llama dfdx
1.0.0
Dieses Repo enthält das beliebte Lama 7B -Sprachmodell, das in der Rust -Programmiersprache vollständig implementiert ist!
Verwendet DFDX -Tensoren und Cuda -Beschleunigung.
Dies läuft Lama direkt in F16, was bedeutet, dass die CPU keine Hardwarebeschleunigung gibt. Die Verwendung von CUDA wird stark empfohlen.
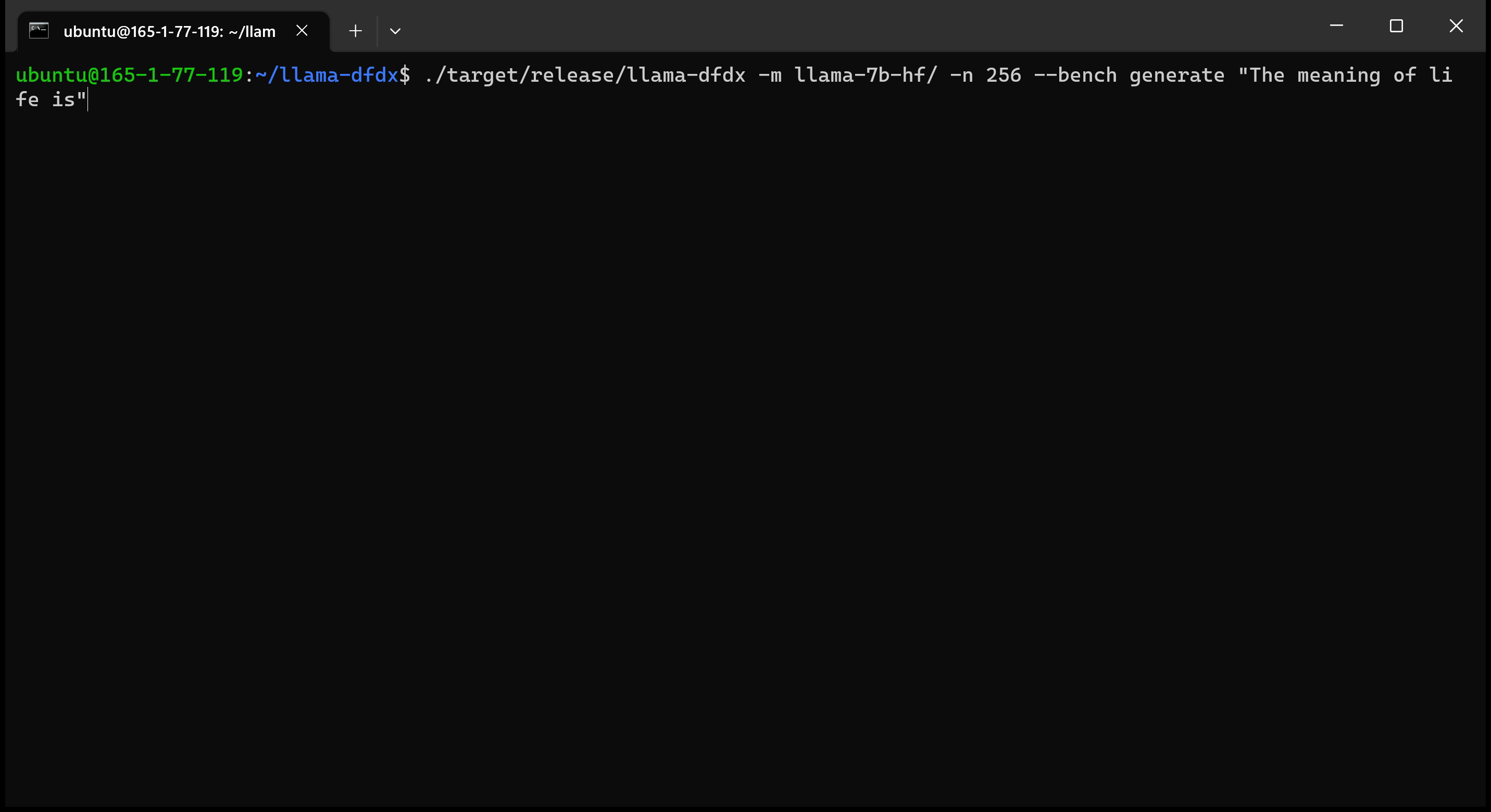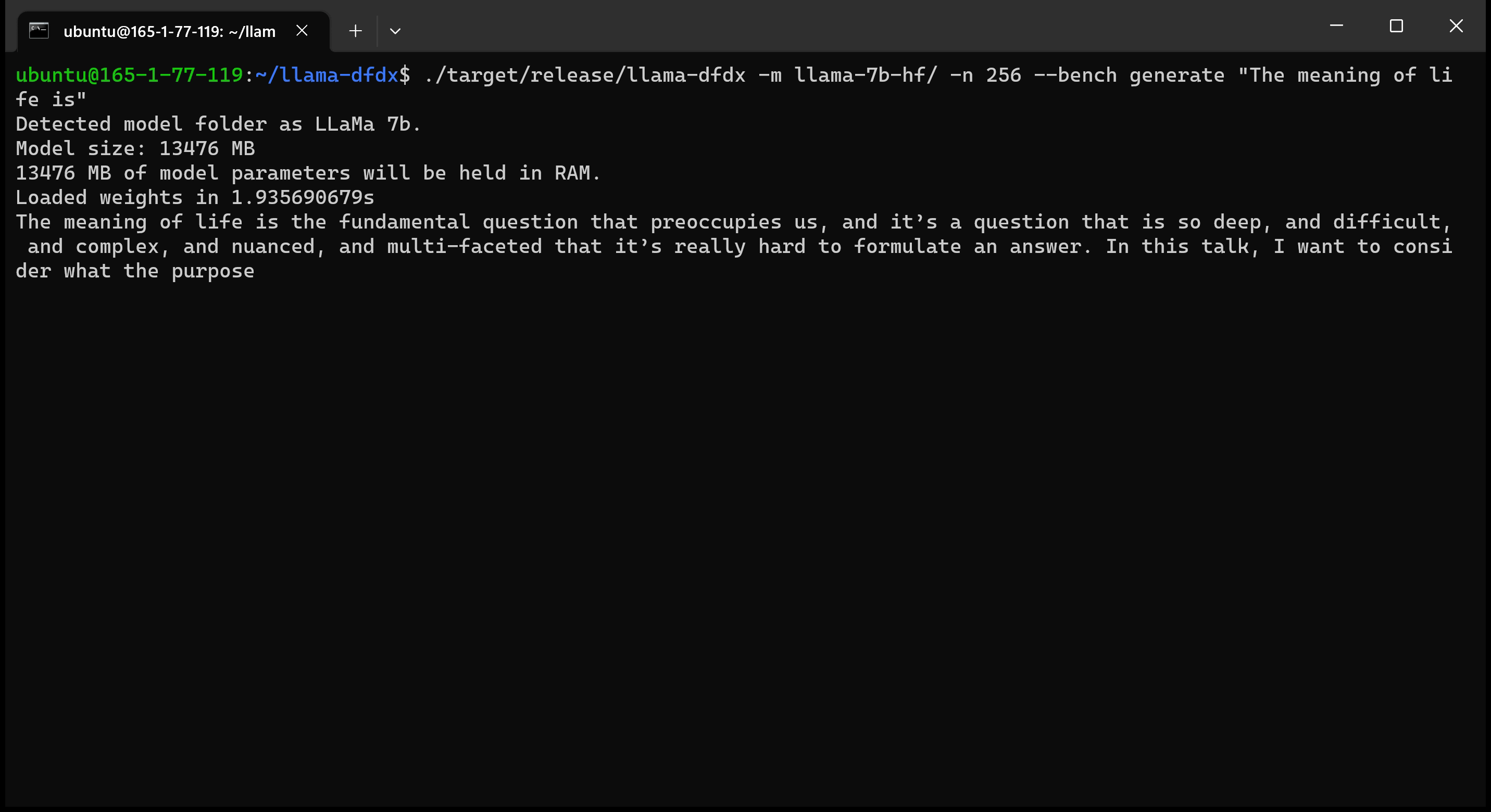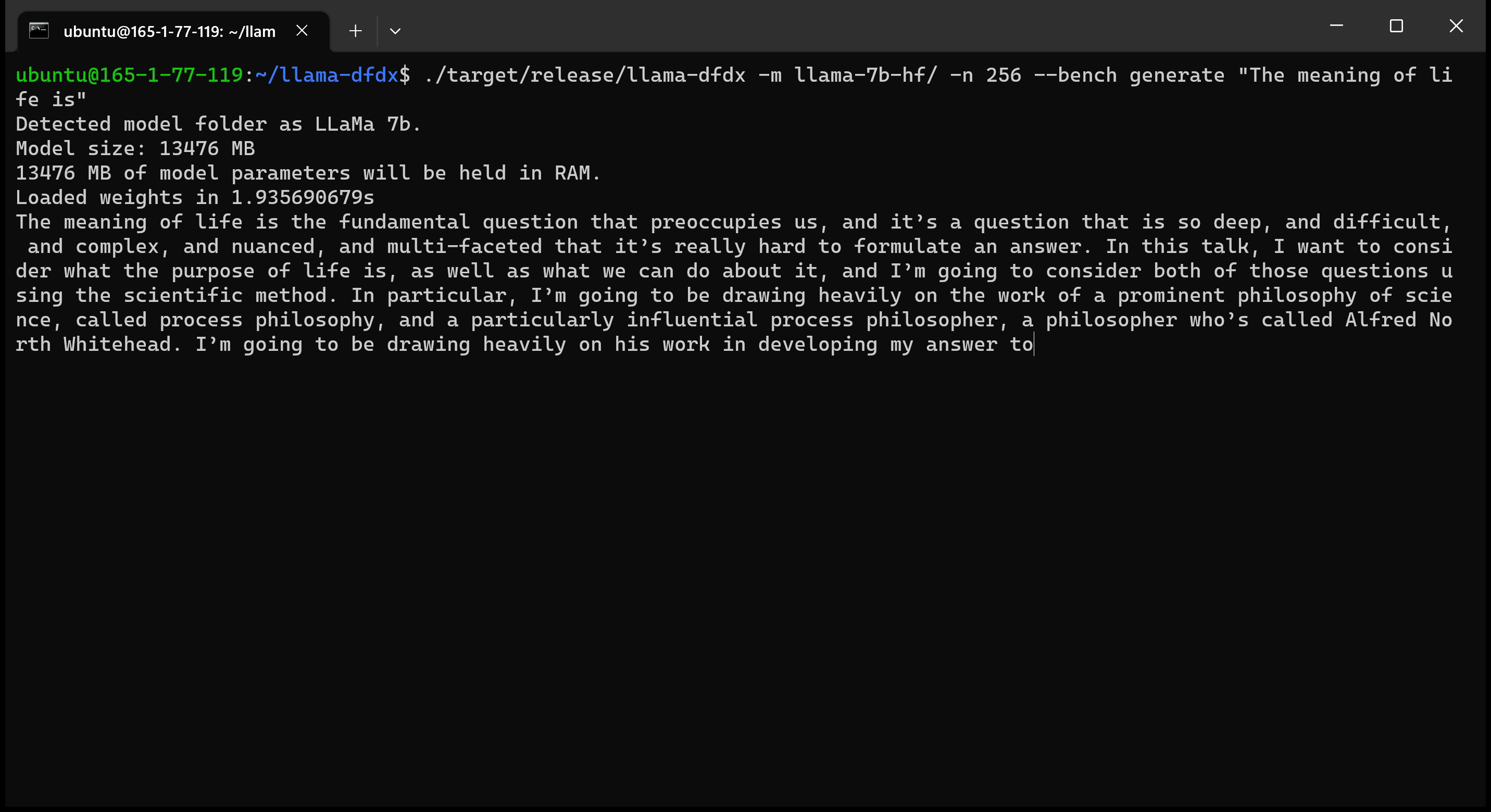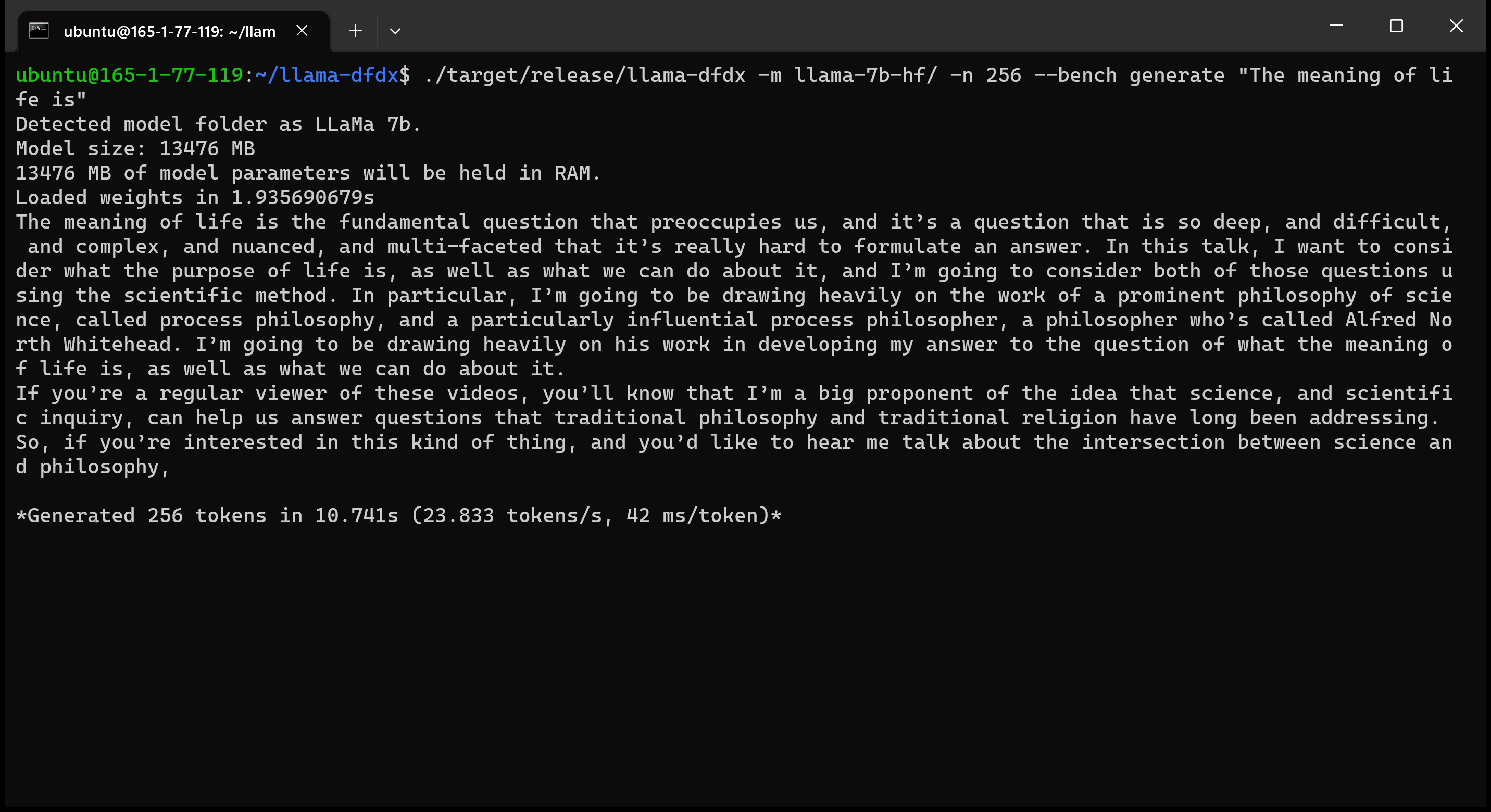
Hier ist das 7B -Modell, das auf einer A10 -GPU ausgeführt wird:
sudo apt install git-lfsgit lfs install .git clone https://huggingface.co/decapoda-research/llama-7b-hfgit clone https://huggingface.co/decapoda-research/llama-13b-hfgit clone https://huggingface.co/decapoda-research/llama-65b-hfpython3.x -m venv <my_env_name> aus, um eine virtuelle Python -Umgebung zu erstellen, in der x Ihre bevorzugte Python -Version istsource <my_env_name>binactivate (oder <my_env_name>Scriptsactivate wenn unter Windows), um die Umgebung zu aktivierenpip install numpy torchpython convert.py aus, um die Modellgewichte in das verständliche Format zu konvertieren: a. LAMA 7B: python convert.py b. LAMA 13B: python convert.py llama-13b-hf c. LAMA 65B: python convert.py llama-65b-hf Sie können mit normalen Rostbefehlen kompilieren:
Mit Cuda:
cargo build --release -F cudaOhne Cuda:
cargo build --releaseMit Standardargs:
./target/release/llama-dfdx --model < model-dir > generate " <prompt> "
./target/release/llama-dfdx --model < model-dir > chat
./target/release/llama-dfdx --model < model-dir > file < path to prompt file >Um zu sehen, welche Befehle/benutzerdefinierten Argumente Sie verwenden können:
./target/release/llama-dfdx --help

