llama dfdx
1.0.0
¡Este repositorio contiene el popular modelo de lenguaje LLAMA 7B, totalmente implementado en el lenguaje de programación de óxido!
Utiliza tensores DFDX y aceleración CUDA.
Esto se ejecuta directamente en F16, lo que significa que no hay aceleración de hardware en la CPU. El uso de CUDA es muy recomendable.
Aquí está el modelo 7B que se ejecuta en una GPU A10:
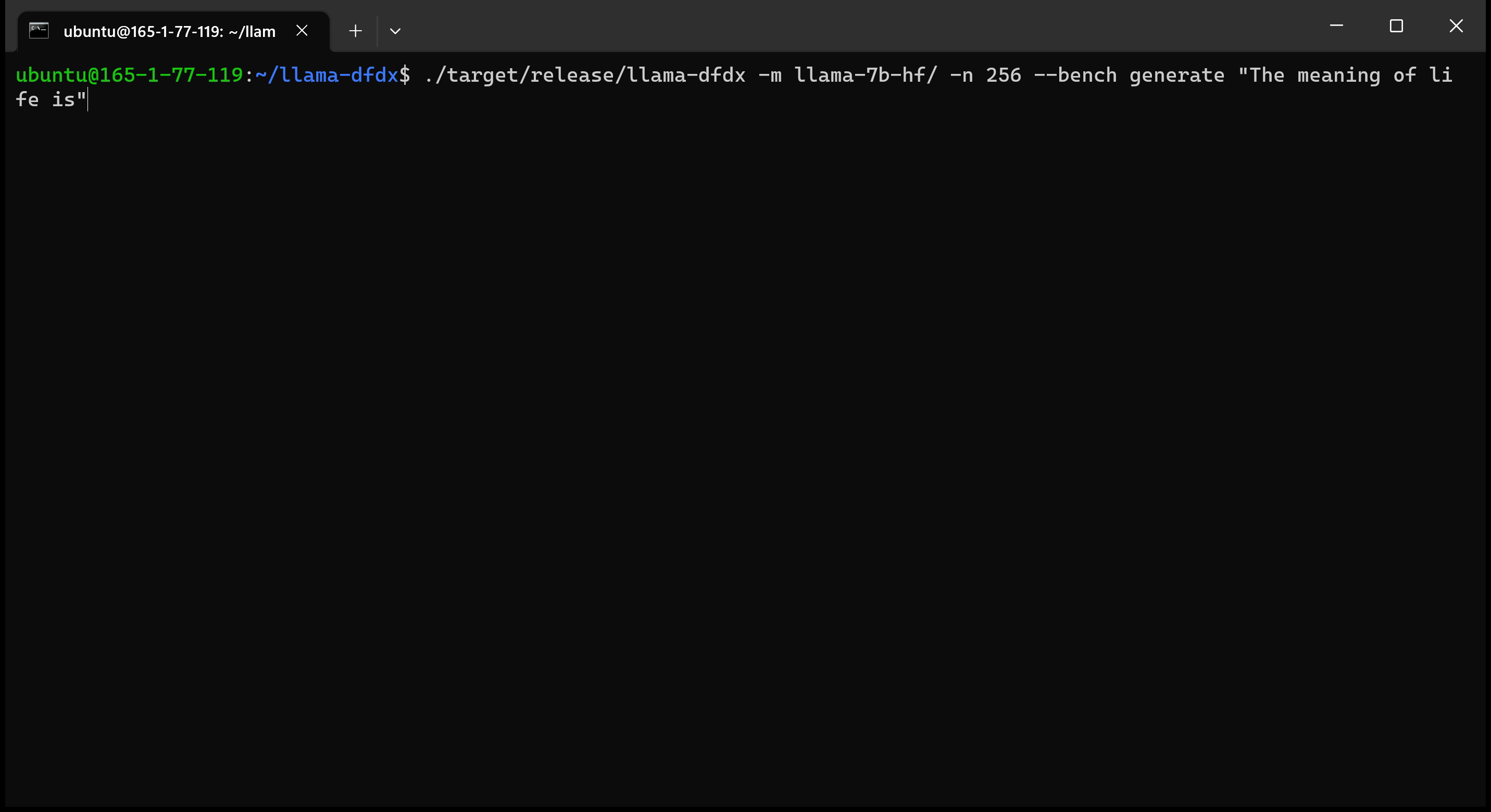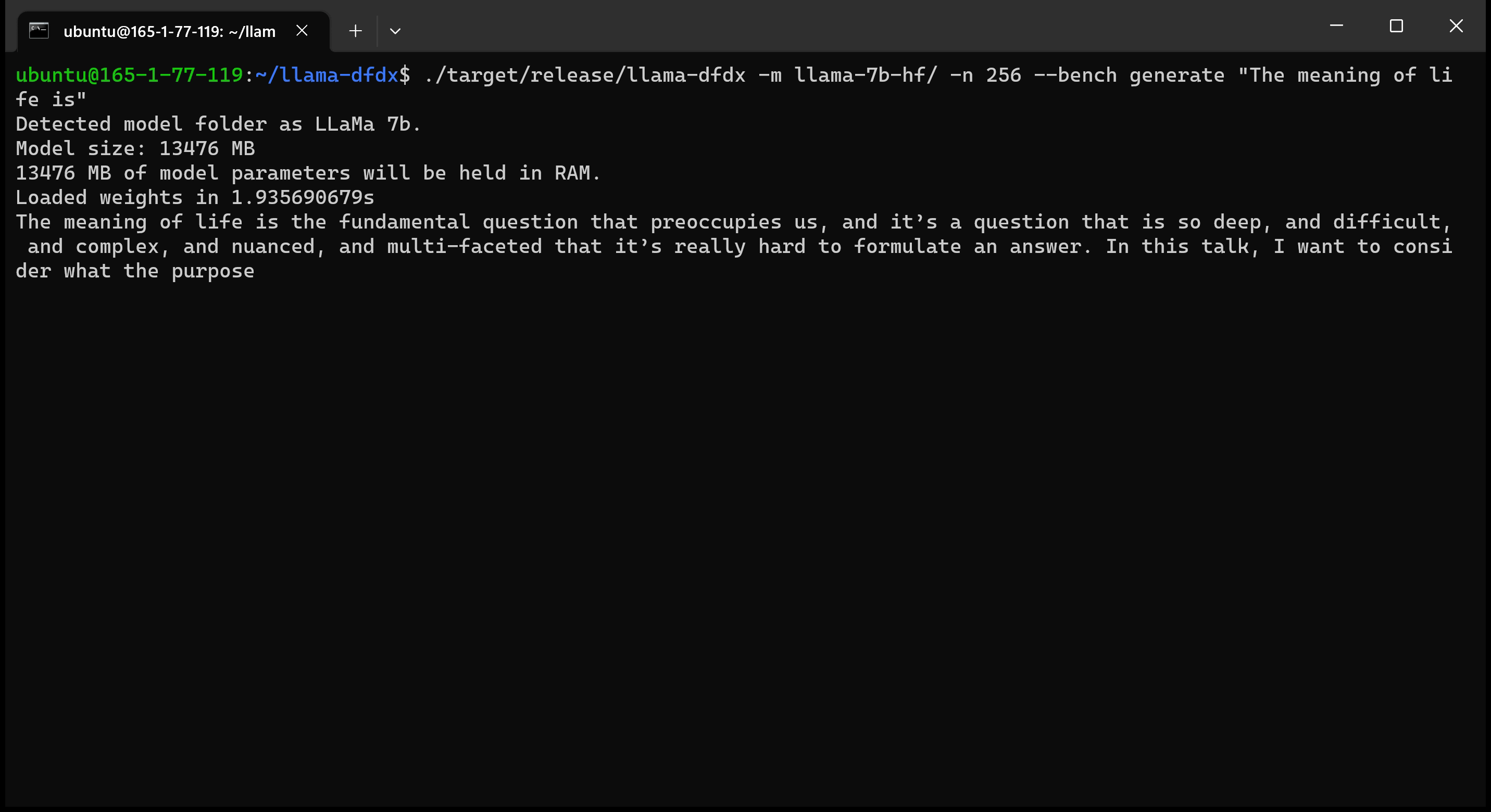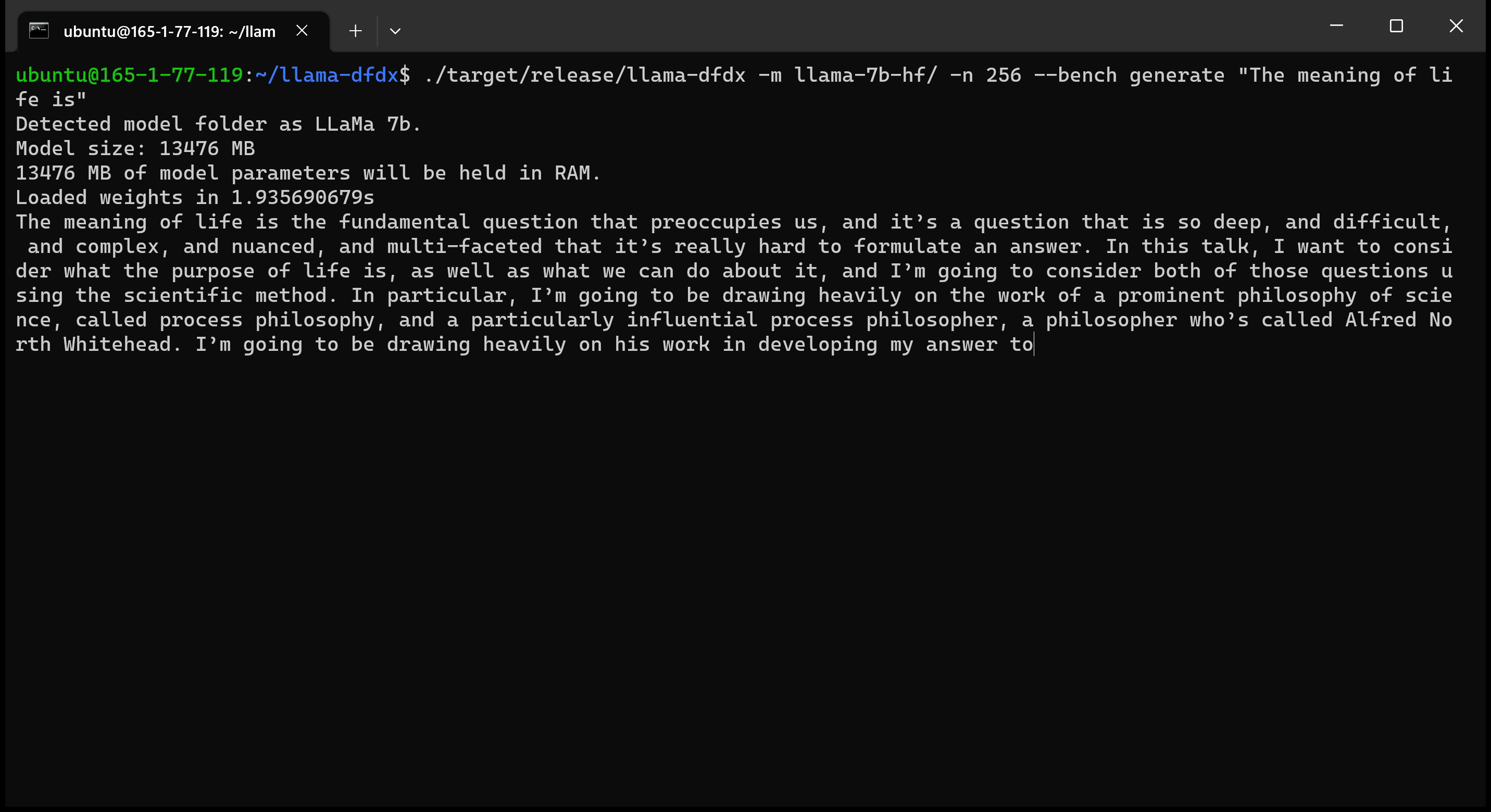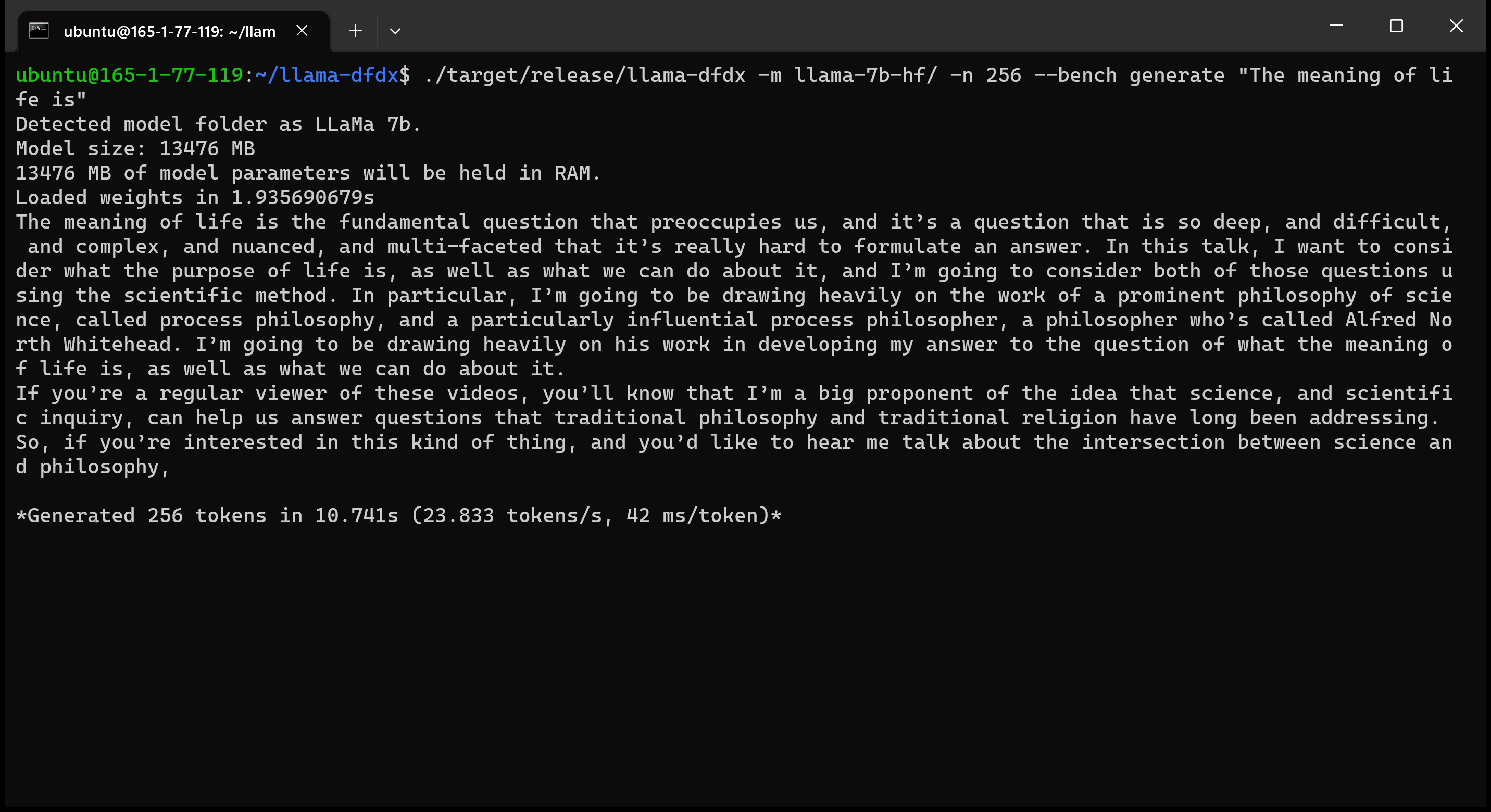
sudo apt install git-lfsgit lfs install .git clone https://huggingface.co/decapoda-research/llama-7b-hfgit clone https://huggingface.co/decapoda-research/llama-13b-hfgit clone https://huggingface.co/decapoda-research/llama-65b-hfpython3.x -m venv <my_env_name> para crear un entorno virtual de Python, donde x es su versión de Python preferidasource <my_env_name>binactivate (o <my_env_name>Scriptsactivate si está en Windows) para activar el entornopip install numpy torchpython convert.py para convertir los pesos del modelo en Formato comprensible de oxidación: a. Llama 7b: python convert.py b. Llama 13B: python convert.py llama-13b-hf c. Llama 65b: python convert.py llama-65b-hf Puedes compilar con comandos normales de óxido:
Con cuda:
cargo build --release -F cudaSin cuda:
cargo build --releaseCon args predeterminados:
./target/release/llama-dfdx --model < model-dir > generate " <prompt> "
./target/release/llama-dfdx --model < model-dir > chat
./target/release/llama-dfdx --model < model-dir > file < path to prompt file >Para ver qué comandos/args personalizados puede usar:
./target/release/llama-dfdx --help

