llama dfdx
1.0.0
このレポは、Rustプログラミング言語で完全に実装された人気のあるLlama 7B言語モデルが含まれています!
DFDXテンソルとCUDA加速を使用します。
これにより、F16で直接ラマが実行されます。つまり、CPUにハードウェアアクセラレーションはありません。 CUDAの使用をお勧めします。
これがA10 GPUで実行されている7Bモデルです。
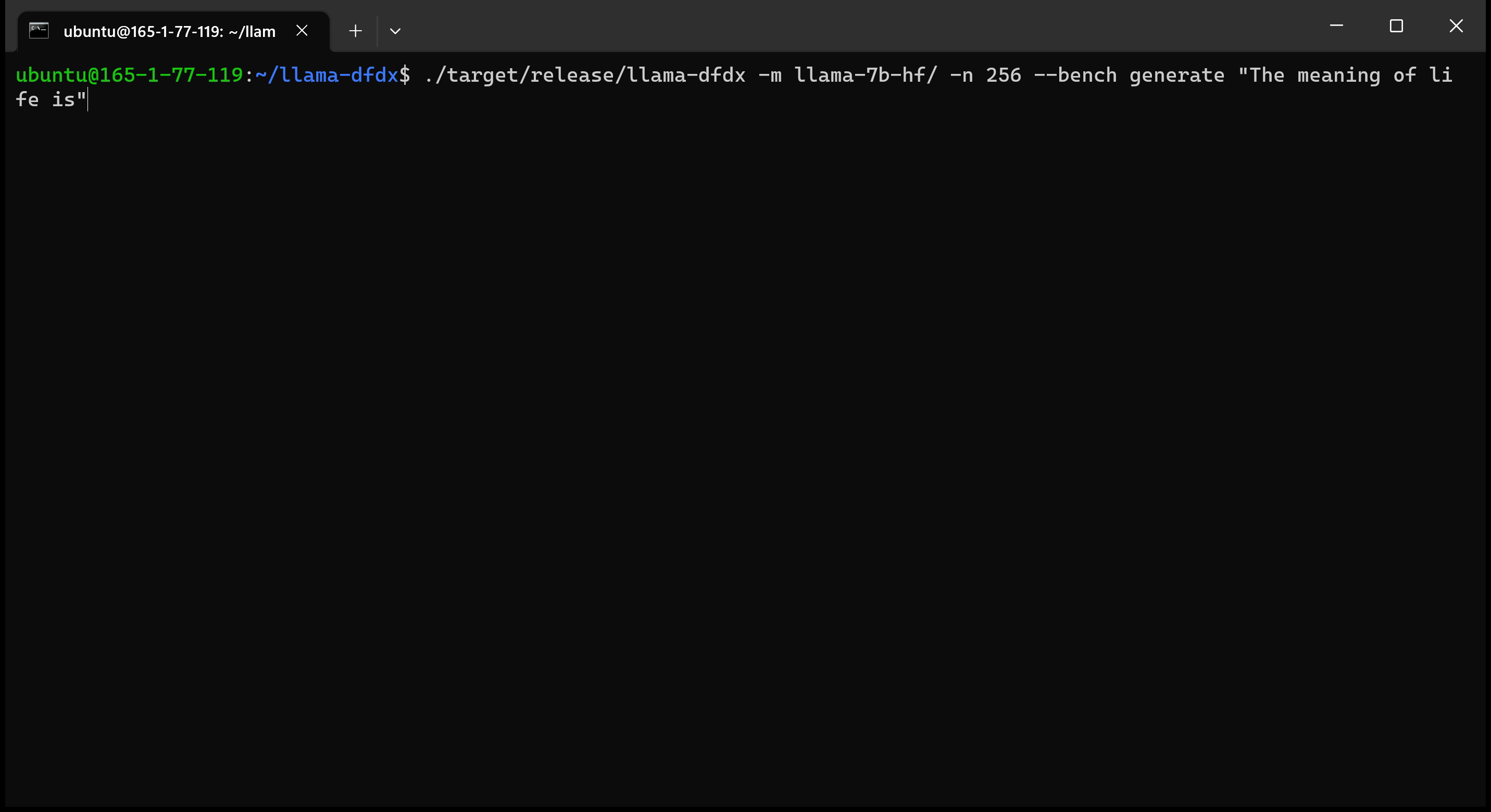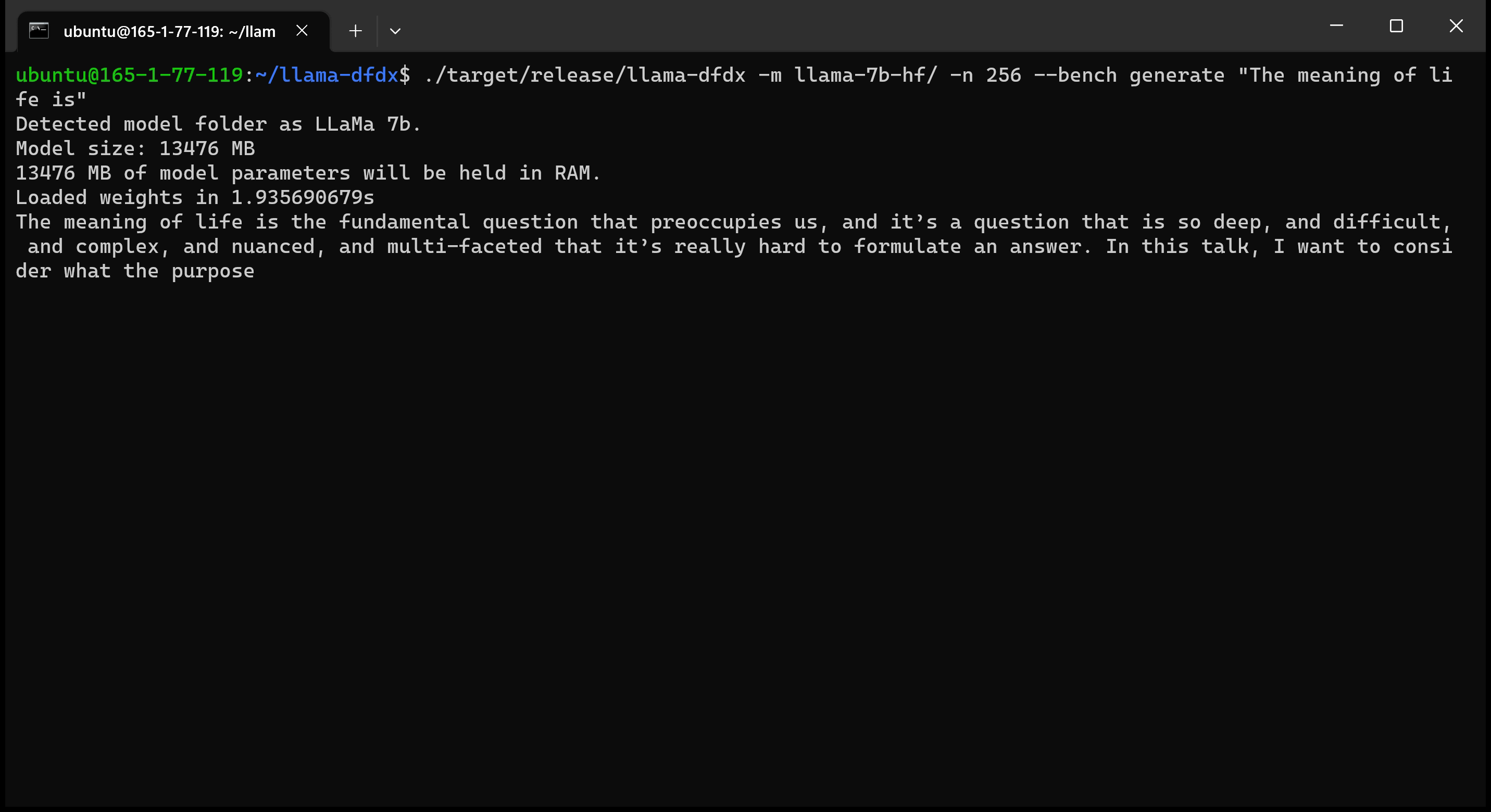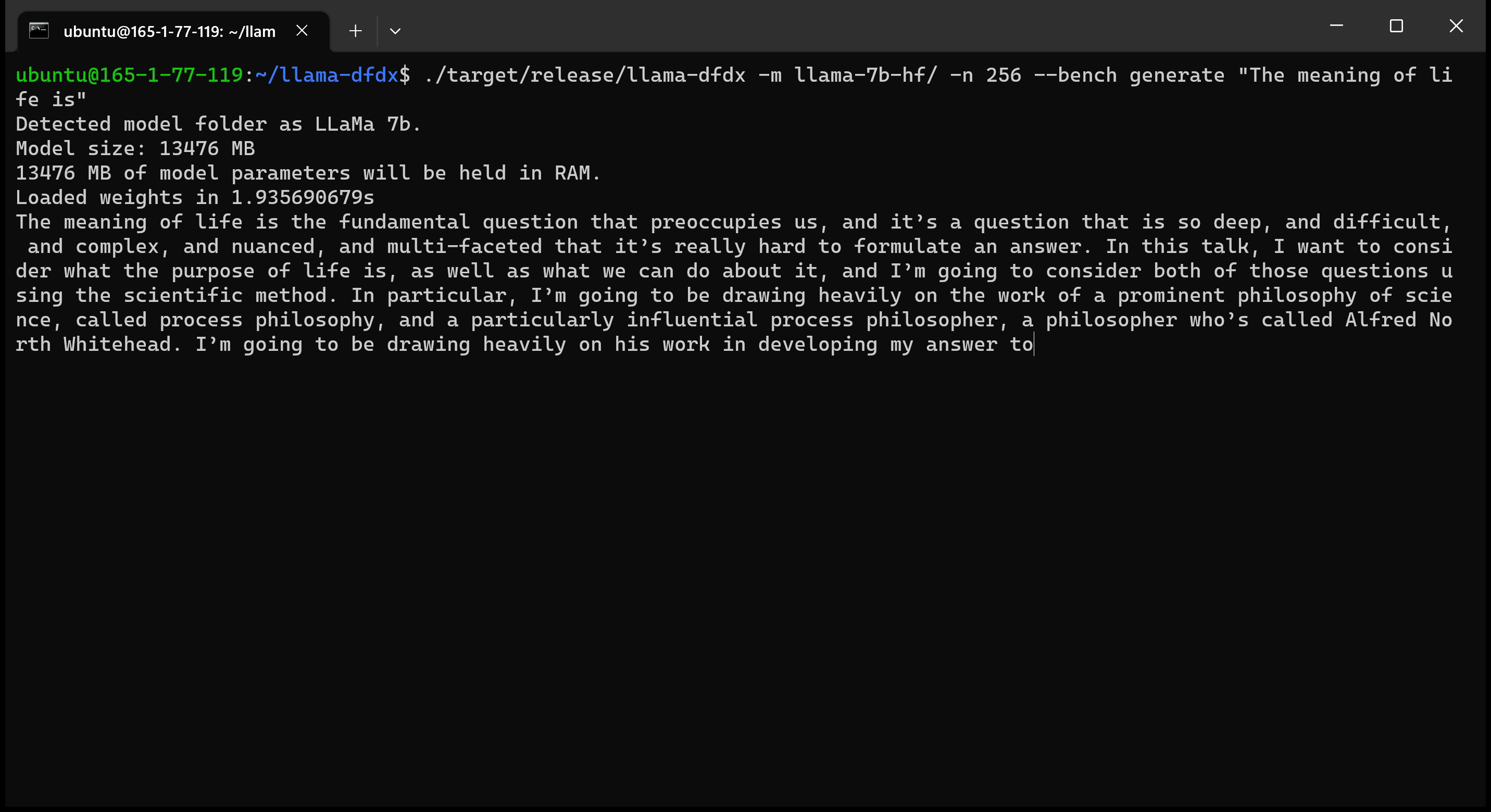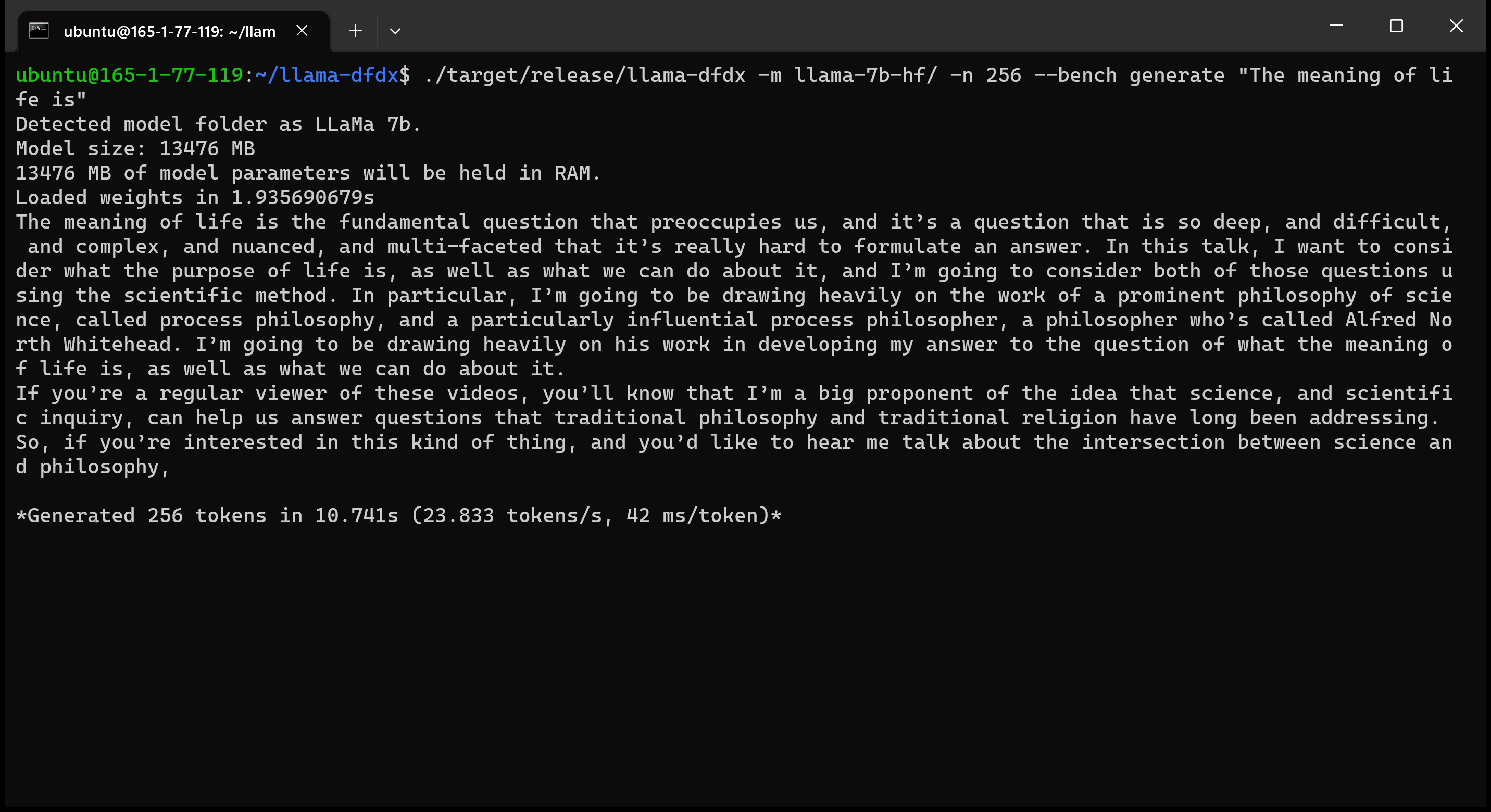
sudo apt install git-lfs実行できますgit lfs installを使用してGit LFSを有効にします。git clone https://huggingface.co/decapoda-research/llama-7b-hfgit clone https://huggingface.co/decapoda-research/llama-13b-hfgit clone https://huggingface.co/decapoda-research/llama-65b-hfx python3.x -m venv <my_env_name>を実行するには、python仮想環境を作成します。source <my_env_name>binactivate (または<my_env_name>Scriptsactivate )環境をアクティブにしますpip install numpy torch実行しますpython convert.pyを実行して、モデルの重みを錆に変換して理解できる形式:a。 llama 7b: python convert.py b。 llama 13b: python convert.py llama-13b-hf c。 llama 65b: python convert.py llama-65b-hf 通常の錆コマンドでコンパイルできます。
cudaで:
cargo build --release -F cudacudaなし:
cargo build --releaseデフォルトのargsで:
./target/release/llama-dfdx --model < model-dir > generate " <prompt> "
./target/release/llama-dfdx --model < model-dir > chat
./target/release/llama-dfdx --model < model-dir > file < path to prompt file >どのコマンド/カスタムARGを使用できるかを確認するには:
./target/release/llama-dfdx --help

