llama dfdx
1.0.0
This repo contains the popular LLaMa 7b language model, fully implemented in the rust programming language!
Uses dfdx tensors and CUDA acceleration.
This runs LLaMa directly in f16, meaning there is no hardware acceleration on CPU. Using CUDA is heavily recommended.
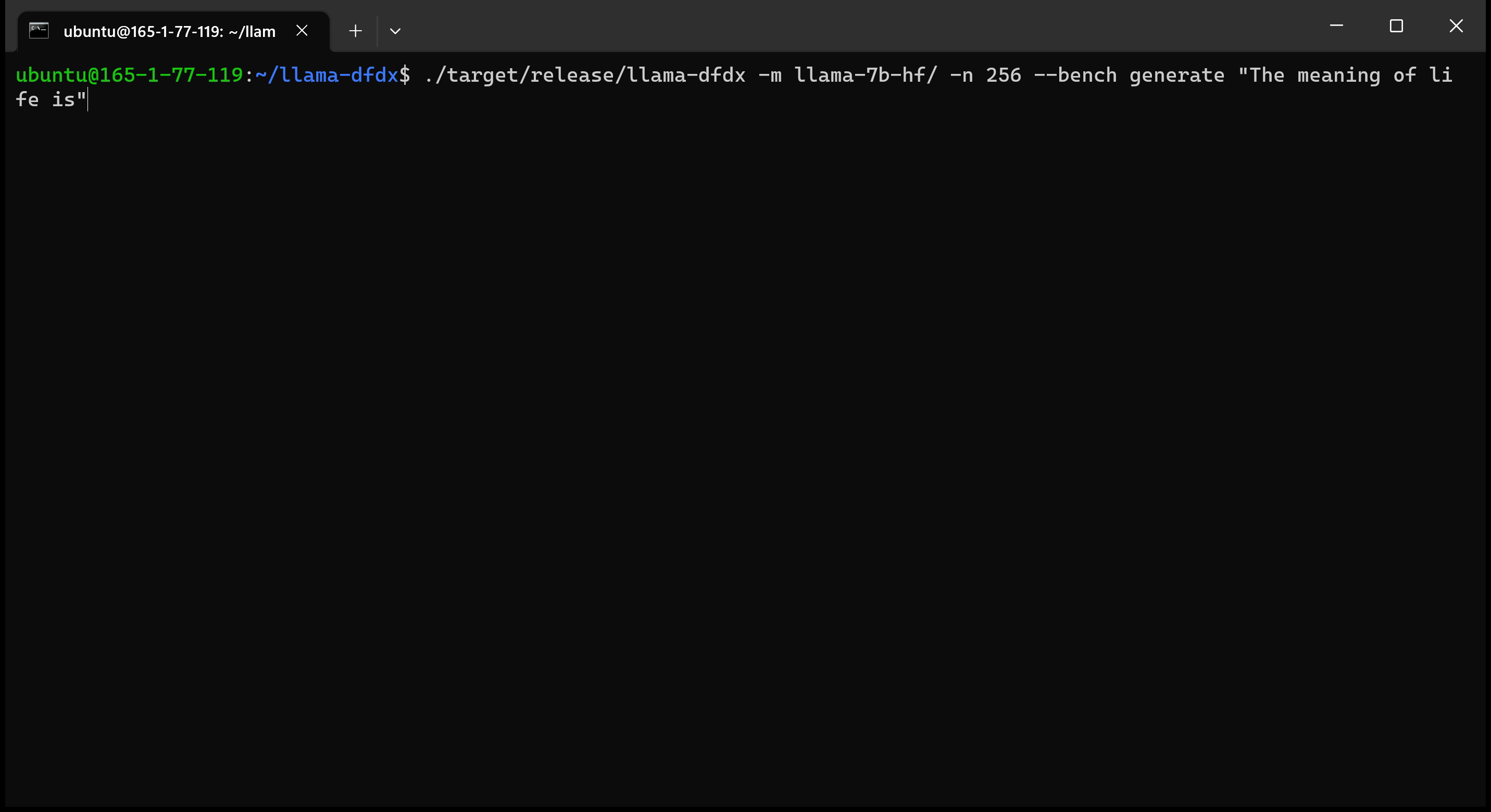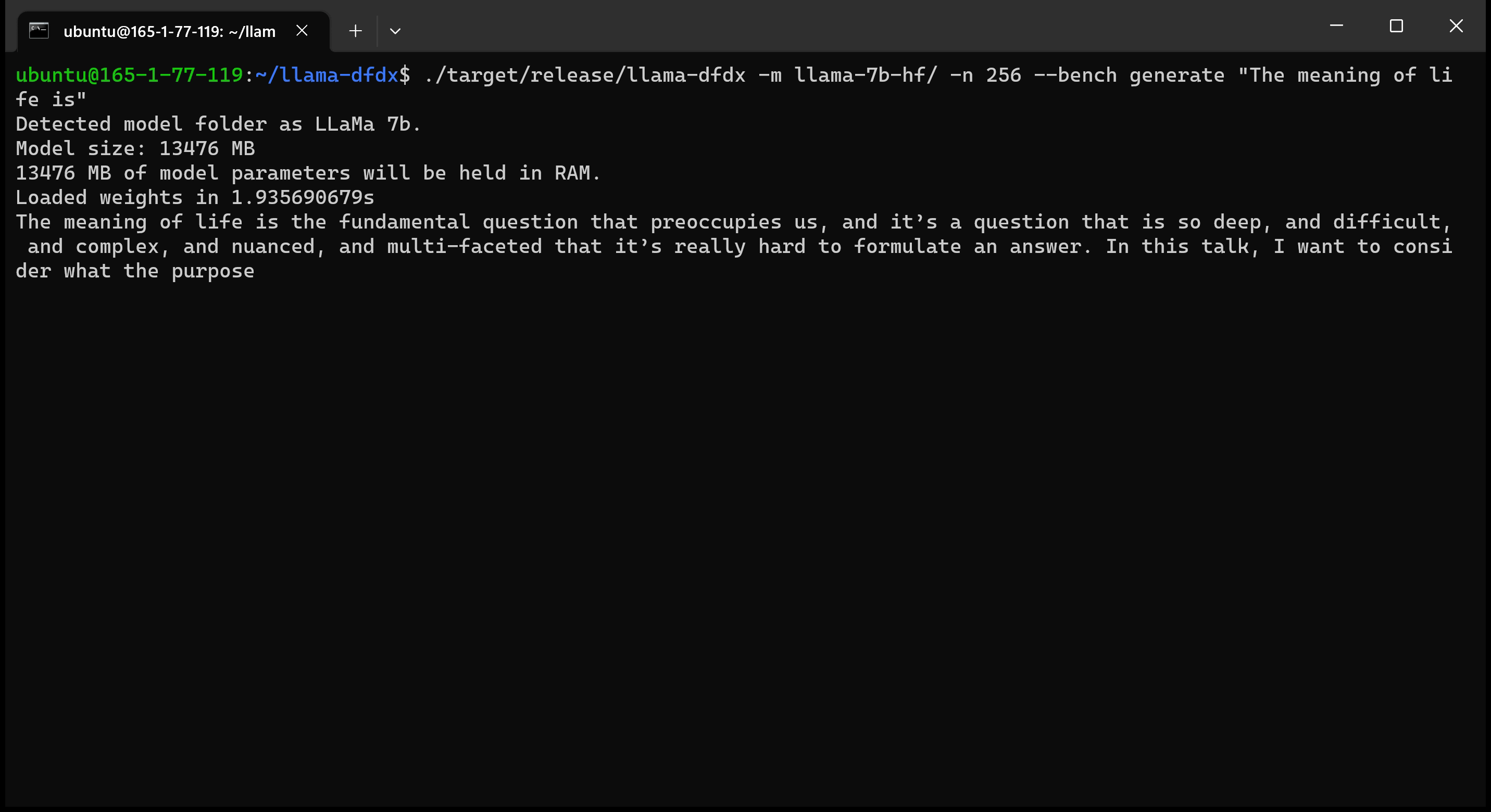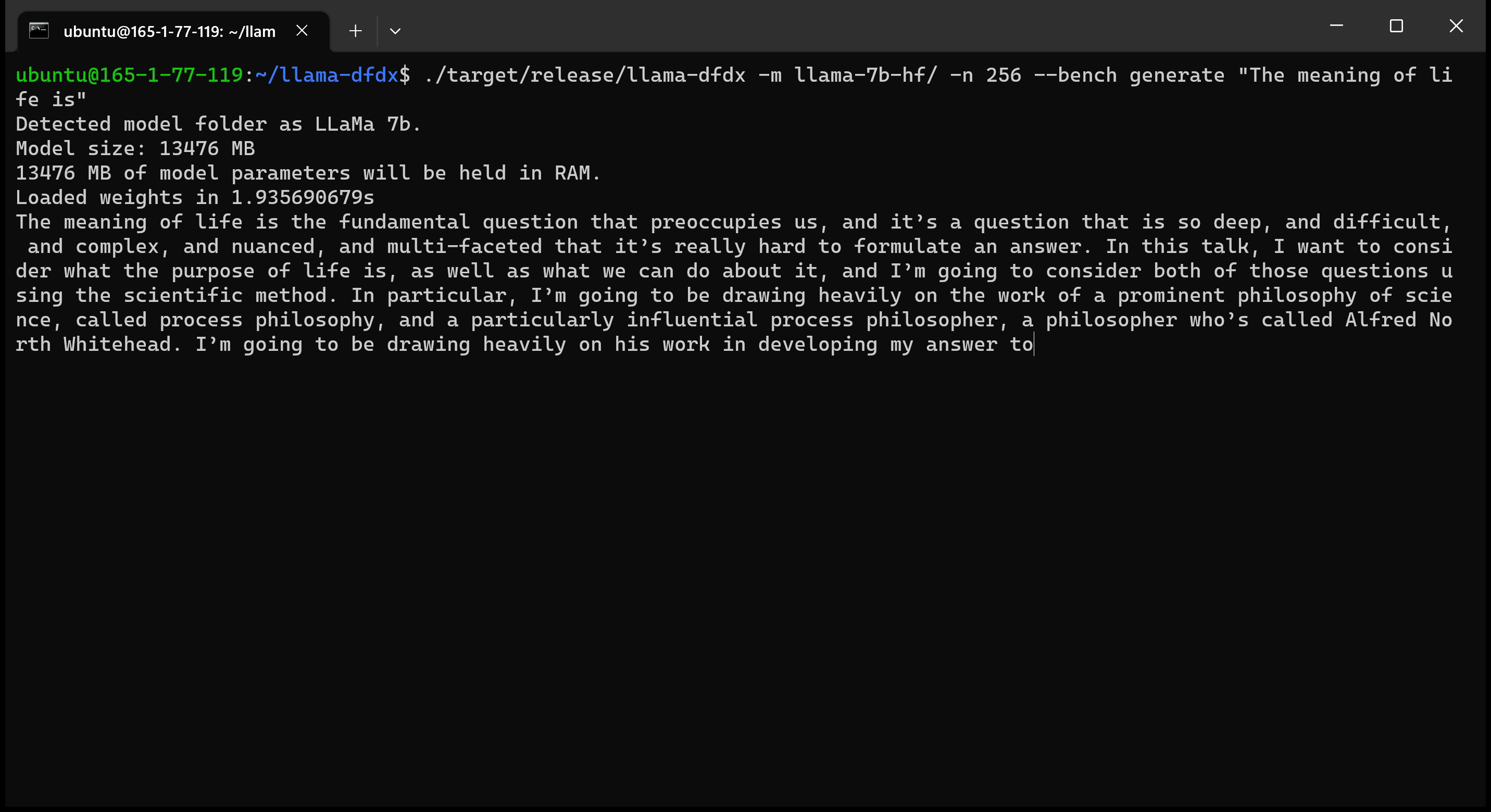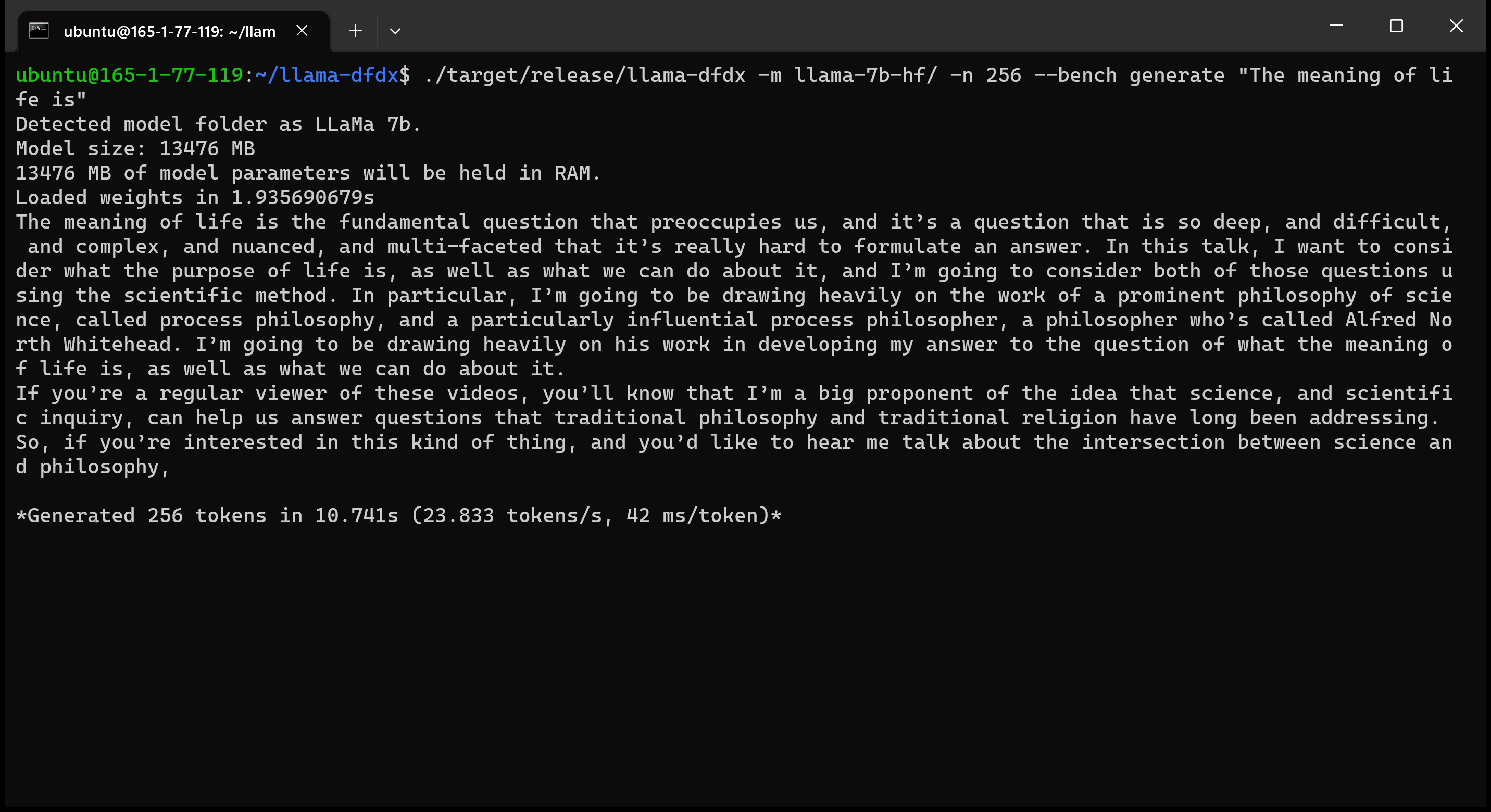
Here is the 7b model running on an A10 GPU:
sudo apt install git-lfsgit lfs install.git clone https://huggingface.co/decapoda-research/llama-7b-hfgit clone https://huggingface.co/decapoda-research/llama-13b-hfgit clone https://huggingface.co/decapoda-research/llama-65b-hfpython3.x -m venv <my_env_name> to create a python virtual environment, where x is your prefered python versionsource <my_env_name>binactivate (or <my_env_name>Scriptsactivate if on Windows) to activate the environmentpip install numpy torchpython convert.py to convert the model weights to rust understandable format:
a. LLaMa 7b: python convert.py
b. LLaMa 13b: python convert.py llama-13b-hf
c. LLaMa 65b: python convert.py llama-65b-hfYou can compile with normal rust commands:
With cuda:
cargo build --release -F cudaWithout cuda:
cargo build --releaseWith default args:
./target/release/llama-dfdx --model <model-dir> generate "<prompt>"
./target/release/llama-dfdx --model <model-dir> chat
./target/release/llama-dfdx --model <model-dir> file <path to prompt file>To see what commands/custom args you can use:
./target/release/llama-dfdx --help

