-dir > file < path to prompt file >Чтобы увидеть, какие команды/пользовательские аргументы вы можете использовать:
./target/release/llama-dfdx --help

