llama dfdx
1.0.0
Ce repo contient le modèle de langue LLAMA 7B populaire, pleinement implémenté dans le langage de programmation Rust!
Utilise des tenseurs DFDX et une accélération CUDA.
Cela fonctionne directement dans F16, ce qui signifie qu'il n'y a pas d'accélération matérielle sur le CPU. L'utilisation de CUDA est fortement recommandée.
Voici le modèle 7B fonctionnant sur un GPU A10:
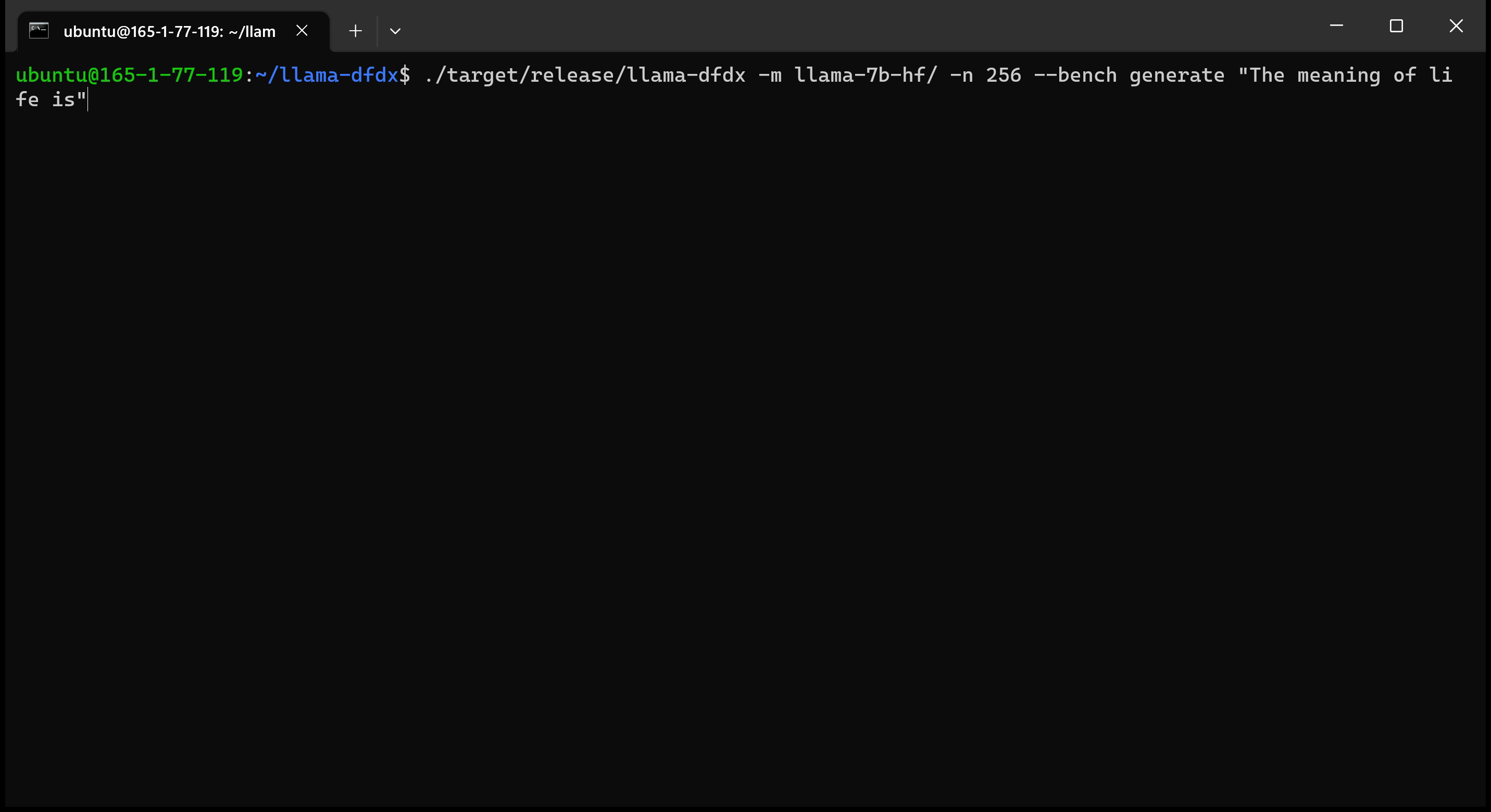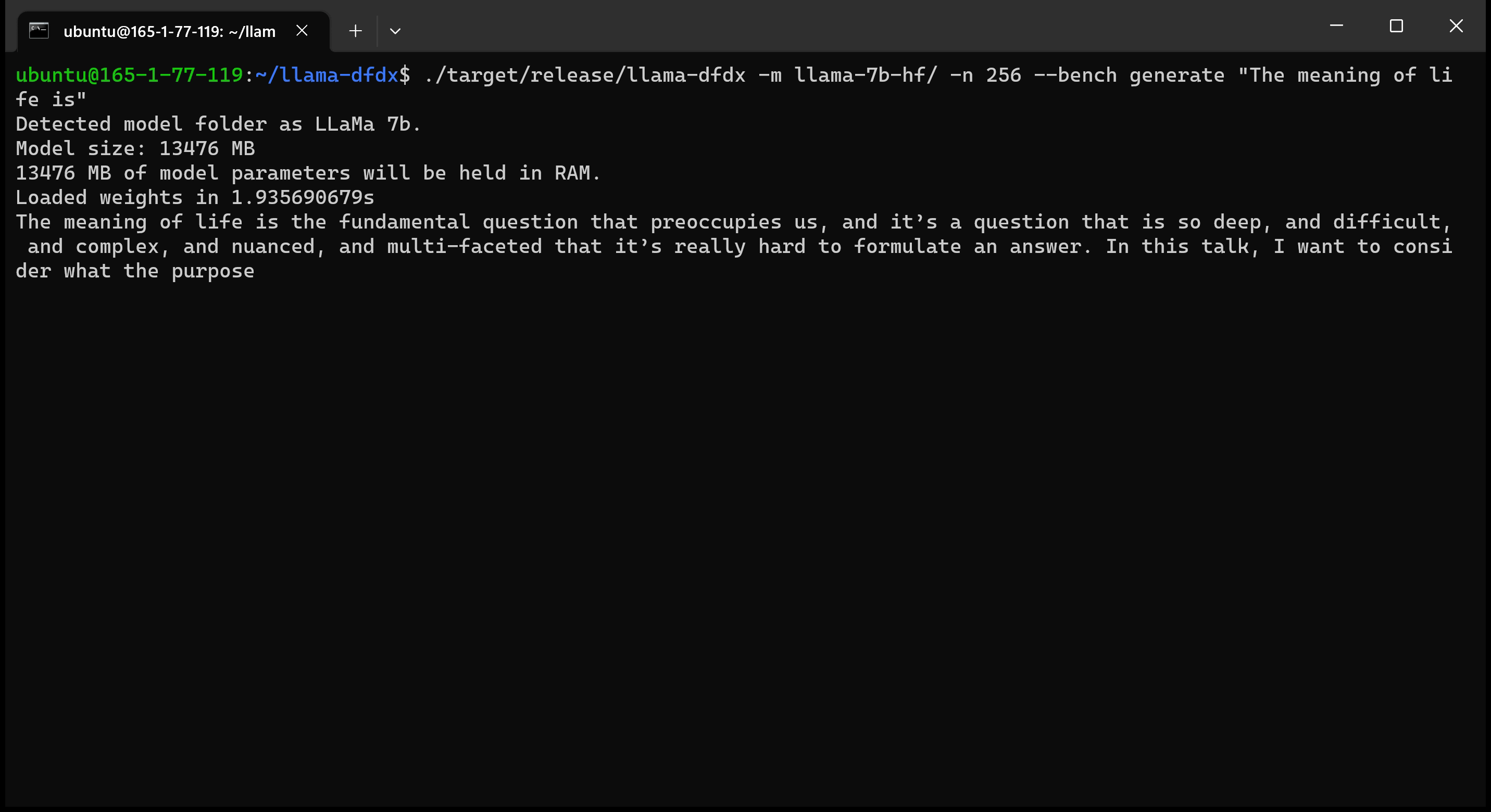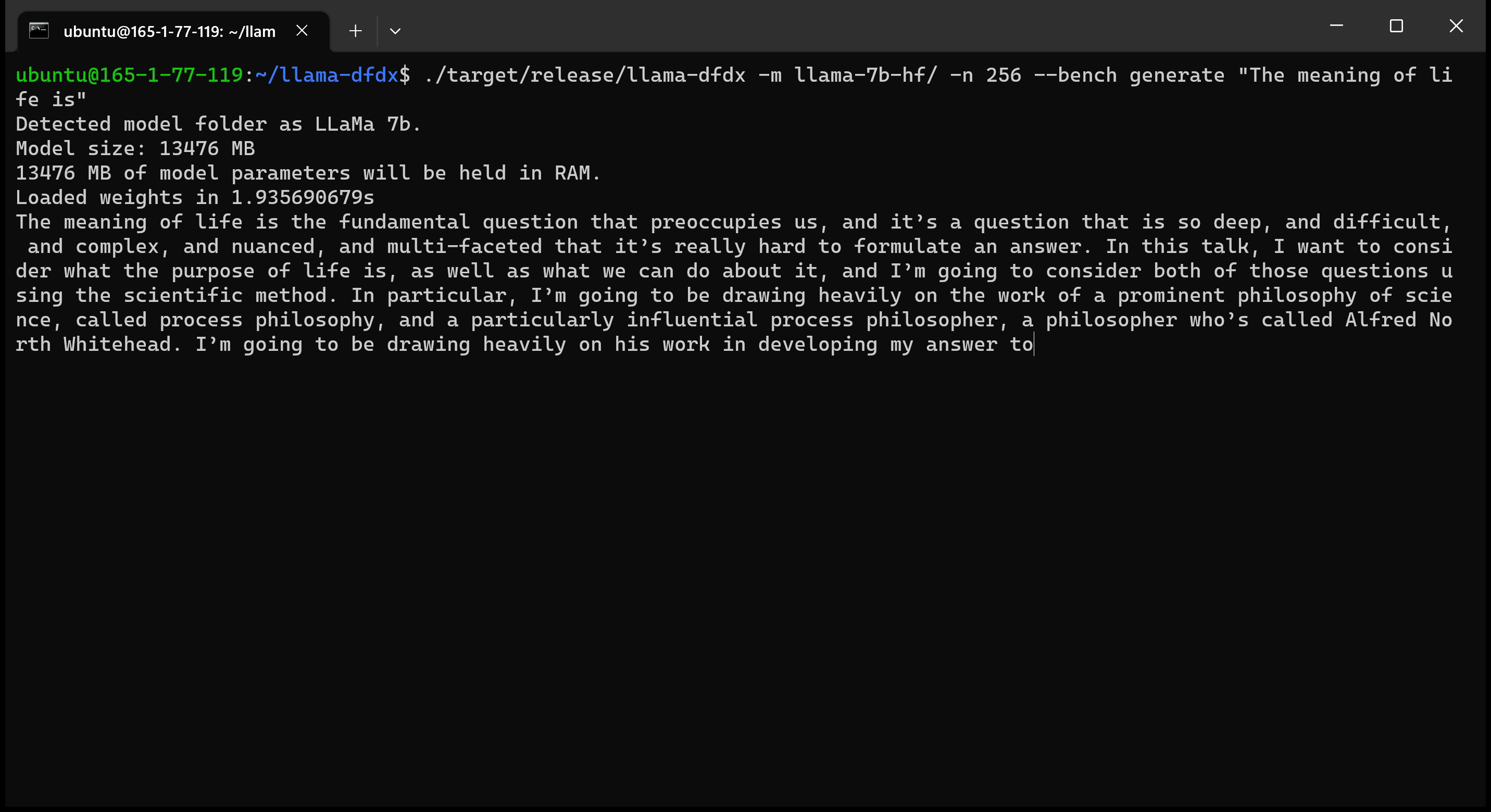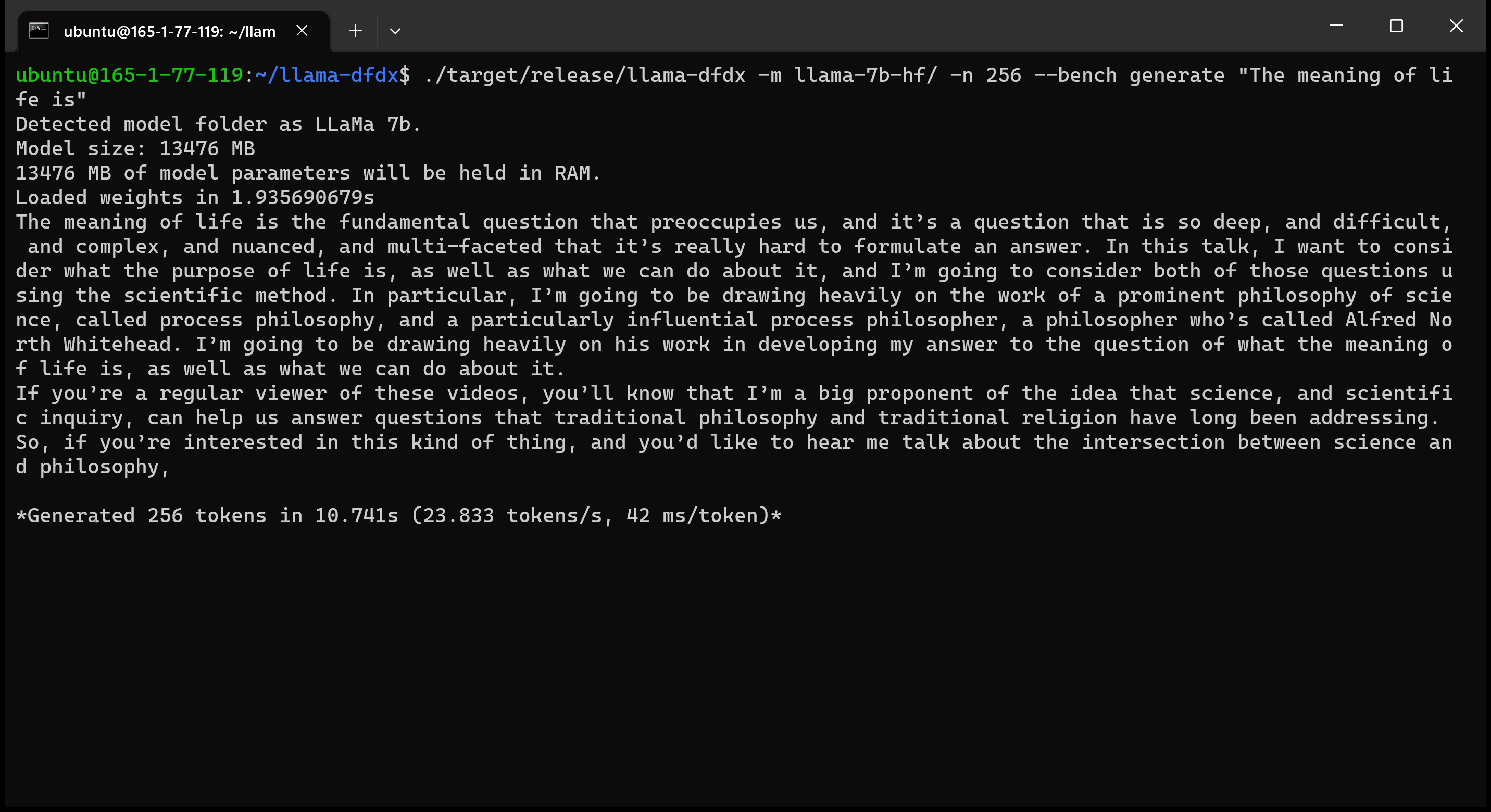
sudo apt install git-lfsgit lfs install .git clone https://huggingface.co/decapoda-research/llama-7b-hfgit clone https://huggingface.co/decapoda-research/llama-13b-hfgit clone https://huggingface.co/decapoda-research/llama-65b-hfpython3.x -m venv <my_env_name> pour créer un environnement virtuel Python, où x est votre version Python préféréesource <my_env_name>binactivate (ou <my_env_name>Scriptsactivate si sous Windows) pour activer l'environnementpip install numpy torchpython convert.py pour convertir les poids du modèle en Rust Format compréhensible: a. Lama 7b: python convert.py b. LLAMA 13B: python convert.py llama-13b-hf c. Lama 65b: python convert.py llama-65b-hf Vous pouvez compiler avec des commandes de rouille normales:
Avec Cuda:
cargo build --release -F cudaSans Cuda:
cargo build --releaseAvec des args par défaut:
./target/release/llama-dfdx --model < model-dir > generate " <prompt> "
./target/release/llama-dfdx --model < model-dir > chat
./target/release/llama-dfdx --model < model-dir > file < path to prompt file >Pour voir quelles commandes / args personnalisés vous pouvez utiliser:
./target/release/llama-dfdx --help

