llama dfdx
1.0.0
Este repo contém o popular modelo de linguagem LLAMA 7B, totalmente implementado na linguagem de programação da ferrugem!
Usa tensores DFDX e aceleração CUDA.
Isso é executado diretamente no F16, o que significa que não há aceleração de hardware na CPU. Usando CUDA é fortemente recomendado.
Aqui está o modelo 7B em execução em uma GPU A10:
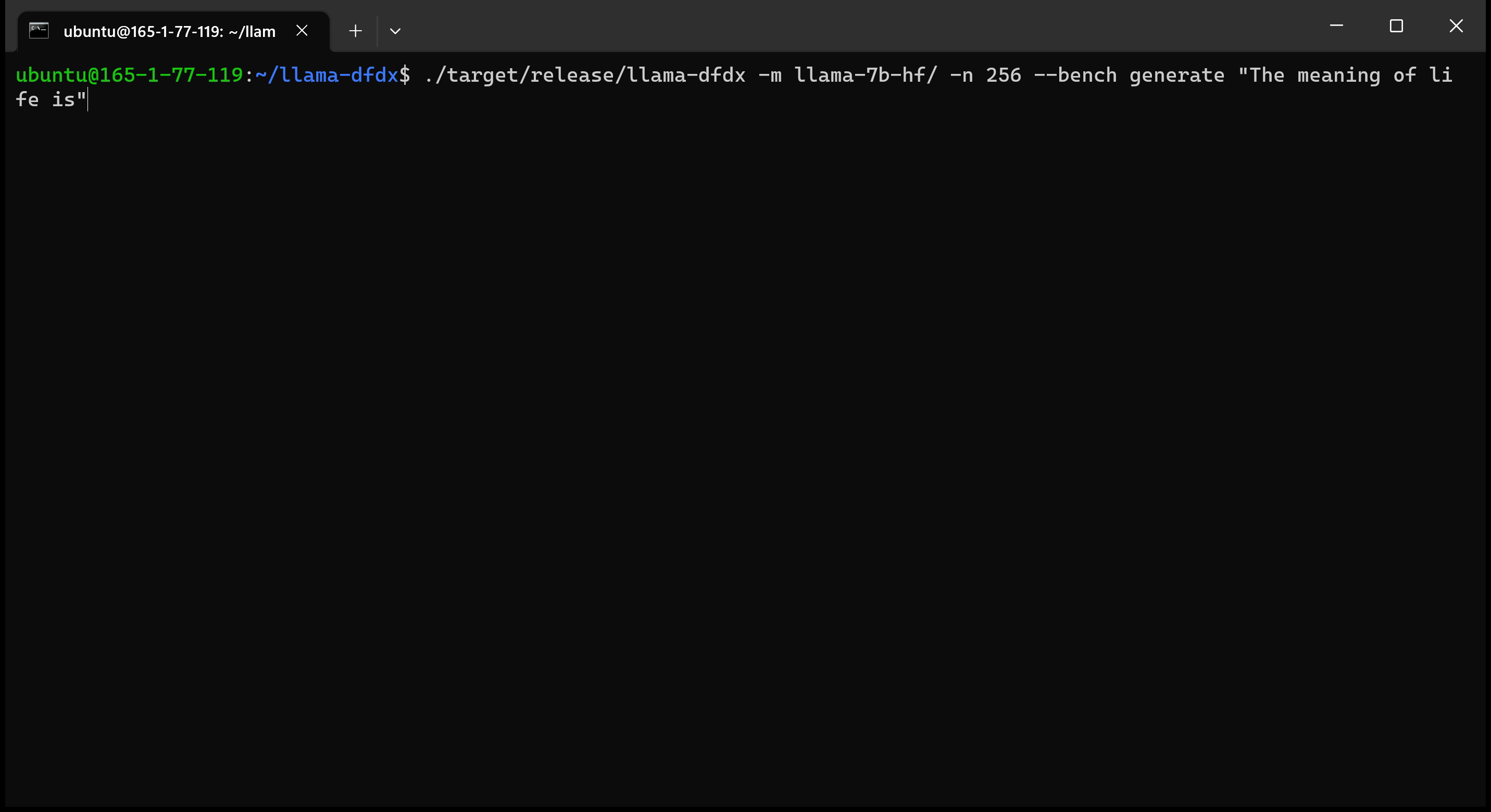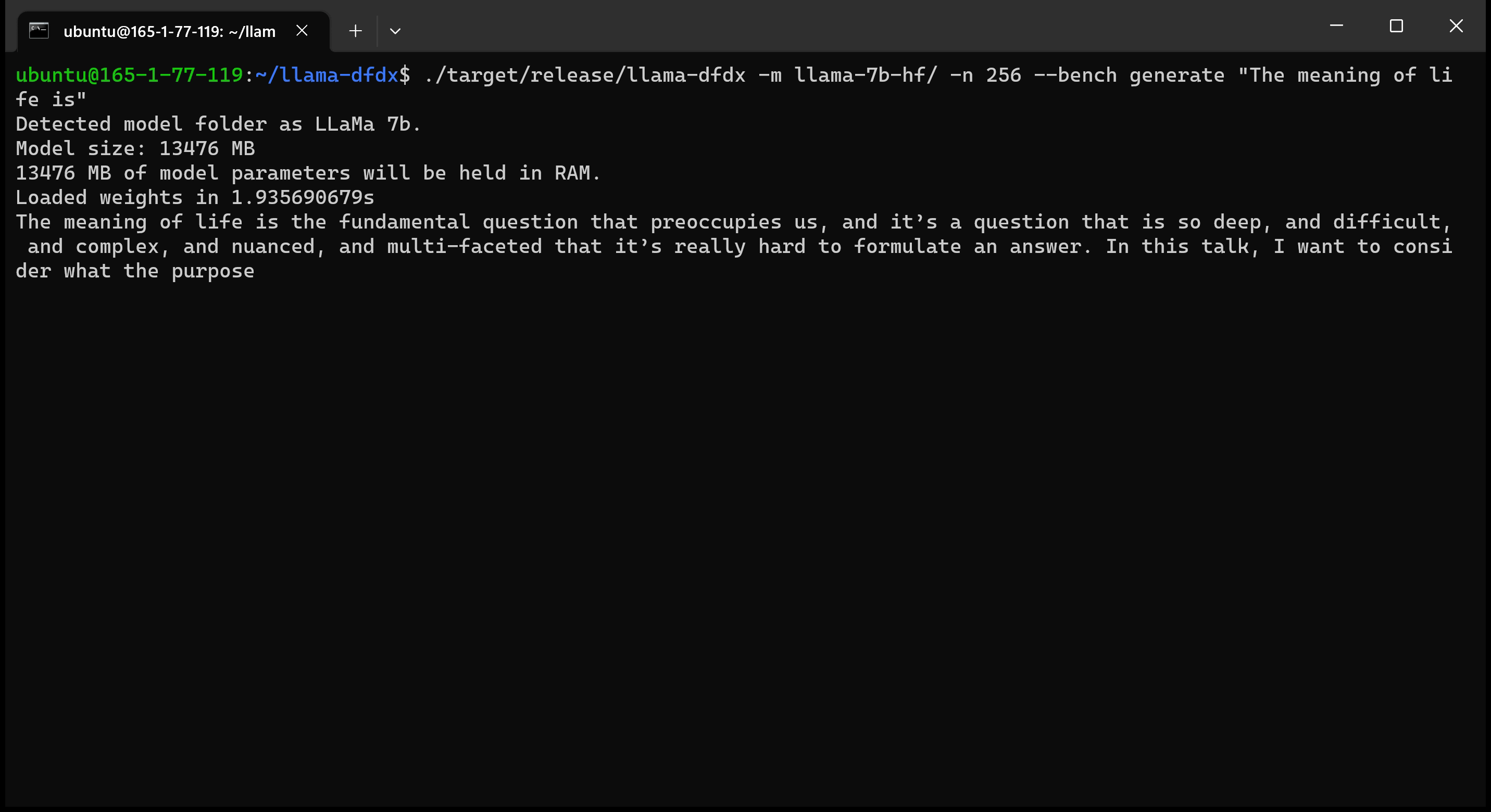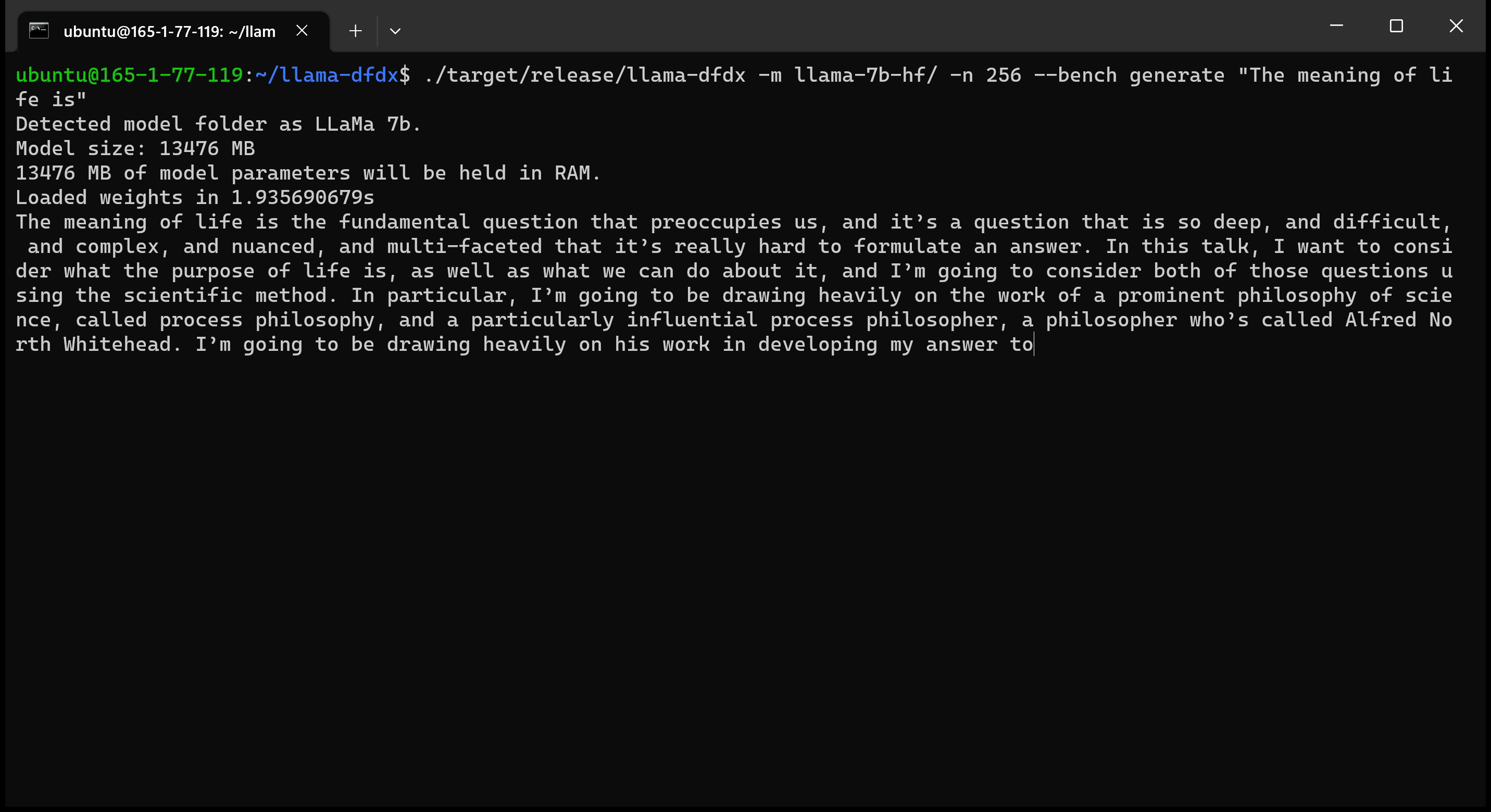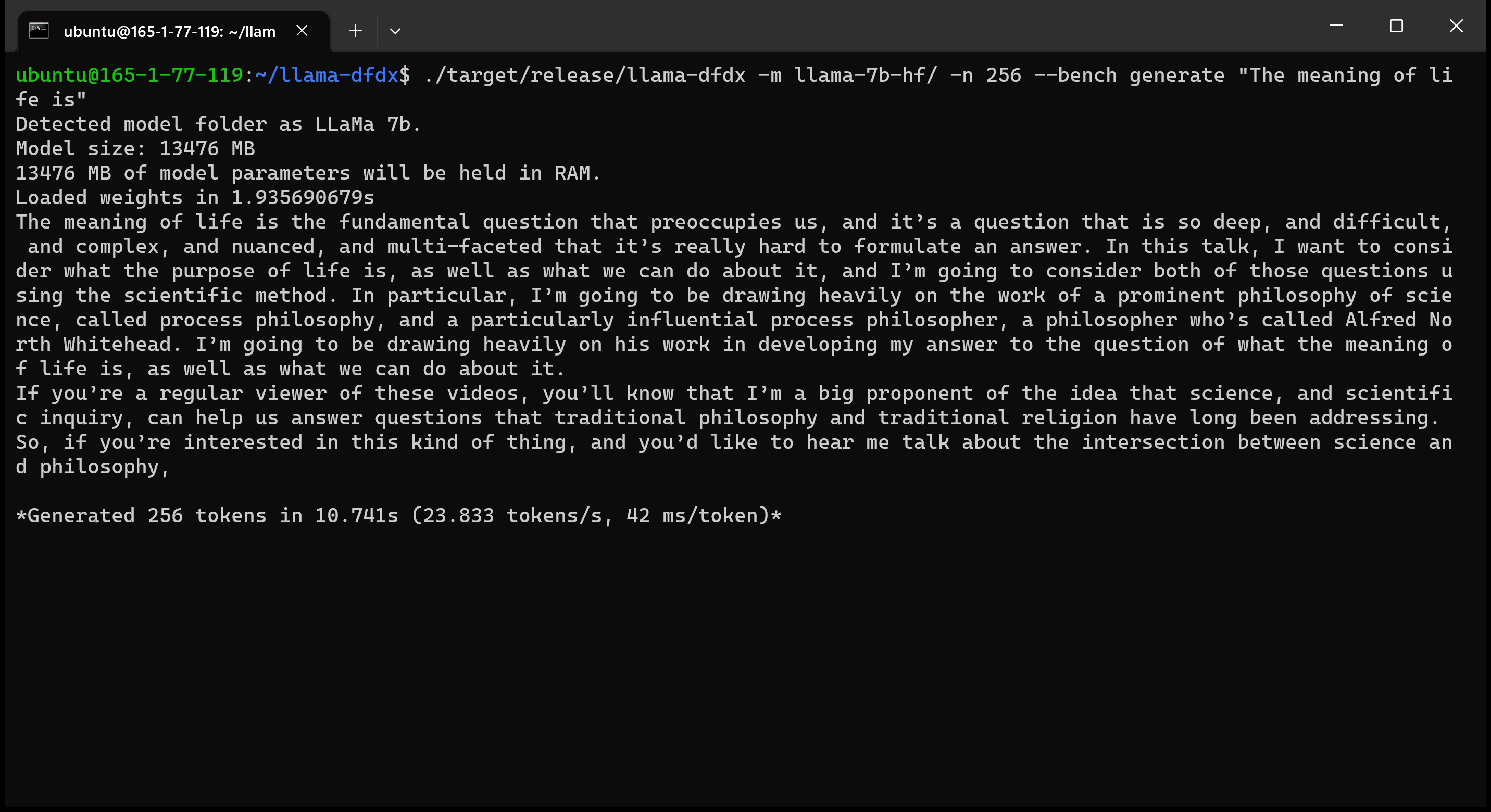
sudo apt install git-lfsgit lfs install .git clone https://huggingface.co/decapoda-research/llama-7b-hfgit clone https://huggingface.co/decapoda-research/llama-13b-hfgit clone https://huggingface.co/decapoda-research/llama-65b-hfpython3.x -m venv <my_env_name> para criar um ambiente virtual python, onde x é sua versão preferida do Pythonsource <my_env_name>binactivate (ou <my_env_name>Scriptsactivate se no Windows) para ativar o ambientepip install numpy torchpython convert.py para converter os pesos do modelo em formato compreensível da ferrugem: a. Llama 7b: python convert.py b. LLAMA 13B: python convert.py llama-13b-hf c. Llama 65b: python convert.py llama-65b-hf Você pode compilar com comandos normais de ferrugem:
Com CUDA:
cargo build --release -F cudaSem Cuda:
cargo build --releaseCom args padrão:
./target/release/llama-dfdx --model < model-dir > generate " <prompt> "
./target/release/llama-dfdx --model < model-dir > chat
./target/release/llama-dfdx --model < model-dir > file < path to prompt file >Para ver quais comandos/args personalizados você pode usar:
./target/release/llama-dfdx --help

